HBase详解
1、 学HBase的意义是什么
我本想用MySQL来与HBase作比较,但发现他们两者毫无可比性,因为两者运用领域不同,各自有各自的优点,就好比爬山穿登山鞋,潜水穿脚蹼一般。
一门技术的兴起,一个优秀的开源项目的存在肯定是有它所存在的意义,正如大数据一样,正是因为随着时间的发展,随着技术的发展导致我们每天的数据增量达到一个非常庞大的状态,同时在数据之中又能挖掘到很多有用的信息。所以才有了大数据技术的飞速发展。
而学习HBase不仅仅是因为他属于Hadoop生态圈,而且他很特殊;
我想各位在接触HBase之前可能就没有看到过哪个数据库是面向列存储的,我也不知该如何简述他的与众不同,总之我们就沉浸下来,由笔者带各位从下文的学习中深刻体会一下吧。
1.1、引入
HBase是什么
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统;
HBase是Apache的Hadoop项目的子项目;
HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库;
HBase另一个不同的是HBase基于列的而不是基于行的模式;
HBase利用Hadoop的HDFS作为其文件存储系统,利用zookeeper作为其分布式协调服务主要用来存储半结构化或非结构化的松散数据。
1.2、HBase能做什么
海量数据存储:
上百亿行 x 上百万列
并没有列的限制
当表非常大的时候才能发挥这个作用, 最多百万行的话,没有必要放入hbase中
1.3、准实时查询:
百亿行 x 百万列,在百毫秒以内
Hbase在实际场景中的应用
1). 交通方面:
船舶GPS信息,全长江的船舶GPS信息,每天有1千万左右的数据存储
2). 金融方面:
消费信息,贷款信息,信用卡还款信息等
3). 电商:
淘宝的交易信息等,物流信息,浏览信息等
4). 移动:
通话信息等,都是基于HBase的存储
1.4、HBase特点是什么
容量大:
传统关系型数据库,单表不会超过五百万,超过要做分表分库
Hbase单表可以有百亿行、百万列,数据矩阵横向和纵向两个维度所支持的数据量级都非常具有弹性
面向列:
面向列的存储和权限控制,并支持独立检索,可以动态增加列,即,可单独对列进行各方面的操作
列式存储,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,能大大减少读取的数量
多版本:
Hbase的每一个列的数据存储有多个Version,比如住址列,可能有多个变更,所以该列可以有多个version
稀疏性:
为空的列并不占用存储空间,表可以设计的非常稀疏。
不必像关系型数据库那样需要预先知道所有列名然后再进行null填充
拓展性:
底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加datanode节点服务(机器)就可以了
高可靠性:
WAL机制,保证数据写入的时候不会因为集群异常而导致写入数据丢失
Replication机制,保证了在集群出现严重的问题时候,数据不会发生丢失或者损坏
Hbase底层使用HDFS,本身也有备份。
高性能:
底层的LSM数据结构和RowKey有序排列等架构上的独特设计,使得Hbase写入性能非常高。
Region切分、主键索引、缓存机制使得Hbase在海量数据下具备一定的随机读取性能,该性能针对Rowkey的查询能够到达毫秒级别
LSM树,树形结构,最末端的子节点是以内存的方式进行存储的,内存中的小树会flush到磁盘中(当子节点达到一定阈值以后,会放到磁盘中,且存入的过程会进行实时merge成一个主节点,然后磁盘中的树定期会做merge操作,合并成一棵大树,以优化读性能。)
总结:
面向列,容量大,写入比mysql快但是读取没有,超过五百万条数据的话建议读写用Hbase。
2、HBase数据模型
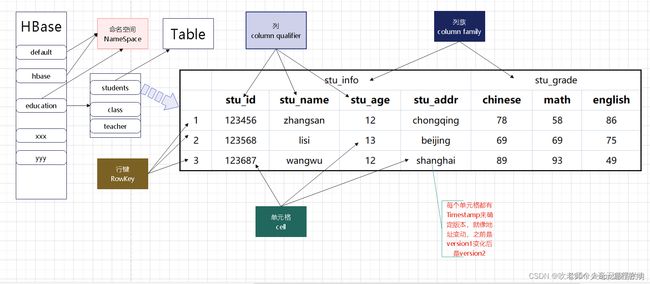
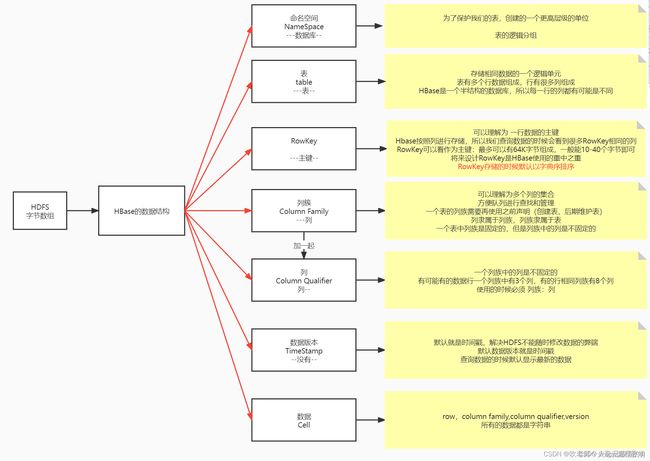
在HBase中有些术语需要提前了解一下:
2.1、NameSpace
命名空间类似于关系型数据库中数据库的概念,它其实是表的逻辑分组。
命名空间是可以管理维护的,可以创建,删除或者更改命名空间
HBase有两个特殊定义的命名空间:
default:没有明确指定命名空间的表将自动划分到此命名空间
hbase:系统命名空间,用于包含HBase内部表
2.2、Table
HBase采用表来组织数据;
他不同于MySQL的是他的表不是单纯由行(记录)列(字段)组成
他的表由RowKey、Colum Family、Colum Qualifier、Timestamp、cell共同构成
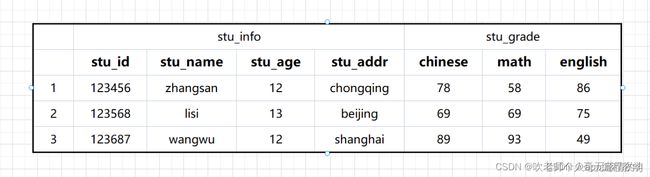
2.3、RowKey
RowKey是用来检索记录的主键,是一行数据的唯一标识
RowKey可以是任意字符串最大长度是64KB,以字节数组保存
存储时,数据按照Row Key的字典序排序,设计RowKey时要充分考虑排序存储这个特性,将经常读取的行存放到一起
2.4、 Colum Family
列族在物理上包含了许多列与列的值,每个列族都有一些存储的属性可配置
将功能相近的列存放到同一个列族中,相同列族中的列会存放在同一个store中
列族一般需要在创建表的时候声明,一般一个表中的列族不超过3个
列隶属于列族,列族隶属于表
2.5、Colum Qualifier
列族的限定词,理解为列的唯一标识。但是列标识是可以改变的,因此每一行会有不同的列标识
使用的时候必须列族:列
