分布式并行计算——数据并行
更新:
关于分布式计算在机器学习方面的系统设计,强烈推荐李沐的一篇论文 Scaling distributed machine learning with the parameter server,这是他博士期间的一项工作,算得上分布式计算在系统层面设计的巅峰之作。
这篇 2014 年的论文,现在读来仍不过时。文章调用了上千台服务器做分布式计算的实验,数据量在几百 TB 量级,模型参数量也达到了千亿的量级。考虑到频繁且大量的数据传输、网络带宽限制,以及上千台服务器的容灾管理,我们需要在算法效果与系统性能之间做一些取舍和平衡。在遵守一些通用原则的前提下,算法与系统架构的融合设计,一定程度上体现了设计者的“审美”与个人喜好。
读过论文再来看 Pytorch 中 DP 和 DDP 的设计,会感觉很熟悉。李沐也自豪地说,一些公司根据这篇论文对它们的系统做了改进和优化。如果论文读起来太费劲,可以参考沐神亲自对这篇文章的详细梳理:参数服务器(Parameter Server)逐段精读
数据并行的基本思想是将训练数据分成更小的块,让每个 GPU 处理一个单独的数据块。然后将每个节点的结果组合起来,用于更新模型参数。在 概述 中提到,Pytorch 中的数据并行有 DataParallel (DP) 和 DistributedDataParallel (DDP) 两种方式。
DataParallel (DP)
DP 的工作流程:
- 将模型拷贝到多个 GPU 上
- 将一个 Batch 的数据均分到每一个 GPU 上
- 各 GPU 上的模型进行前向传播,得到输出
- 主 GPU(逻辑序号为0)收集各 GPU 的输出,并计算损失
- 分发损失函数,各 GPU 各自反向传播计算梯度
- 主 GPU 收集梯度并更新参数,将更新后的模型参数分发到各 GPU

注意:一个 Batch 的数据要分发到多个 GPU 上,所以 Batch size 必须要大于 GPU 数量。并且 Batch size 不能过小,否则 GPU 之间的通讯过程会耗费大量时间,反而比单 GPU 计算更慢。
DP 相当于把 Batch size 增大了 N 倍(N 为 GPU 数量);且利用了多 GPU 的计算性能。
关于 DP 更详细的讨论,可参考:Pytorch 的 nn.DataParallel 详细解析
DP 的优点是代码简单:
model = nn.DataParallel(model)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
代码可参考官方 Demo:OPTIONAL: DATA PARALLELISM
DP 的弊病也很明显:它需要选择一个 GPU 作为主卡,负责汇总输出、计算损失和更新权重,显存和使用率相比其他 GPU 都会更高,造成 GPU 之间的负载不均衡。由于主卡负责和其他 GPU 通信,主卡也会存在通信瓶颈。
并且 DP 采用的是单进程、多线程的并行训练方式,只能在单台机器上运行,限制了多机多卡的使用场景。
因此 Pytorch 官方建议:
Most use cases involving batched inputs and multiple GPUs should default to using
DistributedDataParallelto utilize more than one GPU.
