OpenStack入门与架构介绍
OpenStack入门与架构介绍
- 前言——OpenStack介绍
- 一、预备知识
-
- 1.虚拟化
-
- 1.1虚拟化的发展历程
- 1.2KVM与基本概念
-
- 1.2.1基本概念
- 1.2.2KVM虚拟化原理
- 1.3网络虚拟化
-
- 1.3.1Linux Bridge
- 1.3.2VLAN
- 1.3.3KVM对VLAN的实现
- 2.云计算
-
- 2.1云计算的发展历程
- 2.2基本概念
- 2.3关键技术
- 二、OpenStack架构
-
- 1.服务介绍与概念架构
- 2.逻辑架构分析
- 3.物理架构分析
- 4.通用技术介绍
-
- 4.1 消息总线
- 4.2SQLAlchemy和数据库
- 4.3RESTfulAPI和WSGI
-
- 4.3.1RESTful
- 4.3.2WSGI
- 4.4Eventlet和AsyncIO
前言——OpenStack介绍
2010年7月,Rackspace和NASA合作发布了OpenStack。OpenStack每几个月就会发布一个新的版本,并以首字母从A到Z的顺序命名。OpenStack峰会和中国OpenStack黑客松活动也随之诞生。
一、预备知识
1.虚拟化
1.1虚拟化的发展历程
- 1959年,国际信息处理大会,克里斯托弗在《大型高速计算机中的时间共享》报告中,提出了“虚拟化”的概念。
- 1964年,CP-40操作系统首次实现了虚拟内存和虚拟机;IBM推出的分时共享系统也被认为是最原始的虚拟化技术。
- 20世纪70年代,IBM System 370系列利用虚拟机监控器(Virtual Machine Monitor)在物理硬件运行多个独立操作系统的虚拟机实例。
- 1998年,VMware成立,并于1999年在x86平台推出商业虚拟化软件,进入高速发展阶段。
- 21世纪,Xen问世;微软宣布Virtual Server 2005计划;英特尔推出VT(Vanderpool Technology)技术。AMD、Oracle、RedHat等进入虚拟化市场。
1.2KVM与基本概念
本节以KVM为例简要介绍虚拟化技术。
1.2.1基本概念
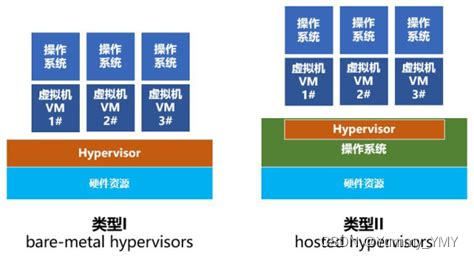
Ⅰ型虚拟化:Hypervisor(管理程序)直接安装在物理机上,一般是一个特殊定制的Linux系统,虚拟机则在Hypervisor上运行。
Ⅱ型虚拟化:物理机上首先安装常规的操作系统,Hypervisor作为程序在操作系统上运行,并对多个虚拟机进行管理。
理论上来讲,Ⅰ型的性能要高,但Ⅱ型更为灵活。
Libvirt:KVM(Kernel-Based Virtual Machine,一种Ⅱ型虚拟化技术)的Hypervisor。包含后台服务程序Libvirt,可用于处理请求;API库,供高级开发使用;virsh,KVM命令行工具。
1.2.2KVM虚拟化原理
CPU虚拟化
KVM的虚拟化需要CPU硬件的支持,使用如下命令,如果有输出vmx或者svm,就说明当前CPU支持KVM虚拟化。
egrep -o'(vmx|svm)' /proc/cpuinfo
