代码规范和技巧

一、规范命名
比如类、属性、方法、参数等遵循以下几点:
见名知义、代码对齐、代码注释
try中的核心代码可以抽取,方法别太长
if嵌套太多——> return优化
if (条件1) {
if (条件2) {
if (条件3) {
if (条件4) {
if (条件5) {
System.out.println("三友的java日记");
}
}
}
}
}
if (!条件1) {
return;
}
if (!条件2) {
return;
}
if (!条件3) {
return;
}
if (!条件4) {
return;
}
if (!条件5) {
return;
}
System.out.println("三友的java日记");
if条件表达式不要太复杂
if (((StringUtils.isBlank(person.getName())
|| "三友的java日记".equals(person.getName()))
&& (person.getAge() != null && person.getAge() > 10))
&& "汉".equals(person.getNational())) {
// 处理逻辑
}
boolean sanyouOrBlank = StringUtils.isBlank(person.getName()) || "三友的java日记".equals(person.getName());
boolean ageGreaterThanTen = person.getAge() != null && person.getAge() > 10;
boolean isHanNational = "汉".equals(person.getNational());
if (sanyouOrBlank
&& ageGreaterThanTen
&& isHanNational) {
// 处理逻辑
}
二、参数校验优化
当前端传递给后端参数的时候,,需要对参数进行校验
@PostMapping
public void addPerson(@RequestBody AddPersonRequest addPersonRequest) {
if (StringUtils.isBlank(addPersonRequest.getName())) {
throw new BizException("人员姓名不能为空");
}
if (StringUtils.isBlank(addPersonRequest.getIdCardNo())) {
throw new BizException("身份证号不能为空");
}
// 处理新增逻辑
}
当字段的多的时候,光校验就占据了很长的代码,不够优雅。
针对参数校验这个问题,有第三方库已经封装好了,比如hibernate-validator框架,只需要拿来用即可。
/**
在实体类上加@NotBlank、@NotNull注解来进行校验
*/
@Data
@ToString
private class AddPersonRequest {
@NotBlank(message = "人员姓名不能为空")
private String name;
@NotBlank(message = "身份证号不能为空")
private String idCardNo;
//忽略
}
此时Controller接口的需要添加@Valid注解
@PostMapping
public void addPerson(@RequestBody @Valid AddPersonRequest addPersonRequest) {
// 处理新增逻辑
}
尽量使用工具类,比如在对集合判空的时候,可以这么写
public void updatePersons(List<Person> persons) {
if (persons != null && persons.size() > 0) {
}
}
但是一般不推荐这么写,可以通过一些判断的工具类来写
不仅集合,比如字符串的判断等等,就使用工具类,不要手动判断。
public void updatePersons(List<Person> persons) {
if (!CollectionUtils.isEmpty(persons)) {
}
}
尽量不要重复造轮子,就拿格式化日期来来说,我们一般封装成一个工具类来调用,比如如下代码
private static final SimpleDateFormat DATE_TIME_FORMAT = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static String formatDateTime(Date date) {
return DATE_TIME_FORMAT.format(date);
}
这段代码看似没啥问题,但是却忽略了SimpleDateFormat是个线程不安全的类,所以这就会引起坑。
一般对于这种已经有开源的项目并且已经做得很好的时候,比如Hutool,就可以把轮子直接拿过来用了。
