Dynamic Convolution:在卷积核上的注意力
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
Dynamic Convolution:在卷积核上的注意力
摘要
轻量级卷积神经网络(CNNs)由于其较低的计算预算限制了CNNs的深度(卷积层数)和宽度(通道数),导致其表示能力有限,从而导致性能下降。 为了解决这个问题,我们提出了动态卷积,一种在不增加网络深度或宽度的情况下增加模型复杂性的新设计。 动态卷积不是每层使用一个卷积核,而是根据依赖于输入的注意力动态聚合多个并行的卷积核。 集合多个核不仅由于卷积核小而计算效率高,而且由于这些核通过注意力以非线性方式聚合而具有更强的表示能力。 通过对最先进的体系结构MobileNetv3-Small简单地使用动态卷积,ImageNet分类的TOP-1精度提高了2.9%,仅增加了4%的Flops,COCO关键点检测的增益达到了2.9AP。
1. Dynamic Convolution
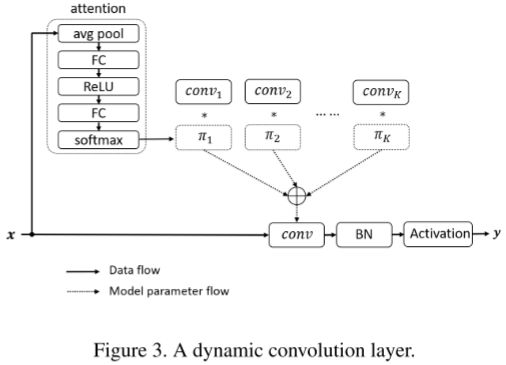
常规卷积对所有实例使用同样的卷积核,这会损害模型对实例的表示能力。为此,如图3所示,本文提出了Dynamic Convolution。与CondConv思想一样:首先创建一个可学习的卷积核库,然后使用路由函数预测每一卷积核的权重,从而得到针对该实例的专门卷积核。具体实现有两点不同:
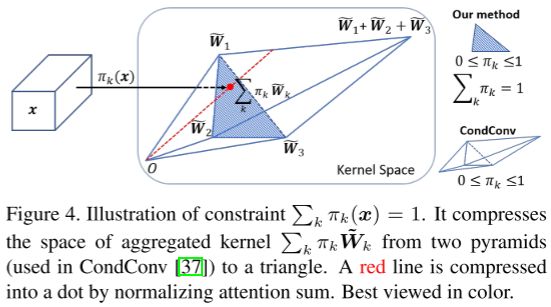
- CondConv仅使用一个简单的全连接层和Sigmoid函数生成权重(这会削弱表达能力),因此本文采用类似SE Layer的操作,激活函数使用Softmax函数(如图4所示,可以约束解空间)。
- 在早期Dynamic Convolution使用几乎均匀的注意力以保证在早期,卷积核库中的卷积核可以有效地更新。这个通过设置Softmax函数的温度参数来实现,早期阶段使用较大的温度,然后进行线性衰减到1。
2. 代码复现
2.1 下载并导入所需要的包
%matplotlib inline
import paddle
import paddle.fluid as fluid
import numpy as np
import matplotlib.pyplot as plt
from paddle.vision.datasets import Cifar10
from paddle.vision.transforms import Transpose
from paddle.io import Dataset, DataLoader
from paddle import nn
import paddle.nn.functional as F
import paddle.vision.transforms as transforms
import os
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
from paddle import ParamAttr
from paddle.nn.layer.norm import _BatchNormBase
import math
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.Resize((130, 130)),
transforms.RandomResizedCrop(128),
transforms.RandomHorizontalFlip(0.5),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
])
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
])
paddle.vision.set_image_backend('cv2')
# 使用Cifar10数据集
train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)
print("train_dataset: %d" % len(train_dataset))
print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000
val_dataset: 10000
batch_size=512
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing
def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss
return loss.mean()
2.4 AlexNet-DY
2.4.1 Dynamic Convolution
class RoutingAttention(nn.Layer):
def __init__(self, inplanes, num_experts, ratio=4, temperature=30, end_epoches=10):
super().__init__()
self.avgpool = nn.AdaptiveAvgPool2D(1)
self.net = nn.Sequential(
nn.Conv2D(inplanes, inplanes//ratio, 1),
nn.ReLU(),
nn.Conv2D(inplanes//ratio, num_experts, 1)
)
self.temperature = temperature
