A Simple Baseline for multi-object Tracking(FairMOT)论文阅读笔记
FairMOT论文笔记
-
- (一)Title
- (二)Summary
- (三)Research Obejct
- (四)Problem Statement
- (五)Method
-
- 5.1 backbone
- 5.2 Object Detection Branch
- 5.3 Identity Embedding Branch
- 5.4 Loss Functions
- 5.5 在线跟踪
- (六)Experiment
-
- 6.1 数据集
- 6.2 实现细节
-
- 实验1
- 实验2 Multi-Layer Aggregation的影响
- 实验3 对Re-ID特征维度的选择
- 实验4 和State-of-the-arts的比较
- (七)Conclusion
- (八)Notes
-
- 8.1 multi-object tracking中的核心部件
- 8.2 State-of-art模型的做法
- 8.3 MOT问题的解决方法
-
- two-step MOT
- one-shot MOT
- (九)Sentences
(一)Title

前言:目前人流量统计中,往往能够检测摄像头视频中指定区域进出人数,仅仅使用目标检测算法有些困难,因此,打算入坑目标跟踪,利用跟踪算法来重新考虑人流量统计这个问题。目前多目标跟踪的最先前沿使用GCN(图卷积神经网路),循环神经网络(Transformer.GRU)。不过本文的出发点基于anchor-free框架,针对Re-ID提出提升方法Multi-Layer Aggregation,同时指出使用anchors带来的ambiguities问题。
论文地址:https://arxiv.org/pdf/2004.01888v2.pdf
代码地址:https://github.com/ifzhang/FairMOT
(二)Summary
目标检测:object detection和 再识别:re-identification是多目标跟踪的核心组成部分,近年来取得了显著的进展。然而,很少有人关注在单个网络中完成这两项任务来提高推理速度。
性能表现:
作者提出的simple baseline在公开数据集上的表现超过了state-of-arts,并且具有可以达到30FPS的速度。
作者在尝试将object detection和re-identification结合在一起失败之后,从失败的结果中分析原因,得到了对跟踪结果至关重要的3个因素:
-
Anchor don’t fit Re-ID
目前one-shot跟踪器都是基于anchors,它们是从object detection框架中修改得到的。但是作者指出anchors并不适合去学习Re-ID特征anchors不适合学习Re-ID特征的原因:

首先,很多anchors,对应着不同的image patches,可能用于去估计相同的目标的identity,这会造成网络严重的ambiguities。这里博主理解的意思是对于同一个目标,会产生很多的预测框,而Re-Identification是基于每一个预测bounding boxes获取特征的,此时,在anchor-based的方法中,就会出现一个目标对应多个预测bounding boxes(作者希望在同一个网络中实现object detection和re-identification,而anchor-based的方法中往往使用NMS做后处理来筛出多余的预测框,在网络内部无法实现一个目标和一个bounding box对应上,从而导致Re-identification得到了若干个结果,从而产生ambiguities问题)。
接着,使用anchors的第二个问题是:特征图往往进行了8倍下采样来balance效率和速度,这对于目标检测来说是可以接受的,但是对于ReID来说过于coarse,the object centers may not align with the features extracted at coarse anchor locations for predicting the object’s identity作者这里将MOT问题看成是pixel-wise的关键点(object center)估计问题
-
Multi-Layer Feature Aggregation(多层特征的聚合)
Multi-Layer Feature Aggregation对于MOT来说是非常重要的,Re-ID特征需要利用low-level和high-level特征来容纳小目标和大目标。作者实验中发现:Multi-Layer Aggregation is helpful to reduce identity switches for the one-shot methods due to the improved ability to handle scale variatioins
