以爬取中国官网政策为引的爬虫入门笔记
以爬取中国官网政策为引的爬虫入门笔记
我们一般从爬去文本数据、标题、链接最基本的文本的数据并把他们保存在自己的电脑为引子,快速地入门爬虫。用中国官网的消息是因为官网的消息不会被轻易删除或者无效,所以无论什么时候大家看到这篇文章都可以直接用这个代码实验。
我们先来看下我们需要爬去的官网文章。
链接:http://www.gov.cn/zhengce/content/2017-11/23/content_5241727.htm

Request库和自己的User Agent
这里我们我们用到python的一个request库,之所以选择它,是因为这个是最简单的爬虫库之一了。在这个之前我们需要安装这个库,打开终端直接下达安装的指令
pip insatll requests
而什么是User Agent呢?它是你的计算机的一些信息,比如说我们的操作系统、CPU、用的是什么浏览器,基本上这个不太好自己打,你可以在百度搜ua查询,随便点进去一个就可以查,或者可以用我这个也没问题的
Mozilla/5.0(windows NT 10.0;win 64;x64)\AppleWekit/537.36(KHTML,like Gecko)Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063
import requests
#我们的电脑信息
user_agent='Mozilla/5.0(windows NT 10.0;win 64;x64)\AppleWekit/537.36(KHTML,like Gecko)Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'
headers={'User-Agent':user_agent}
#我们需要的网址
r=requests.get("http://www.gov.cn/zhengce/content/2017-11/23/content_5241727.htm")
#这里是编码方式,后面需要专门讲
r.encoding='utf-8'
打印我们的文本信息来看下
print(r.text)

使用BeautifulSoup进行HTML解析
这里上面是不是很复杂,那我们先从简单的开始,python有两个用于HTML的解析的库,分别是lxml 和BeautifulSoup。用哪个都行,用这个解析后网站的参数会变得很清晰。首先我们需要安装这个库,还是老样子在终端上输入pip install beautifulsoup4
接下来我们往python里面输入这个代码
from bs4 import BeautifulSoup
soup=BeautifulSoup(r.text,'lxml',from_encoding='utf8')
print(soup)
你会看到这个原本混乱的页面变得更加清晰,出现了tittle、content等字眼

这个时候我们想要来打印比如说标题、文章和链接都可以
打印标题
print(soup.title.string)
国务院办公厅关于创建“中国制造2025”国家级示范区的通知(国办发〔2017〕90号)_政府信息公开专栏
In [16]:
打印某个段落
print(soup.p.string)
国务院办公厅关于创建“中国制造2025”
In [17]:
打印全片文章
texts=soup.find_all('p')
for text in texts:
print(text.string)

打印链接
link=soup.find_all('a')[-1]
print(link.get('href'))
http://www.gov.cn/home/2014-02/18/content_5046260.htm
平时要粘贴复制的这些都我们都可以简单地实现了,那么接下来我们变得更复杂些。
进阶的爬取
分析结构
我们先来打开官网,大概是这样子的
http://www.gov.cn
那好,我们先来理解下链接
这个是官网的链接
http://www.gov.cn
这个文章是在官网的政策分栏里面的
http://www.gov.cn/zhengce
这个就是文章的地址了
http://www.gov.cn/zhengce/content/2017-11/23/content_5241727.htm
这里我们可以清楚地看到,网页是层层深入的,不同的页面用/分开
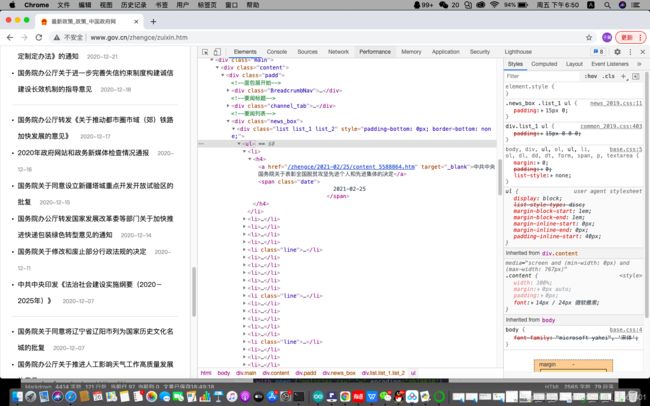
这个就是最简单的网页链接认识,接下来我们更深入一点,我们来看下前端的一些内容,这里你需要选择向谷歌或者其他可以有“检查”功能的浏览器。

就可以直接看到页面的构成了,我们基本上的爬虫都要对这里进行分析。

那好接下来我们就来爬去最新资讯的里面所有的标题和链接,好,我们直接给出最新政策这个网址
http://www.gov.cn/zhengce/zuixin.htm
我们也是点开检查,这里的很友好,直接就可以看到“要问列表”,直接点开
- ,我们又可以有个
- 可以点,最后是
,那里已经是有我们的新闻标题,现在我们就把这个标题和链接抓来做一个CSV(ecxel)表
#导入request
import requests
#导入CSV我们到时要保存为csv
import csv
#导入BeautifulSoup
from bs4 import BeautifulSoup、
#导入正规表达,这里是用来让我们的文字更加准确
import re
#我们的个人电脑信息
user_agent='Mozilla/5.0(windows NT 10.0;win 64;x64)\AppleWekit/537.36(KHTML,like Gecko)Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'
headers={'User-Agent':user_agent}
policies=requests.get("http://www.gov.cn/zhengce/zuixin.htm")
#这里指定我们的编码方式,下次找个机会来讲
policies.encoding='utf-8'
#用这个来解析lxml
p=BeautifulSoup(policies.text,'lxml')
#这里是来处理我们爬下里的文本,让他们更加准确
contents=p.find_all(href=re.compile('content'))
3定义一个空列表
rows=[]
#循环,对每一个链接和标题提取
for content in contents:
href=content.get('href')
row=('国务院',content.string,href)
rows.append(row)
#定义CSV的表头
header=['发文部门','标题','链接']
#建立一个文件,以写入模式打开
with open ('policies.csv','w',encoding='gb18030')as f:
f_csv=csv.writer(f)
f_csv.writerow(header)
f_csv.writerows(rows)
print('\n\n最新的信息获取完成\n\n')
打开你选择保存的位置就可以看到很多链接了。

笔记总结自
《深入浅出 python机器学习》–段小手