K8S内容分发网络之集群,nginx,负载均衡,防火墙

K8S内容分发网络之集群,nginx,负载均衡,防火墙
-
- 一、Kubernetes 区域可采用 Kubeadm 方式进行安装。
-
- 1.所有节点,关闭防火墙规则,关闭selinux,关闭swap交换
- 2.修改主机名
- 3.所有节点修改hosts文件
- 4.调整内核参数
- 5.生效参数
- 6.安装软件
- 7.部署K8S集群
- 8.查看 kubeadm-init 日志
- 9.设定kubectl
- 10.所有节点部署网络插件flannel
- 11.在 node 节点上执行 kubeadm join 命令加入群集
- 12.在master节点查看节点状态
- 二、创建两个自主式Pod资源
-
- 1.生成nginx的pod模板文件
- 2.修改模板文件
- 3.两个node节点的存储卷,写入不同的html文件内容,验证访问网页
- 三、创建service资源
-
- 1.编写service对应的yaml文件
- 2.查看service资源
- 3.测试使用nodeIP:nodePort访问nginx网页
- 四、搭建负载均衡层
-
- 1.两台负载均衡器配置nginx
- 2.两台负载均衡器配置keepalived
- 3.关闭主调度器的nginx服务,模拟故障,测试keepalived
- 五、配置防火墙服务器
-
- 1.关闭防火墙和selinux
- 2.开启路由转发功能
- 3.配置iptables策略
- 4.新增一台客户机(192.168.174.12)
- 5.测试
| 节点 | IP | 安装组件 |
|---|---|---|
| master(2C/4G,cpu核心数要求大于2) | 192.168.174.15 | docker、kubeadm、kubelet、kubectl、flannel |
| node01(2C/2G) | 192.168.174.18 | docker、kubeadm、kubelet、kubectl、flannel |
| node02(2C/2G) | 192.168.174.19 | docker、kubeadm、kubelet、kubectl、flannel |
| lb01 | 192.168.174.18 | nginx,keepalived |
| lb02 | 192.168.174.19 | nginx,keepalived |
| 网关服务器 | 内网网卡ens33:192.168.174.12,外网网卡ens37:12.0.0.1 | iptables |
| 客户端 | 12.0.0.12 |
一、Kubernetes 区域可采用 Kubeadm 方式进行安装。
1.所有节点,关闭防火墙规则,关闭selinux,关闭swap交换
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
swapoff -a #交换分区必须要关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab #永久关闭swap分区,&符号在sed命令中代表上次匹配的结果
#加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
2.修改主机名
hostnamectl set-hostname master01
hostnamectl set-hostname node01
hostnamectl set-hostname node02
3.所有节点修改hosts文件
vim /etc/hosts
192.168.174.15 master01
192.168.174.18 node01
192.168.174.19 node02
4.调整内核参数
cat > /etc/sysctl.d/kubernetes.conf << EOF
#开启网桥模式,可将网桥的流量传递给iptables链
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-iptables=1
#关闭ipv6协议
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
EOF
5.生效参数
sysctl --system
6.安装软件
(1)所有节点安装docker
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce docker-ce-cli containerd.io
cat > /etc/docker/daemon.json <(2)所有节点安装kubeadm,kubelet和kubectl
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum install -y kubelet-1.20.11 kubeadm-1.20.11 kubectl-1.20.11
systemctl enable kubelet.service
#K8S通过kubeadm安装出来以后都是以Pod方式存在,即底层是以容器方式运行,所以kubelet必须设置开机自启
7.部署K8S集群
(1)查看初始化需要的镜像
kubeadm config images list
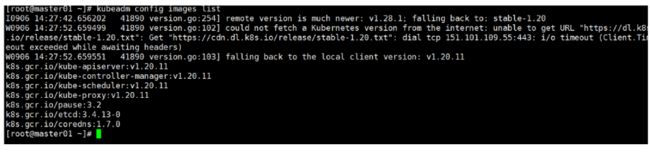
(2)在 master 节点上传 v1.20.11.zip压缩包至 /opt 目录
unzip v1.20.11.zip -d /opt/k8s
cd /opt/k8s/v1.20.11
for i in $(ls *.tar); do docker load -i $i; done
(3)复制镜像和脚本到 node 节点,并在 node 节点上执行脚本加载镜像文件
scp -r /opt/k8s [email protected]:/opt
scp -r /opt/k8s [email protected]:/opt
cd /opt/k8s/v1.20.11
for i in $(ls *.tar); do docker load -i $i; done
(3)初始化kubeadm
方法一:
kubeadm config print init-defaults > /opt/kubeadm-config.yaml
cd /opt/
vim kubeadm-config.yaml
......
