【多模态】AIGC论文笔记整理(持续更新)
AIGC
- Diffusion Models
-
- 【202012】Denoising Diffusion Probabilistic Models(DDPM)
- 【202102】Improved Denoising Diffusion Probabilistic Models(Improved DDPM)
- 【202103】Learning Transferable Visual Models From Natural Language Supervision(CLIP)
- PS:扩散模型条件生成的有分类器引导和无分类器引导
- 【202112】GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models(GLIDE)
- 【202204】Hierarchical Text-Conditional Image Generation with CLIP Latents(DALL-E2 / unCLIP)
- 【202205】Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding(Imagen)
- 【202210】High-Resolution Image Synthesis with Latent Diffusion Models(LDM、Stable Diffusion)
- 【202302】Adding Conditional Control to Text-to-Image Diffusion Models(ControlNet)
Diffusion Models
【202012】Denoising Diffusion Probabilistic Models(DDPM)
链接:https://arxiv.org/pdf/2006.11239.pdf
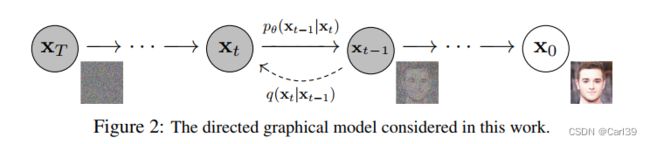
DDPM是最基本的扩散模型,其架构如下图所示。从图中可以看到,其训练分为前向和反向两个过程(图中为推断时的顺序,和训练时相反,此处的“前向”指从x0到xT,“反向”指从xT到x0)。图中的每一个状态xt也被称为step。
在前向过程中,在每两个step之间都加入微小的随机噪声,通过不断地加入(图中是共计加入T次),使原始清晰图像x0最终转化为随机噪声图片xT,这也就是此类模型被称为“扩散”模型的原因。在反向过程中,通过训练神经网络(通常是UNet结构)来拟合前向过程中加入的噪声的分布,试图在每两个step之间消除在前向过程中加入的随机噪声,使图像恢复到添加噪声之前的状态,也就是去噪。
简单的公式推导过程如下:
(部分贴图来自https://zhuanlan.zhihu.com/p/617895786,已获得作者授权)
在前向传播过程中,从step xt-1到xt之间的映射关系可以表示为
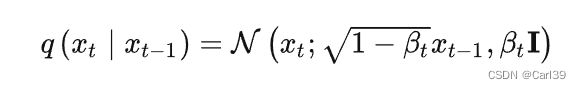
其中βt表示噪声控制系数,其值处于0-1之间并在前向过程中逐渐增大,DDPM原文采用的是线性的增加策略。
基于高斯分布的可叠加性,从x0到xt的映射可以表示为

现在,我们设

经过数学推导,最后得到

其中 α t ‾ \overline{α_t} αt表示从step 1到step t的累积衰减系数, z t ‾ \overline{z_t} zt表示从step 1到step t的累积噪声。
从该式可以看出,现在我们可以通过这一个通用的公式从 x 0 x_0 x0一步计算出任何step x t x_t xt的分布,而不需要进行多次的累加。这个式子方便我们之后用于计算损失函数。
在前向过程中,我们给出了每一步映射q( x t x_t xt| x t − 1 x_{t-1} xt−1)的表达式,而在反向过程中,我们需要知道q( x t − 1 x_{t-1} xt−1| x t x_{t} xt),这样我们就能从 x t x_{t} xt去除掉前向过程添加的噪声,得到 x t − 1 x_{t-1} xt−1,经过多个这样的step最终得到输入 x 0 x_{0} x0。但这个转移概率是无法直接计算得到的,故只能通过神经网络去拟合这个分布。我们将神经网络拟合的这个映射设为 p θ ( x t − 1 ∣ x t ) p_θ(x_{t-1}|x_{t}) pθ(xt−1∣xt),易证这个分布也是高斯分布,我们将其表示为:
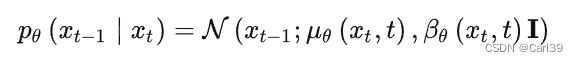
其中 μ θ ( x t , t ) μ_θ(x_t, t) μθ(xt,t)、 β θ ( x t , t ) β_θ(x_t, t) βθ(xt,t)就是神经网络要学习的均值系数和方差系数。经过数学推导,最终得到

