几种典型的算法类型
文章目录
- 一、 单调栈
-
- 1. 套路
- 2. 模板:
- 3. leetcode例题:
- 二、 并查集
-
- 1. 套路:
- 2. 模板:
- 3. leetcode例题:
- 三、 滑动窗口
-
- 1. 套路
- 2. 模板
- 3. leetcode例题
- 四、 前缀和&HASH
-
- 1. 套路
-
- 1.1 前缀和 --- 复杂度(O(n^2))
- 1.2 前缀和带HASH --- 复杂度(O(n))
- 2. 模板
-
- 2.1 前缀和
- 2.2 前缀和带HASH(推荐)
- 3. leetcode例题
- 四、 差分
-
- 1. 套路
-
-
- 1.1 套路1(适用小数据)
- 1.2 套路2(适用大数据)
-
- 2. 模板
- 3. leetcode例题
- 五、 排序
-
- 1. 套路
-
- 1.1 拓扑排序(BFS)
- 2. 模板
-
- 2.1 拓扑排序(BFS)
- 3. leetcode例题
- 六、 字符串
-
- 1. 套路
- 2. 模板
- 3. leetcode例题
- 七、 DFS
-
- 1. 套路
- 2. 模板
- 3. leetcode例题
- 八、 BFS
-
- 1. 套路
- 2. 模板
- 3. leetcode例题
- 九、 贪心
-
- 1. 套路
- 2. 模板
- 3. leetcode例题
- 十、 字典树
-
- 1. 套路
- 2. 模板
- 3. leetcode例题
- *、 几套题目
一、 单调栈
https://leetcode-cn.com/problems/next-greater-element-i/solution/dan-diao-zhan-jie-jue-next-greater-number-yi-lei-w/
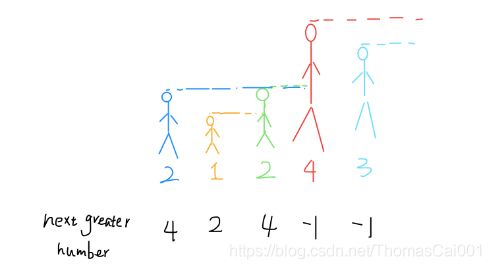
1. 套路
- 从已知容器的后往前存栈
- 如果单调栈不为空,栈中元素小的出栈
- 先获取数,再把当前值入栈
2. 模板:
(1) 单数组版
vector<int> nextGreaterElement(vector<int>& nums) {
vector<int> ans(nums.size()); // 存放答案的数组
stack<int> s;
for (int i = nums.size() - 1; i >= 0; i--) { // 倒着往栈里放
while (!s.empty() && s.top() <= nums[i]) { // 判定个子高矮
s.pop(); // 矮个起开,反正也被挡着了。。。
}
ans[i] = s.empty() ? -1 : s.top(); // 这个元素身后的第一个高个
s.push(nums[i]); // 进队,接受之后的身高判定吧!