列可以根据需求动态添加或删除,同一个表中的不同行的数据列都可以不同
2.6、Timestamp
通过rowkey、columFamily、columqualifier确定一个存储单元通过时间戳来索引
每个cell都保存着同一份数据的多个版本
每个cell中,不同版本的数据按照时间顺序倒叙排序,即最新的数据排到最前面。
为了避免数据存在过多版本中造成管理负担,HBase提供了两种数据版本回收方式
一是存储数据的最后n个版本
二是保存最近一段时间的版本
2.7、cell
Cell是由row columFamily、columQualifier、version组成
cell中数据没有类型,全部是字节码存储的
因为HDFS上的数据是字节数组
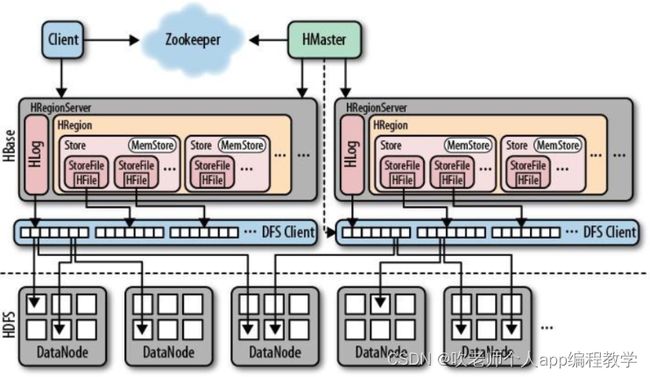
3、HBase架构模型
HBase架构有三个主要组成部分:
客户端(Client)
主服务器(HMaster)
区域服务器(HRegionServer)
3.1、Client
主要功能
客户端负责发送请求到数据库,客户端连接的方式有很多种
hbase shell
类JDBC
client维护着一些cache来加快对hbase的访问,比如regione的位置信息。
发送请求的类型
DDL:数据库定义语言(表的建立,删除,添加删除列族,控制版本)
DML:数据库操作语言(增删改)
DQL:数据库查询语言(查询–全表扫描–基于主键–基于过滤器)
3.2、HMaster
定义
HBase集群的主节点,HMaster也可以实现高可用(active–standby)
通过Zookeeper来维护主副节点的切换
作用
上下线的监督,创建表的时候为Region server分配region并负责Region server的负载均衡
负责接受客户端对table的结构DDL(创建,删除,修改)操作,DML和DQL由其他节点承担
因为HMaster没有联邦机制,业务承载能力有限,而且数据库的表结构很少会变化,大部分都是CRUD操作
表的元数据信息–>Zookeeper上面
表的数据–>HRegionServer上
负责监督HRegionServer的健康状况
当HRegionServer下线的时候,HMaster会将当前HRegionServer上的Region转移到其他的HRegionServer
3.3、 HRegionServer
定义
HBase的具体工作节点(RegionServer属于HBase具体数据的管理者),一般一台主机就是一个RegionServer
作用
一个RegionServer中包含很多HMaster分配给RegionServer的Region,同时RegionServer处理这些Region的IO请求(DML和DQL请求)
当客户端发送DML和DQL操作的时候,HRegionServer负责和客户端建立连接
HRegionServer会实时和HMaster保持心跳,汇报当前节点的信息
当接收到Hmaster命令创建表的时候,分配一个Region对应一张表
Region server负责切分在运行过程中变得过大的region
其他:
当意外关闭的时候,当前节点的Region会被其他HRegionServer管理
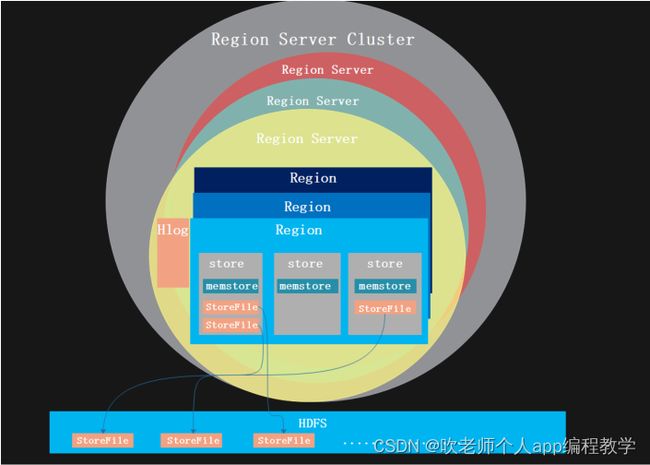
图解 RegionServer、Region、store和storefile之间的关系
3.4、HRegion
定义理解
HRegion是HBase中分布式存储和负载均衡最小单元(HBase的表数据具体存放的位置)
最小单元就表示不同的HRegion可以分布在不同的 HRegion server上。
一个Region只属于一张表,但是一张表可以有多个Region
HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据
Region的平分
最开始声明表的时候就会为这个表默认创建一个Region,一个Region只属于一张表,随着时间的推移Region会越来越大 ,当达到阈值10G时,然后Region会1分为2(逻辑上平分,尽量保证数据的完整性)
切分后的其中一个Region转移到其他的HRegionServer上管理
预分区
当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Regionserver 上。
为了防止前期数据的处理都集中在一个HRegionServer,我们可以根据自己的业务进行预分区
3.5、Store
定义理解
一个表中的一个列族对应一个Store
一个Store里面分为1个MenStore和0或多个StoreFile
HRegion、Store和columns family之间的关系
HRegion是表获取和分布的基本元素,由一个或者多个Store组成,每个store保存一个columns family。
HFile
HFile是Hbase在HDFS中存储数据的格式,它包含多层的索引,这样在Hbase检索数据的时候就不用完全的加载整个文件。
StoreFile存储在HDFS上之后就称为HFile
3.6、StoreFile
定义理解
StoreFile是文件的硬盘存储,直接存到HDFS上,存到HDFS之后被称为HFile
StoreFile是数据存储文件的映射,对应HDFS上的HFile
表、Region、Store、StoreFile之间的关系
一个table对应多个Region,一个Region对应多个Store,一个Store对应一个MEMStore和多个StoreFile,多个StoreFile内部有序,但是外部无序
