FairMOT 论文学习
1. 解决了什么问题?
现有的多目标跟踪方案将目标检测和 reID 任务放在一个网络里面优化学习,计算效率高。目标检测首先在每一帧中检测出兴趣目标,要么将其与现有的轨迹关联起来,要么创建一个新的轨迹。这两个任务会相互竞争,现有的方法都将 reID 任务列为次优先级任务,而检测任务为主优先级,reID 的准确率受检测影响很大,这对 reID 不公平。当场景中目标很多时,先检测再跟踪的方式无法取得实时的效果,因为这两个模型并不共享特征,需要对每个目标框分别使用 reID 模型。
对于现有的方法,提出了三点问题:
- Anchors 常用于目标检测,不适合提取 reID 特征。因为基于 anchors 的跟踪器会先在 RPN 中使用 anchors 检测目标,然后根据检测结果提取 reID 特征。如果检测结果错了,则 reID 特征没意义。因此当两个任务相互竞争时,它会偏向检测任务。训练 reID 特征时,anchors 会造成不少歧义:一个 anchor 可能对应多个 ID,一个 ID 可能对应多个 anchors。
- 第二个问题就是检测和 reID 任务是完全不同的,它们需要不同的特征。reID 需要的是更低层级的特征,来区分同类别的不同实例;而对于检测任务来说,不同实例的特征要更加相近。特征共享会造成特征间的冲突,使每个任务的表现受损。
- 第三个问题就是特征维度。reID 特征的维度通常设为 512 或 1024,要远高于目标检测需要的维度。这也会降低两个任务的表现。
2. 提出了什么方法?
提出了一个基于 CenterNet 目标检测的方法 FairMOT,同等对待检测和 reID 任务,与之前的“先检测再 reID” 的框架不同。检测分支是 anchor-free 的,用位敏图表征目标的中心点和大小。对于每个目标的中心点,reID 分支预测其所表征目标的 reID 特征。这俩分支几乎一样,而以前的方法是先检测再 reID 的双阶段级联方式。FairMOT 可以学习高质量的 reID 特征,平衡检测任务和 reID 任务。
2.1 Unfairness issues in one-shot trackers
现有的 one-shot 跟踪方案主要有三个问题,造成表现变差。
2.1.1 Unfairness Caused by Anchors
基于 anchors 的设计并不适合学习 reID 特征,造成大量的 ID 切换问题。
- 忽略了 reID 任务:Track RCNN 首先预测一组目标候选框,然后从它们中提取特征,预测出相应的 reID 特征。训练时,reID 特征质量严重依赖于候选框的质量。这样训练时,模型就会努力去预测准确的目标候选框,而不是学习高质量的 reID 特征。因此,这种先检测再 reID 的方案并不能让 one-shot 跟踪器公平地学习。
- 一个 anchor 对应多个 IDs:基于 anchors 的方法通常使用 ROI-Align 从候选框提取特征。ROI-Align 中大多数的采样点可能属于其它干扰实例或背景,这样提取的特征就无法最优地表示目标物体。作者发现,只使用一个点提取特征效果更好,即预测目标的中心点。
- 一个 ID 对应多个 anchors:多个相邻的 anchors 可能被迫去预测相同的 ID,只要它们的 IOU 足够大。这会引起一定的歧义。另一方面,当图像发生一定的扰动时,同一个 anchor 可能会预测不同的 ID。目标检测通常使用 8/16/32 倍下采样提取特征图,平衡速度和准确率。这对 reID 特征学习来说太粗糙了,anchors 的特征与目标中心点有可能不对齐。
2.1.2 Unfairness Caused by Features
对于 one-shot 跟踪器,目标检测和 reID 特征是共享的。目标检测需要深度特征来预测目标类别和位置,而 reID 特征需要浅层特征来区分同类别的不同实例。在损失函数中,这俩优化目标是冲突的。
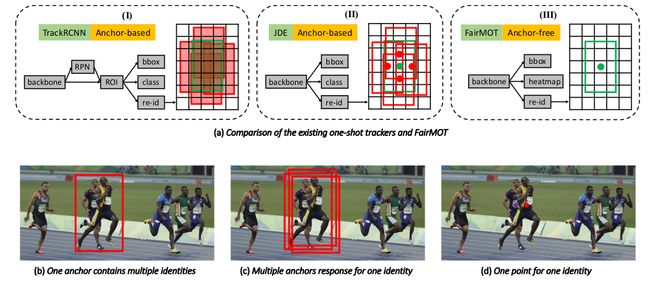
上图(a) 中 Track RCNN 将 re-ID 看作为次要任务,而检测是主要任务。Track RCNN 和 JDE 都是基于 anchors 的。红框表示 positive anchors,绿框表示目标框。Track RCNN 使用 ROI-Align 提取所有 positive anchors 的 reID 特征。JDE 提取所有 positive anchors 中心点的 reID 特征。FairMOT 只提取中心点的 reID 特征。(b) 红色 anchor 包含两个不同的实例,会导致预测两个冲突类别。© 不同的 anchors 对应着同一个 ID。(d) FairMOT 只提取目标中心点的 reID 特征,缓解了 © 与 (d) 的问题。