可以看到这个式子中间的表达式带有波浪线,所以这一步推导其实包含了一定的近似性假设。在训练阶段,式中所有的α、β都是已知的,因此现在神经网络只要学习拟合前向过程中累积的噪声分布 z t ‾ \overline{z_t} zt即可。
我们还可以观察到一个细节,就是此时 μ θ ( x t , t ) μ_θ(x_t, t) μθ(xt,t)是可学习的,而 β θ ( x t , t ) β_θ(x_t, t) βθ(xt,t)是一个已知确定的结果,也就是不可学习的,而这也是后续Improved DDPM改进的切入点。
综合上面的结果,我们最终得到损失函数为

其中 z t ‾ \overline{z_t} zt是从 x 0 {x_0} x0到 x t {x_t} xt的累积噪声分布(已知), z θ {z_θ} zθ是神经网络学习的噪声分布。
附上原文中给出的训练和推断过程的伪代码:

其中 ε ε ε、 ε θ ε_θ εθ分别对应上述公式中的 z t ‾ \overline{z_t} zt、 z θ {z_θ} zθ。

其中σ表示标准差,等于 β θ ( x t , t ) \sqrt{β_θ(x_t, t)} βθ(xt,t)。
【202102】Improved Denoising Diffusion Probabilistic Models(Improved DDPM)
链接:https://arxiv.org/pdf/2102.09672.pdf
本文相对DDPM做出2点改进:
- 将方差设置为可学习参数
- 将方差系数变化模式由线性变化改为余弦变化
在DDPM中,我们认为方差 β θ ( x t , t ) β_θ(x_t, t) βθ(xt,t)近似等于式

而作者指出,这个系数随着训练过程中步数的变化情况如图所示:

可见,当一开始训练的时候,β的权重值很小,均值所占的比重更大;而当训练了几个step后,β的权重又几乎保持不变,导致方差对最终学习结果的贡献也很有限,也就是说在DDPM的整个训练过程中方差的左右都不大,而且这个现象T越大表现得越严重。
因此,本文提出使用新的可学习的β来改善这一现象,新的方差表示为
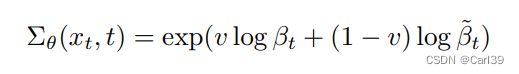
之后,针对新的方差,我们还要设置新的损失函数(因为DDPM中原先的损失函数无法更新方差),为

其中 L s i m p l e {L_{simple}} Lsimple就是原DDPM的损失函数,而 L v l b {L_{vlb}} Lvlb是新加入的惩罚项,λ是惩罚项系数,文中将其设置为0.001。 L v l b {L_{vlb}} Lvlb的定义如下,为每个step估计转移概率和实际转移概率的KL散度(相对熵)的和。

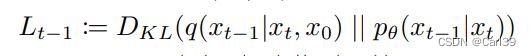
此外作者还指出,原DDPM的方差系数中 α t ‾ \overline{α_{t}} αt设置为线性变化,这导致在前向过程中加噪的速度偏快。将其设置为余弦变化会使噪声的变化过程更为平缓,有利于训练的收敛。线性变化和余弦变化下 α t ‾ \overline{α_{t}} αt随时间步的变化对比如下所示:

从可视化对比也可以直观的看出余弦变化相比线性变化更为缓慢,在中间的时间步能保留更多原图像信息。

【202103】Learning Transferable Visual Models From Natural Language Supervision(CLIP)
链接:https://arxiv.org/pdf/2103.00020.pdf
CLIP被称为是连接语言与视觉的模型,它实现了文本和图像信息的对齐。
CLIP是为了解决大型数据集中图像-文本配对问题而提出的。其原理比较简单易懂,如下图(1)描述了其训练过程,其核心思想便是将N个文本-图像对拆分,分别输入text encoder和image encoder进行特征提取,并将得到的两组归一化编码结果两两之间计算余弦相似性,得到N*N的矩阵。原先配对的文本-图像之间应当具有较高的相似性(对角线元素),而不同组的文本和图像之间相似性较低。
图(2)描述了CLIP的主要应用——(零样本)数据分类,对于大型的数据集或者无序的文本-图像对,使用CLIP可以快速实现分类和划分。

