Go语言基础语法之变量、常量
变量、数据类型和常量是编程基础中的基础,所以要学习一门语言,必定需要先学习掌握好这三个概念。
何为变量?
变量是计算机语言中能储存计算结果或能表示值的抽象概念。
何为数据类型?
数据类型在数据结构中的定义是:一组性质相同的值的集合以及定义在这个值集合上的一组操作的总称。
何为常量?
“常量”的广义概念是:‘不变化的量’,在计算机程序运行时,不会被程序修改的量,称为字面常量或直接常量。
三者之间是一种怎样的关系?
变量和常量都是用来存储值的所在处,它们有名字和数据类型。名字使得我们可以通过名称访问它们的值,数据类型决定了如何将代表这些值的位存储到计算机的内存中。所有的变量和常量都具有数据类型,以决定能够存储哪种数据。在声明变量和常量时可指定它的数据类型,也必须有类型,有时候不用显示声明,由编译器进行推导。
经过上面的简单介绍和分析,可以得知的是变量和常量的声明和使用都离不开数据类型。原本想着先和大家分享关于go语言数据类型的具体介绍,但是发现如果单纯的讲述一些概念性的知识而不提供示例的话会让人晦涩难懂,而如果需要提供示例的话又离不开变量的使用,所以最终还是决定先和大家介绍go语言的变量声明及使用,关于数据类型的详细介绍在后续文章中再和大家分享。
在开始介绍变量的使用之前,先简单的介绍下Go语言支持的数据类型,避免在示例中出现时大家不能理解。Go语言数据类型包括整型(int)、浮点型(float32、float64)、布尔型(bool)、字符(byte、rune)、字符串(string)、切片([]T)、结构体(struct)、函数(func)、映射(map)、通道(channel)、指针(*T)等
一、变量声明
1.1、go语言的变量声明格式为:var 变量名 变量类型
示例如下:
// 声明一个整型变量
var i int
// 声明一个浮点型变量
var f float32
// 声明一个字符串变量
var s string
1.2、支持批量声明
示例如下:
// 批量声明变量
var (
a int
b float32
c string
)
二、变量初始化
2.1、系统默认初始化
go语言在声明变量时,会自动对变量对应的内存区域进行初始化操作,每个变量都会初始化其类型的默认值,例如:
整型和浮点型变量的默认值为0。
字符串变量的默认值为空字符串。
布尔型变量的默认值为false。
切片、函数、指针变量的默认值为nil
2.2、显式赋值初始化,标准格式:var 变量名 类型 = 表达式
// 声明并初始化一个整型变量
var i int = 1
2.3、编译器推导类型,格式:var 变量名 = 表达式
// 声明并初始化一个整型变量
var i = 1
// 声明并初始化一个浮点型变量
var f = 1.11111
2.4、短变量声明并初始化,格式:变量名 := 表达式
// 短变量声明并初始化一个整型变量
i := 1
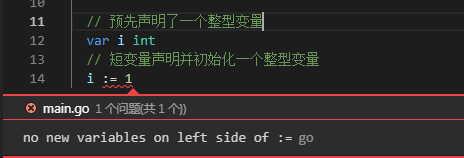
注意(1):":="是声明并初始化一个变量,因此这种声明写法的变量名必须是没有定义过的变量,否则,将会发生变量已声明的编译错误,如下图:
注意(2):在多个短变量声明和赋值中,如果至少有一个新声明的变量出现在左边,即便其他变量是重复声明的,编译器也不会报错,如:
// 预先声明了一个整型变量
var i int
// 短变量声明并初始化一个整型变量和一个浮点型变量
i, f := 1, 1.111
// 打印结果
fmt.Println(i)
fmt.Println(f)
/*
输出结果为:
1
1.111
*/
2.5、多个变量同时赋值
// 多变量同时赋值
i, s = 10, "字符串"
// 输出结果
println(i)
println(s)
/*
结果:
10
字符串
*/
应用场景 —— 变量交换
示例:
// 声明两个整型变量
var a = 10
var b = 20
// 变量交换
a, b = b, a
// 输出结果
println(a)
println(b)
/*
结果:
20
10
*/
2.6、匿名变量
在使用多重赋值时,如果不需要在左值中接受变量,可以使用匿名变量,用"_"下划线表示,匿名变量不占用命名空间,不会分配内存,匿名变量与匿名变量之间也不会因为多次声明而无法使用。
// 例1:
a, _ = 10, 20
// 例2:
i, _ := 100, 200
// 结果打印
println(a)
println(i)
/*
结果:
10
100
*/
三、变量的生命周期
3.1、为什么变量要有生命周期?
