小样本学习
一、基础知识
小样本学习(few shot learning)旨在使用先验知识(prior knowledge)基于有限数量的样本推广(generaling)到新任务(new task)。这些先验(prior knowledge)通常指的是很大规模的训练集,有很多的类和样本,然而在新任务(new task)中的样本(the samples)在这些大规模的训练集上面从来都没有出现过。例如在小样本图像分类中(in few shot image classification),预训练模型只能看到 五个鸟类图像,(一个类有一个图像,并且不存在预训练数据集中)和 预测查询图像中的鸟类类别。
总的来说,小样本学习关注下面两个方面:
1.如何将先验知识嵌入到模型中(使用大规模的数据集进行预训练)
2.如何转移知识以适应新的任务(在少量有标签样本上学习)
小样本学习的一些术语:
训练集(trainning set):在训练集上面,每一个类别有很多样本,这个数据集足够大以训练一个深度神经网络。
支撑集(support set):“Support set”指的是一个小型的带有标签的图像集合,其中所有的类别在训练集中都不存在。
查询集(query set):查询集(Query set)是指一组未标记的图像,用于预测并与支持集(Support set)共享相同的类别。
N way K shot:是一种支撑集设置,它表示支持图像包含N个类别,每个类别有K个样本。
在深度学习中,对于分类任务,一个支持集(support set)中会有NxK个支持图像。
对于检测任务,一个支持集中会有NxK个支持实例,而支持集中的图像数量可以少于NxK。
二、模型评估(evaluation)
小样本图像分类
数据集的类别将会被分为三个互不相交的组:训练集、测试集、验证集。
评估也被叫做元测试,将会从测试集随机采样已经被标注的支持图片和未被标注的查询集图片形成一个任务并且会得到一个预测的在那个任务中查询集的准确率。通常元测试将会重复采样大量的人任务进而得到一个充分的评估,从所有任务中学习到acc的平均值和标准差。
三、配置文件(config)
这段代码是一个深度学习模型的配置文件,主要包括了模型结构、数据预处理、训练参数等信息。
-
模型配置:
type: 模型的类型,这里是Baseline。backbone: 模型的主干网络,这里是Conv4。head: 分类器的头部结构,这里是线性分类器。meta_test_head: 在元测试中使用的分类器头部结构。
-
数据处理管道:
train_pipeline: 训练数据的预处理管道,包括从文件路径加载图片、随机裁剪、随机翻转、颜色增强、归一化等操作。test_pipeline: 测试数据的预处理管道,包括从文件路径加载图片、调整尺寸、中心裁剪、归一化等操作。
-
Fine-tuning的配置:
num_steps: Fine-tuning的迭代次数。optimizer: Fine-tuning使用的优化器配置。
-
数据集配置:
samples_per_gpu: 单个GPU上的batch size。workers_per_gpu: 单个GPU上用于数据预取的worker数。train: 训练集的配置,包括数据集名称、数据集路径前缀和预处理管道等。val: 验证集的配置,用于元测试。test: 测试集的配置,用于模型的验证,与val类似。
-
日志和保存配置:
log_config: 日志打印配置,包括间隔和日志记录器类型。checkpoint_config: 模型保存配置,包括保存间隔。evaluation: 模型评估配置,包括评估间隔和评估指标。
-
分布式训练配置:
dist_params: 分布式训练的后端配置。
-
训练参数配置:
log_level: 日志级别。load_from: 加载预训练模型的路径。resume_from: 恢复训练的断点路径。workflow: 运行流程配置。pin_memory: 是否使用pin memory加速数据传输。use_infinite_sampler: 是否使用无限采样器。seed: 随机种子。runner: 运行器类型和最大训练轮数。optimizer: 优化器配置。optimizer_config: 优化器的其他配置。lr_config: 学习率调整策略配置。
这些配置文件用于构建深度学习模型的训练过程,包括模型结构、数据处理和优化策略等方面的设置。
四、环境配置:
在Ubuntu上查看您的计算机是否支持单个GPU、多个GPU等功能,可以通过以下步骤进行操作:
-
打开终端(Terminal)。
-
使用以下命令查看您的计算机是否具有GPU设备:
lspci | grep -i vga如果输出中包含类似于"NVIDIA Corporation"的字样,则说明您的计算机拥有NVIDIA GPU设备。如果输出为空或没有提及GPU相关信息,则可能是您的计算机不具备独立的GPU设备。
-
如果您的计算机具有GPU设备,您可以使用以下命令查看可用的GPU数量:
nvidia-smi -L此命令将显示每个可用GPU的索引和名称。如果只显示一个GPU,则表示您的计算机只具有一个GPU,如果显示多个GPU,则表示您的计算机有多个GPU可供使用。
-
如果您只有一个GPU,并且希望在单个GPU上运行测试脚本,您可以使用以下命令:
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]请注意,在此命令之前,确保已安装了依赖库和相关软件。
-
如果您的计算机具有多个GPU,并且希望在多个GPU上并行运行测试脚本,您可以使用以下命令:
shell复制代码
sh ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [optional arguments]其中,
${GPU_NUM}是指您要使用的GPU数量。
请根据您的实际情况选择适当的命令和参数来运行测试脚本。
五、常见的小样本模型
在Proto network里面