然而这种提升对于two-step 方法是less significant,这是由于在crop和resize操作之后,目标会有相似的scales -
ReID特征的维度
之前的ReID方法往往学习一个高维特征,并在高维特征上取得了一个promising的结果,然而,我们发现对于MOT来说,低维特征实际上更好,因为它们和ReID相比来说有更少的训练图像,学习低维特征有利于降低模型过拟合的风险,并且提高跟踪的鲁棒性。
(三)Research Obejct
作者希望将目标检测任务和re-Identification任何在单个网络中实现从而获得更快的inference速度,但是在整合过程中遇到问题,the ID switches increases a lot,基于此,作者分析了将目标检测和重识别整合到一起存在的问题,基于这些思路来进行网络的设计。
(四)Problem Statement
作者他们尝试在单个网络中同时加入object detection和re-identification,但是没能得到一个好的结果,他们分析原因为:re-identification分支没能够被很好地学习。并且整理出3个利于跟踪的要素:
- Anchors don’t fit Re-ID
- Multi-Layer Feature Aggregation
- Dimensionality of the ReID Features,较少的维度更有利
(五)Method

作者提出方法的一个整体框架如上图所示,首先基于一个anchor-free的方法在high-resolution特征图上进行object centers的一个估计。消除掉anchors能够缓解ambiguity问题,并且使用高分辨率的特征图能够更好地对齐目标的中心。
作者使用一个parallel 分支用于估计pixel-wise Re-ID特征用来预测目标的id,这里比较特别的是,作者使用了一个low-dimensional Re-ID特征,不仅减少了计算时间,而且提高了特征匹配的鲁棒性。
作者为backbone网络配置了Deep Layer Aggregation 操作用于融合多层的特征,从而处理不同尺度的目标。
作者使用anchor-free的方法,用于目标检测和identity embedding,从而显著地提升了跟踪效率。
5.1 backbone
- 作者采用ResNet-34作为backbone,tradeoff between accuracy以及speed
- 作者在backbone上应用了一种variant of Deep Layer Aggregation(DLA),这个是不同于原始的DLA的,他有更多的skip connections在low-level和high-level特征之间,和Feature Pyramid Network(FPN)非常similar。
- 所有的上采样层中的卷积都是用deformable convolution layers进行替换的,使得他们能够根据object scales以及poses动态地适应receptive filed
- backbone的输入size大小为 H i m a g e × W i m a g e H_{image} \times W_{image} Himage×Wimage,输出size大小为 C × H × W C \times H \times W C×H×W,其中 H = H i m a g e / 4 H=H_{image}/4 H=Himage/4, W = W i m a g e / 4 W = W_{image}/4 W=Wimage/4
5.2 Object Detection Branch
作者将目标检测看成high-resolution feature map基于关键点(center-point)的一个regression问题,并且使用了3个parallel regression heads连接到backbone的输出上,分别去估计heatmaps,bounding box sizes,object center offsets。每一个head是通过一个 3 × 3 3 \times 3 3×3的带有256个通道的卷积,接着跟着一个 1 × 1 1 \times 1 1×1的卷积层产生了最后的目标。
- Heatmap Head
用于估计目标的中心位置,在heatmap上一个位置的响应是:在目标中心为1,随着heatmap上位置和物体中心之间的距离而指数衰减。 - Center Offset Head
用于更精确地定位objects,预测center offset head对于目标检测性能来说可能是微乎其微,但是对于Re-ID来说就至关重要了。作者通过实验发现ReID特征和目标中心点careful对齐对于性能来说是至关重要的。 - Box Size Head
这个head是负责估计target bounding box的height和width。这边的回归精度影响目标检测性能的评估。
5.3 Identity Embedding Branch
