超分辨率地震速度模型
文献分享
1. Multitask Learning for Super-Resolution
原题目:Multitask Learning for Super-Resolution of Seismic Velocity Model
全波形反演(FWI)是估算地下速度模型的强大工具。与传统反演策略相比,FWI充分利用了地震波的运动学和动力特性,具有更高的精度和分辨率。近年来,低频和中频波数的FWI发展迅速,而高频FWI由于其计算成本巨大,亟待解决。由于深度学习技术在各种地球物理问题中取得了显著的性能,作者建议使用深度学习方法来提高FWI的效率和准确性。
Core parts:
1.super-resolution:目标是从给定的低分辨率图像中获得视觉上令人愉悦的高分辨率图像。作者专注于使用SR技术来辅助FWI任务,即使用SR作为后处理操作来提高FWI的质量。
2.multitask learning:把多个相关的任务放在一起学习,同时学习多个任务。通过在一定程度上提高辅助任务的性能和共享参数,可以更好地泛化原始任务(主要任务)。
1.1 方法
边缘图像:是对原始图像进行边缘提取后得到的图像。边缘是图像性区域和另一个属性区域的交接处,是区域属性发生突变的地方,是图像中不确定性最大的地方,也是图像信息最集中的地方,图像的边缘包含着丰富的信息。
具有硬参数共享的MTL:边界恢复是当前SR处理的难点,并且这在地震速度模型的SR中尤为突出。在地球物理学中,地震速度模型的边缘信息是地质模型的重要组成部分,这证明了使用边缘图像重建作为辅助任务的相关性。并且由于地震速度模型与其边缘图像高度相关,因此采用硬参数共享策略更加高效。文章得到的边缘图像是原始图像经过sobel算子卷积的结果。

混合损失函数:由MSE和TV组成,表达式如下:
loss ( Φ ) = mse ( Φ ) + TV ( Φ ) \text{loss}(\Phi)= \text{mse}(\Phi) +\text{TV}(\Phi) loss(Φ)=mse(Φ)+TV(Φ)
mse ( Φ ) = 1 N M ∑ k = 1 3 α k ∑ i = 1 N ∑ j = 1 M ( f ( I L , Φ ) i , j , k , − I H i , j , k ) 2 , \text{mse}(\Phi) =\frac{1}{NM}\sum^{3}_{k=1}\alpha_k\sum^{N}_{i=1}\sum^{M}_{j=1}(f(I_L,\Phi)^{i,j,k},-I_H^{i,j,k})^2, mse(Φ)=NM1k=1∑3αki=1∑Nj=1∑M(f(IL,Φ)i,j,k,−IHi,j,k)2, where ∑ k = 1 3 α k = 1 \sum^{3}_{k=1}\alpha_k=1 ∑k=13αk=1 and a k l 1 ( I H − I L ) ∣ c = k ≡ C , k = 1 , 2 , 3 a_k l_1(I_H-I_L)|_{c=k}\equiv C, k=1,2,3 akl1(IH−IL)∣c=k≡C,k=1,2,3
TV ( Φ ) = β 1 1 K 1 ∑ i = 1 N ∑ j = 2 M ∣ f ( I L , Φ ) i , j , 1 − f ( I L , Φ ) i , j − 1 , 1 ∣ + β 2 1 K 2 ∑ i = 1 N ∑ j = 2 M ∣ f ( I L , Φ ) i , j , 1 − f ( I L , Φ ) i − 1 , j , 1 ∣ , \text{TV}(\Phi)=\beta_1\frac {1}{K_1}\sum^{N}_{i=1}\sum^{M}_{j=2}\lvert f(I_L,\Phi)^{i,j,1}-f(I_L,\Phi)^{i,j-1,1}\rvert+ \ \beta_2\frac {1}{K_2}\sum^{N}_{i=1}\sum^{M}_{j=2}\lvert f(I_L,\Phi)^{i,j,1}-f(I_L,\Phi)^{i-1,j,1}\rvert, TV(Φ)=β1K11i=1∑Nj=2∑M∣f(IL,Φ)i,j,1−f(IL,Φ)i,j−1,1∣+ β2K21i=1∑Nj=2∑M∣f(IL,Φ)i,j,1−f(IL,Φ)i−1,j,1∣,
where K 1 = N ( M − 1 ) , K 2 = ( N − 1 ) M K_1 = N(M-1), K_2=(N-1)M K1=N(M−1),K2=(N−1)M.

同时,在训练过程中,采用了学习率衰减方法。实际学习率表示为
η i = a i η 0 \eta_i = a^i\eta_0 ηi=aiη0
η 0 \eta_0 η0为初始学习率, a a a为衰减率。
1.2 实验结果

