HDL4SE:软件工程师学习Verilog语言(十一)
11 流水线
前面一节介绍了状态机的概念。状态机用于描述事务处理的一个程序性流程,可以组成顺序,分支,循环的事务处理流程。这些概念本来在verilog中的行为级描述中是有的,但是由于不是RTL描述,因此无法直接编译成电路,状态机则提供了顺序,分支,循环等控制结构的RTL描述。
状态机的特点是,整个处理流程任何时候只会在一个状态中,只处理一个事务。比如描述一个软件工程师的工作,可能是需求分析,概要设计,详细设计,编码,调试,测试,并在这几个状态之间来回切换,用状态机是比较恰当的。但是如果对一个分工比较明确的团队,上述几种工作可能是固定由相应的小组完成的,整个团队可以同时开展几个项目,项目在小组之间流转,特定的小组只完成针对项目的固定事务,这就是工厂的生产流水线的概念。
流水线由处理不同事务的节点组成,节点之间必须协同工作,这种协同有两种方式,一种是同步的,这种流水线每个节点事务处理的时间是固定的,事务进入节点后,会在某个固定的时钟周期后完成。此时节点之间只要在时钟同步下进行协同就行了。典型的实例是4个时钟周期完成一个32位的浮点乘法运算,其实是将浮点乘法分成四步,每一步都在一个时钟周期内完成,从前一步接收输入数据,处理后送到下一步继续处理。这样,虽然每个浮点都需要四个时钟周期才能完成,但是浮点乘法器采用流水线结构后,每个时钟周期都能够接收一个运算请求,并且输出一个结果,也就是平均每个周期能够完成一个浮点乘法运算。而且这种流水线组织各个部件之间不需要连接控制信号,它们各自按照事先规定好的时钟周期处理,就能够协同完成事务,这种协同称为同步协同。还有一种就是异步的了,由于各个节点完成事务的时钟周期不确定,可能与事务内容相关,也有可能跟外部环境(比如多节点共享的DDR读写)相关。此时节点之间就需要进行通信,来实现节点之间的协同。一般的通信手段就是用一个通知信号传递信息,比如允许信号,完成信号什么的,高级一点的用个比如FIFO之类进行缓冲,让节点之间的协同相对柔性一些,不至于造成大量的相互等待,这样有助于提高整个流水线的效率。
我们按惯例还是举个例子来说明流水线的做法,本节先讨论异步流水线,关于同步流水线后面实现RISC-V CPU时会有相应例子。
本节以流行的深度卷积神经网络推理的实现作为例子。先介绍深度卷积神经网络的基本概念,然后描述具体实现步骤,也会分多次逐步修改实现,一开始是用c语言实现各个单元,后面逐步把每个c语言描述的模型改写成verilog的实现。目标是,将一个训练好的网络模型转换为c语言代码,然后在基本库的支持下运行推理过程,在运行过程中将网络结构和系数转换为verilog语言表示,然后将verilog代码描述的卷积神经网络编译为目标代码,用HDL4SE系统运行。
11.1 深度卷积神经网络简介
深度卷积神经网络是进行数据分类的比较有效的算法,本节中主要介绍GoogLeNet网络,它的输入是固定的224x224像素大小的彩色图像数据,每个像素有三个分量,对应RGB分量。GoogLeNet网络将图像分为1000类,每一幅图像经过GoogLeNet计算后,输出一个1000x1的向量,表示这幅图像属于对应类的概率。注意其中的字母L用大写,据说是为了纪念深度神经网络的先驱LeNet。
深度神经网络的基本算法是卷积。所谓卷积,可以理解为用一个模板,去与目标进行乘累加计算,得到的结果是目标与模板的相符程度。模板在宽度和高度上一般比较小,一般是1x1, 3x3, 5x5, 7x7 ,据说也有更大的。模板中每个位置对应图像每个分量也有一个值,这样对三个分量的原始图像, 一个7x7模板实际上由7x7x3个数字组成。一个1x1的模板,实际上是对分量之间的相关性进行计算,比如检验彩色图片中像素是否为红色,可能用个(1,-3,-3)的1x1x3模板去跟每个像素的RGB分量进行乘累加,后面抛掉小于零的结果,得到的数字基本上是像素偏红的程度。一般把模板称为卷积核,模板中的数字称为卷积核系数。用这个模板套在输入数据上,将7x7x3中的每个系数与对应的图像数据相乘后累加在一起,构成这次计算的一个输出值,可以理解为是图像这个位置与模板的相似程度。在水平方向和垂直方向上移动模板,每次移动的步长称为卷积的步长(Stride)。移动后再计算一次乘累加值,这样每移动到一个位置就得到一个的值,于是就构成了输出图像的一个分量。据说麻坛高手用拇指在牌面一划,就能通过卷积认出手上的牌是红中、发财、三万、九筒、七条等等中的哪一种,低手就只能区分白板和非白板,会不会跟他脑中的卷积核配置相关啊。用多个卷积核对图像进行计算,就可以得到一幅多分量图像,实际上已经不是通常意义下的图像了,姑且继续称之为图像吧。一般计算之前会在输入图像周边扩展几个像素行或列,保证图像边缘的数据信息不会丢失,这个称为边缘扩展(PAD)。
总结一下:对InWxInHxInC的输入图像,一个卷积操作就是用N个kWxkHxInC系数组成的卷积核,按照(sW,sH)的步长在图像上移动,移动到边缘时假定边上有pW, pH的扩展像素,扩展的图像像素分量全部假设为0。每个位置将kWxkHxInC个系数和图像数据对应相乘再累加在一起,生成一个输出图像的像素,这样输出的图像是OutWxOutHxN,其中
OutH = (InH + 2 * pH - kH) / sH + 1;
OutW = (InW + 2 * pW - kW) / sW + 1;
这个运算操作将一个InWxInHxInC的输入图像变换为一个OutWxOutHxOutC的图像。卷积核的参数包括卷积的大小kW, kH,卷积核的个数N也就是输出图像的分量数OutC,平移步长sW, sH,扩展宽度pW, pH,如下图所示。
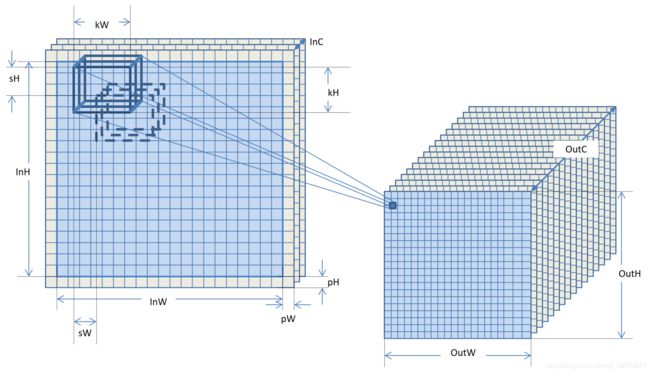
卷积计算的结果中,每个结果像素的分量与原始图像中的一个卷积核大小范围内的所有像素的所有分量都相关,因此卷积核的大小,其实是结果分量中信息来源范围。从原理上讲,卷积核大小大的,可以从原图像中较大范围内得到相关的信息,卷积核小的,相关的范围就小一些,不同大小的卷积核构成了不同尺度的相关信息。按说卷积核大的能够收集到的信息要更加全面一些,大不了把有些系数设置为0,效果就跟小的核一样了,然而卷积核大的计算量要大,3x3是1x1的九倍,5x5是3x3的将近三倍,7x7是5x5的将近两倍。更重要的原因是,较大的卷积核由于范围输入更大,得到的特征值反而更容易受到污染,需要经过更多的样本计算才能得到合适的系数,我们看东西时实在眼花缭乱,可以眯着眼睛看,让进来的图像信息少一些,反而更容易识别是什么场景。因此设计算法时需要考虑计算量的考虑还需要考虑用合适大小的卷积核,当然分量数直接跟计算量线性相关,因此控制分量数也是算法设计中的一个考虑因素。
除了卷积之外,还有全连接层也是线性操作,就是输出图像中的像素分量跟输入图像中的每个像素及分量都相关,有对应的系数,不是类似卷积的局部相关,可以看成是一个大小跟输入图像一样大而且无法移动的卷积核,当然结果也就是一个数。对图像的操作还有所谓Pooling,有点象卷积,只不过它不是通过系数乘累加,而是计算出局部范围内的最大值或平均值, LRN则是在分量内或者跨分量进行能量归一化操作,这些都是非线性操作,还有更多类型的操作,每个操作称为一个算子。类型众多的算子给网络设计带来了更多的可能。
一般卷积或者Pooling之后对生成的每个像素分量会有一个所谓的激活函数的概念,大概的意思是模拟人类神经元细胞的输出必须有个最低阈值才能激活的意思。激活函数一般是非线性的,比如常用的ReLU激活,就是将小于0的分量全部变成0,只有大于0的分量才有机会携带信息参与后面的计算。(理论上有说道吗?我也不大清楚)
从理论上可以证明,用单层的卷积计算或者全连接计算是无法完成复杂分类的,因此卷积神经网络一般是多层连接在一起的,前面的输出图像作为后面的输入图像,构成所谓的深度卷积神经网络。后面还出现了一个输出图像送到多个不同的算子,或者多个计算节点的输出汇总成一个输出,前者试图对一个输出图像进行不同(尺度或方法)的特征提取,后者试图将不同的方法提取出来的特征连接在一起,通过一个卷积或其他办法得到这些特征的之间相关性,获得新的特征。这样一来,深度神经网络的计算就构成了一个计算网络。
在卷积神经网络的发展中,对于如何设计计算网络,没有明确的理论或者方法做指导,也无法对一个网络的效果进行理论分析,似乎大家都是拼结果,由结果好坏来证明网络的好坏(当然,也许是孤陋寡闻了…)。然而有一种所谓的inception结构,在网络中作为基本的构成部件,得到了很多网络模型的认同。inception结构的的基本思路是对同一个输入图像进行1x1, 3x3, 5x5三个卷积计算和一个Pooling计算,注意设置参数让每个计算输出的w,h一致,但是输出的分量数可以不一样,每个卷积后面都用ReLU进行激活,最后把四个计算结果的每个像素的各个分量合并在一起(Concat),形成一个新的图像,这样就能够将输入图像的不同尺度卷积和Pool的结果相关在一起,得到更为本质的图像特征(为什么?理论上能说道么?)。inception结构已经发展了四个版本,基本思路是一样的,只是在3x3, 5x5和Pooling的卷积的处理不同,大部分是为了减少计算量,比如在3x3之前先做个1x1, 5x5之前也先做个1x1,缩减输入分量数,达到减少计算量的目的,再比如用1x3和3x3替代5x5,减少计算量等等。
在GoogLeNet中,inception的结构如下:

整个GoogLeNet网络中有9个Inception结构,每个结构中只是输出的分量数不同。这些inception结构再加上一些其他节点构成整个GoogLeNet网络结构如下:

这里看着似乎就是一条流水线,然而如果把其中的inception展开,那么这个网络还是挺复杂的。下面是这个网络的计算过程:

以下是各个节点的结构参数表,我们进行初步的统计,得到GoogLeNet对一幅图进行分类计算,需要的计算量是6390669848(乘累加),大概6.4G次左右,理论上1Tops的有效计算能力每秒能够分类156幅图像。
| NO | 名称 | 类型 | INW | INH | INC | OUTW | OUTH | OUTC | W/C0 | H/C1 | SW/C2 | SH/C3 | PW | PH | N | ACT | 计算量 | 系数个数 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | data | Data | 224 | 224 | 3 | 224 | 224 | 3 | ||||||||||
