【地震数据处理】GAN网络基础知识
初识GAN网络
- 学习GAN网络的初衷
- 系列文章目录
- 前言
- 一、GAN网络
-
- 1.基本原理
- 2.应用领域
-
- (1)图像处理
- (2)声音处理
- (3)文字生成
- (4)信息破译与信息安全
- (5)生成个性化产物
- 二、CycleGAN网络
-
- 1.基本原理
-
- 单向GAN
- 2.对CG的评价
- 3.应用领域
- 三、Dual GAN网络
学习GAN网络的初衷
在绞尽脑汁写第一篇论文,我对如何打造自己的创新点正头疼不已的时候,畅畅君给我提了一个想法:“最近我们公司说想通过构建GAN网络生成自己的数据,你可以试一试!”。虽然我之前在网上找相关文献时曾经看到过GAN网络的一些介绍,但是由于我最开始没有想过将GAN网络应用到自己的研究领域 并且那时候我已经开始做密集网络没有时间研究其他东西的原因,就这样忽略掉了它。
现在我有了时间和精力,加之在各种博客上了解了一些GAN的知识后,我想最近就开始做把GAN应用于自己领域的研究。但是网上有关GAN的知识点很多,还有很多基于GAN的变种网络。为了避免自己学习的时候逻辑混乱,所以就开始写这么一系列博客。目的是归纳知识,总结经验教训,让后面像我一样的菜鸡有所启发。
系列文章目录
转载:GAN网络合集
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 学习GAN网络的初衷
- 系列文章目录
- 前言
- 一、GAN网络
-
- 1.基本原理
- 2.应用领域
-
- (1)图像处理
- (2)声音处理
- (3)文字生成
- (4)信息破译与信息安全
- (5)生成个性化产物
- 二、CycleGAN网络
-
- 1.基本原理
-
- 单向GAN
- 2.对CG的评价
- 3.应用领域
- 三、Dual GAN网络
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、GAN网络
GAN网络又名生成对抗网络,是近年来比较火热的深度学习模型。Lan Goodfellow在其论文Generative Adversarial Networks中率先提出了GAN,算是这个领域的开山之作。
1.基本原理
GAN网络的基本原理很简单,主要是两个网络起作用: G \textbf{G} G(Generator)和 D \textbf{D} D(Discriminator)。正如它们名字所表示的那样,它们的功能分别是生成和判别。
GAN网络的平面图如下:
训练过程可以理解成由虚线流程转移到实线流程的过程。
这里我们以通过生成图片为例。
- G \textbf{G} G(生成网络): G \textbf{G} G接受一个随机噪声 n \textbf{n} n ,通过噪声生成图片 G(n) \textbf{G(n)} G(n) 。
- D \textbf{D} D(判别网络): D \textbf{D} D判别一张图片是不是“真实的”。其输入是一张图片 x \textbf{x} x,输出 D(x) \textbf{D(x)} D(x)是 x \textbf{x} x为真实图片的概率。一般确定为真实图片为 1 \textbf{1} 1,不可能是真实图片为 0 \textbf{0} 0。
训练过程中, G \textbf{G} G网络会尽量生成真实的图片去欺骗判别网络 D \textbf{D} D。而 D \textbf{D} D网络会尽量把 G \textbf{G} G生成的图片和真实的图片区分开来。通过这样一个动态的博弈过程,最终在最理想的情况下, G \textbf{G} G网络可以生成让 D \textbf{D} D无法区分是否真实的图片 G(n) \textbf{G(n)} G(n)。
通过论文中的公式可以将GAN的核心原理表达如下:
min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ log D(x) ] + E n ∼ p n ( n ) [ 1 − log D(G(n)) ] . \min_{\textbf{G}} \max_{\textbf{D}} V(\textbf{D},\textbf{G}) = E_{\textbf{x}\sim p_{data}(\textbf{x})}[\log{{\textbf{D(x)}}}] + E_{\textbf{n}\sim p_{\textbf{n}}(\textbf{n})}[1-\log{{\textbf{D(G(n))}}}]. GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+En∼pn(n)[1−logD(G(n))].