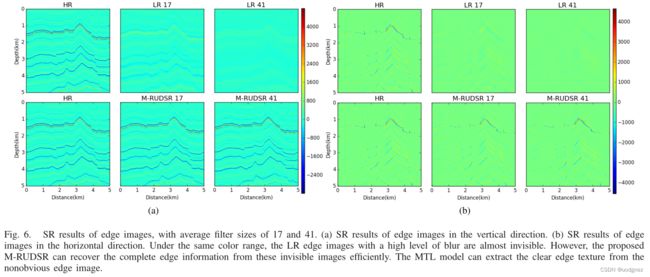

2. Super-resolution guided by seismic data
原题目:Super-Resolution of Seismic Velocity Model Guided by Seismic Data
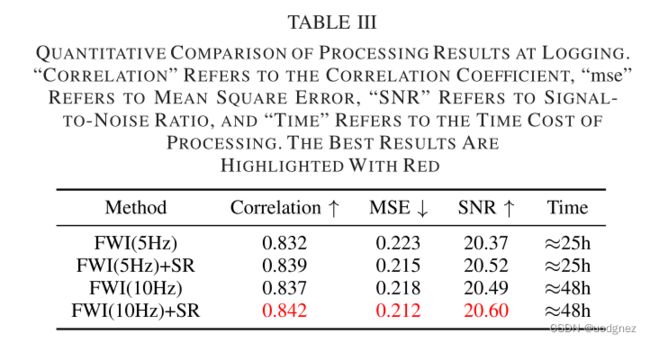
前面的提到的,M-RUDSR的多任务学习框架已经成功通过提高地震速度模型的分辨率,来提高FWI结果的精度。
然而,作者认为它并没有充分利用地震数据。但由于地震速度模型和地震数据处于不同的频段,单纯增加模型输入输出通道来实现地震数据的利用效果有限。在M-RUSDR的基础上,提出了M-RUSDRv2。
不同的是,M-RUSDR是仅将地震速度模型边缘图像的SR作为辅助任务以增强地震速度模型的分辨率,而M-RUSDRv2不仅考虑地震速度模型及其边缘图像,还考虑了地震数据及其边缘图像。并且M-RUSDRv2通过在特定数据的训练,海量数据上的微调,实现了较强的泛化能力。
2.1 方法
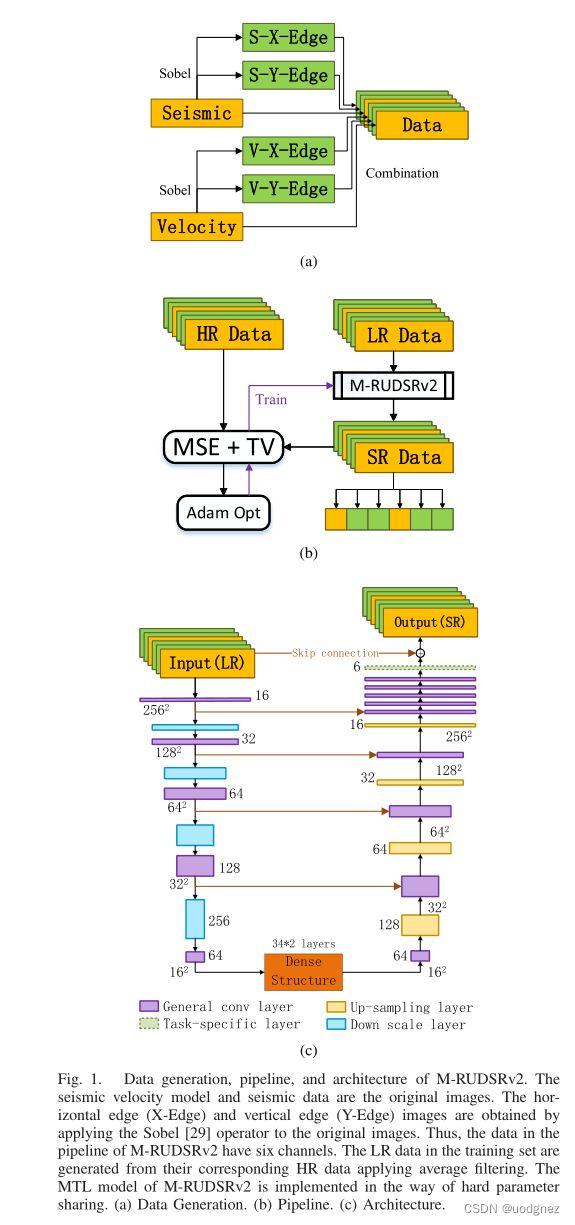
损失函数:与上文仅仅有一处不同,即 a k a_k ak
∑ k = 1 K a k = 1 , K = 6 \sum_{k=1}^K a_k=1,K=6 ∑k=1Kak=1,K=6 and a k = m a k + 3 , m > 0 , k ∈ [ 1 , 3 ] a_k=ma_{k+3},m>0,k \in[1,3] ak=mak+3,m>0,k∈[1,3] and a k 1 ∥ I H k 1 − I L k 1 ∥ 1 = a k 2 ∥ I H k 2 − I L k 2 ∥ 1 , k 1 , k 2 ∈ [ 1 , 3 ] a_{k_1}\lVert I_H^{k_1}-I_{L}^{k_1}\rVert_1=a_{k_2}\lVert I_H^{k_2}-I_{L}^{k_2}\rVert_1, k_1,k_2 \in[1,3] ak1∥IHk1−ILk1∥1=ak2∥IHk2−ILk2∥1,k1,k2∈[1,3]
训练过程分为三个步骤:
1.对具有相同模糊级别的地震速度模型和地震数据进行训练,包括四种类型的训练数据(与上文类似)。上式参数 m m m设置为1。此时模型仅针对特定数据进行初步学习,泛化能力较差。
2.对地震速度模型和各种模糊级别的地震数据进行训练,包括16种训练数据。因此,该模型广泛学习各种数据,具有很强的泛化能力。 m m m值设置同上。
3.对地震速度模型和各种模糊级别的地震数据的训练(与步骤2中的训练数据类似)。此外,将参数 m m m调整为 m > 1 m > 1 m>1,这使得损失函数对地震速度模型更加敏感。
2.2 实验结果