这里identity Embedding branch的作用是生成features 用于区分不同的目标,理想情况下,不同的objects之间的距离应当比相同object之间的距离要大,作者在backbone特征上,对于每一个location使用128个核的卷积来提取identity embedding features。
输出结果为 E ∈ R 128 × W × H \mathbb E \in R^{128 \times W \times H} E∈R128×W×H,在特征图 ( x , y ) (x,y) (x,y)位置的identity embedding feature为 E x , y ∈ R 128 \mathbb E_{x,y} \in R^{128} Ex,y∈R128。
5.4 Loss Functions
- Heatmap Loss
GT boxes b i = ( x 1 i , y 1 i , x 2 i , y 2 i ) \mathbf b^i = (x_1^i,y_1^i,x_2^i,y_2^i) bi=(x1i,y1i,x2i,y2i),计算中心点坐标 ( c x i , c y i ) (c_x^i,c_y^i) (cxi,cyi),其中 c x i = x 1 i + x 2 i 2 c_x^i = \frac{x_1^i+x_2^i}{2} cxi=2x1i+x2i, c y i = y 1 i + y 2 i 2 c_y^i = \frac{y_1^i+y_2^i}{2} cyi=2y1i+y2i,在特征图上的位置为 ( c ~ x i , c ~ y i ) = ( ⌊ c x i 4 ⌋ , ⌊ c y i 4 ⌋ ) \left(\widetilde{c}_{x}^{i}, \widetilde{c}_{y}^{i}\right) = \left(\left\lfloor\frac{c_{x}^{i}}{4}\right\rfloor,\left\lfloor\frac{c_{y}^{i}}{4}\right\rfloor\right) (c xi,c yi)=(⌊4cxi⌋,⌊4cyi⌋)。在heatmap上 ( x , y ) (x,y) (x,y)位置的响应为:
M x y = ∑ i = 1 N exp − ( x − c ~ x i ) 2 + ( y − c ~ y i ) 2 2 σ c 2 M_{x y}=\sum_{i=1}^{N} \exp ^{-\frac{\left(x-\tilde{c}_{x}^{i}\right)^{2}+\left(y-\tilde{c}_{y}^{i}\right)^{2}}{2 \sigma_{c}^{2}}} Mxy=i=1∑Nexp−2σc2(x−c~xi)2+(y−c~yi)2
其中 N N N表示图像中目标的数量, σ c \sigma_c σc表示标准偏差,heatmap Loss 函数的定义为:
L heatmap = − 1 N ∑ x y { ( 1 − M ^ x y ) α log ( M ^ x y ) , if M x y = 1 ( 1 − M x y ) β ( M ^ x y ) α log ( 1 − M ^ x y ) otherwise L_{\text {heatmap }}=-\frac{1}{N} \sum_{x y}\left\{\begin{array}{ll} \left(1-\hat{M}_{x y}\right)^{\alpha} \log \left(\hat{M}_{x y}\right), & \text { if } M_{x y}=1 \\ \left(1-M_{x y}\right)^{\beta}\left(\hat{M}_{x y}\right)^{\alpha} \log \left(1-\hat{M}_{x y}\right) & \text { otherwise } \end{array}\right. Lheatmap =−N1xy∑⎩⎨⎧(1−M^xy)αlog(M^xy),(1−Mxy)β(M^xy)αlog(1−M^xy) if Mxy=1 otherwise - Offset和Size Loss
预测的size head以及offset head为 S ^ ∈ R W × H × 2 \hat S \in R^{W \times H \times 2} S^∈RW×H×2以及 O ^ ∈ R W × H × 2 \hat{O} \in R^{W \times H \times 2} O^∈RW×H×2,对于每一个GT box b i = ( x 1 i , y 1 i , x 2 i , y 2 i ) \mathbf{b}^{i}=\left(x_{1}^{i}, y_{1}^{i}, x_{2}^{i}, y_{2}^{i}\right) bi=(x1i,y1i,x2i,y2i),可以达到他的size为 s i = ( x 2 i − x 1 i , y 2 i − y 1 i ) \mathbf{s}^{i}=\left(x_{2}^{i}-x_{1}^{i}, y_{2}^{i}-y_{1}^{i}\right) si=(x2i−x1i,y2i−y1i),同样GT的offset为 o i = ( c x i 4 , c y i 4 ) − ( ⌊ c x i 4 ⌋ , ⌊ c y i 4 ⌋ ) \mathbf{o}^{i}=\left(\frac{c_{x}^{i}}{4}, \frac{c_{y}^{i}}{4}\right)-\left(\left\lfloor\frac{c_{x}^{i}}{4}\right\rfloor,\left\lfloor\frac{c_{y}^{i}}{4}\right\rfloor\right) oi=(4cxi,4cyi)−(⌊4cxi⌋,⌊4cyi⌋)。计算上述两个head的l1损失为:
L b o x = ∑ i = 1 N ∥ o i − o ^ i ∥ 1 + ∥ s i − s ^ i ∥ 1 L_{\mathrm{box}}=\sum_{i=1}^{N}\left\|\mathbf{o}^{i}-\hat{\mathbf{o}}^{i}\right\|_{1}+\left\|\mathbf{s}^{i}-\hat{\mathbf{s}}^{i}\right\|_{1} Lbox=i=1∑N∥∥oi−o^i∥∥1+∥∥si−s^i∥∥1 - Identity Embedding Loss
对于GT box b i = ( x 1 i , y 1 i , x 2 i , y 2 i ) \mathbf{b}^{i}=\left(x_{1}^{i}, y_{1}^{i}, x_{2}^{i}, y_{2}^{i}\right) bi=(x1i,y1i,x2i,y2i),接着我们可以得到中心点对应在heatmap上的坐标 ( c ~ x i , c ~ y i ) \left(\widetilde{c}_{x}^{i}, \widetilde{c}_{y}^{i}\right) (c xi,c yi)。网络在 ( c ~ x i , c ~ y i ) \left(\widetilde{c}_{x}^{i}, \widetilde{c}_{y}^{i}\right) (c xi,c yi)位置预测一个feature vector E x i , y i \mathbf{E}_{x^{i}, y^{i}} Exi,yi,然后将它map到一个类别分布上 p ( k ) \mathbf{p}(k) p(k)上,这个类别分布的真值为GT class label L i ( k ) \mathbf{L}^{i}(k) Li(k),对应的Identity Embedding Loss为:
L identity = − ∑ i = 1 N ∑ k = 1 K L i ( k ) log ( p ( k ) ) L_{\text {identity }}=-\sum_{i=1}^{N} \sum_{k=1}^{K} \mathbf{L}^{i}(k) \log (\mathbf{p}(k)) Lidentity =−i=1∑Nk=1∑KLi(k)log(p(k))
其中 K K K是类别数。
5.5 在线跟踪
我们有了object detection 结果以及identity embeddings之后,作者是怎么来执行bbox跟踪呢?
Network Inference
网络输入采用 1088 × 608 1088 \times 608 1088×608大小的图像,这是和JDE中的工作相同,在预测的heatmap上采用了非极大抑制(NMS)用于提取peak关键点,我们保留那些heatmap分数超过一个阈值的locations,然后我们在location位置同样预测出来offsets以及box sizes,同时在locations位置提取预测的identity embeddings
Online Box Linking
作者这里使用了一个标准的在线跟踪算法,
首先,根据第一帧中的估计boxes来初始化tracklets,
接着在随后的帧中,作者根据Re-ID特征以及IoU的结果将boxes link到已知的轨迹上
作者还使用Kalman Filter来预测在接下来frame中轨迹的位置。如果预测位置和链接的detection太原,将相应的成本设置为无穷大,可以防止detection和large motion link到一起
如果
(六)Experiment
6.1 数据集
数据集
作者通过组合6个公共数据集的训练图像来构建一个大的训练数据集,使用ETH和CityPerson数据集来训练detection分支,使用CalTech,MOT17,CUHK-SYSU以及PRW数据集来训练bounding box和identity annotations。由于在ETH中出现的一些视频同时在MOT16数据集中出现,为了公平起见,从ETH中将这些视频移除,在一些消融实验中,我们建议在较小的数据集上训练我们的模型。测试集采用的是:2DMOT15,MOT16,MOT17以及最新发布的MOT20
