C++ 【 类和对象 】【 第二回 】
验证环境 vs2022 x86
目录
1. 面向过程和面向对象的认知
1.1 面向对象和面向过程的区别
1.1.1 面向过程
1.1.2 面向对象
2. 类
2.1类的引入
2.2 类的定义
2.2.1 定义类的方式
2.2.2 C++封装特性
2.2.3 class 和 struct区别
2.3 类的作用域
2.4类的实例化
3. 类对象模型
3.1 计算类对象的大小
3.1.1 结构体内存对齐问题
3.1.2 空类的大小
4. this指针
4.1 this 指针的特性
4.1.1 不定参数
4.2 函数调用约定
4.2.1 __cdecl调用约定
4.2.2 __thiscall调用约定
4.3 this 的存储
4.4 this为空
5. 类的6个默认成员函数
6. 构造函数
6.1 构造函数的特性
7. 析构函数
7.1 析构函数的特性
8. 拷贝构造函数
8.1 拷贝构造函数的特性
8.2 拷贝构造函数的调用时机
8.2.1 用一个对象直接构造一个新对象
8.2.2 以类类型方式传参--以值的方式
8.2.3 以类类型方式作为函数的返回值---以值的方式返回的
1. 面向过程和面向对象的认知
- C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用逐步解决问题。
- C++是基于面向对象的,关注的是对象,将一件事情拆分成不同的对象,靠对象之间的交互完成。
1.1 面向对象和面向过程的区别
1.1.1 面向过程
把一个事件分析成一个个流程,比如把大象放进冰箱,就需要三步
1.打开冰箱
2.把大象放进去
3.关上冰箱门
我放一只大象这还不简单,每一步操作写一个函数不就完事了,碰见一个问题把他分解为许多的小问题,一个小问题对应一个函数,写出函数依次调用它就完事了,看上去是十分的完美的解决问题的办法,那我现在要装100,1000个大象呢?害这有啥的我有函数呀我调用1000次10000次呀,这样的话代码的耦合度是非常高的,那怎么解决呢?
1.1.2 面向对象
当前问题中设计那些对象,把他一个个抽象出来,比如这个装大象这个例子,我们就能具体抽象出来一个对象就是冰箱,我想要计算机解决这个问题,那就要先通过我们要解决的问题,对冰箱有一个宏观的认知,那我这冰箱能干哈呢?
1.开门
2.装大象
3.关门
这三个是我冰箱会干的事情,是冰箱解决当前问题的方法,我要装大象的时候我拿个冰箱就好了,我能通过冰箱这个对象来解决问题,我设计冰箱的时候结合我的需求,以及我对冰箱的宏观认知,制作了一个冰箱说明书,我以后的冰箱就应该按照这个说明书来造,这个说明书就是类,通过这个说明书生产出来的冰箱就是对象,或者叫做类的实例,生产冰箱这一个过程叫做类的实例化
2. 类
2.1类的引入
我们在之前用C实现过Stack这个自定义数据类型,我们在回顾一下。
#include
#include
typedef int DataType;
typedef struct Stack
{
DataType* array;
int capacity;
int top;
}Stack;
void StackInit(Stack* ps)
{
assert(ps);
ps->array = (DataType*)malloc(sizeof(DataType) * 3);
if (NULL == ps->array) {
assert(0);
}
ps->capacity = 3;
ps->top = 0;
}
void StackCheckCapacity(Stack* ps)
{
assert(ps);
if (ps->top == ps->capacity)
{
int newCapacity = (ps->capacity << 1);
DataType* temp = (DataType*)malloc(sizeof(DataType) * newCapacity);
if (NULL == temp) {
assert(0);
}
memcpy(temp, ps->array, sizeof(DataType) * ps->capacity);
free(ps->array);
ps->array = temp;
ps->capacity = newCapacity;
}
}
void StackPush(Stack* ps, DataType data)
{
StackCheckCapacity(ps);
ps->array[ps->top] = data;
ps->top++;
}
void StackPop(Stack* ps)
{
if (StackEmpty(ps)) {
return;
}
ps->top--;
}
DataType StackTop(Stack* ps)
{
assert(ps);
return ps->array[ps->top - 1];
}
int StackSize(Stack* ps)
{
assert(ps);
return ps->top;
}
int StackEmpty(Stack* ps)
{
assert(ps);
return 0 == ps->top;
}
void StackDestroy(Stack* ps)
{
assert(ps);
if (ps->array)
{
free(ps->array);
ps->capacity = 0;
ps->top = 0;
}
} 在C语言中数据和操作数据的方法是分离开的,也就是结构体里面不能写函数。

