lecture1 Introduction-笔记
本文参考了该作者的一些图解和见解:https://zhuanlan.zhihu.com/p/128156349
由于疫情原因,偶然间学习了南大的软件分析(Static Analysis)课程,后面会用SA来替代Static Analysis,因此从该篇起将每一节课的内容做一些记录和个人补充。若存在一些不合理或者有错的地方,请小伙伴们指出来。
一、什么是静态分析&为什么要用静态分析?
Programming Languages领域主要关注以下三个方面:
其中,Application是本课的重点内容,这个部分关注在运行前能对程序代码进行的一些工作,例如错误检测,代码优化等等,IDE里面就大量应用了SA的成果,如变量未定义的错误提示,循环中的不变量表达式的移出优化;程序的静态验证(或者叫程序证明),程序合成等等。
Static analysis analyzes a program P to reason about its behaviors and determines whether it satisfies some properties before running P.
• Does P contain any private information leaks?
• Does P dereference any null pointers?
• Are all the cast operations in P safe?
• Can v1 and v2 in P point to the same memory location?
• Will certain assert statements in P fail?
• Is this piece of code in P dead (so that it could be eliminated)?
根据以上可知,SA也就是判断程序是否满足一些Non-trivial(非平凡特性) Properties(例如以上几点),而这些特性就是我们所需要判断的程序运行时行为的一些相关特性,如程序的安全性、可靠性等。
由于程序的复杂性在不断上升,对于程序的可靠性(reliability)、安全性(security)的要求也在不断上升,而静态分析则给予了这样一个工具来让我们能够对程序进行分析,实现查错、编译优化等功能。而SA主要用的技术有抽象解释(Abstract interpretation),数据流分析(Data-flow analysis, ),Hoare logic,Model checking,Symbolic execution等等,本课程只会讲到其中的两个,分别是数据流分析和抽象解释,重点讲的是数据流分析。
二、Implement Static Analysis
然而SA并不能给予一个exact answer:Yes or No,但能通过Sound和Comlete来满足我们的需求。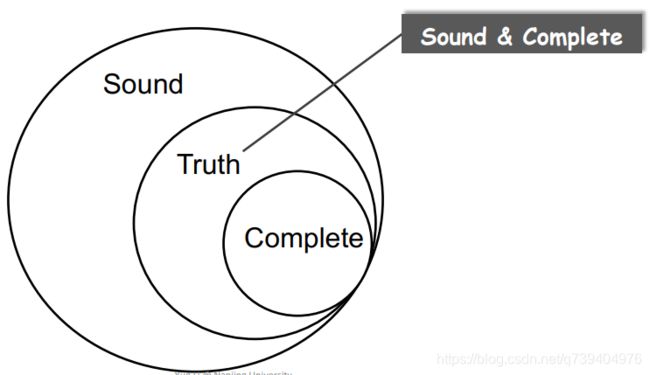
以SA的检错分析举例:
Truth:检测正确,没有发生误报和漏报;
Sound:全面,表示包含了Truth,但产生了误报,一定不会漏报;
Complete:属于Truth,一定不会误报,但会产生漏报,适用于不可发生分析错误的情况;
用个代码分析例子来说明什么是overapproximate也即sound和underapproximate也即complete:
if (input) {
x = 1
} else {
x = 0
}对于这样的一段代码,静态分析的结果报告如果 x∈{0,1} ,就说这个静态分析是完美的,如果报告x∈{0},就说这个分析是complete的(也说对程序进行了underapproximate),如果报告x∈{0,1,2}就说这个分析是sound(也说对程序进行了overapproximate),如果报告是x∈{0,-1},就是既发生了漏报(漏报1),也发生了误报(误报-1),则这个分析是错误的。
还是上面的例子,
- x∈{0,1}
- x = 1 when input == true, x = 0 when input == false
可以看出第二种的精度更高一些,因为报告中包含了x具体情况下的取值,但是这种方式也要求分析过程维护上下文信息,从而提高了分析的代价,而静态分析的目标应该是在确保(或尽量接近)sound的前提下在精度和速度上做一个平衡,试想一下IDE在你写下使用一个未初始变量的代码后二十秒后才给出提示,做静态分析要把握住精度的控制,不然极端情况下岂不是要把静态分析往解释器的方向写了吗?
因此并不存在完美的SA,也即是Truth情况。所以SA只能选择妥协completeness保全soundness或妥协soundness保全completeness。大多数情况下,保全soundness是较为常见的用法,如航天军工等程序,宁愿花费更多的人力去进行bug真伪检验,也不希望出现漏检,又如编译器优化和程序验证等。
最后,实现SA的两步骤如下所示:Abstraction+Over-approximation
1、Abstraction
下图中,左边为程序,右边为抽象的结果。分为正、负、0、unknown和undefined。其中v不知道他是0、+、-则为unknown,而w/0发生了错误,为undefined。这是一个从“算术表达式”到“符号”的抽象。

2、Over-approximation
(1)Transfer functions
有了数据抽象之后,还需要定义一个transfer function,transfer function是作用在程序代码的抽象值上的,对应这个例子就是从“算术表达式抽象符号”到“符号”上的函数,有以下定义:
transfer function:
map: + + + = +
map: - + - = -
map: 0 + 0 = 0
map: + + - = unknown
map: + / + = +
map: - / - = +
map: unknown / 0 = undefined
map: + / - = -然后用上面的抽象值和transfer function在代码上做overapproximate分析,得到下面的结果
#include
void main() {
int arr[3] = {0, 1, 2};
int x = 10; // +
int y = -1; // -
int z = 0; // 0
int a = x + y; // unknown
int b = z / y; // 0
int c = a / b; // undefined 除0错误
int p = arr[y];
int q = arr[a];
printf("the number is %d", q);
} (2)Control flows
由下图可见,一个简短的程序拥有两个分支路径,数据的流动根据实际需求来决定。引用老师的一句话:As it’s impossible to enumerate all paths in practice,flow merging (as a way of over-approximation 过度逼近方式) is taken for granted in most static analyses.可知枚举所有路径是不可能的事,那么如何选择,在第三节开始会具体谈及。