2.1.3 Unfairness Caused by Feature Dimension
现有的 reID 方法通常学习高维度特征,作者发现对于 one-shot MOT 任务,学习低维度特征更好。因为,
- 高维度 reID 特征对目标检测表现不利,因为这俩任务会相互竞争。考虑到目标检测的特征维度比较低(类别数+边框坐标),学习低维特征能平衡这俩任务。
- MOT 任务和 reID 任务不同,MOT 任务只需在连续两帧之间进行少量的 one-to-one 匹配。reID 任务则需要将 query 和大量候选样本进行匹配,需要更高维度的 reID 特征。因此,MOT 并不需要高维度特征。
- 低维度 reID 特征能够提升推理速度。
2.2 FairMOT
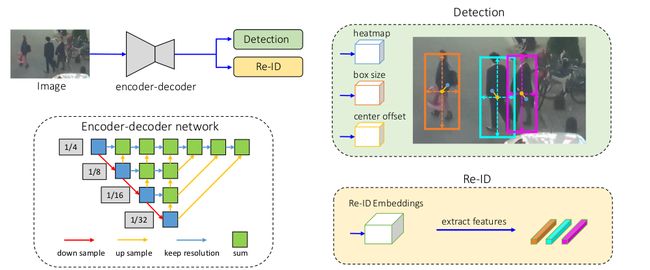
2.2.1 Backbone
主干网络是 ResNet-34,平衡速度和准确率。上图主干使用的是 DLA,融合多层特征。与原始 DLA 相比,它在低层级和高层级特征之间增加了短路连接,与 FPN 相似。此外,所有上采样模块中的卷积层替换为了可变形卷积,根据目标尺度和姿态动态调整感受野。这样得到的模型就是 DLA-34。输入图像记做 H i m a g e × W i m a g e H_{image}\times W_{image} Himage×Wimage,输出特征图形状为 C × H × W , H = H i m a g e 4 , W = W i m a g e 4 C\times H\times W, H=\frac{H_{image}}{4},W=\frac{W_{image}}{4} C×H×W,H=4Himage,W=4Wimage。
2.2.2 检测分支
构建于 CenterNet 基础上。在 DLA-34 上面是 3 个并行的 heads,预测热力图、目标中心偏移量和边框大小。每个 head 使用 256 256 256通道的 3 × 3 3\times 3 3×3卷积计算 DLA-34 的输出特征,然后是 1 × 1 1\times 1 1×1卷积层输出最终结果。
2.2.2.1 Heatmap Head
负责预测每个目标中心点的位置。基于热力图的表征是预测关键点任务的标准做法。热力图维度是 1 × H × W 1\times H\times W 1×H×W,如果一个位置与 ground-truth 目标的中心点重合,则该位置的响应值为 1 1 1。该响应值会随着坐标与目标中心点的距离疏远而呈指数级降低。
对于每个 GT 框 b i = ( x 1 i , y 1 i , x 2 i , y 2 i ) \mathbf{b}^i=(x_1^i, y_1^i, x_2^i, y_2^i) bi=(x1i,y1i,x2i,y2i),通过 c x i = x 1 i + x 2 i 2 c_x^i=\frac{x_1^i+x_2^i}{2} cxi=2x1i+x2i和 c y i = y 1 i + y 2 i 2 c_y^i=\frac{y_1^i+y_2^i}{2} cyi=2y1i+y2i计算目标中心点 ( c x i , c y i ) (c_x^i, c_y^i) (cxi,cyi)。然后它在特征图上的位置是: ( c ~ x i , c ~ y i ) = ( ⌊ c x i 4 ⌋ , ⌊ c y i 4 ⌋ ) (\tilde{c}_x^i,\tilde{c}_y^i)=(\lfloor \frac{c_x^i}{4}\rfloor,\lfloor \frac{c_y^i}{4}\rfloor) (c~xi,c~yi)=(⌊4cxi⌋,⌊4cyi⌋)。位置 ( x , y ) (x,y) (x,y)的响应值是 M x y = ∑ i = 1 N exp [ − ( x − c ‾ x i ) 2 + ( y − c ‾ y i ) 2 2 σ c 2 ] M_{xy}=\sum_{i=1}^N \exp \left[-\frac{(x-\overline{c}_x^i)^2 + (y-\overline{c}_y^i)^2}{2\sigma_c^2}\right] Mxy=∑i=1Nexp[−2σc2(x−cxi)2+(y−cyi)2], N N N表示目标个数, σ c \sigma_c σc是标准方差。损失函数基于 Focal loss:
L heat = − 1 N ∑ x y { ( 1 − M ^ x y ) α log ( M ^ x y ) , M x y = 1 ( 1 − M x y ) β ( M ^ x y ) α log ( 1 − M ^ x y ) , otherwise \begin{align} L_{\text{heat}}=-\frac{1}{N}\sum_{xy}\begin{cases} (1-\hat{M}_{xy})^{\alpha}\log(\hat{M}_{xy}),&\quad M_{xy}=1\\ (1-{M}_{xy})^{\beta}(\hat{M}_{xy})^{\alpha}\log(1-\hat{M}_{xy}),&\quad\text{otherwise} \end{cases} \nonumber \end{align} Lheat=−N1xy∑{(1−M^xy)αlog(M^xy),(1−Mxy)β(M^xy)αlog(1−M^xy),Mxy=1otherwise
M ^ \hat{M} M^是预测的热力图, α , β \alpha,\beta α,β是 focal loss 的超参数。
2.2.2.2 Box Offset and Size Heads
边框偏移 head 让目标定位更加准确。最终特征图的步长是 4,会引入至多为 4 个像素的量化误差。对于每个像素点,该分支预测关于目标中心点的连续的偏移量,缓解下采样的影响。Box size head 预测每个位置目标框的高度和宽度。
Size head 的输出记做 S ^ ∈ R 2 × H × W \hat{S}\in \mathbb{R}^{2\times H\times W} S^∈R2×H×W,offset head 的输出记做 O ^ ∈ R 2 × H × W \hat{O}\in\mathbb{R}^{2\times H\times W} O^∈R2×H×W。对于图中每个 GT 框 b i = ( x 1 i , y 1 i , x 2 i , y 2 i ) \mathbf{b}^i=(x_1^i, y_1^i, x_2^i, y_2^i) bi=(x1i,y1i,x2i,y2i),计算 GT size 为 s i = ( x 2 i − x 1 i , y 2 i − y 1 i ) \mathbf{s}^i=(x_2^i-x_1^i, y_2^i-y_1^i) si=(x2i−x1i,y2i−y1i)。GT offset 计算为 o i = ( c x i 4 , c y i 4 ) − ( ⌊ c x i 4 ⌋ , ⌊ c y i 4 ⌋ ) \mathbf{o}^i=(\frac{c_x^i}{4},\frac{c_y^i}{4})-(\lfloor\frac{c_x^i}{4}\rfloor,\lfloor\frac{c_y^i}{4}\rfloor) oi=(4cxi,4cyi)−(⌊4cxi⌋,⌊4cyi⌋)。将相应位置预测的 size 和 offset 记做 s ^ i , o ^ i \hat{\mathbf{s}}^i,\hat{\mathbf{o}}^i s^i,o^i。对这两个 heads 使用 l 1 l_1 l1损失:
L box = ∑ i = 1 N ∥ o i − o ^ i ∥ 1 + λ s ∥ s i − s ^ i ∥ 1 L_{\text{box}}=\sum_{i=1}^N \left\| \mathbf{o}^i - \hat{\mathbf{o}}^i\right\|_1 + \lambda_s \left\|\mathbf{s}^i - \hat{\mathbf{s}}^i\right\|_1 Lbox=i=1∑N oi−o^i 1+λs si−s^i 1
λ s \lambda_s λs是加权系数,设为 0.1 0.1 0.1。
2.2.3 Re-ID 分支
Re-ID 分支输出的特征能区分不同的目标。不同目标的相似度应该低于相同的目标之间的相似度。作者在主干网络上使用了一个 128 维的卷积层,提取每个位置的 ReID 特征。将该特征图记做 E ∈ R 128 × H × W \mathbf{E}\in \mathbb{R}^{128\times H\times W} E∈R128×H×W。特征图上位置 ( x , y ) (x,y) (x,y)的 ReID 特征是 E x y ∈ R 128 \mathbf{E}_{xy}\in \mathbb{R}^{128} Exy∈R128。
2.2.4 Re-ID Loss