集群会设置一些阈值,当达到阈值的时候开始将小文件合并成大文件
3.7、MemStore
定义理解
MemStore是基于内存存放数据,每个Store大概分配128M的空间
HFile中并没有任何Block,数据首先存在于MemStore中。Flush发生时,创建HFile Writer
数据最开始优先写入到MemStore,当flush的时候才会被写入到磁盘中(之前在内存中)
默认情况下,一个MemStore的大小为128M,当客户端向数据库插入数据的时候,当内存使用到128M的时候,直接申请128M的内存空间,数据直接写到新内存中,原来已经满的数据写出到HDFS上,称为HFile
MemStore与 Data Block之间的关系
当操作数据的时候,第一个空的Data Block初始化,初始化后的Data Block中为Header部分预留了空间,Header部分用来存放一个Data Block的元数据信息。
位于MemStore中的KeyValues被一个个append到位于内存中的第一个Data Block中
如果配置了Data Block Encoding,则会在Append KeyValue的时候进行同步编码,编码后的数据不再是单纯的KeyValue模式。
Data Block Encoding是HBase为了降低KeyValue结构性膨胀而提供的内部编码机制
3.8、 Hlog
定义理解
HBase的日志机制,WAL(Write After Log)做任何操作之前先写日志,一个HRegionServer只有一个Log文档
日志也会存储到HDFS上,在任何操作之前先记录日志到HDFS,以后MenStore丢失数据或者RegionServer异常都能够通过日志进行恢复一个RegionServer对应的一个Hlog
HLog文件就是一个普通的Hadoop Sequence File,SequeceFile的Key是HLogKey对象
作用
当memStore达到阈值的时候开始写出到文件之后,会在日志中对应的位置标识一个检查点
WAL记录所有的Hbase数据改变,如果一个RegionServer在MemStore进行FLush的时候挂掉了,WAL可以保证数据的改变被应用到。如果写WAL失败了,那么修改数据的完整操作就是失败的。
图解Hlog在整个HBase中的结构
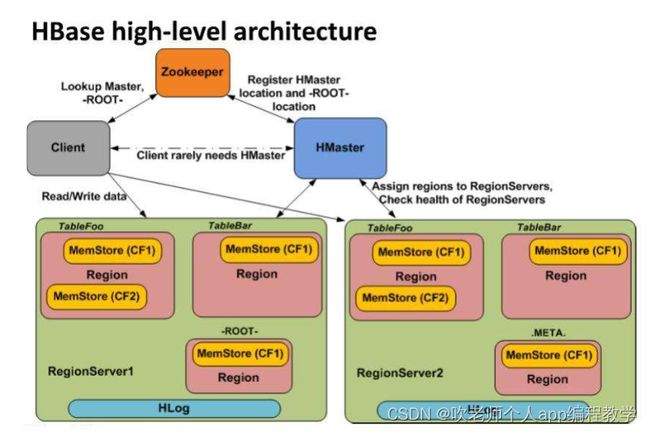
3.9、Zookeeper
定义理解
HBase的协调服务
作用
主备选举与切换
记录当前集群的状态信息,当主备切换的时候,集群的状态可以被新主节点直接读取到
记录当前集群的数据存放信息
存储HBase的元数据信息
4、HBase集群搭建
其实我们搭建了这么多集群总结起来无外乎三步:
解压安装包
配置文件
启动测试
注:在搭建HBase之前,请完成jdk、zookeeper、Hadoop等基础配置,详情可见我之前的文章
Hadoop-HDFS详解与HA,完全分布式集群搭建(细到令人发指的教程)
大数据学前准备–zookeeper详解与集群搭建(保姆级教程)
搭建准备
安装包下载:Index of /hbase https://downloads.apache.org/hbase/
本文示例版本:https://downloads.apache.org/hbase/2.4.14/ Index of /hbase/2.4.14
或者通过wget命令下载
wget https://downloads.apache.org/hbase/1.7.2/hbase-1.7.2-bin.tar.gz # 红色是版本信息,依情景或公司要求自行选择

这里笔者为方便演示,直接上传已经下载好的安装包:hbase-2.4.14-bin.tar.gz
接下来以hbase-2.4.14-bin.tar.gz为例讲解hbase集群模式。
上传安装包并解压
上传后在安装包的目录执行:tar -zxvf hbase-2.4.14-bin.tar.gz -C /opt
5、 集群搭建
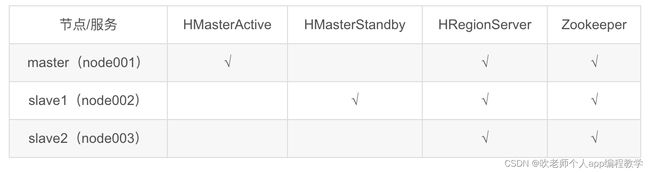
5.1、节点规划
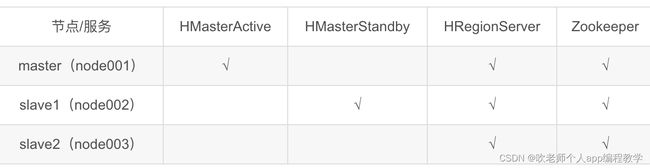
5.2、配置文件
配置hbase环境变量
终端输入:vim /etc/profile
末行加入:
export HBASE_HOME=/opt/hbase-2.4.14
export PATH=$PATH:$HBASE_HOME/bin
重新加载配置文件:source /etc/profile
创建logs目录存放日志文件
[root@node001 ~]# mkdir -p /opt/hbase-2.4.14/logs
hbase-env.sh
终端输入:vim /opt/hbase-2.4.14/conf/hbase-env.sh
末行加入:
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
export HADOOP_HOME=/opt/hadoop-3.1.2
export HBASE_HOME=/opt/hbase-2.4.14
export HBASE_MANAGES_ZK=false #不启动hbase内置的zookeeper集群,因为我们已经搭建了
hbase-site.xml
终端输入:vim /opt/hbase-2.4.14/conf/hbase-site.xml
将configuration中内容修改为:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://bdp/hbase</value>
