【论文阅读】DenseMP: Unsupervised Dense Pre-training for Few-shot Medical Image Segmentation
这里写自定义目录标题
- 摘要
- 方法
-
- 第 1 阶段:分割感知密集对比预训练
- 第 2 阶段:少镜头感知超像素引导密集预训练
- 结论和展望
摘要
当前存在的问题:现有的方法在训练阶段努力应对数据稀缺的挑战,导致过拟合。
提出的方法:DenseMP利用无监督的密集预训练
方法的内容:由两个不同的阶段组成:1) 分割感知密集对比预训练 2) 少数镜头感知超像素引导密集预训练。写作产生一个专门为少镜头医学图像分割设计的预训练初始模型,随后可以在目标数据集上进行微调。
效果:我们提出的综合解决方案显著增强了广受认可的少镜头分割模型PA-Net的性能,在Abd-CT和Abd-MRI数据集上实现了最先进的结果。
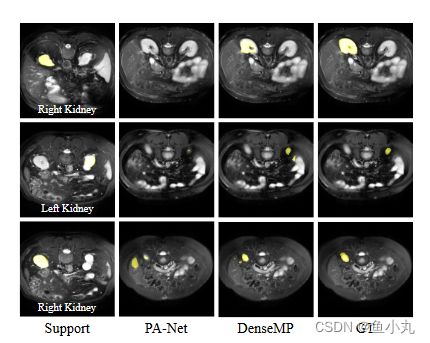
贡献:
- 提出了DenseMP,这是一种为少镜头医学图像分割量身定制的新型无监督预训练管道,它大大提高了PA-Net基线的性能,并优于现有的预训练方法,如SimCLR。
- 我们介绍了无监督预训练的两个关键组成部分:分割感知密集对比预训练阶段和少数镜头感知超像素引导密集预训练阶段。
- 在著名的Abd-CT和Abd-MRI数据集上对该方法进行了广泛的评估,证明了它优于现有的最先进的预训练方法。
方法
少镜头医学图像分割的定义:事件训练和测试问题。使用一段包含k个支持图像 I s I^s Is,查询图像 I q I^q Iq和支持图像的分割掩码 M s M^s Ms中存在的信息来预测分割掩码 M q M^q Mq。在自然图像中一般称为N-way-K-shot问题,通常 C t r ∩ C t e C_tr∩C_te Ctr∩Cte成立,表明测试请见不需要使用大量标记数据在新类上对模型进行训练或者微调。医学图像方面利用有限数量的标记支持图像突进分割过程,一般是1-way-1shot问题。设定如下任务 M q ^ = f ( { I s , I q } , M s ) \hat{M_q}=f(\{I_s,I_q\},M_s) Mq^=f({Is,Iq},Ms),f表示可训练模型。
DenseMP方法是使用PANet作为任务模型,其中包含用于从支持和查询图像中提取特征的主干组件,以及用于生成分割掩码的分割头。
主干组件提取特征图 F s F^s Fs, F q F^q Fq。
F s = B a c k b o n e ( I s ) F_s=Backbone(I^s) Fs=Backbone(Is), F q = B a c k b o n e ( I q ) F^q=Backbone(I^q) Fq=Backbone(Iq).
在分割头中使用自适应局部原型池化技术,以提取目标类的原型 P P P。
P = A d a p t i v e P o o l i n g ( F s ) P = AdaptivePooling(F^s) P=AdaptivePooling(Fs).
之后应用基于相似性的分割策略将原型与查询特征图进行比较,得到分割掩码M:
M = S i m i l a r i t y ( P , F q ) M = Similarity(P,F^q) M=Similarity(P,Fq)
鉴于医学图像数据集的大小有限,该网络难以学习足够的一般特征以进行少数镜头分割,特别是对于未观察到的类别。为解决这个问题,提出DenseMP,包含两个不同的阶段:(1)分割感知密集对比预训练(2)少镜头感知超像素引导密集预训练。

第 1 阶段:分割感知密集对比预训练
一般无监督将增强样本作为正样本,其他为负样本,但是仅依靠全局特征,不适用于分割任务。对于分割来说,backbone必须在预训练期间学习如此密集的局部信息。使用了密集预训练(Wang et al. 2021b),在这项工作中预训练backbone.