self.step = self.temperature // end_epoches
def update_temperature(self):
if self.temperature > 1:
self.temperature -=self.step
if self.temperature < 1:
self.temperature = 1
return self.temperature
def set_temperature(self, temperature=1):
self.temperature = temperature
return self.temperature
def forward(self, x):
attn=self.avgpool(x)
attn=self.net(attn).reshape((attn.shape[0], -1))
return F.softmax(attn / self.temperature)
class DYConv2D(nn.Layer):
def __init__(self, inplanes, outplanes, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias_attr=True, num_experts=4):
super().__init__()
self.inplanes=inplanes
self.outplanes=outplanes
self.kernel_size=kernel_size
self.stride=stride
self.padding=padding
self.dilation=dilation
self.groups=groups
self.bias=bias_attr
self.num_experts=num_experts
self.routing=RoutingAttention(inplanes=inplanes, num_experts=num_experts)
self.weight=self.create_parameter((num_experts, outplanes, inplanes // groups, kernel_size, kernel_size),
default_initializer=nn.initializer.KaimingNormal()) # num_experts, out, in//g, k, k
if(bias_attr):
self.bias=self.create_parameter((num_experts, outplanes), default_initializer=nn.initializer.KaimingNormal())
else:
self.bias=None
def forward(self, x):
b, c, h, w = x.shape
attn = self.routing(x) # b, num_experts
x = x.reshape((1, -1, h, w)) #由于DY CNN对每一个样本都有不同的权重,因此为了使用F.conv2d,将batch维放入特征C中
weight = paddle.mm(attn, self.weight.reshape((self.num_experts, -1))).reshape(
(-1, self.inplanes//self.groups, self.kernel_size, self.kernel_size)) # b*out, in//g, k, k
if(self.bias is not None):
bias=paddle.mm(attn, self.bias.reshape((self.num_experts, -1))).reshape([-1])
output=F.conv2d(x, weight=weight, bias=bias, stride=self.stride, padding=self.padding, dilation=self.dilation, groups=self.groups * b)
else:
bias=None
output=F.conv2d(x, weight=weight, bias=bias, stride=self.stride, padding=self.padding, dilation=self.dilation, groups=self.groups * b)
output=output.reshape((b, self.outplanes, output.shape[-2], output.shape[-1]))
return output
model = DYConv2D(64, 128, 3, padding=1, stride=2, num_experts=4)
paddle.summary(model, (4, 64, 224, 224))
W0131 21:58:42.897727 396 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0131 21:58:42.901930 396 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
AdaptiveAvgPool2D-1 [[4, 64, 224, 224]] [4, 64, 1, 1] 0
Conv2D-1 [[4, 64, 1, 1]] [4, 16, 1, 1] 1,040