}
return ans;
}
作者:labuladong
链接:https://leetcode-cn.com/problems/next-greater-element-i/solution/dan-diao-zhan-jie-jue-next-greater-number-yi-lei-w/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
(2) 循环数组版
class Solution {
public:
vector<int> nextGreaterElements(vector<int>& nums) {
int n = nums.size();
vector<int> res(n, 0);
stack<int> monoStack;
// 1. 从已知容器的后往前存栈
for (int i = n * 2 - 1; i >= 0; i--) {
// 2. 如果单调栈不为空,栈中元素小的出栈
while (!monoStack.empty() and nums[i % n] >= monoStack.top()) {
monoStack.pop();
}
// 3. 先获取数,再把当前值入栈
res[i % n] = monoStack.empty() ? -1 : monoStack.top();
monoStack.push(nums[i % n]);
}
return res;
}
};
3. leetcode例题:
496 下一个更大元素 I
503 下一个更大元素 II
739 每日温度
二、 并查集
https://leetcode-cn.com/problems/number-of-provinces/solution/python-duo-tu-xiang-jie-bing-cha-ji-by-m-vjdr/
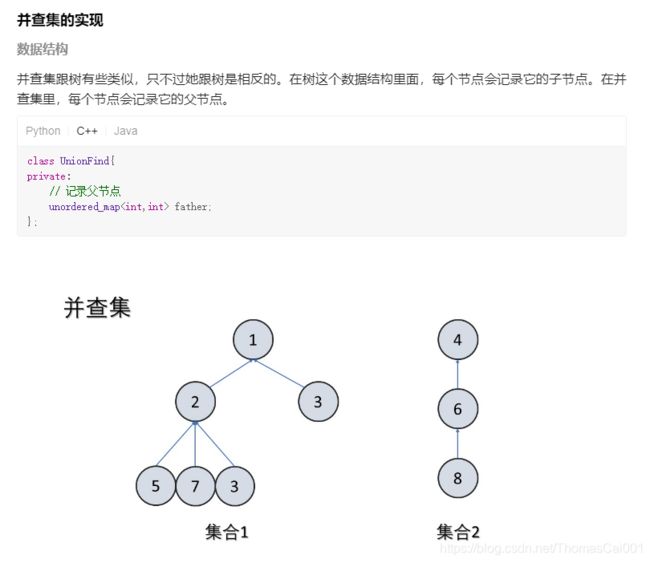
1. 套路:
- 记录父节点
- 添加新节点
- 合并两个节点
- 判断两个节点是否连通
- 查找祖先(用状态压缩)
2. 模板:
class UnionFind{
public:
// 5. 查找祖先(用状态压缩)
int find(int x){
int root = x;
while (father[root] != -1) {
root = father[root];
}
// 注意条件,容易错
while (root != x) {
int other_node = father[x];
father[x] = root;
x = other_node;
}
return root;
}
// 4. 判断两个节点是否连通
bool is_connected(int x,int y){
return find(x) == find(y);
}
// 3. 合并两个节点
void merge(int x,int y){
int root_x = find(x);
int root_y = find(y);
if (root_x != root_y) {
father[find(x)] = find(y);
}
}
// 2. 添加新节点
void add(int x){
if (father.count(x) == 0) {
father[x] = -1;
}
}
private:
// 1. 记录父节点
unordered_map<int, int> father;
};
3. leetcode例题:
547 朋友圈
684 冗余连接
200 岛屿数量
1102 得分最高的路径(会员)
1135 最低成本联通所有城市(会员)
924 尽量减少恶意软件的传播
737 句子相似性II (会员)
三、 滑动窗口
1. 套路
- 先申请一个unordered_map保存,目标集合的元素need;
- 再申请一个unordered_map保存,滑动窗口的元素windows;
- 右指针滑动改变值,到一定条件,然后左指针滑动改变值;
- 注意左滑和右滑的逻辑一致;
2. 模板
void slidingWindow(string s, string t) {
// 1. 先申请一个unordered_map保存,目标集合的元素need;
unordered_map<char, int> need;
// 2. 再申请一个unordered_map保存,滑动窗口的元素windows;
unordered_map<char, int> windows;
for (char c : t) need[c]++;
int left = 0, right = 0;
int valid = 0;
while (right < s.size()) {
// 注意:先取数再右移
char c = s[right];
right++;
// 进行窗口内数据的一系列操作
···
// debug
cout << left << ", " << right << endl;
// 判断左侧窗口是否要收缩
while (window needs shrink) {