三、统一返回值
后端在设计接口的时候,需要统一返回值
{
"code":0,
"message":"成功",
"data":"返回数据"
}
不仅是给前端参数,也包括提供给第三方的接口等,这样接口调用方法可以按照固定的格式解析代码,不用进行判断。
Spring中很多方法可以做到统一返回值,而不用每个方法都返回,比如基于AOP,或者可以自定义HandlerMethodReturnValueHandler来实现统一返回值。
四、统一异常处理
没有统一异常处理的时候,那么所有的接口避免不了try catch操作。
@GetMapping("/{id}")
public Result<T> selectPerson(@PathVariable("id") Long personId) {
try {
PersonVO vo = personService.selectById(personId);
return Result.success(vo);
} catch (Exception e) {
//打印日志
return Result.error("系统异常");
}
}
所以可以基于Spring提供的统一异常处理机制来完成。
五、尽量不传递null,不返回null
不传null值可以避免方法不支持为null入参时产生的空指针问题
为了更好的表明该方法是不是可以传null值,可以通过@NonNull和@Nullable注解来标记。@NonNull就表示不能传null值,@Nullable就是可以传null值。
//示例1
public void updatePerson(@Nullable Person person) {
if (person == null) {
return;
}
personService.updateById(person);
}
//示例2
public void updatePerson(@NonNull Person person) {
personService.updateById(person);
}
尽量不返回null值是为了减少调用者对返回值的为null判断,如果无法避免返回null值,可以通过返回Optional来代替null值。
public Optional<Person> getPersonById(Long personId) {
return Optional.ofNullable(personService.selectById(personId));
}
如果不想这么写,也可以通过@NonNull和@Nullable表示方法会不会返回null值。
六、日志打印规范
好的日志打印能帮助我们快速定位问题
好的日志应该遵循以下几点:
可搜索性,要有明确的关键字信息
异常日志需要打印出堆栈信息
合适的日志级别,比如异常使用error,正常使用info
日志内容太大不打印,比如有时需要将图片转成Base64,那么这个Base64就可以不用打印
在日志打印的时候,日志是可以把线程的名字给打印出来。

如上图,日志打印出来的就是tomcat的线程。
所以,设置线程的名称可以帮助我们更好的知道代码是通过哪个线程执行的,更容易排查问题。
七、统一类库
在一个项目中,可能会由于引入的依赖不同导致引入了很多相似功能的类库,比如常见的json类库,又或者是一些常用的工具类,当遇到这种情况下,应当规范在项目中到底应该使用什么类库,而不是一会用Fastjson,一会使用Gson。
八、尽量使用聚合/组合代替继承
继承的弊端:
灵活性低。java语言是单继承的,无法同时继承很多类,并且继承容易导致代码层次太深,不易于维护
耦合性高。一旦父类的代码修改,可能会影响到子类的行为
所以一般推荐使用聚合/组合代替继承。
聚合/组合的意思就是通过成员变量的方式来使用类。
比如说,OrderService需要使用UserService,可以注入一个UserService而非通过继承UserService。
聚合和组合的区别就是,组合是当对象一创建的时候,就直接给属性赋值,而聚合的方式可以通过set方式来设置。
/**
组合
*/
public class OrderService {
private UserService userService = new UserService();
}
/**
聚合
*/
public class OrderService {
private UserService userService;
public void setUserService(UserService userService) {
this.userService = userService;
}
}
九、使用设计模式优化代码
当你需要做一个可以根据不同的平台做不同消息推送的功能时,就可以使用策略模式的方式来优化。
public interface MessageNotifier {
/**
* 是否支持改类型的通知的方式
*
* @param type 0:短信 1:app
* @return
*/
boolean support(int type);
/**
* 通知
*
* @param user
