Java IO 详解 之 字节流抽象父类
Java IO 详解 之 字节流抽象父类
-
在 java.io 包中,有四个流的抽象父类:
InputStream、OutputStream、Reader、Writer。 -
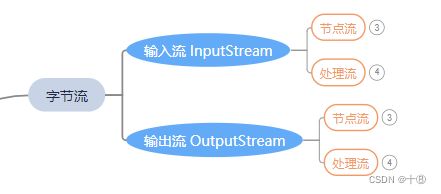
字节输入流:InputStream。操作的数据单位是 字节。
-
字节输出流:OutputStream。操作的数据单位是 字节。
-
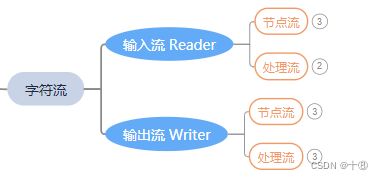
字符输入流:Reader。操作的数据单位是 字符。
-
字符输出流:Writer。操作的数据单位是 字符。
-
1 字节(byte) = 8 比特(bit),比特是计算机信息量的最小单位。
-
1 KB = 1024 byte,1MB(M) = 1024 KB,1GB = 1024 MB,1TB = 1024 GB (以此类推)。
-
字节流读写数据时,都是一个一个字节读写的,遇到需要多个字节表示一个字符时,需要
手动拼接字节来实现,十分麻烦。 -
在
GBK 编码中,汉字用两个字节存储,英文字母用一个字节存储。而在UTF-8 中,汉字用三个字节存储,英文字母用一个字节存储。 -
如果还使用 字节流 读写文本,字符乱码的概率极大(默认是使用 UTF-8 来处理文本,如果文本编码方式是 UTF-8 才不会乱码,其他情况乱码)。
// 手动向文件写数据 示例
// 默认是 UTF-8
write(“中文”.getBytes());
write(“中文”.getBytes("[GBK]"));
-
也就是说:字符流可以理解是字节流的一个变种,
专门用来处理汉字这种需要多个字节存储的字符。 -
当然,处理英文字符不会有影响,不论 GBK 还是 UTF-8 编码,中文的第一个字节都是负数,逐个字节读写文件时会根据不同的编码自动对字节进行拼接。
字节输入流 InputStream
- InputStream 是
字节输入流的抽象父类,InputStream 的所有实现类所操作的数据单位都是字节,即:一个或多个 的读取字节。
InputStream 的方法 和 常量
-
read()方法是 InputStream 的子类必须实现的。 -
nullInputStream() 是 InputStream 的静态方法。
-
InputStream 还定义了 最大跳过缓冲区大小、最大缓冲区大小、默认缓冲区大小 三个静态私有常量。
private static final int MAX_SKIP_BUFFER_SIZE = 2048;
private static final int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8;
private static final int DEFAULT_BUFFER_SIZE = 8192;
读入字节的方法:
read() 从输入流中读取数据的下一个字节。
-
返回值:整型(int);
正常读取到数据时,返回读到的字节数(0 ~ 255 之中的一个),可以为 0;到达流的末尾而没有可用的字节时,返回 -1。 -
此方法阻塞,直到输入数据可用,检测到流结束 或 抛出异常。
read(byte[]) 从输入流中读取一些字节并将它们存储到指定的(传入的 byte[])缓冲区数组中。
-
返回值:整型(int);
实际读取的字节数。如果 byte[] 的长度为零,则不读取字节并返回 0;如果由于流位于文件的结尾而没有可用字节,则返回值 -1。 -
此方法阻塞。直到输入数据可用、检测到文件结尾 或 抛出异常。
-
如果 byte[] 的长度为零,则不读取字节并返回 0;如果由于流位于文件的结尾而没有可用字节,则返回值 -1。
-
否则,将尝试读取 b.length 个字节存入 byte[];至少读取一个字节并将其存储到 byte[] 中。
-
读取的第一个字节存储在元素 b[0] 中,下一个字节存储在 b[1] 中,依此类推。最多读取 b.length 个。
-
如果 k 为实际读取的字节数,那么这些字节将存储在元素中 b[0] 到 b[k-1] 中,而剩余的 b[k] 到 b[b.length-1] 不受影响。
read(byte[], int, int) 从输入流中读取最多 len 个字节的数据到指定的(传入的 byte[])缓冲区数组的指定位置(off)之后。
-
