05_Oracle-事务-视图-同义词-索引
数据库中的对象:表、视图、索引、序列等。
一 事务
1 什么是事务
一个不可分割的子操作形成一个整体,该整体要么全部执行成功,要么全部执行失败。(例:转帐)
2 为什么要用事务
如果不用事务的话(以转帐为例,可能出现一个用户钱增加了,另一个用户钱不变)
3 回顾编程中,事务可用于哪一层
事务放在业务层
4 回顾jdbc编程中,如何使用事务
connection.setAutoCommit(false);
pstmt.executeUpdate();
connection.commit();
connection.rollback();
5.回顾hibernate编程中,如何使用事务?
transaction.begin();
session.save(new User());
transaction.commit();
transaction.rollback();
6.回顾spring编程中,如何使用事务?
spring可以分为二种:
>编程式事务,藕合
>声明式事务,解藕,提倡
7.Oracle事务只针对
事务针对于DML操作(DML:数据库操作语言),即select/insert/update/delete
8 MySQL的事务开始
start transaction
9.Oracle的事务开始
第一条DML操作:为事务开始
10.Oracle的提交事务
( 1)显示提交:commit
(2)隐藏提交:DDL/DCL/exit(sqlplus工具)
注意:提交是的从事务开始到事务提交中间的内容,提交到ORCL数据库中的DBF二进制文件
11.Oracle的回滚事务
( 1)显示回滚:rollback
(2)隐藏回滚:关闭窗口(sqlplus工具),死机,掉电
注意:回滚到事务开始的地方
12.什么是回滚点?
在操作之间设置的一个标志位,用于将来回滚之用
13.为什么要设置回滚点?
avepoint a;rollback to savepoint a;
如果没有设置回滚点的话,Oracle必须回滚到事务开始的地方,其间做的一个正确的操作也将撤销
14.使用savepoint 回滚点,设置回滚点a
savepoint a;
15.使用rollback to savepoint,回滚到回滚点a处
rollback to savepoint a;
16.Oracle提交或回滚后,原来设置的回滚点还有效吗
原回滚点无效了
17.Oracle之所以能回滚的原因是?
主要机制是实例池
18.MySQL支持的四种事务隔离级别及能够解决的问题
(1)read uncommitted -- 不能解决任何缺点
(2)read committed -- 脏读,Oracle默认
(3)reapatable read -- 不可重复读,脏读,MySQL默认
(4)serializable -- 幻读,不可重复读,脏读,效率低
19.Oracle支持的二种事务隔离级别及能够解决的问题
Oracle支持:read committed 和 serializable
20.Oracle中设置事务隔离级别为serializable
set transaction isolation level serializable;
21.两个用户同时操作emp表,删除KING这条记录,会有什么后果?
因为有隔离级别的存在,所以不会出现二个用户都删除了KING这条记录,一定是一个用户删除KING成功,在该用户没有提交的情况下,另一个用户等待
二 视图(view)
1)概念
视图就是一张虚表,里边包含了一张或者多张表的组合数据。我们可以使用create view语句进行视图的创建。(把多张表的数据整合到一张表中,可以简化开发中的多表查询业务)
视图建立在已有表的基础上, 视图赖以建立的这些表称为基表。(基表可以是一张表也可以是多张表),一个基表可以有0个或者多个视图。
注:视图没有存储真正的数据,真正的数据还是存储在基表中。程序员虽然操作的是视图,但最终视图还会转换为操作基表。
2)什么情况下会用到视图
(1)如果你不想让用户看到所有数据(字段,记录),只想让用户看到某些的数据时,此时可以使用视图
(2)当你经常使用某些sql语句时,就可以使用视图来减化SQL查询语句的编写,但使用视图不提高查询效率