* @param content
*/
void notify(User user, String content);
}
短信通知实现
@Component
public class SMSMessageNotifier implements MessageNotifier {
@Override
public boolean support(int type) {
return type == 0;
}
@Override
public void notify(User user, String content) {
//调用短信通知的api发送短信
}
}
app通知实现
public class AppMessageNotifier implements MessageNotifier {
@Override
public boolean support(int type) {
return type == 1;
}
@Override
public void notify(User user, String content) {
//调用通知app通知的api
}
}
最后提供一个方法,当需要进行消息通知时,调用notifyMessage,传入相应的参数就行。
@Resource
private List<MessageNotifier> messageNotifiers;
public void notifyMessage(User user, String content, int notifyType) {
for (MessageNotifier messageNotifier : messageNotifiers) {
if (messageNotifier.support(notifyType)) {
messageNotifier.notify(user, content);
}
}
}
假设此时需要支持通过邮件通知,只需要有对应实现就行。
但设计模式不可滥用,如下面打印Person信息的代码,用if判断就能够做到效果,你说我要不用责任链或者什么设计模式来优化一下吧,没必要。
public void printPerson(Person person) {
StringBuilder sb = new StringBuilder();
if (StringUtils.isNotBlank(person.getName())) {
sb.append("姓名:").append(person.getName());
}
if (StringUtils.isNotBlank(person.getIdCardNo())) {
sb.append("身份证号:").append(person.getIdCardNo());
}
// 省略
System.out.println(sb.toString());
}
十、面向接口编程
在实际项目中可能需要对一些图片进行存储,但是存储的方式很多,比如可以选择阿里云的OSS,又或者是七牛云,存储服务器等等。所以对于存储图片这个功能来说,这些具体的实现是可以相互替换的。
public interface FileStorage {
String store(String fileName, byte[] bytes);
}
如果选择了阿里云OSS作为存储服务器,那么就可以基于OSS实现一个FileStorage,在项目中哪里需要存储的时候,只要实现注入这个接口就可以了。
@Autowired
private FileStorage fileStorage;
假设用了一段时间之后,发现阿里云的OSS比较贵,此时想换成七牛云的,那么此时只需要基于七牛云的接口实现FileStorage接口,然后注入到IOC,那么原有代码用到FileStorage根本不需要动,实现轻松的替换。
十一、魔法值用常量表示
public void sayHello(String province) {
if ("广东省".equals(province)) {
System.out.println("靓仔~~");
} else {
System.out.println("帅哥~~");
}
}
代码里,广东省就是一个魔法值,那么就可以将用一个常量来保存
private static final String GUANG_DONG_PROVINCE = "广东省";
public void sayHello(String province) {
if (GUANG_DONG_PROVINCE.equals(province)) {
System.out.println("靓仔~~");
} else {
System.out.println("帅哥~~");
}
}
十二、资源释放写到finally
比如在使用一个api类锁或者进行IO操作的时候,需要主动写代码需释放资源,为了能够保证资源能够被真正释放,那么就需要在finally中写代码保证资源释放。
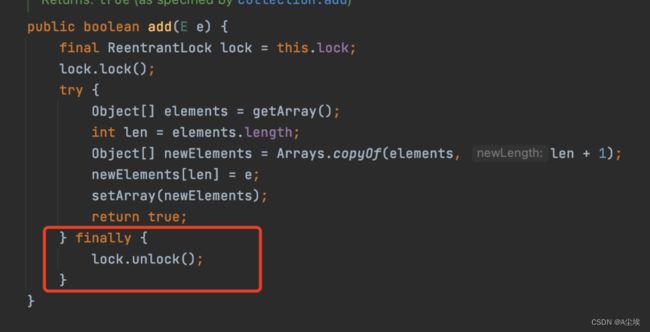