在C++中可以将数据 和 操作数据的方法集合到一块在结构体中定义函数,C语言的结构体中只能放变量不能放函数
#include
#include
#include
using namespace std;
typedef int DataType;
typedef struct Stack
{
DataType* array;
int capacity;
int top;
int StackEmpty(Stack* ps)
{
assert(ps);
return 0 == ps->top;
}
void StackInit(Stack* ps)
{
assert(ps);
ps->array = (DataType*)malloc(sizeof(DataType) * 3);
if (NULL == ps->array) {
assert(0);
}
ps->capacity = 3;
ps->top = 0;
}
void StackCheckCapacity(Stack* ps)
{
assert(ps);
if (ps->top == ps->capacity)
{
int newCapacity = (ps->capacity << 1);
DataType* temp = (DataType*)malloc(sizeof(DataType) * newCapacity);
if (NULL == temp) {
assert(0);
}
memcpy(temp, ps->array, sizeof(DataType) * ps->capacity);
free(ps->array);
ps->array = temp;
ps->capacity = newCapacity;
}
}
void StackPush(Stack* ps, DataType data)
{
StackCheckCapacity(ps);
ps->array[ps->top] = data;
ps->top++;
}
void StackPop(Stack* ps)
{
if (StackEmpty(ps)) {
return;
}
ps->top--;
}
DataType StackTop(Stack* ps)
{
assert(ps);
return ps->array[ps->top - 1];
}
int StackSize(Stack* ps)
{
assert(ps);
return ps->top;
}
void StackDestroy(Stack* ps)
{
assert(ps);
if (ps->array)
{
free(ps->array);
ps->capacity = 0;
ps->top = 0;
}
}
}Stack;
int main()
{
Stack s;
s.StackInit(&s);
s.StackPush(&s, 1);
s.StackPush(&s, 2);
s.StackPush(&s, 3);
s.StackPush(&s, 4);
cout << s.StackTop(&s) << endl;
cout << s.StackSize(&s) << endl;
return 0;
} 我定义了一个Stack 类型的变量s 使用 s 内的成员方法,如果在C语言的思维中就是这样写的,但是这样子是很怪的,我s 里面的方法 然后传进去s地址进行操作。那我们再将代码优化一下。
#include
#include
#include
#include
using namespace std;
typedef int DataType;
struct Stack
{
DataType* array;
int capacity;
int top;
void StackInit()
{
array = (DataType*)malloc(sizeof(DataType) * 3);
if (NULL == array){
assert(0);
}
capacity = 3;
top = 0;
}
void StackCheckCapacity()
{
if (top == capacity)
{
int newCapacity = (capacity << 1);
DataType* temp = (DataType*)malloc(sizeof(DataType) * newCapacity);
if (NULL == temp) {
assert(0);
}
memcpy(temp, array, sizeof(DataType) * capacity);
free(array);
array = temp;
capacity = newCapacity;
}
}
void StackPush(DataType data)
{
StackCheckCapacity();
array[top] = data;
top++;
}
void StackPop()
{
if (StackEmpty()) {
return;
}
top--;
}
DataType StackTop()
{
return array[top - 1];
}
int StackSize()
{
return top;
}
int StackEmpty()
{
return 0 == top;
}
void StackDestroy()
{
if (array)
{
free(array);
capacity = 0;
top = 0;
}
}
};
int main()
{
Stack s;
s.StackInit();
s.StackPush(1);
s.StackPush(2);
s.StackPush(3);
s.StackPush(4);
cout << s.StackTop() << endl;
cout << s.StackSize() << endl;
return 0;
} 这样就对这个对象进行操作了, 用struct定义的Stack在C++中就是一个类,类实际也是一种自定义类型,可以用Stack来定义变量,在C++中用自定义类型创建出来的变量一般将其称为对象,不过在C++中更喜欢用Class来定义类,
2.2 类的定义
#include
using namespace std;
typedef int DataType;
class Stack
{
//类中数据 一般称为类的属性 ,或者成员变量
DataType* array;
int capacity;
int top;
//类中方法或者函数 一般称类的行为,或者成员函数
void StackInit(){}
void StackCheckCapacity(){}
void StackPush(DataType data){}
void StackPop(){}
DataType StackTop(){}
int StackSize(){}
int StackEmpty(){}
void StackDestroy(){}
}; - C++ 中struct 和 class 都是定义类的关键字
- class 和 struct 后面跟的是类的名字 {}里面是类的主体,{}后面要跟;
- 类中的数据,一般被称为类的属性,或者叫做类的成员变量。
- 类中的方法或者函数,一般被称为是类的行为,或者类的成员函数。
2.2.1 定义类的方式
1.声明和定义在类体中
#include
using namespace std;
//声明和定义全部放在类体中间
class Student
{
char _name[20];
char _gender[3];
int _age;
char _school[20];
void Init(char name[], char gender[], int age, char school[]){
strcpy(_name, name);
strcpy(_gender, gender);
_age = age;
strcpy(_school, school);
}
void DoClass(){
cout << _name << "在上课呢" << endl;
}
void DoHomeworlk(){
cout << _name << "在写作业呢" << endl;
}
void DoExam(){
cout << _name << "在考试呢" << endl;
}
}; 注意:有时候传入的参数和你的成员变量同名,假如你想把传入的参数赋值给成员变量,age = age 这条语句写出来之后是到底是想将成员变量赋值给形参,还是想将形参赋值给成员变量就说不清了,所以我们常常采用对成员函数在命名的时候加一点操作,一方面没有破坏见名知意,一方面又解决了二义性的问题。
_name
name_
m_name2.声明和定义分开
#include
using namespace std;
#include
#pragma warning(disable:4996)
//声明和定义直接分开
class Student
{
string _name;
string _gender;
int _age;
string _school;
void Init(string name, string gender, int age, string school);
void DoClass();
void DoHomeworlk();
void DoExam();
};
//通过作用域运算符 :: 来告诉编译器是类内成员函数
void Student:: Init(string name, string gender, int age, string school){
_name = name;
_gender = gender;
_age = age;
_school = school;
}
void Student::DoClass() {
cout << _name << "在上课呢" << endl;
}
void Student::DoHomeworlk() {
cout << _name << "在写作业呢" << endl;
}
void Student::DoExam() {
cout << _name << "在考试呢" << endl;
}
int main()
{
Student s1;
s1.Init("小明", "女", 12, "阳光中学");
s1.DoClass();
} 通过作用域运算符 ::进行操作,如果不添加就是全局作用域下的函数,就不是类内的成员函数了,就跟类没有关系了。
F5跑一下就有问题了
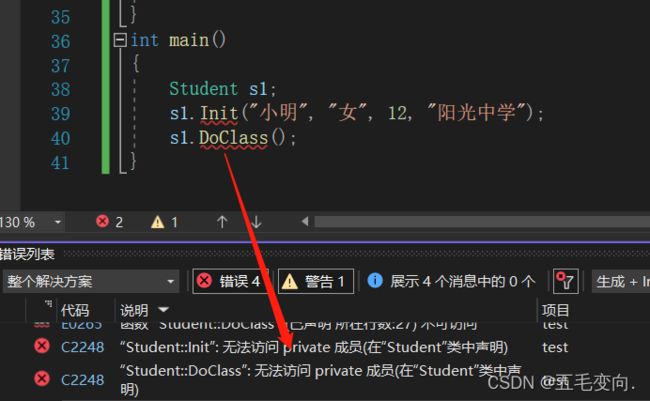
为啥是不可访问呢?我们类都定义好了。
2.2.2 C++封装特性
在C++中为了给类中的成员变量和成员函数,有一定的保护作用 就给了类中成员函数,和成员变量设置了访问权限,public ,protected ,private。
面向对象程序设计的三大特性:
封装,继承,多态,(抽象)
这块我们先谈谈封装:
举个例子,我们使用的电脑主机箱,里面有主板,显卡,cpu,内存条,风冷,水冷……
主机箱,有HDMI接口,雷电3接口,电源按键,3.5mm耳机接口,DP接口……这些接口却暴漏在外。
用主机箱将这些内部零件包装起来的原因是:
1. 安全不想让用户直接修改,或者不经意间就给破坏掉。
2. 不想让用户看见内部构造。
那C++是如何实现封装的特性的呢?
总而言之封装就是将数据和操作数据的方法,也就是成员变量和成员函数进行结合,隐藏对象属性和实现的过程细节,仅仅对外公开接口让你使用,和对象进行交互,成员函数和成员变量的结合就是类的作用,隐藏对象的属性和实现的过程细节是访问权限来控制的。
访问限定符:
1.public (公有) 形象一点也就是公交车,我谁都可以坐公交车。
类外可以访问成员变量和成员函数,类内也可以访问成员变量和成员函数。
2.protected(保护) 也就是通勤车,你属于这个单位,你才能上车。
类外不可以访问,只有在类内可以访问成员变量跟成员函数。
3.private(私有) 也就是私家车,这个车是我自己的车,只有我自己能上
类外不可以访问,只有在类内可以访问成员变量跟成员函数。
4.访问限定符的作用域是从这个限定符开始到下一个限定符出现为止。
这protected 跟 private 不是一样的吗这咋非要弄两个,其实在后面继承就能看出来差异性了。
还是刚刚的例子我把school给成private来看看。

我们的name是可以打印出来的但是school不行因为两个成员变量的访问权限不同!
2.2.3 class 和 struct区别
我们刚刚谈到struct 和 class 都可以来定义类,这俩有啥区别呢?
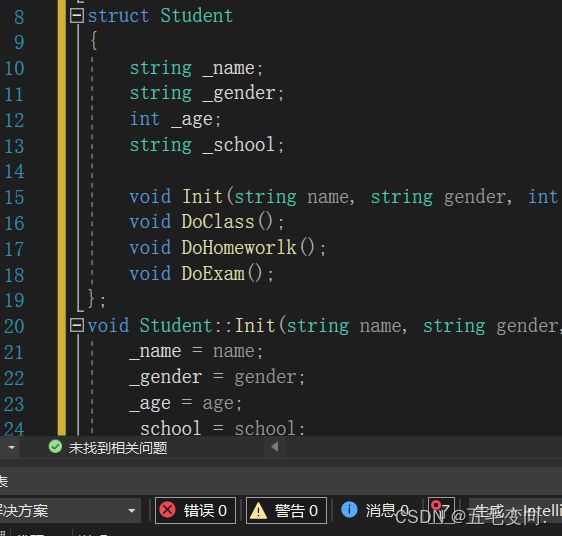

不可访问,那就应该是访问权限的问题了!
- 用class定义的类:默认的访问权限就是private
- 用struct定义的类:默认的访问权限就是public
2.3 类的作用域
类定义了一个新的作用域,类的所有成员都在类的作用域中。在类体外定义成员,需要使用 :: 作用域运算符指明成员属于哪个类域。
就好比刚刚在类内定义成员函数,然后类外声明。就是用到了作用域运算符。
2.4类的实例化
回到我们一开始的把大象装进冰箱,我们的面向对象的方法,不就是要设计出来对应的说明书按照这个说明书生产出来的就是我们要的冰箱也就是类的实例化。
类:
- 类是对对象进行描述的。
- 类也是一种自定义类型。
- 类是一种类型,那么类中间就不能直接存储数据。
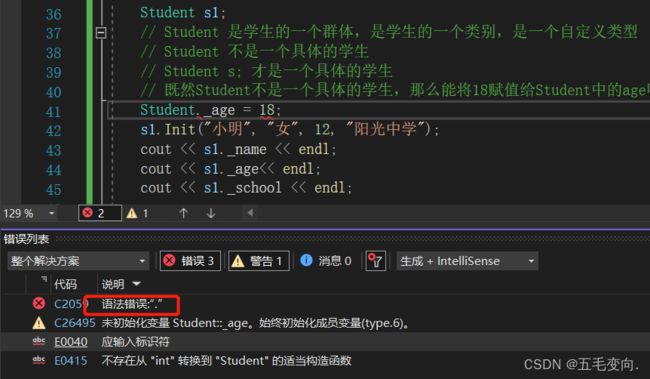
报了一个语法错误,学生是一个类,一个大的群体不可能全部的学生都是18岁吧,只能是特定的人是18岁,小明是18岁。这样子写就类似于
int = 10;对象:
- 对象是类具体的一个体现,即实体。
- 对象是用类自定义类型定义出来的
- 对象里面是可以存放数据的