| 2 | conv1/7x7_s2 | Convolution | 224 | 224 | 3 | 112 | 112 | 64 | 7 | 7 | 2 | 2 | 3 | 3 | 64 | ReLU | 118816768 | 9472 |
| 4 | pool1/3x3_s2 | Pooling | 112 | 112 | 64 | 56 | 56 | 64 | 3 | 3 | 2 | 2 | 0 | 0 | 115806208 | |||
| 5 | pool1/norm1 | LRN | 56 | 56 | 64 | 56 | 56 | 64 | 802816 | |||||||||
| 6 | conv2/3x3_reduce | Convolution | 56 | 56 | 64 | 56 | 56 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 13045760 | 4160 |
| 8 | conv2/3x3 | Convolution | 56 | 56 | 64 | 56 | 56 | 192 | 3 | 3 | 1 | 1 | 1 | 1 | 192 | ReLU | 347418624 | 110784 |
| 10 | conv2/norm2 | LRN | 56 | 56 | 192 | 56 | 56 | 192 | 2408448 | |||||||||
| 11 | pool2/3x3_s2 | Pooling | 56 | 56 | 192 | 28 | 28 | 192 | 3 | 3 | 2 | 2 | 0 | 0 | 260262912 | |||
| 13 | inception_3a/1x1 | Convolution | 28 | 28 | 192 | 28 | 28 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 9683968 | 12352 |
| 15 | inception_3a/3x3_reduce | Convolution | 28 | 28 | 192 | 28 | 28 | 96 | 1 | 1 | 1 | 1 | 0 | 0 | 96 | ReLU | 14525952 | 18528 |
| 17 | inception_3a/3x3 | Convolution | 28 | 28 | 96 | 28 | 28 | 128 | 3 | 3 | 1 | 1 | 1 | 1 | 128 | ReLU | 86804480 | 110720 |
| 19 | inception_3a/5x5_reduce | Convolution | 28 | 28 | 192 | 28 | 28 | 16 | 1 | 1 | 1 | 1 | 0 | 0 | 16 | ReLU | 2420992 | 3088 |
| 21 | inception_3a/5x5 | Convolution | 28 | 28 | 16 | 28 | 28 | 32 | 5 | 5 | 1 | 1 | 2 | 2 | 32 | ReLU | 10060288 | 12832 |
| 23 | inception_3a/pool | Pooling | 28 | 28 | 192 | 28 | 28 | 192 | 3 | 3 | 1 | 1 | 1 | 1 | 260262912 | |||
| 26 | inception_3a/output | Concat | 28 | 28 | 28 | 28 | 416 | 64 | 128 | 32 | 192 | |||||||
| 28 | inception_3b/1x1 | Convolution | 28 | 28 | 416 | 28 | 28 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 41846784 | 53376 |
| 30 | inception_3b/3x3_reduce | Convolution | 28 | 28 | 416 | 28 | 28 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 41846784 | 53376 |
| 32 | inception_3b/3x3 | Convolution | 28 | 28 | 128 | 28 | 28 | 192 | 3 | 3 | 1 | 1 | 1 | 1 | 192 | ReLU | 173558784 | 221376 |
| 34 | inception_3b/5x5_reduce | Convolution | 28 | 28 | 416 | 28 | 28 | 32 | 1 | 1 | 1 | 1 | 0 | 0 | 32 | ReLU | 10461696 | 13344 |
| 36 | inception_3b/5x5 | Convolution | 28 | 28 | 32 | 28 | 28 | 96 | 5 | 5 | 1 | 1 | 2 | 2 | 96 | ReLU | 60286464 | 76896 |
| 38 | inception_3b/pool | Pooling | 28 | 28 | 416 | 28 | 28 | 416 | 3 | 3 | 1 | 1 | 1 | 1 | 1221409280 | |||
| 39 | inception_3b/pool_proj | Convolution | 28 | 28 | 416 | 28 | 28 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 20923392 | 26688 |
| 41 | inception_3b/output | Concat | 28 | 28 | 28 | 28 | 480 | 128 | 192 | 96 | 64 | |||||||
| 42 | pool3/3x3_s2 | Pooling | 28 | 28 | 480 | 14 | 14 | 480 | 3 | 3 | 2 | 2 | 0 | 0 | 406519680 | |||
| 44 | inception_4a/1x1 | Convolution | 14 | 14 | 480 | 14 | 14 | 192 | 1 | 1 | 1 | 1 | 0 | 0 | 192 | ReLU | 18100992 | 92352 |
| 46 | inception_4a/3x3_reduce | Convolution | 14 | 14 | 480 | 14 | 14 | 96 | 1 | 1 | 1 | 1 | 0 | 0 | 96 | ReLU | 9050496 | 46176 |
| 48 | inception_4a/3x3 | Convolution | 14 | 14 | 96 | 14 | 14 | 208 | 3 | 3 | 1 | 1 | 1 | 1 | 208 | ReLU | 35264320 | 179920 |
| 50 | inception_4a/5x5_reduce | Convolution | 14 | 14 | 480 | 14 | 14 | 16 | 1 | 1 | 1 | 1 | 0 | 0 | 16 | ReLU | 1508416 | 7696 |
| 52 | inception_4a/5x5 | Convolution | 14 | 14 | 16 | 14 | 14 | 48 | 5 | 5 | 1 | 1 | 2 | 2 | 48 | ReLU | 3772608 | 19248 |
| 54 | inception_4a/pool | Pooling | 14 | 14 | 480 | 14 | 14 | 480 | 3 | 3 | 1 | 1 | 1 | 1 | 406519680 | |||
| 55 | inception_4a/pool_proj | Convolution | 14 | 14 | 480 | 14 | 14 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 6033664 | 30784 |
| 57 | inception_4a/output | Concat | 14 | 14 | 14 | 14 | 512 | 192 | 208 | 48 | 64 | |||||||
| 59 | loss1/ave_pool | Pooling | 14 | 14 | 512 | 4 | 4 | 512 | 5 | 5 | 3 | 3 | 0 | 0 | 104865792 | |||
| 67 | inception_4b/1x1 | Convolution | 14 | 14 | 512 | 14 | 14 | 160 | 1 | 1 | 1 | 1 | 0 | 0 | 160 | ReLU | 16087680 | 82080 |
| 69 | inception_4b/3x3_reduce | Convolution | 14 | 14 | 512 | 14 | 14 | 112 | 1 | 1 | 1 | 1 | 0 | 0 | 112 | ReLU | 11261376 | 57456 |
| 71 | inception_4b/3x3 | Convolution | 14 | 14 | 112 | 14 | 14 | 224 | 3 | 3 | 1 | 1 | 1 | 1 | 224 | ReLU | 44299136 | 226016 |
| 73 | inception_4b/5x5_reduce | Convolution | 14 | 14 | 512 | 14 | 14 | 24 | 1 | 1 | 1 | 1 | 0 | 0 | 24 | ReLU | 2413152 | 12312 |
| 75 | inception_4b/5x5 | Convolution | 14 | 14 | 24 | 14 | 14 | 64 | 5 | 5 | 1 | 1 | 2 | 2 | 64 | ReLU | 7538944 | 38464 |