- x \textbf{x} x表示真实图片, n \textbf{n} n表示输入 G \textbf{G} G网络的噪声, G(n) \textbf{G(n)} G(n)表示 G \textbf{G} G网络生成的图片。
- D(x) \textbf{D(x)} D(x)表示 D \textbf{D} D网络判断真实图片是否真实的概率( x \textbf{x} x为真实图片,对于 D \textbf{D} D来说,这个值应该逼近于 1 \textbf{1} 1)。 D(G(z)) \textbf{D(G(z))} D(G(z))是 D \textbf{D} D网络判断 G \textbf{G} G生成的图片的是否真实的概率。
- G \textbf{G} G希望 D(G(n)) \textbf{D(G(n))} D(G(n))尽可能大,这时 V(D, G) \textbf{V(D, G)} V(D, G)会变小。因此公式的最前面的记号是 min G \min_{G} minG。
- D \textbf{D} D的能力越强, D(x) \textbf{D(x)} D(x)应该越大, D(G(x)) \textbf{D(G(x))} D(G(x))应该越小,这时 V(D,G) \textbf{V(D,G)} V(D,G)会变大。因此公式对于 D \textbf{D} D来说是求 max D \max_{D} maxD
最后我们将会得到一个生成式的模型 G \textbf{G} G,我们可以用它来生成图片。
2.应用领域
从基本原理上看,GAN可以通过不断的自我判别来推导出更真实、更符合训练目的的生成样本。这就给图片、视频等领域带来了极大的想象空间。
当其他 AI 技术还在标榜稳定性、兼容性,以及与多种技术的融合程度时,生成对抗网络却能直截了当地告诉别人它能干什么。综合来看,生成对抗网络至少在以下几个方向上可能提供全新的解决方案。
(1)图像处理
目前网上流传最广的案例,就是通过 GAN 来生成全新图像,其在真实度和准确度上甚至超过了人工作业。在真实工作场景中,为黑白图像上色、通过低清晰度的图片获得高清版本、复原受损图片等都可以运用它来解决。当然这仅仅是生成对抗网络技术的低配版,目前甚至有实验证明了可以用生成对抗网络来把图片变成视频。
(2)声音处理
语音合成一直都是初级 AI 商业化的核心领域。生成对抗网络可以在合成和恢复语音素材中提供重大助力。例如,用 AI 合成语音、从大量杂音中恢复某条音轨,甚至模仿一个人的语速、语气和语言心理,都可以应用生成对抗网络。
(3)文字生成
同样的道理,生成对抗网络在文本生成、写稿机器人等领域也有极大应用空间。AI 创作文字,最大的难关在于机器没有思想和感情,无法表现出人类写作的文本张力。而这些流于字里行间的所谓张力,说不定可以通过GAN来解决。
(4)信息破译与信息安全
既然生成对抗网络的目的是使某物不断趋近真实,那么产生出真实的笔记、密码习惯,甚至生物密码也都是可能的。借助 GAN破译个体习惯来解锁信息,以及提前运用相关技术进行信息安全防护,未来都可能有很大的市场。
(5)生成个性化产物
生成对抗网络的学习方式,是根据一系列数据指标来将样本生成为可被接受的信息。那么,个性化产物的制造其实也在可应用范畴中。
二、CycleGAN网络
CycleGAN又名CG网络,是发表于ICCV17的一篇GAN工作,可以让两个domain的图片互相转化。传统的GAN是单向生成,而CycleGAN是互相生成,网络是个环形,所以命名为Cycle。并且CycleGAN一个非常实用的地方就是输入的两张图片可以是任意的两张图片,也就是unpaired。

1.基本原理
CycleGAN(CG)其实就是一个 A → B A→B A→B 单向GAN 加上一个 B → A B→A B→A 单向GAN。两个GAN共享两个生成器,然后各自带一个判别器,所以加起来总共有两个判别器和两个生成器。一个单向GAN有两个loss,而CycleGAN加起来总共有四个loss。
单向GAN
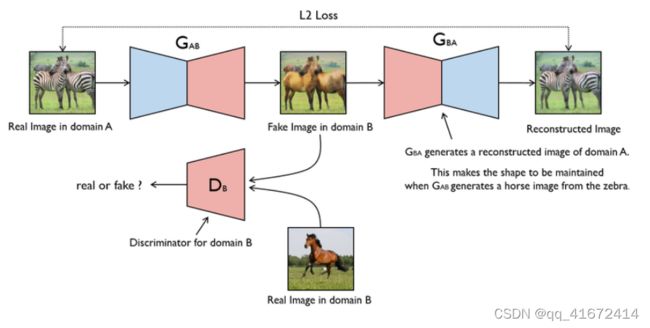