返回值:整型(int);实际读取的字节数。如果 len 为零,则不读取字节并返回 0;如果由于流位于文件的结尾而没有可用字节,则返回值 -1。
-
此方法阻塞。直到输入数据可用、检测到文件结尾 或 抛出异常。
-
如果 len 为零,则不读取字节并返回 0;如果由于流位于文件的结尾而没有可用字节,则返回值 -1。
-
否则,将
尝试读取 len 个字节将其存储到 byte[];至少读取一个字节并将其存储到 byte[] 中。 -
读取的第一个字节存储在元素 b[off] 中,下一个字节存储在 b[off+1] 中,依此类推。最多读取 len 个。
-
如果 k 为实际读取的字节数,那么这些字节将存储在元素中 b[off] 到 b[off+k-1] 中,而剩余的 b[off+k] 到 b[b.len-1] 不受影响。
-
也就是说,byte[] 的长度为:len。
readAllBytes() 从输入流中读取所有剩余字节。
-
返回值:字节数组(byte[])。存储字节的数组;如果这个流到达流的末尾后,再调用这个方法将返回一个空字节数组。
-
返回数组的长度取决于 实际读取了多少个字节,或者 数组是否为空。
-
此方法阻塞,直到所有剩余字节已被读取并检测到流结束 或 引发异常。
-
此方法不会关闭输入流。
-
读取数据的最大值是:Integer.MAX_VALUE,即 231-1。
-
注意,此方法
适用于方便将所有字节读入字节数组的简单情况。它不适用于读取具有大量数据的输入流。 -
强烈建议,如果发生 I/O 错误,请立即关闭流。
readNBytes(int) 从输入流中读取指定数量的字节。
-
返回值:字节数组(byte[])。存储字节的数组;如果这个流到达流的末尾后,再调用这个方法将返回一个空字节数组。
-
返回数组的长度取决于 实际读取了多少个字节,或者 数组是否为空。
-
此方法会阻塞,直到已读取请求的字节数、检测到流的结束 或 引发异常。
-
此方法不会关闭输入流。
-
如果 len 为零,则不读取字节并返回 空数组;如果由于流位于文件的结尾而没有可用字节,也返回 空数组。
-
否则,将
尝试读取 len 个字节并将其存储到 byte[] 中,当然如果遇到流结束,则可能读取少于 len 个字节。 -
请注意,此方法适用于方便将指定数量的字节读入字节数组的简单情况。
-
此方法分配的内存总量与从由 len 限制的流中读取的字节数成正比;如果有足够的可用内存,可以使用非常大的 len 值安全地调用该方法。
-
强烈建议,如果发生 I/O 错误,请立即关闭流。
readNBytes(byte[], int, int) 从输入流中读取最多 len 个字节的数据到指定的(传入的 byte[])缓冲区数组的指定位置(off)之后。
-
返回值:整型(int)。返回实际读取的字节数,可能为零;同时,当此流到达流的末尾时,进一步调用方法将返回 0。
-
如果 len 为零,则不读取任何字节并返回 0;否则,将尝试读取最多 len 个字节。 -
此方法会阻塞,直到指定数量的字节的输入数据已被读取、检测到流结束 或 抛出异常。
-
此方法不会关闭输入流。
-
读取的第一个字节存储在元素 b[off] 中,下一个字节存储在 b[off+1] 中,依此类推。最多读取 len 个。
-
如果 k 为实际读取的字节数,那么这些字节将存储在元素中 b[off] 到 b[off+k-1] 中,而剩余的 b[off+k] 到 b[b.len-1] 不受影响。
-
那么,byte[] 的大小就是 len。
-
强烈建议,如果发生 I/O 错误,请立即关闭流。
其它方法:
- 注意:
其他方法是不能读取数据的,read()及其重载方法 才能读。
skip(long) 跳过并丢弃 n 个字节
-
返回值:长整型(long)。
返回实际跳过的字节数,可以为零。 -
工作原理:创建一个字节数组,重复读入字节,直到读取 n 个字节 或 流结束已达到末尾。
-
当 n 小于零时,不跳过任何字节并返回零。
available() 返回可以在没有阻塞的情况下从此输入流中读取(或 跳过)的字节数的估计值。
-
返回值:整型(int)。返回可以
在没有阻塞的情况下从此输入流中读取(或 跳过)的字节数的估计值,可能是零;当检测到流结束时也为 0。 -
因为这个输入流的读取可能在同一个线程 或 另一个线程上,本次读取 或 跳过 x 个字节可能不会阻塞。
-
不同的实现还有其它的功能,如:返回流中的总字节数。但较少,故,使用此方法的返回值来分配用于保存此流中所有数据的缓冲区是不正确的。