</property>
<!--配置WEB UI界面-->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<!--超时时间-->
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<!--zookeeper集群配置,如果是集群,则添加其他主机地址-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node001:2181,node002:2181,node003:2181</value>
</property>
<!--hbase数据存放目录,tmp并不是临时文件目录-->
<property>
<name>hbase.tmp.dir</name>
<value>/var/bdp/hbase</value>
</property>
<!--集群或者单机模式,false是单机模式,true是分布式-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--hbase在zookeeper上数据的根目录znode节点-->
<property>
<name>hbase.znode.parent</name>
<value>/hbase</value>
</property>
<!--使用本地文件系统设置为false,使用hdfs设置为true-->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
regionservers
终端输入:vim /opt/hbase-2.4.14/conf/regionservers
去掉localhost加入:
node001
node002
node003
backup-masters(原本没有这个文件)
终端输入:vim /opt/hbase-2.4.14/conf/backup-masters
node002 # 将node002作为备用节点standby
拷贝Hadoop中core-site.xml文件到hbase中
终端输入:scp /opt/hadoop-3.1.2/etc/hadoop/core-site.xml /opt/hbase-2.4.14/conf/
拷贝Hadoop中hdfs-site.xml文件到hbase中
终端输入:scp /opt/hadoop-3.1.2/etc/hadoop/hdfs-site.xml /opt/hbase-2.4.14/conf/
5.3、分发配置文件
拷贝hbase文件
发送hbase到node002节点
终端输入:scp -r /opt/hbase-2.4.14/ node002:/opt/
发送hbase到node003节点
终端输入:scp -r /opt/hbase-2.4.14/ node003:/opt/
拷贝profile文件
发送profile到node002节点
终端输入:scp /etc/profile node002:/etc/
发送profile到node003节点
终端输入:scp /etc/profile node003:/etc/
重新加载配置文件
在node001终端输入:
ssh root@node002 “source /etc/profile” # 重新加载node002 配置文件
ssh root@node003 “source /etc/profile” # 重新加载node0023配置文件
5.4、启动测试
先启动zookeeper集群
三台节点都输入:zkServer.sh start

再启动Hadoop集群
node001输入:start-all.sh
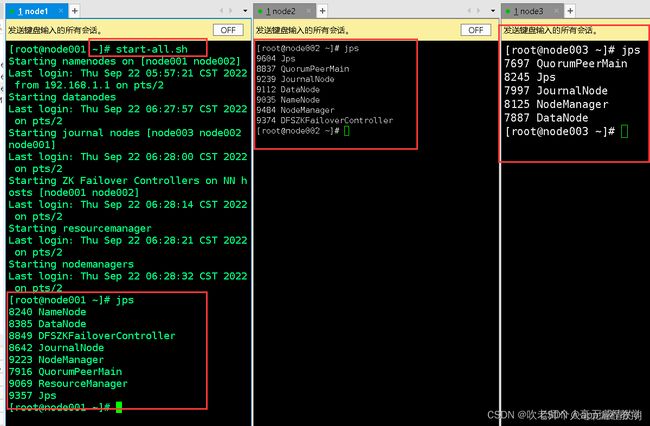
启动HBase集群
node001终端输入:start-hbase.sh
访问web界面
通过hbase-env.sh配置文件中所配置的端口号(60010)访问web界面
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
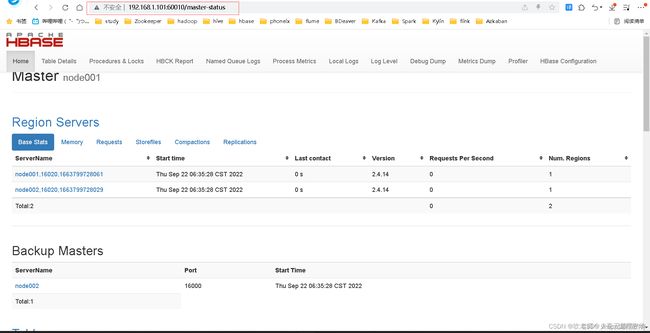
查看日志文件
还记得我们在hbase-env.sh中配置的logs日志文件么
export HBASE_LOG_DIR=${HBASE_HOME}/logs
我们进入这个目录:cd /opt/hbase-2.4.14/logs/
输入:ls 展示一下自动生成的日志文件
在node002,node003节点也生成了他对应的日志文件

所以以后hbase集群有了什么问题可以在这些日志文件中查看。
到此HBase集群搭建完成!记得拍摄快照哟~
6、HBase操作
hbase的操作也类似于MySQL库、表的增删改查等操作
这里罗列一些常用的hbase操作
通过命令:hbase shell进入hbase(hbase集群启动的情况下)
通过help命令查看帮助命令
通过exit命令退出hbase客户端界面
查看服务器状态:status

查看hbase版本:version

6.1、命名空间操作
创建命名空间
语法:create_namespace ‘命名空间名称’
create_namespace ‘test’
查看命名空间
根据命名空间名称查询
describe_namespace ‘test’
在某命名空间中创建表
语法:create ‘命名空间名称:表名’,‘列族’,‘列族’
create ‘test:tab_test’,‘love’,‘you’