// 注意:一样,先取数,再右移
char d = s[left];
left++;
// 进行窗口内数据的一系列操作
···
}
}
}
3. leetcode例题
1208 尽可能使字符串相等 中等 滑动窗口
209 长度最小的子数组 中等 滑动窗口
1004. 最大连续1的个数 III 中等 滑动窗口
159 至多包含两个不同字符的最长子串(会员) 中等 会员 滑动窗口
1100 长度为 K 的无重复字符子串(会员) 中等 会员 滑动窗口
四、 前缀和&HASH
1. 套路
1.1 前缀和 — 复杂度(O(n^2))
- 申请一个vector保存叠加和,空间为原数组个数+1;
- 计算叠加和放入vector中;
- 逐步计算vector中的差值,如果等于目标值,count+1;
1.2 前缀和带HASH — 复杂度(O(n))
- 用一个值来保存叠加和;
- 用一个map来保存每个叠加和的出现次数,初始值0的value为1;
- 遍历原数组的值,并与叠加值求和,如果该值减去目标值的差值在map中出现过,则count加上map中对应差值的值;
- 最后把该叠加值存放在map中,值加1;
注意:该解法,不管中间过程,只计算个数,所以可以一遍过去计算完成。
2. 模板
2.1 前缀和
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
// 1. 申请一个vector保存叠加和,空间为原数组个数+1;
vector<int> preNums(nums.size() + 1);
int count = 0;
// 2. 计算叠加和放入vector中;
for (int i = 0; i < nums.size(); i++) {
preNums[i + 1] = preNums[i] + nums[i];
}
// 3. 逐步计算vector中的差值,如果等于目标值,count+1;
for (int i = 0; i < nums.size(); i++) {
for (int j = i; j < nums.size(); j++) {
if (preNums[j+1] - preNums[i] == k) {
count++;
}
}
}
return count;
}
};
2.2 前缀和带HASH(推荐)
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
//1. 用一个值来保存叠加和;
int preNum = 0;
int count = 0;
// 2. 用一个map来保存每个叠加和的出现次数,初始值0的value为1;
unordered_map<int, int> preNumFraq;
preNumFraq[0] = 1;
// 3. 遍历原数组的值,并与叠加值求和,如果该值减去目标值的差值在map中出现过,则count加上map中对应差值的值;
// 注意:for循环里的内容要根据具体改!!
for (auto num : nums) {
preNum += num;
if (preNumFraq.count(preNum - k) != 0) {
count += preNumFraq[preNum - k];
}
// 4. 最后把该叠加值存放在map中,值加1;
// 注意:这里的preNum有些题要改!!
preNumFraq[preNum]++;
}
return count;
}
};
3. leetcode例题
560 和为K的子数组:O(n)复杂度解决 中等 前缀和&HASH
974 和可被 K 整除的子数组 中等 前缀和&HASH
四、 差分
1. 套路
1.1 套路1(适用小数据)
- 一般来说,这类题目要算差值;
- 可以先考虑平铺一个数组,作为中间变量,存值;
- 然后再逐个更新该数组,按照题目的要求;
1.2 套路2(适用大数据)
- 也可以用map(这里需要map的顺序)来存放内容;
- 然后逐个比对;
2. 模板
class Solution {
public:
bool carPooling(vector<vector<int>>& trips, int capacity) {
const int TOTAL = 1002;
// 新建一个数组作为中间变量
vector<int> pareVec(TOTAL);
for (auto trip : trips) {
pareVec[trip[1]+1] += trip[0];
pareVec[trip[2]+1] -= trip[0];
}
// 然后对该数组逐个更新,要符合题意,最后得出结果
for (int i = 1; i < TOTAL; i++) {
pareVec[i] += pareVec[i - 1];
if (pareVec[i] > capacity) {
return false;
}
}
return true;
}
};
class Solution {
public:
bool carPooling(vector<vector<int>>& trips, int capacity) {
map<int, int> tripMap;
for (auto trip : trips) {
tripMap[trip[1]] += trip[0];
tripMap[trip[2]] -= trip[0];
}
int res = 0;
int capMax = 0;
for (auto trip : tripMap) {
res += trip.second;
capMax = max(res, capMax);
if (capMax > capacity) {
return false;
}
}
return true;
}
};
3. leetcode例题
1094 拼车 中等 差分
122 买卖股票的最佳时机 II 简单 差分
1109 航班预订统计 中等 差分
253 会议室 II (会员) 中等 会员 差分
五、 排序
1. 套路
1.1 拓扑排序(BFS)
- 识别该类题,看题中元素是否有关联关系;
- 核心思路是以队列为载体,每次把入度为0的元素放入;
- 需要几个数据结构,分别是unordered_map,元素是int和set,存放元素以及后续结点;
- 还需要一个vector存放元素的入度数;
- 然后就是队列来存放入度为0的元素(注意是元素,而不是入度数);
- 每次从队列取值,进行相应操作,从unordered_map,并结合vector找到后续相应元素(入度为0),继续放入队列中,循环从队列取值,直到队列中没值;
2. 模板
2.1 拓扑排序(BFS)
class Solution {
public:
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
unordered_map<int, set<int>> adjTable;
vector<int> inDegree(numCourses, 0);
queue<int> workQueue;
vector<int> res;
if (numCourses <= 0) {
return res;
}
for (auto p : prerequisites) {
if (adjTable.count(p[1]) == 0) {
set<int> newSet;
newSet.insert(p[0]);
adjTable[p[1]] = newSet;
} else {
adjTable[p[1]].insert(p[0]);
}
inDegree[p[0]]++;
}
for (int i = 0; i < inDegree.size(); i++) {
if (inDegree[i] == 0) {
workQueue.push(i);
}
}
int count = 0;
while (!workQueue.empty()) {
int value = workQueue.front();
workQueue.pop();
res.push_back(value);
count++;
for (auto successor : adjTable[value]) {
inDegree[successor]--;
if (inDegree[successor] == 0) {
workQueue.push(successor);
}
}
}
if (count != numCourses) {
vector<int> res1;
return res1;
}
return res;
}
};
3. leetcode例题
210 课程表 II 中等 拓扑排序
444 序列重建 中等 会员 拓扑排序
269 火星词典 困难 会员 拓扑排序
179 最大数 中等 排序+字符串处理(熟练使用c++排序函数)
1305 两棵二叉搜索树中的所有元素 中等 排序+二叉搜索树
1353 最多可以参加的会议数目 中等 排序+贪心
853 车队 中等 排序+遍历
1333 餐厅过滤器 中等 排序
六、 字符串
1. 套路
2. 模板
3. leetcode例题
5 最长回文子串 中等 字符串
93 复原IP地址 中等 字符串
227 基本计算器 II 中等 字符串
七、 DFS
1. 套路
核心思想是基于栈,一直往深度遍历,然后逐步返回得到解
2. 模板
result = []
def backtrack(路径,选择列表):
if 满足结束条件:
result.add(路径)
return;
for 选择 in 选择列表:
做选择
backtrack(路径,选择列表)
撤销选择
3. leetcode例题
八、 BFS
1. 套路
- 核心思想基于队列,一般也是用队列求解;
- 取出一个值,把符合条件的值放入队列尾部,直到队列为空;
2. 模板
int BFS(Node start, Node target) {
Queue<Node> q; // 核心数据结构
Set<Node> visited; // 避免走回头路
q.offer(start); // 将起点加入队列
visited.add(start);