如图所示,就是CopyOnWriteArrayList的add方法的实现,最终是在finally中进行锁的释放。
十三、使用线程池代替手动创建线程
使用线程池还有以下好处:
降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统 的稳定性,使用线程池可以进行统一的分配,调优和监控。
所以为了达到更好的利用资源,提高响应速度,就可以使用线程池的方式来代替手动创建线程。
十四、涉及线程间可见性加volatile
在RocketMQ源码中有这么一段代码
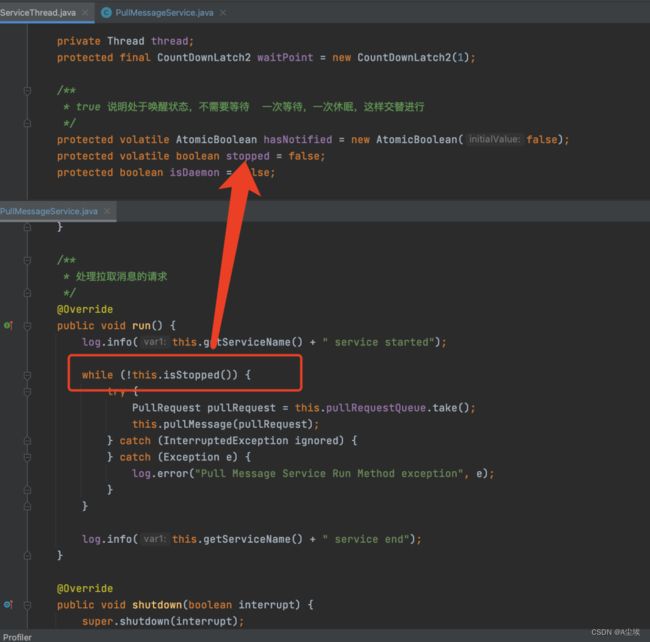
在消费者在从服务端拉取消息的时候,会单独开一个线程,执行while循环,只要stopped状态一直为false,那么就会一直循环下去,线程就一直会运行下去,拉取消息。
当消费者客户端关闭的时候,就会将stopped状态设置为true,告诉拉取消息的线程需要停止了。但是由于并发编程中存在可见性的问题,所以虽然客户端关闭线程将stopped状态设置为true,但是拉取消息的线程可能看不见,不能及时感知到数据的修改,还是认为stopped状态设置为false,那么就还会运行下去。
针对这种可见性的问题,java提供了一个volatile关键字来保证线程间的可见性。
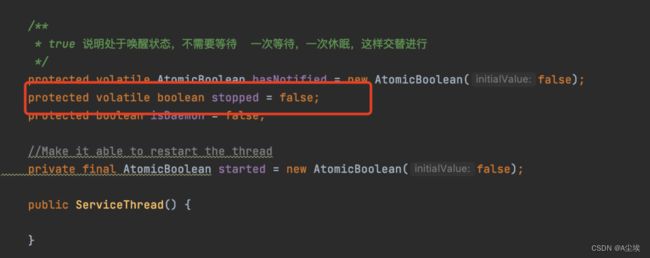
所以,源码中就加了volatile关键字。
加了volatile关键字之后,一旦客户端的线程将stopped状态设置为true时候,拉取消息的线程就能立马知道stopped已经是false了,那么再次执行while条件判断的时候,就不成立,线程就运行结束了,然后退出。
十五、考虑线程安全问题
在平时开发中,有时需要考虑并发安全的问题。
举个例子来说,一般在调用第三方接口的时候,可能会有一个鉴权的机制,一般会携带一个请求头token参数过去,而token也是调用第三方接口返回的,一般这种token都会有个过期时间,比如24小时。
我们一般会将token缓存到Redis中,设置一个过期时间。向第三方发送请求时,会直接从缓存中查找,但是当从Redis中获取不到token的时候,我们都会重新请求token接口,获取token,然后再设置到缓存中。
整个过程看起来是没什么问题,但是实则隐藏线程安全问题。
假设当出现并发的时候,同时来两个线程AB从缓存查找,发现没有,那么AB此时就会同时调用token获取接口。假设A先获取到token,B后获取到token,但是由于CPU调度问题,线程B虽然后获取到token,但是先往Redis存数据,而线程A后存,覆盖了B请求的token。
这下就会出现大问题,最新的token被覆盖了,那么之后一定时间内token都是无效的,接口就请求不通。
针对这种问题,可以使用double check机制来优化获取token的问题。
所以,在实际中,需要多考虑考虑业务是否有线程安全问题,有集合读写安全问题,那么就用线程安全的集合,业务有安全的问题,那么就可以通过加锁的手段来解决。
十六、慎用异步
虽然在使用多线程可以帮助我们提高接口的响应速度,但是也会带来很多问题。
事务问题
一旦使用了异步,就会导致两个线程不是同一个事务的,导致异常之后无法正常回滚数据。
cpu负载过高
之前有个小伙伴遇到需要同时处理几万调数据的需求,每条数据都需要调用很多次接口,为了达到老板期望的时间要求,使用了多线程跑,开了很多线程,此时会发现系统的cpu会飙升
意想不到的异常
还是上面的提到的例子,在测试的时候就发现,由于并发量激增,在请求第三方接口的时候,返回了很多错误信息,导致有的数据没有处理成功。
虽然说慎用异步,但不代表不用,如果可以保证事务的问题,或是CPU负载不会高的话,那么还是可以使用的。
十七、减小锁的范围
减小锁的范围就是给需要加锁的代码加锁,不需要加锁的代码不要加锁。这样就能减少加锁的时间,从而可以较少锁互斥的时间,提高效率。

比如CopyOnWriteArrayList的addAll方法的实现,lock.lock(); 代码完全可以放到代码的第一行,但是作者并没有,因为前面判断的代码不会有线程安全的问题,不放到加锁代码中可以减少锁抢占和占有的时间。
十八、有类型区分时定义好枚举
比如在项目中不同的类型的业务可能需要上传各种各样的附件,此时就可以定义好不同的一个附件的枚举,来区分不同业务的附件。
不要在代码中直接写死,不定义枚举,代码阅读起来非常困难,直接看到数字都是懵逼的。。
十九、远程接口调用设置超时事件
比如在进行微服务之间进行rpc调用的时候,又或者在调用第三方提供的接口的时候,需要设置超时时间,防止因为各种原因,导致线程”卡死“在那。
我以前就遇到过线上就遇到过这种问题。当时的业务是订阅kafka的消息,然后向第三方上传数据。在某个周末,突然就接到电话,说数据无法上传了,通过排查线上的服务器才发现所有的线程都线程”卡死“了,最后定位到代码才发现原来是没有设置超时时间。
二十、集合使用应当指明初始化大小
比如在写代码的时候,经常会用到List、Map来临时存储数据,其中最常用的就是ArrayList和HashMap。但是用不好可能也会导致性能的问题。