6.2、表操作
创建表
# 语法:create 表名,列族1,列组2,...
# 例如:create 'tabname','column_family01','column_family02'
create 'student','info','grade'

现在先不用创建列,列名是后期插入数据时才定义的。
展示表
list:罗列出所有表
hbase:012:0> list
TABLE
student
tab_test
2 row(s)
Took 0.0286 seconds
=> [“student”, “tab_test”]
describe:展示表的详细信息
hbase:013:0> describe 'tab_test'
Table tab_test is ENABLED
tab_test
COLUMN FAMILIES DESCRIPTION
{NAME => 'column_family01', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSION
S => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRES
SION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BL
OCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'column_family02', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSION
S => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRES
SION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BL
OCKSIZE => '65536', REPLICATION_SCOPE => '0'}
2 row(s)
Quota is disabled
Took 0.1754 seconds
6.3、列族
增加列族
语法:alter ‘tablename’,‘column_famaily03’
alter ‘student’,‘class’
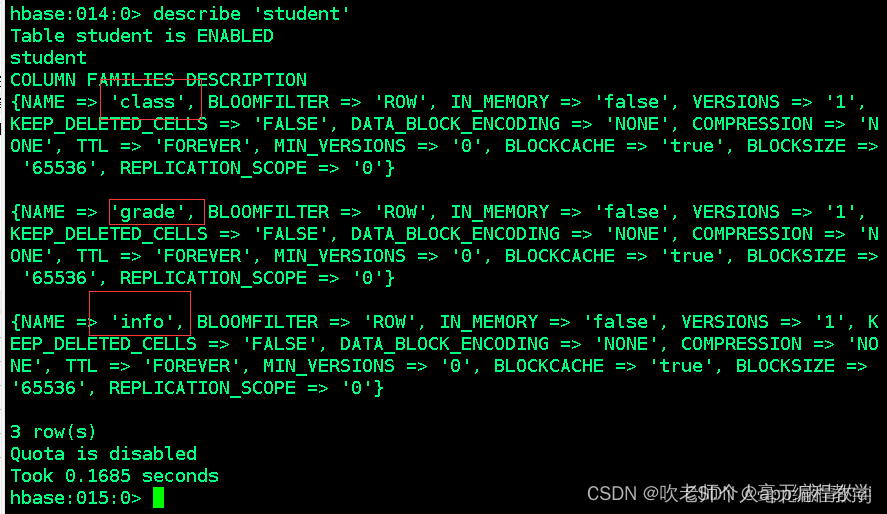
删除列族
语法:alter 表名, ‘delete’ => 列族名
我们删除student表的class列族试试:
alter 'student','delete'=>'class'
alter 'student',{NAME=>'class',METHOD=>'delete'}
hbase:015:0> alter 'student','delete'=>'class'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 2.8162 seconds
hbase:016:0> describe 'student' # 展示student的详细信息,发现class列族已经没有了
Table student is ENABLED
student
COLUMN FAMILIES DESCRIPTION
{NAME => 'grade', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1',
KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'N
ONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE =>
'65536', REPLICATION_SCOPE => '0'}
{NAME => 'info', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', K
EEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NO
NE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE =>
'65536', REPLICATION_SCOPE => '0'}
2 row(s)
Quota is disabled
Took 0.1113 seconds
删除表
表创建成功后,默认状态是enable,即“使用中”的状态,删除表之前需先设置表为“关闭中”。
disable ‘student’
再使用关键字drop删除表
drop ‘student’
对数据的操作
插入(跟新)数据
由于hbase有时间戳版本这一概念,所以跟新操作跟插入操作一样,但是旧数据不会就消失了,旧数据会被当做老版本依旧存放于表中。
语法:put ‘表名’,‘行键’,‘列族:列名’,‘值’
put 'student','student_01','grade:math','82'
put 'student','student_01','grade:english','96'
put 'student','student_01','info:name','lisi'
put 'student','student_01','info:addr','chongqing'
查看数据(get|scan)
语法:
get: 只查看某个行键的数据 get ‘表名’ ,‘行键’
scan:查看表的所有数据 scan ‘表名’
说明:scan全表扫描与get获取到的数据都是目前时间戳最新的数据。
我们如何查看老版本的信息呢:scan时可以设置是否开启RAW模式,开启RAW模式会返回已添加删除标记但是未实际进行删除的数据
语法:scan ‘表名’,{RAW=>true,VERSIONS=>你想展示多少个版本的信息就写几}
scan ‘student’,{RAW=>true,VERSIONS=>2}

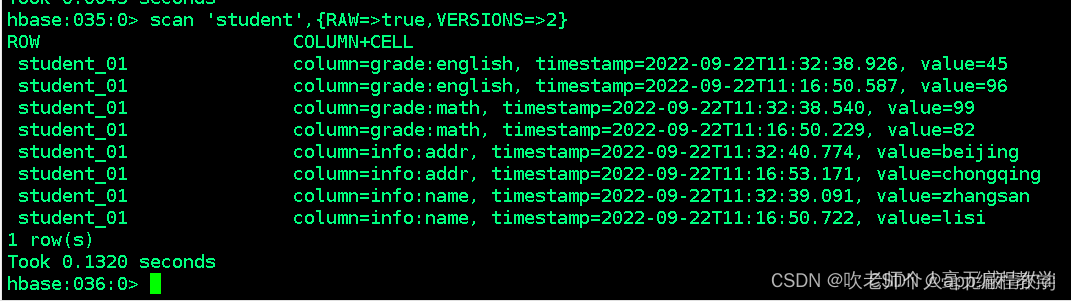
删除一行数据中的列值
delete ‘表名’,‘行键’,‘列族:列名’ # 不指定时间戳的话,默认删除当前最新版本的记录
或deleteall ‘表名’,‘行键’,‘列族:列名’ # 删除指定单元格所有版本的记录
delete ‘student’,‘student_01’,‘info:addr’