| 77 | inception_4b/pool | Pooling | 14 | 14 | 512 | 14 | 14 | 512 | 3 | 3 | 1 | 1 | 1 | 1 | 462522368 | |||
| 78 | inception_4b/pool_proj | Convolution | 14 | 14 | 512 | 14 | 14 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 6435072 | 32832 |
| 80 | inception_4b/output | Concat | 14 | 14 | 14 | 14 | 512 | 160 | 224 | 64 | 64 | |||||||
| 82 | inception_4c/1x1 | Convolution | 14 | 14 | 64 | 14 | 14 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 1630720 | 8320 |
| 84 | inception_4c/3x3_reduce | Convolution | 14 | 14 | 64 | 14 | 14 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 1630720 | 8320 |
| 86 | inception_4c/3x3 | Convolution | 14 | 14 | 128 | 14 | 14 | 256 | 3 | 3 | 1 | 1 | 1 | 1 | 256 | ReLU | 57852928 | 295168 |
| 88 | inception_4c/5x5_reduce | Convolution | 14 | 14 | 64 | 14 | 14 | 24 | 1 | 1 | 1 | 1 | 0 | 0 | 24 | ReLU | 305760 | 1560 |
| 90 | inception_4c/5x5 | Convolution | 14 | 14 | 24 | 14 | 14 | 64 | 5 | 5 | 1 | 1 | 2 | 2 | 64 | ReLU | 7538944 | 38464 |
| 92 | inception_4c/pool | Pooling | 14 | 14 | 64 | 14 | 14 | 64 | 3 | 3 | 1 | 1 | 1 | 1 | 7237888 | |||
| 93 | inception_4c/pool_proj | Convolution | 14 | 14 | 64 | 14 | 14 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 815360 | 4160 |
| 95 | inception_4c/output | Concat | 14 | 14 | 14 | 14 | 512 | 128 | 256 | 64 | 64 | |||||||
| 97 | inception_4d/1x1 | Convolution | 14 | 14 | 64 | 14 | 14 | 112 | 1 | 1 | 1 | 1 | 0 | 0 | 112 | ReLU | 1426880 | 7280 |
| 99 | inception_4d/3x3_reduce | Convolution | 14 | 14 | 64 | 14 | 14 | 144 | 1 | 1 | 1 | 1 | 0 | 0 | 144 | ReLU | 1834560 | 9360 |
| 101 | inception_4d/3x3 | Convolution | 14 | 14 | 144 | 14 | 14 | 288 | 3 | 3 | 1 | 1 | 1 | 1 | 288 | ReLU | 73213056 | 373536 |
| 103 | inception_4d/5x5_reduce | Convolution | 14 | 14 | 64 | 14 | 14 | 32 | 1 | 1 | 1 | 1 | 0 | 0 | 32 | ReLU | 407680 | 2080 |
| 105 | inception_4d/5x5 | Convolution | 14 | 14 | 32 | 14 | 14 | 64 | 5 | 5 | 1 | 1 | 2 | 2 | 64 | ReLU | 10047744 | 51264 |
| 107 | inception_4d/pool | Pooling | 14 | 14 | 64 | 14 | 14 | 64 | 3 | 3 | 1 | 1 | 1 | 1 | 7237888 | |||
| 108 | inception_4d/pool_proj | Convolution | 14 | 14 | 64 | 14 | 14 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 815360 | 4160 |
| 110 | inception_4d/output | Concat | 14 | 14 | 14 | 14 | 528 | 112 | 288 | 64 | 64 | |||||||
| 112 | loss2/ave_pool | Pooling | 14 | 14 | 528 | 4 | 4 | 528 | 5 | 5 | 3 | 3 | 0 | 0 | 111522048 | |||
| 120 | inception_4e/1x1 | Convolution | 14 | 14 | 528 | 14 | 14 | 256 | 1 | 1 | 1 | 1 | 0 | 0 | 256 | ReLU | 26543104 | 135424 |
| 122 | inception_4e/3x3_reduce | Convolution | 14 | 14 | 528 | 14 | 14 | 160 | 1 | 1 | 1 | 1 | 0 | 0 | 160 | ReLU | 16589440 | 84640 |
| 124 | inception_4e/3x3 | Convolution | 14 | 14 | 160 | 14 | 14 | 320 | 3 | 3 | 1 | 1 | 1 | 1 | 320 | ReLU | 90379520 | 461120 |
| 126 | inception_4e/5x5_reduce | Convolution | 14 | 14 | 528 | 14 | 14 | 32 | 1 | 1 | 1 | 1 | 0 | 0 | 32 | ReLU | 3317888 | 16928 |
| 128 | inception_4e/5x5 | Convolution | 14 | 14 | 32 | 14 | 14 | 128 | 5 | 5 | 1 | 1 | 2 | 2 | 128 | ReLU | 20095488 | 102528 |
| 130 | inception_4e/pool | Pooling | 14 | 14 | 528 | 14 | 14 | 528 | 3 | 3 | 1 | 1 | 1 | 1 | 491878464 | |||
| 131 | inception_4e/pool_proj | Convolution | 14 | 14 | 528 | 14 | 14 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 13271552 | 67712 |
| 133 | inception_4e/output | Concat | 14 | 14 | 14 | 14 | 832 | 256 | 320 | 128 | 128 | |||||||
| 134 | pool4/3x3_s2 | Pooling | 14 | 14 | 832 | 7 | 7 | 832 | 3 | 3 | 2 | 2 | 0 | 0 | 305311552 | |||
| 136 | inception_5a/1x1 | Convolution | 7 | 7 | 832 | 7 | 7 | 256 | 1 | 1 | 1 | 1 | 0 | 0 | 256 | ReLU | 10449152 | 213248 |
| 138 | inception_5a/3x3_reduce | Convolution | 7 | 7 | 832 | 7 | 7 | 160 | 1 | 1 | 1 | 1 | 0 | 0 | 160 | ReLU | 6530720 | 133280 |
| 140 | inception_5a/3x3 | Convolution | 7 | 7 | 160 | 7 | 7 | 320 | 3 | 3 | 1 | 1 | 1 | 1 | 320 | ReLU | 22594880 | 461120 |
| 142 | inception_5a/5x5_reduce | Convolution | 7 | 7 | 832 | 7 | 7 | 32 | 1 | 1 | 1 | 1 | 0 | 0 | 32 | ReLU | 1306144 | 26656 |
| 144 | inception_5a/5x5 | Convolution | 7 | 7 | 32 | 7 | 7 | 128 | 5 | 5 | 1 | 1 | 2 | 2 | 128 | ReLU | 5023872 | 102528 |
| 146 | inception_5a/pool | Pooling | 7 | 7 | 832 | 7 | 7 | 832 | 3 | 3 | 1 | 1 | 1 | 1 | 305311552 | |||
| 147 | inception_5a/pool_proj | Convolution | 7 | 7 | 832 | 7 | 7 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 5224576 | 106624 |