比如说,在ArrayList中,底层是基于数组来存储的,数组是一旦确定大小是无法再改变容量的。但不断的往ArrayList中存储数据的时候,总有那么一刻会导致数组的容量满了,无法再存储其它元素,此时就需要对数组扩容。所谓的扩容就是新创建一个容量是原来1.5倍的数组,将原有的数据给拷贝到新的数组上,然后用新的数组替代原来的数组。
在扩容的过程中,由于涉及到数组的拷贝,就会导致性能消耗;同时HashMap也会由于扩容的问题,消耗性能。所以在使用这类集合时可以在构造的时候指定集合的容量大小。
二十一、尽量不使用BeanUtils来拷贝属性
在开发中经常需要对JavaBean进行转换,但是又不想一个一个手动set,比较麻烦,所以一般会使用属性拷贝的一些工具,比如说Spring提供的BeanUtils来拷贝。不得不说,使用BeanUtils来拷贝属性是真的舒服,使用一行代码可以代替几行甚至十几行代码,我也喜欢用。
但是喜欢归喜欢,但是会带来性能问题,因为底层是通过反射来的拷贝属性的,所以尽量不要用BeanUtils来拷贝属性。
比如你可以装个JavaBean转换的插件,帮你自动生成转换代码;又或者可以使用性能更高的MapStruct来进行JavaBean转换,MapStruct底层是通过调用(settter/getter)来实现的,而不是反射来快速执行。
二十二、使用StringBuilder进行字符串拼接
String str1 = "123";
String str2 = "456";
String str3 = "789";
String str4 = str1 + str2 + str3;
使用 + 拼接字符串的时候,会创建一个StringBuilder,然后将要拼接的字符串追加到StringBuilder,再toString,这样如果多次拼接就会执行很多次的创建StringBuilder,z执行toString的操作。
所以可以手动通过StringBuilder拼接,这样只会创建一次StringBuilder,效率更高。
StringBuilder sb = new StringBuilder();
String str = sb.append("123").append("456").append("789").toString();
二十三、@Transactional应指定回滚的异常类型
平时在写代码的时候需要通过rollbackFor显示指定需要对什么异常回滚,原因在这:

默认是只能回滚RuntimeException和Error异常,所以需要手动指定,比如指定成Expection等。
二十四、谨慎方法内部调用动态代理的方法
@Service
public class PersonService {
public void update(Person person) {
// 处理
updatePerson(person);
}
@Transactional(rollbackFor = Exception.class)
public void updatePerson(Person person) {
// 处理
}
}
update调用了加了@Transactional注解的updatePerson方法,那么此时updatePerson的事务就是失效。
其实失效的原因不是事务的锅,是由AOP机制决定的,因为事务是基于AOP实现的。AOP是基于对象的代理,当内部方法调用时,走的不是动态代理对象的方法,而是原有对象的方法调用,如此就走不到动态代理的代码,就会失效了。
如果实在需要让动态代理生效,可以注入自己的代理对象
@Service
public class PersonService {
@Autowired
private PersonService personService;
public void update(Person person) {
// 处理
personService.updatePerson(person);
}
@Transactional(rollbackFor = Exception.class)
public void updatePerson(Person person) {
// 处理
}
}
二十五、需要什么字段select什么字段
查询全字段有以下几点坏处:
增加不必要的字段的网络传输
比如有些文本的字段,存储的数据非常长,但是本次业务使用不到,但是如果查了就会把这个数据返回给客户端,增加了网络传输的负担
会导致无法使用到覆盖索引
比如说,现在有身份证号和姓名做了联合索引,现在只需要根据身份证号查询姓名,如果直接select name 的话,那么在遍历索引的时候,发现要查询的字段在索引中已经存在,那么此时就会直接从索引中将name字段的数据查出来,返回,而不会继续去查找聚簇索引,减少回表的操作。
所以建议是需要使用什么字段查询什么字段。比如mp也支持在构建查询条件的时候,查询某个具体的字段。
Wrappers.query().select("name");
二十六、不循环调用数据库
不要在循环中访问数据库,这样会严重影响数据库性能。