int step = 0; // 记录扩散的步数
while (q not empty) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散 */
for (int i = 0; i < sz; i++) {
Node cur = q.poll();
/* 划重点: 这里判断是否到达终点 */
if (cur is target) {
return step;
}
/* 将cur的相邻节点加入队列 */
for (Node x : cur.adj()) {
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
}
/* 划重点:在这里更新步数 */
step++;
}
}
3. leetcode例题
九、 贪心
1. 套路
- 主要是优先选择,按固定的规律取值(会用到优先队列取最小值);
- 重点思想是把一些值平铺开;
2. 模板
3. leetcode例题
- 1353 最多可以参加的会议数目
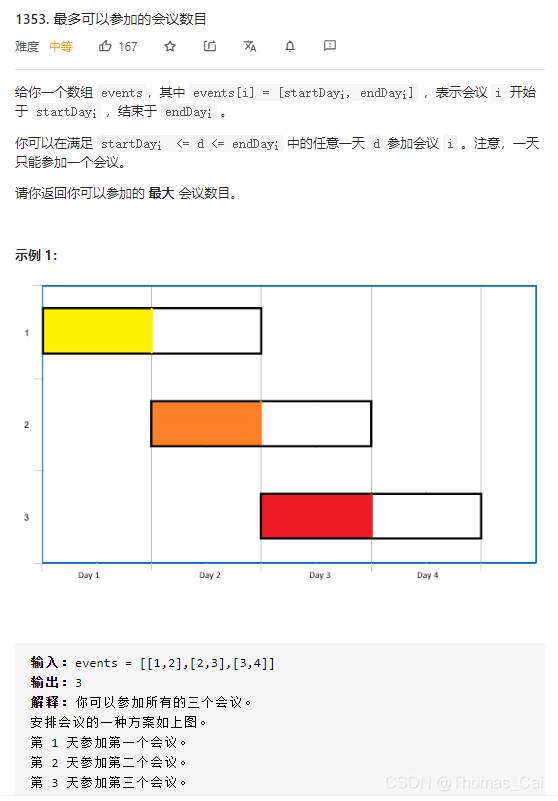
class Solution {
public:
int maxEvents(vector<vector<int>>& events) {
int maxDay = 0;
// 构建一个【开始天】 和 【结束天】的映射
unordered_map<int, vector<int>> day2days;
for (vector<int>& event : events)
{
if (maxDay < event[1])
{
maxDay = event[1];
}
day2days[event[0]].push_back(event[1]);
}
// 记录参见会议的次数
int res = 0;
// 小顶堆队列
priority_queue<int, vector<int>, greater<int>> q;
for (int i = 1; i <= maxDay; ++i)
{
// 增加新的结束时间
if (day2days.find(i) != day2days.end())
{
for (int day : day2days[i])
{
q.push(day);
}
}
// 删除队列里结束时间小于i的会议:因为它们已经结束了,无法再选择
while (!q.empty() && q.top() < i)
{
q.pop();
}
// 直接取最小结束时间会议,次数+1
if (!q.empty())
{
q.pop();
++res;
}
}
return res;
}
};
class Solution:
def maxEvents(self, events: List[List[int]]) -> int:
day_to_days = dict()
max_day = 0
for start, end in events:
day_to_days.setdefault(start, []).append(end)
max_day = max(max_day, end)
q = list()
res = 0
for d in range(1, max_day+1):
if day_to_days.get(d):
for i in day_to_days[d]:
heapq.heappush(q, i)
while len(q) > 0 and q[0] < d:
heapq.heappop(q)
if len(q) > 0:
heapq.heappop(q)
res += 1
return res
class Solution {
public:
int scheduleCourse(vector<vector<int>>& courses) {
sort(courses.begin(), courses.end(), [](const auto& c0, const auto& c1) {
return c0[1] < c1[1];
});
priority_queue<int> q;
// 优先队列中所有课程的总时间
int total = 0;
for (const auto& course: courses) {
int ti = course[0], di = course[1];
if (total + ti <= di) {
total += ti;
q.push(ti);
}
else if (!q.empty() && q.top() > ti) {
total -= q.top() - ti;
q.pop();
q.push(ti);
}
}
return q.size();
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/course-schedule-iii/solution/ke-cheng-biao-iii-by-leetcode-solution-yoyz/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