3. 类对象模型
3.1 计算类对象的大小
计算类的大小首先我们要知道对象中包含了那些内容?那我们不妨再次举个例子。
#include
using namespace std;
class Date{
public:
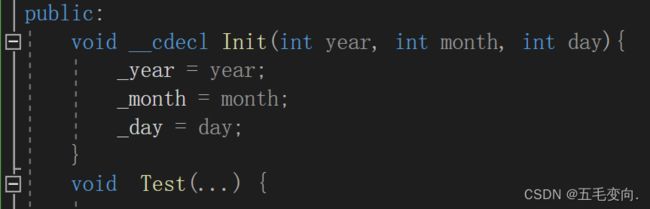
void Init(int year, int month, int day){
_year = year;
_month = month;
_day = day;
}
void Print(){
cout << _year << "-" << _month << "-" << _day << endl;
}
int _year;
int _month;
int _day;
};
int main(){
Date d1;
d1.Init(2022, 4, 30);
d1.Print();
cout << sizeof(d1) << endl;
Date d2;
d2.Init(2022, 5, 1);
d2.Print();
return 0;
} 
在vs下我们能清晰的看见一个对象中的内容 ,这里面有成员函数,还有成员变量,函数名就是函数的入口地址,在32位下就是4个字节,在64位下就是8个字节这里我使用的是32位来检测的。按照这样的话我这个对象的大小就应该是20.那我们来检测一下。
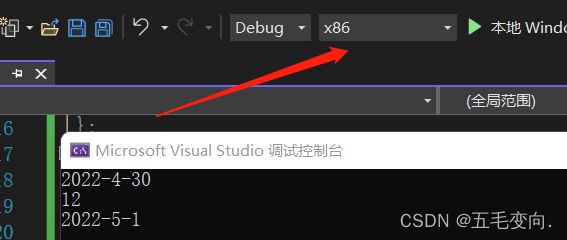
12 那我们的结论是有问题的,为社么是这样的结果呢?推测一下差了8个字节又可能是函数的地址没有存进去。
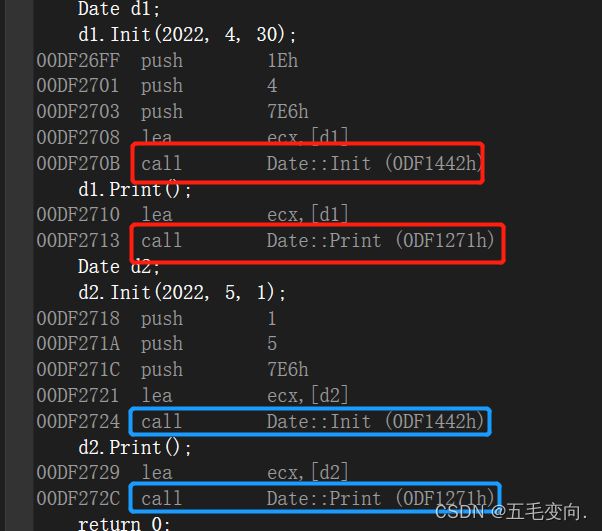
这样一看这俩对象call的的一个函数,因为入口地址都是一样的 ,d1 d2两个对象函数入口地址一样但是里面的成员变量不一样,所以成员函数的没有必要在每一个对象中都存储一份,这样无疑会浪费空间,对象中实际只包含了成员变量,没有包含和成员函数任何相关的东西,所以计算一个类的大小,实际跟计算结构体大小是完全是相同的。
3.1.1 结构体内存对齐问题
#include
using namespace std;
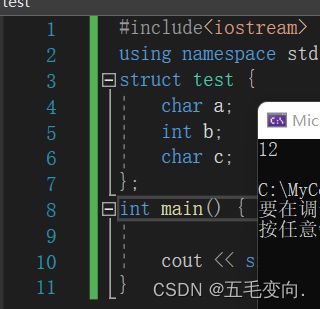
struct test {
char a;
int b;
char c;
};
int main() {
cout << sizeof(test) << endl;
} sizeof出来是多少呢?这还不简单 1 + 4 + 1 = 6!那结果会是这样吗?
答案真的是让我们大跌眼镜,那这样我把 b , c换一下位置会怎么样呢

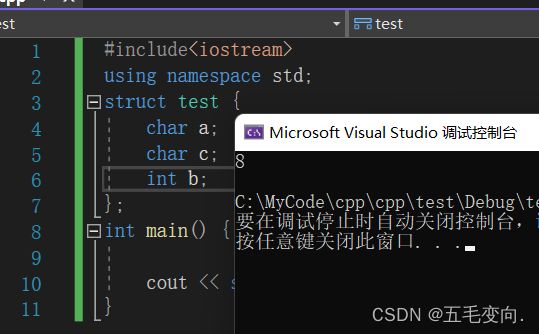
答案又变成8了,为啥会出现这样的现象呢?
结构体的大小不能,进行简单的元素的大小相加,结构体的内存布局,要考虑内存对齐。
如何内存对齐呢?
- 第一个成员在结构体变量偏移量为0的地址处。
- 其他成员变量除了第一个之外,要对齐(起始偏移量要能整除该成员的对齐数)到某个数字(对齐数 ---- 不考虑编译器设置对齐数的情况下指的是自身大小)的整数倍的地址处。
- 结构体的大小必须是最大对齐数的整数倍。


那我们在看一个例子:
#include
using namespace std;
struct test {
double a;
char b;
int c;
char e;
};
int main() {
cout << sizeof(test) << endl;
} 
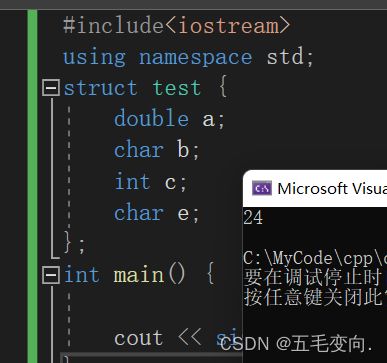
证明我们的分析正确
在回到这个类大小的计算

要计算一个类的大小,你就要知道类的内容是什么,通过执行程序调用汇编,发现d1,d2
调用的是一个成员函数,因为入口地址是一样的,程序编译链接完成之后入口地址是不会再发生改变的,既然不会发生改变就没有必要在每个对象里面都存储成员函数的入口地址,不但会浪费空间还对是编译实际过长!
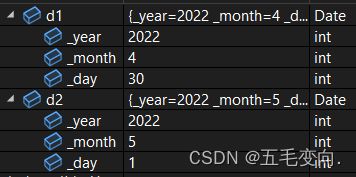
对象只包含了成员变量,没有存储跟成员函数相关的内容,一个类的大小就是该类成员中成员变量的累加,当然需要进行内存对齐。
3.1.2 空类的大小
#include
using namespace std;
class Date{
};
int main(){
Date d1;
cout << sizeof(d1) << endl;
Date d2;
cout << sizeof(d2) << endl;
return 0;
} 这个类很特殊没有,没有成员变量,也没有成员函数那他的大小会不会是 0 呢?让我们跑一下看看。
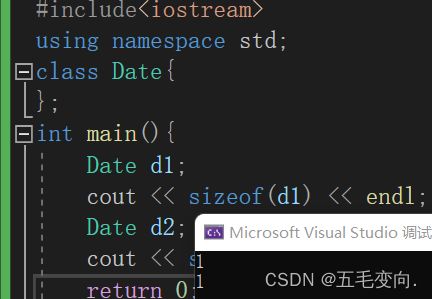
发现结果不是0是1,则说明空类的大小在主流的编译器是1。那空类的大小为啥是1不是0呢?
假设空类的大小是0:
从内存的角度来分析,我main函数开辟栈帧,我参数压栈的时候我的d1,d2就是在一个位置也就是这俩的地址相同,那和我们面向对象程序设计思想就是矛盾的,每个对象都是不同的!给空对象一个字节的大小就是为了区别不同的对象,我们可以把对象地址打印出来也可发现不同。

4. this指针
还是刚刚举的那个日期类
#include
using namespace std;
class Date{
public:
void Init(int year, int month, int day){
_year = year;
_month = month;
_day = day;
}
void Print(){
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
int main(){
Date d1;
d1.Init(2022, 4, 30);
d1.Print();
Date d2;
d2.Init(2022, 5, 1);
d2.Print();
return 0;
}
我们刚刚通过分析对象的大小,得到了一个结论就是对象只包含成员变量,没有包含成员函数。