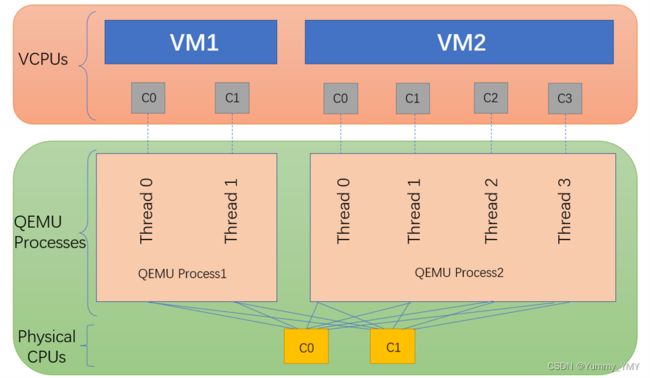
一个虚拟机在宿主机中以qemu-kvm进程的形式存在,与其他进程一样服从调度;虚拟机中的每一个vCPU就是对应qemu-kvm进程中的一个线程。vCPU的数量超过宿主机的物理CPU数的情况称为CPU超配(overcommit)。
内存虚拟化
KVM通过虚拟内存来共享物理内存,实现对虚拟机的动态分配。虚拟机操作系统中内存管理(以段页式为例)的虚拟内存映射关系为:VA(虚拟地址)->LA(线性地址)->PA(物理地址),此时的PA为虚拟机虚拟化的地址,不是实际上的物理地址;KVM需要负责实现PA(虚拟机)->PA(宿主机)的映射关系。同样的,内存也存在超配的情况。
存储虚拟化
KVM的存储虚拟化是通过存储池(storage pool)和卷(volume)来管理的,存储池是宿主机上可见的一部分存储空间,卷是存储池中的一块空间,由宿主机以硬盘的形式分配给虚拟机。其中存储池可分为以下几种常见类型:
- 目录类型。KVM将宿主机的/var/lib/libvirt/images目录作为默认存储池,该目录下的每个.img文件都被虚拟化为一个卷。
- LVM类型。VG(volume group)中的LV(logical volume)也可以作为一个虚拟磁盘使用,此时VG就是一个存储池。但是LV不能作为启动盘,只能作为数据盘使用。
- KVM还支持iSCSI、Ceph等存储池类型。
新建卷的常见格式与优点见下表:
| 文件格式 | 优点 |
|---|---|
| raw | 默认的原始磁盘镜像格式,移植性好,性能好,但不节省空间 |
| qcow2 | 推荐使用格式,写时复制节省空间,支持多种功能 |
| vmdk | VMWare的虚拟磁盘格式,兼容VMWare虚拟机 |
KVM通过/etc/libvirt/storage来得到所有存储池的相关信息,每个可用存储池都会在该目录下有个xml文件,默认会存在default.xml
1.3网络虚拟化
网络虚拟化最为复杂,因此独立成节单独讨论。
1.3.1Linux Bridge
Linux Bridge是Linux上用来做TCP/IP二层协议交换的设备,可简单理解为是虚拟机网卡与宿主机网卡连接的桥梁,会将来自宿主机的数据转发给特定虚拟机的网卡,也可以将虚拟机的数据转发到宿主机,并凭借宿主机的物理网卡与外网通信。

1.3.2VLAN
LAN(Local Area Network,本地局域网),通常使用Hub和Switch连接局域网内的计算机。一个LAN表示一个广播域,LAN中的所有成员都会收到任一成员发出的广播包。
VLAN表示Virtual LAN,一个带有VLAN功能的Switch能将自己的端口划分为多个LAN,逻辑上产生系列交换机。即实际上在同一个物理网内,但被逻辑地分为不同的网络区域,不同区域不能通过广播通信,但可以使用IP互通。
VLAN的隔离是二层上的隔离,即广播包无法跨越VLAN边界
目前的交换机都支持VLAN功能,但有不同的端口配置模式:
- Access端口。使用VLAN ID来表明端口独属于哪个VLAN,VLAN ID的范围从1到4096。Access口直接与网卡相连,数据包通过时打上所在VLAN的标签。
