较真儿学源码系列-PowerJob时间轮源码分析
PowerJob版本:4.3.2-main。
之前分析过PowerJob的启动流程源码,感兴趣的可以查看《较真儿学源码系列-PowerJob启动流程源码分析》
1 简介
试想一下,如果此时有一个需要延迟3s执行的任务,你会怎么实现呢?一种常规的思路是不断轮询,每1s轮询一次。等到轮询到第三次的时候,发现当前任务需要被执行。那么如果此时有100个延迟任务呢?并且每个任务的延迟时间都不等,小的有几毫秒,大的有几分钟甚至几天。如果还按照这个思路来实现的话,那么每个任务都需要开启一个线程去定时轮询。这样的开销未免太大了。而时间轮算法的本质是不再以任务为主体,而是以轮询线程为主体。既然之前每个任务都需要开启一个线程,开销比较大。那么换个思路,只用一个线程行不行?一个线程去统一调度所有的延迟任务(这样的话就意味着所有的任务都需要放在合适的位置上等待被调度,任务需要被分组),所以时间轮算法就应运而生了。
1.1 单层时间轮
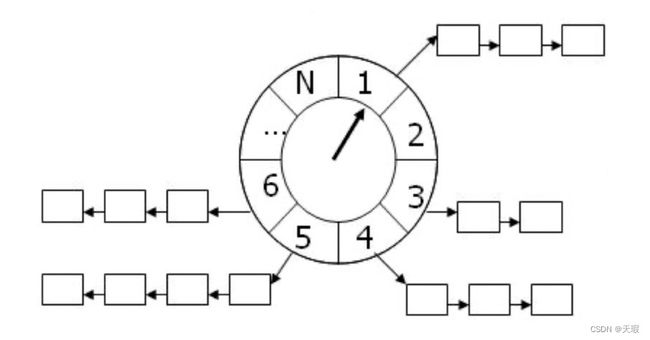
上图是时间轮的数据结构,主体是一个循环数组,数组的每个位置上都会挂一个链表。当来了一个新的延迟任务的时候,会根据延迟时间和当前时间计算出它应该放的位置(数组位置,找到数组位置后再挂接在链表上)。而每走一个时间刻度,时间轮指针就会前进一格,继而就会执行当前这个格内的任务。因为格内的任务是以链表排列的,所以会遍历执行。当指针走到最后一个刻度并执行完最后一个刻度里的任务后,又会重新走到初始刻度处,再次循环。
举个例子:假如说现在有一个时间刻度为12,每1s走一格的时间轮。同时现在有3个延迟任务,分别是延迟1s、6s和13s。那么此时首先需要计算出这三个任务所需要插入的位置。计算方式是:((当前时间 + 任务延迟时间 - 时间轮开始时间) / 时间间隔 ) % 时间刻度。这里我们简化一下,时间轮开始时间是0,当前时间也是0,时间间隔如上所示1s,所以上面的公式可以简化为:任务延迟时间 % 时间刻度。经过计算后,上面3个延迟任务会分别放到第1、6、1号位置(第一和第三任务会挂接在一起)。在完成了任务的插入后,接下来等待指针转动。
- 1s后,指针转到了1号位置处,发现此时有两个任务。但是这个时候只会执行第一个任务,因为第三个任务是需要延迟13s后才执行的,而现在只过了1s,所以不能执行;
- 2s-5s期间,指针持续转动,但是发现此时没有任何任务需要执行;
- 6s后,指针转到了6号位置处,发现此时有第二个任务,执行它;
- 7s-12s期间,同样没有任务需要被执行,指针继续空转;
- 13s后,指针重新走到了1号位置处,此时第三个任务会被执行;
- 之后,指针会持续空转,直到新任务的来临。
以上就是时间轮最简单的实现,也被称为单层时间轮。尽管满足了需求,但是单层时间轮也有自己的不足:时间轮的时间间隔到底应该取多少呢?在上面的例子中,时间间隔为1s。但是假如说有一个任务的延迟时间是200ms,因为当前时间轮的粒度是1s,所以最早也只能等到1s之后,该任务才会被执行。所以这就会造成延迟时间短的任务无法被及时执行的问题出现;而如果将时间间隔改成比如说是100ms,这个任务虽然能被及时执行,但是如果此时还有另外一个任务的延迟时间是1分钟的话,同时当前时间轮中又只有很少的任务。那么时间轮的大部分时间都会在做空转,浪费系统资源。
1.2 多层时间轮
由此,多层时间轮就出现了。顾名思义,多层时间轮会有多个时间轮,组合在一起被称为多层时间轮(好像说了一句废话-_-)。多个时间轮之间会协同工作,每个时间轮都会维护下一层时间轮的指针。拿我们日常生活中的钟表举例:钟表会有三个时间轮,分别是时、分和秒。分和秒时间轮的刻度是60,时时间轮的刻度是12(12小时钟表)。当秒时间轮转完60个刻度后,分时间轮会前进一个刻度,同时秒时间轮的指针会清零;当分时间轮转完60个刻度后,时时间轮会前进一个刻度,同时分时间轮的指针会清零,如下所示:
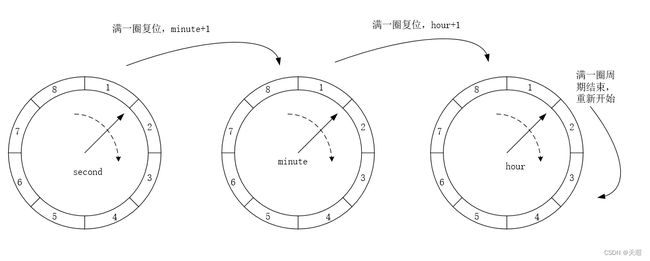
多层时间轮能用较小的空间(60 + 60 + 12 = 132),来表示出尽可能多的时间跨度(60 * 60 * 12= 43200)。同样举个例子:假如说现在有三个延迟任务,分别需要延迟30s、20min10s、1h20min3s。三个任务会分别被插入到秒、分、时时间轮中(插入规则是依次从秒、分和时,从低到高的时间轮中判断。如果低一层的时间轮中能放下任务的话就放,放不下的话就往上一层的时间轮中判断,以此类推)。在完成了任务的插入后,接下来等待指针转动。
- 一开始秒时间轮会转动,等转动到30s时,第一个任务会被执行;
- 当秒时间轮转动60s后,分时间轮转动一格,同时秒时间轮清零;