评价指标
- Average Precision(AP)用于评估detection性能
- True Positive Rate(TPR)以错误接受率0.1用于评估Re-ID特征
- CLEAR度量以及IDF1用于评估跟踪效率
6.2 实现细节
在COCO数据集上预训练模型用于初始化我们的模型,使用Adam训练了30个epoch,初始学习率1e-4,在第20个epoch和27个epoch学习率衰减到1e-5以及1e-6。batchsize设置为12,使用标准的数据增强技术:旋转,尺度变换以及color jittering,输入图像resized到 1088 × 608 1088 \times 608 1088×608,4倍下采样,输出特征图的分辨率为 272 × 512 272 \times 512 272×512,在2块2080上训练了30个小时。
实验1
作者将detection branch改成了anchor-based,其他地方不进行调整,构建了一个anchor-based的baseline。并且这个模型是在大型训练数据集上进行训练的,在小型数据集上训练时,anchor-based方法会得到一个非常差的结果。

从上图中可以看出,anchor-free的方法在各个方面都要优于anchor-based方法。在MOTA分数上,anchor-free方法相比于anchor-based方法在Re-ID上具有明显的优势,主要原因是anchors和目标中心的mis-alignment导致了severe ambiguities。
步长为4的表现,相比于步长为2的表现性能要相差很多,这是因为:当使用高分辨率的特征图时,会有更多的unaligned positive anchors,使得网络训练更加困难,作者这里没有显示步长为2 的anchor-based的方法,主要是因为anchor数量太多超显存了。
并且作者这里将不同模型学习到的Re-ID特征使用t-SNE进行了plot,如下图所示

在上图中,同一个人使用相同的颜色点进行表示。并且从图中观察到对于anchor-based方法,不同的人(identities)混到了一起,而对于anchor-free方法来说,他们是比较分得开的。
实验2 Multi-Layer Aggregation的影响
为了评估Multi-Layer Aggregation的影响,作者基于ResNet,FPN,HRNet以及DLA-34网络进行实验,其他的因素保持不变,使用特征图的步长为4,在普通ResNet基础上增加了3个撒谎给你采样操作,以得到stride为4的特征图,接着将2DMOT15数据集划分成5个训练视频和6个验证视频,这里并没有使用大规模数据集进行训练。

DLA-34是基于ResNet-34的,取得了最佳的表现,使得ID switches从372降低到136上,说明了Multi-Layer Aggregation能够提升Re-ID的能力。
通过比较ResNet34和ResNet50,我们可以发现,使用更大的网络能够提升整体的MOTA分数,但是这个的主要提升原因在于AP的提升,而Re-ID并没有能够从更大的网络中获得性能提升,说明使用Multi-Layer Aggregation对于Re-ID性能的提升,相比于使用更加复杂的网络来说更加具有优势。
同时作者使用HRNet以及FPN来和Multi-Layer Aggregation进行对比,对于HRNet和DLA-34来说,提升的不仅仅是detection部分,同时提升了Re-ID特征提取部分。
同时对不同的backbone网络得到的Re-ID特征进行了可视化
从可视化结果来看,DLA-34确实取得了比较有区分度的Re-ID特征。

实验3 对Re-ID特征维度的选择
之前的工作通常使用512维度的Re-ID特征,并没有进行Ablation实验,然而,在我们的实验中发现了特征的维度实际上起着重要的作用,一般来说,为了避免过拟合,对高维的Re-ID特征的训练需要大量的训练图像,这里由于无法使用更多丰富的重识别数据集,因此,作者这里通过降低Re-ID特征维度来减少对数据的依赖。

当维度从512降低到1228时,TPR不断提高,说明了使用低维特征能够带来一定的优势,然而继续降低的话,Re-ID特征的对于person的代表能力降低,使得不同person之间的区分度降低,不过对于MOTA分数的影响较小,此外,降低Re-ID特征维度能够提升inference速度,不过需要注意的是使用低维Re-ID特征仅仅是作者在数据量不够情况下的一种权宜之计,随着训练数据的增加,特征维度之间的影响会越来越小。
实验4 和State-of-the-arts的比较
我们和state-of-the-arts的比较包括one-shot 方法以及two-step 方法
one-shot方法
目前one-shot方法仅仅有两种公开的works,JDE和TrackRCNN,他们联合执行object detection以及identity feature embedding,不过在TrackRCNN中,需要额外的分割annotations用于分割任务,因此,在本文中,仅仅和JDE进行比较