452 用最少数量的箭引爆气球 中等 贪心
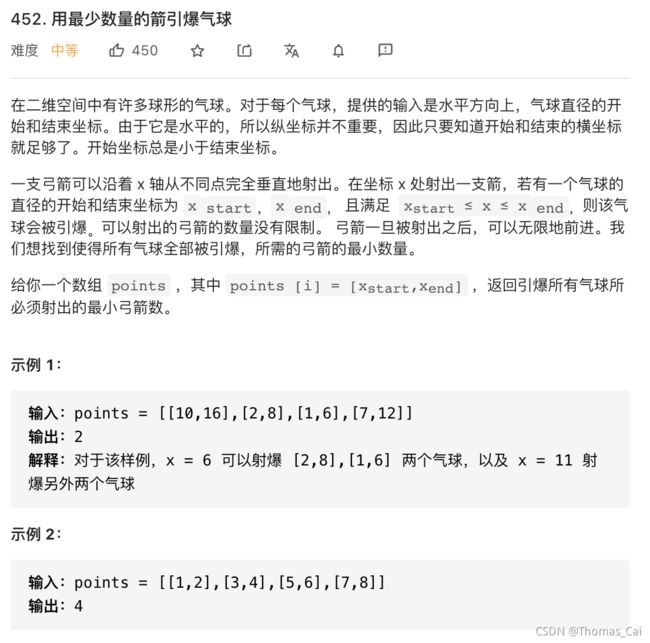
class Solution {
public:
int findMinArrowShots(vector<vector<int>>& points) {
if (points.empty()) {
return 0;
}
sort(points.begin(), points.end(), [](const vector<int> &p1, const vector<int> &p2) {
return p1[1] < p2[1];
});
int pos = points[0][1];
int res = 1;
for (auto point : points) {
if (point[0] > pos) {
pos = point[1];
res++;
}
}
return res;
}
};
376 摆动序列 中等 贪心
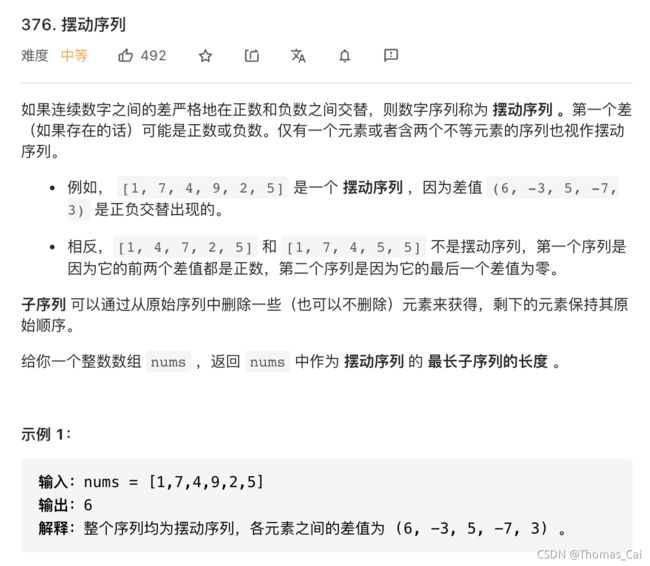
贪心题解:
class Solution {
public:
int wiggleMaxLength(vector<int>& nums) {
if (nums.size() == 1) {
return 1;
}
int preDiff = nums[1] - nums[0];
int res = preDiff != 0 ? 2 : 1;
for (int i = 2; i < nums.size(); i++) {
int currDiff = nums[i] - nums[i - 1];
if ((preDiff >= 0 && currDiff < 0) || (preDiff <= 0 && currDiff > 0)) {
res++;
preDiff = currDiff;
}
}
return res;
}
};
类比:
6066. 统计区间中的整数数目
给你区间的 空 集,请你设计并实现满足要求的数据结构:
新增:添加一个区间到这个区间集合中。
统计:计算出现在 至少一个 区间中的整数个数。
实现 CountIntervals 类:
CountIntervals() 使用区间的空集初始化对象
void add(int left, int right) 添加区间 [left, right] 到区间集合之中。
int count() 返回出现在 至少一个 区间中的整数个数。
注意:区间 [left, right] 表示满足 left <= x <= right 的所有整数 x 。
示例 1:
输入
["CountIntervals", "add", "add", "count", "add", "count"]
[[], [2, 3], [7, 10], [], [5, 8], []]
输出
[null, null, null, 6, null, 8]
解释
CountIntervals countIntervals = new CountIntervals(); // 用一个区间空集初始化对象
countIntervals.add(2, 3); // 将 [2, 3] 添加到区间集合中
countIntervals.add(7, 10); // 将 [7, 10] 添加到区间集合中
countIntervals.count(); // 返回 6
// 整数 2 和 3 出现在区间 [2, 3] 中
// 整数 7、8、9、10 出现在区间 [7, 10] 中
countIntervals.add(5, 8); // 将 [5, 8] 添加到区间集合中
countIntervals.count(); // 返回 8
// 整数 2 和 3 出现在区间 [2, 3] 中
// 整数 5 和 6 出现在区间 [5, 8] 中
// 整数 7 和 8 出现在区间 [5, 8] 和区间 [7, 10] 中
// 整数 9 和 10 出现在区间 [7, 10] 中
提示:
1 <= left <= right <= 109
最多调用 add 和 count 方法 总计 105 次
调用 count 方法至少一次
通过次数2,536提交次数9,939
from sortedcontainers import SortedDict as SD
class CountIntervals:
def __init__(self):
self.mp = SD()
self.cnt = 0
def add(self, left: int, right: int) -> None:
idx = self.mp.bisect_left(left)
n = len(self.mp)
while idx < n and self.mp.values()[idx] <= right:
r, l = self.mp.items()[idx]
left, right = min(left, l), max(r, right)