有一个图片 I I I,经过数据增强技术得到增强后的图片 I v 1 , I v 2 , I v k I_{v_1},I_{v_2},I_{v_k} Iv1,Iv2,Ivk,提取这k个不同版本图片的特征图,设特征图尺寸为 S W × S H × C S_W×S_H×C SW×SH×C,我们把特征图投影到 S × S × C S×S×C S×S×C。每个特征图获得 S × S S×S S×S特征向量,表示为编码key{ a 0 , a 1 , . . . . a s s a_0,a_1,....a_{ss} a0,a1,....ass}。负样本是从其他图片中随机选的特征(?) F v 1 , F v 2 , . . . F_{v_1},F_{v_2},... Fv1,Fv2,...,映射到 S × S S×S S×S大小,) F a 1 , F a 2 , . . . F_{a_1},F_{a_2},... Fa1,Fa2,...获得对齐向量 a 0 , a 2 , . . . a s s a_0,a_2,...a_{ss} a0,a2,...ass。计算同一图像的其他视图中a和所有其他对齐向量之间的相似性,将最相似的对其向量对应的编码key记为 t + t_+ t+。
L t = 1 s 2 ∑ s − l o g ( e ( t , t + ) τ e ( t , t + ) + ∑ t − e ( t , g − ) τ ) L_t = \frac{1} {s^2}\sum\limits_{s}{-log(\frac{e^{\frac{(t,t_+)}{\tau}}}{e^{(t,t_+)}+\sum_{t_-}{e^{\frac{(t,g_-)}{\tau}}}}}) Lt=s21s∑−log(e(t,t+)+∑t−eτ(t,g−)eτ(t,t+))
(正样本比正样本加负样本)
上面这个损失函数获取局部信息。为了获取全局信息,也使用了每个特征图的全局特征向量,{ g 0 , g 1 , . . . g k g_0,g_1,...g_k g0,g1,...gk}, g + g_+ g+是同一图像的不同视角获得的全局信息, g − g_- g−是不同图像的全局信息。
L t = − l o g ( e ( g , g + ) τ e ( g , g + ) + ∑ g − e ( g , g − ) τ ) L_t = {-log(\frac{e^{\frac{(g,g_+)}{\tau}}}{e^{(g,g_+)}+\sum_{g_-}{e^{\frac{(g,g_-)}{\tau}}}}}) Lt=−log(e(g,g+)+∑g−eτ(g,g−)eτ(g,g+))
L = ( 1 − λ ) L g + λ L t L = (1-\lambda)L_g+\lambda L_t L=(1−λ)Lg+λLt
通过结合密集局部和全局特征学习,分割感知密集对比预训练能够有效利用多尺度信息,从而增强few-shot医学图像分割任务的泛化和性能。
第 2 阶段:少镜头感知超像素引导密集预训练
第一阶段,通过预训练学习生成适合医学图像分割的通用密集特征图。但是分割头没有从第一阶段直接获益。
给定我们的任务是few-shot医学图像分割,关键方面是分割和few-shot。可以提出问题:
能否为few-shot网络设计一个预训练算法?
为了应对这一个挑战,需要解决两个问题:
- 怎么获取无标签的监督信号
- 怎么模拟few-shot过程
a. 无监督预训练。
提出使用超像素标签来解决这些问题。首先使用基于图的算法,随机选择一个聚类为目标类,分配所有其他区域为背景,获得图像的伪二进制编码。
b.模拟少镜头学习过程。将 I I I视为 I s I_s Is,对 I I I和 M p s M_ps Mps使用随机几何和强度变换(T),获得查询图像 I q I_q Iq及其对应掩码 M p q M_{pq} Mpq。假设( I q , M p q I_q,M_{pq} Iq,Mpq)是从不同患者捕获的。 E = { ( I q , M p q ) , ( I s , M p s ) } E = \{(I_q,M_{pq}),(I_s,M_ps)\} E={(Iq,Mpq),(Is,Mps)}
损失函数: L = L C E + λ L P A L = L_{CE}+\lambda L_{PA} L=LCE+λLPA应用PA-Net标准的少镜头训练backbone和分割头。
使用超像素作为伪标签极大地减轻了昂贵且耗时的手工标签。
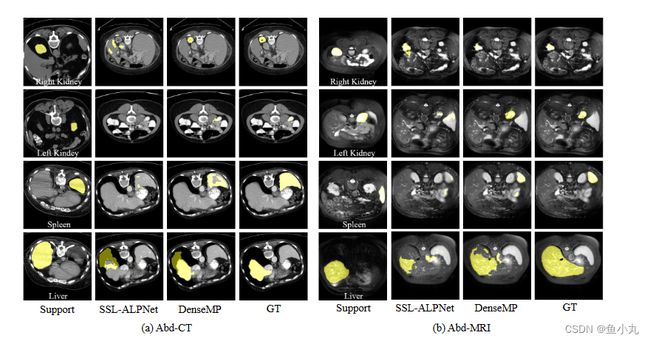
结论和展望
DenseMP 结合了分割感知密集对比预训练和少镜头感知超像素引导的密集预训练,有助于对有价值的特征进行无监督学习。
局限性:依赖于预定义的超像素。可能并不总是以最佳方式代表医学图像中的底层结构。
展望:探索自适应超像素生成技术,以更好地捕获各种解剖结构的复杂细节。研究整合多模态医学成像数据的潜力,以进一步提高DenseMP的性能。