为了进行公平比较,作者使用2DMOT15-train和MOT16-test用于验证,结果验证了anchor-free方法相对于以往anchor-based方法的有效性。两种方法的推理速度接近视频速率,FairMOT方法更快
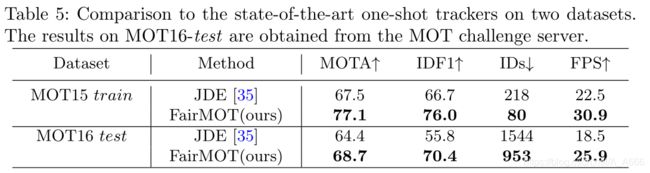
two-step 方法
分别在2DMOT15,MOT16,MOT17以及MOT20上报告我们的结果,我们的方法在所有online trackers中rank first。并且我们在速度上要远超于目前two-step的state-of-arts的方法。
(七)Conclusion
作者从研究以前方法不能达到两步方法可比结果开始,从中发现使用anchor是导致object detection和Re-ID性能退化的原因,因为大量anchors可能对应着一个目标的不同parts,从而估计相同的identity导致网络训练中存在着ambiguities问题。作者基于anchor-free框架提出了一种简单方法,并达到了state-of-arts的水平。
(八)Notes
8.1 multi-object tracking中的核心部件
- object detection
- re-identification
但是目前很少有人关注在单个网络中完成这两项任务来提高推理速度。
8.2 State-of-art模型的做法
通常采用两个分开的模型:
- detection model 用于定位图像中的感兴趣bounding boxes
- association model首先提取每一个bounding box的Re-Identification(Re-ID),然后基于特征以及特定的度量方式将其links到某一条已知的tracks。
目前State-of-art使用两个分开的模型存在的问题
不能以视频速率执行推理,因为两个网络不共享特征
8.3 MOT问题的解决方法
two-step MOT
Two-Step MOT方法
方法思路
首先,使用CNNdetectors来localize图像中所有感兴趣的目标。
接着根据bboxes对图像进行crop,并将crop下来的bounding boxes输入到identity embedding network用于extract Re-ID特征,然后将boxes link到一起从而形成multiple tracks,
在进行box link的时候,首先根据Re-ID特征以及IoU计算一个cost matrix,接着使用Kalman Filter以及Hungarian algorithm(匈牙利算法)来完成link任务。一些少数的工作中使用更加复杂的更加复杂的关联策略:比如group models和RNNs
Two-Step方法的优势
分成两个任务,可以为每一个任务选择一个最合适的模型,不需要做出妥协,并且可以根据the 预测bounding boxes来对图像进行crop和resize,这有助于处理目标的尺度变化问题。
Two-Step方法劣势
目标检测和re-identification通常需要大量的计算,两个任务之间并没有共享,导致inference速率较低。
one-shot MOT
one-shot MOT的目标在于通过在object detection和re-identification通过共享most of the computation来减少inference时间从而同时实现object detection以及identity embedding(Re-ID features)
- Track-RCNN中增加了一个Re-ID head在Mask-RCNN的top位置,对于每一个候选框回归一个bounding box以及一个proposal。
- JDE 是基于YOLOv3框架的并且取得了接近视频速率的inference
one-shot方法存在的问题是:one-shot方法的tracking accuracy 通常lower than two-step方法,作者发现这是因为所学的Re-ID特征不是最优的,这样会导致a large number of ID switches,然后作者更深一步地分析了原因:发现在anchors处提取的embedding features和object centers是不对齐(not aligned)的,导致了严重的ambiguities。
(九)Sentences
- The goal is to estimate the trajectories of multiple objects of interest in videos.
- stride较小存在的问题是:because the introduction of lower-level features makes the representation less robust to appearance variations(外观变化的鲁棒性较差)