ReLU-5 [[4, 16, 1, 1]] [4, 16, 1, 1] 0
Conv2D-2 [[4, 16, 1, 1]] [4, 4, 1, 1] 68
RoutingAttention-1 [[4, 64, 224, 224]] [4, 4] 0
===============================================================================
Total params: 1,108
Trainable params: 1,108
Non-trainable params: 0
-------------------------------------------------------------------------------
Input size (MB): 49.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 49.01
-------------------------------------------------------------------------------
{'total_params': 1108, 'trainable_params': 1108}
2.4.2 AlexNet-DY
class AlexNet_DY(nn.Layer):
def __init__(self,num_classes=10):
super().__init__()
self.features=nn.Sequential(
nn.Conv2D(3, 48, kernel_size=11, stride=4, padding=11//2),
nn.BatchNorm(48),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3, stride=2),
nn.Conv2D(48, 128, kernel_size=5, padding=2),
nn.BatchNorm(128),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3, stride=2),
DYConv2D(128, 192, kernel_size=3, stride=1, padding=1, num_experts=2),
nn.BatchNorm(192),
nn.ReLU(),
DYConv2D(192, 192, kernel_size=3, stride=1, padding=1, num_experts=2),
nn.BatchNorm(192),
nn.ReLU(),
DYConv2D(192, 128, kernel_size=3, stride=1, padding=1, num_experts=2),
nn.BatchNorm(128),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3, stride=2),
)
self.classifier=nn.Sequential(
nn.Linear(3 * 3 * 128, 2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048, 2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048, num_classes),
)
def forward(self,x):
x = self.features(x)
x = paddle.flatten(x, 1)
x=self.classifier(x)
return x
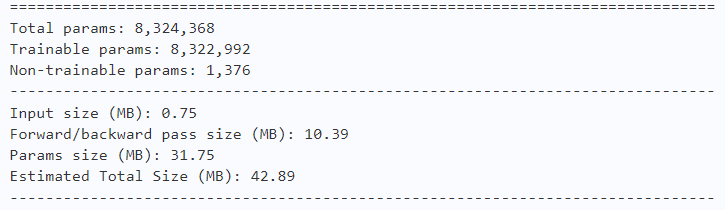
model = AlexNet_DY(num_classes=10)
paddle.summary(model, (4, 3, 128, 128))
2.5 训练
learning_rate = 0.1
n_epochs = 100
paddle.seed(42)
np.random.seed(42)
def init_weight(m):
zeros = nn.initializer.Constant(0)
ones = nn.initializer.Constant(1)
if isinstance(m, (nn.Conv2D, nn.Linear)):
nn.initializer.KaimingNormal(m.weight)
if isinstance(m, nn.BatchNorm2D):
zeros(m.bias)
ones(m.weight)
work_path = 'work/model'
model = AlexNet_DY(num_classes=10)
model.apply(init_weight)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.MultiStepDecay(learning_rate=learning_rate, milestones=[30, 60, 90], verbose=False)
optimizer = paddle.optimizer.SGD(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
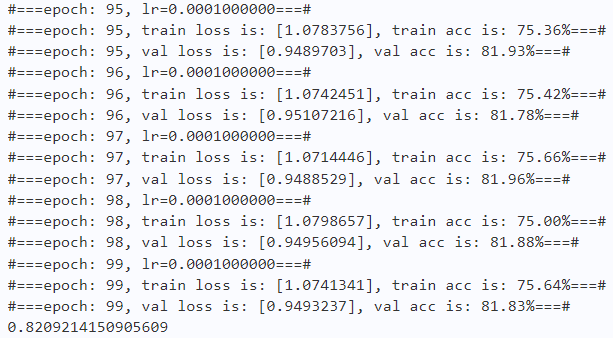
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