-
如果此输入流已调用 close() 方法关闭,则此方法的子类实现可能会选择抛出 IOException。
close() 关闭此输入流并释放与流相关的任何系统资源。
-
没有返回值,
用来关闭输入流。 -
InputStream 的 close 方法什么也不做。
markSupported() 是否支持 mark、reset 方法。
-
返回值:布尔类型(Boolean)。
true、false。 -
如果支持 mark、reset 方法,即:mark 和 reset 是该输入流实例的不变属性,那么返回 true。
-
InputStream 的 markSupported() 方法返回 false。
-
FileInputStream 的 markSupported() 方法返回 false。
mark(int) 用来标记此输入流的当前位置。
-
没有返回值。
标记此输入流的当前位置。 -
当该输入流的 markSupported() 方法返回 true 时,流才会处理该方法。
-
与 reset() 方法搭配使用。
-
工作原理:使用该方法时,输入流会标记此输入流中的当前位置,后续使用 reset 方法会将流重新定位到最新标记的位置。
-
输入参数 readlimit 表示这个输入流在标记位置无效之前允许读取那么多字节。
-
如果在调用 reset 之后,该流读取的字节数大于最后调用 mark 时的参数,则可能抛出 IOException。
-
但是,如果在调用 reset 之前从流中读取了超过 readlimit 个字节,则流根本不需要记住任何数据。
-
InputStream 的 markSupported() 方法返回 false,那么,InputStream 调用 mark() 方法会什么都不做。(InputStream 的子类同理)
reset() 将当前输入流重新定位到最后标记的位置。
-
没有返回值。
重新定位到最后标记的位置。 -
当该输入流的 markSupported() 方法返回 true 时,流才会处理该方法。
-
与 mark() 方法搭配使用。
-
InputStream 的 markSupported() 方法返回 false,那么,InputStream 调用 reset() 方法会抛出 IOException。(InputStream 的子类同理)
-
如果方法 mark 自从创建流后没有被调用,或者从流中读取的字节数大于最后一次调用时 mark 的参数时,则可能会抛出 IOException。
-
如果没有抛出这样的 IOException,那么流将被重置为一个状态:即将最近一次调用 mark 以来读取的所有字节(或者从文件开始,如果 mark 没有被调用)重新提供给 read 方法的后续调用者。
-
就是将最近的输入数据赋给 read 方法的调用者。
transferTo(OutputStream) 从输入流中读取所有字节,并按照读取顺序将字节写入给定的输出流。
-
返回值:长整型(long)。
返回实际跳过的字节数,可以为零(官方未说明,从源码中总结)。 -
此方法可能会无限期地阻止 从输入流中读取 或 写入输出流。
-
如果 从输入流读取 或 写入输出流 时发生 I/O 错误,错误可能会在读取或写入某些字节后发生,故,输入流可能不在流的末尾,并且两个流可能处于不一致状态。
-
强烈建议,如果发生 I/O 错误,立即关闭两个流。
nullInputStream() 返回一个不读取字节的新的字节输入流。
-
返回值:字节输入流(InputStream)。
返回一个不读取字节的新 InputStream。 -
本文称:该方法返回的新的 InputStream 为 newInput,下同。
-
newInput 可以使用 InputStream 的所有方法,与 new 的 InputStream 无异。
-
其中,newInput 最初是打开的,可以使用 close() 方法关闭,即:newInput.close()。后续再调用 close() 方法无效。
-
同时,newInput.markSupported() 返回 false;newInput.mark();newInput.reset() 抛出 IOException。不受 newInput 是否开启或关闭 影响。
-
而,available()、skip(long)、transferTo() 和 read()及其所有重载方法,在流开启时,表现得在流末尾了;在流关闭时,抛出 IOException。
