计算机底层:ASCII码、区位码、国标码、汉字机内码,还有字形码和输入输出编码之间的关系以及介绍
计算机底层:ASCII、区位码、国标码、汉字机内码之间的关系,还有字形码和输入输出编码之间的关系以及介绍
键盘上有:数字、字母、符合。这些都称作为字符,而它们的组合就叫做:字符串。
ASCII

键盘上所能表示的字符有128个,刚好是2^7,因此计算机用7个bit位就可以表示这些字符。
但是在计算机内部,并不会使用7个bit位,而是在7位的前面补一个0,变成8位。也就是一个存储单元,因此一个字符就会存放在一个存储的单元内
有了7bit个bit位就可以表示128种不同的符合。每种符号就被附上了不同的与之对应的二进制编码。用一个二进制编码就可以表示一个符号。
为了让人们更好地记住这些二进制编码以及所对应地符号,制作了一个表,这个表上使用的不再是二进制对应一个字符串 而是 十进制对应一个字符。
这就是ASCII码表。
最后,我们知道在ASCII中,通常是8bit表示一个字符,且最高位都是0。

ASCII码对应了128个字符。
这些字符被分成三类:可印刷字符、控制字符、通信字符
可印刷字符:32~126都是可印刷字符。可以打印出来给人看的。
控制字符:127是控制字符,DEL就是键盘上的delete,用于删除。
通信字符:0~32,比如6,ACK,在两个电脑通信时,会一方接到另一方传来的数据时,就会回一个ACK包。
需要注意的是,在内存中存放的数据是该字符在ASCII码对应的二进制。这个二进制就是上面ASCII码表中的十进制转成二进制的二进制。
![]()
 如果你知道M的ASCII码值那么这些计算只不过是锦上添花罢了。
如果你知道M的ASCII码值那么这些计算只不过是锦上添花罢了。


我们知道,中文也是字符,但ASCII码值对应字符内没有一个中文。
那么中文的字符怎么在计算机内打印出来呢?
为了能够存储和打印中文字符,中国发明了属于自己的汉字编码。
GB 2312 -80
GB 2312-80是由区位码演变而来的:
区位码中,汉字被分成了94个区域,每个区域有94个位置。这被称为:区(区域)位(位置)码
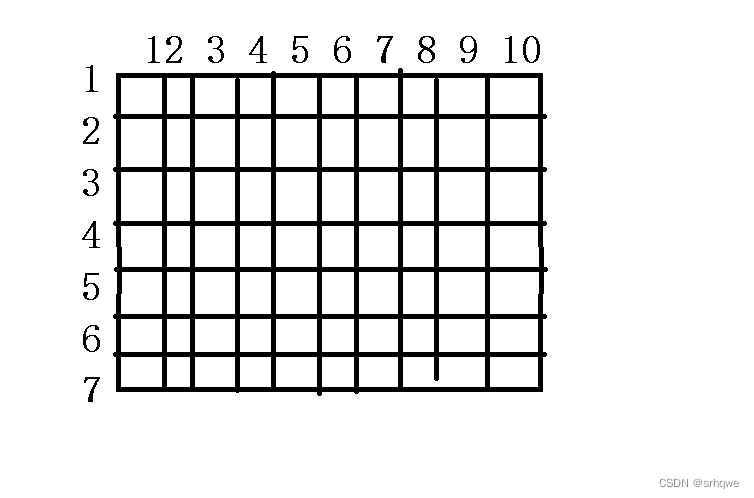
其中,就像是坐标一样,区是横坐标,位是纵坐标一样。

比如,表示'啊'这个字符,区位码:区是16 位是01。这是十进制,计算机表示时是二进制。
区和位组成区位码:即'啊'的区位码就是1610
区位码的存放与取出:
存放:区位码在内存中是分开存储的,就是将区码和位码分开存放。而为了适应计算机,在计算机内部,无论是区码还是位码,都是由8个bit位组成的。一个区码或是位码都会放到一个存储单元内。如:'啊'区码是16位码是01,那么内存中存放的区码:0001 0000,位码:0000 0001
取出:区位码取出时,会将区码和位码结合,变成16bit的二进制。高8bit是区码,底8bit是位码。然后计算机再用通过区位码读取出信息,易于理解地说就是区码和位码被翻译成10进制,组合后对照设定地区位码表,进行读取信息。比如:'啊',计算机从内存中读到了区码和位码,通过组合后计算机发现对应了'啊'字,那么就输出了'啊'
GB 2312 -80:
在网络传输的过程中:A要给B传输一个数据,如果A传去的数据是用GB2312-80编的,而B读取地方式是用ASCII方式的,GB 2312-80将区位码传过去,当B收到时会先读到区码,因为区码和位码的范围用十进制表示都是0~93,如果此时的区码的十进制是6,那么ASCII对应的6则是ACK,会发现ACK是回包的指示。那么就会出现问题。