比如需要查询一批人员的信息,人员的信息存在基本信息表和扩展表中,错误的代码如下:
public List<PersonVO> selectPersons(List<Long> personIds) {
List<PersonVO> persons = new ArrayList<>(personIds.size());
List<Person> personList = personMapper.selectByIds(personIds);
for (Person person : personList) {
PersonVO vo = new PersonVO();
PersonExt personExt = personExtMapper.selectById(person.getId());
// 组装数据
persons.add(vo);
}
return persons;
}
遍历每个人员的基本信息,去数据库查找。
正确的方法应该先批量查出来,然后转成map:
public List<PersonVO> selectPersons(List<Long> personIds) {
List<PersonVO> persons = new ArrayList<>(personIds.size());
List<Person> personList = personMapper.selectByIds(personIds);
//批量查询,转换成Map
List<PersonExt> personExtList = personExtMapper.selectByIds(person.getId());
Map<String, PersonExt> personExtMap = personExtList.stream().collect(Collectors.toMap(PersonExt::getPersonId, Function.identity()));
for (Person person : personList) {
PersonVO vo = new PersonVO();
//直接从Map中查找
PersonExt personExt = personExtMap.get(person.getId());
// 组装数据
persons.add(vo);
}
return persons;
}
二十七、用业务代码代替多表join
如上面代码所示,原本也可以将两张表根据人员的id进行关联查询。但是不推荐这么,阿里也禁止多表join的操作

而之所以会禁用,是因为join的效率比较低。
MySQL是使用了嵌套循环的方式来实现关联查询的,也就是for循环会套for循环的意思。用第一张表做外循环,第二张表做内循环,外循环的每一条记录跟内循环中的记录作比较,符合条件的就输出,这种效率肯定低。
装上阿里代码检查插件
我们平时写代码由于各种因为,比如什么领导啊,项目经理啊,会一直催进度,导致写代码都来不及思考,怎么快怎么来,cv大法上线,虽然有心想写好代码,但是手确不听使唤。所以我建议装一个阿里的代码规范插件,如果有代码不规范,会有提醒,这样就可以知道哪些是可以优化的了。

JavaScript中常用的技巧总结
一、If-Else 用 || 或 ?? 运算符进行简化
逻辑或操作符||,这里要注意的是0和’'也会认为是false。如果||前面的值是0 ‘’ false null undefined NaN其中的任意一种,则直接返回||后面的值
function(obj){
var a = obj || {}
}
//等价于
function(obj){
var a;
if(obj === 0 || obj === "" || obj === false || obj === null || obj === undefined || isNaN(obj)){
a = {}
}else{
a = obj;
}
}
空值合并操作符??如果没有定义左侧返回右侧。如果是,则返回左侧。
这种方法非常实用,有时候仅仅只是想判断一个字段有没有值,而不是把空字符串或者0也当做false处理
function(obj){
var a = obj ?? {}
}
//等价于
function(obj){
var a;
if(obj === null || obj === undefined){
a = {}
}else{
a = obj;
}
}
输入框非空的判断(有时候不想把0当成false可以用此方法。比如分数0也是个值,这种情况就不能认为是false)
if(value !== null && value !== undefined && value !== ''){
}
//等价于
if((value ?? '') !== ''){
}
二、includes使用
在上面逻辑或操作符||代码段里有一个if判断比较长,这时候就可以用includes去简化代码
if(
obj === 0 ||
obj === "" ||
obj === false ||
obj === null ||
obj === undefined
){
// ...