- Trunk端口。将不同物理交换机上具有相同VLAN ID的VLAN相连通。
1.3.3KVM对VLAN的实现

eth0是宿主机的物理网卡;与外网相连,eth0.1就是VLAN设备,其VLAN ID就是VLAN 1;veth0是虚拟网卡,eth0.1与veth0均挂在名为 br vlan1的Linux Bridge上。其他虚拟机同样的。其中VM0和VM1在同一个VLAN内,与VM2在不同的VLAN。
Linux Bridge+VLAN就相当于一个虚拟交换机,两者分别承担了交换和隔离功能的实现。
2.云计算
现阶段的云计算是分布式计算、效用计算、负载均衡、并行计算、网络存储、热备份冗杂和虚拟化等计算机技术混合演进并跃升的结果,云计算基本涉及IT基础设施的所有服务,包括计算、存储、网络、虚拟化、高可用、安全等等领域,涉及范围广泛,不宜不易展开,在此仅作概述,留坑待补。
2.1云计算的发展历程
- 1983年,“网络即计算机”被认为是云计算的雏形。
- 2006年,亚马逊推出弹性计算(EC2),云计算商业化开始。
2.2基本概念
- IaaS(Infrastructure as a Service),提供虚拟机服务,负责管理虚拟机的生命周期,包括创建、修改、备份、启停、销毁等。
- PaaS(Platform as a Service),提供应用的运行环境和一系列中间件服务。
- SaaS(Software as a Service),提供应用服务。
2.3关键技术
- 虚拟化技术。虚拟化是云计算最核心的技术,它为云计算提供架构层面的支持,是ICT服务快速走向云计算的最主要驱动力。虚拟化是一种在软件中仿真硬件,以虚拟资源为用户提供服务的计算模式,旨在合理调配资源,实现了架构的动态化、物理资源的集中管理。
- 分布式存储技术。采用可扩展的系统架构,将数据存储在不同的物理设备中,提高了系统的可靠性、可用性和存取效率,还易于扩展。
- 分布式并行编程模式。MapReduce是当前主流分布式并行编程模式之一,将任务自动分成多个子任务,通过Map和Reduce实现任务在大规模计算节点中的高度分配,能够更高效地利用软、硬件资源,让用户更快速、更简单地使用应用服务。
- 大规模数据管理。典型的有Google的BT数据管理技术和Hadoop的开源数据管理模块HBase。
- 分布式资源管理。在多节点的并发执行环境中,保证各个节点的状态同步,单个节点故障时,保证其他节点不受干扰
- 信息安全技术。涉及到网络安全、服务器安全、软件安全、系统安全等。
- 云计算平台管理。用于部署和开通新业务、快速发现并恢复系统故障,实现大规模系统自动化、智能化的可靠运营。
- 绿色节能技术。
二、OpenStack架构
1.服务介绍与概念架构
| 组件名称 | 简要介绍 |
|---|---|
| Nova | 计算服务,用于为单个用户或使用群组管理虚拟机实例的整个生命周期,根据用户需求提供虚拟服务,负责虚拟机的创建、挂起、调整、销毁等操作,配置CPU和内存等信息。 |
| Swift | 对象存储服务,通过内置冗余和高容错机制在大规模可扩展系统实现对象存储,允许进行存储或检索文件,可为Glance提供镜像存储服务,为Cinder提供卷备份服务。 |
