【CMU15-445 Part-13】Query Execution II
Part13-Query Execution II
talk about how to execute with multiple workers
TCO:Total Cost of Ownship
Parallel VS. Distributed
区分数据库系统的并行执行和分布式数据库系统的分布式执行
数据库通过分散multiple resources 来改善数据库某些方面的性能
Parallel DBMSs:
- 一个系统上可用资源在物理意义上彼此临近
- 可用资源之间通过高速的interconnect 来通讯。
- 通信是被认为cheap and reliable
Distributed DBMSs:
- 可用资源可以离得很远
- 可用资源之间通过slower interconnect 来通信
- 通讯代价和问题不可以忽视,是不可靠的互联
Process Model
如何组织系统来通过多个worker来处理并发请求,系统如何架构来支持多用户的并发请求。Worker就是DBMS执行任务返回结果的一部分。
Approach #1-Process per DBMS Worker
一个进程一个worker,依赖于OS的scheduler,使用shared-memory来利用全局数据结构(不会从磁盘中取一个page 同时在内存中该page有两份),一个进程crash不会影响整个系统。
Approach #2-Process Pool
仍然是一个worker是一个进程但是不会一一对应,有需求就从worker pool里面拿;重点是OS负责调度查询的执行,数据库管不了。
Approach #3-Thread per DBMS Worker
好处:上下文切换的代价小,不需要管理共享内存。
Scheduling
DBMS的dispatcher or coordinator决定怎么拆分任务,使用CPU core来执行,线程之间依赖关系,CPU core应该执行哪些任务,一个task 怎么存储输出。
Inter VS. Intra-Query Parallelism
Inter-Query Parallelism指的是同一时间执行多个不同的查询
Intra-Query Parallelism指的是将一个查询拆分更为多个子任务或者片段,在不同资源上同时并发执行这些任务。具体通过并行执行算子,算子之间的关系就是生产者消费者模式,对每一个关系模型算子都有并行算法,可以通过多线程获取centralized data structures或者分区来工作 9.46
Parallel Grace Hash Join
对bucket进行join,可以对相应的每一层分配一个worker来并行
Intra-Query Parallelism
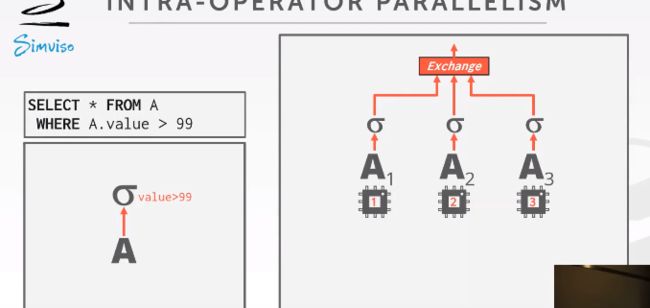
Approach #1:Intra-operator parallelism(Horizontal)