- 之后秒时间轮和分时间轮会协同转动,分时间轮转动一格,秒时间轮转动一圈。直到分时间轮转动到第20个格的时候(20min),发现此时挂载了第二个任务。这个时候会将第二个任务拿出来,重新放到秒时间轮中第10个位置处(这个操作被称为降级操作,同时因为高层级时间轮维护着低层级时间轮的指针,所以这个操作很好实现);
- 此时轮到秒时间轮转动了。当秒时间轮转动10个格的时候(20min10s),此时拿取到了第二个任务去执行;
- 在这之后秒时间轮和分时间轮会再次协同转动,直到分时间轮转动60个格后(60min),时时间轮转动一格,同时分时间轮清零;
- 此时时时间轮中发现挂载了第三个任务。这个时候会将第三个任务拿出来,重新放到分时间轮中第20个位置处;
- 在这之后秒时间轮和分时间轮继续协同转动,直到当分时间轮转动20个格的时候(1h20min),此时拿取到了第三个任务。以此类推,将第三个任务重新放到秒时间轮中第3个位置处;
- 此时轮到秒时间轮转动了。当秒时间轮转动3个格的时候(1h20min3s),此时拿取到了第三个任务去执行。
从上面的流程中可以看到,执行任务永远是在最低层级的时间轮上执行的。
多层时间轮的思想在很多的框架中都有实现,比如Netty、Kafka、Dubbo等等。虽然多层时间轮能很好地节省空间和控制粒度,但是依然解决不了空转的问题。而在Kafka中提供了一种优化思路:使用多层时间轮+延迟队列DelayQueue的方式。延迟队列中会存放着所有的桶(也就是时间轮中的每一个位置),按照延迟时间排队(DelayQueue本质上是个小顶堆,我之前详细分析过小顶堆的运行过程,感兴趣的话可以查看《较真儿学源码系列-ScheduledThreadPoolExecutor(逐行源码带你分析作者思路)》)。Kafka中的时间轮不会按照固定的速率转动,而是等到延迟队列中能拿到过期任务的时候才会转动,并且转动的时间也取决于任务的过期时间(DelayQueue拿不到数据意味着此时没有过期的数据,这个时候线程会被休眠,杜绝了空转的情况出现)。
说了这么多,让我们把思路拉回来,看看在PowerJob中是如何实现时间轮算法的吧。
2 schedule方法
之前在分析PowerJob的启动流程源码的时候,服务端在启动的时候会执行多个定时任务,其中在ScheduleCronJob/ScheduleDailyTimeIntervalJob定时任务中会将任务推入时间轮中等待调度执行,方法是InstanceTimeWheelService.schedule,查看其实现:
/**
* InstanceTimeWheelService:
* 定时调度
*
* @param uniqueId 唯一 ID,必须是 snowflake 算法生成的 ID
* @param delayMS 延迟毫秒数
* @param timerTask 需要执行的目标方法
*/
public static void schedule(Long uniqueId, Long delayMS, TimerTask timerTask) {
//长延迟阈值为1分钟,如果任务的延迟时间<=1分钟,则直接用精确调度时间轮(每1ms走一格)进行调度
if (delayMS <= LONG_DELAY_THRESHOLD_MS) {
realSchedule(uniqueId, delayMS, timerTask);
return;
}
//否则,用非精确调度时间轮(每10s走一格)进行调度。等非精确调度时间轮时间快到了的时候(真正执行的时间-1分钟),再送到精确调度时间轮进行调度
long expectTriggerTime = System.currentTimeMillis() + delayMS;
TimerFuture longDelayTask = SLOW_TIMER.schedule(() -> {
//CARGO是用来缓存所有等待执行的任务(延迟时间需要大于1s)
CARGO.remove(uniqueId);
realSchedule(uniqueId, expectTriggerTime - System.currentTimeMillis(), timerTask);
}, delayMS - LONG_DELAY_THRESHOLD_MS, TimeUnit.MILLISECONDS);
CARGO.put(uniqueId, longDelayTask);
}
/**
* 第12行代码处和第21行代码处:
*/
private static void realSchedule(Long uniqueId, Long delayMS, TimerTask timerTask) {
//用精确调度时间轮进行调度
TimerFuture timerFuture = TIMER.schedule(() -> {
CARGO.remove(uniqueId);
timerTask.run();