d1 和 d2 最后调用的是一个Init 和 Print 的函数,但是在这两个函数内部并没有关于对象区分的信息,那Init 和 print 是怎么知道要操纵哪个对象呢?
那让我们把同样的代码用C语言写一份看看。
#include
using namespace std;
struct Date{
int year;
int month;
int day;
};
void Init(Date* pthis, int year, int month, int day){
pthis->year = year;
pthis->month = month;
pthis->day = day;
}
void Print(Date* pthis){
printf("%d-%d-%d\n", pthis->year, pthis->month, pthis->day);
}
int main(){
Date d1;
Init(&d1, 2022, 4, 30);
Print(&d1);
Date d2;
Init(&d2, 2022, 5, 1);
Print(&d2);
return 0;
} C语言下真的是一目了然,但是却很麻烦。我要初始化d1 那我就把地址传进去,赋值的时候用指针操纵他就把数据传进去了。但是C++中我的Init 不知道是接收 d1 的 还是 d2 的数据,print 也不知道打印的是 d1 还是 d2 的数据。 C++中通过加入了this指针解决这个问题,C++编译器给每个成员函数增加了一个隐藏的指针,让该指针指向当前的对象(函数运行的时候调用的函数的对象),在函数体中所有成员变量的操作,都是通过指针去访问,只不过所有的操作不需要用户做,编译器自动完成。
是通过 this 来操作对象的,那也是说明每次调用的时候 this指向的就是当前对象的地址,验证一x下
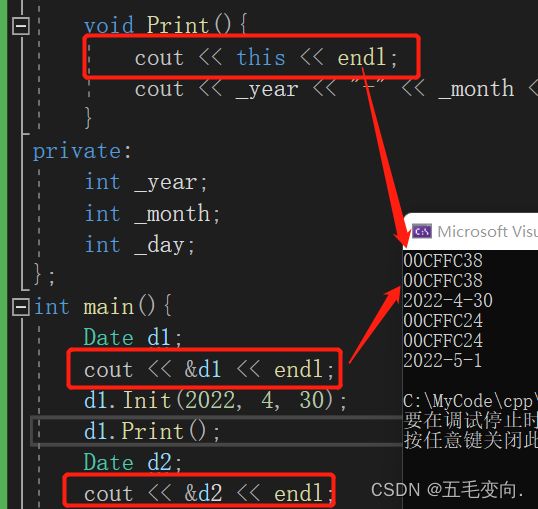
我们的结构体指针可以指向空,那我们这个this可以乱指指向空吗?
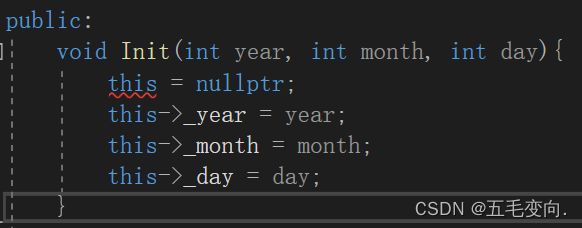
也就是指针指向的目标不可以修改,那也就说他是一个 Date *const类型指针常量!
所以在编译阶段做了:
1.还原this指针。
2.所有成员变量都是通过this指针来访问的。
我们再来看看到底编译器是怎么搞的?
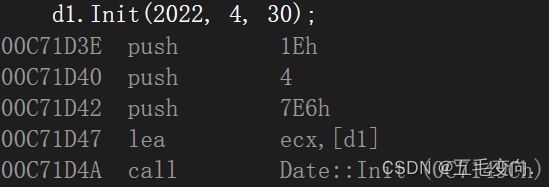
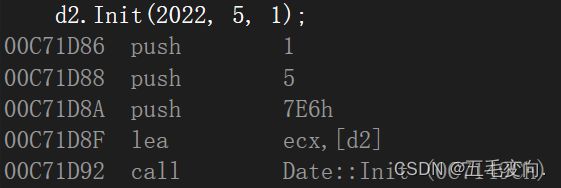
调用这个函数的过程:
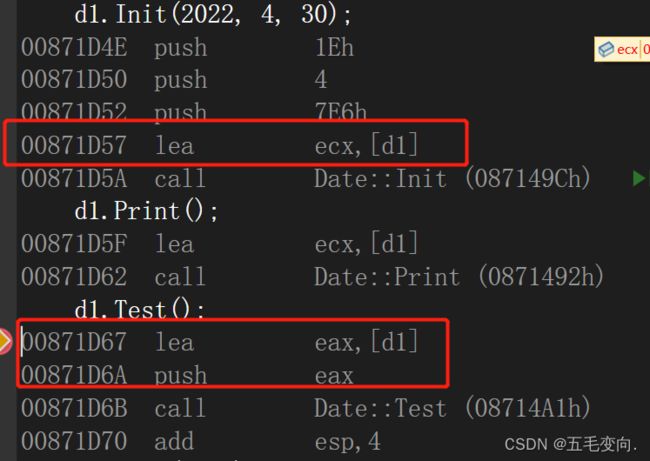
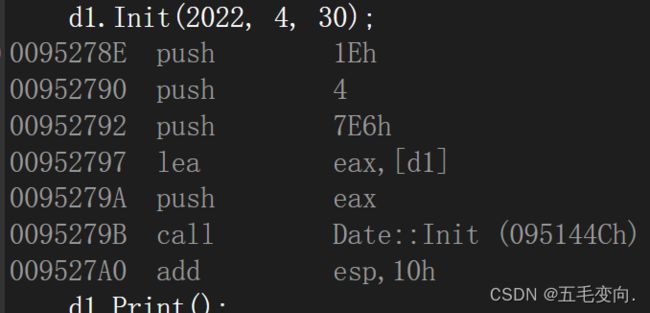
- 先push指令参数压栈,根据函数调用约定从右往左依次压入,7E6就是2022.
- 然后lea取d2的地址,把他放到ecx寄存器中,可以理解为全局变量,通过寄存器传递信息,this实际就是通过ecx来传递的(vs2022 下)。
- 最后在call这个函数。
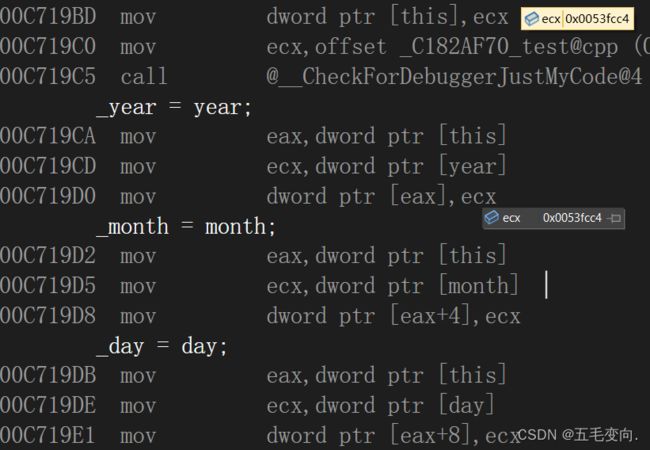

- 我们刚刚不是把 d1 的地址放到了寄存器 ecx 中,这里则是把 ecx 寄存器里面的内容放到了this指针里面,可以很清晰由下面这图看到 ecx 的的确确放的是 d1 的地址。
- 下面这三条就是开始对对象内容赋值了,先让this指针赋值给 eax 然后再一个个写入
- 因为刚刚已经把year写入了 他是int 所以再eax + 4的地方放month以此类推再 + 8的地方放day。
4.1 this 指针的特性
1. this指针的类型:类类型* const
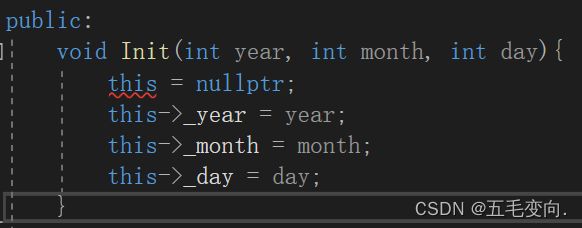
指针常量 :不可修改指针所指向的目标 。
char* const str = NULL;
//这是指针常量,指向的目标不可改变!
char const* str = NULL;
//这是常量指针,是指针指向的变量不可以通过指针来修改!2. 只能在成员函数的内部使用

这里直接就报错了,this 要在成员函数内部使用,你这个再主函数里面你是要指向哪个对象呀?你就说不清楚了。
3. this指针本质上其实是一个成员函数的形参,是对象调用成员函数时,将对象地址作为实参传递给this形参。所以对象中不存储this指针。
4. this指针是成员函数第一个隐含的指针形参,一般情况由编译器通过ecx寄存器(vs2022 x86)传递,不需要用户传递.
并不是所有的 this 都是通过ecx寄存器进行传递的。
不定参数就是参数压栈进行传递的

