最小生成树 | 市政道路拓宽预算的优化 (Minimum Spanning Tree)
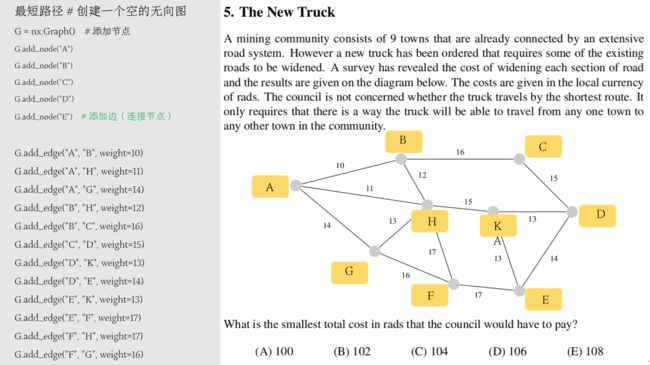
任务描述:
市政投资拓宽市区道路,本着执政为民,节省纳税人钱的目的,论证是否有必要对每一条路都施工拓宽?
这是一个连问带答的好问题。项目制学习可以上下半场,上半场头脑风暴节省投资的所有可行的思路;
下半场总结可行的思路,归为算法问题解决。
思路
MST = Minimum Spanning Tree 最小生成树
1、选择每一个节点的最短边,加入树Tree,涂成颜色标记如下:
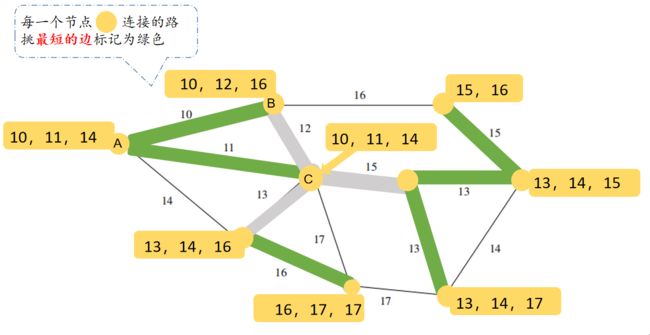
2、同时避免形成环路,

3、遍历所有的节点,循环执行以上步骤直至所有节点都在MST中;
使用Kruskal算法求解最小生成树(Minimum Spanning Tree)的Python代码实现
#上述代码利用Kruskal算法的贪心思想, 每次选择权值最小的边加入MST, 同时避免形成环路,
#直到遍历完所有节点, 得到最小生成树的所有边。

Kruskal算法和Prim算法都是解决最小生成树(Minimum Spanning Tree,MST)问题的常用算法,但它们的工作原理和实现方式略有不同。以下是它们之间的主要区别:
-
工作原理:
-
Kruskal算法:Kruskal算法基于贪心策略。它首先将所有的边按权重升序排列,然后从最小权重的边开始,逐渐构建最小生成树。在构建的过程中,Kruskal算法不断选择下一条最小权重的边,但要确保选择的边不会形成环路。它使用了一个并查集(Disjoint Set)数据结构来判断边是否会形成环路。
-
Prim算法:Prim算法也是一种贪心算法,但它从一个初始顶点开始,逐步添加顶点到最小生成树中。它每次选择一个与当前最小生成树相邻的顶点,并选择连接它们的边中权重最小的那条边。这个过程一直进行,直到所有顶点都包含在最小生成树中为止。
-
-
起始点:
-
Kruskal算法:Kruskal算法不需要指定一个起始点,它从边集合出发,根据权重来构建最小生成树。
-
Prim算法:Prim算法需要指定一个起始点,它从指定的起始点开始构建最小生成树。
-
-
数据结构:
-
Kruskal算法:Kruskal算法主要依赖于边的排序和并查集数据结构,用于检测环路。
-
Prim算法:Prim算法通常使用优先队列(Priority Queue)来管理候选边和顶点,以及一个数组来维护顶点的键(键表示连接到最小生成树的最小边的权重)。
-
-
适用情况:
-
Kruskal算法:Kruskal算法适用于稀疏图,即边相对较少的情况。它不受起始点选择的限制,因此在不同起始点下可能会得到相同的最小生成树。
-
Prim算法:Prim算法适用于稠密图,即边相对较多的情况。它的最终结果可能受起始点选择的影响,因为不同的起始点可能会导致不同的最小生成树。
-
总的来说,Kruskal算法和Prim算法都是有效的最小生成树算法,选择哪个算法取决于具体的问题和图的性质。在实际应用中,可以根据图的密度和其他要求来选择适当的算法。
import sys
class Graph:
def __init__(self):
self.graph = {}
def add_edge(self, u, v, w):
if u not in self.graph:
self.graph[u] = {}
if v not in self.graph:
self.graph[v] = {}
self.graph[u][v] = w
self.graph[v][u] = w
def prim(self):
key = {}
parent = {}
mst_set = set()
# 初始化key值为无穷大
for vertex in self.graph:
key[vertex] = sys.maxsize
# 从起始顶点开始
start_vertex = list(self.graph.keys())[0]
key[start_vertex] = 0
parent[start_vertex] = None
while mst_set != set(self.graph.keys()):
# 找到key值最小的未加入MST的顶点
min_vertex = None
for vertex in self.graph:
if vertex not in mst_set and (min_vertex is None or key[vertex] < key[min_vertex]):
min_vertex = vertex
mst_set.add(min_vertex)
# 更新与min_vertex相邻的顶点的key值和parent
for neighbor, weight in self.graph[min_vertex].items():
if neighbor not in mst_set and weight < key[neighbor]:
key[neighbor] = weight
parent[neighbor] = min_vertex
# 构建最小生成树的边列表
mst_edges = []
for vertex, p in parent.items():
if p is not None:
mst_edges.append((p, vertex, key[vertex]))
return mst_edges
创建图并添加边
g = Graph()
g.add_edge("A", "B", 10)
g.add_edge("A", "H", 11)
g.add_edge("A", "G", 14)
g.add_edge("B", "H", 12)
g.add_edge("B", "C", 16)
g.add_edge("C", "D", 15)
g.add_edge("D", "K", 13)
g.add_edge("D", "E", 14)
g.add_edge("E", "K", 13)
g.add_edge("E", "F", 17)
g.add_edge("F", "H", 17)
g.add_edge("F", "G", 16)
g.add_edge("G", "H", 13)
g.add_edge("H", "K", 15)
计算最小生成树
mst = g.prim()
# 打印最小生成树的边和权重
s = 0
for u, v, w in mst:
s += w
print(f"{u} - {v}: {w}")
print('total = ',s)
A - B: 10
A - H: 11
H - G: 13
D - C: 15
G - F: 16
H - K: 15
K - D: 13
K - E: 13
total = 106
根据图的疏密程度选择合适的最小生成树算法是一个重要的考虑因素。下面是对于不同的图疏密程度如何选择算法的一些建议:
-
稀疏图(Sparse Graph):
-
Kruskal算法:对于稀疏图,通常边的数量相对较少,这使得Kruskal算法的效率较高。因为Kruskal算法不依赖于起始点,适合用于连接各个部分的边比较少的情况。如果图是非连通的,Kruskal算法也可以应对。
-
Prim算法:虽然Prim算法也可以用于稀疏图,但在这种情况下,通常Kruskal算法更具优势,因为它的时间复杂度相对较低。
-
-
稠密图(Dense Graph):
-
Prim算法:稠密图通常包含大量的边,此时Prim算法更适合,因为它在连接到当前最小生成树的顶点之间选择边的效率更高。Prim算法的时间复杂度在稠密图中通常比Kruskal算法更低。
-
-
图的连通性:
-
Kruskal算法:如果图是非连通的,Kruskal算法可以构建最小生成森林,而不需要将图变为连通的。这在一些应用中可能很有用。
-
-
起始点选择:
-
Kruskal算法:Kruskal算法不受起始点选择的限制,因此在不同的起始点下可能会得到相同的最小生成树。这对于某些问题可能是一个优点。
-
Prim算法:Prim算法需要指定一个起始点,因此选择起始点可能会影响最终的最小生成树结果。在某些情况下,选择不同的起始点可能导致不同的最小生成树。
-
总的来说,根据图的疏密程度、连通性和起始点选择的灵活性来选择最小生成树算法。通常,如果图较稀疏,可以优先考虑Kruskal算法,如果图较稠密,可以优先考虑Prim算法。然而,具体的应用可能需要根据问题的特点进行权衡和选择。
同学对算法缺乏兴趣或没有时间研究的,最好的选择,也是Python的优势所在,直接导入第三方库。
额外的福利是收获直观可见的无向图,顺便学习一点可视化。
import networkx as nx
import matplotlib.pyplot as plt
#1 创建一个空的无向图
G = nx.Graph()
#2 添加节点
G.add_node("A")
G.add_node("B")
G.add_node("C")
G.add_node("D")
G.add_node("E")
G.add_node("F")
G.add_node("G")
G.add_node("H")
G.add_node("K")
#根据需求添加边两端连接节点
#3 添加边(连接节点)
G.add_edge("A", "B", weight=10)
G.add_edge("A", "H", weight=11)
G.add_edge("A", "G", weight=14)
G.add_edge("B", "H", weight=12)
G.add_edge("B", "C", weight=16)
G.add_edge("C", "D", weight=15)
G.add_edge("D", "K", weight=13)
G.add_edge("D", "E", weight=14)
G.add_edge("E", "K", weight=13)
G.add_edge("E", "F", weight=17)