| 149 | inception_5a/output | Concat | 7 | 7 | 7 | 7 | 832 | 256 | 320 | 128 | 128 | |||||||
| 151 | inception_5b/1x1 | Convolution | 7 | 7 | 832 | 7 | 7 | 384 | 1 | 1 | 1 | 1 | 0 | 0 | 384 | ReLU | 15673728 | 319872 |
| 153 | inception_5b/3x3_reduce | Convolution | 7 | 7 | 832 | 7 | 7 | 192 | 1 | 1 | 1 | 1 | 0 | 0 | 192 | ReLU | 7836864 | 159936 |
| 155 | inception_5b/3x3 | Convolution | 7 | 7 | 192 | 7 | 7 | 384 | 3 | 3 | 1 | 1 | 1 | 1 | 384 | ReLU | 32532864 | 663936 |
| 157 | inception_5b/5x5_reduce | Convolution | 7 | 7 | 832 | 7 | 7 | 48 | 1 | 1 | 1 | 1 | 0 | 0 | 48 | ReLU | 1959216 | 39984 |
| 159 | inception_5b/5x5 | Convolution | 7 | 7 | 48 | 7 | 7 | 128 | 5 | 5 | 1 | 1 | 2 | 2 | 128 | ReLU | 7532672 | 153728 |
| 161 | inception_5b/pool | Pooling | 7 | 7 | 832 | 7 | 7 | 832 | 3 | 3 | 1 | 1 | 1 | 1 | 305311552 | |||
| 162 | inception_5b/pool_proj | Convolution | 7 | 7 | 832 | 7 | 7 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 5224576 | 106624 |
| 164 | inception_5b/output | Concat | 7 | 7 | 7 | 7 | 1024 | 384 | 384 | 128 | 128 | |||||||
| 165 | pool5/7x7_s1 | Pooling | 7 | 7 | 1024 | 1 | 1 | 1024 | 7 | 7 | 1 | 1 | 0 | 0 | 51381248 | |||
| 167 | loss3/classifier | InnerProduct | 1 | 1 | 1024 | 1 | 1 | 1000 | 1000 | 1024000 | 1024000 | |||||||
| 168 | loss3/loss3 | SoftmaxWithLoss | 1 | 1 | 1000 | 1 | 1 | 1000 | 1000 | |||||||||
| 合计 | 6390669848 | 6735888 |
总共有85个不同类型的节点,注意中间有inception结构,ReLU已经跟卷积层节点合在一起。
每个节点我们统一看成是一个数据处理单元,输入来自于上一节点的输出,每个节点包括一个处理单元,数据缓冲区,如果是卷积节点和全连接节点还包括系数缓冲区。我们用数据缓冲区来协同上下游节点的处理过程。具体过程是,数据缓冲区先允许上游节点写,上游节点写完成后,通知数据缓冲区,数据缓冲区于是禁止上游节点写入,并允许下游节点读,下游节点读完后通知数据缓冲区,数据缓冲区又开放上游节点的写允许,这样就可以形成一个前后协同的流水线结构。这个结构可以让多幅图在流水线中同时进行分类。下面是计算节点的示意图:

具体配置时,可以根据每个节点生成的数据大小来配置存储器,每个缓冲区用内部的RAM实现,系数缓冲区也如此处理。这样处理对内部存储器的大小要求比较高,很多FPGA都无法满足要求,此时可以用一个cache结构来实现缓冲区,数据统一存放在DDR等外存中。另外,对计算量比较大的节点,比如卷积或者池化节点,还可以分成若干个并发的子节点,每个负责计算其中的一部分。
我们目前的实现方案,采用最简单的方案,每个缓冲区用RAM实现FIFO方式提供流水线控制,参数也放在RAM中,每个节点不进行分割,作为一个单一节点处理。
11.2 深度卷积神经网络基本单元
我们来定义每个节点可能的类型,也就是深度卷积神经网络的基本单元。从11.1中的分析可以看出,我们需要如下的基本单元:
| 单元名称 | 模块名 | 功能 |
|---|---|---|
| 卷积 | Convolution | 读入上游的图像数据和卷积系数数据,进行卷积计算和激活函数计算 |
| 池化 | Pooling | 读入上游的图像数据,完成池化计算 |
| 汇合 | Concat | 将多个上游输出汇合成一个 |
| 局部归一化 | LRN | 对输入图像进行局部响应归一化处理 |
| 全连接点积 | InnerProduct | 对输入数据进行全连接点积计算 |
| 归一化 | Softmax | 对输入数据进行归一化,输出分类结果概率值 |
| 数据缓冲区 | buffer | 保存节点生成的数据,供下游节点读,输出读写允许信号, 协同上下游的工作流程数据缓冲区根据读写节点数量不同分别有一读一写, 一读四写,四读一写,四读四写等类型,缓冲区在处理多个读写节点的信号时, 可以考虑用分时复用的方式提供服务,也可以设计一个命令FIFO,放松节点和 缓冲区之间的耦合,提高处理效率 |
| 数据源 | datasource | 提供输入数据,先可以提供一个简单的固定输入数据,将来可以考虑从目录中读 一系列图片进行分类,也可以直接从摄像头获得数据。 |
| 结果输出 | dataoutput | 读出分类结果,输出Top 5的类型名称和对应的概率值 |
事实上,caffe支持的算子类型很多,这里只给出了我们关心的几个,能够支持GoogLeNet的运行。如果运行其他网络,可能需要新的算子支持,需要重新定义和实现新的基本单元。
我们给出基本单元的verilog描述如下,目前基本单元正在用c语言实现,后面先验证c语言实现的版本,然后在逐个改写成verilog语言实现,这样我们就有了一个全部由verilog代码实现的深度卷积神经网络的推理系统了。
/*
* cnncell.v
202107030835: rxh, initial version
*/
(*
HDL4SE="LCOM",
CLSID="C72D0D42-2D4D-4DC3-9DDA-4F58CE7569BC",
softmodule="hdl4se"
*)
module hdl4se_cnn_coeffbuf
#(parameter filename="test.coeff")
(
input wClk,
input nwReset,
input wCoeffRead,
output wCoeffReadValid,
input [31:0] bCoeffReadAddr,
output[31:0] bCoeffReadData,
output[31:0] bCoeffOffset,
output[31:0] bCoeffScale,
output[15:0] bCoeff_N,
output[15:0] bCoeff_C,
output[15:0] bCoeff_H,
output[15:0] bCoeff_W,
output[31:0] bCoeffBiasOffset,
output[31:0] bCoeffBiasScale,
output[15:0] bCoeffBias_N,
output[15:0] bCoeffBias_C,
output[15:0] bCoeffBias_H,
output[15:0] bCoeffBias_W
);
endmodule
(*
HDL4SE="LCOM",
CLSID="230946EF-3EC1-43EC-A841-CDE8A9E97314",
softmodule="hdl4se"
*)
module hdl4se_fifo
#(parameter WIDTH=16, DEPTH=128)
(
input wClk,
input nwReset,
input wRead,
output wDataValid,
output[WIDTH-1:0] bReadData,
output wWriteEnable,
input wWrite,
input [WIDTH-1:0] bWriteData
);
endmodule
(*
HDL4SE="LCOM",
CLSID="9AA0D743-5FFB-4649-ACEC-4B4675AE2A57",
softmodule="hdl4se"
*)
module hdl4se_cnn_buf_r4
#(parameter wordsize=32, wordcount=1024)
(
input wClk,
input nwReset,
input wDataRead_0,
output wDataReadValid_0,
output [31:0]bDataReadData_0,
input wDataRead_1,
output wDataReadValid_1,
output [31:0]bDataReadData_1,
input wDataRead_2,
output wDataReadValid_2,
output [31:0]bDataReadData_2,
input wDataRead_3,
output wDataReadValid_3,
output [31:0]bDataReadData_3,
output wDataWriteEnable,
input wDataWrite,
input [31:0] bDataWriteData
);
endmodule
`define ACTIVATION_NONE 0
`define ACTIVATION_RELU 1
`define ACTIVATION_TANH 2
`define ACTIVATION_SIGMOID 3
`define ACTIVATION_RELUNEG 4
(*
HDL4SE="LCOM",