通过分类任务学习 re-ID 特征。训练集中,同一 ID 的所有目标实例被认为属于同一类别。对于每个 GT 框 b i = ( x 1 i , y 1 i , x 2 i , y 2 i ) \mathbf{b}^i=(x_1^i,y_1^i,x_2^i,y_2^i) bi=(x1i,y1i,x2i,y2i),获取热力图上目标的中心点 ( c ~ x i , c ~ y i ) (\tilde{c}_x^i,\tilde{c}_y^i) (c~xi,c~yi)。提取 re-ID 特征向量 E c ~ x i , c ~ y i \mathbf{E}_{\tilde{c}_x^i,\tilde{c}_y^i} Ec~xi,c~yi,用全连接层和 softmax 操作将其映射为一个类别分布向量 P = { p ( k ) , k ∈ [ 1 , K ] } \mathbf{P}=\lbrace \text{p}(k),k\in \left[1,K\right]\rbrace P={p(k),k∈[1,K]}。将 GT 类别标签用 one-hot 表示为 L i ( k ) \mathbf{L}^i(k) Li(k)。这样 re-ID 损失为:
L identity = − ∑ i = 1 N ∑ k = 1 K L i ( k ) log ( p ( k ) ) L_{\text{identity}}=-\sum_{i=1}^N\sum_{k=1}^K \mathbf{L}^i(k)\log(\mathbf{p}(k)) Lidentity=−i=1∑Nk=1∑KLi(k)log(p(k))
K K K是训练集中 ID 的个数。训练过程中,只会使用目标中心点的 ID 特征向量。
2.3 训练
联合训练检测分支和 re-ID 分支。使用 uncertainty loss 自动平衡检测和 re-ID 任务:
L detection = L heat + L box L_{\text{detection}}=L_{\text{heat}}+L_{\text{box}} Ldetection=Lheat+Lbox
L total = 1 2 ( 1 e w 1 L detection + 1 e w 2 L identity + w 1 + w 2 ) L_{\text{total}}=\frac{1}{2}(\frac{1}{e^{w_1}}L_{\text{detection}}+\frac{1}{e^{w_2}}L_{\text{identity}}+w_1+w_2) Ltotal=21(ew11Ldetection+ew21Lidentity+w1+w2)
w 1 , w 2 w_1,w_2 w1,w2是平衡两个任务的可学习参数。给定一张图像和若干个目标,以及它们的 IDs,生成热力图、box offset 和 size maps,以及目标的 one-hot 类别表征。
FairMOT 提出了单张图像的训练方法。CenterTrack 使用两个连续帧图像作为输入,FairMOT 只使用单张图像作为输入。每个边框有唯一的 ID,因此每个目标实例都是单独的一类。对整张图像做各种变换,包括 HSV 增广、旋转、缩放、平移和裁剪。单张图像的训练策略有多个重要意义。
2.4 在线推理
2.4.1 网络推理
输入帧大小是 1088 × 608 1088\times 608 1088×608。对预测的热力图,使用 NMS 提取峰值关键点。用一个简单的 3 × 3 3\times 3 3×3最大池化操作实现 NMS。若关键点的热力图分数高于阈值,保留它。然后根据预测的偏移量和边框大小,计算相应的边框。提取预测目标中心点的 ID 特征。
2.4.2 在线关联
使用了一个启发式在线数据关联的方法。首先,根据第一帧的检测框初始化一组 tracklets,然后在后续帧,通过双阶段的匹配策略将检测框和现有的 tracklets 关联起来。在第一个阶段,使用 Kalman filter 和 reID 特征得到初始的跟踪结果。使用 Kalman filter 预测后续帧的 tracklet 位置,计算预测框和检测框的 Mahalanobis 距离 D m D_m Dm。将 D m D_m Dm融合到 reID 特征的余弦距离中: D = λ D r + ( 1 − λ ) D m , λ = 0.98 D=\lambda D_r + (1-\lambda)D_m,\quad \lambda=0.98 D=λDr+(1−λ)Dm,λ=0.98。如果 D m D_m Dm大于某阈值,则设为无穷大。使用 Hungarian 算法(匹配阈值为 τ 1 = 0.4 \tau_1=0.4 τ1=0.4)完成第一阶段的匹配。
在第二阶段,对于未匹配的检测框和 tracklets,根据它们边框的 IoU 来匹配。匹配阈值设为 τ 2 = 0.5 \tau_2=0.5 τ2=0.5。在每个时间步骤,更新 tracklets 的外观特征,以解决外观变动。最后将未匹配的检测框初始化为新的 tracks,将未能匹配的检测框保留 30 帧以防止再次出现。