It is recommended to useDistributedDataParallel, instead ofDataParallelto do multi-GPU training, even if there is only a single node.—— Use nn.parallel.DistributedDataParallel instead of multiprocessing or nn.DataParallel
知识补充
MPI(Message Passing Interfacce):作为高性能计算领域的元老和通信标准,定义了一系列的通信接口,其上层可以由不同编程语言实现。比较流行的通信库:Open MPI, Gloo, NCCL,这些通信库用不同的算法实现了 MPI 的接口通信模式。常用的通信模式有:
- Broadcast:数据从主节点广播至其他各个指定的节点
- Scatter:将主节点的数据划分、散布至其他指定的节点
- Gather:收集各个节点上的元素,汇总后保存到指定节点
- All gather:与 Gather 一样,只不过把结果保存在所有节点
- Reduce:规约运算,在各个节点上获取一个输入元素数组,通过执行操作(比如 SUM、MIN、MAX),将得到更少的元素,并保存在指定节点
- All reduce:与 Reduce 一样,只不过将结果保存在所有节点
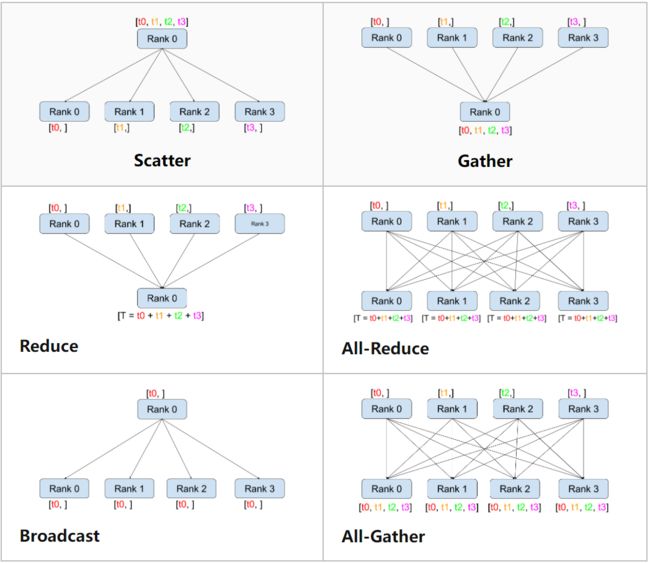
对于分布式深度学习来说,使用频率最高的就是
All reduce操作。同步更新梯度时,需要从各节点收集梯度,并汇总、更新到每一个节点,这些组合起来就是一个 all reduce sum 操作。其中ring all reduce是一种比较优秀的、也是常用的 all reduce 实现。
ring all reduce 示意图:

DistributedDataParallel (DDP)
DDP 启动多进程进行运算,不会受限于 GIL,从而大幅度提升计算资源的利用率。可以基于torch.distributed 实现真正的分布式计算。torch.distributed 为在一台或多台节点上运行多个 GPU 之间的多进程并行提供 PyTorch 支持和通信支持,并且支持多种后端。
下面是一些分布式计算的基本概念:
- Group(进程组):我们所有进程的子集。组内的进程可以互相发现并通信
- node(节点):物理实例或容器,可以理解成服务器。
- backend(后端):本质上后端是一种进程间通信机制。这些通信机制一般是由 PyTorch 之外的第三方实现的。PyTorch 支持 NCCL(NVIDIA 推出),GLOO(Facebook 推出),MPI 三种后端通信库,它们有各自的功能和优势。
- world_size(世界大小):进程组中的进程数。
- rank(秩):进程组中每个进程的唯一标识符,是从 0 到 world_size - 1 的连续整数。
- local rank:进程内的 GPU 编号。非显式参数,这个一般由 torch.distributed.launch 内部指定。例如, rank=3,local_rank=0 表示第 3 个进程内的第 1 块 GPU。
后端选择:
- 使用英伟达 GPU 时,选择 NCCL
- 使用 CPU 时,选择 Gloo
Using DDP means to start an independent python training script on each node (these scripts are all identical). As we will see, once started, these training scripts will be synchronized together by PyTorch distributed backend.
下面的示例展现了两个各自包含4个 GPU 的节点。server - 1 是主节点(master),它负责协调其他进程;其他节点通过 IP 地址和端口号与主节点进行通信。

DDP 概览
首先将模型和优化器复制到各个 GPU 上。各 GPU 上模型的参数初始化一致;而且优化器的随机种子也相同。

DistributedSampler 为每个 GPU 加载一个 Batch 中不同部分的数据。各个 GPU 上分别进行前向和反向传播,计算出梯度:

由于输入不同,计算出的梯度也不同。此时,进行分布式通讯:利用 ring all reduce 算法,使每个 GPU 都拥有其他 GPU 上计算出的梯度:

然后各 GPU 利用各自的优化器上分别进行参数更新。由于各个模型初始参数以及优化器的随机种子均一致,更新后的参数也是一样的。这样就进入下一轮计算和优化。后面我们会看到,如何通过保存、加载检查点,在单个 GPU 上优化、保存模型,在其他 GPU 上加载模型,避免重复优化。
DDP 工作流程
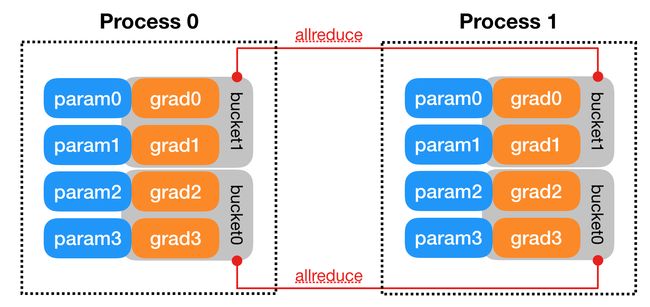
实际工作中,不会等到模型的全部梯度计算完毕后再进行 all reduce,而是计算一部分就传输一部分,让梯度计算与进程间通信相互覆盖,提高效率。这就是下面提到的“参数分桶”
- 初始化进程组。
- 创建分布式并行模型,每个进程都会有相同的模型和参数。
- 创建 DistributedSampler,使每个进程加载一个 Batch 中不同部分的数据。
- 网络中相邻参数分桶,一般为神经网络模型中需要进行参数更新的每一层网络。
- 每个进程前向传播并各自计算梯度。
- 模型某一层的参数得到梯度后,马上进行通讯并进行梯度平均。
- 各 GPU 更新模型参数。
参数分桶:将不同参数的梯度按照 Model.parameters() 的逆序进行分桶(Buckets)。每一个桶内的梯度计算完毕后,就进行 all reduce 操作。
单机多 GPU 代码示例
单机多 GPU 代码范例参见官方 tutorial 仓库:multigpu.py
下面主要看一下,相比于单 GPU,单机多 GPU 训练代码有哪些变动:
- 导入分布式训练所需模块
+ import torch.multiprocessing as mp
+ from torch.utils.data.distributed import DistributedSampler
+ from torch.nn.parallel import DistributedDataParallel as DDP
+ from torch.distributed import init_process_group, destroy_process_group
+ import os