G.add_edge("F", "H", weight=17)
G.add_edge("F", "G", weight=16)
G.add_edge("G", "H", weight=13)
G.add_edge("H", "K", weight=15)
# 绘制图形
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, node_size=700, node_color='skyblue', font_size=10, font_color='black')
labels = nx.get_edge_attributes(G, 'weight')
nx.draw_networkx_edge_labels(G, pos, edge_labels=labels)
# 查找最小生成树
minimum_spanning_tree = nx.minimum_spanning_tree(G)
print("Minimum Spanning Tree Edges:")
s = 0
for edge in minimum_spanning_tree.edges(data=True):
s += edge[2]['weight']
print(edge)
# 查找节点之间的最短路径
shortest_path = nx.shortest_path(G, source="A", target="D", weight="weight")
print("Shortest Path from A to D:", shortest_path)
# 计算最短路径长度
shortest_path_length = nx.shortest_path_length(G, source="A", target="D", weight="weight")
print("Shortest Path Length from A to D:", shortest_path_length)
# 查找节点之间的最短路径
shortest_path = nx.shortest_path(G, source="H", target="K", weight="weight")
print("Shortest Path from H to K:", shortest_path)
# 计算最短路径长度
shortest_path_length = nx.shortest_path_length(G, source="H", target="K", weight="weight")
print("Shortest Path Length from H to K:", shortest_path_length)
# Total length of Minimum Spanning Tree Edges
print(''' totals ''')
print(minimum_spanning_tree) #Graph with 9 nodes and 8 edges
print([edge for edge in minimum_spanning_tree])
print('total length = ',s)
# 显示图形
plt.show()
输出结果:
Minimum Spanning Tree Edges:
('A', 'B', {'weight': 10})
('A', 'H', {'weight': 11})
('C', 'D', {'weight': 15})
('D', 'K', {'weight': 13})
('E', 'K', {'weight': 13})
('F', 'G', {'weight': 16})
('G', 'H', {'weight': 13})
('H', 'K', {'weight': 15})
Shortest Path from A to D: ['A', 'H', 'K', 'D']
Shortest Path Length from A to D: 39
Shortest Path from H to K: ['H', 'K']
Shortest Path Length from H to K: 15
totals
Graph with 9 nodes and 8 edges
['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'K']
total length = 106
与原题的图等价。

最小生成树为:
('A', 'B', {'weight': 10})
('A', 'H', {'weight': 11})
('C', 'D', {'weight': 15})
('D', 'K', {'weight': 13})
('E', 'K', {'weight': 13})
('F', 'G', {'weight': 16})
('G', 'H', {'weight': 13})
('H', 'K', {'weight': 15})