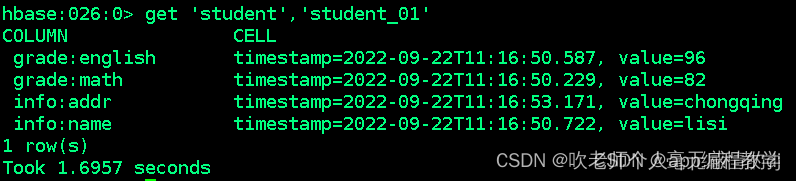
hbase:036:0> get 'student','student_01' # 第一次获取数据,zhangsan的地址是beijing
COLUMN CELL
grade:english timestamp=2022-09-22T11:32:38.926, value=45
grade:math timestamp=2022-09-22T11:32:38.540, value=99
info:addr timestamp=2022-09-22T11:32:40.774, value=beijing
info:name timestamp=2022-09-22T11:32:39.091, value=zhangsan
1 row(s)
Took 0.0510 seconds
hbase:039:0> delete 'student','student_01','info:addr' # 删除掉了新版本的addr记录
Took 0.1579 seconds
hbase:040:0> get 'student','student_01' # 第二次获取数据,zhangsan的地址是chongqing(旧版本)
COLUMN CELL
grade:english timestamp=2022-09-22T11:32:38.926, value=45
grade:math timestamp=2022-09-22T11:32:38.540, value=99
info:addr timestamp=2022-09-22T11:16:53.171, value=chongqing
info:name timestamp=2022-09-22T11:32:39.091, value=zhangsan
1 row(s)
Took 0.0583 seconds
hbase:041:0> delete 'student','student_01','info:addr' # 再次删除掉当前最新版本也就是之前的旧版本chongqing
Took 0.0370 seconds
hbase:042:0> get 'student','student_01' # 由于只存入了两个版本的信息,两条addr的信息都被删除后就,没有数据展示了
COLUMN CELL
grade:english timestamp=2022-09-22T11:32:38.926, value=45
grade:math timestamp=2022-09-22T11:32:38.540, value=99
info:name timestamp=2022-09-22T11:32:39.091, value=zhangsan
1 row(s)
Took 0.0424 seconds
deleteall ‘student’,‘student_01’,‘grade:math’
hbase:048:0> get 'student','student_01'
COLUMN CELL
grade:english timestamp=2022-09-22T11:32:38.926, value=45
grade:math timestamp=2022-09-22T11:32:38.540, value=99
info:name timestamp=2022-09-22T11:32:39.091, value=zhangsan
1 row(s)
Took 0.0599 seconds
hbase:049:0> deleteall 'student','student_01','grade:math' # 一次性删除所有版本的记录
Took 0.0256 seconds
hbase:050:0> get 'student','student_01'
COLUMN CELL
grade:english timestamp=2022-09-22T11:32:38.926, value=45
info:name timestamp=2022-09-22T11:32:39.091, value=zhangsan
1 row(s)
Took 0.0303 seconds
删除一行数据(deleteall)
deleteall ‘表名’,‘行键’
deleteall ‘student’,‘student_01’
6.4、HBase读写流程
写流程
先回顾一下我们的节点规划:
接下来以我们搭建好的hbase集群与我们刚才上文对表的操作来讲讲当我们提交了put ‘student’,‘student_01’,‘grade:math’,'82’命令后hbase到底做了什么(建议初学者将下图着重掌握):
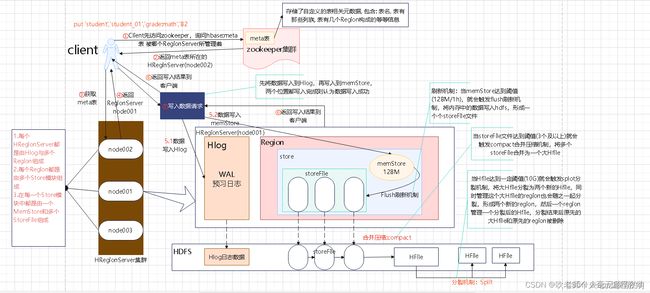
写入流程
由客户端发起写入数据的请求, 首先会先连接zookeeper
从zookeeper中获取 hbase:meta表(meta-region-server)被哪一个个regionServer所管理
我们也可以登录zookeeper客户端(zkCli.sh)后使用命令:get /hbase/meta-region-server 获取meta表存储的信息,如图现在meta表在node002上。
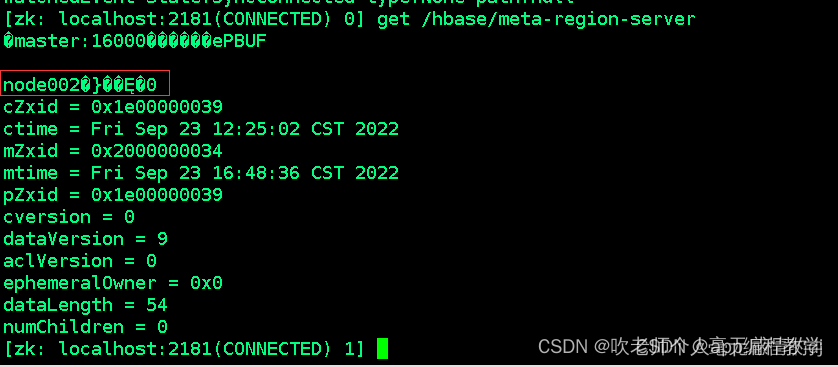
连接meta表对应的RegionServer地址(假设是node001), 从meta表获取当前要写入的表对应region被那个RegionServer所管理(一般只会返回一个RegionServer地址, 除非一次性写入多条数据)
连接对应要写入RegionServer的地址, 开始写入数据, 将数据首先会写入到HLog中,然后将数据写入到对应Region的对应Store模块的MemStore中(有可能会写入到MemStore), 当这两个地方都写入完成后, 客户端认为数据写入完成了(即hbase服务端与客户端的一次交流就结束了)
服务端写入过程: 异步操作(可能客户端执行N多次写入后, 服务端才开始对之前的数据进行操作)
随着客户端不断的写入操作, memstore中数据会越来越多, 当内存中数据达到阈值(128M / 1h)后, 就会触发flush刷新机制, 将数据<最终>刷新到HDFS上形成StoreFile(小Hfile)文件.