}, delayMS, TimeUnit.MILLISECONDS);
//当延迟时间大于1s的时候,才放到CARGO中
if (delayMS > MIN_INTERVAL_MS) {
CARGO.put(uniqueId, timerFuture);
}
}上面的代码中,当任务的延迟时间大于1分钟的时候,会同时用到精确时间轮和非精确时间轮。试想一下为什么?正如第1.1小节最后说的,如果此时只有一个任务,其延迟时间是10分钟,因为精确时间轮是每1ms走一格,那么在10分钟到来之前,精确时间轮已经走了很多圈了,但是这些动作都是在做空转、在做无用功,很浪费系统资源。所以,当任务的延迟时间大于1分钟的时候,会用到精确时间轮和非精确时间轮相结合的方式去运行。当延迟时间大的时候,先用跨步大的非精确时间轮去延迟执行,等到快到延迟时间的时候,再改用跨步小的精确时间轮去延迟执行。
接下来就来看下,在上面第18行代码处和第31行代码处,时间轮schedule方法的实现吧:
/**
* HashedWheelTimer:
*/
@Override
public TimerFuture schedule(TimerTask task, long delay, TimeUnit unit) {
//真正执行的时间
long targetTime = System.currentTimeMillis() + unit.toMillis(delay);
HashedWheelTimerFuture timerFuture = new HashedWheelTimerFuture(task, targetTime);
// 直接运行到期、过期任务
if (delay <= 0) {
runTask(timerFuture);
return timerFuture;
}
// 写入阻塞队列,保证并发安全(性能进一步优化可以考虑 Netty 的 Multi-Producer-Single-Consumer队列)
waitingTasks.add(timerFuture);
return timerFuture;
}
/**
* 第9行代码处:
*/
public HashedWheelTimerFuture(TimerTask timerTask, long targetTime) {
this.targetTime = targetTime;
this.timerTask = timerTask;
//初始状态是WAITING
this.status = WAITING;
}
/**
* 第13行代码处:
*/
private void runTask(HashedWheelTimerFuture timerFuture) {
//状态改为RUNNING
timerFuture.status = HashedWheelTimerFuture.RUNNING;
if (taskProcessPool == null) {
//没有线程池,就直接调用目标方法
timerFuture.timerTask.run();
} else {
//有线程池,就放入线程池中去执行
taskProcessPool.submit(timerFuture.timerTask);
}
}3 构造器
在上面第18行代码处,将任务写入到阻塞队列中,看起来流程是走完了。但是肯定是会有一个地方从阻塞队列中拿取任务去执行。之前在InstanceTimeWheelService类中会初始化精确时间轮和非精确时间轮:
/**
* 定时调度任务实例
*
* @author tjq
* @since 2020/7/25
*/
public class InstanceTimeWheelService {
private static final Map CARGO = Maps.newConcurrentMap();
/**
* 精确调度时间轮,每 1MS 走一格
*/
private static final Timer TIMER = new HashedWheelTimer(1, 4096, Runtime.getRuntime().availableProcessors() * 4);
/**
* 非精确调度时间轮,用于处理高延迟任务,每 10S 走一格
*/
private static final Timer SLOW_TIMER = new HashedWheelTimer(10000, 12, 0);
/**
* 支持取消的时间间隔,低于该阈值则不会放进 CARGO
*/
private static final long MIN_INTERVAL_MS = 1000;
/**
* 长延迟阈值
*/
private static final long LONG_DELAY_THRESHOLD_MS = 60000;
//...