}
// 使用includes简化
if([0, '', false, null, undefined].includes(obj)){
// ...
}
三、防止崩溃的可选链(?.)
可选链操作符?. 如果访问未定义的属性,则会产生错误。这就是可选链的用武之地。在未定义属性时使用可选链运算符,undefined将返回而不是错误。这可以防止你的代码崩溃。
const student = {
name: "lwl",
address: {
state: "New York"
},
}
// 一层一层判断
console.log(student && student.address && student.address.ZIPCode) // 输出:undefined
// 使用可选链操作符
console.log(student?.address?.ZIPCode) // 输出:undefined
可选链运算符也可以用于方法调用。如果方法存在,它将被调用,否则将返回 undefined。例如:
const obj = {
foo() {
console.log('Hello from foo!')
}
}
obj.foo?.() // 输出:'Hello from foo!'
obj.bar?.() // 输出:undefined,因为 bar 方法不存在
同样,数组也可以使用。例如:
const arr = [1, 2, 3, 4]
console.log(arr[0]) // 输出:1
console.log(arr[4]) // 输出:undefined
// 使用可选链运算符
console.log(arr?.[0]) // 输出:1
console.log(arr?.[4]) // 输出:undefined
console.log(arr?.[0]?.toString()) // 输出:'1'
四、逻辑空赋值(??=)
逻辑空赋值??= 逻辑空赋值运算符(x ??= y)仅在 x 是 nullish (null 或 undefined) 时对其赋值。
const a = { duration: 50 };
a.duration ??= 10;
console.log(a.duration);
// expected output: 50
a.speed ??= 25;
console.log(a.speed);
// expected output: 25
五、快速生成1-10的数组
生成0-9,利用数组的下表值
// 方法一
const arr1 = [...new Array(10).keys()]
// 方法二
const arr2 = Array.from(Array(10), (v, k) => k)
生成1-10,通过map特性
const arr2 = [...Array(10)].map((v, i) => i + 1)
快速生成10个0的数组
const arr = new Array(10).fill(0)
快速生成10个[]的数组(二维数组)
注意: 二维数组不能直接写成new Array(10).fill([])(也就是fill方法不能传引用类型的值,[]换成new Array()也不行),因为fill里传入引用类型值会导致每一个数组都指向同一个地址,改变一个数据的时候其他数据也会随之改变,详见 mdn官方说明
// 错误写法
const arr = new Array(10).fill([]) // 注意这是错误写法,不要这么写
// 正确写法
const arr = new Array(10).fill().map(() => new Array())
数组降维
你是否还在用递归给一个多维数组降维?如果是,那你应该知道一下es6的 flat()方法。
如果不确定需要降维的数组有多深,可以传入最大值作为参数Infinity,默认值深度为1
const arr = [1, [2, [3, 4], 5], 6]
const flatArr = arr.flat(Infinity) // 输出 [1, 2, 3, 4, 5, 6]
你是否在使用map的时候想要对数组降维?大概像这样:
const arr = [1, 2, 3, 4]
const result = arr.map(v => [v, v * 2]).flat()
console.log(result); // 输出 [1, 2, 2, 4, 3, 6, 4, 8]
其实js也提供了更简便的方法,那就是flatMap(),可以改成这样:
const result = arr.flatMap(v => [v, v * 2])
六、从数组中删除重复项
在 JavaScript 中,Set 是一个集合,它允许你仅存储唯一值。这意味着删除任何重复的值。
因此,要从数组中删除重复项,你可以将其转换为集合,然后再转换回数组。
const numbers = [1, 1, 20, 3, 3, 3, 9, 9];
const uniqueNumbers = [...new Set(numbers)]; // -> [1, 20, 3, 9]
它是如何工作的?