11 localAPIEndpoint:
12 advertiseAddress: 192.168.174.15 #指定master节点的IP地址
13 bindPort: 6443
......
34 kubernetesVersion: v1.20.11 #指定kubernetes版本号
35 networking:
36 dnsDomain: cluster.local
37 podSubnet: "10.244.0.0/16" #指定pod网段,10.244.0.0/16用于匹配flannel默认网段
38 serviceSubnet: 10.96.0.0/16 #指定service网段
39 scheduler: {}
#末尾再添加以下内容
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs #把默认的kube-proxy调度方式改为ipvs模式
kubeadm init --config=kubeadm-config.yaml --upload-certs | tee kubeadm-init.log
#--experimental-upload-certs 参数可以在后续执行加入节点时自动分发证书文件,K8S V1.16版本开始替换为 --upload-certs
#tee kubeadm-init.log 用以输出日志

8.查看 kubeadm-init 日志
less kubeadm-init.log
kubernetes配置文件目录
ls /etc/kubernetes/
//存放ca等证书和密码的目录
ls /etc/kubernetes/pki
方法二:
kubeadm init \
--apiserver-advertise-address=192.168.174.15 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.20.11 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--token-ttl=0
初始化集群需使用kubeadm init命令,可以指定具体参数初始化,也可以指定配置文件初始化。
可选参数:
--apiserver-advertise-address:apiserver通告给其他组件的IP地址,一般应该为Master节点的用于集群内部通信的IP地址,0.0.0.0表示节点上所有可用地址
--apiserver-bind-port:apiserver的监听端口,默认是6443
--cert-dir:通讯的ssl证书文件,默认/etc/kubernetes/pki
--control-plane-endpoint:控制台平面的共享终端,可以是负载均衡的ip地址或者dns域名,高可用集群时需要添加
--image-repository:拉取镜像的镜像仓库,默认是k8s.gcr.io
--kubernetes-version:指定kubernetes版本
--pod-network-cidr:pod资源的网段,需与pod网络插件的值设置一致。Flannel网络插件的默认为10.244.0.0/16,Calico插件的默认值为192.168.0.0/16;
--service-cidr:service资源的网段
--service-dns-domain:service全域名的后缀,默认是cluster.local
--token-ttl:默认token的有效期为24小时,如果不想过期,可以加上 --token-ttl=0 这个参数
方法二初始化后需要修改 kube-proxy 的 configmap,开启 ipvs
kubectl edit cm kube-proxy -n=kube-system
修改mode: ipvs
9.设定kubectl
kubectl需经由API server认证及授权后方能执行相应的管理操作,kubeadm 部署的集群为其生成了一个具有管理员权限的认证配置文件 /etc/kubernetes/admin.conf,它可由 kubectl 通过默认的 “$HOME/.kube/config” 的路径进行加载。
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
(1)如果 kubectl get cs 发现集群不健康,更改以下两个文件

vim /etc/kubernetes/manifests/kube-scheduler.yaml
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
修改如下内容
把--bind-address=127.0.0.1变成--bind-address=192.168.174.15 #修改成k8s的控制节点master01的ip
把httpGet:字段下的hosts由127.0.0.1变成192.168.174.15(有两处)
#- --port=0 # 搜索port=0,把这一行注释掉
systemctl restart kubelet

10.所有节点部署网络插件flannel
方法一:
(1)所有节点上传flannel镜像 flannel.tar 到 /opt 目录,master节点上传 kube-flannel.yml 文件
cd /opt
unzip kuadmin-flannel.zip
docker load -i flannel-cni-v1.2.0.tar
docker load -i flannel-v0.22.2.tar
mv cni cni_bak
mkdir cni/bin -p
tar zxvf cni-plugins-linux-amd64-v1.2.0.tgz -C cni/bin
ll cni/bin
(2)在 master 节点创建 flannel 资源
kubectl apply -f kube-flannel.yml
方法二:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
11.在 node 节点上执行 kubeadm join 命令加入群集
kubeadm join 192.168.174.15:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:c93b6ce2fe56803f792c49da16d0faf04c001f93c8ee8abd24a5fb344474b50c
