Spring关于三级缓存的那些事儿
聊聊spring的三级缓存,三级缓存是什么?
说到缓存,想到的第一个就是存储对象的一些容器,如LIST,MAP等,那么spring框架的三级缓存是用什么存储的?

可以看到三个缓存结构在DefaultSingletonBeanRegistry皆是用Map存储的,那么第二个问题
缓存的内容是什么?
在看具体的代码之前,先申明两个对象用作例子

spring有一套获取对象的方法逻辑,getBean(),doGetBean(),createBean(),doCreateBean(),在doCreateBean方法中执行完createBeanInstance获得A对象之后会有一个这样的方法
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean.
// 这个beanWrapper是用来持有创建出来的bean对象的
BeanWrapper instanceWrapper = null;
// 获取factoryBean实例缓存
if (mbd.isSingleton()) {
// 如果是单例对象,从factorybean实例缓存中移除当前bean定义信息
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
// 没有就创建实例
if (instanceWrapper == null) {
// 根据执行bean使用对应的策略创建新的实例,如,工厂方法,构造函数主动注入、简单初始化
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// 从包装类中获取原始bean
Object bean = instanceWrapper.getWrappedInstance();
// 获取具体的bean对象的Class属性
Class beanType = instanceWrapper.getWrappedClass();
// 如果不等于NullBean类型,那么修改目标类型
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// Allow post-processors to modify the merged bean definition.
// 允许beanPostProcessor去修改合并的beanDefinition
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
// MergedBeanDefinitionPostProcessor后置处理器修改合并bean的定义
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
// 判断当前bean是否需要提前曝光:单例&允许循环依赖&当前bean正在创建中,检测循环依赖
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 为避免后期循环依赖,可以在bean初始化完成前将创建实例的ObjectFactory加入工厂
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
//只保留二级缓存,不向三级缓存中存放对象
// earlySingletonObjects.put(beanName,bean);
// registeredSingletons.add(beanName);
// synchronized (this.singletonObjects) {
// if (!this.singletonObjects.containsKey(beanName)) {
// //实例化后的对象先添加到三级缓存中,三级缓存对应beanName的是一个lambda表达式(能够触发创建代理对象的机制)
// this.singletonFactories.put(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
// this.registeredSingletons.add(beanName);
// }
// }
}
// Initialize the bean instance.
// 初始化bean实例
Object exposedObject = bean;
try {
// 对bean的属性进行填充,将各个属性值注入,其中,可能存在依赖于其他bean的属性,则会递归初始化依赖的bean
populateBean(beanName, mbd, instanceWrapper);
// 执行初始化逻辑
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}
if (earlySingletonExposure) {
// 从缓存中获取具体的对象
Object earlySingletonReference = getSingleton(beanName, false);
// earlySingletonReference只有在检测到有循环依赖的情况下才会不为空
if (earlySingletonReference != null) {
// 如果exposedObject没有在初始化方法中被改变,也就是没有被增强
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
// 返回false说明依赖还没实例化好
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
// 因为bean创建后所依赖的bean一定是已经创建的
// actualDependentBeans不为空则表示当前bean创建后其依赖的bean却没有全部创建完,也就是说存在循环依赖
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
// Register bean as disposable.
try {
// 注册bean对象,方便后续在容器销毁的时候销毁对象
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}
return exposedObject;
} 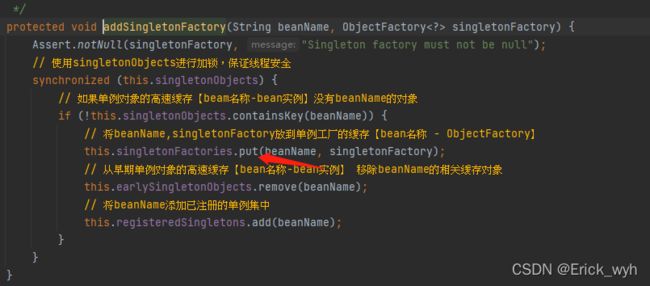
可以看到在获得对象后,注意这个时候获得的A对象还并没有填充属性,会先往singletonFactories也就是三级缓存存储一个K为a,VALUE为一个函数式接口,并不是获得的bean对象
A对象现在Spring已经帮我们创建出来了,接下来就开始解析A对象的属性值

具体的代码太长就不放上去了,有兴趣的可以自己点进去看,在执行populateBean时,会发现A对象的属性值B也是一个对象,那么会去执行getBean去容器里找