这里就是把 d1 的地址放在eax 寄存器里面,将eax里面的信息参数压栈进去。
4.1.1 不定参数
所谓不定参数,指的就是在函数的定义中,函数的参数列表不确定的情况,即函数并不清楚自己将要接收多少个参数,举个例子printf就说一个。
printf 函数原型
int printf ( const char * format, ... );我们之前说过printf函数也是有返回值的,输出字符的个数。
printf();也是一个函数,他的设计就是可以输出很多不一样的类型,个数的函数,那我们不是有重载吗,要他干啥?但是你要重载的话无疑会十分的低效,因此,我们可以将函数定义成能够接受任意数量的实参。可以通过3个句点…写在函数定义中参数列表的最后,即可表示调用该函数时可以提供数量可变的实参。
回到刚刚这个例子,那我咋知道啥时候 this 是ecx寄存器穿,啥时候是 eax 参数压栈进行传递呢?
他俩的调用约定不一样!
4.2 函数调用约定
4.2.1 __cdecl调用约定
__cdecl 这个其实是函数的调用约定,在msvc中C和C++函数调用约定都是__cdecl,__cdecl调用约定又称为 C 调用约定,是 C/C++ 语言缺省的调用约定。。
__cdecl调用方式规定:
- 参数按照从右至左的方式入栈。
- 函数本身不清理栈,此工作由调用者负责。
- 返回值在eax中。由于由调用者清理栈,所以允许可变参数函数存在。
- 调用参数个数可变的函数只能采用这种方式(不定参数)。
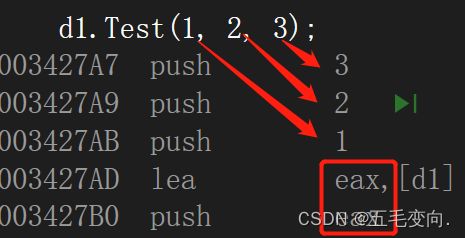
我们在汇编代码可以清晰到是由右向左依次入栈的,我们是 d1 操作的,然后将 返回值放在eax ,所以我们在缺省参数给默认值的时候,必须是从右向左依次给的,如果不然那函数就不知道把谁压栈。
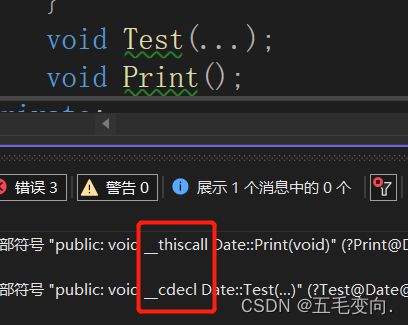
4.2.2 __thiscall调用约定
__thiscall是唯一一个不能明确指明的函数修饰,因为thiscall只能用于C++类成员函数的调用,同时thiscall也是C++成员函数缺省的调用约定。由于成员函数调用还有一个this指针,因此必须特殊处理。
__thiscall调用方式规定:
- 采用栈传递参数,参数从右向左入栈。
- 如果参数个数确定,this指针通过ecx传递给被调用者;如果参数个数不确定,this指针在所有参数压栈后被压入堆栈;
- 对参数个数不定的,调用者清理堆栈,否则由被调函数清理堆栈。


参数确实还是从右向左压入栈,this指针通过ecx传递给被调用者。
还可以再写代码的时候 就把调用约定加上来改变他的调用约定。
这里就是直接将 d1 的值参数压栈了,不是刚刚的放在 ecx 中再把它给 this 指针。
函数的调用约定还有很多这里就不一一赘述。
4.3 this 的存储
那我想知道 this 存在哪里那我在某一个成员函数里面把 this 地址打印一下不久好了
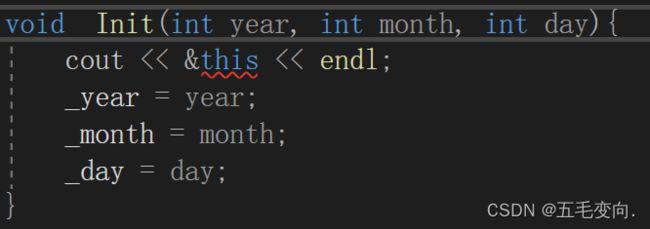
好家伙你还不让我打印!我这样来一下
Date* const &Mythis = this;
//this 是指针常量 指向的内容不能改
//如果不用const修饰 & 别名也可以修改!
cout << &Mythis << endl;
引用和他本身的地址是一样的这里的&Mythis 也就是 &this this里面放的还是 d1 也就是指向当前调用成员函数的对象,ebp 和 esp 是两个指向函数栈帧的指针,一个指向栈底,一个指向栈顶。(当前就是Init这个函数的栈帧),&Mythis 刚好就在两个指针之间,换而言之this指针的存储位置就是在栈上!
4.4 this为空
#include
using namespace std;
class Date{
public:
void Init(int year, int month, int day){
Date* const &Mythis = this;
cout << &Mythis << endl;
_year = year;
_month = month;
_day = day;
}
void Test() {
cout << this << endl;
cout << "Date::Test" << endl;
}
void Print(){
cout << this << endl;
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
int main(){
Date d1;
d1.Init(2022, 5, 1);
d1.Print();
//定义一个指针指向对象
Date* p = &d1;
//就可以用箭头调用成员函数
p->Print();
//this是*const 但是普通指针可以改变方向
p = nullptr;
//再去调用看看this指针是否为空
p->Test();
p->Print();
return 0;
}
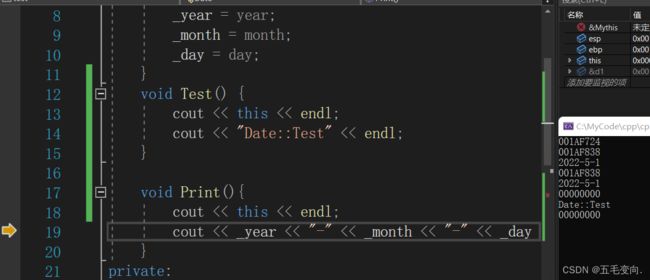
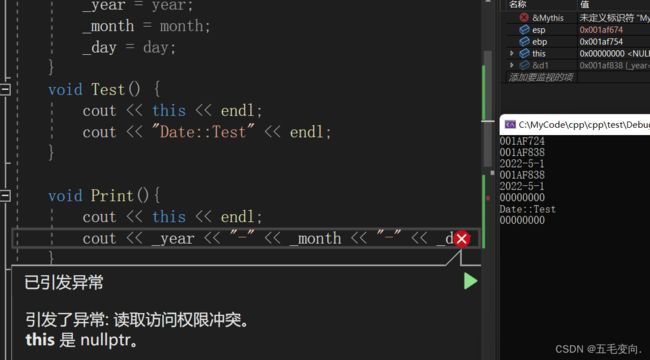
其实这样写就是:
p->Print(); //Date::Printf(p);
// 如果成员函数是通过指针调用,this有可能会为nullptr
// 当指针指向nullptr的时候,this就是nullptr当 this 为nullptr时,只要在成员函数中没有访问成员变量,则代码不会崩溃,如果访问成员变量,则代码一定崩溃,在成员函数中是通过this指针来访问成员变量的。
5. 类的6个默认成员函数
有一个空类可不是啥都没有,编译器会给生成6个成员函数。
初始化和清理:
- 构造函数主要完成初始化工作
- 析构函数主要完成清理工作
拷贝复制:
- 拷贝构造是使用同类对象初始化创建对象
- 赋值重载主要是把一个对象赋值给另外一个对象
取地址重载:
- 主要是普通对象和const对象取地址
6. 构造函数
还是刚才的Date类 我们刚刚的初始话是自己给了一个 Init 方法来实现的,Date是一种自定义类型,对比内置类型我可以这样
int main() {
//可以先声明,后定义然后里面是随机值
int a1;
a1 = 10;
//声明和定义在一块
int a2 = 20;
int a3(30);
}
类比的尝试了一下,为啥说没有重载函数,接受三个参数,那也就是反向证明,构造函数是默认的,你没写编译器是会给你的。
概念:构造函数是特殊的成员函数,构造函数虽然叫构造,但是他的主要任务不是开辟空间创建对象,而是初始化对象。
6.1 构造函数的特性
1. 构造函数名字必须和类名相同。
2.构造函数一定不能有返回值类型,写成void也不行。
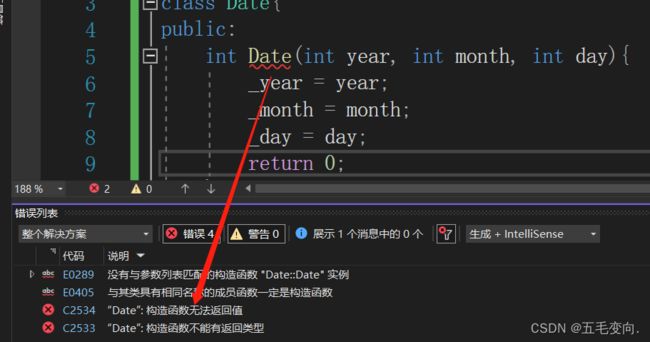
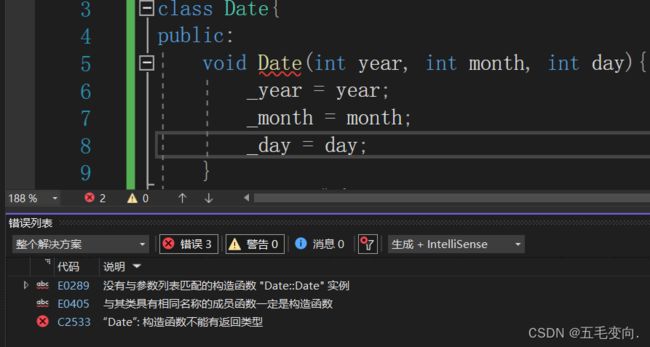
3. 用户不能调用,在创建对象的时候由编译器自动调用。