注: 使用视图并不会提高查询效率。视图经常用在多表查询业务中 删除视图中的某条记录会影响基表;将整个视图删除不会影响基表;删除基表会影响视图 删除视图不会进入回收站
3)好处
可以简化开发中的多表查询业务
4)视图创建
语法:CREATE [OR REPLACE] VIEW 视图名 SELECT 子句 [WITH READ ONLY]; 因为视图中的数据一旦被删除,那么基表中的数据也会被删除,非常不安全,所以一般建立只读视图
5)需求
创建一个dept_emp_view的视图,包含员工的名称,编号,薪水和部门编号以及部门名称。(多表查询业务)
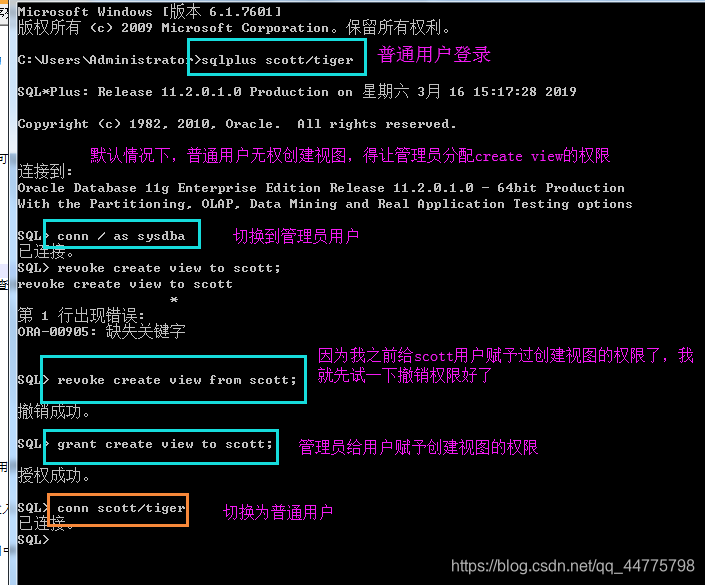

6)创建只读视图
因为视图中的数据一旦被删除,那么基表中的数据也会被删除,非常不安全,所以一般建立只读视图
--创建一个dept_emp_view的视图,包含员工的名称,编号,薪水和部门编号以及部门名称。
CREATE VIEW DEPT_EMP_VIEW AS
SELECT E.ENAME,E.EMPNO,E.SAL,D.DEPTNO,D.DNAME
FROM EMP E,DEPT D
WHERE D.DEPTNO=E.DEPTNO;
--创建只读视图
CREATE OR REPLACE VIEW DEPT_EMP_VIEW
AS
SELECT E.ENAME,E.EMPNO,E.SAL,D.DEPTNO,D.DNAME
FROM EMP E,DEPT D
WHERE D.DEPTNO=E.DEPTNO
WITH READ ONLY;
例:基于emp表指定列,创建视图emp_view_2,该视图包含编号/姓名/工资/年薪/年收入(查询中使用列别名)(只想展示表中的部分数据而不是展示所有的字段业务)
注:
1.nvl函数:如果第一个参数为空,那么显示第二个参数的值;如果第一个参数的值不为空,则显示第一个参数本来的值。 2.as:为关键字
--基于emp表指定列,创建视图emp_view_2,该视图包含编号/姓名/工资/年薪/年收入(查询中使用列别名)
CREATE OR REPLACE VIEW EMP_VIEW_2
AS
SELECT EMPNO 员工编号,ENAME 员工姓名,SAL 工资, SAL*12 年薪,SAL*12+NVL(COMM, 0) 年收入
from EMP
WITH READ ONLY;二 同义词(synonym)
1)概念:
对一些比较长名字的对象(表,视图,索引,序列,。。。)做减化,用别名替代。 类似于起别名,我们数据库中也许有些对象名字比较长,我们就可以给他们起一个别名,这就是同义词。
注:删除同义词不会影响基表;删除基表会影响同义词。
2)同义词的作用
(1)缩短对象名字的长度
(2)方便访问其它用户的对象
3)创建同义词
语法:CREATE synonym 别名 for 对象;
4)需求
给上边创建的视图dept_emp_view起个别名

4)删除同义词
DROP SYNONYM A;
三 索引(Index)
1) 概述
相当于字典的目录一样的东西。 索引包括单列索引和组合索引/多列索引 。
注:索引创建后,只有查询表有关,和其它(insert/update/delete)无关,解决速度问题
2) 作用
提高的是查询效率。
3) 语法
CREATE INDEX 索引名称 ON 表名(字段名,...);
4) 什么时候使用索引,什么时候不使用
1)当表很大(数据多)、列名经常作为连接条件或出现在where语句中、需要做频繁的查询工作的时候考虑创建索引
2)表很小(数据少)、列名不经常作为连接条件或出现在where语句中、表需要做频繁的增删改操作,不要创建索引了
注:
1)创建索引时我们一般在频繁当做条件的字段上添加索引。
2)只有一个字段的索引我们叫做单列索引,有多个字段的索引称为组合索引/多列索引
3)索引是Oracle/mysql这些数据库底层自己调用的,我们没有办法手动调用
5)需求
(1) 给emp表创建一个索引
--给emp表创建一个索引
--多列索引/联合索引 :为多个字段创建索引
CREATE INDEX EMP_INDEX
ON EMP(EMPNO,ENAME);
--单列索引: 为表中的一个字段创建索引