上图是一个单向GAN的示意图。我们希望能够把domain A的图片(命名为 a a a )转化为domain B的图片(命名为图片 b b b)。为了实现这个过程,我们需要两个生成器 G A B \textbf{G}_{AB} GAB 和 G B A \textbf{G}_{BA} GBA ,分别把domain A和domain B的图片进行互相转换。图片A经过生成器 G A B \textbf{G}_{AB} GAB 表示为Fake Image in domain B,用 G A B ( a ) \textbf{G}_{AB}(a) GAB(a)表示。而 G A B ( a ) \textbf{G}_{AB}(a) GAB(a)经过生成器 G B A \textbf{G}_{BA} GBA表示为图片 A A A 的重建图片,用 G B A ( G A B ( a ) ) \textbf{G}_{BA}(\textbf{G}_{AB}(a)) GBA(GAB(a))表示。最后为了训练这个单向GAN需要两个loss,分别是生成器的重建loss和判别器的判别loss。
- 判别loss :
判别器 D B \textbf{D}_B DB是用来判断输入的图片是否是真实的domain B图片。生成的假图片 G A B ( a ) \textbf{G}_{AB}(a) GAB(a)和原始的真图片 b b b都会输入到判别器里面进行判定。最后的loss表示为:
L G A N ( G A B , D B , A , B ) = E b ∼ B [ log D B ( b ) ] + E a ∼ A [ log ( 1 − D B ( G A B ( a ) ) ] L_{GAN}(\textbf{G}_{AB},\textbf{D}_{B},\textbf{A},\textbf{B})=E_{b\sim B}[\log\textbf{D}_{B}(b)]+E_{a\sim A}[\log(1-\textbf{D}_{B}(\textbf{G}_{AB}(a))] LGAN(GAB,DB,A,B)=Eb∼B[logDB(b)]+Ea∼A[log(1−DB(GAB(a))] - 生成loss:
生成器用来重建图片 a a a,目的是希望生成的图片 G B A ( G A B ( a ) ) \textbf{G}_{BA}(\textbf{G}_{AB}(a)) GBA(GAB(a))和原图 a a a尽可能的相似,那么可以很简单的采取 L 1 L_1 L1 loss或者 L 2 L_2 L2 loss。最后生成loss可以表示为:
L ( G A B , D B , A , B ) = E a ∼ A [ ∥ G B A ( G A B ( a ) ) − a ∥ 1 ] L(\textbf{G}_{AB},\textbf{D}_{B},\textbf{A},\textbf{B}) = E_{a\sim A}[\|\textbf{G}_{BA}(\textbf{G}_{AB}(a))-a\|_1] L(GAB,DB,A,B)=Ea∼A[∥GBA(GAB(a))−a∥1]
以上就是 A → B A→B A→B 单向GAN的原理。但是遇到的问题也很典型,就是无论输入是什么,生成器的输出都是同一张图。为了避免发生这样的问题,还需要一个逆向的单向GAN作为补充。
下图是网友自制的CycleGAN网络的剖面图(原贴链接点击此处)。值得注意的是下面的网络不是相互独立、并行的,只是为了方便理解网络所以用两个网络表示。
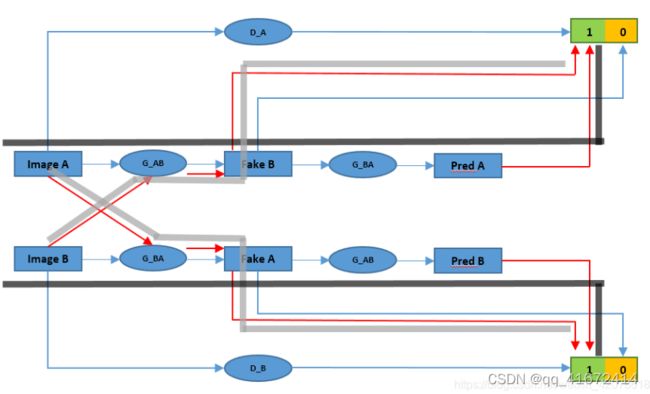
红色的路线,也就是灰色透明袋的路线(一共四条),就是需要训练的网络结构。简洁的说就是需要训练 A − A A-A A−A, A − B − A A-B-A A−B−A, B − B B-B B−B, B − A − B B-A-B B−A−B的四条路线。其中 A − B − A A-B-A A−B−A 和 B − A − B B-A-B B−A−B 两条线能训练处风格迁移的双向过程,即往哪个方向迁都能够做到。 A − A A-A A−A 和 B − B B-B B−B 在我看来,应该算是泛化迁移能力的过程,防止训练的迁移只能对 B B B 迁移到 A A A 或者 A A A 迁移到 B B B 效果比较好,而其他风格难以迁移。
2.对CG的评价
CG的特点就是它能对风格做双向迁移,而pix2pix只能对特定形状的简单图形注意单向风格迁移,从这里看CG确实要比pix2pix优势更加明显一点。
对于卷积神经网络(CNN)来说,个人感觉因为其结构其实已经很成熟了,虽然后面有很多优化方法引入,但是优化结构的趋势已经很不明显了。而GAN网络不一样,还是有非常大的发展空间,还有很多没有发掘的网络结构,相信在未来还会有不小的发展。
3.应用领域
基本都是应用于图片的风格迁移。如下图。