前面有提到,go语言在声明变量时,会自动分配内存并进行默认初始化操作,也就是说使用变量时必定会消耗内存,虽然现在计算机的内存越来越大,但终究还是有限的,如果让变量一直常驻内存中,随着声明的变量越来越多,内存迟早也会爆满。所以为每个变量设置一个生命周期是很有必要的,以便在其使用完毕后将其所使用的内存进行回收利用,进而节省计算机资源。
3.2、如何决定变量生命周期?
在go语言中,变量的生命周期由编译器自行决,编译器会根据代码的特征进行分析,进入决定变量的生命周期,go语言将这一过程称为——变量逃逸分析
3.3、变量逃逸分析做了些什么?
要看变量逃逸分析做了什么,我们可以在go run 运行程序时 通过“-gcflags” 指定编译参数,下面看下具体实例:
func escapeTest(a int) *int {
// 声明并赋值变量b
b := a
// 返回b的指针
return &b
}
func main() {
// 打印返回的指针
println(escapeTest(10))
}// 执行go run 结果
C:\Users\kenny\Desktop\MyFirstGo>go run -gcflags "-m -l" main.go
# command-line-arguments
.\main.go:9:9: &b escapes to heap // 提示&b发生了逃逸
.\main.go:8:2: moved to heap: b // 提示编译器自动将b变量移动到了堆中
0xc00004a000
从上诉例子可以得知,变量逃逸分析主要做了以下事情:
(1)分析代码特征、判断变量是否发生逃逸,从而决定变量的生命周期
如上述例子分析得知&b发生了逃逸,那么变量b在escapeTest函数执行结束后其生命周期并没有结束,而是要等到使用到&b的最后一个函数执行完之后其声明周期才算结束,也就是上诉的main函数执行完毕后。
为什么呢?
原因是返回值是对b进行取址操作,返回的是变量b的指针,这就要求变量b必须继续存在,否则返回一个已经回收掉的内存地址是没有意义的,甚至会引发不可预估的问题。
假如返回的是局部变量b是否会发生变量逃逸呢?
经试验得知,如果返回值是局部变量b的话,那么分析结果将不会提示b发生了变量逃逸,因为此时返回值会以复制的形式供调用者使用,而不要求局部变量继续存在。这种微妙的差异似乎和c#语言中的值类型和引用类型是同样的道理。在c#语言中使用值类型的参数时会对传入参数进行复制,也就是说你在函数内部操作传入的数据时并不会影响到参数本身,而使用引用类型的参数时,当你在函数内部操作更改时会直接影响到参数本身。
(2)决定变量内存分配方式
从“moved to heap: b”可以得知,go编译器将b变量移动到了堆上,因为编译器已经确认如果将变量c分配在栈上将无法保证程序的正常运行。如果坚持这样做的话,返回的将会是一个不可预知的内存地址,这种情况是在c语言中很容易犯错的地方,也就是引用了一个函数局部变量的地址。
3.3、变量逃逸分析的好处:
(1)自动分析代码特征,决定变量生命周期,对内存进行自动回收,优化代码性能
(2)使得开发者不需要将精力放在内存应该分配在栈还是堆上,减少开发者因内存分配决策错误引发的一系列问题。
四、常量
常理的声明方式和变量的声明方式很像,只是把var 换成了 const,具体如下:
// 声明并赋值一份常量标准格式
const a int = 10
// 编译器推导类型
const b = 1.111
// 批量方式
const (
c = 100
d = 1.1111
)
注意:常量声明后必须赋值,并且只接受字面量的赋值,上述示例所示,不能以函数返回值或表达式等进行赋值,如:const e = a * b 是不被允许的
以上是关于go语言变量及常量的一些学习总结及个人理解,希望对大家有所帮助,如有错误之处,请各位指出。下篇文章将和大家分享go语言数据类型的详细介绍。