CLSID="FB3D226E-D508-476B-81E1-F3B22CCF8F11",
softmodule="hdl4se"
*)
module hdl4se_cnn_convolution
#(parameter
INW=224, INH=224, INC=3,
OUTW=112, OUTH=112, OUTC=64,
W=7, H=7,
SW=2, SH=2,
PW=3, PH=3,
ACT_FUNC=`ACTIVATION_NONE)
(
/*
inputsize[0] = INH;
inputsize[1] = INW;
inputsize[2] = INC;
outputsize[0] = (INH + 2 * PH - H) / SH + 1;
outputsize[1] = (INW + 2 * PW - W) / SW + 1;
outputsize[2] = OUTC;
*/
input wClk,
input nwReset,
output wCoeffRead, /*系数读接口*/
input wCoeffReadValid,
output [31:0] bCoeffReadAddr,
input [31:0] bCoeffReadData,
input [31:0] bCoeffOffset,
input [31:0] bCoeffScale,
input [15:0] bCoeff_N,
input [15:0] bCoeff_C,
input [15:0] bCoeff_H,
input [15:0] bCoeff_W,
input [31:0] bCoeffBiasOffset,
input [31:0] bCoeffBiasScale,
input [15:0] bCoeffBias_N,
input [15:0] bCoeffBias_C,
input [15:0] bCoeffBias_H,
input [15:0] bCoeffBias_W,
output wDataRead,
input wDataReadValid,
input [31:0] bDataReadData,
input wDataWriteEnable, /*写下游数据接口*/
output wDataWrite,
output [31:0] bDataWriteData
);
endmodule
/*
// {78B9BEC2-3DF7-4421-9274-645BFB60320B}
DEFINE_GUID(<>,
0x78b9bec2, 0x3df7, 0x4421, 0x92, 0x74, 0x64, 0x5b, 0xfb, 0x60, 0x32, 0xb);
*/
(*
HDL4SE="LCOM",
CLSID="78B9BEC2-3DF7-4421-9274-645BFB60320B",
softmodule="hdl4se"
*)
module hdl4se_cnn_innerproduct
#(parameter
INW=1, INH=1, INC=1024,
OUTW=1, OUTH=1, OUTC=1000
)
(
/*
inputsize[0] = HEIGHT;
inputsize[1] = WIDTH;
inputsize[2] = COMPONENT;
outputsize[0] = 1;
outputsize[1] = 1;
outputsize[2] = N;
*/
input wClk,
input nwReset,
output wCoeffRead, /* 系数读接口 */
input wCoeffReadValid,
output [31:0] bCoeffReadAddr,
input [31:0] bCoeffReadData,
input [31:0] bCoeffOffset,
input [31:0] bCoeffScale,
input [15:0] bCoeff_N,
input [15:0] bCoeff_C,
input [15:0] bCoeff_H,
input [15:0] bCoeff_W,
input [31:0] bCoeffBiasOffset,
input [31:0] bCoeffBiasScale,
input [15:0] bCoeffBias_N,
input [15:0] bCoeffBias_C,
input [15:0] bCoeffBias_H,
input [15:0] bCoeffBias_W,
output wDataRead,
input wDataReadValid,
input [31:0] bDataReadData,
input wDataWriteEnable, /* 写下游数据接口 */
output wDataWrite,
output [31:0] bDataWriteData
);
endmodule
/*
DEFINE_GUID(<>,
0x8ec66cdf, 0xc750, 0x46a1, 0xaa, 0x1f, 0xc4, 0x43, 0x8, 0xe1, 0xf0, 0x1);
*/
(*
HDL4SE="LCOM",
CLSID="8EC66CDF-C750-46A1-AA1F-C44308E1F001",
softmodule="hdl4se"
*)
module hdl4se_cnn_concat4
#(parameter
INW0=128, INH0=64, INC0=1,
INW1=128, INH1=64, INC1=1,
INW2=128, INH2=64, INC2=1,
INW3=128, INH3=64, INC3=1,
OUTW3=128, OUTH3=64, OUTC3=4
)
(
/*
inputsize[0][0] = HEIGHT;
inputsize[0][1] = WIDTH;
inputsize[0][2] = C0;
inputsize[1][0] = HEIGHT;
inputsize[1][1] = WIDTH;
inputsize[1][2] = C1;
inputsize[2][0] = HEIGHT;
inputsize[2][1] = WIDTH;
inputsize[2][2] = C2;
inputsize[3][0] = HEIGHT;
inputsize[3][1] = WIDTH;
inputsize[3][2] = C3;
outputsize[0] = HEIGHT;
outputsize[1] = WIDTH;
outputsize[2] = C0 + C1 + C2 + C3;
*/
input wClk,
input nwReset,
output wDataRead_0,
input wDataReadValid_0,
input [31:0] bDataReadData_0,
output wDataRead_1,
input wDataReadValid_1,
input [31:0] bDataReadData_1,
output wDataRead_2,
input wDataReadValid_2,
input [31:0] bDataReadData_2,
output wDataRead_3,
input wDataReadValid_3,
input [31:0] bDataReadData_3,
input wDataWriteEnable, /*写下游数据接口*/
output wDataWrite,
output [31:0] bDataWriteData
);
endmodule
`define LRN_NormRegion_ACROSS_CHANNELS 0
`define LRN_NormRegion_WITHIN_CHANNEL 1
(*
HDL4SE="LCOM",
CLSID="59076B10-44F2-46E4-B950-179B8D2959B6",
softmodule="hdl4se"
*)
module hdl4se_cnn_lrn
#(parameter WIDTH=1024, HEIGHT=1000, COMPONENT=1, localsize=5,
parameter real k=1.0, alpha=0.00001, beta=0.75,
parameter LRN_NORMREGION = `LRN_NormRegion_ACROSS_CHANNELS)
(
/*
inputsize[0] = HEIGHT;
inputsize[1] = WIDTH;
inputsize[2] = COMPONENT;
outputsize[0] = HEIGHT;
outputsize[1] = WIDTH;
outputsize[2] = COMPONENT;
*/
input wClk,
input nwReset,
output wDataRead,
input wDataReadValid,
input [31:0] bDataReadData,
input wDataWriteEnable, /*写下游数据接口*/
output wDataWrite,
output [31:0] bDataWriteData
);
endmodule
`define CNN_POOLING_MAX 0
`define CNN_POOLING_AVE 1
`define CNN_POOLING_RAN 2
(*
HDL4SE="LCOM",
CLSID="3B2E096B-5572-47E2-A4BC-3139419D3321",
softmodule="hdl4se"
*)
module hdl4se_cnn_pooling
#(parameter
INW=224, INH=224, INC=3,
OUTW=224, OUTH=224, OUTC=3,
W=7, H=7, SW=2, SH=2, PW=3, PH=3,
POOLING_METHOD=`CNN_POOLING_MAX,
ACT_FUNC=`ACTIVATION_NONE
)
(
/*
inputsize[0] = HEIGHT;
inputsize[1] = WIDTH;
inputsize[2] = COMPONENT;
outputsize[0] = (inputsize[0] + 2 * PH - H + SH - 1) / SH + 1;