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
// 从单例对象缓存中获取beanName对应的单例对象
Object singletonObject = this.singletonObjects.get(beanName);
// 如果单例对象缓存中没有,并且该beanName对应的单例bean正在创建中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
//从早期单例对象缓存中获取单例对象(之所称成为早期单例对象,是因为earlySingletonObjects里
// 的对象的都是通过提前曝光的ObjectFactory创建出来的,还未进行属性填充等操作)
singletonObject = this.earlySingletonObjects.get(beanName);
// 如果在早期单例对象缓存中也没有,并且允许创建早期单例对象引用
if (singletonObject == null && allowEarlyReference) {
// 如果为空,则锁定全局变量并进行处理
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// 当某些方法需要提前初始化的时候则会调用addSingletonFactory方法将对应的ObjectFactory初始化策略存储在singletonFactories
ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 如果存在单例对象工厂,则通过工厂创建一个单例对象
singletonObject = singletonFactory.getObject();
// 记录在缓存中,二级缓存和三级缓存的对象不能同时存在
this.earlySingletonObjects.put(beanName, singletonObject);
// 从三级缓存中移除
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
也就是一二三级缓存各找一次,B对象还没被spring创建,所以自然是找不到的,那么又执行到doCreateBean开始创建B对象,同样的,在执行puoulateBean方法之前会先执行
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
先把B对象和lambda表达式去存储到三级缓存中,到B对象开始填充属性时,发现属性值A也是一个对象,那么还是会执行之前一样的逻辑,我先去一二三级缓存中找,看看能不能找到,同样的一级二级缓存并没有根据key获取的都是空,但是从三级缓存中查找时,可以获得一个lambda表达式,之前在getsingleton方法里可以看到当三级缓存不为空时,会把三级缓存中的A删除,同时把A和A对应的对象存储到二级缓存中,注意这个时候的A并没有完成赋值操作,我们是解析A对象的值B,发现容器里没有,去创建B对象,B开始填充属性时去容器里找A,在三级缓存中找到了A,但是三级缓存中放的只是一个lambda表达式,当执行完getObject方法时才获取到了A这个已完成实例化但是并没有完成赋值操作的对象,所以二级缓存中存的是一个半成品对象

会执行getObject方法,也就是回调getEarlyBeanReference返回A对象
这个时候的B对象已经解析完属性值,获得了A对象,填充完属性后已经是一个完整的对象,一步一步往回返,返回到dogetBean方法中的getSingleton方法执行addSingleton会直接把B对象放到一级缓存中,并且从三级缓存中移除
public Object getSingleton(String beanName, ObjectFactory singletonFactory) {
// 如果beanName为null,抛出异常
Assert.notNull(beanName, "Bean name must not be null");
// 使用单例对象的高速缓存Map作为锁,保证线程同步
synchronized (this.singletonObjects) {
// 从单例对象的高速缓存Map中获取beanName对应的单例对象
Object singletonObject = this.singletonObjects.get(beanName);
// 如果单例对象获取不到
if (singletonObject == null) {
// 如果当前在destorySingletons中
if (this.singletonsCurrentlyInDestruction) {
throw new BeanCreationNotAllowedException(beanName,
"Singleton bean creation not allowed while singletons of this factory are in destruction " +
"(Do not request a bean from a BeanFactory in a destroy method implementation!)");
}
// 如果当前日志级别时调试
if (logger.isDebugEnabled()) {
logger.debug("Creating shared instance of singleton bean '" + beanName + "'");
}
// 创建单例之前的回调,默认实现将单例注册为当前正在创建中
beforeSingletonCreation(beanName);
// 表示生成了新的单例对象的标记,默认为false,表示没有生成新的单例对象
boolean newSingleton = false;
// 有抑制异常记录标记,没有时为true,否则为false
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
// 如果没有抑制异常记录
if (recordSuppressedExceptions) {
// 对抑制的异常列表进行实例化(LinkedHashSet)
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
// 从单例工厂中获取对象
singletonObject = singletonFactory.getObject();
// 生成了新的单例对象的标记为true,表示生成了新的单例对象
newSingleton = true;
}
catch (IllegalStateException ex) {
// Has the singleton object implicitly appeared in the meantime ->
// if yes, proceed with it since the exception indicates that state.