| Glance | 虚拟机镜像查找检索系统,支持多种虚拟机镜像格式,可创建上传镜像、删除镜像、编辑镜像基本信息等。 |
| Keystone | 为OpenStack提供身份验证、服务规则和服务令牌,管理Domains、Projects、Users、Groups、Roles。 |
| Neutron | 提供网络虚拟化技术,为其他服务提供网络连接,为用户提供接口。 |
| Cinder | 块存储,为虚拟机运行提供稳定的数据块存储服务 |
| Horizon | UI界面,各种服务的Web管理门户。 |
| Ceilometer | 测量,为计费、监控以及为其他服务提供统计数据支撑。 |
| Heat | 部署编排,提供模板定义的协同部署方式,实现云基础设施软件运行环境的自动化部署。 |
| Trove | 数据库服务,为用户在OpenStack的环境提供可扩展和可靠的关系与非关系数据引擎服务。 |
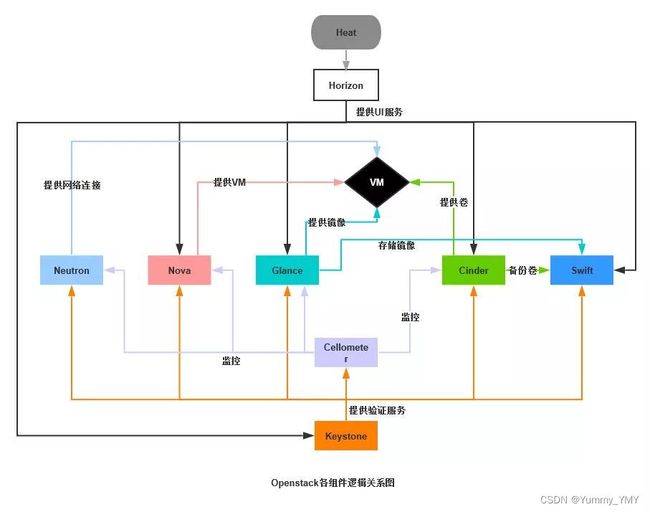
Neutron、Nova、Glance和Cinder分别为VM(虚拟机)提供网络、计算、镜像和存储服务,相当于实体机的网卡、CPU与内存、操作系统和硬盘。Cellometer则计量各种资源的使用情况并提供统计信息给其他服务使用。用户可以通过Horizon的UI界面便捷管理虚拟机,Keystone则提供认证服务,给用户不同的访问与管理权限。Swift实现对象存储,对用户可实现云存储,对Cinder可提供卷备份服务,为Glance提供镜像存储服务,提高系统的容灾能力。
2.逻辑架构分析
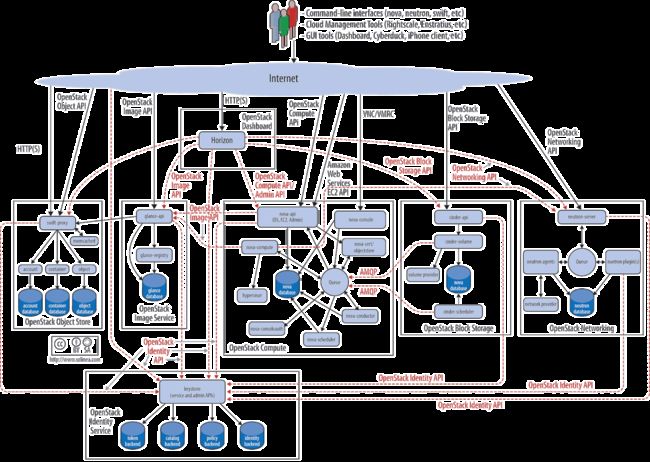
不同的服务内还有不同的组件,并对外提供了API,用户可以通过Horizon提供的UI界面或者http请求来调用相应服务。不同服务之间的相互调用也是通过http调用的。服务内的不同组件间的调用则是通过RPC(远程调用)实现的。
用户的不同权限访问是通过Keystone内的身份认证实现的,可以以管理员的身份在OpenStack平台上为其他用户进行注册。Nova是OpenStack内部至关重要的一项服务,其内部实现有计算、调度、监管、引导、对象存储组件,并通过高级消息队列协议与Cinder的调度组件进行数据传输。Neutron则分为代理、服务端、提供者、插件等组件,实现网络的交换与隔离的虚拟化。对用户的云存储而言,Cinder提供块存储服务;而Swift则提供对象存储,内部逐层实现记录有账户、容器和对象的数据库。
3.物理架构分析

OpenStack的不同服务可以分布在多个物理节点上,也可以集中在一个物理节点。一般而言,根据不同物理节点的功能不同,将其分为四种:控制节点、网络节点、计算节点和存储节点。其中不同物理节点需要支持的服务和网络接口一般不同。
根据节点的名称,网络、存储、计算节点主要实现OpenStack平台的三大主要资源:网络(Neutron)、存储(Cinder和Swift)和计算(Nova,也可以扩展Celimeter审计资源使用情况);而控制节点则需要支持其他功能,例如身份认证(Keystone)、UI界面(Horizon)、镜像服务(Glance)等,同时控制节点需要支持数据库,以保存各类记录,为了更为便捷的部署与编排,控制节点可以扩展实现Heat服务。