outputsize[1] = (inputsize[1] + 2 * PW - W + SW - 1) / SW + 1;
outputsize[2] = COMPONENT;
*/
input wClk,
input nwReset,
output wDataRead,
input wDataReadValid,
input [31:0] bDataReadData,
input wDataWriteEnable, /*写下游数据接口*/
output wDataWrite,
output [31:0] bDataWriteData
);
endmodule
(*
HDL4SE="LCOM",
CLSID="5B646EF4-FE9E-44BF-925F-AF98566AEB23",
softmodule="hdl4se"
*)
module hdl4se_cnn_softmax
#(parameter WIDTH=224, HEIGHT=224, COMPONENT=3)
(
/*
inputsize[0] = HEIGHT;
inputsize[1] = WIDTH;
inputsize[2] = COMPONENT;
outputsize[0] = HEIGHT;
outputsize[1] = WIDTH;
outputsize[2] = COMPONENT;
*/
input wClk,
input nwReset,
output wDataRead,
input wDataReadValid,
input [31:0] bDataReadData,
input wDataWriteEnable, /*写下游数据接口*/
output wDataWrite,
output [31:0] bDataWriteData
);
endmodule
(*
HDL4SE="LCOM",
CLSID="70B19638-03B9-466D-972A-5D31ABD448D4",
softmodule="hdl4se"
*)
module hdl4se_cnn_datasource
#(parameter WIDTH=224, HEIGHT=224, COMPONENT=3)
(
input wClk,
input nwReset,
input wDataWriteEnable, /*写下游数据接口*/
output wDataWrite,
output [31:0] bDataWriteData
);
endmodule
(*
HDL4SE="LCOM",
CLSID="CC51DF54-F7AF-407C-A4B3-24D67139E17E",
softmodule="hdl4se"
*)
module hdl4se_cnn_dataoutput
#(parameter WIDTH=1, HEIGHT=1, COMPONENT=1000)
(
input wClk,
input nwReset,
output wDataRead,
input wDataReadValid,
input [31:0] bDataReadData
);
endmodule
11.3 模型数据解析
GoogLeNet中涉及到大约6.7M个系数,这些系数据说是根据150万张已经分类好(标记过的)的图像经过训练得到的。这里不讨论训练如何做,我们的例子只关心推理,也就是如何将一副输入图像经过GoogLeNet的计算得到它的分类。
从网络上可以找到训练好的系数,我们得到的是bvlc的版本,用caffe架构训练的结果bvlc_googlenet.caffemodel。这个文件是用Google的Proto格式组织的。bvlc给出了caffe架构的格式文件caffe.proto,通过google的Proto编译工具可以得到访问caffe数据文件的c++代码(还可以得到JAVA/PYTHON等语言的访问代码),然后就可以将bvlc_googlenet.caffemodel中的系数文件,网络结构等信息提取出来生成我们需要的c语言文件,再将这些c语言表示的数据文件连接在一起,就可以执行一次推理操作了。
我们的git中提供了proto的代码,可以用来支持模型数据的解析,解析模型的代码文件在/hdl4se/examples/hdl4secnn/modeldump中。目前这个程序可以正确解析GoogLeNet,对其他的模型,理论上也可以解析,但是要看是否用到了新的节点类型。有意思的是,这些代码只能在Linux下运行,在Windows下无法解析bvlc_googlenet.caffemodel文件,感觉似乎是Proto的问题,这里不深究了,Linux就Linux吧,反正生成出来的代码不用经常修改的。
我们从bvlc_googlenet.caffemodel解析出来的数据分为两种,一种是其中的节点信息,包括节点类型,节点参数,节点上下游之间的连接关系等,这是GoogLeNet网络的结构信息。还有一种信息就是节点附带的训练结果,即各种系数。下面是一个节点信息的例子,完整的解析结果请到hdl4se/examples/hdl4secnn/googlenet/model-c中查看:
/*
* 由modeldump程序生成
* 生成时间:Sun Jul 4 20:19:54 2021
* 源文件:/media/raoxianhong/_dde_data/gitwork/hdl4se/examples/hdl4secnn/googlenet/model/bvlc_googlenet.caffemodel
* 请不要手工修改以确保文件与源文件数据一致。
*/
#include 其中的param_0和param_1就是系数信息,其他的cnn_convolution_layer layer中存放着节点的类型即参数信息。开始的地方的layer_top和layer_bottom中有节点的上下游关系的信息。这是靠每个节点的名称来进行连接的。
我们在通用的基本库cnncell的支持下,在googlenet目录中实现了一个推理运行程序googlenet,将解析的数据构成的网络连接在一起,并用一个示例图像数据实现了推理过程,在推理过程中一边进行计算一边就将网络结构转换为网络的verilog语言表示。如果推理结果正确,表明执行过程是没有问题的,最后的输出结果是这样的:
0.4901 n03085013 computer keyboard, keypad
0.1591 n04264628 space bar
0.0543 n04074963 remote control, remote
0.0439 n03832673 notebook, notebook computer
0.0356 n04505470 typewriter keyboard
表明我们输入的图像中有一个貌似键盘的东西。
googlenet还生成了googlenet的verilog主模块googlenet.v。这个文件由cnn基本单元组成,中间用线网连接在一起,用verilog表示了GoogLeNet的网络结构以及相关网络参数,各种系数单独文件给出。这个文件比较长,下面这个局部,可以看到上下游的节点是如何生成的并连接在一起:
/*
* 由googlenet程序生成
* 生成时间:Wed Aug 4 19:13:51 2021
* 请不要手工修改。
*/
`include "hdl4secell.v"
`include "cnncell.v"
module googlenet(
input wClk,
input nwReset,
output wSrcDataRead,
input wSrcDataReadValid,
input[31:0] bSrcDataReadData,
input wDstDataRead,
output wDstDataReadValid,
output[31:0] bDstDataReadData
);
/* module input --> 2(conv1/7x7_s2) */
assign wSrcDataRead = wDataRead_2;
assign wDataReadValid_2 = wSrcDataReadValid;
assign bDataReadData_2 = bSrcDataReadData;
/* 节点 2(名称:conv1/7x7_s2, 类型:CONVOLUTION(4)) */
/* 读系数接口 */
wire wCoeffRead_2;
wire wCoeffReadValid_2;
wire[31:0] bCoeffReadAddr_2;
wire[31:0] bCoeffReadData_2;
wire[31:0] bCoeffOffset_2;
wire[31:0] bCoeffScale_2;
wire[15:0] bCoeff_N_2;
wire[15:0] bCoeff_C_2;
wire[15:0] bCoeff_H_2;
wire[15:0] bCoeff_W_2;
wire[31:0] bCoeffBiasOffset_2;
wire[31:0] bCoeffBiasScale_2;
wire[15:0] bCoeffBias_N_2;
wire[15:0] bCoeffBias_C_2;
wire[15:0] bCoeffBias_H_2;
wire[15:0] bCoeffBias_W_2;
/* 读输入数据接口 */
wire wDataRead_2;
wire wDataReadValid_2;
wire[31:0] bDataReadData_2;
/* 写输出数据接口 */
wire wDataWriteEnable_2;
wire wDataWrite_2;
wire[31:0] bDataWriteData_2;
/* 系数缓冲区 */
hdl4se_cnn_coeffbuf #("cnn_coeff_2.coeff")
coeffbuf_2(
wClk, nwReset,
/* 读系数接口 */
wCoeffRead_2,
wCoeffReadValid_2,
bCoeffReadAddr_2,
bCoeffReadData_2,
bCoeffOffset_2,
bCoeffScale_2,
bCoeff_N_2,
bCoeff_C_2,
bCoeff_H_2,
bCoeff_W_2,
bCoeffBiasOffset_2,
bCoeffBiasScale_2,