CREATE INDEX EMP_EMPNO_INDEX
ON EMP(EMPNO);
--删除索引
DROP INDEX EMP_INDEX;
(2) 删除索引
DROP INDEX EMP_INDEX;
五 序列(Sequence)
1)概念
序列可以自动递增,实现oracle中主键的自动递增。序列可以保证唯一但是不能保证连续
(类似于MySQL中的auto_increment自动增长机制,但Oracle中无auto_increment机制;是oracle提供的一个产生唯一数值型值的机制;通常用于表的主健值;序列只能保证唯一,不能保证连续 (声明:oracle中,只有rownum永远保持从1开始,且继续);序列值,可放于内存,取之较快)
2)为什么oracle不直接用rownum做主健呢
rownum=1这条记录,不能永远唯一表示SMITH这个用户(rownum一直是从1开始,并且是连续的 如果从表中删了一条数据的话,rownum就又重新排序)
但主键=1却可以永远唯一表示SMITH这个用户,所以使用的是序列
3)为什么要用序列
在oracle中,我们为主键设置值,需要人工设置值,容易出错。所以使用序列,可以自动生成值,并且是唯一的
4)创建序列
语法:CREATE SEQUENCE 序列名; 每次递增1,没有最大值
5)案例
(1)为emp表的empno字段,创建序列emp_empno_seq
查询emp_empno_seq序列的当前值currval和下一个值nextval 第一次使用序列时,必须选用:序列名.nextval
注:序列在使用之前必须初始化
--为emp表的empno字段,创建序列emp_empno_seq
CREATE SEQUENCE EMP_EMPNO_SEQ;
--查询emp_empno_seq序列的当前值currval和下一个值nextval
--注:第一次使用序列时,必须选用:序列名.nextval(序列初始化)
SELECT EMP_EMPNO_SEQ.NEXTVAL FROM DUAL;
--查询序列的当前值:currval
SELECT EMP_EMPNO_SEQ.CURRVAL FROM DUAL;
--查询序列的下一个值
SELECT EMP_EMPNO_SEQ.NEXTVAL FROM DUAL;
--删除序列
DROP SEQUENCE EMP_EMPNO_SEQ;

(2)使用序列,向emp表插入记录,empno字段使用序列值
INSERT INTO EMP(EMPNO) VALUES(EMP_EMPNO_SEQ.NEXTVAL);

(3)删除序列emp_empno_seq
DROP SEQUENCE EMP_EMPNO_SEQ;
例:
8.修改emp_empno_seq序列的increment by属性为20,默认start with是1,alter sequence 序列名
alter sequence emp_empno_seq
increment by 20;
9.修改修改emp_empno_seq序列的的increment by属性为5
alter sequence emp_empno_seq
increment by 5;
10.修改emp_empno_seq序列的start with属性,行吗
alter sequence emp_empno_seq
start with 100;
11.有了序列后,还能为主键手动设置值吗?
insert into emp(empno) values(9999);
insert into emp(empno) values(7900);
(4)完整语法
CREATE [OR REPLACE] SEQUENCE name
[INCREMENT BY n] 递增步长默认是1
[START WITH n] 初始化值
[{MAXVALUE n | NOMAXVALUE}] 最大值
[{MINVALUE n | NOMINVALUE}] 最小值
[{CYCLE | NOCYCLE}] 是否循环,默认不循环
[{CACHE n | NOCACHE}] 是否缓存到内存中,默认不存储到内存中
注:删除表,会影响序列吗? 删除表之后不能做insert操作
删除序列,会影响表吗? 表真正亡时,序列才会真正亡