Pandas 多行合并成一行
import pandas as pd
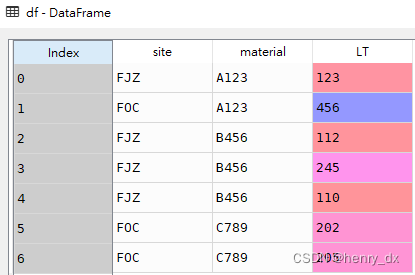
df = pd.DataFrame([['FJZ','A123',123],
['FOC','A123',456],
['FJZ','B456',112],
['FJZ','B456',245],
['FJZ','B456',110],
['FOC','C789',202],
['FOC','C789',205]
],columns=['site','material','LT'])
# 对'site'和'LT'字段进行处理
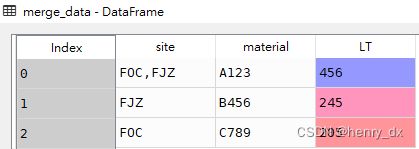
df = df.groupby(['material']).agg({'site':[','.join],'LT':max})
# 更换字段栏位名称
new_column = ['site','LT']
df.columns = new_column另一种解决方案(更优)
import pandas as pd
df = pd.DataFrame([['FJZ','A123',123],
['FOC','A123',456],
['FJZ','B456',112],
['FJZ','B456',245],
['FJZ','B456',110],
['FOC','C789',202],
['FOC','C789',205]
],columns=['site','material','LT'])
df_copy = df.copy()
# 筛选字段'material'并进行去重处理
merge_data = df_copy[['material']]
merge_data = merge_data.drop_duplicates(subset = ['material'])
# 定义拼接函数,并对字段进行去重
def concat_func(row):
return pd.Series({
'site':','.join(map(str,row['site'].unique()))
})
# 对'site'和'LT'字段进行处理
df_copy = df_copy.groupby(df_copy['material']).apply(lambda row:concat_func(row))
merge_data = pd.merge(merge_data, df_copy, how='left', on=['material'])
df_copy = df.copy()
df_copy = df_copy.groupby(df['material']).agg({'LT':max})
merge_data = pd.merge(merge_data, df_copy, how='left', on=['material'])
# 调整字段顺序
order = ['site','material','LT']
merge_data = merge_data[order]扩展补充多行合并成一行操作案例
问题:把多行数据按“姓名”合并,并保留所有信息
import pandas as pd
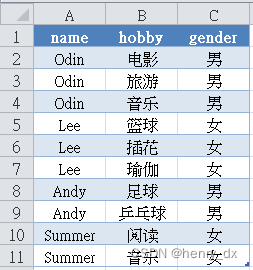
df = pd.DataFrame([['Odin','电影','男'],
['Odin','旅游','男'],
['Odin','音乐','男'],
['Lee','篮球','女'],
['Lee','插花','女'],
['Lee','瑜伽','女'],
['Andy','足球','男'],
['Andy','乒乓球','男'],
['Summer','阅读','女'],
['Summer','音乐','女'],
],columns=['name','hobby','gender'])
# 定义拼接函数,并对字段进行去重
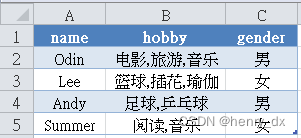
def concat_func(row):
return pd.Series({
'hobby':','.join(row['hobby'].unique()),
'gender':','.join(row['gender'].unique())
})
result = df.groupby(df['name']).apply(lambda row:concat_func(row)).reset_index()问题: 把多行数据按“material”合并,并保留所有信息,其中'site'字段进行去重处理,'usages'字段不进行去重处理

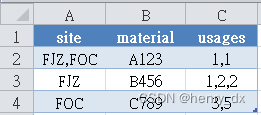
import pandas as pd
df = pd.DataFrame([['FJZ','A123',1],
['FOC','A123',1],
['FJZ','B456',1],
['FJZ','B456',2],
['FJZ','B456',2],
['FOC','C789',3],
['FOC','C789',5]
],columns=['site','material','usages'])
order = ['site','material','usages']
data_new = df[order]
# 定义拼接函数,并对字段进行去重
def concat_func(row):
return pd.Series({
'site':','.join(map(str,row['site'].unique())),
'usages':','.join(map(str,row['usages']))
})
data_new = data_new.groupby(data_new['material']).apply(lambda row:concat_func(row)).reset_index()
# 调整字段栏位顺序
order = ['site','material','usages']
data_new = data_new[order]