把一个完整操作分成多个平行操作,数据分成多段,每一段的执行函数都一样,使用一个exchange operator来把这些结果组合到一起,在进行分段执行的地方放置Ex Op来合并结果,每个fragment都有一个scan operator 以及 filter operator,如下:
-
Exchange Type #1 - Gather
把不同worker线程执行任务得到的结果或者operator产生的输出进行合并,生成一个单一的输出结果到输出流。
-
Exchange Type #2 - Repartition
shuffle,对多个输入流reorganize然后生成多个输出流
-
Exchange Type #3 - Distribute
拿到一个输入流拆分成多个输出流
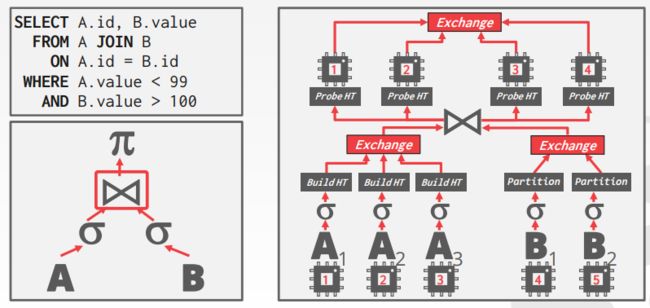
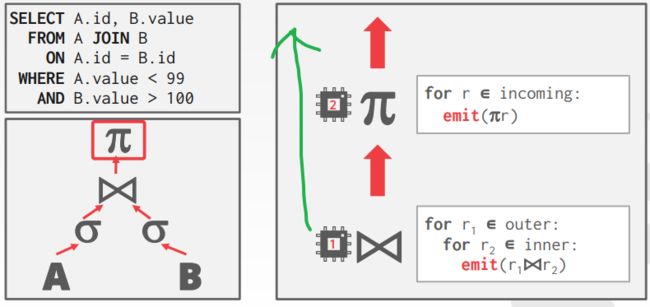
Approach #2:Inter-operator parallelism(Vertical)
不同线程在同一时间执行不同的operator,自旋等待数据传入,读一波数据处理完如果需要再读一下波没有返回结果就等待。类似于生产者消费者模型,但是如果生成的tuple很多速度就会慢,因为生产者消费者的容器需要加锁进行读写。一个线程中任务高内聚,多个线程间低耦合。
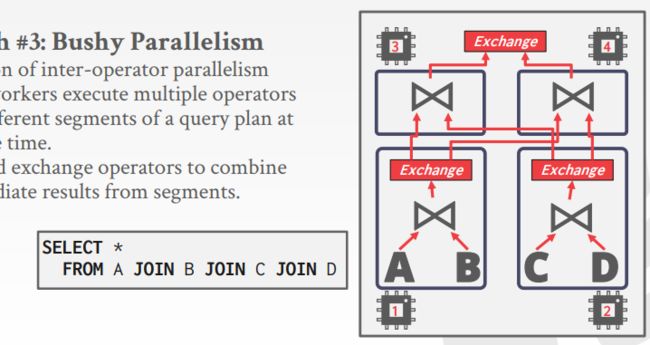
Approach #3:Bushy parallelism
让不同worker在同一个时刻对一个查询计划的不同部分进行操作,依然使用ex op来再op之间移动数据,
I/O Parallelism
对数据库系统的文件和数据进行拆分分散到存储设备上的不同位置上
- Multiple Disks Per Database
- One DB per Disk
- One Relation per Disk
- Split Relation across Multiple Disks
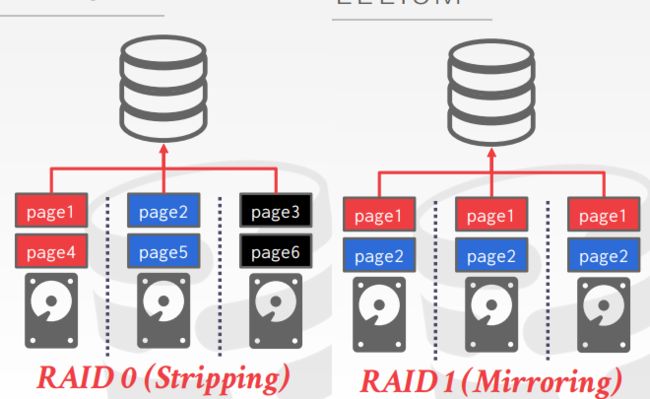
RAID:Redundant Arrays of Independent Disks 独立磁盘构成具有冗余能力的队列
思路是让多个存储设备以单个逻辑设备的形式供DB使用,
Multi-Disk Parallelism
通过配置OS或者硬件来横跨多个存储设备来存储DBMS的文件,可以通过stroage appliances 或者 RAID configuration,对DBMS 是透明的。
例子:一个DBMS有六个page,stripping 数据分条技术,mirror 磁盘镜像,在每个存储设备上保存一份该page的副本。
Database Partitioning
把数据拆分成为不相交的子集然后分配给离散的磁盘。一个单个的逻辑表将表中的数据拆分成不相交的子集,把子集放在不同的存储设备上,进行管理
Vertical Partitioning垂直分区
垂直分区,列存
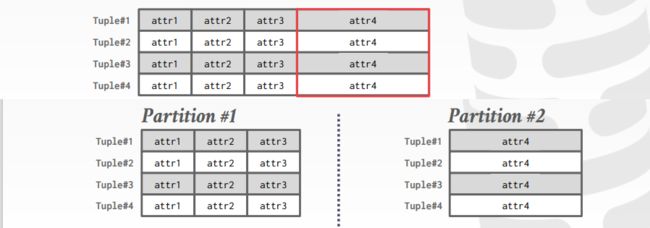
Horizontal Partitioning水平分区
sharding