bCoeffBias_N_2,
bCoeffBias_C_2,
bCoeffBias_H_2,
bCoeffBias_W_2,
);
/* 卷积层 2:conv1/7x7_s2 */
hdl4se_cnn_convolution #(
224, 224, 3, /* 输入大小 */
112, 112, 64, /* 输出大小 */
7, 7, /* 卷积核大小 */
2, 2, /* 卷积步长 */
3, 3, /* 卷积填充 */
`ACTIVATION_RELU) /* 激活模式 */
convolution_2 (
wClk, nwReset,
/* 读系数接口 */
wCoeffRead_2,
wCoeffReadValid_2,
bCoeffReadAddr_2,
bCoeffReadData_2,
bCoeffOffset_2,
bCoeffScale_2,
bCoeff_N_2,
bCoeff_C_2,
bCoeff_H_2,
bCoeff_W_2,
bCoeffBiasOffset_2,
bCoeffBiasScale_2,
bCoeffBias_N_2,
bCoeffBias_C_2,
bCoeffBias_H_2,
bCoeffBias_W_2,
/* 读输入数据接口 */
wDataRead_2,
wDataReadValid_2,
bDataReadData_2,
/* 写输出数据接口 */
wDataWriteEnable_2,
wDataWrite_2,
bDataWriteData_2
);
/* 缓冲区: 2(conv1/7x7_s2)写 --> 4(pool1/3x3_s2)读 */
hdl4se_fifo #(32, 128)
cnn_buf_2(
wClk, nwReset,
wDataRead_4,
wDataReadValid_4,
bDataReadData_4,
wDataWriteEnable_2,
wDataWrite_2,
bDataWriteData_2
);
这段代码是处理2号节点的时候生成的,可以看到这是一个卷积节点,它带有一个输入的参数缓冲区和一个输出的数据缓冲区。从模型文件中解析出来的2号节点的下游节点是4号节点,于是2号节点负责写数据缓冲区,4号节点则从这个数据缓冲区中来读,中间由cnn_buf_2这个数据缓冲区来协同2号节点和4号节点的动作,实现流水线的上下游功能,这里的cnn_buf_2是用FIFO实现的,仅仅占用128个字。
再看一段稍微复杂的:
/* 缓冲区: 24(inception_3a/pool_proj)写 --> 26(inception_3a/output, port 3)读 */
hdl4se_fifo #(32, 64)
cnn_buf_24(
wClk, nwReset,
wDataRead_26_3,
wDataReadValid_26_3,
bDataReadData_26_3,
wDataWriteEnable_24,
wDataWrite_24,
bDataWriteData_24
);
/* 节点 26(名称:inception_3a/output, 类型:CONCAT(3)) */
/* 读输入数据接口 */
wire wDataRead_26_0;
wire wDataReadValid_26_0;
wire[31:0] bDataReadData_26_0;
/* 读输入数据接口 */
wire wDataRead_26_1;
wire wDataReadValid_26_1;
wire[31:0] bDataReadData_26_1;
/* 读输入数据接口 */
wire wDataRead_26_2;
wire wDataReadValid_26_2;
wire[31:0] bDataReadData_26_2;
/* 读输入数据接口 */
wire wDataRead_26_3;
wire wDataReadValid_26_3;
wire[31:0] bDataReadData_26_3;
/* 写输出数据接口 */
wire wDataWriteEnable_26;
wire wDataWrite_26;
wire[31:0] bDataWriteData_26;
/* 汇合层 26:inception_3a/output */
hdl4se_cnn_concat4 #(
28, 28, 64, /* 输入0大小 */
28, 28, 128, /* 输入1大小 */
28, 28, 32, /* 输入2大小 */
28, 28, 32, /* 输入3大小 */
28, 28, 256 /* 输出大小 */
)
concat_26 (
wClk, nwReset,
/* 读输入数据接口 0*/
wDataRead_26_0,
wDataReadValid_26_0,
bDataReadData_26_0,
/* 读输入数据接口 1*/
wDataRead_26_1,
wDataReadValid_26_1,
bDataReadData_26_1,
/* 读输入数据接口 2*/
wDataRead_26_2,
wDataReadValid_26_2,
bDataReadData_26_2,
/* 读输入数据接口 3*/
wDataRead_26_3,
wDataReadValid_26_3,
bDataReadData_26_3,
/* 写输出数据接口 */
wDataWriteEnable_26,
wDataWrite_26,
bDataWriteData_26
);
hdl4se_cnn_buf_r4 #(32, 512000)
cnn_buf_26(
wClk, nwReset,
/*读端口0, 26(inception_3a/output)写 --> 28(inception_3b/1x1)读 */
wDataRead_28,
wDataReadValid_28,
bDataReadData_28,
/*读端口1, 26(inception_3a/output)写 --> 30(inception_3b/3x3_reduce)读 */
wDataRead_30,
wDataReadValid_30,
bDataReadData_30,
/*读端口2, 26(inception_3a/output)写 --> 34(inception_3b/5x5_reduce)读 */
wDataRead_34,
wDataReadValid_34,
bDataReadData_34,
/*读端口3, 26(inception_3a/output)写 --> 38(inception_3b/pool)读 */
wDataRead_38,
wDataReadValid_38,
bDataReadData_38,
wDataWriteEnable_26,
wDataWrite_26,
bDataWriteData_26
);
这是26号节点,这个节点是inception_3a结构的汇合节点,它的上游节点有四个:13(inception_3a/1x1),17(inception_3a/3x3),21(inception_3a/5x5)和 24(inception_3a/pool_proj),inception_3a的下游是inception_3b结构,因此下游是inception_3b的四个输入节点来读数据,一次用了一写四读数据缓冲区,四个下游节点分别是28(inception_3b/1x1), 30(inception_3b/3x3_reduce),34(inception_3b/5x5_reduce)和38(inception_3b/pool),它们去读hdl4se_cnn_buf_r4 #(32, 512000) cnn_buf_26数据缓冲区,并与26号节点实现协同。这样cnn_buf_26实际上协同了5个节点的工作。
生成googlenet.v的同时,也生成了各个系数文件。这些系数文件运行时由系数缓冲区单元读入,为相关单元提供系数。
我们在编译器testparser中支持了googlenet.v的编译工作,目前能够正常生成目标代码googlenet.c,这个目标代码与一个通用模拟器主程序和cnn基本单元库连接起来,于是就可以支持HDL4SE环境下面运行GoogLeNet网络的推理了。
其中,hdl4se_cnn_buf_r4内部用4个FIFO实现一写四读的FIFO,用来控制上下游流水线:
#define M_ID(id) cnncell_buf_r4##id
#define cnncell_buf_r4_MODULE_VERSION_STRING "0.4.0-20210718.0955 CNN buf r4 cell"
#define cnncell_buf_r4_MODULE_CLSID CLSID_CNN_BUF_R4
IDLIST
VID(wClk),
VID(nwReset),
VID(wDataRead_0),
VID(wDataReadValid_0),
VID(bDataReadData_0),
VID(wDataRead_1),
VID(wDataReadValid_1),
VID(bDataReadData_1),
VID(wDataRead_2),
VID(wDataReadValid_2),
VID(bDataReadData_2),
VID(wDataRead_3),
VID(wDataReadValid_3),
VID(bDataReadData_3),
VID(wDataWriteEnable),
VID(wDataWrite),
VID(bDataWriteData),
VID(wDataWriteEnable_0),
VID(wDataWriteEnable_1),
VID(wDataWriteEnable_2),
VID(wDataWriteEnable_3),
END_IDLIST
MODULE_DECLARE(cnncell_buf_r4)
int wordsize, wordcount;
END_MODULE_DECLARE(cnncell_buf_r4)
DEFINE_FUNC(cnncell_buf_r4_gen_write) {
vput(wDataWriteEnable,
vget(wDataWriteEnable_0)
&& vget(wDataWriteEnable_1)
&& vget(wDataWriteEnable_2)