网络接口的不同则是依据不同节点数据交换方的需要而确定。网络节点需要提供外部网络对整体服务的访问,故需要实现外部接口;而控制节点仅执行对其他节点的控制管理功能,因此只需要实现管理接口;控制节点外的其他节点除了接收控制信息的管理接口外,还会彼此之间传递数据,因此需要实现数据接口。
4.通用技术介绍
4.1 消息总线
项目内部的不同服务进程之间的通信,必须通过消息总线。oslo(OpenStack Common Libraries).messaging实现了以下两种方式完成项目内部不同服务进程间的通信:
- 远程过程调用(RPC)
通过RPC一个进程可以远程调用其他进程的方法,并且有call和cast两种调用方式。 - 事件通知(Event Notification)
某个进程将消息通知发送到消息总线,对此事件感兴趣的进程,可以获取处理此事件。
在OpenStack支持的消息类型(RabbitMQ、ZeroMQ等)中,大部分都是基于AMQP(Advanced Message Queue Protocol,高级消息队列)实现的。AMQP是一个异步消息传递所使用的开放层协议,主要包括消息的导向、队列、路由可靠性和安全性。

生产者(左侧)将消息发送给Exchange(Exchange有不同类型,如Direct、Fanout等,不同类型的Exchange使用不同的匹配算法),并由Exchange决定消息的路由,即决定消息发送给哪个Queue,然后消费者(右侧)从Queue中取出消息,进行处理。需要注意的是,Exchange本身不会保存数据,仅查看接收到消息的消息属性、消息头和消息体,并根据绑定(Binding)表转发到相应的Queue。
4.2SQLAlchemy和数据库
SQLAlchemy是基于Python的一款开源软件,提供了SQL工具包以及对象关系映射器(Object Relational Mapper,ORM),是联系Python和后台数据库的桥梁。
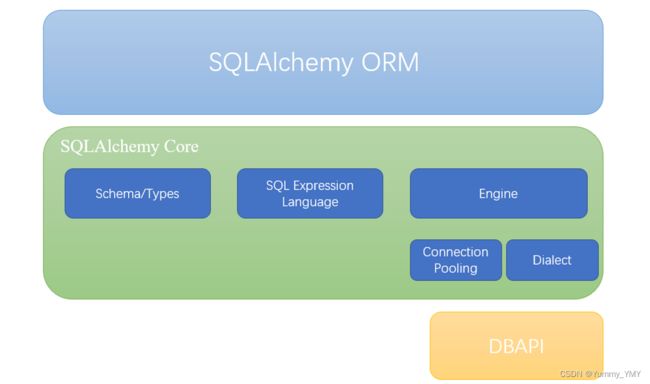
SQLAlchemy主要分为两部分SQLAlchemy Core和SQLAlchemy ORM。SQLAlchemy Core包括SQL语言表达式、数据引擎、连接池等,所有的实现都是以连接不同类型的后台数据库、提交查询和更新SQL请求、定义数据库类型以及定义schema等为目的。SQLAlchemy ORM提供数据映射模式,即把程序语言的对象数据映射成数据库中的关系数据,或者把关系数据映射成对象数据。
4.3RESTfulAPI和WSGI
4.3.1RESTful
RESTful是一种互联网软件架构,其核心概念是资源,网络里的任何东西都是资源,每个资源有一个特定的URI(统一资源定位符),并用它来标识访问获取资源。资源的不同表现形式体现为资源的文件格式。网络中,在客户端和服务端之间互动传递的只是资源的表述,这个互动使用无状态协议HTTP,客户端的基本操作会使服务端的资源发生“状态转化”,也就是所谓的“表述性状态转移”。
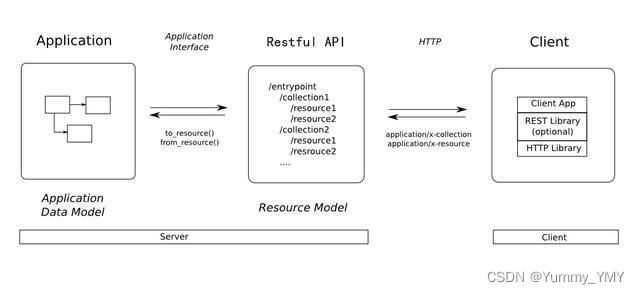