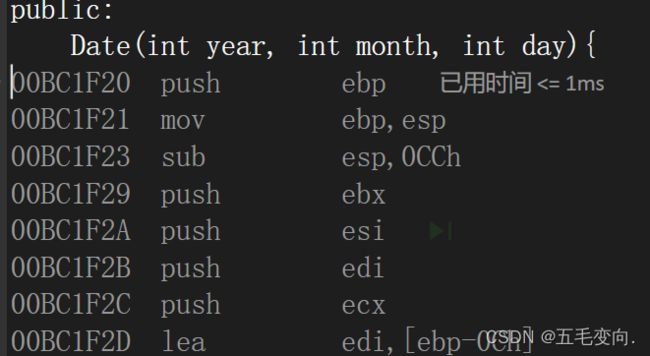
这里是 jump指令 跳到指定地址![]()
就到我们的构造函数里面了我们 用户并没有调用构造函数只是在初始化的时候给他传值了
4. 整个对象声明周期内只能调用一次。
检验这个有两种方法:
1.在构造函数内部打印 相关信息 this指针看打印了几次

2.利于静态成员变量 类内声明类外定义。
#include
using namespace std;
class Date {
public:
Date(int year, int month, int day) {
count++;
_year = year;
_month = month;
_day = day;
}
void Print() {
cout << _year << "-" << _month << "-" << _day << endl;
}
static int count;
private:
int _year;
int _month;
int _day;
};
int Date::count = 0;
int main() {
Date d1(2022, 5, 1);
d1.Print();
cout << Date::count << endl;
return 0;
} 
5. 构造函数可以重载。

我不传参数不久好了,你不是说给你提供内置的构造函数了吗,你看他俩颜色都不一样,一个是对象,一个是返回值是Date,参列表为空的函数声明!
这时候我们在重载构造函数。

构造函数是可以重载的!
6. 如果类中没有显式定义构造函数,则C++编译器会自动生成一个无参的默认构造函数,一旦用户显式定义编译器将不再生成。
来看这个例子:
#include
using namespace std;
class Time{
public:
Time(){
_hour = 0;
_minute = 0;
_second = 0;
}
private:
int _hour;
int _minute;
int _second;
};
class Date {
public:
void Print() {
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
Time t;
};
int main() {
Date d;
return 0;
} 我的主函数干的什么事情,就实例化了一个对象类里面也只有一个打印的成员函数

底下就调用了一个无参数的构造函数,里面都是随机值。
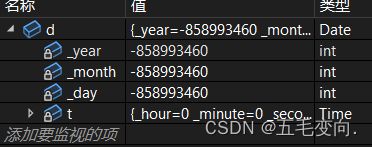
一旦用户显式定义编译器将不再生成,这个呢这样来看。
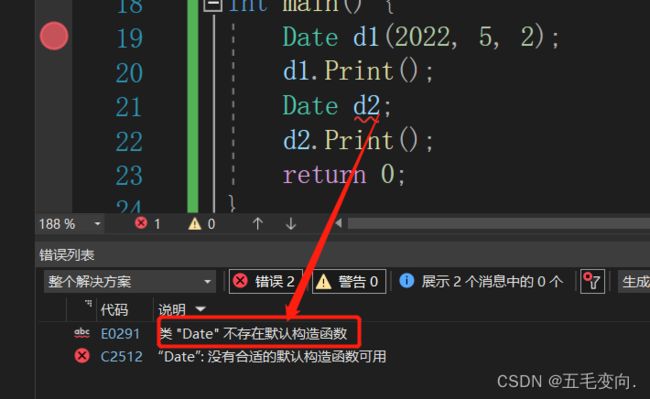
用户自己定义这个构造函数了,编译器就不会给你默认构造函数了,你想让他通过编译就得自己在写一遍没有参数的构造函数。
7. 无参的构造函数和全缺省的构造函数都称为默认构造函数,并且默认构造函数只能有一个。注意:无参构造函数、全缺省构造函数、我们没写编译器默认生成的构造函数,都可以认为是默认成员函数。
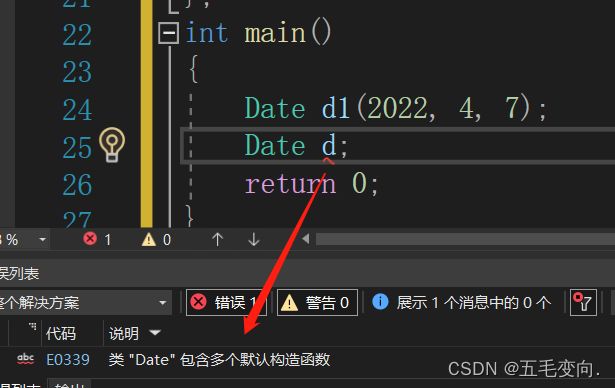
我有个全缺省的构造函数,还有无参构造函数,你这样不传参数编译器就不知道调用谁了,编译器发现调用无参构造函数可以,调用全缺省的构造函数也可以 。
无参构造函数和全缺省构造函数都叫做默认构造函数,且这两个是不能共存的。
8. 如果用户没有显式提供任何构造函数,则编译器会生成一个无参的默认构造函数当Date d; 发现d对象创建好之后,d对象的成员变量全部都是随机值也就是说编译器生成的无参构造函数没有意义那是不是说:编译器生成的无参构造函数一定是没有意义的呢?
#include
using namespace std;
class Time{
public:
Time(){
cout << "Time()" << endl;
_hour = 0;
_minute = 0;
_second = 0;
}
private:
int _hour;
int _minute;
int _second;
};
class Date{
public:
void Print(){
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
// C++11中:为了解决默认构造函数不对内置类型初始化问题
// int _year = 2022;
// int _month = 5;
// int _day = 3;
int _year;
int _month;
int _day;
Time _t; // 日期类型对象中包含了一个时间对象
};
int main(){
Date d; // 创建那个类的对象,编译器就会调用该类的构造函数
return 0;
} 不是这样的,我一个d对象的创建会调用无参构造函数然后给我的_year ,_month,_day给与默认值,到了_t的时候他是自定义类型了,那怎么初始话他呢,就要调用构造函数来初始化了。


我没写构造函数,但是他编译器自己给我补起来了也就是一个类原本就有的。

给那几个成员变量的值就是0cccccccch 最后调用Time构造函数来初始化_t成员变量。形象一点就是这样子的,
class Time{
//1.内置类型成员变量 给随机值初始化
//2.自定义类型成员变量 调用构造函数初始化
};总结一下构造函数的作用,构造函数不是开辟空间 创建对象,而是初始化对象
1. 全局对象:
编译器编译完代码之后,就已经将对象的空间预留好了,只是你没有调用构造函数,并没有真正实例化出来一个对象,此时的对象不完整。
2. 函数体内部对象:
局部对象,每个函数运行的时候都会在虚拟地址空间的栈上开辟一个栈帧,局部对象的空间就在栈帧上,而栈帧的大小也是编译器编译的时候可以提前计算出来的,也就说局部对象的空间也被预留出来了,函数一调用,栈帧开辟,局部对象的空间也就有了,但是此时还没有调用构造函数也是一个不完整的对象。