// 同时,单例对象是否隐式出现 -> 如果是,请继续操作,因为异常表明该状态
// 尝试从单例对象的高速缓存Map中获取beanName的单例对象
singletonObject = this.singletonObjects.get(beanName);
// 如果获取失败,抛出异常
if (singletonObject == null) {
throw ex;
}
}
// 捕捉Bean创建异常
catch (BeanCreationException ex) {
// 如果没有抑制异常记录
if (recordSuppressedExceptions) {
// 遍历抑制的异常列表
for (Exception suppressedException : this.suppressedExceptions) {
// 将抑制的异常对象添加到 bean创建异常 中,这样做的,就是相当于 '因XXX异常导致了Bean创建异常‘ 的说法
ex.addRelatedCause(suppressedException);
}
}
// 抛出异常
throw ex;
}
finally {
// 如果没有抑制异常记录
if (recordSuppressedExceptions) {
// 将抑制的异常列表置为null,因为suppressedExceptions是对应单个bean的异常记录,置为null
// 可防止异常信息的混乱
this.suppressedExceptions = null;
}
// 创建单例后的回调,默认实现将单例标记为不在创建中
afterSingletonCreation(beanName);
}
// 生成了新的单例对象
if (newSingleton) {
// 将beanName和singletonObject的映射关系添加到该工厂的单例缓存中:
addSingleton(beanName, singletonObject);
}
}
// 返回该单例对象
return singletonObject;
}
}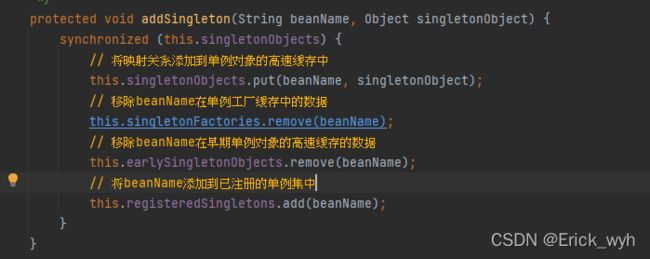
当完成这些的时候我们只是为了执行了A对象的populatBean方法,完成了赋值操作,那么这个时候A对象也是完整的,同样的一步步往回返到addSingleton方法,往一级缓存里填充A从二级缓存中移除A
以上内容说明了了三级缓存中各存储的什么?并且都是在什么时候放入的,代码太多,所以有些步骤没有放上去,从spirng中获取对象,都是会走getBean(),doGetBean(),createBean(),doCreateBean()这些方法,而我们上面的逻辑是从doGetBean()的getSingleton()中进入,其它像原型模式,是不会走三级缓存这一套逻辑的,创建完对象直接返回了,还有在createBean()中会通过resolveBeforeInstantiation方法判断容器中是否有bean实现了InstantiationAwareBeanPostProcessor,如果能通过重写里面的Before方法实例化之前返回一个对象,是会直接把这个对象放到一级缓存的,实现FactoryBean接口获得的Bean是会放在factoryBeanObjectCache中,也不会放在三级缓存中
@Nullable
protected Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd) {
Object bean = null;
// 如果beforeInstantiationResolved值为null或者true,那么表示尚未被处理,进行后续的处理
if (!Boolean.FALSE.equals(mbd.beforeInstantiationResolved)) {
// Make sure bean class is actually resolved at this point.
// 确认beanclass确实在此处进行处理
// 判断当前mbd是否是合成的,只有在实现aop的时候synthetic的值才为true,并且是否实现了InstantiationAwareBeanPostProcessor接口
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
// 获取类型
Class targetType = determineTargetType(beanName, mbd);
if (targetType != null) {
bean = applyBeanPostProcessorsBeforeInstantiation(targetType, beanName);
if (bean != null) {
bean = applyBeanPostProcessorsAfterInitialization(bean, beanName);
}
}
}
// 是否解析了
mbd.beforeInstantiationResolved = (bean != null);
}
return bean;
}从以上分析,用二级缓存就可以解决spring的循环依赖问题了,把完成实例化未完成初始化的对象放在二级缓存就可以了,但是在spring中使用AOP时会生成代理对象,我们无法知道什么时候需要代理对象,所以用三级缓存存储了一个生成对象的lambda表达式,当你需要创建对象时调用getEarlyBeanReference方法,如果有实现AOP,直接在获取对象时返回的就是代理对象,但是还有一种情况比如例子中的B对象,他的代理对象是在initinlizebean初始化方法的applyBeanPostProcessorsAfterInitialization中调用实现了BeanPostProcessor接口的AbstractAutoProxyCreator类的postProcessAfterInitialization方法,只是生成代理对象的时间不一样,A对象是在getEarlyBeanReference方法中生成,B对象是在initinlizebean方法完成初始化时生成的代理对象
@Override
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
//初始化结果对象为result,默认引用existingBean
Object result = existingBean;
//遍历该工厂创建的bean的BeanPostProcessors列表
for (BeanPostProcessor processor : getBeanPostProcessors()) {
//回调BeanPostProcessor#postProcessAfterInitialization来对现有的bean实例进行包装
Object current = processor.postProcessAfterInitialization(result, beanName);
//一般processor对不感兴趣的bean会回调直接返回result,使其能继续回调后续的BeanPostProcessor;
// 但有些processor会返回null来中断其后续的BeanPostProcessor
// 如果current为null
if (current == null) {
//直接返回result,中断其后续的BeanPostProcessor处理
return result;
}
//让result引用processor的返回结果,使其经过所有BeanPostProcess对象的后置处理的层层包装
result = current;
}
//返回经过所有BeanPostProcess对象的后置处理的层层包装后的result
return result;
}
好了,以上就是一个大概的总结,每个关键点都有很多的扩展处理,所以上面的代码只是很少的一部分。