OpenStack的各个项目都提供了RESTful架构的API作为对外提供的接口。API服务进程在接收到客户端的HTTP请求时,一个所谓的“路由”模块会将请求的URL转换成相应的资源,并路由到合适的操作函数上。OpenStack中的路由模块源自对Rails路由系统的重新实现。Rail路由系统采用MVC模式。在收到浏览器的HTTP请求后,Rails路由系统将这个请求指派到相对应的Controller。每个Controller对应一个RESTful资源,代表对该资源的操作集合,其中包含很多个action,每个action都对应一个HTTP的请求和回应。
4.3.2WSGI
WSGI(Web Server Gateway Interface,Web 服务器网关接口)是Python语言中所定义的Web服务器和Web应用程序或框架之间的通用接口标准。当处理一个WSGI请求时,服务端会为应用端提供上下文信息和一个回调函数,应用端处理完请求后,会使用服务端提供的回调函数返回响应。
WSGI将Web组件分为:Web服务端、Web中间件、Web应用程序。Web服务端用于接收HTTP请求,封装环境变量。Web应用程序是一个可被调用的Python对象,只接收两个参数,通常为environ和start_response。Web中间件同时实现了服务端和应用端的API,在两端之间起协调作用。

可以利用WebOb对WSGI的请求与响应进行封装,简化WSGI应用的编写。在WebOb中有两个重要的对象,一个是webob.Request,可以对WSGI请求的参数environ进行封装;另一个是webob.Response,包含了WSGI响应的所有要素。此外,webob.exc可以对HTTP错误代码进行封装。
Pecon是一个轻量级的WSGI网络框架,其设计思想并不是解决Web世界的所有问题,而是主要集中在对象路由和RESTful的支持上,并不提供对话和数据库支持,用户可自由选择其他模块相配合。
4.4Eventlet和AsyncIO
OpenStack的大部分项目采用所谓的协程(coroutine)模型。一个OpenStack服务只会运行在一个进程中,但可以利用Eventlet产生多个协程,并且协程只有在调用了某些特殊的Eventlet库函数时才会发生切换。
与线程类似,协程也拥有自己独立的栈和堆,与其他协程共享全局变量,但在同一时间只能有一个协程运行。协程的执行顺序和时间完全由程序自己决定。协程的实现主要是在协程挂起时保存当前寄存器,重新工作时再将其恢复,可以被理解为一个线程内的伪并发方式。
Eventlet是Python的网络库,通过协程的方式实现并发。在Eventlet中协程被称为GreenThread。由于Eventlet的局限,OpenStack考虑使用AsyncIO代替Eventlet。AsyncIO提供了一套用来写单线程并发代码的基础架构,包括协程、IO多路复用,以及信号量、队列、锁等一系列同步原语。
参考文献
[1] OpenStack入门科普,看这一篇就够啦!
[2] 《每天5分钟玩转OpenStack》CloudMan编著
[3] OpenStack百度百科
[4] 《OpenStack设计与实现》英特尔亚太研发有限公司 著
部分图源网络,侵删。