12.在master节点查看节点状态
kubectl get nodes
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-bccdc95cf-c9w6l 1/1 Running 0 71m
coredns-bccdc95cf-nql5j 1/1 Running 0 71m
etcd-master 1/1 Running 0 71m
kube-apiserver-master 1/1 Running 0 70m
kube-controller-manager-master 1/1 Running 0 70m
kube-flannel-ds-amd64-kfhwf 1/1 Running 0 2m53s
kube-flannel-ds-amd64-qkdfh 1/1 Running 0 46m
kube-flannel-ds-amd64-vffxv 1/1 Running 0 2m56s
kube-proxy-558p8 1/1 Running 0 2m53s
kube-proxy-nwd7g 1/1 Running 0 2m56s
kube-proxy-qpz8t 1/1 Running 0 71m
kube-scheduler-master 1/1 Running 0 70m
二、创建两个自主式Pod资源
要求在 Kubernetes 环境中,通过yaml文件的方式,创建2个Nginx Pod分别放置在两个不同的节点上,Pod使用hostPath类型的存储卷挂载,节点本地目录共享使用 /data,2个Pod副本测试页面二者要不同,以做区分
1.生成nginx的pod模板文件
kubectl run mynginx --image=nginx:1.14 --port=80 --dry-run=client -o yaml > mynginx.yaml
2.修改模板文件
vim mynginx.yaml
---
apiVersion: v1
kind: Pod
metadata:
labels:
app: mcl-nginx #pod的标签
name: mcl-nginx01
spec:
nodeName: node01 #指定该pod调度到node01节点
containers:
- image: nginx:1.14
name: mynginx
ports:
- containerPort: 80 #定义容器的端口
volumeMounts: #挂载存储卷
- name: page01 #名称需要与下方定义的存储卷的名称一致
mountPath: /usr/share/nginx/html #容器中的挂载点,设置为nginx服务的网页根目录
readOnly: false #可读可写
volumes: #定义一个存储卷
- name: page01 #存储卷的名称
hostPath: #存储卷的类型为 hostPath
path: /data #node节点的共享目录
type: DirectoryOrCreate #该类型表示如果共享目录不存在,则系统会自动创建该目录
---
apiVersion: v1
kind: Pod
metadata:
labels:
app: mcl-nginx #pod的标签
name: mcl-nginx02
spec:
nodeName: node02 #指定该pod调度到node02节点
containers:
- name: mynginx
image: nginx:1.14
ports:
- containerPort: 80 #定义容器的端口
volumeMounts: #挂载存储卷
- name: page02 #名称需要与下方定义的存储卷的名称一致
mountPath: /usr/share/nginx/html #容器中的挂载点
readOnly: false
volumes: #定义一个存储卷
- name: page02 #存储卷的名称
hostPath: #存储卷类型为 hostPath
path: /data #node节点的共享目录
type: DirectoryOrCreate #该类型表示如果共享目录不存在,则系统会自动创建该目录
#使用yaml文件创建自主式Pod资源
kubectl apply -f mynginx.yaml
#查看创建的两个pod,被调度到了不同的node节点
[root@master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mcl-nginx01 1/1 Running 0 38s 10.244.1.10 node01
mcl-nginx02 1/1 Running 0 38s 10.244.2.14 node02
nginx-deployment-9448647c5-h7h26 1/1 Running 0 15d 10.244.2.13 node02
nginx-deployment-9448647c5-qs99r 1/1 Running 0 15d 10.244.2.11 node02
nginx-deployment-9448647c5-vm6sk 1/1 Running 0 15d 10.244.2.12 node02

3.两个node节点的存储卷,写入不同的html文件内容,验证访问网页
#node01节点
echo "this is node01" > /data/index.html
#node02节点
echo "this is node02 ~~" > /data/index.html
curl 10.244.1.10 #访问Node01节点的Pod的IP
curl 10.244.2.14 #访问Node02节点的Pod的IP

三、创建service资源
编写service对应的yaml文件,使用NodePort类型和TCP 30000端口将Nginx服务发布出去。
1.编写service对应的yaml文件
vim myservice.yaml
apiVersion: v1
kind: Service
metadata:
name: mcl-nginx-svc
namespace: default
spec:
type: NodePort #service类型设置为NodePort
ports:
- port: 80 #service使用的端口号,ClusterIP后面跟的端口号。
targetPort: 80 #需要转发到的后端Pod的端口号
nodePort: 30000 #指定映射到物理机的端口号,k8s集群外部可以使用nodeIP:nodePort访问service
selector:
app: mcl-nginx #标签选择器要和上一步创建的pod的标签保持一致
#创建service资源
kubectl apply -f myservice.yaml
2.查看service资源
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 16d
mcl-nginx-svc NodePort 10.96.152.69 80:30000/TCP 12s
nginx NodePort 10.96.173.35 80:30291/TCP 15d
nginx-deployment NodePort 10.96.134.133 30000:32070/TCP 15d
#查看service资源的详细信息
kubectl describe svc mcl-nginx-svc
Name: mcl-nginx-svc
Namespace: default
Labels:
Annotations:
Selector: app=mcl-nginx
Type: NodePort
IP Families:
IP: 10.96.152.69
IPs: 10.96.152.69
Port: 80/TCP
TargetPort: 80/TCP
NodePort: 30000/TCP
Endpoints: 10.244.1.10:80,10.244.2.14:80
Session Affinity: None
External Traffic Policy: Cluster
Events:
3.测试使用nodeIP:nodePort访问nginx网页
curl 192.168.174.18:30000 #node01
curl 192.168.174.19:30000 #node02
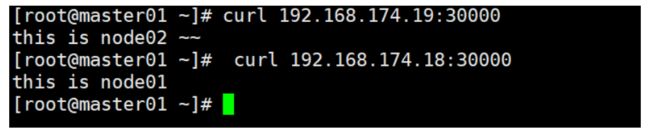
四、搭建负载均衡层
负载均衡区域配置Keepalived+Nginx,实现负载均衡高可用,通过VIP 192.168.174.100和自定义的端口号即可访问K8S发布出来的服务。
- lb01:192.168.174.18
- lb02:192.168.174.19
- VIP:192.168.174.100
1.两台负载均衡器配置nginx
#关闭防火墙和selinux
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
#设置主机名
hostnamectl set-hostname lb01
su
hostnamectl set-hostname lb02
su
#配置nginx的官方在线yum源
cat > /etc/yum.repos.d/nginx.repo << 'EOF'
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
EOF
yum install nginx -y
#修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台node的节点ip和30000端口
vim /etc/nginx/nginx.conf
events {
worker_connections 1024;
}
#在http块上方,添加stream块
stream {
upstream k8s-nodes {
server 192.168.174.18:30000; #node01IP:nodePort
server 192.168.174.19:30000; #node02IP:nodePort
}
server {
listen 3344; #自定义监听端口
proxy_pass k8s-nodes;
}
}
http {
......
#include /etc/nginx/conf.d/*.conf; #建议将这一行注释掉,否则会同时加载/etc/nginx/conf.d/default.conf文件中的内容,nginx会同时监听80端口。
}
#检查配置文件语法是否正确
nginx -t
#启动nginx服务,查看到已监听3344端口
systemctl start nginx
systemctl enable nginx
netstat -natp | grep nginx
tcp 0 0 0.0.0.0:3344 0.0.0.0:* LISTEN 941/nginx: master p
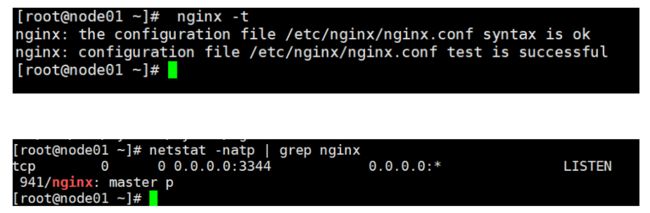
2.两台负载均衡器配置keepalived
#安装keepalived服务
yum install keepalived -y
#修改keepalived配置文件
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
# 接收邮件地址
notification_email {
[email protected]
[email protected]
[email protected]
}
# 邮件发送地址
notification_email_from [email protected]
smtp_server 127.0.0.1 #修改为本机回环地址
smtp_connect_timeout 30
router_id node01 #lb01节点的为node01,lb02节点的为node02
}
#添加一个周期性执行的脚本
vrrp_script check_nginx {
script "/etc/nginx/check_nginx.sh" #指定检查nginx存活的脚本路径
}
vrrp_instance VI_1 {
state MASTER #lb01节点的为 MASTER,lb02节点的为 BACKUP
interface ens33 #指定网卡名称 ens33
virtual_router_id 51 #指定组ID,两个节点要一致
priority 100 #设置优先级,lb01节点设置为 100,lb02节点设置为 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.174.100 #指定VIP地址