&& vget(wDataWriteEnable_3)
);
} END_DEFINE_FUNC
MODULE_INIT(cnncell_buf_r4)
char param[32];
pobj->wordsize = (int)MODULE_PARAM(0);
pobj->wordcount = (int)MODULE_PARAM(1);
PORT_IN(wClk, 1);
PORT_IN(nwReset, 1);
PORT_IN(wDataRead_0, 1);
PORT_OUT(wDataReadValid_0, 1);
PORT_OUT(bDataReadData_0, pobj->wordsize);
PORT_IN(wDataRead_1, 1);
PORT_OUT(wDataReadValid_1, 1);
PORT_OUT(bDataReadData_1, pobj->wordsize);
PORT_IN(wDataRead_2, 1);
PORT_OUT(wDataReadValid_2, 1);
PORT_OUT(bDataReadData_2, pobj->wordsize);
PORT_IN(wDataRead_3, 1);
PORT_OUT(wDataReadValid_3, 1);
PORT_OUT(bDataReadData_3, pobj->wordsize);
GPORT_OUT(wDataWriteEnable, 1, cnncell_buf_r4_gen_write);
PORT_IN(wDataWrite, 1);
PORT_IN(bDataWriteData, pobj->wordsize);
WIRE(wDataWriteEnable_0, 1);
WIRE(wDataWriteEnable_1, 1);
WIRE(wDataWriteEnable_2, 1);
WIRE(wDataWriteEnable_3, 1);
sprintf(param, "%d, %d", pobj->wordsize, pobj->wordcount);
CELL_INST("230946EF-3EC1-43EC-A841-CDE8A9E97314", /* hdl4se_fifo */
"cnncell_buf_r4_0",
param,
"wClk, nwReset, wDataRead_0, wDataReadValid_0, bDataReadData_0, "
"wDataWriteEnable_0, wDataWrite, bDataWriteData");
CELL_INST("230946EF-3EC1-43EC-A841-CDE8A9E97314", /* hdl4se_fifo */
"cnncell_buf_r4_1",
param,
"wClk, nwReset, wDataRead_1, wDataReadValid_1, bDataReadData_1, "
"wDataWriteEnable_1, wDataWrite, bDataWriteData");
CELL_INST("230946EF-3EC1-43EC-A841-CDE8A9E97314", /* hdl4se_fifo */
"cnncell_buf_r4_2",
param,
"wClk, nwReset, wDataRead_2, wDataReadValid_2, bDataReadData_2, "
"wDataWriteEnable_2, wDataWrite, bDataWriteData");
CELL_INST("230946EF-3EC1-43EC-A841-CDE8A9E97314", /* hdl4se_fifo */
"cnncell_buf_r4_3",
param,
"wClk, nwReset, wDataRead_3, wDataReadValid_3, bDataReadData_3, "
"wDataWriteEnable_3, wDataWrite, bDataWriteData");
END_MODULE_INIT(cnncell_buf_r4)
我们采用了类似于systemc的描述方式,后面会给出详细的说明。
11.4 运行结果
目前整个模型已经可以运行起来了,下面是运行结果(局部输出):
clocks: 1867776, TSPD=9728.000000cps, LSPD=8192.000000cps
softmax_168 complete
0.4901 n03085013 computer keyboard, keypad
0.1591 n04264628 space bar
0.0543 n04074963 remote control, remote
0.0439 n03832673 notebook, notebook computer
0.0356 n04505470 typewriter keyboard
clocks: 1884160, TSPD=9712.164948cps, LSPD=8192.000000cps
运行结果与c语言实现的版本是一致的。
我们使用openmp来实现多线程并发,这是在simulator对象中实现的:
#define THREADCOUNT 3
static int hdl4sesim_hdl4se_simulator_ClkTick(HOBJECT object)
{
sHDL4SESim* pobj;
int i;
pobj = (sHDL4SESim*)objectThis(object);
pobj->clk = 0;
hdl4se_module_ClkTick(&pobj->data);
for (i = 0; i < pobj->singlethreadmodules.itemcount; i++) {
hdl4se_module_ClkTick(&((IHDL4SEModuleVar*)(pobj->singlethreadmodules.array[i]))->data);
}
#pragma omp parallel for num_threads(THREADCOUNT)
for (i = 0; i < pobj->multithreadmodules.itemcount; i++) {
hdl4se_module_ClkTick(&((IHDL4SEModuleVar*)(pobj->multithreadmodules.array[i]))->data);
}
return 0;
}
static int hdl4sesim_hdl4se_simulator_Setup(HOBJECT object)
{
sHDL4SESim* pobj;
int i;
pobj = (sHDL4SESim*)objectThis(object);
pobj->clk = 1;
pobj->clocks++;
vartempClean();
hdl4se_module_Setup(&pobj->data);
for (i = 0; i < pobj->singlethreadmodules.itemcount; i++) {
hdl4se_module_Setup(&((IHDL4SEModuleVar*)(pobj->singlethreadmodules.array[i]))->data);
}
#pragma omp parallel for num_threads(THREADCOUNT)
for (i = 0; i < pobj->multithreadmodules.itemcount; i++) {
hdl4se_module_Setup(&((IHDL4SEModuleVar*)(pobj->multithreadmodules.array[i]))->data);
}
return 0;
}
我们在实现时考虑了线程安全性,因此可以支持多线程仿真,修改THREADCOUNT就可以调整并发的线程数量。试验结果表明,并不是线程越多越好,后面有图表来说明这个事实。多线程仿真时的加速比,与模型之间的依赖关系非常有关系,对建模过程有一些要求,比如尽可能减少模型间的访问等,因为跨模型访问是需要进行线程间同步处理的,在多线程并发编程中,线程间同步的代价非常高,应该尽量减少线程间的同步与通信。
这是在一台笔记本电脑上跑的结果,横坐标是线程数,纵坐标是速度(每秒仿真周期数):

这是在一台台式机上跑的结果:
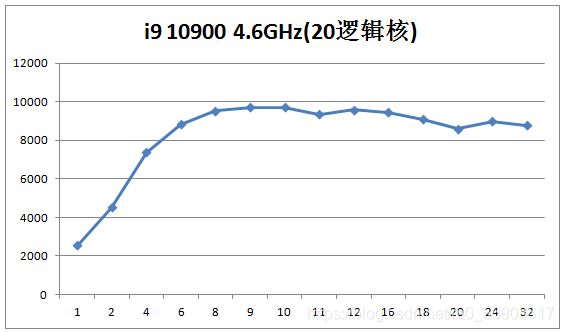
可以看出,并发的线程数并不是越多越好,在4核CPU上跑,2线程加速比最好,可以达到1.7,在20核CPU 上跑,9/10线程最好,加速比可以达到4左右(就是比单核跑仿真可以快4倍)。注意这两个例子都是在windows7/10下跑的结果,linux下面还没有测试。如果在专用的服务器上跑,不知道加速比能达到多少,真是值得期待啊。
另一方面,也不清楚用HDL4SE仿真跟用SystemC跑同样的模型速度相比如何,后面有机会再做测试好了。
当然这个神经网络模型只是用来演示流水线控制的,并不是真实的AI芯片应该采用的结构,因此实际跑的效果肯定不如专用的AI处理器,实际上目前的实现方式是一种抽象程度比较高的实现,还不是RTL的,因此如果要用verilog实现,还需要比较大的调整。
【请参考】
01.HDL4SE:软件工程师学习Verilog语言(十)
02.HDL4SE:软件工程师学习Verilog语言(九)
03.HDL4SE:软件工程师学习Verilog语言(八)
04.HDL4SE:软件工程师学习Verilog语言(七)
05.HDL4SE:软件工程师学习Verilog语言(六)
06.HDL4SE:软件工程师学习Verilog语言(五)
07.HDL4SE:软件工程师学习Verilog语言(四)
08.HDL4SE:软件工程师学习Verilog语言(三)
09.HDL4SE:软件工程师学习Verilog语言(二)
10.HDL4SE:软件工程师学习Verilog语言(一)
11.LCOM:轻量级组件对象模型
12.LCOM:带数据的接口
13.工具下载:在64位windows下的bison 3.7和flex 2.6.4
14.git: verilog-parser开源项目
15.git: HDL4SE项目
16.git: LCOM项目
17.git: GLFW项目