- 初始化进程组,默认用 TCP 方式初始化。初始化方法的更多信息:three initialization methods
+ def ddp_setup(rank: int, world_size: int):
+ """
+ Args:
+ rank: Unique identifier of each process
+ world_size: Total number of processes
+ """
+ os.environ["MASTER_ADDR"] = "localhost" # 单机多GPU训练,主节点的IP地址就是 'localhost'
+ os.environ["MASTER_PORT"] = "12355" # 主节点闲置端口
+ init_process_group(backend="nccl", rank=rank, world_size=world_size) # 使用 CUDA GPU 训练,用 nccl 后端
- 构建 DDP 模型
- self.model = model.to(gpu_id)
+ self.model = DDP(model, device_ids=[gpu_id])
- 利用
DistributedSampler在进程间分发数据。注意:shuffle=False且sampler要指定为DistributedSampler实例
train_data = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=32,
- shuffle=True,
+ shuffle=False,
+ sampler=DistributedSampler(train_dataset),
)
并且在每个 epoch 开始时,都要调用 DistributedSampler 的 set_epoch() 方法。
In distributed mode, calling the
set_epoch()method at the beginning of each epoch before creating the DataLoader iterator is necessary to make shuffling work properly across multiple epochs. Otherwise, the same ordering will be always used.—— torch.utils.data.distributed.DistributedSampler
def _run_epoch(self, epoch):
b_sz = len(next(iter(self.train_data))[0])
+ self.train_data.sampler.set_epoch(epoch)
for source, targets in self.train_data:
...
self._run_batch(source, targets)
- 保存检查点:对于 DDP 模型,需要用
model.module.state_dict()访问模型参数。并且只需要在一个进程中保存检查点
- ckp = self.model.state_dict()
+ ckp = self.model.module.state_dict()
...
...
- if epoch % self.save_every == 0:
+ if self.gpu_id == 0 and epoch % self.save_every == 0:
self._save_checkpoint(epoch)
- 训练 DDP 模型
- def main(device, total_epochs, save_every):
+ def main(rank, world_size, total_epochs, save_every):
+ ddp_setup(rank, world_size) # 初始化进程组
dataset, model, optimizer = load_train_objs()
train_data = prepare_dataloader(dataset, batch_size=32)
- trainer = Trainer(model, train_data, optimizer, device, save_every)
+ trainer = Trainer(model, train_data, optimizer, rank, save_every)
trainer.train(total_epochs)
+ destroy_process_group() # 进程结束后删除
if __name__ == "__main__":
import sys
total_epochs = int(sys.argv[1])
save_every = int(sys.argv[2])
- device = 0 # shorthand for cuda:0
- main(device, total_epochs, save_every)
+ world_size = torch.cuda.device_count()
+ mp.spawn(main, args=(world_size, total_epochs, save_every,), nprocs=world_size)
调用脚本:
python multigpu.py 50 10
ddp_setup 函数:在所有节点上设置以下四个环境变量。以便所有进程都可以正常连接到 master(即 rank 0 进程),获取其他进程的信息,并最终与它们握手。
MASTER_PORT:承载 rank 0 进程的机器上的一个空闲端口。MASTER_ADDR:承载 rank 0 进程的机器的 IP 地址。WORLD_SIZE:进程总数,因此 master 知道要等待多少 worker。RANK:每个进程的 rank,所以它们会知道自己是否是 master。
torch.multiprocessing.spawn(fn, args=(), nprocs) 函数:初始化 nprocs 个进程,把 fn 作为每个进程的初始化入口。
- fn (function) – Function is called as the entrypoint of the spawned process. The function is called as
fn(i, *args), whereiis the process index (rank) andargsis the passed through tuple of arguments. - args (tuple) – Arguments passed to fn.