scheduler.step()
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
for i in model.features.children():
if isinstance(i, DYConv2D):
i.routing.update_temperature()
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
2.6 实验结果
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
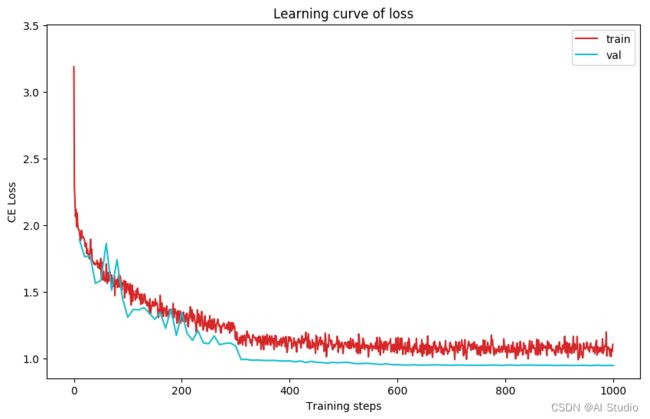
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
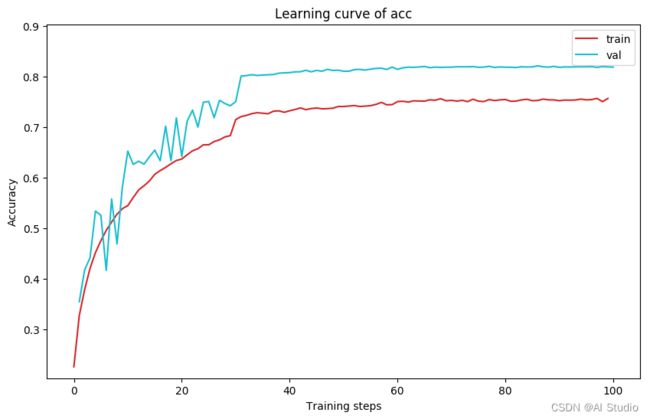
import time
work_path = 'work/model'
model = AlexNet_DY(num_classes=10)
for i in model.features.children():
if isinstance(i, CondConv2D):
i.routing.set_temperature()
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
bb = time.time()
print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:1764
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [
'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog',
'horse', 'ship', 'truck']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if paddle.is_tensor(img):
ax.imshow(img.numpy())
else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
ax.set_title("pt: " + str(pred[i]) + "\ngt: " + str(gt[i]))
return axes
work_path = 'work/model'
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
model = AlexNet_DY(num_classes=10)
for i in model.features.children():
if isinstance(i, CondConv2D):
i.routing.set_temperature()
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
logits = model(X)
y_pred = paddle.argmax(logits, -1)
X = paddle.transpose(X, [0, 2, 3, 1])
axes = show_images(X.reshape((18, 128, 128, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

3. AlexNet
3.1 AlexNet
class AlexNet(nn.Layer):
def __init__(self,num_classes=10):
super().__init__()
self.features=nn.Sequential(
nn.Conv2D(3,48, kernel_size=11, stride=4, padding=11//2),
nn.BatchNorm2D(48),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(48, 128, kernel_size=5, padding=2),
nn.BatchNorm2D(128),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(128, 192, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2D(192),
nn.ReLU(),
nn.Conv2D(192, 192, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2D(192),
nn.ReLU(),
nn.Conv2D(192, 128,kernel_size=3, stride=1, padding=1),
nn.BatchNorm2D(128),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3, stride=2),
)
self.classifier=nn.Sequential(
nn.Linear(3 * 3 * 128, 2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048, 2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048, num_classes),