为了解决这一问题,科学家就将区位码加上32,因为ASCII的通信字符是0~32,如果将区位码的区码和位码都+32,那么区码和位码的范围就变成了32-125。就避开了与ASCII中通信字符与控制字符的相同的情况,提高了ASCII和区位码的兼容性。而这种32~125的区位码就是所谓的:国标码(GB2312 -80)
但是国标码是用十六进制表示的,实际上是再区位码的区码和位码分别加上20H(32O),也就是加上2020H,最后得到了GB 2312-80
![]()
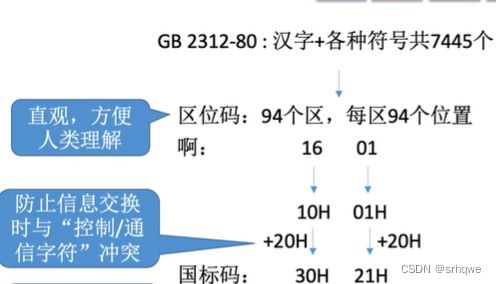
GB 2312 -80是国标码,也被称之为交换码
GB 2312 :
上面说到出现国标码是为了防止与ASCII的控制字符和通信字符冲突,但是还是会和打印字符发送冲突,因此为了彻底让国标码和ASCII兼容。就再GB 2312-80的基础上分别在加上8080H,也就是在区码和位码上再加上128(80H)。最后得到了:汉字机内码,GB 2312就是汉字机内码。
由于ASCII的范围是再0-127,而GB 2312在(128+32=160)160~253(93+160),因此GB2312与ASCII就不会发生冲突了,使得中国汉字与外国英文兼容了。
最后在计算机内部,使用的就是汉字机内码(GB 2312)
汉字机内码也有别的称呼:汉字内码、内码。
![]()

除了GB 2312这种汉字编码方式,还有许多其他的,比如:UTF-8、GBK等等...
汉字在计算机内部的输入和输出:
输入:

如果此时要用输入法打出一个'内'字,那么我需要在键盘上点4个键:nei1。
输入nei1后,输入法会将nei1转换成国标码,然后计算机系统或者是引用软件,会将国标码再转换成汉字机内码,最后计算机或是手机再去保存这个汉字机内码。
输入法也可能会直接将nei1转换成机内码。
输出:
汉字要输出,就需要用到另一种编码:汉字字形码。
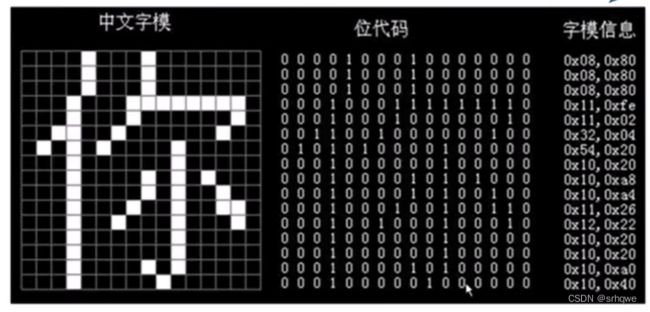
汉字字形码是通过用一块一块的像素拼组而成的,1表示这里的像素需要图上颜色,0表示不用。从而达到输出一个汉字。
计算机会将汉字机内码转换成国标码,再将国标码转换成汉字字形码,或是直接由汉字机内码转换成汉字字形码。最后输出。
汉字机内码转换成汉字字形码需要经过以下步骤:
1. 根据汉字机内码的编码规则,将每个汉字转换成相应的二进制编码。
2. 对于一些早期的编码规则,需要使用专门的编码转换表将汉字机内码转换成Unicode编码。
3. 根据汉字字形库中的字形信息,将汉字机内码转换成相应的汉字字形码。
4. 在显示设备上根据汉字字形码渲染出汉字的图形形态,供用户观看和使用。
总之,汉字机内码转换成汉字字形码需要依赖计算机编码规则和字形库信息,经过多个步骤才能完成。