【CMU15-445 Part-12】Query Execution I
Part12-Query Execution I
Processing Models
Processing Model主要指的是明确如何去执行一个查询计划(top 2 bottom or bottom 2 top,operator之间的传递)。
Iterator Model
(volcano model/pipeline model);每个算子实现一个Next( ),父节点会调用子节点的next,然后子节点返回结果(下一个父节点需要处理的tuple);
对一个tuple来说这种模型能让查询计划中尽可能多的使用它,一个operator处理完返回传入下一个继续用该tuple。

- 遍历子节点next返回的每个tuple,进行projection操作。


pipeline model的原因是针对一个tuple进行了一系列的操作,并且在对一个tuple处理的时候,其他还可以进行去tuple等操作,更像是流水线。当我们将某些东西放到内存之后,在对下一条数据处理前要尽可能多的对该数据进行处理。
有些算子不适合流水线处理,pipeline breaker (joins,subqueries,order by),在去做下个操作前,这些算子需要从子节点获取更多数据。iterator model再输出控制很简单(limit clauses)
Materialization Model
主要用在内存数据库。
调用Next的时候不想只返回一个tuple而是调用每个operator的时候就返回所有的tuples,不用逐个获取。假设需要limit 10,可以将查询信息向下传递来避免扫描很多tuples。返回的可以是一个单独的列或者一个materialized row
这里不同就是output返回的的all tuples。对OLTP wordload来说很好因为查询可以一次性获得少量或者一个tuple。对OLAP不好 因为数据量很大的时候在算子之间传递的代价就会很高

difference? one tuple passing in M model and iterator model?
Vectorized/Bactch Model
调用next的时候传递的是a batch的tuples而非单个tuple,重写next。每次调用Next返回的tuple size 取决于hardware,取决于速度多快,是不是循序IO。设定一个n,如果buffer size 足够一个batch就像上返回一堆tuple。对OLAP友好,因为OLAP主要对表中大部分数据进行长时间的一个扫描处理(数据仓库)

Plan Processing Direction
Approach #1 Top-to-Bottom
root开始 pull data from children,tuples
Approach #2 Bottom-to-Top
从叶子结点开始 向上推data,向上传递数据的时候得确保我们所正在处理的数据能够放在CPU cache and registers,对CPU友好但是对人难以解释。
Access Methods
叶子节点发生的事,通过access methods到DBMS表里面查找数据通过next进行传递。
三种基本方式:循序扫描sequential scan,索引扫描index scan以及multi-Index/”Bitmap” Scan
Sequential Scan
对1个table的每个page,取到bufferpool;迭代器遍历tuple,check是否符合。 DBMS一般会维护内部cursor来tracks last page/slot/tuple?
优化:prefectching(双缓冲)、buffer pool Bypass(用一个小buffer来对线程或者查询进行缓存 而不是去污染buffer pool 缓存)、
-
Zone Maps
提前计算关于page中某列的聚合信息 明确是否需要去访问这些page。即:Min、Max\AVG\SUM\COUNT… DBMS会首先检查zone map然后才会决定会不会访问该page。有些是把zone map存到page里面,所以实际还是访问了page。有些保存在单独的page里面,zone map block、Zone page保存了不同page的zone map,类似于元数据的东西可能放在内存中。维护zone map代价也很高 一般不会用在OLTP中,而是在OLAP,读多写少。
-
Late Materialization
对列式存储系统来说可以延迟将数据从一个oper 传播到下一个oper,只需要传递offset或者判断条件,具体数据很可能不需要的最后,因为列存最后组成tuple的话得拼接,代价大。下面的例子:filter以join算子不需要传递具体的数据因为对应的a,b列用不到,只需要最后去取c列。

-
Heap clustering/Clustering Index 聚簇索引

Index Scan
索引扫描,DBMS选取一个合适的index来找到查询所需要的tuples。选哪个index取决于:
- 哪些属性上有index
- 哪些属性是索引需要的
- 属性的具体值,是否具有选择性能否查得更快
- 具体的判断条件
- unique index / non-unique index
以上是查询优化器要做的事情。
例子:在第一个场景中 要使用dept作为索引 只需要找到两个就可以了。第二个场景是99个人是CS的,就俩人小于30岁,用age作为索引,更有选择性

- Multi-Index Scan:
- 对于每个匹配的index 计算负荷的record ids
- 根据查询的判断条件combine这些sets,and or
- Retrieve the records
Bitmap Scan in PG,没饿过bit对应了每个record的位置,进而可以使用位操作and or出结果。

Index Scan Page Sorting
如果是非聚簇索引,如果输出结果并不是基于索引的id来进行排序,可能是其他的属性排序并且该属性上没有索引,沿着叶子节点扫描获取所有record id,根据page id排序。
DBMS 通常会先找到所有需要的 tuples,根据它们的 page id 来排序,完毕后再读取 tuples 数据,使得整个过程每个需要访问的 page 只会被访问一次。

order by,subquery,join,limit,min,max are all pipeline breakers;
Expression Evaluation
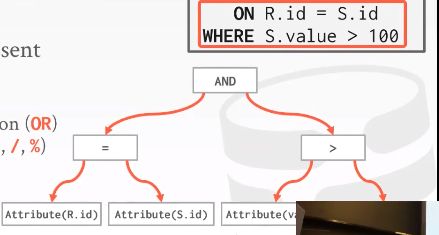
where子句表示为一个表达式树expression tree,该tree上所有节点代表了条件判断中不同类型的表达式,
- comparisons = < > ≠
- conjunction:And Disjunction OR
- Arithmetic Operators + - * /
- 常量
- tuple attribute references
select * from s where B.value = ? + 1;
Prepared Statement 声明查询模板,占位符运行时填入,类似于调用函数
需要关注execution context

优化where 1=1,JIT:just in time compilation。