(附12306抢票脚本)国庆长假马上来啦,Python分析【去哪儿旅游攻略】数据,制作可视化图表
目录
- 前言
-
- 环境使用
- 模块使用
- 数据来源分析
- 代码实现
-
- 导入模块
- 请求数据
- 解析
- 保存
- 数据可视化
-
- 导入模块、数据
- 年份分布情况
- 月份分布情况
- 出行时间情况
- 费用分布情况
- 人员分布情况
前言
2023年的中秋节和国庆节即将来临,好消息是,它们将连休8天!这个长假为许多人提供了绝佳的休闲机会,让许多人都迫不及待地想要释放他们被压抑已久的旅游热情,所以很多朋友已经开始着手规划他们的旅游行程。

今天我们来分析下去哪儿的旅游攻略数据,看看吃、住、游玩在价位合适的情况下,怎样才能玩的开心
环境使用
Python 3.8
Pycharm
模块使用
requests
parsel
csv
数据来源分析
明确需求
这次选的月份为10 ~ 12月,游玩费用为1000 ~ 2999这个价位
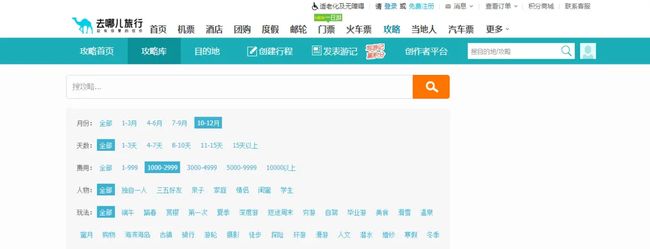
- 抓包分析
按F12,打开开发者工具,点击搜索,输入你想要的数据
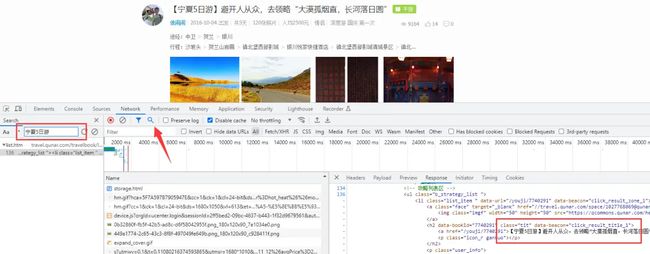
找到数据链接
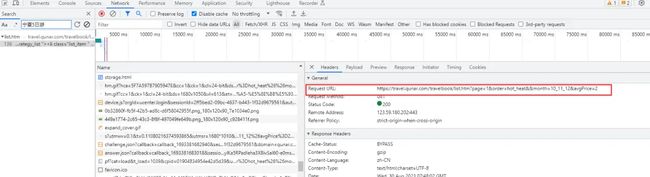
https://travel.qunar.com/travelbook/list.htm?page=1&order=hot_heat&&month=10_11_12&avgPrice=2
代码实现
导入模块
import requests
import parsel
import csv
请求数据
模拟浏览器: <可以直接复制>
response.text 获取响应文本数据
response.json() 获取响应json数据
response.content 获取响应二进制数据
我们使用requests.get()方法向指定的URL发送GET请求,并获取到响应的内容
url = f'https://travel.qunar.com/travelbook/list.htm?page=1&order=hot_heat&&month=10_11_12&&avgPrice=2'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
解析
先取响应文本数据
selector = parsel.Selector(response.text)
css选择器::根据标签属性提取数据内容,看元素面板, 为了帮助找到数据标签,
遇到问题没人解答?可以加小曼vx:python10010 发送验证时记得备注 “M”噢(这样小曼才知道是我的粉丝哦)
寻找有志同道合的小伙伴,互帮互助,还给大家准备了有不错的视频学习教程和PDF电子书!
lis = selector.css('.list_item')
for li in lis:
title = li.css('.tit a::text').get()
user_name = li.css('.user_name a::text').get()
date = li.css('.date::text').get()
days = li.css('.days::text').get()
photo_nums = li.css('.photo_nums::text').get()
fee = li.css('.fee::text').get()
people = li.css('.people::text').get()
trip = li.css('.trip::text').get()
places = ''.join(li.css('.places ::text').getall()).split('行程')
place_1 = places[0].replace('途经:', '')
place_2 = places[-1].replace(':', '')
href = li.css('.tit a::attr(href)').get().split('/')[-1]
link = f'https://travel.qunar.com/travelbook/note/{href}'
dit = {
'标题': title,
'昵称': user_name,
'日期': date,
'耗时': days,
'照片': photo_nums,
'费用': fee,
'人员': people,
'标签': trip,
'途径': place_1,
'行程': place_2,
'详情页': link,
}
print(title, user_name, date, days, photo_nums, fee, people, trip, place_1, place_2, link, sep=' | ')
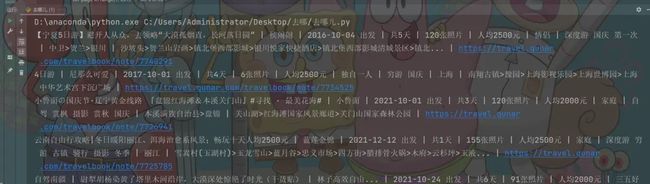
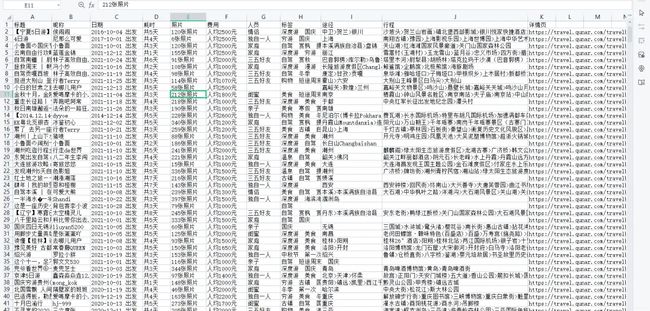
保存
f = open('data.csv', mode='w', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'标题',
'昵称',
'日期',
'耗时',
'照片',
'费用',
'人员',
'标签',
'途径',
'行程',
'详情页',
])
csv_writer.writeheader()
数据可视化
导入模块、数据
import pandas as pd
df = pd.read_csv('data.csv')
df.head()