随着不断的刷新, 在HDFS上StoreFile文件会越来越多, 当StoreFlie文件数量达到阈值(3个及以上)后, 就会触发compact合并压缩机制, 将多个StoreFlie文件<最终>合并为一个大的HFile文件
随着不断的合并, 大的HFile也会越来越大, 当大HFile达到一定的阈值(<最终>10GB)后, 就会触发Split分裂机制, 将大HFile进行一分为二,形成两个新的大HFile, 同时管理这个大HFile的Region也会形成两个新的Region, 形成的两个新的Region和两个新的大HFile 进行一对一的管理即可, 原来的Region和原来的大的HFile就会下线删除掉。
6.5 、读流程
读取流程
客户端发起读取数据的请求, 首先会先连接zookeeper
从zookeeper中获取一个 hbase:meta表 被那个RegionServer所管理着
连接meta表对应RegionServer, 从meta表获取当前要读取的这个表对应的Region是那些, 并且这些Region对应的RegionServer是谁当表有多个Region的时候: 如果执行的Get操作获取某一条数据, 只会返回一个RegionServer的地址;如果执行的Scan操作, 会将所有的Region对应RegionServer地址全部返回(前三步与写流程差不多)。
连接要读取表对应的RegionServer, 从RegionServer上开始获取数据即可:
读取顺序:
MemStore —> blockCache(缓存) —> StoreFlie(小HFile) —>大HFile
当从后续的文件中读取到数据后, 会将这一部分存储到缓存中
如果执行Scan操作, blockCache基本没有太大意义
————————————————
7、javaAPI访问HBase数据库
org.apache.hbase hbase-client 2.4.5 org.apache.hbase hbase-common 2.4.5 org.apache.hbase hbase-protocol 2.4.5 org.apache.hbase hbase-server 2.4.5 junit junit 4.12在操作之前确保hbase集群正常运行!
编程实现
环境介绍
使用的是IDEA+Maven来进行测试
Maven的pom.xml中hbase依赖如下:
获取所有表
package com.libing.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
/**
* @author liar
* @version 1.0
* @date 2022/9/24 13:48
*/
public class GetAllTableTest {
public static Configuration cfg = HBaseConfiguration.create();
public static Connection conn;
public static void main(String[] args) throws IOException {
cfg.set("hbase.zookeeper.quorum","192.168.1.101:2181,192.168.1.102:2181,192.168.1.103:2181");
//cfg.set("hbase.zookeeper.quorum","node001:2181,node002:2181,node003:2181");
//创建数据库连接
conn = ConnectionFactory.createConnection(cfg);
/**
* Admin 用于管理HBase数据库的表信息
* org.apache.hadoop.hbase.client.Admin是为管理HBase而提供的接口,在Connection
* 实例调用getAdmin()和close()方法期间有效。
*/
Admin admin = conn.getAdmin();
for(TableName name : admin.listTableNames())
{
System.out.println(name);
}
//关闭连接
conn.close();
}
}
注:这里运行报错Caused by: java.net.UnknownHostException: can not resolve node001,16000,1663…的需要在Windows的C:\Windows\System32\drivers\etc\hosts文件中添加对应的域名解析(我也不知道为啥,反正我的加了解决了报错):192.168.1.101 node001
言归正传:
org.apache.hadoop.hbase.client.Admin是为管理HBase而提供的接口,在Connection
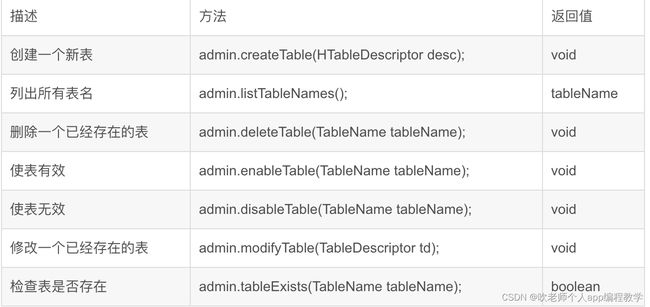
实例调用getAdmin()和close()方法期间有效。使用Admin接口可以实现的主要
HBase Shell命令包括create, list, drop, enable, disable, alter,相应java方法如下表:
创建表
package com.libing.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
/**
* @author liar
* @version 1.0
* @date 2022/9/24 15:16
*/
public class CreateTableTest {
public static Configuration cfg = HBaseConfiguration.create();
public static Connection conn;
public static void main(String[] args) throws IOException {
cfg.set("hbase.zookeeper.quorum","192.168.1.101:2181,192.168.1.102:2181,192.168.1.103:2181");
//创建数据库连接
conn = ConnectionFactory.createConnection(cfg);
/**
* Admin 用于管理HBase数据库的表信息
* org.apache.hadoop.hbase.client.Admin是为管理HBase而提供的接口,在Connection
* 实例调用getAdmin()和close()方法期间有效。
*/
Admin admin = conn.getAdmin();
String tableName = "create_test";
String columFamily1 = "create_test_family1";
String columFamily2 = "create_test_family2";
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
HColumnDescriptor hColumnDescriptor1 = new HColumnDescriptor(columFamily1);
HColumnDescriptor hColumnDescriptor2 = new HColumnDescriptor(columFamily2);
tableDescriptor.addFamily(hColumnDescriptor1).addFamily(hColumnDescriptor2);
admin.createTable(tableDescriptor);
for (TableName tables :admin.listTableNames()) {
System.out.println(tables);
}
//关闭连接
