【RocketMQ】【源码】DLedger选主源码分析
RocketMQ 4.5版本之前,可以采用主从架构进行集群部署,但是如果master节点挂掉,不能自动在集群中选举出新的Master节点,需要人工介入,在4.5版本之后提供了DLedger模式,使用Raft算法,如果Master节点出现故障,可以自动选举出新的Master进行切换。
Raft协议
Raft是分布式系统中的一种共识算法,用于在集群中选举Leader管理集群。Raft协议中有以下角色:
Leader(领导者):集群中的领导者,负责管理集群。
Candidate(候选者):具有竞选Leader资格的角色,如果集群需要选举Leader,节点需要先转为候选者角色才可以发起竞选。
Follower(跟随者 ):Leader的跟随者,接收和处理来自Leader的消息,与Leader之间保持通信,如果通信超时或者其他原因导致节点与Leader之间通信失败,节点会认为集群中没有Leader,就会转为候选者发起竞选,推荐自己成为Leader。
Raft协议中还有一个Term(任期)的概念,任期是随着选举的举行而变化,一般是单调进行递增,比如说集群中当前的任期为1,此时某个节点发现集群中没有Leader,开始发起竞选,此时任期编号就会增加为2,表示进行了新一轮的选举。一般会为Term较大的那个节点进行投票,当某个节点收到了过半Quorum的投票数(一般是集群中的节点数/2 + 1),将会被选举为Leader。
DLedger选主源码分析
在Broker启动的时候,会判断是否开启了DLedger,如果开启会创建角色变更处理器DLedgerRoleChangeHandler, 然后获取CommitLog转为DLedgerCommitLog类型,并添加创建的角色变更处理器:
public class BrokerController {
public boolean initialize() throws CloneNotSupportedException {
result = result && this.consumerOffsetManager.load();
result = result && this.subscriptionGroupManager.load();
result = result && this.consumerFilterManager.load();
if (result) {
try {
this.messageStore = new DefaultMessageStore(this.messageStoreConfig, this.brokerStatsManager, this.messageArrivingListener, this.brokerConfig);
// 如果开启了DLeger
if (messageStoreConfig.isEnableDLegerCommitLog()) {
// 创建DLedgerRoleChangeHandler
DLedgerRoleChangeHandler roleChangeHandler = new DLedgerRoleChangeHandler(this, (DefaultMessageStore) messageStore);
// 获取CommitLog并转为DLedgerCommitLog类型,并添加角色变更处理器DLedgerRoleChangeHandler
((DLedgerCommitLog)((DefaultMessageStore) messageStore).getCommitLog()).getdLedgerServer().getdLedgerLeaderElector().addRoleChangeHandler(roleChangeHandler);
}
// ...
} catch (IOException e) {
result = false;
log.error("Failed to initialize", e);
}
}
// ...
}
}
在DefaultMessageStore构造函数中可以看到,如果开启了DLedger,使用的是DLedgerCommitLog,所以上面可以将CommitLog转换为DLedgerCommitLog:
public class DefaultMessageStore implements MessageStore {
public DefaultMessageStore(final MessageStoreConfig messageStoreConfig, final BrokerStatsManager brokerStatsManager,
//...
// 如果开启DLeger
if (messageStoreConfig.isEnableDLegerCommitLog()) {
this.commitLog = new DLedgerCommitLog(this); // 创建DLedgerCommitLog类型的CommitLog
} else {
this.commitLog = new CommitLog(this);
}
// ...
}
}
进入到DLedgerCommitLog,可以看到它引用了DLedgerServer,并在start方法中对其进行了启动,而在DLedgerServer中又启动了DLedgerLeaderElector进行Leader选举:
// DLedgerCommitLog
public class DLedgerCommitLog extends CommitLog {
// DLedgerServer
private final DLedgerServer dLedgerServer;
@Override
public void start() {
// 启动DLedgerServer
dLedgerServer.startup();
}
}
// DLedgerServer
public class DLedgerServer implements DLedgerProtocolHander {
public void startup() {
this.dLedgerStore.startup();
this.dLedgerRpcService.startup();
this.dLedgerEntryPusher.startup();
// 启动Leader选择
this.dLedgerLeaderElector.startup();
this.executorService.scheduleAtFixedRate(this::checkPreferredLeader, 1000L, 1000L, TimeUnit.MILLISECONDS);
}
}
在DLedgerLeaderElector中,引用了StateMaintainer,并在startup方法中启动了StateMaintainer,然后遍历RoleChangeHandler,调用其startup进行启动:
public class DLedgerLeaderElector {
// 实例化StateMaintainer
private StateMaintainer stateMaintainer = new StateMaintainer("StateMaintainer", logger);
public void startup() {
// 启动StateMaintainer
stateMaintainer.start();
// 遍历RoleChangeHandler
for (RoleChangeHandler roleChangeHandler : roleChangeHandlers) {
// 启动角色变更处理器
roleChangeHandler.startup();
}
}
}
StateMaintainer是DLedgerLeaderElector的内部类,继承了ShutdownAbleThread,所以这里其实是开启了一个线程会不断执行doWork方法,在doWork方法中调用了maintainState方法维护状态:
public class DLedgerLeaderElector {
public class StateMaintainer extends ShutdownAbleThread {
@Override public void doWork() {
try {
if (DLedgerLeaderElector.this.dLedgerConfig.isEnableLeaderElector()) {
DLedgerLeaderElector.this.refreshIntervals(dLedgerConfig);
// 维护状态
DLedgerLeaderElector.this.maintainState();
}
// 睡眠10ms
sleep(10);
} catch (Throwable t) {
DLedgerLeaderElector.logger.error("Error in heartbeat", t);
}
}
}
}
在maintainState方法中,可以看到对节点的角色进行了判断:
- 如果当前节点是Leader,调用
maintainAsLeader方法处理; - 如果当前节点是Follower,调用
maintainAsFollower方法处理; - 如果当前节点是Candidate,调用
maintainAsCandidate方法处理;
public class DLedgerLeaderElector {
private void maintainState() throws Exception {
if (memberState.isLeader()) { // 如果是Leader
maintainAsLeader();
} else if (memberState.isFollower()) { // 如果是Follower
maintainAsFollower();
} else { // 如果是Candidate
maintainAsCandidate();
}
}
}
MemberState中可以看到role的值默认为CANDIDATE,所以初始状态下,各个节点的角色为CANDIDATE,接下来进入到maintainAsCandidate方法看下如何发起选举:
public class MemberState {
// 默认CANDIDATE角色
private volatile Role role = CANDIDATE;
}
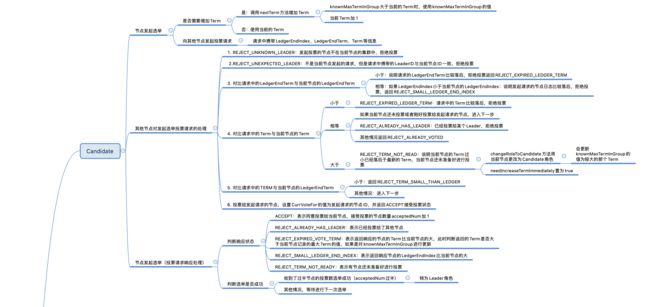
Candidate发起竞选
**needIncreaseTermImmediately:**默认为false,为true时表示需要增加投票轮次Term的值,并立刻发起新一轮选举。
**currTerm:**当前选举的投票轮次。
**LedgerEndIndex:**当前记录的CommitLog日志的index。
**LedgerEndTerm:**Leader节点的投票轮次,也就是最近一次Leader选举成功时的那个Term,会记录在LedgerEndIndex中。
在Candidate候选者角色下可以选举Leader,发起选举的过程如下:
- 判断当时时间是否小于下一次投票开始时间并且
needIncreaseTermImmediately为false,如果未到开始时间并且needIncreaseTermImmediately为false,直接返回,等待下一次投票; - 校验当前角色是否是
Candidate,如果不是直接返回; - 由于Leader选举可能会失败,所以先判断上一次选举的结果,对以下两个条件进行判断,满足两个条件之一,会增加Terem的值,为新一轮竞选做准备,反之使用当前的Term即可:
(1)如果是WAIT_TO_VOTE_NEXT状态,也就是等待下一次重新进行选举;
(2)needIncreaseTermImmediately为true; - 如果
needIncreaseTermImmediately为true,需要重置其状态为false,并调用getNextTimeToRequestVote更新下一次发起选举的时间; - 调用
voteForQuorumResponses方法向其他节点发起投票请求; - 处理投票结果,这里先省略,稍后再讲;
public class DLedgerLeaderElector {
private final MemberState memberState;
private void maintainAsCandidate() throws Exception {
// 判断当时时间是否小于下一次投票开始时间并且needIncreaseTermImmediately为false
if (System.currentTimeMillis() < nextTimeToRequestVote && !needIncreaseTermImmediately) {
return;
}
long term;
long ledgerEndTerm;
long ledgerEndIndex;
synchronized (memberState) {
// 如果不是Candidate直接返回
if (!memberState.isCandidate()) {
return;
}
// 如果上一次选举Leader之后的结果是等待下一下重新进行选举或者如果需要立刻增加任期
if (lastParseResult == VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT || needIncreaseTermImmediately) {
long prevTerm = memberState.currTerm();
term = memberState.nextTerm(); // 增加Term
logger.info("{}_[INCREASE_TERM] from {} to {}", memberState.getSelfId(), prevTerm, term);
lastParseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
} else {
// 使用获取当前的Term
term = memberState.currTerm();
}
// 获取CommitLog日志的index
ledgerEndIndex = memberState.getLedgerEndIndex();
// 获取Leader的投票轮次
ledgerEndTerm = memberState.getLedgerEndTerm();
}
// 如果needIncreaseTermImmediately为true
if (needIncreaseTermImmediately) {
// 更新下次选举的时间
nextTimeToRequestVote = getNextTimeToRequestVote();
// 恢复needIncreaseTermImmediately的默认状态
needIncreaseTermImmediately = false;
return;
}
long startVoteTimeMs = System.currentTimeMillis();
// 发起投票请求
final List<CompletableFuture<VoteResponse>> quorumVoteResponses = voteForQuorumResponses(term, ledgerEndTerm, ledgerEndIndex);
// 处理投票结果,先省略
// ...
}
}
nextTerm
nextTerm方法用于增加投票轮次Term的值,不过在增加之前会先判断当前节点维护的集群中已知的最大Term也就是knownMaxTermInGroup的值是否大于currTerm,如果是则使用knownMaxTermInGroup的值作为下一次投票的轮次,否则才对当前的TermcurrTerm做自增操作:
public class MemberState {
public synchronized long nextTerm() {
// 校验角色
PreConditions.check(role == CANDIDATE, DLedgerResponseCode.ILLEGAL_MEMBER_STATE, "%s != %s", role, CANDIDATE);
// 如果已知集群中最大的Term大于当前的Term,返回集群中最大的Term大
if (knownMaxTermInGroup > currTerm) {
currTerm = knownMaxTermInGroup;
} else {
// 否则对Term自增
++currTerm;
}
currVoteFor = null;
persistTerm(); // 持久化
return currTerm;
}
}
getNextTimeToRequestVote
getNextTimeToRequestVote用于更新下次发起选举的时间,规则为:当前时间 + 300ms + 随机值(在最大和最小投票时间间隔之间也就是300-1000之间生成随机值)。
public class DLedgerLeaderElector {
// 最小投票时间间隔
private int minVoteIntervalMs = 300;
// 最大投票时间间隔
private int maxVoteIntervalMs = 1000;
private long getNextTimeToRequestVote() {
if (isTakingLeadership()) {
return System.currentTimeMillis() + dLedgerConfig.getMinTakeLeadershipVoteIntervalMs() +
random.nextInt(dLedgerConfig.getMaxTakeLeadershipVoteIntervalMs() - dLedgerConfig.getMinTakeLeadershipVoteIntervalMs());
}
// 当前时间 + 300ms + 随机值(在最大和最小投票时间间隔之间也就是300-1000之间生成随机值)
return System.currentTimeMillis() + minVoteIntervalMs + random.nextInt(maxVoteIntervalMs - minVoteIntervalMs);
}
}
发送投票请求
在voteForQuorumResponses方法中,对当前节点维护的集群中所有节点进行了遍历,向每一个节点发送投票请求:
- 构建VoteRequest投票请求;
- 设置组信息、LedgerEndIndex、LedgerEndTerm等信息;
- 设置Leader节点ID,也就是当前发起投票请求的节点的ID;
- 设置本次选举的Term信息;
- 设置请求目标节点的ID;
- 如果是当前节点自己,直接调用
handleVote处理投票,否则调用dLedgerRpcService的vote方法发送投票请求;
public class DLedgerLeaderElector {
private List<CompletableFuture<VoteResponse>> voteForQuorumResponses(long term, long ledgerEndTerm,
long ledgerEndIndex) throws Exception {
List<CompletableFuture<VoteResponse>> responses = new ArrayList<>();
// 遍历节点
for (String id : memberState.getPeerMap().keySet()) {
// 构建投票请求
VoteRequest voteRequest = new VoteRequest();
// 设置组
voteRequest.setGroup(memberState.getGroup());
voteRequest.setLedgerEndIndex(ledgerEndIndex);
voteRequest.setLedgerEndTerm(ledgerEndTerm);
// 设置Leader节点ID
voteRequest.setLeaderId(memberState.getSelfId());
// 设置Term信息
voteRequest.setTerm(term);
// 设置目标节点的ID
voteRequest.setRemoteId(id);
CompletableFuture<VoteResponse> voteResponse;
// 如果是当前节点自己
if (memberState.getSelfId().equals(id)) {
// 直接调用handleVote处理
voteResponse = handleVote(voteRequest, true);
} else {
// 发送请求
voteResponse = dLedgerRpcService.vote(voteRequest);
}
responses.add(voteResponse);
}
return responses;
}
}
投票请求处理
其他节点收到投票请求后,对请求的处理在handleVote方法中:
- 判断发起投票的节点是否在当前节点的集群中,如果不在集群中,拒绝投票,返回状态为
REJECT_UNKNOWN_LEADER; - 如果不是当前节点发起的请求,但是请求中携带的LeaderID与当前节点ID一致,拒绝投票,返回状态为
REJECT_UNEXPECTED_LEADER; - 对比请求中的携带的
LedgerEndTerm与当前节点记录的LedgerEndTerm:
- 小于:说明请求的LedgerEndTerm比较落后,拒绝投票
REJECT_EXPIRED_LEDGER_TERM; - 相等,但是LedgerEndIndex小于当前节点维护的LedgerEndIndex:说明发起请求的节点日志比较落后,拒绝投票,返回
REJECT_SMALL_LEDGER_END_INDEX; - 其他情况:继续下一步;
-
对比请求中的Term与当前节点的Term大小:
- 小于:说明请求中的Term比较落后,拒绝投票返回状态为
REJECT_EXPIRED_LEDGER_TERM; - 相等:如果当前节点还未投票或者刚好投票给发起请求的节点,进入下一步;如果已经投票给某个Leader,拒绝投票返回
REJECT_ALREADY_HAS_LEADER;除此之外其他情况返回REJECT_ALREADY_VOTED; - 大于:说明当前节点的Term过小已经落后于最新的Term,调用
changeRoleToCandidate方法将当前节点更改为Candidate角色,needIncreaseTermImmediately置为true,返回REJECT_TERM_NOT_READY表示当前节点还未准备好进行投票;
调用changeRoleToCandidate方法时传入了请求中携带的Term的值,在方法内会与当前节点已知的最大Term的值knownMaxTermInGroup
做对比,如果knownMaxTermInGroup比请求中的Term小,会更新为请求中的Term的值,在上面maintainAsCandidate方法中可以知道,如果needIncreaseTermImmediately`置为true,会调用nextTerm增加Term,nextTerm方法上面也提到过,这个方法中会判断knownMaxTermInGroup是否大于当前的Term如果是返回knownMaxTermInGroup的值,所以如果当前节点的Term落后于发起选举的Term,不能进行投票,需要在下次更新Term的值后,与发起Leader选举的Term一致时才可以投票; - 小于:说明请求中的Term比较落后,拒绝投票返回状态为
-
如果请求中的TERM小于当前节点的LedgerEndTerm,拒绝投票,返回
REJECT_TERM_SMALL_THAN_LEDGER; -
投票给发起请求的节点,设置CurrVoteFor的值为发起请求的节点ID,并返回ACCEPT接受投票状态;
public CompletableFuture<VoteResponse> handleVote(VoteRequest request, boolean self) {
// 加锁
synchronized (memberState) {
// 判断发起投票的节点是否在当前节点的集群中
if (!memberState.isPeerMember(request.getLeaderId())) {
logger.warn("[BUG] [HandleVote] remoteId={} is an unknown member", request.getLeaderId());
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_UNKNOWN_LEADER));
}
// 如果不是当前节点发起的请求,但是请求中的LeaderID与当前节点一致
if (!self && memberState.getSelfId().equals(request.getLeaderId())) {
logger.warn("[BUG] [HandleVote] selfId={} but remoteId={}", memberState.getSelfId(), request.getLeaderId());
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_UNEXPECTED_LEADER));
}
// 如果请求中的LedgerEndTerm小于当前节点的LedgerEndTerm,说明请求的Term已过期
if (request.getLedgerEndTerm() < memberState.getLedgerEndTerm()) {
// 返回REJECT_EXPIRED_LEDGER_TERM
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_EXPIRED_LEDGER_TERM));
} else if (request.getLedgerEndTerm() == memberState.getLedgerEndTerm() && request.getLedgerEndIndex() < memberState.getLedgerEndIndex()) { // 如果LedgerEndTerm一致但是请求中的LedgerEndIndex小于当前节点的
// 返回REJECT_SMALL_LEDGER_END_INDEX
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_SMALL_LEDGER_END_INDEX));
}
// 如果请求中的TERM小于当前节点的Term
if (request.getTerm() < memberState.currTerm()) {
// 拒绝投票
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_EXPIRED_VOTE_TERM));
} else if (request.getTerm() == memberState.currTerm()) { // 如果请求中的TERM等于当前节点的Term
if (memberState.currVoteFor() == null) { // 如果当前节点还未投票
//let it go
} else if (memberState.currVoteFor().equals(request.getLeaderId())) { // 如果当前节点刚好投票给发起请求的节点
//repeat just let it go
} else {
if (memberState.getLeaderId() != null) { // 如果已经有Leader
// 返回REJECT_ALREADY_HAS_LEADER,表示已投过票
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_ALREADY_HAS_LEADER));
} else { // 拒绝投票
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_ALREADY_VOTED));
}
}
} else {
// 走到这里表示请求中的Term大于当前节点记录的Term
// 当前节点更改为Candidate角色
changeRoleToCandidate(request.getTerm());
// needIncreaseTermImmediately置为true,在下次执行时增加Term
needIncreaseTermImmediately = true;
// 返回REJECT_TERM_NOT_READY
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_TERM_NOT_READY));
}
// 如果请求中的TERM小于当前节点的LedgerEndTerm
if (request.getTerm() < memberState.getLedgerEndTerm()) {
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.getLedgerEndTerm()).voteResult(VoteResponse.RESULT.REJECT_TERM_SMALL_THAN_LEDGER));
}
if (!self && isTakingLeadership() && request.getLedgerEndTerm() == memberState.getLedgerEndTerm() && memberState.getLedgerEndIndex() >= request.getLedgerEndIndex()) {
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_TAKING_LEADERSHIP));
}
// 投票给发起请求的节点
memberState.setCurrVoteFor(request.getLeaderId());
// 返回ACCEPT接收投票的状态
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.ACCEPT));
}
}
处理投票响应结果
回到maintainAsCandidate方法,继续看处理投票结果的部分,给集群中每个节点发起投票请求之后,会等待每个请求返回响应,并进行处理:
ACCEPT:表示同意投票给当前节点,接受投票的节点数量acceptedNum加1;REJECT_ALREADY_VOTED或者REJECT_TAKING_LEADERSHIP:表示拒绝投票给当前节点;REJECT_ALREADY_HAS_LEADER:表示已经投票给了其他节点,alreadyHasLeader设置为true;REJECT_EXPIRED_VOTE_TERM:表示反映响应的节点的Term比当前节点的大,此时判断返回的Term是否大于当前节点记录的最大Term的值,如果是对knownMaxTermInGroup进行更新;REJECT_SMALL_LEDGER_END_INDEX:表示返回响应节点的LedgerEndIndex比当前节点的大,biggerLedgerNum加1;REJECT_TERM_NOT_READY:表示有节点还未准备好进行投票,notReadyTermNum加1;
public class DLedgerLeaderElector {
private void maintainAsCandidate() throws Exception {
// ...
// 发起投票
final List<CompletableFuture<VoteResponse>> quorumVoteResponses = voteForQuorumResponses(term, ledgerEndTerm, ledgerEndIndex);
final AtomicLong knownMaxTermInGroup = new AtomicLong(term);
final AtomicInteger allNum = new AtomicInteger(0);
final AtomicInteger validNum = new AtomicInteger(0);
// 记录接受投票的节点个数
final AtomicInteger acceptedNum = new AtomicInteger(0);
final AtomicInteger notReadyTermNum = new AtomicInteger(0);
final AtomicInteger biggerLedgerNum = new AtomicInteger(0);
// 记录是否有节点投票给了其他节点
final AtomicBoolean alreadyHasLeader = new AtomicBoolean(false);
CountDownLatch voteLatch = new CountDownLatch(1);
// 处理投票响应结果
for (CompletableFuture<VoteResponse> future : quorumVoteResponses) {
future.whenComplete((VoteResponse x, Throwable ex) -> {
try {
if (ex != null) {
throw ex;
}
logger.info("[{}][GetVoteResponse] {}", memberState.getSelfId(), JSON.toJSONString(x));
if (x.getVoteResult() != VoteResponse.RESULT.UNKNOWN) {
validNum.incrementAndGet();
}
synchronized (knownMaxTermInGroup) {
switch (x.getVoteResult()) { // 判断投票结果
case ACCEPT: // 如果接受投票
acceptedNum.incrementAndGet();
break;
case REJECT_ALREADY_VOTED: // 拒绝投票
case REJECT_TAKING_LEADERSHIP:
break;
case REJECT_ALREADY_HAS_LEADER: // 如果已经投票了其他节点
alreadyHasLeader.compareAndSet(false, true);
break;
case REJECT_TERM_SMALL_THAN_LEDGER:
case REJECT_EXPIRED_VOTE_TERM: // 如果响应中的Term大于当前节点发送请求时的Term
// 判断响应中的Term是否大于当前节点已知的最大Term
if (x.getTerm() > knownMaxTermInGroup.get()) {
knownMaxTermInGroup.set(x.getTerm()); // 进行更新
}
break;
case REJECT_EXPIRED_LEDGER_TERM:
case REJECT_SMALL_LEDGER_END_INDEX:// 如果返回响应节点的LedgerEndIndex比当前节点的大
biggerLedgerNum.incrementAndGet();
break;
case REJECT_TERM_NOT_READY: // 如果还未准备好
notReadyTermNum.incrementAndGet();
break;
default:
break;
}
}
if (alreadyHasLeader.get()
|| memberState.isQuorum(acceptedNum.get())
|| memberState.isQuorum(acceptedNum.get() + notReadyTermNum.get())) {
voteLatch.countDown();
}
} catch (Throwable t) {
logger.error("vote response failed", t);
} finally {
allNum.incrementAndGet();
if (allNum.get() == memberState.peerSize()) {
voteLatch.countDown();
}
}
});
}
// 判断投票结果,先省略....
}
}
经过以上处理,等待(2000 + 一个随机数)毫秒之后,接下来判断本次选举是否成功:
- 如果其他节点返回的响应中有比当前节点的Term大的,说明本次选举的Term已经落后其他节点,使用请求中返回的较大的那个Term作为下次竞选的Term,并计算下次发起选举的时间,等待下一次进行选举,对应状态为
WAIT_TO_VOTE_NEXT; - 如果有节点已经投票给了其他节点,说明有其他节点在竞争Leader,需要等待下一次进行选举,对应状态为
WAIT_TO_REVOTE; - 如果收到的有效投票数未过半,等待下一次进行选举,对应状态为
WAIT_TO_REVOTE; - 如果收到有效投票数减去比当前节点ledgerEndIndex大的节点个数未过半,如果走到这一个条件中,说明收到有效投票个数是过半的(如果未过半会先进入条件3),但是其中有些节点的ledgerEndIndex大于当前节点,将这部分减去之后还未过半,意味着本次选举没获得过半的有效投票数不能成功选举,等待下一次进行选举,对应状态为
WAIT_TO_REVOTE; - 如果收到的投票数过半也就是达到了Quorum,本轮选举成功,对应状态
PASS; - 如果接受投票的节点个数+未准备好的节点数过半,表示有部分节点Term落后,与当前选举的Term不一致,立刻进行下一次投票,对应状态为
REVOTE_IMMEDIATELY; - 其他情况,等待下一次投票,对应状态为
WAIT_TO_VOTE_NEXT;
如果进入到第5步,意味着选举成功,此时会调用changeRoleToLeader转为Leader角色:
public class DLedgerLeaderElector {
private void maintainAsCandidate() throws Exception {
// 发起投票
// ...
// 处理投票响应结果
// ...
try {
// 等待
voteLatch.await(2000 + random.nextInt(maxVoteIntervalMs), TimeUnit.MILLISECONDS);
} catch (Throwable ignore) {
}
lastVoteCost = DLedgerUtils.elapsed(startVoteTimeMs);
VoteResponse.ParseResult parseResult;
// 判断投票结果
if (knownMaxTermInGroup.get() > term) { // 1.如果其他节点返回的响应中有比当前节点的Term大的
// 等待下一次选举
parseResult = VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT;
// 计算下次发起选举的时间
nextTimeToRequestVote = getNextTimeToRequestVote();
// 转为Candidate,传入knownMaxTermInGroup,下次会使用knownMaxTermInGroup的值进选举
changeRoleToCandidate(knownMaxTermInGroup.get());
} else if (alreadyHasLeader.get()) {// 2.如果有节点已经投票给了其他节点
parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
// 设置下次选举时间
nextTimeToRequestVote = getNextTimeToRequestVote() + heartBeatTimeIntervalMs * maxHeartBeatLeak;
} else if (!memberState.isQuorum(validNum.get())) { // 3.如果收到的有效投票数未过半
parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
nextTimeToRequestVote = getNextTimeToRequestVote();
} else if (!memberState.isQuorum(validNum.get() - biggerLedgerNum.get())) {// 4.如果收到有效投票数减去比当前节点ledgerEndIndex大的节点个数未过半
parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
nextTimeToRequestVote = getNextTimeToRequestVote() + maxVoteIntervalMs;
} else if (memberState.isQuorum(acceptedNum.get())) {
// 5.投票数如果达到了Quorum,选举通过
parseResult = VoteResponse.ParseResult.PASSED;
} else if (memberState.isQuorum(acceptedNum.get() + notReadyTermNum.get())) {
// 6. 如果接受投票数+未准备好的节点数过半,立刻进行下一次投票
parseResult = VoteResponse.ParseResult.REVOTE_IMMEDIATELY;
} else {
// 7.其他情况,等待下一次投票
parseResult = VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT;
nextTimeToRequestVote = getNextTimeToRequestVote();
}
lastParseResult = parseResult;
logger.info("[{}] [PARSE_VOTE_RESULT] cost={} term={} memberNum={} allNum={} acceptedNum={} notReadyTermNum={} biggerLedgerNum={} alreadyHasLeader={} maxTerm={} result={}",
memberState.getSelfId(), lastVoteCost, term, memberState.peerSize(), allNum, acceptedNum, notReadyTermNum, biggerLedgerNum, alreadyHasLeader, knownMaxTermInGroup.get(), parseResult);
// 如果选举通过
if (parseResult == VoteResponse.ParseResult.PASSED) {
logger.info("[{}] [VOTE_RESULT] has been elected to be the leader in term {}", memberState.getSelfId(), term);
// 选举成功,转为Leader角色
changeRoleToLeader(term);
}
}
}
成为Leadr
节点收到集群中大多数投票后,调用changeRoleToLeader方法转为Leader:
- 调用
changeToLeader方法将角色更改为Leader; - 调用
handleRoleChange方法触发角色变更事件;
public class DLedgerLeaderElector {
public void changeRoleToLeader(long term) {
synchronized(this.memberState) {
// 如果Term一致
if (this.memberState.currTerm() == term) {
// 转为Leader角色
this.memberState.changeToLeader(term);
this.lastSendHeartBeatTime = -1L;
// 触发角色改变事件
this.handleRoleChange(term, Role.LEADER);
logger.info("[{}] [ChangeRoleToLeader] from term: {} and currTerm: {}", new Object[]{this.memberState.getSelfId(), term, this.memberState.currTerm()});
} else {
logger.warn("[{}] skip to be the leader in term: {}, but currTerm is: {}", new Object[]{this.memberState.getSelfId(), term, this.memberState.currTerm()});
}
}
}
}
成为Leader角色之后,下次执行StateMaintainer的doWork方法时,调用DLedgerLeaderElector.this.maintainState()后,会进入到Leader角色的处理逻辑,也就是maintainAsLeader方法中,在方法中会判断上次发送心跳的时间是否大于心跳发送间隔,如果是做如下处理:
- 校验是否是Leader角色,如果不是直接返回;
- 调用
sendHeartbeats方法,向集群中其他节点发送心跳包;
也就是说,如果某个节点成为了Leader角色,会定期执行进入到maintainAsLeader方法中,如果距离上次发送心跳的时间超过了心跳发送间隔,向其他节点发送心跳包保持通信。
public class DLedgerLeaderElector {
private void maintainAsLeader() throws Exception {
// 如果上次发送心跳的时间大于心跳发送间隔
if (DLedgerUtils.elapsed(lastSendHeartBeatTime) > heartBeatTimeIntervalMs) {
long term;
String leaderId;
synchronized (memberState) {
// 校验是否是Leader
if (!memberState.isLeader()) {
return;
}
term = memberState.currTerm();
leaderId = memberState.getLeaderId();
// 更新发送心跳的时间
lastSendHeartBeatTime = System.currentTimeMillis();
}
// 向集群中其他节点发送心跳包
sendHeartbeats(term, leaderId);
}
}
}
计算时间差
DLedgerUtils的elapsed方法用于计算时间差,使用当前时间减去参数传入的时间,后面会看到某些情况下会将上次发送心跳的时间置为-1,这里相减之后,返回值会大于心跳时间间隔,所以会立刻发送心跳包:
public class DLedgerUtils {
public static long elapsed(long start) {
return System.currentTimeMillis() - start;
}
}
发送心跳包
在sendHeartbeats方法中遍历当前节点维护的集群中所有节点,向除自己以外的其他节点发送心跳请求:
- 构建
HeartBeatRequest请求; - 请求中设置本次选举的相关信息,包括组信息、当前节点的ID、目标节点的ID、LeaderID、当前的Term;
- 调用
heartBeat发送心跳请求; - 处理心跳请求返回的响应数据,这个稍后再讲;
public class DLedgerLeaderElector {
private void sendHeartbeats(long term, String leaderId) throws Exception {
final AtomicInteger allNum = new AtomicInteger(1);
final AtomicInteger succNum = new AtomicInteger(1);
final AtomicInteger notReadyNum = new AtomicInteger(0);
final AtomicLong maxTerm = new AtomicLong(-1);
final AtomicBoolean inconsistLeader = new AtomicBoolean(false);
final CountDownLatch beatLatch = new CountDownLatch(1);
long startHeartbeatTimeMs = System.currentTimeMillis();
// 遍历集群中的节点
for (String id : memberState.getPeerMap().keySet()) {
// 如果是当前节点自己,跳过
if (memberState.getSelfId().equals(id)) {
continue;
}
// 构建心跳请求
HeartBeatRequest heartBeatRequest = new HeartBeatRequest();
heartBeatRequest.setGroup(memberState.getGroup()); // 设置组信息
heartBeatRequest.setLocalId(memberState.getSelfId());// 设置当前节点的ID
heartBeatRequest.setRemoteId(id);// 设置目标节点的ID
heartBeatRequest.setLeaderId(leaderId); // 设置LeaderID
heartBeatRequest.setTerm(term); // 设置Term
// 发送心跳请求
CompletableFuture<HeartBeatResponse> future = dLedgerRpcService.heartBeat(heartBeatRequest);
// 先省略心跳响应处理
// ...
}
// ...
}
}
心跳请求处理
lastLeaderHeartBeatTime:最近一次收到Leader心跳请求的时间,用于在Follower角色下判断心跳时间是否超时使用,如果长时间未收到心跳包,会认为Master故障,转为Candidate角色进行竞选。
集群中其他节点收到心跳请求后,对请求的处理在handleHeartBeat方法中:
-
判断发送心跳请求的节点是否在当前节点维护的集群中,如果不在返回状态为
UNKNOWN_MEMBER; -
判断心跳请求中携带的LeaderID是否是当前节点,如果是,返回
UNEXPECTED_MEMBER; -
对比请求中携带的Term与当前节点的Term:
- 小于:返回
EXPIRED_TERM表示请求中的Term已过期; - 相等:如果请求中的LeaderID与当前节点维护的LeaderID一致,表示之前已经同意节点成为Leader,更新收到心跳包的时间
lastLeaderHeartBeatTime为当前时间,返回成功即可;
- 小于:返回
-
再次对比请求中的Term与当前节点的Term:
(1)小于:说明请求的Term已落后,返回EXPIRED_TERM;
(2)相等:
- 如果当前节点记录的LeaderId为空,调用changeRoleToFollower转为Follower角色,返回成功;
- 如果请求中的LeaderId与当前节点的Leader一致,表示之前已经同意节点成为Leader,更新收到心跳包的时间
lastLeaderHeartBeatTime为当前时间,返回成功; - 其他情况:主要是为了容错处理,返回
INCONSISTENT_LEADER;
(3)大于:说明当前节点Term比较落后,此时调用
changeRoleToCandidate转为Candidate角色,然后将needIncreaseTermImmediately置为true,返回TERM_NOT_READY,表示未准备好(与选举投票时的处理逻辑一致);
public class DLedgerLeaderElector {
public CompletableFuture<HeartBeatResponse> handleHeartBeat(HeartBeatRequest request) throws Exception {
// 判断发送心跳请求的节点是否在集群中
if (!memberState.isPeerMember(request.getLeaderId())) {
logger.warn("[BUG] [HandleHeartBeat] remoteId={} is an unknown member", request.getLeaderId());
// 返回UNKNOWN_MEMBER
return CompletableFuture.completedFuture(new HeartBeatResponse().term(memberState.currTerm()).code(DLedgerResponseCode.UNKNOWN_MEMBER.getCode()));
}
// 判断心跳请求中携带的LeaderID是否是当前节点
if (memberState.getSelfId().equals(request.getLeaderId())) {
logger.warn("[BUG] [HandleHeartBeat] selfId={} but remoteId={}", memberState.getSelfId(), request.getLeaderId());
// 返回UNEXPECTED_MEMBER
return CompletableFuture.completedFuture(new HeartBeatResponse().term(memberState.currTerm()).code(DLedgerResponseCode.UNEXPECTED_MEMBER.getCode()));
}
// 对比Term
if (request.getTerm() < memberState.currTerm()) { // 请求中的Term如果小于当前节点的Term
// 返回EXPIRED_TERM表示请求中的Term已过期
return CompletableFuture.completedFuture(new HeartBeatResponse().term(memberState.currTerm()).code(DLedgerResponseCode.EXPIRED_TERM.getCode()));
} else if (request.getTerm() == memberState.currTerm()) { // 如果相等
// 如果请求中的LeaderID与当前节点维护的LeaderID一致,表示已经同意节点成为Leader
if (request.getLeaderId().equals(memberState.getLeaderId())) {
// 更新为当前时间
lastLeaderHeartBeatTime = System.currentTimeMillis();
// 返回成功
return CompletableFuture.completedFuture(new HeartBeatResponse());
}
}
synchronized (memberState) {
// 请求中的Term如果小于当前节点的Term
if (request.getTerm() < memberState.currTerm()) {
// 返回EXPIRED_TERM
return CompletableFuture.completedFuture(new HeartBeatResponse().term(memberState.currTerm()).code(DLedgerResponseCode.EXPIRED_TERM.getCode()));
} else if (request.getTerm() == memberState.currTerm()) { // 请求中的Term于当前节点的Term相等
if (memberState.getLeaderId() == null) { // 如果当前节点记录的LeaderId为空
// 转为Follower角色
changeRoleToFollower(request.getTerm(), request.getLeaderId());
// 返回成功
return CompletableFuture.completedFuture(new HeartBeatResponse());
} else if (request.getLeaderId().equals(memberState.getLeaderId())) { // 如果请求中的LeaderId与当前节点的Leader一致
lastLeaderHeartBeatTime = System.currentTimeMillis();
// 返回成功
return CompletableFuture.completedFuture(new HeartBeatResponse());
} else {
logger.error("[{}][BUG] currTerm {} has leader {}, but received leader {}", memberState.getSelfId(), memberState.currTerm(), memberState.getLeaderId(), request.getLeaderId());
// 返回INCONSISTENT_LEADER
return CompletableFuture.completedFuture(new HeartBeatResponse().code(DLedgerResponseCode.INCONSISTENT_LEADER.getCode()));
}
} else { // 如果请求中的Term大于当前节点的Term
// 转为Candidate
changeRoleToCandidate(request.getTerm());
// needIncreaseTermImmediately置为true
needIncreaseTermImmediately = true;
// 返回TERM_NOT_READY
return CompletableFuture.completedFuture(new HeartBeatResponse().code(DLedgerResponseCode.TERM_NOT_READY.getCode()));
}
}
}
}
心跳响应结果处理
回到sendHeartbeats方法,当请求返回响应之后,会对返回响应状态进行判断:
SUCCESS:表示成功,记录心跳发送成功的节点个数,succNum加1;EXPIRED_TERM:表示当前节点的Term已过期落后于其他节点,将较大的那个Term记录在maxTerm中;INCONSISTENT_LEADER:将inconsistLeader置为true;TERM_NOT_READY:表示有节点还未准备好,也就是Term较小,此时记录未准备节点的数量,notReadyNum加1;
接下来根据上面的处理结果进行判断:
- 如果集群中过半节点对心跳包返回了成功的状态,更新心跳包成功的时间lastSendHeartBeatTime的值;
- 如果未过半进行以下判断:
- 如果成功的个数+未准备好的个数过半,lastSendHeartBeatTime值置为-1,下次进入maintainAsLeader方法会认为已经超过心跳发送时间间隔,所以会立刻发送心跳包;
- 如果maxTerm值大于当前节点的Term,表示当前节点Term已过期,调用changeRoleToCandidate转为Candidate,并使用maxTerm做为下次选举的Term,等待下次选举;
- inconsistLeader为true,调用changeRoleToCandidate转为Candidate,等待下次选举;
- 如果上次成功发送心跳的时间大于maxHeartBeatLeak(最大心跳时间) * heartBeatTimeIntervalMs(心跳发送间隔),调用changeRoleToCandidate转为Candidate,等待下次选举;
public class DLedgerLeaderElector {
private void sendHeartbeats(long term, String leaderId) throws Exception {
final AtomicInteger allNum = new AtomicInteger(1);
final AtomicInteger succNum = new AtomicInteger(1);
final AtomicInteger notReadyNum = new AtomicInteger(0);
final AtomicLong maxTerm = new AtomicLong(-1);
final AtomicBoolean inconsistLeader = new AtomicBoolean(false);
final CountDownLatch beatLatch = new CountDownLatch(1);
long startHeartbeatTimeMs = System.currentTimeMillis();
// 遍历集群中的节点
for (String id : memberState.getPeerMap().keySet()) {
// 如果是当前节点自己,跳过
if (memberState.getSelfId().equals(id)) {
continue;
}
// 构建心跳请求
HeartBeatRequest heartBeatRequest = new HeartBeatRequest();
heartBeatRequest.setGroup(memberState.getGroup()); // 设置组信息
heartBeatRequest.setLocalId(memberState.getSelfId());// 设置当前节点的ID
heartBeatRequest.setRemoteId(id);// 设置目标节点的ID
heartBeatRequest.setLeaderId(leaderId); // 设置LeaderID
heartBeatRequest.setTerm(term); // 设置Term
// 发送心跳
CompletableFuture<HeartBeatResponse> future = dLedgerRpcService.heartBeat(heartBeatRequest);
future.whenComplete((HeartBeatResponse x, Throwable ex) -> {
try {
if (ex != null) {
memberState.getPeersLiveTable().put(id, Boolean.FALSE);
throw ex;
}
switch (DLedgerResponseCode.valueOf(x.getCode())) {
case SUCCESS: // 如果成功
// 记录成功的数量
succNum.incrementAndGet();
break;
case EXPIRED_TERM: // 如果Term过期
// 使用响应返回的较大的那个Term记录在maxTerm中
maxTerm.set(x.getTerm());
break;
case INCONSISTENT_LEADER: // 如果是INCONSISTENT_LEADER
// inconsistLeader置为true
inconsistLeader.compareAndSet(false, true);
break;
case TERM_NOT_READY:// 如果未准备
// 记录未准备节点的数量
notReadyNum.incrementAndGet();
break;
default:
break;
}
// ...
} catch (Throwable t) {
logger.error("heartbeat response failed", t);
} finally {
allNum.incrementAndGet();
if (allNum.get() == memberState.peerSize()) {
beatLatch.countDown();
}
}
});
}
beatLatch.await(heartBeatTimeIntervalMs, TimeUnit.MILLISECONDS);
// 如果集群中过半节点对心跳包返回了成功的状态
if (memberState.isQuorum(succNum.get())) {
// 记录心跳成功的时间
lastSuccHeartBeatTime = System.currentTimeMillis();
} else {
logger.info("[{}] Parse heartbeat responses in cost={} term={} allNum={} succNum={} notReadyNum={} inconsistLeader={} maxTerm={} peerSize={} lastSuccHeartBeatTime={}",
memberState.getSelfId(), DLedgerUtils.elapsed(startHeartbeatTimeMs), term, allNum.get(), succNum.get(), notReadyNum.get(), inconsistLeader.get(), maxTerm.get(), memberState.peerSize(), new Timestamp(lastSuccHeartBeatTime));
if (memberState.isQuorum(succNum.get() + notReadyNum.get())) { // 如果成功的个数+未准备好的个数
// 上次发送心跳的时间间隔置为-1
lastSendHeartBeatTime = -1;
} else if (maxTerm.get() > term) { // 如果Term信息过期
// 转为Candidate重新选举,这里传入的是maxTerm的值
changeRoleToCandidate(maxTerm.get());
} else if (inconsistLeader.get()) { // 如果inconsistLeader为true
// 转为Candidate重新选举
changeRoleToCandidate(term);
} else if (DLedgerUtils.elapsed(lastSuccHeartBeatTime) > maxHeartBeatLeak * heartBeatTimeIntervalMs) {
// 如果上次成功发送心跳的时间大于 最大心跳时间* 心跳发送间隔
changeRoleToCandidate(term);
}
}
}
}
Follower
当节点收到心跳包并同意发起选举的节点成为Leader时,会转为Follower角色,在下次执行doWork方法时会进入到maintainAsFollower的处理逻辑,会判断上次收到心跳包的实际是否超过了两倍的发送心跳间隔,如果超过,判断当前节点是否是Follower并且上次收到心跳包的时间大于最大心跳时间 * 每次发送心跳的时间间隔,如果成立,会调用changeRoleToCandidate方法 转为Candidate发起竞选,也就是说如果Follower节点长时间未收到Leader节点的心跳请求,会认为Leader出现了故障,所以会转为Candidate重新发起竞选:
public class DLedgerLeaderElector {
private void maintainAsFollower() {
// 上次收到心跳包的时间是否超过了两倍的发送心跳间隔
if (DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > 2 * heartBeatTimeIntervalMs) {
synchronized (memberState) {
// 如果是Follower并且上次收到心跳包的时间大于 最大心跳时间 * 每次发送心跳的时间间隔
if (memberState.isFollower() && (DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > maxHeartBeatLeak * heartBeatTimeIntervalMs)) {
logger.info("[{}][HeartBeatTimeOut] lastLeaderHeartBeatTime: {} heartBeatTimeIntervalMs: {} lastLeader={}", memberState.getSelfId(), new Timestamp(lastLeaderHeartBeatTime), heartBeatTimeIntervalMs, memberState.getLeaderId());
// 转为Candidate发起竞选
changeRoleToCandidate(memberState.currTerm());
}
}
}
}
}
总结

参考
【中间件兴趣圈】源码分析 RocketMQ DLedger 多副本之 Leader 选主
RocketMQ源码分析之Dledger模式
RocketMQ版本:4.9.3