hive-sql简单查询之select语句
文章目录
- 1 准备数据
- 2 取出所有行和列
- 3 限制返回行数
- 4 选取指定的列
- 5 重命名列
- 6 单行注释
- 7 distinct 去重
- 8 group by 去重
select语句是最基本最常用的sql语句,也非常简单。
1 准备数据
运行下面代码,在test数据库,新建一个test_zw表,并插入几条测试数据。
drop table if exists test.test_zw;
CREATE TABLE if not exists test.test_zw(
name string COMMENT '姓名',
course string comment '课程',
score double comment '成绩'
)
COMMENT '测试表'
STORED as parquet TBLPROPERTIES('parquet.compression'='SNAPPY');
-- 插入数据
insert into test.test_zw values
('小王','A',100),
('小李','A',90),
('小张','A',90),
('小李','B',80),
('小红','A',80),
('小张','B',80),
('小红','B',100);
2 取出所有行和列
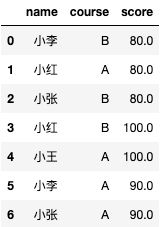
使用星号可以选取所有的列,总共有7条数据,全部返回。
select *
from test.test_zw
3 限制返回行数
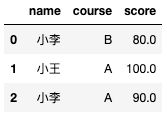
使用limit可以限制返回的行数,当数据表有几千万甚至几十亿数据时,不限制返回行数会出问题,甚至可能搞挂系统,好在大部分的查询系统都有默认的行数限制。限制3行数据,因为没有排序,返回的数据可能不一样。
select *
from test.test_zw
limit 3
4 选取指定的列
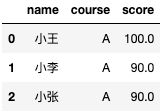
使用星号返回所有列,在宽表中返回字段多,并不是最佳实践,最佳实践是只返回需要的列。有些公司可能禁止使用select * 奥。
select name,course,score
from test.test_zw
limit 3
5 重命名列
英文字段名不太友好,可以进行重命名。使用as关键字进行重命名,as也可以省略。注意中文字段名要用反引号括起来,不然会出错。反引号就是键盘左上角esc下面那个键,按shift可以出来。
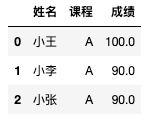
select name as `姓名`
,course as `课程`
,score `成绩`
from test.test_zw
limit 3
6 单行注释
注释后的代码不执行,也可以用来进行代码解释,多写注释,生活简单。
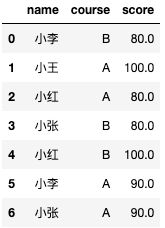
-- 读取学生成绩数据
select name,course,score
from test.test_zw
-- limit 3 -- 限制三行
7 distinct 去重
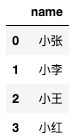
distinct关键字可以去重,返回不重复的学生姓名。
select distinct name
from test.test_zw
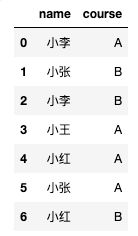
distinct是作用在整行,而不是一个字段,返回不重复的姓名和课程
select distinct name,course
from test.test_zw
数据量大的话,使用distinct去重会很耗资源,很多公司限制使用distinct关键字。
8 group by 去重
groupby分组,刚好可以用来去重,当数据量大时,效率比distinct高很多,返回不重复的姓名。
select name
from test.test_zw
group by name