}
track_script { #追踪脚本
check_nginx #指定vrrp_script配置的脚本
}
}
#将配置文件中剩余的内容全都删除
#主调度器lb01创建nginx状态检查脚本
vim /etc/nginx/check_nginx.sh
#!/bin/bash
#egrep -cv "grep|$$" 用于过滤掉包含grep 或者 $$ 表示的当前Shell进程ID
count=$(ps -ef | grep nginx | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
systemctl stop keepalived
fi
chmod +x /etc/nginx/check_nginx.sh #为脚本增加执行权限
#启动keepalived服务(一定要先启动了nginx服务,再启动keepalived服务,否则keepalived检测到nginx没有启动,会杀死自己)
systemctl start keepalived
systemctl enable keepalived
ip addr #查看主节点的VIP是否生成
#测试使用VIP:3344访问web网页
curl 192.168.174.100:3344

3.关闭主调度器的nginx服务,模拟故障,测试keepalived
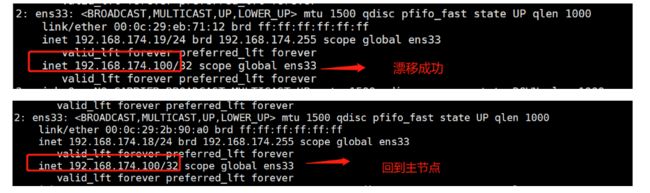
#关闭主调度器lb01的Nginx服务,模拟宕机,观察VIP是否漂移到备节点
systemctl stop nginx
ip addr
systemctl status keepalived #此时keepalived被脚本杀掉了
#备节点查看是否生成了VIP
ip addr #此时VIP漂移到备节点lb02
#恢复主节点
systemctl start nginx #先启动nginx
systemctl start keepalived #再启动keepalived
ip addr
五、配置防火墙服务器
iptables防火墙服务器,设置双网卡,并且配置SNAT和DNAT转换实现外网客户端可以通过12.0.0.1访问内网的Web服务。
- 内网网卡ens33:192.168.174.16
- 外网网卡ens37:12.0.0.1
##两台负载均衡器,将网关地址修改为防火墙服务器的内网IP地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
GATEWAY="192.168.174.16"
systemctl restart network #重启网络
systemctl restart keepalived #如果VIP丢失,需要重启一下keepalived
##配置防火墙服务器
1.关闭防火墙和selinux
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
2.开启路由转发功能
vim /etc/sysctl.conf
net.ipv4.ip_forward = 1 //在文件中增加这一行,开启路由转发功能
sysctl -p //加载修改后的配置
3.配置iptables策略
#先将原有的规则清除
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
#设置SNAT服务,解析源地址。修改nat表中的POSTROUTING链。
#将源地址192.168.174.100转换为为12.0.0.1
iptables -t nat -A POSTROUTING -s 192.168.174.100/24 -j SNAT --to 12.0.0.1
#-t nat //指定nat表
#-A POSTROUTING //在POSTROUTING链中添加规则
#-s 192.168.174.100/24 //数据包的源地址
#-o ens36 //出站网卡
#-j SNAT --to 12.0.0.1 //使用SNAT服务,将源地址转换成公网IP地址。
#设置DNAT服务,解析目的地址。修改nat表中的PRETROUTING链。
#将目的地址12.0.0.1:3344 转换成 192.168.174.100:3344
iptables -t nat -A PREROUTING -i ens37 -d 12.0.0.1 -p tcp --dport 3344 -j DNAT --to 192.168.174.100:3344
#-A PREROUTING //在PREROUTING链中添加规则
#-i ens36 //入站网卡
#-d 12.0.0.254 //数据包的目的地址
#-p tcp --dport 3344 //数据包的目的端口
#-j DNAT --to 192.168.174.100:3344 //使用DNAT功能,将目的地址和端口转换成192.168.174.100:3344
iptables -t nat -nL #查看策略
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DNAT tcp -- 0.0.0.0/0 12.0.0.1 tcp dpt:3344 to:192.168.174.100:3344
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
SNAT all -- 192.168.174.0/24 0.0.0.0/0 to:12.0.0.1
4.新增一台客户机(192.168.174.12)
systemctl stop firewalld.service #关闭防火墙安全机制
setenforce 0
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=b2546c1c-91ee-4caf-b51a-f24baa1c5027
DEVICE=ens33
ONBOOT=yes
IPADDR=12.0.0.12
NETMASK=255.255.255.0
GATEWAY=12.0.0.1
#DNS1=8.8.8.8
systemctl restart network #重启网卡

5.测试
curl 12.0.0.1:3344