这一段汇编代码基本上每个函数的开辟都是这样子的,这里的ebp跟esp就是两个寄存器,ebp指向栈底,esp指向栈顶。

3. 堆上申请的对象:
就是用new出来的,这里到第三回动态内存管理的时候我在给你娓娓道来。
7. 析构函数
概念:析构函数与构造函数功能相反,析构函数不是完成对象的销毁,局部对象的销毁是由编译器完成的,而对象在销毁的时候回自动调用析构函数,完成类的一些资源清理工作。
我们再拿最开始封装的栈举例子,到这块了现在的栈就最开始是大不相同了
#include
#include
#include
using namespace std;
typedef int DataType;
class Stack{
public:
Stack(){
_array = (DataType*)malloc(sizeof(DataType) * 10);
if (NULL == _array)
{
assert(0);
return;
}
_capacity = 10;
_size = 0;
}
~Stack(){
if (_array)
{
free(_array);
_array = nullptr;
_capacity = 0;
_size = 0;
}
}
void Push(const DataType& data) {
_array[_size] = data;
_size++;
}
void Pop(){
if (Empty())
return;
--_size;
}
DataType Top(){
return _array[_size - 1];
}
size_t Size(){
return _size;
}
bool Empty(){
return 0 == _size;
}
private:
DataType* _array;
size_t _capacity;
size_t _size;
};
void TestStack(){
Stack s;
// StackInit(&s);--->C语言中的做法
s.Push(1);
s.Push(2);
s.Push(3);
s.Push(4);
cout << s.Size() << endl;
cout << s.Top() << endl;
s.Pop();
s.Pop();
cout << s.Size() << endl;
cout << s.Top() << endl;
// StackDestroy(&s); // ----C语言中的做法
}
int main()
{
TestStack();
_CrtDumpMemoryLeaks();
return 0;
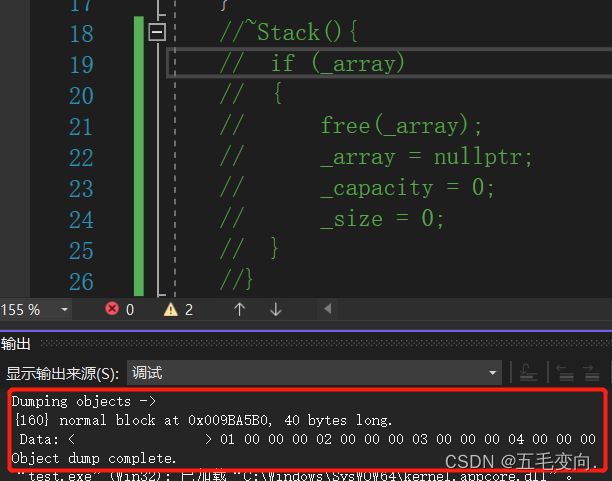
} 这里我先不给他写析构函数,把析构函数注释掉,用_CrtDumpMemoryLeaks();这个方法来查看是否有内存泄漏,因为析构函数不是完成对象的销毁,只是对资源的清理,换而言之就是不会释放开辟的空间。
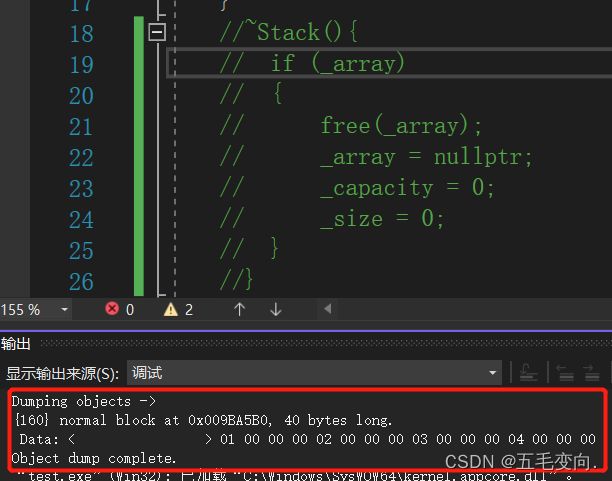
有40个字节的内存泄漏!再次印证析构函数只是清理资源的, 不是完成对象的销毁!
7.1 析构函数的特性
1. 析构函数名是在类名前加上字符 ~。
2. 无参数无返回值。
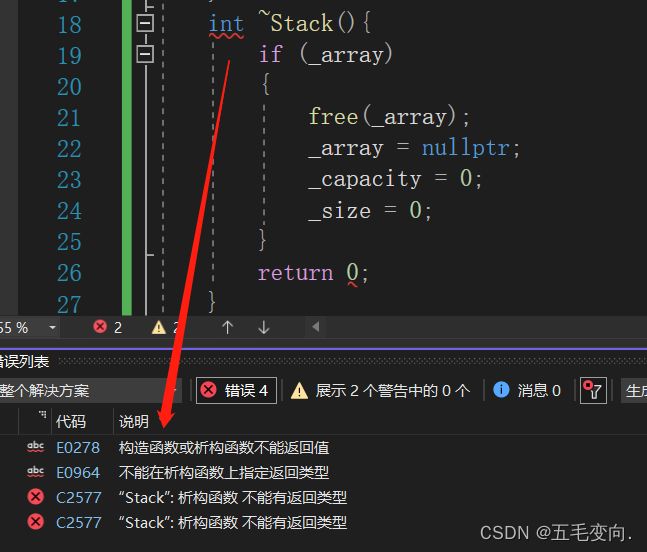
我给viod呢?
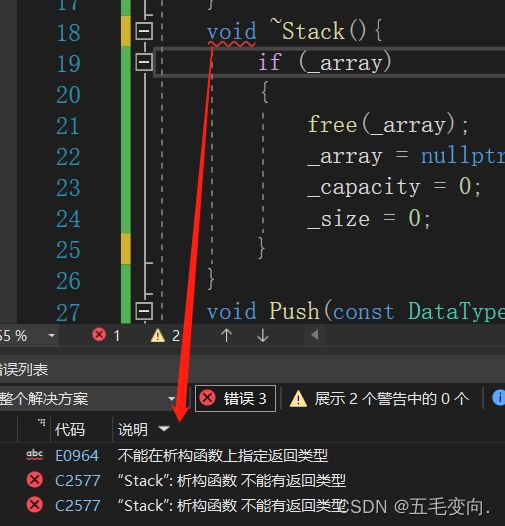
void 也不行析构函数这一块跟构造函数是一样的。
3.析构函数的参数列表必须为空。
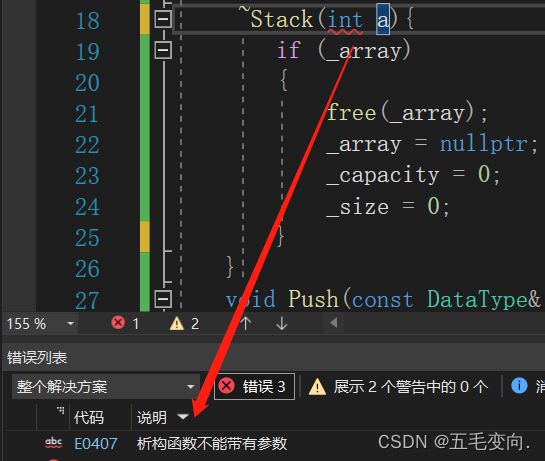
或者这边变成void也可,但是平常不这样用。

4. 一个类有且只有一个析构函数。若未显式定义,系统会自动生成默认的析构函数。
第三点我们聊过了析构函数不能有参数,所以一个类只能有一个析构函数,换而言之析构函数不能重载,重载的条件,函数名相同,同一个作用域下,形参列表的个数类型顺序不同,你都不能有参数你咋重载。
5. 对象生命周期结束时,C++编译系统系统自动调用析构函数
语法是这样的但是编译器一定会这样做吗?
来看这个例子:
class Date{
public:
void Print(){
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
void Test() {
Date d;
}
int main() {
Test();
}
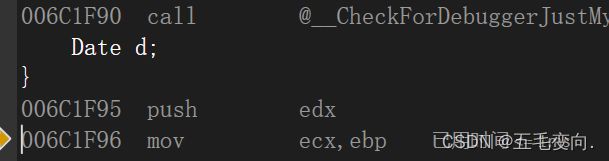
call 啥都没有,那就是没有调用,因为你也没传参,那就是给默认值就好了,如果在掉构造函数那一系列的函数调用的花费太耗时间。所以就干脆不调用析构和构造函数了。
但是语法确实这样的:
- 构造函数没有显式定义,则编译器会自动生成一份无参的默认构造函数
- 析构函数没有显式定义,则编译器会自动生成一份析构函数
那啥时候调用啥时候不调用呢?
#include
using namespace std;
class Time{
public:
Time(){
}
~Time(){
}
private:
int _hour;
int _minute;
int _second;
};
class Date{
public:
void Print(){
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
Time _t;
};
void TestDate(){
Date d;
}
int main(){
TestDate();
return 0;
}