self.mp.popitem(idx)
n -= 1
self.cnt -= r - l + 1
self.mp[right] = left
self.cnt += right - left + 1
def count(self) -> int:
return self.cnt
# Your CountIntervals object will be instantiated and called as such:
# obj = CountIntervals()
# obj.add(left,right)
# param_2 = obj.count()
知识点:
- SortedDict bisect_left 方法
十、 字典树
1. 套路
2. 模板
首先是手撕前缀树,一个前缀树包括当前的值word以及子节点数组children,这个数组的长度是26。然后就可以利用c++的结构体struct进行构造
struct TrieNode{
string word;
TrieNode* children[26];
//初始化
TrieNode(){
word = "";
//利用memset方法,把children所有元素填充0
memset(children, 0, sizeof(children));
}
};
第二,实现分割字符串的方法,这里返回一个字符串数组,每一个元素是一个单词。
vector<string> Split(string& str){
vector<string> res;
//转化成为stringsteam对象
stringstream ss(str);
string curr;
//使用std::getline方法按照空格分割stringstream对象ss,并把结果存储到curr当中
while(std::getline(ss, curr, ' ')){
if(curr.size() > 0){
res.push_back(curr);
}
}
return res;
}
第三,通过dictionary数组构造前缀树
TrieNode* root = new TrieNode();
for(int i = 0; i < dictionary.size(); i++){
TrieNode* curr = root;
for(char letter: dictionary[i]){
if(curr -> children[letter - 'a'] == NULL){
curr -> children[letter - 'a'] = new TrieNode();
}//不断往下插入字母
curr = curr -> children[letter - 'a'];
}
//直到最后插入一个前缀的所有字母之后,在最后一个节点存储前缀单词名称
curr -> word = dictionary[i];
}
注意是在每一个前缀存储完成之后的节点存储前缀的名称,因为最后的替换操作要求的是最短的满足条件的前缀,因此只要是word 不为空,即说明对当前单词的替换过程要终止了
第四步,替换单词
//首先利用之前实现的split方法,分割字符串
vector<string> words = Split(sentence);
string res;
for(int i = 0; i < words.size(); i++){
TrieNode* curr = root;
for(char letter: words[i]){
//如果没有对应的子节点了,就跳出对words[i]的循环,不对它进行替换
if(curr -> children[letter - 'a'] == NULL){
break;
}
else{
curr = curr -> children[letter - 'a'];
//如果当前节点的前缀不为空了,意味着到达了最短的前缀,此时完成替换过程,跳出当前的循环
if(!curr -> word.empty()){
break;
}
}
}
//除了刚开始,其他的时候在插入字符串之前,都要先插入“ ”
if(!res.empty()) {
res += " ";
}
//如果当前的前缀是空,则说明是没有合适替换的情况,此时不进行替换,直接插入原单词,反之,如果为空,则进行最短前缀的替换
res += (curr -> word.empty())? words[i]: curr -> word;
}
作者:Algorithms_Sustecher
链接:https://leetcode-cn.com/problems/replace-words/solution/c-chao-guo-96-qian-zhui-shu-de-qing-xi-j-3ld7/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
3. leetcode例题
820 单词的压缩编码 中等 字典树
648 单词替换 中等 字典树
208 实现 Trie (前缀树) 中等 字典树
*、 几套题目
406, 358, 316,635