} 那么接下来就来看下HashedWheelTimer构造器的实现,看看有没有什么逻辑:
/**
* HashedWheelTimer:
* 新建时间轮定时器
*
* @param tickDuration 时间间隔,单位毫秒(ms)
* @param ticksPerWheel 轮盘个数
* @param processThreadNum 处理任务的线程个数,0代表不启用新线程(如果定时任务需要耗时操作,请启用线程池)
*/
public HashedWheelTimer(long tickDuration, int ticksPerWheel, int processThreadNum) {
//多少ms走一格,后面会看到,实际上就是线程睡眠的时间(Thread.sleep)
this.tickDuration = tickDuration;
// 初始化轮盘,大小格式化为2的N次,可以使用 & 代替取余
int ticksNum = CommonUtils.formatSize(ticksPerWheel);
wheel = new HashedWheelBucket[ticksNum];
for (int i = 0; i < ticksNum; i++) {
//每一个槽位初始化桶(HashedWheelBucket继承于LinkedList,本质上是个链表)
wheel[i] = new HashedWheelBucket();
}
//掩码,取余(%)替换为按位与(&)所需
mask = wheel.length - 1;
// 初始化执行线程池
if (processThreadNum <= 0) {
taskProcessPool = null;
} else {
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("HashedWheelTimer-Executor-%d").build();
// 这里需要调整一下队列大小
BlockingQueue queue = Queues.newLinkedBlockingQueue(8192);
int core = Math.max(Runtime.getRuntime().availableProcessors(), processThreadNum);
// 基本都是 io 密集型任务
//为了尽量减少执行任务所带来的额外时间损耗,这里选择使用线程池来执行
taskProcessPool = new ThreadPoolExecutor(core, 2 * core,
60, TimeUnit.SECONDS,
queue, threadFactory, RejectedExecutionHandlerFactory.newCallerRun("PowerJobTimeWheelPool"));
}
startTime = System.currentTimeMillis();
// 启动后台线程
//真正干事的线程
indicator = new Indicator();
new Thread(indicator, "HashedWheelTimer-Indicator").start();
}
/**
* 第15行代码处:
* 将大小格式化为 2的N次
* HashMap的实现方式,取cap的最小2次幂(我之前也对HashMap的源码进行过分析,其中对取cap的最小2次幂的方法详细分析过,感兴趣的话可以查看:https://blog.csdn.net/weixin_30342639/article/details/107383800)
*
* @param cap 初始大小
* @return 格式化后的大小,2的N次
*/
public static int formatSize(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
} 4 Indicator
在上面第44行代码处,新开启了一个Indicator线程去执行,那么接下来就来看下其run方法的实现:
/**
* Indicator:
*/
@Override
public void run() {
while (!stop.get()) {
// 1. 将任务从队列推入时间轮
pushTaskToBucket();
// 2. 处理取消的任务
processCanceledTasks();
// 3. 等待指针跳向下一刻
tickTack();
// 4. 执行定时任务
//计算当前时间点的槽位
int currentIndex = (int) (tick & mask);
//拿取此时的槽
HashedWheelBucket bucket = wheel[currentIndex];
//执行任务
bucket.expireTimerTasks(tick);
//每走过一个刻度,tick就会+1。同时在上面第7行代码处是个while循环,也就意味着指针会一直转动,直到时间轮被停止,stop赋值为true
tick++;
}
//当时间轮停止的时候,getUnprocessedTasks方法获取所有处于WAITING状态的任务,需要等待这里latch.countDown方法执行完成后才能获取。其实也就是在等待最后一轮时间轮执行完毕
latch.countDown();
}
/**
* 第10行代码处:
* 将队列中的任务推入时间轮中
*/
private void pushTaskToBucket() {
while (true) {
//这里就可以看到,从阻塞队列中拿取任务
HashedWheelTimerFuture timerTask = waitingTasks.poll();
//循环执行,只有拿取的任务是空的话,才会终止循环。这就意味着一次会把所有任务一起取出来
if (timerTask == null) {
return;
}