年份分布情况
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
num = df['年份'].value_counts().to_list()
info = df['年份'].value_counts().index.to_list()
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(
info,
num,
)
],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="年份分布情况"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_scroll_legend.html")
)
c.render_notebook()

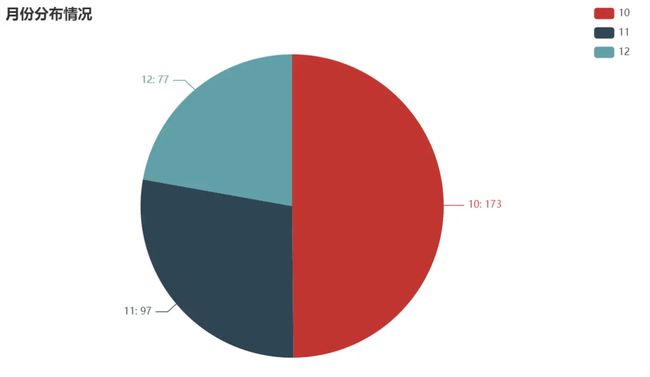
月份分布情况
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
num = df['月份'].value_counts().to_list()
info = df['月份'].value_counts().index.to_list()
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(
info,
num,
)
],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="月份分布情况"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_scroll_legend.html")
)
c.render_notebook()
出行时间情况
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
num = df['耗时'].value_counts().to_list()
info = df['耗时'].value_counts().index.to_list()
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(
info,
num,
)
],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="出行时间情况"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_scroll_legend.html")
)
c.render_notebook()

费用分布情况
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
num = df['费用'].value_counts().to_list()
info = df['费用'].value_counts().index.to_list()
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(
info,
num,
)
],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="费用分布情况"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_scroll_legend.html")
)
c.render_notebook()

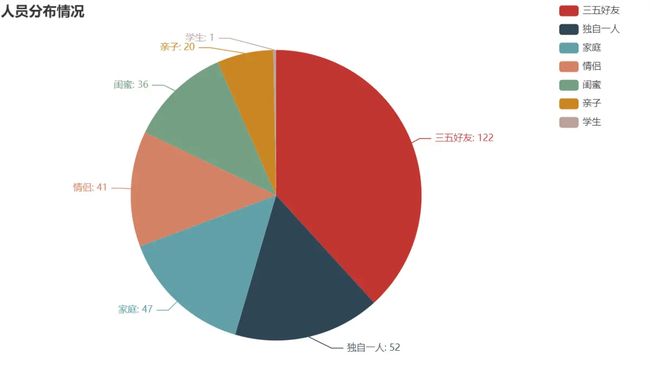
人员分布情况
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
num = df['人员'].value_counts().to_list()
info = df['人员'].value_counts().index.to_list()
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(
info,
num,
)
],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="人员分布情况"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_scroll_legend.html")
)
c.render_notebook()
【全网最通俗易懂】12306自动抢票脚本,100%成功!(附源码)