字节输出流 OutputStream
- OutputStream 是
字节输入流的抽象父类,OutputStream 的所有实现类所操作的数据单位都是字节,即:一个或多个 的写入字节。
OutputStream 的方法
-
write(int)方法是 OutputStream 的子类必须实现的。 -
nullOutputStream 是 OutputStream 的静态方法。
输出字节的方法:
write(int) 将指定字节写入此输出流。
-
没有返回值。
-
参数 b,就是 表示要输入的字节。
-
一般的实现都是:将一个字节写入输出流。
-
方法
取参数 b 的最低位的一个字节,作为要写入的字节。解析如下:
整型 int 在 Java 中为 32 位(bit),也就是 4 个字节,可以表示为:00000000_00000000_00000000_00000000(比特版)、0_0_0_0(字节版)。
// 原文
The byte to be written is the eight low-order bits of the argument <code>b</code>.
The 24 high-order bits of <code>b</code> are ignored.
// 将 b 换成 X
The byte to be written is the eight low-order bits of the argument X.
The 24 high-order bits of X are ignored.
意思是:要写入的字节是参数 X 的 8 个低位,忽略 X 的 24 个高位。
也就是取 int 的低位字节作为 要输入的字节。
刚好 8 个低位比特组成一个字节。
write(byte[]) 将指定字节数组(byte[])中的 b.length 个字节(数组的长度)写入此输出流。
-
没有返回值。
-
将字节数组中的
所有字节写入此输出流,当然,如果发生错误,是不会写完的。 -
一般要求其实现要与 write(byte[], int, int) 一致,其实 OutputStream 的 write(b) 方法就是 write(b, 0, b.length)。
write(byte[], int, int) 将指定字节数组(byte[])中的 off 到 off+len-1 范围内的字节(不大于实际的数组长度)写入此输出流。
-
没有返回值。
-
将字节数组中的
off 到 off+len-1 的所有字节写入此输出流,当然,如果发生错误,是不会写完的。 -
b[off] 是写入的第一个字节,而 b[off+len-1] 是此操作写入的最后一个字节。
-
一般情况是将数组 b 中的一些字节按顺序写入输出流;
-
当 off 为负数时,或 len 为负数,或 off+len 大于数组的长度 b.length,抛出 IndexOutOfBoundsException。
-
当 b 为 null,则抛出 NullPointerException。
其它方法
flush() 刷新此输出流并强制写出任何缓冲中的字节到输出流中。
-
使用输出缓冲时(先前写入的任何字节已被输出流的实现缓冲),则应
立即将这些字节写入其预期目的地(文件节点或执行处理)。 -
如果此流的预期目的地是底层操作系统提供的抽象,例如文件时(节点流),则刷新流仅保证先前写入流的字节被传递给操作系统进行写入;它不能保证它们实际上被写入了物理设备,例如磁盘驱动器。
-
OutputStream 的 flush 方法什么也不做。
close() 关闭此输出流并释放与此流关联的所有系统资源。
-
没有返回值,用来
关闭输出流。 -
关闭的流无法执行输出操作,也无法重新打开。
-
OutputStream 的 close 方法什么也不做。
nullOutputStream() 返回一个丢弃所有字节的新的字节输出流。
-
返回值:OutputStream,
返回一个不输出字节的输出流。 -
返回的流最初是打开的。通过调用 close() 方法关闭流,后续再调用 close() 无效。
-
当流是打开时,write(int)、 write(byte[]) 和 write(byte[], int, int) 方法什么也不做;流关闭后,这些方法都会抛出 IOException。
-
而 flush() 方法什么都不做。