// 总共的偏移量
//偏移量的计算方式是目标时间的时间戳-开始时间的时间戳
long offset = timerTask.targetTime - startTime;
// 总共需要走的指针步数
timerTask.totalTicks = offset / tickDuration;
// 取余计算 bucket index
//计算槽位
int index = (int) (timerTask.totalTicks & mask);
HashedWheelBucket bucket = wheel[index];
// TimerTask 维护 Bucket 引用,用于删除该任务
timerTask.bucket = bucket;
if (timerTask.status == HashedWheelTimerFuture.WAITING) {
//只有状态是WAITING的时候才会添加任务进槽里
bucket.add(timerTask);
}
}
}
/**
* 第12行代码处:
* 处理被取消的任务
*/
private void processCanceledTasks() {
while (true) {
//同pushTaskToBucket方法一样,一次把所有取消的任务都取出来
HashedWheelTimerFuture canceledTask = canceledTasks.poll();
if (canceledTask == null) {
return;
}
// 从链表中删除该任务(bucket为null说明还没被正式推入时间格中,不需要处理)
if (canceledTask.bucket != null) {
canceledTask.bucket.remove(canceledTask);
}
}
}
/**
* 第14行代码处:
* 模拟指针转动,当返回时指针已经转到了下一个刻度
*/
private void tickTack() {
// 下一次调度的绝对时间
//tick是指针每走过一个刻度,就会+1。这里也就是在计算指针转动到下一个刻度的时间
long nextTime = startTime + (tick + 1) * tickDuration;
//需要睡眠的时间=指针转动到下一个刻度的时间-当前时间
long sleepTime = nextTime - System.currentTimeMillis();
//当需要睡眠的时间不大于0的时候,意味着此时不需要睡眠,直接执行任务就好了
if (sleepTime > 0) {
try {
//这里就可以看到,指针跳动是通过Thread.sleep方法来模拟实现的。当线程被重新唤醒时,此时也就走过了一个刻度
Thread.sleep(sleepTime);
} catch (Exception ignore) {
}
}
}
/**
* HashedWheelBucket:
* 第21行代码处:
*/
public void expireTimerTasks(long currentTick) {
//里面返回true代表任务需要被删除
removeIf(timerFuture -> {
// processCanceledTasks 后外部操作取消任务会导致 BUCKET 中仍存在 CANCELED 任务的情况
if (timerFuture.status == HashedWheelTimerFuture.CANCELED) {
return true;
}
if (timerFuture.status != HashedWheelTimerFuture.WAITING) {
log.warn("[HashedWheelTimer] impossible, please fix the bug");
return true;
}
// 本轮直接调度
if (timerFuture.totalTicks <= currentTick) {
if (timerFuture.totalTicks < currentTick) {
log.warn("[HashedWheelTimer] timerFuture.totalTicks < currentTick, please fix the bug");
}
try {
// 提交执行
runTask(timerFuture);
} catch (Exception ignore) {
} finally {
//执行完毕后,状态赋值为FINISHED
timerFuture.status = HashedWheelTimerFuture.FINISHED;
}
//这里返回true意味着任务执行完成后,需要从时间轮的槽中删除
return true;
}
return false;
});
}从上面的代码中可以看出,Indicator线程才是时间轮真正干事的线程。值得一提的是,在上面第124行代码处的判断是很有必要的。正如第1.1小节说的,试想一下,如果时间轮的槽数是12,时间轮一秒转一次。此时有两个任务,分别是在第1秒和第13秒执行。那么这两个任务都会被放在第1号槽中(对12取余)。当1秒过后,取出1号槽中的任务链表,发现这两个任务都会被取出。那么这两个任务都会被执行吗?肯定不是的。只有第一个任务需要被执行,第二个任务此时需要再延迟12秒后才会被执行。所以这里也就是在判断是不是本轮时间轮需要执行的任务,不是的话就等到下一轮(currentTick也就是传进来的tick,时间轮每转一轮就会+1,会不断累加。totalTicks是当前这个任务总共需要走的步数,当totalTicks>currentTick时,意味着这个任务不是本轮需要执行的。还是拿上面的例子来说,1秒过后,currentTick=1,此时第一个任务的totalTicks=1,会被执行;而第二个任务的totalTicks为13,此轮不会被执行)。
原创不易,未得准许,请勿转载,翻版必究