mysql join语句优化实战
生产环境的大表join语句性能经常很差。这里给出大表join语句的优化思路。
准备材料
两张表,t1表N行,t2表M行
CREATE TABLE `identity`.`t1` (
`id` INT NOT NULL COMMENT 'Id',
`a` INT NULL,
PRIMARY KEY (`id`));
CREATE TABLE `identity`.`t2` (
`id` INT NOT NULL COMMENT 'Id',
`a` INT NULL,
PRIMARY KEY (`id`));
t1表用procedure脚本写入10000000行数据, 批量造数脚本如下
delimiter //
create procedure zqtest8()
begin
declare i int default 0;
set i=0;
start transaction;
while i<10000000 do
insert into t1(a) values(i);
set i=i+1;
end while;
commit;
end;
//
delimiter ;
call zqtest8();
t2表用procedure写入1000行数据,批量造数脚本省略。
join语句
select *
from t1 join t2 on (t1.a = t2.a)
1. t2表join关联的列没有索引的情况
被驱动表join列没有索引的情况下,用的是近似Simple Nested-Loop Join 算法。t1表全表扫描,每取一行,就会去t2表找与之相同的数据。因为t2表没有索引,所以需要对t2表全表扫描。后端开发同学可以近似看成是一个双层for循环。时间复杂度是O(N * M)。
我的mysql版本显示实际使用的是Block Nested Loop算法。
![]()
sql执行耗时49ms

通过explain命令可以看出,两张表均使用了全表扫描。
2. t2表join关联的列有索引的情况
为了解决被驱动表全表扫描的问题,为被被驱动表建索引。
ALTER TABLE `t2` ADD INDEX `idx_a` (`a`);
再次执行join语句,耗时4.4ms
![]()
执行explain命令,被驱动表用上了索引。
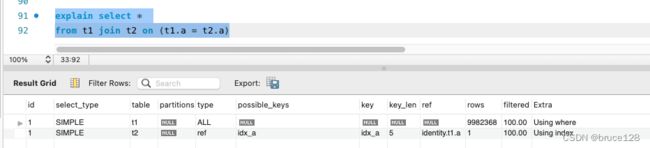
t2表不再全表扫描,而是走的索引树搜索。时间复杂度降低到O (N * log(M)), 1000W * log(1000) = 10000W, mysql需要近似扫描1亿行数据(对数的底数取2)
3. 是否还能再次优化?
修改SQL,把t1表放到后面,t2表放到前面,并且为t1表加索引
select *
from t2 join t1 on (t1.a = t2.a);
ALTER TABLE `t1`
ADD INDEX `idx_a` (`a);;
![]()
执行时间降低到了2.7ms
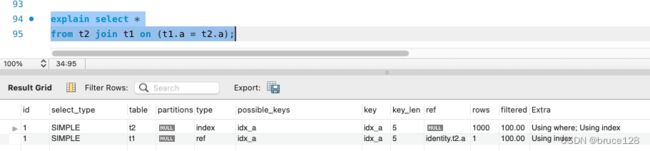
时间复杂度是O (M * log(N)), 1000 * log(10000000) = 16W,mysql需要近似扫描16W条数据(对数的底数取2)
小结
性能差的join语句
- 被驱动表索引列构建B数索引
- 数据量小的表放前面,数据量大的表放后面