- new Set(numbers)从数字列表中创建一个集合。创建集合会自动删除所有重复值。
- 展开运算符…将任何可迭代对象转换为数组。这意味着将集合转换回数组。[…new Set(numbers)]
在没有第三个变量的情况下交换两个变量
在 JavaScript 中,你可以使用解构从数组中拆分值。这可以应用于交换两个变量而无需第三个
比较简单,es6语法
let x = 1;
let y = 2;
// 交换变量
[x, y] = [y, x];
将对象的值收集到数组中,用于Object.values()将对象的所有值收集到一个新数组中
const info = { name: "Matt", country: "Finland", age: 35 };
// LONGER FORM
let data = [];
for (let key in info) {
data.push(info[key]);
}
// SHORTHAND
const data = Object.values(info);
指数运算符(用的不多)
你Math.pow()习惯把一个数字提高到一个幂吗?你知道你也可以使用**运算符吗?
虽然可以简写,不过我还是建议写成Math.pow()方法,代码更有语义化。
注意:**运算符要求操作数为数值类型,不过在js里也能正常运行。
Math.pow(2, 3); // 输出: 8
2 ** 3; // 输出: 8
Math.pow(4, 0.5); // 输出: 2
4 ** 0.5; // 输出: 2
Math.pow(3, -2); // 输出: 0.1111111111111111
3 ** -2; // 输出: 0.1111111111111111
Math.pow('2', '3'); // 输出: 8 (参数被自动转换为数字)
'2' ** '3'; // js中输出: 8,其他语言可能报错
Math.floor() 简写(用的不多)
向下取整Math.floor()并不是什么新鲜事。但是你知道你也可以使用~~运算符吗?
同上虽然可以简写,不过我还是建议写成Math.floor()方法,代码更有语义化。
注意:对于正数而言两者都是直接去掉小数位,但对于负数来说Math.floor()是向下取整,~~依然是只去掉小数位,整数位不变。 请看下面输出结果:
Math.floor(3.14); // 输出: 3
Math.floor(5.7); // 输出: 5
Math.floor(-2.5); // 输出: -3
Math.floor(10); // 输出: 10
~~3.14; // 输出: 3
~~5.7; // 输出: 5
~~(-2.5); // 输出: -2
~~10; // 输出: 10
第七、逗号运算符(,)
逗号( , )运算符对它的每个操作数从左到右求值,并返回最后一个操作数的值。这让你可以创建一个复合表达式,其中多个表达式被评估,复合表达式的最终值是其成员表达式中最右边的值。这通常用于为 for 循环提供多个参数。
这里只说一下函数return的时候用逗号运算符简化代码的技巧,其他用法请直接点击查看官方文档。
举一个简单的例子:
// 简化前
const result = arr => {
arr.push('a')
return arr
}
console.log(result([1,2])) // 输出:[1, 2, 'a']
这段代码需要返回修改后的数组,不能直接return arr.push(‘a’),因为push的返回值是修改后数组的长度,这时候可以用逗号运算符简化成一行代码。
// 简化后
const result = arr => (arr.push('a'), arr)
console.log(result([1,2])) // 输出:[1, 2, 'a']
Array.map()的简写
比如想要拿到接口返回的特定字段的值,可以用解构赋值和对象的简写方法对map方法简写。
比如接口返回数据,此时如果只想要数据里的id和name,就可以用下面的简写方式
// 接口返回数据
res = [{
id: 1,
name: 'zhangsan',
age: 16,
gender: 0
}, {
id: 2,
name: 'lisi',
age: 20,
gender: 1
}]
// 第一种方法:箭头函数、 解构赋值
const data = res.map(({id, name}) => ({id, name}))
// 第二种方法:箭头函数、返回对象(相对更容易理解)
const data = res.map(v => ({id: v.id, name: v.name}))