)
def forward(self,x):
x = self.features(x)
x = paddle.flatten(x, 1)
x=self.classifier(x)
return x
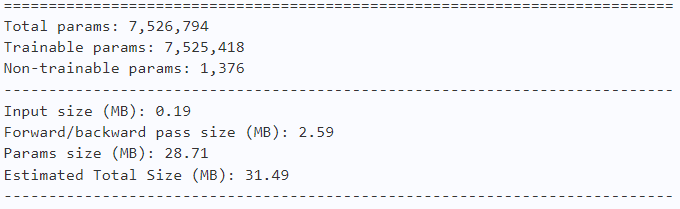
model = AlexNet(num_classes=10)
paddle.summary(model, (1, 3, 128, 128))
3.2 训练
learning_rate = 0.1
n_epochs = 100
paddle.seed(42)
np.random.seed(42)
work_path = 'work/model1'
model = AlexNet(num_classes=10)
model.apply(init_weight)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.MultiStepDecay(learning_rate=learning_rate, milestones=[30, 60, 90], verbose=False)
optimizer = paddle.optimizer.SGD(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record1 = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record1 = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record1['train']['loss'].append(loss.numpy())
loss_record1['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
scheduler.step()
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record1['train']['acc'].append(train_acc)
acc_record1['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record1['val']['loss'].append(total_val_loss.numpy())
loss_record1['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record1['val']['acc'].append(val_acc)
acc_record1['val']['iter'].append(acc_iter)
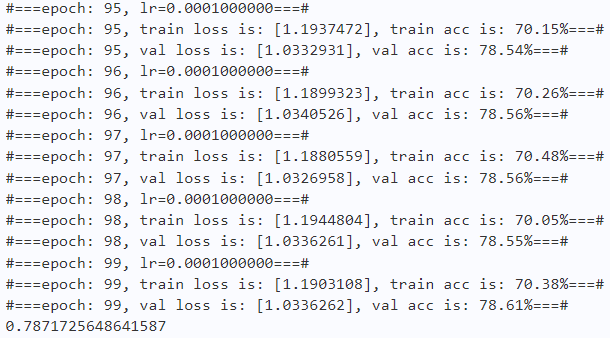
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
3.3 实验结果
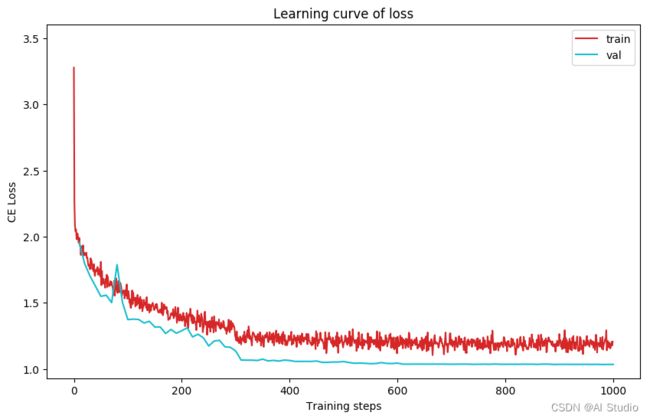
plot_learning_curve(loss_record1, title='loss', ylabel='CE Loss')
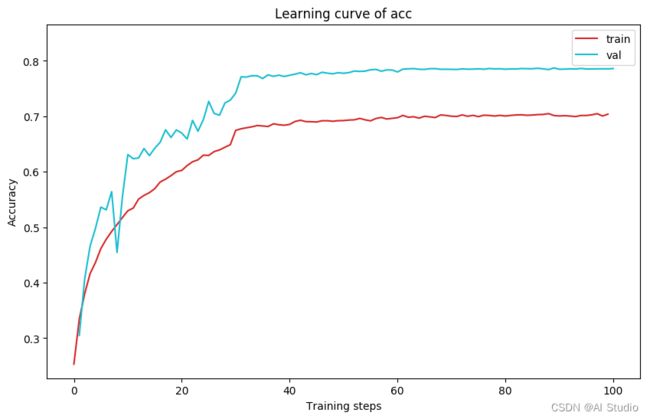
plot_learning_curve(acc_record1, title='acc', ylabel='Accuracy')
##### import time
work_path = 'work/model1'
model = AlexNet(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
bb = time.time()
print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:1822
work_path = 'work/model1'
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
model = AlexNet(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
logits = model(X)
y_pred = paddle.argmax(logits, -1)
X = paddle.transpose(X, [0, 2, 3, 1])
axes = show_images(X.reshape((18, 128, 128, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
with RGB data ([0…1] for floats or [0…255] for integers).

4. 对比实验结果
| Model | Train Acc | Val Acc | Parameter |
|---|---|---|---|
| AlexNet-DY | 0.7515 | 0.8209 | 8324368 |
| AlexNet | 0.7049 | 0.7872 | 7526794 |
总结
Dynamic Convolution在增加少量参数(+0.8M)的同时极大提高网络的性能(+3.3%)
参考文献
论文:Dynamic Convolution: Attention over Convolution Kernels(CVPR 2020)