支撑集与查询集是没有交集的同类的样本的数据。
损失函数:在每一次的迭代过程中更新的目的是,约束支撑集与查询集每一类中圆形的距离,对于同一类的圆形,要使得他们之间的距离要尽可能的小,
距离计算:本文采用的是欧式距离,除了欧氏距离还有余弦距离也别经常用(一个博主证明预先距离出来的实验结果要比欧式距离的结果好)。
思想:类别
六、Baseline++
每次采样都是构建一个元任务的方式构建的,这个支撑集是由n-way-k-shot来构建的(有n个类别,每个类别有k个样本),一般在mini-ImageNet上面都是 5-way-5-shot 或者 5-way-1-shot的。
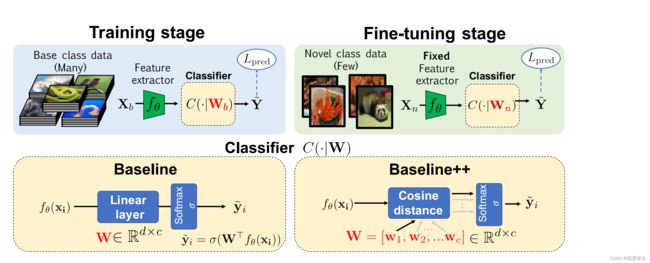
Baseline是标准的线性距离的分类器,而Baseline++换成了余弦距离的分类器。19年之前都是采用的是元学习(比如说miniImageNet上有64个类别的样本,但是每次知识从中选出5个样本进行训练)的思想进行训练的。
训练过程(base class data):将所有的数据放入训练,最后加一个分类器。
微调过程(采用小样本方式测试novel class data):每个类取少量的样本,将特征提取器固定住,

在执行单GPU测试时,您需要按照以下方式填写参数:
{CONFIG_FILE}:配置文件的路径。这是指定模型和测试设置的配置文件。您可以将其替换为实际的配置文件路径。${CHECKPOINT_FILE}:检查点文件的路径。这是指定要加载的模型权重的文件。您可以将其替换为实际的检查点文件路径。[optional arguments]:可选参数。这是一些额外的参数,您可以根据需要添加或省略它们。
请注意,${CONFIG_FILE}和${CHECKPOINT_FILE}是占位符,您需要将它们替换为实际的文件路径。另外,[optional arguments]是一个占位符,表示您可以选择添加其他参数,比如调整批处理大小、设备等。
以下是示例命令的格式:
python tools/test.py path/to/config_file.py path/to/checkpoint.pth --arg1 value1 --arg2 value2
您需要将path/to/config_file.py替换为实际的配置文件路径,path/to/checkpoint.pth替换为实际的检查点文件路径,并根据需要添加/更改其他参数及其值。
请确保您在运行命令之前已经安装了必需的依赖项,并具有正确的环境设置。
七、运行过程中出现的问题:
(1)数据集摆放问题(我本人使用的是一mini ImageNet数据集为模板设置的新数据集摆放),如下:

(2)数据集过小改参数
(3)除了数据集没有问题之外可能包含其他的文件读入到数据集里面,删除即可。
rm -rf .ipynb_checkpoints
find . -name ".ipynb_checkpoints" -exec rm -rf {} \; ## 这个在大文件运行后面就都删了 因为.ipynb_checkpoints是文件夹 需要加-rf循环地删除