PS:扩散模型条件生成的有分类器引导和无分类器引导
在分析GLIDE之前,首先要明确一下扩散模型有分类器引导和无分类器引导的概念。
前面所讲述的DDPM和Improved DDPM都是无条件引导的生成,即当模型训练好后,只要给出一张纯噪声的图像,无需任何额外条件,便能通过反向扩散就能得到一张清晰图像。但在实际应用中,我们更需要的是模型能够根据我们的想法和实际需求生成我们想要的类别或风格的图像,比如一组动物的图片,或者是一组油画风格的图片,等等。这个时候我们就需要向扩散模型中加入相应的条件控制信息,来“引导”扩散模型生成我们想要的效果。
有条件引导生成又根据引入条件方式的不同,分为有分类器引导和无分类器引导两种。有分类器引导的核心思路是使用额外的分类网络对扩散模型逆向每一步的生成结果进行分类,对每个类别通过交叉熵损失计算梯度,并利用这个梯度更新当前模型,引导下一步的条件生成。代表性的方法有Guided Diffusion(类别引导)、Semantic Guidance Diffusion(文本或图像引导)等。有分类器引导不需要改变原有模型的架构,只要将现有模型组合在一起使用即可,比较方便,但其问题也很明显,首先是训练时间和空间上的显著增加,同时扩散模型和引导模型始终是两个独立的整体,当模型体量变大后,不利于联合训练。
因此无分类器引导的条件生成方法被提出,其核心思想是将条件信息直接作为扩散模型逆向神经网络的参数植入,也就是将原 ε θ ( x t ) {ε_θ(x_t)} εθ(xt)转变为 ε θ ( x t , y ) {ε_θ(x_t, y)} εθ(xt,y)(y代表条件信息)。这样,整个有条件扩散模型就成为了一个统一的整体。此外,若要进行无条件生成时,也只需要将y设置为NULL即可。相比有分类器引导,无分类器引导的扩散更有利于模型规模的扩大,且实验证明具有相对更好的生成效果,但相对需要更大的训练成本。
【202112】GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models(GLIDE)
链接:https://arxiv.org/pdf/2112.10741.pdf?trk=cndc-detail
GLIDE是一个基于DDPM架构改进而来的无分类器引导的条件生成模型,它维持了原DDPM扩散模型的架构,但是大幅加大了模型的尺寸(3.5B)。同时,重新定义网络映射函数,改为带有条件信息的版本,是第一个基于扩散模型的文生图模型。GLIDE沿用了最开始提出无分类器引导论文中的表达式,即

其中y表示条件信息,Ø表示条件信息为空,即无条件引导。
对于式子里的条件信息y,GLIDE的获取方式是将文本信息tokenize后输入一个text encoder(作者使用的ADM结构,text encoder是transformer)做编码,之后将输出结果的最后一个token embedding作为类别信息进行引导,也就是y。此外,作者还将最后一层输出的embedding(token数量个vector)映射到ADM的所有注意力层,以强化对条件信息的学习。
作者之后比较了由CLIP作为分类器引导的模型和GLIDE,也就是无分类器引导模型的表现,结果显示不论是人工打分还是自动打分,GLIDE的效果都要更好一些。
【202204】Hierarchical Text-Conditional Image Generation with CLIP Latents(DALL-E2 / unCLIP)
链接:https://arxiv.org/pdf/2204.06125.pdf
DALL-E2,也被称为unCLIP,是一个两阶段的生成模型,其训练共分成三步,通过多个模块分别训练并最终组合在一起实现文生图的任务。
DALL-E2的结构如下图所示,由虚线划分为两个部分。其中虚线上方的部分采用了和CLIP完全一样的结构和方法,即输入文本-图像对训练text encoder和image decoder,通过计算生成文本编码和图像编码之间的相似度实现文本和图像的对齐,这是该模型训练的第一步。
在虚线下方的部分中,首先通过上述训练好的CLIP生成text latents和image latents(一一对应),然后,将text latents作为condition,训练一个自回归(Autoregressive)或者扩散模型prior学习从text latents到image latents的映射(文中实验表明二者表现相近,但扩散模型效率更高一些),这是模型训练的第二步。不难发现,第一步训练CLIP其实是为了给第二步学习先验映射提供数据样本支撑。
最后,将CLIP image encoder生成的image latents作为condition,训练一个基于扩散模型的decoder,使得可以利用image latents conditional prompt从噪声图像生成我们想要的,和text latents对应的图像,这是模型训练的第三步。
最终,在完成所有三步训练后,将训练好的模型组合在一起,我们就得到了一个完整的文生图模型。
DALL-E2可以胜任多种图像生成任务,但作者在文中也提到DALL-E2有以下几个缺点:
- 容易将物体和属性混合,原因可能在于CLIP没有将物体和属性进行绑定。
- 将文本放入图像的能力不足,可能是因为CLIP无法获取单词拼写的信息。
- 在生成复杂场景时细节有缺陷,通过加大图像尺度可以一定程度上解决这个问题,但相对需要更大的训练成本。
【202205】Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding(Imagen)
链接:https://proceedings.neurips.cc/paper_files/paper/2022/file/ec795aeadae0b7d230fa35cbaf04c041-Paper-Conference.pdf
Imagen和GLIDE一样,都是在扩散模型图像生成的像素层级上引入额外信息的方法。Imagen的结构非常简洁直观,如图:

其核心思想是,对于输入文本,首先使用一个冻结参数(不参与训练)的text encoder编码。本文经过和BERT、CLIP对比后,最终选用的是预训练过的T5(参数量11B)。之后,编码结果将首先通过一个小尺寸的扩散模型做生成,得到一个小尺度的图像。然后依次通过两个扩散模型做两次超分,最后得到目标大尺度图像。同时,文本编码结果会被分别添加到三组扩散模型中,保证引导信息不被丢失和稀释。
对于第一个做图像生成的扩散模型,采用传统的64*64大小的UNet结构。而对于之后的两个执行图像超分的扩散模型,使用了名为Efficient UNet的改进UNet结构,实现了更快的推理速度和更低的内存消耗。
Imagen在生成部分定义的神经网络映射函数,可以看出和GLIDE的定义如出一辙。

【202210】High-Resolution Image Synthesis with Latent Diffusion Models(LDM、Stable Diffusion)
链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf
大名鼎鼎的Stable Diffusion是第一个“火出圈”的,将扩散模型概念带入大众视野的应用。其底层原理便是本文所提出的,与上述在图像层次引入额外信息相对的,改为在隐空间引入额外信息的LDM(Latent Diffusion Models)结构,Stable Diffusion是该结构的最佳实践。LDM的原理图如下:

不难看出,LDM和之前提出的扩散模型最本质的区别就在于左侧红色的部分,通过在前向输入图像和反向输出图像的两端分别添加一个encoder ε和decoder D的方式,将图像从原先高维度的像素层次先映射到低维度的隐空间向量层次,之后再在像素层次进行扩散,这样不仅使得模型的训练和推断维度得到大幅下降,从而显著降低了对算力的要求并大幅提升图像生成效率,此外,在隐空间上加入条件控制信息相比在高维像素层次也更为有效。
对于隐空间上的扩散模型,在两个step之间仍然采用的是DDPM经典的UNet+Attention的Auto Encoder-Decoder结构。同时,本文正式提出了“条件”的概念,将semantic map、text、representation、images等额外控制信息统称为条件,它们分别经过各自对应的编码器实现编码,和输入图像的隐空间表示 Z T {Z_T} ZT concat控制扩散模型的条件生成。
【202302】Adding Conditional Control to Text-to-Image Diffusion Models(ControlNet)
链接:https://arxiv.org/abs/2302.05543
ControlNet是一个端到端的神经网络架构,其主要为解决AIGC的可控生成问题而提出,使得用户可以根据需要向扩散模型中加入额外的条件控制信息,对生成的图像做出进一步的规范和限制。ControlNet可用于解决特定问题领域图像数据集稀少、低质量或缺失的问题。

ControlNet并非一个独立的模型,而是作为外挂组件和现有的扩散模型架构(如Stable Diffusion等)组合,帮助原网络学习到新加入的额外条件控制信息。如下图(a)所示,左侧是传统的神经网络块,输入特征图x,得到输出y。而加入ControlNet结构后,如下图(b)所示,ControlNet段额外引入了一个条件控制信息c(可以是上图中的素描稿、边信息或人类动作信息等),同时引入一个新的结构——zero convolution,一个1x1的初始权重为0的卷积层。在ControlNet中,我们复制一份原先网络架构的参数,称为“trainable copy”,同时将原先的参数冻结,称为“locked copy”,如此便定义了一个简单的ControlNet结构。

在本文中,作者将ControlNet应用于Stable Diffusion模型进行训练和测试,每个step之间的整体结构如下图所示。使用的原Stable Diffusion结构包含4个encoder block和4个decoder block(每个block中有3层)以及一个middle block,对每个block加入text prompt和time prompt。引入的ControlNet架构每层的大小和数目被设置成与SD一致,同时引入额外的condition prompt用于可控条件生成。

额外的,作者提到了几个tricks:
- 训练时随机将50%的text prompt替换成空字符串,可以促使模型更好的学习到condition prompt中的语义信息。
- 计算资源不足导致小尺度训练时,可以切断一部分ControlNet和SD之间的连线,以使模型更快的达到收敛。
- 计算资源和数据集充足,进行大规模训练时,可以先训练ControlNet中的参数,之后将原SD中的神经网络参数解冻一同训练,可以达到更好的效果。
以上述模型进行实验,结果如图所示。按列从左到右分别是输入的condition prompt sample、无text prompt / 空字符串、由caption算法自动生成的prompt、以及用户自定义的prompt。
此外,作者还指出,结合了ControlNet的新模型相比于原不带ControlNet结构的纯Stable Diffusion模型仅额外占用23%的显存和34%的训练时间(在A100 40g单卡上的测试结果)。