而且我Date d的汇编也不能是 call Time::Time();我这是实例化Date 类下的d 又不是Time类下的 t 所以还要调用Date的构造函数。
在函数结束调用的时候同理,我要清理资源但是Date 类下的这个 d 成员变量有一个自定义类型的Time 类下的 _t 对象这就要调析构函数了,汇编指令也不能是 call Time::~Time();还得先调用Date 的析构函数一个个清理,清理到_t的时候调用Time的构造函数。
默认的成员函数到底会不会生成,语法是一定会生成的 实际具体的编译器,比如:vs2022是不一定有些情况下会生成,有些情况下就不生成困惑:到底什么情况下会生成? 编译器感觉自己需要的时候才会生成,后面继承多态还会说的。
6. 有些类的析构函数实现出来没有任何的意义----单独的Date类有些类的析构函数是必须要给出来,否则程序中会存在内存泄漏,类中如果不涉及到资源管理时,比如Date类,则析构函数可以不用写,一旦涉及到资源管理时,则析构函数一定要给出,比如:Stack
8. 拷贝构造函数
假如我们有一个需求,用已经实例化完成的对象去初始化另外一个对象应该咋样做呢?
类比一下:
int a(20);就可以这样写
Date d1(2002, 5, 2);
Date d2(d1); 
确确实实两个对象是一模一样,就好像双胞胎,那是谁干的这个工作的呢?
构造函数?不对吧我这个传参数传递的是自定义类型的参数,我的构造函数参数列表里面没有呀!
其实是拷贝构造函数干的这个事情啦。我们发现拷贝构造函数和构造函数不仅仅是名字相像,而且语法相像说明这两个肯定有啥联系(重载关系)。
概念:只有单个形参,该形参是对本类类型对象的引用(一般常用const修饰),在用已存在的类类型对象创建新对象时由编译器自动调用。
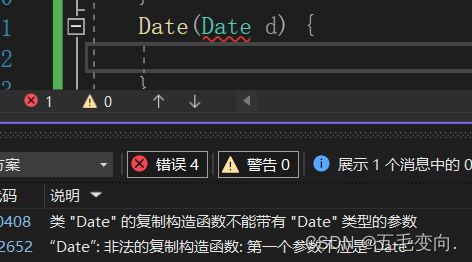
必须是本类对象的引用,不然直接报错!
8.1 拷贝构造函数的特性
1. 拷贝构造函数其实也就是构造函数(构造函数的重载)所以他也满足构造函数的特性。
自己实现一下:
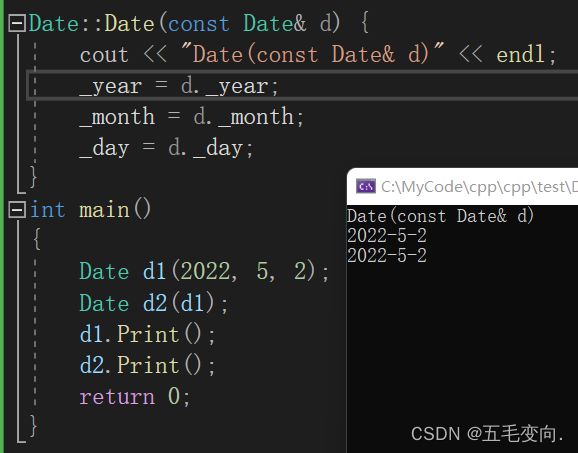
Date(const Date& d) {
_year = d._year;
_month = d._month;
_day = d._day;
}
说明了两个问题;
- 这样操作确实让对象初始化对象了。
- 用户显示提供,编译器就不会给你默认的拷贝构造函数了,你这条cout 语句出来了。
2. 那为啥要加const呢?
不加const的话可能会引发错误:
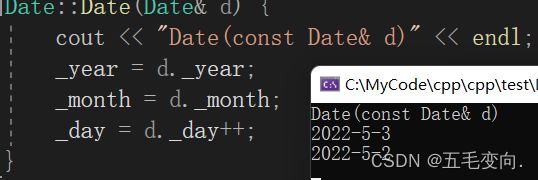
我们本意是想用一个对象初始化另一个对象,这样两个都不相同,已经和我们设计的理念背道而驰,所以应该加上const来限制不能去修改。
3. 一定是以引用的方式传递不是值的方式传递
假设是可以用值传递的我们来看看会发生什么情况:

这样就成了一个没出口的递归了!
4. 3. 若未显示定义,系统生成默认的拷贝构造函数。 默认的拷贝构造函数对象按内存存储按字节序完成拷贝,这种拷贝我们叫做浅拷贝。

发现确实拷贝成功了,而且没有发生内存泄漏。那么也就是说我们就不管了,直接用给的默认的拷贝构造函数就行了,我就不需要实现了?
对于本次案例这种没有涉及到资源管理的类是可以的,一旦类中涉及到资源的管理,拷贝构造函数一定要实现!
还是栈的那个例子:
#include
using namespace std;
#include
#include
typedef int DataType;
// Stack没有显式实现拷贝构造函数,则编译器会生成一份默认的拷贝构造函数
class Stack{
public:
Stack(){
_array = (DataType*)malloc(sizeof(DataType) * 10);
if (NULL == _array)
{
assert(0);
return;
}
_capacity = 10;
_size = 0;
}
~Stack(){
if (_array)
{
free(_array);
_array = nullptr;
_capacity = 0;
_size = 0;
}
}
void Push(const DataType& data){
_array[_size] = data;
_size++;
}
void Pop(){
if (Empty()) {
return;
}
--_size;
}
DataType Top(){
return _array[_size - 1];
}
size_t Size(){
return _size;
}
bool Empty(){
return 0 == _size;
}
private:
DataType* _array;
size_t _capacity;
size_t _size;
};
void TestStack(){
Stack s1;
s1.Push(1);
s1.Push(2);
s1.Push(3);
s1.Push(4);
Stack s2(s1);
cout << s2.Size() << endl;
cout << s2.Top() << endl;
}
int main()
{
TestStack();
return 0;
} F5跑一下

出问题了 是什么原因呢?
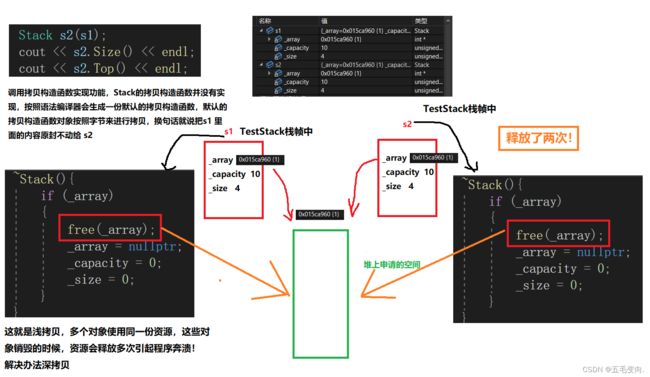
深拷贝在后续会解释,只要不涉及到资源管理都可以使用默认的拷贝构造函数,一涉及到资源管理,可能会释放多次引起程序崩溃!
8.2 拷贝构造函数的调用时机
给上例子:
#include
using namespace std;
class Date{
public:
Date(int year = 2022, int month = 5, int day = 1){
_year = year;
_month = month;
_day = day;
}
Date(const Date& d){
_year = d._year;
_month = d._month;
_day = d._day;
cout << "Date(const Date&)" << endl;
}
private:
int _year;
int _month;
int _day;
};
// 2. 以类类型方式传参--以值的方式
void TestDate1(Date d)
{}
// 3. 以类类型方式作为函数的返回值---以值的方式返回的
Date TestDate2(){
Date d(2022, 5, 4);
return d;
}
Date TestDate3(){
// 创建一个匿名对象:即没有名字的对象
// 在返回时,编译器不会在通过拷贝构造函数创建一个临时对象返回
// 而是将匿名对象直接返回了
// 相当于以匿名对象直接返回时,编译器会做优化
return Date(2022, 5, 2);
}
// 告诉一个结论:对于自定义类型作为函数的参数或者返回值时,能传递引用尽量传递引用
Date& TestDate4(Date& d){
return d;
}
int main()
{
// 1. 用一个对象直接构造一个新对象
Date d1(2022, 5, 3);
Date d2(d1);
TestDate1(d1);
d2 = TestDate2();
d2 = TestDate3();
d2 = TestDate4(d1);
return 0;
} 8.2.1 用一个对象直接构造一个新对象

这个已经见了很多次了,这里就不做赘述了。
8.2.2 以类类型方式传参--以值的方式

确确实实是调用了,刚刚在解释拷贝构造函数不能以值方式传递说了,这个形参是实参的临时拷贝 做这个动作的时候进行拷贝构造函数的调用了!

8.2.3 以类类型方式作为函数的返回值---以值的方式返回的

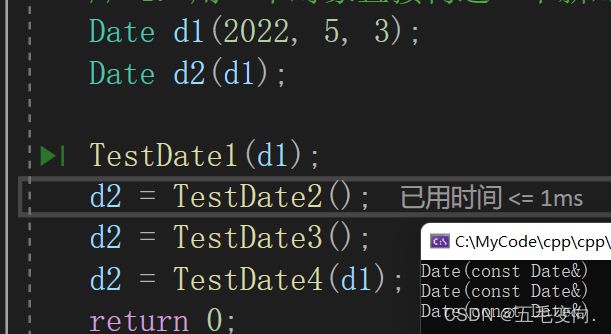
返回这个对象的返回值的时候也调用了。
这里面有个特殊的// 创建一个匿名对象:即没有名字的对象,在返回时,编译器不会在通过拷贝构造函数创建一个临时对象返回,而是将匿名对象直接返回了相当于以匿名对象直接返回时,编译器会做优化!
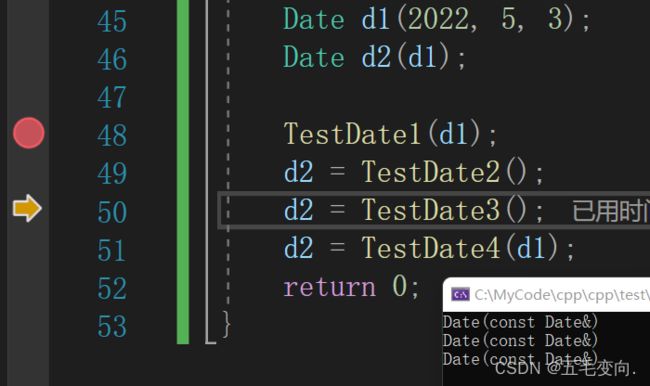
告诉一个结论:对于自定义类型作为函数的参数或者返回值时,能传递引用尽量传递引用,不会调用拷贝构造函数!
5.1 快乐呀!
还在持续更新……