【数据库——MySQL】(13)过程式对象程序设计——存储函数、错误处理以及事务管理
目录
- 1. 存储函数
- 2. 存储函数的应用
- 3. 错误处理
- 4. 抛出异常
- 5. 事务处理
- 6. 事务隔离级
- 7. 应用实例
- 参考书籍
1. 存储函数
-
要 创建 存储函数,需要用到
CREATE语句:CREATE FUNCTION 存储函数名([参数名 类型, ...]) RETURNS 类型 [存储函数体]注意:存储过程名和存储函数名不能相同!
-
要 调用 存储函数,语法格式如下:
存储函数名([参数, ...])注:存储过程只能采用
CALL语句直接调用,而存储函数则可以出现在各种语句中。 -
要 修改 存储函数,需要用到
ALTER语句:ALTER FUNCTION 存储函数名 [ COMMENT ‘string’ | LANGUAGE SQL | {CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } | SQL SECURITY { DEFINER | INVOKER } }注:上述修改语句只能修改存储函数的属性,不能修改功能!修改存储函数的功能,与修改存储过程功能一样也只能采取先删除后重新定义的方式实现。
-
要 删除 存储函数,需要用到
DROP语句:DROP FUNCTION [IF EXISTS] 存储函数名 -
注意在创建自定义存储函数的时候,需要提供权限:
set GLOBAL log_bin_trust_function_creators = 1; # 创建自定义函数需要给权限注:上述语句只需要在开启数据库时输入一次即可。
2. 存储函数的应用
【例 1】在数据库 score 中创建存储函数,要求通过给定的学号输出相对应的姓名。
drop FUNCTION if exists f1;
delimiter $
create FUNCTION f1(stu_id char(20))
returns varchar(20) # 返回学生姓名
begin
declare sname varchar(20);
select stu.`name` into sname
from stu
where stu.id = stu_id;
return sname;
end$
delimiter ;
select f1('20191001') as Name;

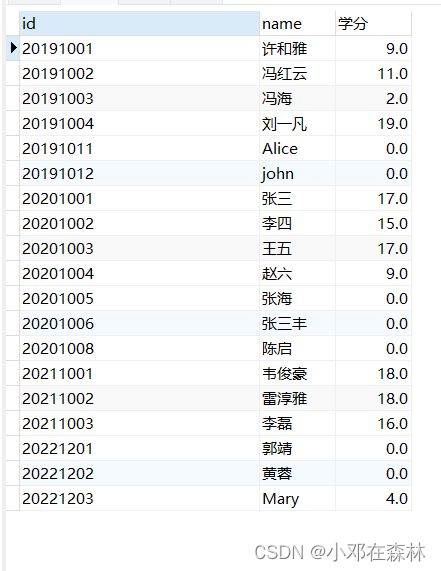
【例 2】在数据库 score 中创建存储函数,要求输出每位学生的所修学分总数。
drop FUNCTION if exists getxf;
delimiter $
create FUNCTION getxf(stu_id char(20))
returns decimal(5,1) # 返回学生总学分
begin
declare s decimal(5,1) default 0; # 因为之后要求和,所以给个缺省值0
select sum(if(score.score >= 60, lesson.xf, 0)) into s
from score join lesson on score.LessonId = lesson.lessonid
where score.stuId = stu_id;
return s;
end$
delimiter ;
select stu.id, stu.`name`, IFNULL(getxf(stu.id),0) as 学分
from stu;
3. 错误处理
在执行 SQL 语句后,可能有时会出错,那么大家可以根据报错编号在 MySQL 手册里面查找出错原因。
错误处理语句:
DECLARE 处理动作 HANDLER
FOR 条件值 ,...
处理语句过程体
4. 抛出异常
我们还可以自定义错误代码以及抛出异常值:
SIGNAL SQLSTATE 错误编号(自定义,不能与系统已有编号重复)
SET message_text = 错误提示信息;
示例如下:
SIGNAL SQLSTATE '12345'
set message_text = '证件号不存在';
5. 事务处理
-
关闭自动提交
自动提交常用语银行系统中,比如小邓给森林转了1元的写博客助力费,那么这个动作应该是同步的,即小邓银行账户扣除1元,与此同时,森林银行账户增加1元(假设小邓银行账户刚好有1元,足够扣除)。不能说小邓银行账户扣除1元,但森林银行账户余额不变(比如转钱信号传输中受到干扰导致信号未正确传输)。这时候 关闭自动提交 就可以实现解决这种情况。当完成一系列操作后,只有手动提交事务,才能算是实现了之前的所有操作!
SET @@AUTOCOMMIT = 0;注:默认是开启自动提交的,即
SET @@AUTOCOMMIT = 0;。 -
开始事务
START TRANSACTION SQL语句 -
结束事务
COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE] -
撤销事务
ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE] -
回滚事务到指定点
回滚前需要先设置一个保存点:SAVEPOINT 保存点名然后才可以回滚事务:
ROLLBACK [WORK] TO SAVEPOINT 保存点名
6. 事务隔离级
- 脏读(dirty reads):一个事务读取了另一个未提交的并行事务写的数据。
- 不可重复读(non-repeatable reads):一个事务重新读取前面读取过的数据, 发现该数据已经被另一个已提交的事务修改过。
- 幻读(phantom read):一个事务重新执行一个查询,返回一套符合查询条件的行, 发现这些行因为其他最近提交的事务而发生了改变。
以上 3 种情况是我们不想看见的。
SET [GLOBAL | SESSION] TRANSACTION ISOLATION LEVEL
SERIALIZABLE //可序列化
| REPEATABLE READ //可重复读
| READ COMMITTED //提交读
| READ UNCOMMITTED //未提交读
如果指定GLOBAL,那么定义的隔离级将适用于所有的SQL用户;如果指定SESSION,则隔离级只适用于当前运行的会话和连接。
基于 ANSI/ISO SQL 规范,MySQL 提供了 4 种隔离级:序列化、可重复读、提交读和未提交读。
查看当前事务隔离级:
SELECT @@TRANSACTION_ISOLATION;
7. 应用实例
请自行创建数据库 bank,并在里面新建一个表 account,表内容如下:
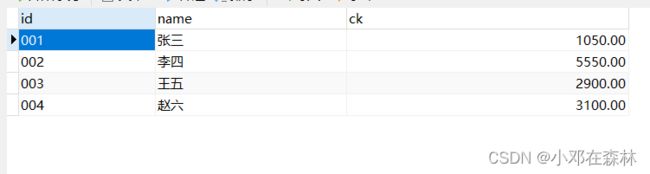
下面完成转账操作:
set @@autocommit = 0; # 关闭自动提交功能
select * from account;
update account
set ck = ck - 500
where id = '001';
SAVEPOINT a; # 保存点(rollback时只撤销后面的操作)
update account
set ck = ck + 500
where id = '002';
select * from account;
此时还未提交事务,大家可以在可视化界面刷新表 account,发现数据并没有更新。这是因为我们关闭了自动提交,因此要手动提交事务:
COMMIT;

参考书籍
《MySQL实用教程(第4版)》
上一篇文章:【数据库——MySQL】(12)过程式对象程序设计——存储过程