conn.close();
}
}
通过hbase客户端也发现这张表的列族也是按照要求创建好了的。

添加数据
Table接口用于和HBase中的表进行通信,代表了该表的实例,使用Connection的getTable(TableName tableName)方法可以获取该接口的实例,用于获取、添加、删除、扫描HBase表中的数据。
Table接口包含的主要方法如下:

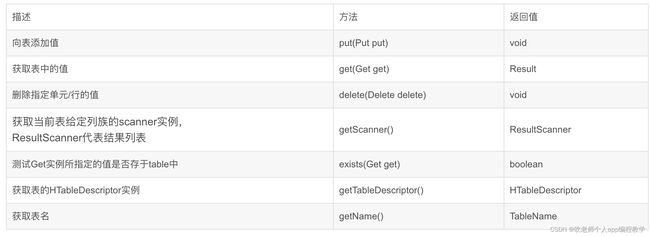
这里不对每一个方法进行展示,不然文章就太臃肿了,读者视情况可以自行测试。
8、HBase常用性能优化
数据库表数据优化
预创建HRegion
默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入HBase时,会按照region分区情况,在集群内做数据的负载均衡。
手动设定预分区
Hbase> create’staff1’,‘info’,‘partition1’,SPLITS =>[‘1000’,‘2000’,‘3000’,‘4000’]
生成 16 进制序列预分区
create ‘staff2’,‘info’,‘partition2’,{NUMREGIONS => 15, SPLITALGO =>‘HexStringSplit’}
按照文件中设置的规则预分区
创建 splits.txt 文件内容如下:
Row Key优化
在HBase中,Row Key可以是任意字符串,最大长度为64KB,实际应用中一般为10~100Bytes,存为byte[]字节数组,一般设计成定长的。Row Key是按照字典顺序存储的,也就是说行键在顺序上接近的数据大概率在物理上是存储在一起的。充分利用这个特性可提高数据查询效率。
生成随机数、 hash 、散列值
字符串反转
字符串拼接
————————————————
列族优化
不要在一张表里定义太多的列族Column Family。目前 HBase并不能很好地处理超过3个列族的表。因为某个列族在刷新缓冲区的时候,它邻近的列族也会因关联效应被触发刷新缓冲区,最终导致系统产生更多的1/O。
版本优化
通过HColumnDescriptor.sctMaxVersions(int maxVersions)设置表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置 setMax Versions( 1)。
数据库读写优化
HBase支持并发读取,为了加快读取数据速度,可以创建多个HTable客户端同时进行读操作,提高吞吐量
Scanner 缓存
调用HTable.setScannerCaching(int scannerCaching)可以设置Hbase扫描一次从服务端抓取的数条数。通过将此值设置成一个合理的值,可以减少扫描过程next()的时间花销,代价是扫描需要通过客户端的内存来维持这些被缓存的行记录。扫描时指定需安的 Coumn Family,可以减少网络传输数据量,否则默认扫描操作会返回整行所有Column family 数据。通过扫描取完数据后,要及时关闭 ResultScanner,否则HRegionServer可能会出现回题(对应的Server资源无法释放)
批量读取
通过调用 HTable.get(Get)方法,可以根据一个指定的Row Key获取一行记录。同样地,HBase 提供了另一个方法:通过调用 HTable.get(List)方法,可以根据指定的Row Key 列表批量获取多行记录。这样做的好处是批量执行,只需要一次网络IO开销,这可能带来明显的性能提升
多线程并发读取
在客户端开启多个 HTable读线程,每个读线程都通过HTable对象进行get 操作
缓存结果查询
对于频繁查询HBase的应用场景,可以考虑在应用程序中进行缓存,当有新的查询请求时首先在缓存中查找,如果存在则直接返回,不再查询HBase;否则对HBase发起读请求查询然后在应用程序中将查询结果缓存起来。至于缓存的替换策略,可以考虑LRU等常用的策略
块缓存
HBase上 HRegionServer 的内存分为两个部分:一部分作为MemStore,主要用来写;另外一部分作为BlockCache,主要用于读。写请求会先写入MemStore,HRegionServer 会给每个HRegion提供一个 MemStore,当MmStore满64MB以后,会清空MemStore并把数据写
9、 HBase参数设置优化
允许在 HDFS 的文件中追加内容
hdfs-site.xml 、 hbase-site.xml
属性:dfs.support.append
解释:开启 HDFS 追加同步,可以优秀的配合 HBase 的数据同步和持久化。默认值为 true
优化 DataNode 允许的最大文件打开数
hdfs-site.xml
属性:dfs.datanode.max.transfer.threads
解释:HBase 一般都会同一时间操作大量的文件,根据集群的数量和规模以及数据动作,
设置为 4096 或者更高。默认值:4096
优化延迟高的数据操作的等待时间
hdfs-site.xml
属性:dfs.image.transfer.timeout
解释:如果对于某一次数据操作来讲,延迟非常高,socket 需要等待更长的时间,建议把
该值设置为更大的值(默认 60000 毫秒),以确保 socket 不会被 timeout 掉
————————————————
优化数据的写入效率
mapred-site.xml
属性:
mapreduce.map.output.compress
mapreduce.map.output.compress.codec
解释:开启这两个数据可以大大提高文件的写入效率,减少写入时间。第一个属性值修改为
true,第二个属性值修改为:org.apache.hadoop.io.compress.GzipCodec 或者其
他压缩方式
设置 RPC 监听数量
hbase-site.xml
属性:Hbase.regionserver.handler.count
解释:默认值为 30,用于指定 RPC 监听的数量,可以根据客户端的请求数进行调整,读写
请求较多时,增加此值
优化 HStore 文件大小
hbase-site.xml
属性:hbase.hregion.max.filesize
解释:默认值 10737418240(10GB),如果需要运行 HBase 的 MR 任务,可以减小此值,因为一个 region 对应一个 map 任务,如果单个 region 过大,会导致 map 任务执行时间过长。该值的意思就是,如果 HFile 的大小达到这个数值,则这个 region 会被切分为两
个 Hfile
优化 HBase 客户端缓存
hbase-site.xml
属性:hbase.client.write.buffer
解释:用于指定 Hbase 客户端缓存,增大该值可以减少 RPC 调用次数,但是会消耗更多内
存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少 RPC 次数的目的
指定 scan.next 扫描 HBase 所获取的行数
hbase-site.xml
属性:hbase.client.scanner.caching
解释:用于指定 scan.next 方法获取的默认行数,值越大,消耗内存越大
flush 、 compact 、 split 机制
当 MemStore 达到阈值,将 Memstore 中的数据 Flush 进 Storefile;compact 机制则是把 flush
出来的小文件合并成大的 Storefile 文件。split 则是当 Region 达到阈值,会把过大的 Region
一分为二。
结语
这篇博客我也是花了很大精力写的,但是难免有错误,希望对文章有意见或建议的朋友可以联系我,我也希望能够听取读者的意见完善自己的文章。
最后,附上一张我在写博客时画的一些图示: