机器学习之支持向量机(SVM)
1. 概述
支持向量机(Support Vector Machine, 也称为支持向量网络)是一种二分类模型. 它源于统计学习理论, 是一个强学习器.
从分类效力来看, SVM无论在处理线性还是非线性分类中, 都是明星般的存在:

从实际来看, SVM在各种实际问题中也都具有不错的表现. 它在手写识别数字和人脸识别中应用广泛, 在文本和超文本的分类中举足轻重, 因为SVM可以大量减少标准归纳 (standard inductive) 和转换设置 (transductive settings) 中对标记训练示例的需求. 同时, SVM也被用来执行图像的分类, 并用于图像分割系统. 实验结果表明, 在仅仅三到四轮相关反馈之后, SVM就能实现比传统的查询细化方案 (query refinement schemes) 高出一大截的搜索精度. 除此之外, 生物学和许多其他科学都是SVM的青睐者, SVM现在已经被广泛用于蛋白质分类, 现在化合物分类的业界平均水平可以达到90%以上的准确率. 在生物科学的尖端研究中, 人们还使用支持向量机来识别用于模型预测的各种特征, 以找出各种基因表现结果的影响因素.
2. SVM如何工作?
下面用一个小故事来进行解释:
在很久以前, 大侠的心上人被反派囚禁, 大侠想要去救出他的心上人, 于是便去和反派谈判。反派说,只要你能顺利通过三关, 我就放了你的心上人. 现在大侠的闯关正式开始:
第一关:反派在桌子上似乎有规律地放了两种颜色的球, 说: 你用一根棍子分离开他们, 要求是尽量再放更多的球之后, 仍然适用.

大侠很干净利索的放了一根棍子如下:
第二关: 反派在桌子上放了更多的球, 似乎有一个红球站错了阵营.
SVM就是试图把棍放在最佳位置, 好让在棍的两边有尽可能大的间隙.

于是大侠将棍子调整如下, 现在即使反派放入更多的球, 棍子依然是一个很好的分界线.

反派看到大侠已经学会了一个"trick", 于是心生一计, 给大侠更难的一个挑战.
第三关: 反派将球散乱地放在桌子上.
现在大侠已经没有方法用一根棍子将这些球分开了, 怎么办呢? 大侠灵机一动, 使出三成内力拍向桌子, 然后桌子上的球就被震到空中, 说时迟那时快, 大侠瞬间抓起一张纸, 插到了两种球的中间.

现在从反派的角度看这些球, 这些球像是被一条曲线分开了. 于是反派乖乖地放了大侠的心上人.

从此之后, 江湖人便给这些分别起了名字, 把这些球叫做「data」, 把棍子叫做「classifier」, 最大间隙trick叫做「optimization」, 拍桌子叫做「kernelling」, 那张纸叫做「hyperplane」.
当一个分类问题, 数据是线性可分的, 也就是用一根棍就可以将两种小球分开的时候, 我们只要将棍的位置放在让小球距离棍的距离最大化的位置即可, 寻找这个最大间隔的过程, 就叫最优化. 但是, 一般的数据是线性不可分的, 也就是找不到一个棍将两种小球很好的分类. 这个时候, 我们就需要像大侠一样, 将小球拍起, 用一张纸代替小棍将小球进行分类. 想要让数据飞起, 我们需要的东西就是核函数 (kernel) , 用于切分小球的纸, 就是超平面 (hyperplane) . 如果数据是N维的, 那么超平面就是N-1维. (补: 未使用核函数情况下)
把一个数据集正确分开的超平面可能有多个, 而那个具有“最大间隔”的超平面就是SVM要寻找的最优解. 而这个真正的最优解对应的两侧虚线所穿过的样本点, 就是SVM中的支持样本点, 称为支持向量(support vector). 支持向量到超平面的距离被称为间隔 (margin) .


3. 线性SVM
一个最优化问题通常有三个基本因素:
1) 决策变量, 改变哪些变量能够使你的目标函数达到最优.
2) 目标函数, 你想要优化的问题 (MAX or MIN).
3) 约束条件
在线性SVM算法中, 目标函数显然就是"间隔", 决策变量则是" 超平面方程的参数".
3.1 超平面
在线性可分的二分类问题中, 超平面就是一条直线. 一般的直线方程表示为:
$$ y = a*x + b $$
现在对其做一点小小改变, 用\(x_1\)替换\(x\), \(x_2\)替换\(y\), 则上式变为:
$$x_2 = a*x_1 + b$$
$$a*x_1 + (-1 ) * x_2 + b = 0$$
写成向量形式:
$$\begin{bmatrix} a & -1 \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} + b = 0$$
进一步可表示为:
$$w^{\mathrm{T}}x + b = 0 \tag{1}$$
公式\(1\)即为超平面方程.
3.2 间隔
"间隔"就是点到直线的距离. 可表示为:
$$\text d =\frac {|w^{\mathrm{T}}x + b|} {||w||} \tag{2}$$
我们的目标是找出一个分类效果好的超平面作为分类器. 分类器的好坏取决于分类间隔\(\text W = 2 \text d\)的大小.
现在看起来, 公式\(2\)有点复杂. But, 我们还可以继续简化.
以下图为例, 在平面空间中有红蓝两种点:

红色代表正样本, 标记为+1.
蓝色代表负样本, 标记为-1.
那么则有:
$$
\begin{cases}
\frac {|w^{\mathrm{T}}x + b|}{||w||} \geq {\text d}, & y = +1 \\[2ex]
\frac {|w^{\mathrm{T}}x + b|}{||w||} \leq -{\text d} , & y = -1 \\
\end{cases} \tag{3}
$$
对公式\(3\)两边同时除以\(\text d\),可得:
$$
\begin{cases}
\frac {|w_{d}^{\mathrm{T}}x + b_{d}|}{||w_{d}||} \geq 1, & y = +1 \\[2ex]
\frac {|w_{d}^{\mathrm{T}}x + b_{d}|}{||w_{d}||} \leq -1 , & y = -1 \\
\end{cases} \tag{4}
$$
其中,
$$w_{\text d} = \frac {w} {||w||{\text d} }, b_d = \frac {b} {||w||{\text d} }$$
因为\(||w||\)和\(\text d\)都是标量, 所以上式中的两个矢量依然描述一条直线的法向量和截距. 故以下两个式子的数学模型的意义是一样的, 都是代表一条直线:
$$w^{\mathrm{T}}x + b = 0$$
$$w_{\text d} ^{\mathrm{T}}x + b_{\text d} = 0$$
即:
$$
\begin{cases}
\frac {|w^{\mathrm{T}}x + b|}{||w||} \geq 1, & y = +1 \\[2ex]
\frac {|w^{\mathrm{T}}x + b|}{||w||} \leq -1 , & y = -1 \\
\end{cases} \tag{5}
$$
根据公式\(5\), 对于我们的支持向量\(x\), 则有\(|w^{\mathrm{T}}x + b| =1 \).
那么对于这些支持向量来说:
$${\text d} =\frac {|w^{\mathrm{T}}x + b|} {||w||} = \frac {1}{||w||} \tag{6}$$
我们的优化问题是\(\max {\text d} \), 为了求解方便, 可以将其改换成\(\min \frac{1}{2} ||w||^2\).
3.3 SMO算法 (序列最小优化算法)
SMO算法是一种解决二次优化问题的算法, 其最经典的应用就是在解决SVM问题上.
SVM算法详解 此贴给出了详细的介绍.
某个数据集, 二分类且线性可分:

代码实现:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import random
data = np.genfromtxt("testSet.txt")
# data = np.genfromtxt("testSetRBF.txt")
x = data[:, :-1]
y = data[:, -1]
plt.scatter(x[:, 0], x[:, 1], c=y, s=50, cmap="rainbow")
# plt.show()
x = np.mat(x)
y = np.mat(y).T
# 核函数
def kernel(x, a, type="lin"):
m, n = x.shape
K = np.mat(np.zeros((m, 1)))
if type == "lin":
K = x * a.T
elif type == "rbf": # 高斯和函数
for j in range(m):
deltaRow = x[j, :] - a
K[j] = deltaRow * deltaRow.T
K = np.exp(K / (-1 * 5 ** 2))
else:
raise NameError("核函数无法识别")
return K
# 随机选择j
def randSelectJ(i, m):
j = i
while j == i:
# j = int(random.uniform(0, m))
j = random.randint(0, m - 1)
return j
# 修剪j
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if aj < L:
aj = L
return aj
# 简单smo算法
def simpleSmo(x, y, C, toler, maxiter, type):
m, n = x.shape
# 初始化 alpha, b, 迭代次数iters
alpha = np.mat(np.zeros((m, 1)))
# alpha = np.zeros((m, 1))
b = 0
iters = 0
K = np.mat(np.zeros((m, m)))
for i in range(m):
K[:, i] = kernel(x, x[i, :], type)
while iters < maxiter:
alpha_iters = 0
for i in range(m):
# 计算误差 Exi
fxi = np.multiply(alpha, y).T * K[:, i] + b
# fxi = (alpha * y).T @ (x @ x[i, :].T)
Ei = fxi - y[i]
# 若满足条件, 开始优化
if (y[i] * Ei < -toler and alpha[i] < C) or (y[i] * Ei > toler and alpha[i] > 0):
# 计算误差 Exj
j = randSelectJ(i, m)
fxj = np.multiply(alpha, y).T * K[:, j] + b
Ej = fxj - y[j]
# 记录当前 alphai, alphaj
alphaOldi = alpha[i].copy()
alphaOldj = alpha[j].copy()
if y[i] != y[j]:
L = max(0, alpha[j] - alpha[i])
H = min(C, C + alpha[j] - alpha[i])
else:
L = max(0, alpha[j] + alpha[i] - C)
H = min(C, alpha[j] + alpha[i])
if L == H:
continue
# 计算学习率 eta
eta = 2 * K[i, j] - K[i, i] - K[j, j]
if eta >= 0:
continue
# 更新 alphaj
alpha[j] -= y[j] * (Ei - Ej) / eta
# 修剪 alphaj
alpha[j] = clipAlpha(alpha[j], H, L)
# 如果更新太小, 不当作更新
if abs(alpha[j] - alphaOldj) < 0.00001:
continue
# 更新 alphai
alpha[i] += y[j] * y[i] * (alphaOldj - alpha[j])
# 更新 b1, b2, b
b1 = b - Ei - y[i] * (alpha[i] - alphaOldi) * K[i, i] - y[j] * \
(alpha[j] - alphaOldj) * K[i, j]
b2 = b - Ej - y[i] * (alpha[i] - alphaOldi) * K[i, j] - y[j] * \
(alpha[j] - alphaOldj) * K[j, j]
if 0 < alpha[i] < C:
b = b1
elif 0 < alpha[j] < C:
b = b2
else:
b = (b1 + b2) / 2
#
alpha_iters += 1
if alpha_iters == 0:
iters += 1
else:
iters = 0
return alpha, b
#获取支持向量
def get_sv(xMat, yMat, alpha):
m = xMat.shape[0]
sv_x = []
sv_y = []
for i in range(m):
if alpha[i] > 0:
sv_x.append(xMat[i])
sv_y.append(yMat[i])
sv_x1 = np.array(sv_x).reshape(-1, 2)
sv_y1 = np.array(sv_y).reshape(-1, 1)
return sv_x1, sv_y1
# 画图
def showDataSet(x, y, alpha, b):
sv_x, sv_y = get_sv(x, y, alpha)
plt.scatter(sv_x[:, 0], sv_x[:, 1], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolor='red')
w = np.dot((np.tile(np.array(y).reshape(1, -1).T, (1, 2)) * np.array(x)).T, np.array(alpha))
a1, a2 = w
x1 = np.linspace(-1, 10)
b = float(b)
a1 = float(a1[0])
a2 = float(a2[0])
y1 = -a1 / a2 * x1 - b / a2
y2 = -a1 / a2 * (x1 - sv_x[0, 0]) +sv_x[0, 1]
y3 = -a1 / a2 * (x1 - sv_x[-1, 0]) +sv_x[-1, 1]
plt.plot(x1, y2, 'k--')
plt.plot(x1, y3, 'k--')
plt.plot(x1, y1)
alpha, b = simpleSmo(x, y, 0.6, 0.001, 40, "lin")
# alpha, b = simpleSmo(x, y, 0.6, 0.001, 5, "rbf")
# print(b)
# print(alpha)
showDataSet(x, y, alpha, b)
plt.show()
结果:
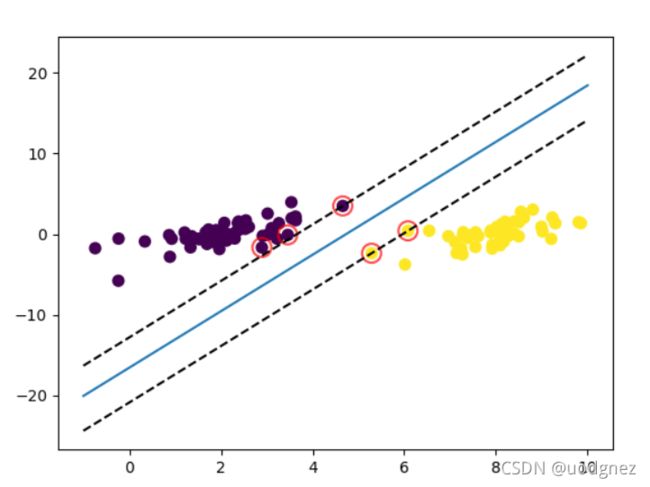
圈出来的即是"支持向量", 共有5个.
3.2 sklearn.svm
代码:
from sklearn.datasets import make_blobs
from sklearn import svm
import matplotlib.pyplot as plt
import numpy as np
# x, y =make_blobs(n_samples=100, centers=2, random_state=1, cluster_std=2)
# print(y.shape)
data = np.genfromtxt("testSet.txt")
x = data[:, :-1]
y = data[:, -1]
plt.scatter(x[:, 0], x[:, 1], c=y, s=50, cmap="rainbow")
# plt.show()
clf = svm.SVC(kernel="linear")
clf.fit(x, y)
w = clf.coef_[0]
b = clf.intercept_[0]
x1 = np.linspace(-1, 10)
# 超平面
Hy1 = -w[0] / w[1] * x1 - b / w[1]
# 支持向量 (取出两个作图)
sv1 = clf.support_vectors_[0]
sv2 = clf.support_vectors_[-1]
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolor='red')
# 边际
Hy2 = -w[0] / w[1] * (x1-sv1[0]) + sv1[1]
Hy3 = -w[0] / w[1] * (x1-sv2[0]) + sv2[1]
# test_x = np.array([[2.5, 5.0], [-5.0, 4]])
# y = clf.predict(test_x)
# plt.scatter(test_x[:, 0], test_x[:, 1], c=y, s=80)
plt.plot(x1, Hy1)
plt.plot(x1, Hy2, "k--")
plt.plot(x1, Hy3, "k--")
# plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=80)
plt.show()
结果:

得到了三个支持向量.