ChatGPT App重大进化!能看能听还会说,多模态模型细节同时公布
本文来自微信公众号“量子位 ”(ID:QbitAI),作者:梦晨,景联文科技经授权发布。作
OpenAI连发两则重磅消息,首先ChatGPT可以看、听、说了。

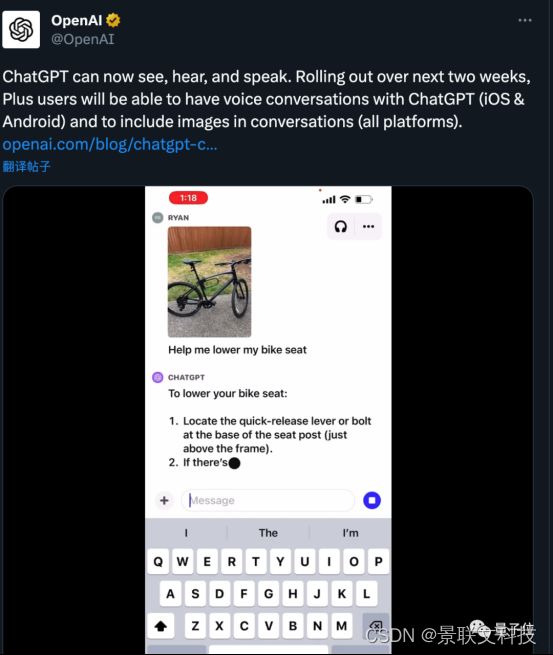
新版ChatGPT开启一种更直观的交互方式,可以向AI展示正在谈论的内容。
比如拍一张照片,询问如何调整自行车座椅高度。
官方还给出另一个实用场景思路:打开冰箱拍一张照片,询问AI晚餐可以吃什么,并生成完整菜谱。
更新将在接下来的两周内向ChatGPT Plus订阅用户和企业版用户推出,iOS和安卓都支持。
与此同时,多模态版GPT-4V模型更多细节也一并放出。
其中最令人惊讶的是,多模态版早在2022年3月就训练完了……

看到这里,有网友灵魂发问:有多少创业公司在刚刚5分钟之内死掉了?
看听说皆备,全新交互方式
更新后的ChatGPT移动APP里,可以直接拍照上传,并针对照片中的内容提出问题。
比如“如何调整自行车座椅高度”,ChatGPT会给出详细步骤。

如果你完全不熟悉自行车结构也没关系,还可以圈出照片的一部分问ChatGPT“说的是这个吗?”。
就像在现实世界中用手给别人指一个东西一样。

不知道用什么工具,甚至可以把工具箱打开拍给ChatGPT,它不光能指出需要的工具在左边,连标签上的文字也能看懂。

提前得到使用资格的用户也分享了一些测试结果。
可以分析自动化工作流程图。
但是没有认出一张剧照具体出自哪部电影。

△认出的朋友欢迎在评论区回复
语音部分的演示还是上周DALL·E 3演示的联动彩蛋。
让ChatGPT把5岁小朋友幻想中的“超级向日葵刺猬”讲成一个完整的睡前故事。

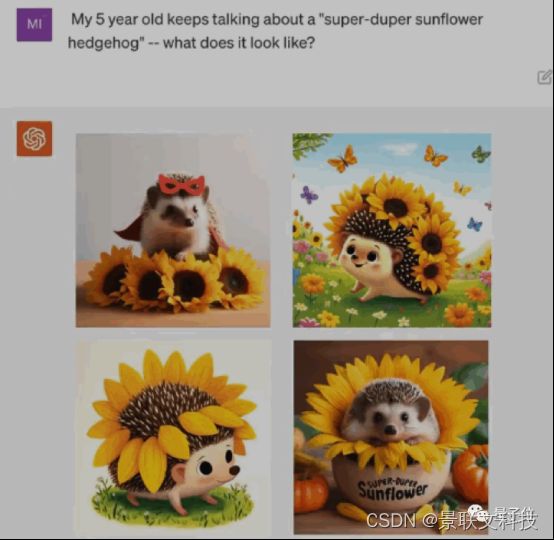
△DALL·E3演示
ChatGPT这次讲的故事文字摘录如下:

过程中更具体的多轮语音交互细节,以及语音试听可参考视频。
多模态GPT-4V能力大揭秘
结合所有公布的视频演示与GPT-4V System Card中的内容,手快的网友已经总结出GPT-4V的视觉能力大揭秘。

物体检测:GPT-4V可以检测和识别图像中的常见物体,如汽车、动物、家居用品等。其物体识别能力在标准图像数据集上进行了评估。
文本识别:该模型具有光学字符识别 (OCR) 功能,可以检测图像中的打印或手写文本并将其转录为机器可读文本。这在文档、标志、标题等图像中进行了测试。
人脸识别:GPT-4V可以定位并识别图像中的人脸。它具有一定的能力,可以根据面部特征识别性别、年龄和种族属性。其面部分析能力是在 FairFace 和 LFW 等数据集上进行测量的。
验证码解决:在解决基于文本和图像的验证码时,GPT-4V显示出了视觉推理能力。这表明该模型具有高级解谜能力。
地理定位:GPT-4V 具有识别风景图像中描绘的城市或地理位置的能力,这证明模型吸收了关于现实世界的知识,但也代表有泄露隐私的风险。
复杂图像:该模型难以准确解释复杂的科学图表、医学扫描或具有多个重叠文本组件的图像。它错过了上下文细节。
同时也总结了GPT-4V目前的局限性。
空间关系:模型可能很难理解图像中对象的精确空间布局和位置。它可能无法正确传达对象之间的相对位置。
对象重叠:当图像中的对象严重重叠时,GPT-4V 有时无法区分一个对象的结束位置和下一个对象的开始位置。它可以将不同的对象混合在一起。
背景/前景:模型并不总是准确地感知图像的前景和背景中的对象。它可能会错误地描述对象关系。
遮挡:当图像中某些对象被其他对象部分遮挡或遮挡时,GPT-4V 可能无法识别被遮挡的对象或错过它们与周围对象的关系。
细节:模型经常会错过或误解非常小的物体、文本或图像中的复杂细节,从而导致错误的关系描述。
上下文推理:GPT-4V缺乏强大的视觉推理能力来深入分析图像的上下文并描述对象之间的隐式关系。
置信度:模型可能会错误地描述对象关系,与图像内容不符。
同时System Card中也重点声明了“目前在科学研究和医疗用途中性能不可靠”。

另外后续还要继续研究,是否应该让模型识别公众人物,是否应该允许模型从人物图像中推断性别、种族或情感等问题。
有网友已经想好,等更新了要问的第一件事是Sam Altman照片的背包里装的是什么。

那么,你想好第一件事问什么了么?