- nprocs (int) – Number of processes to spawn.
利用 torchrun 提高 DDP 容错
在 DDP 中,单个进程的失败会破坏整个训练。随着进程数的增加,失败概率也会增大,因此训练脚本的鲁棒性尤为重要。而且,我们还希望训练工作是弹性的。例如,可以在工作过程中动态地加入和删除计算资源。
PyTorch 提供了 torchrun ,来增强容错、允许弹性训练。当故障发生时,torchrun 会记录错误,并尝试从最后保存的 “快照”(snapshot)中自动重新启动所有进程。快照保存的不仅仅是模型状态;它可以包括关于 epoch、优化器状态、学习率规划器或训练中任何其他必要的状态属性的细节,以保证连续性。
torchrun 的主要功能:
- 无需设置环境变量以及手动分配
rank和world_size - 无需调用
mp.spawn函数,只需要一个main()函数作为入口,然后用torchrun运行脚本 - 可以以快照为起点,继续训练
下面展示单机多 GPU 训练时,有无 torchrun 的代码区别,参见 multigpu_torchrun.py:
- 无需设置环境变量以及手动分配
rank和world_size
- def ddp_setup(rank, world_size):
+ def ddp_setup():
- """
- Args:
- rank: Unique identifier of each process
- world_size: Total number of processes
- """
- os.environ["MASTER_ADDR"] = "localhost"
- os.environ["MASTER_PORT"] = "12355"
- init_process_group(backend="nccl", rank=rank, world_size=world_size)
+ init_process_group(backend="nccl")
- 使用
torchrun提供的环境变量
- self.gpu_id = gpu_id
+ self.gpu_id = int(os.environ["LOCAL_RANK"])
- 保存、加载 snapshot
+ def _save_snapshot(self, epoch):
+ snapshot = {}
+ snapshot["MODEL_STATE"] = self.model.module.state_dict()
+ snapshot["EPOCHS_RUN"] = epoch
+ torch.save(snapshot, "snapshot.pt")
+ print(f"Epoch {epoch} | Training snapshot saved at snapshot.pt")
+ def _load_snapshot(self, snapshot_path):
+ snapshot = torch.load(snapshot_path)
+ self.model.load_state_dict(snapshot["MODEL_STATE"])
+ self.epochs_run = snapshot["EPOCHS_RUN"]
+ print(f"Resuming training from snapshot at Epoch {self.epochs_run}")
- 断点续训
class Trainer:
def __init__(self, snapshot_path, ...):
...
+ if os.path.exists(snapshot_path):
+ self._load_snapshot(snapshot_path)
...
def train(self, max_epochs: int):
- for epoch in range(max_epochs):
+ for epoch in range(self.epochs_run, max_epochs):
self._run_epoch(epoch)
- 像非分布式训练那样,只提供
main()作为入口函数。torchrun会自动调用mp.spawn启动进程。
if __name__ == "__main__":
import sys
total_epochs = int(sys.argv[1])
save_every = int(sys.argv[2])
- world_size = torch.cuda.device_count()
- mp.spawn(main, args=(world_size, total_epochs, save_every,), nprocs=world_size)
+ main(save_every, total_epochs)
调用脚本:
torchrun --standalone --nproc_per_node=4 multigpu_torchrun.py 50 10
--standalone表示在单机上进行训练--nproc_per_node=4表示使用该机器上的4个 GPU 进行训练。也可以直接写--nproc_per_node=gpu,表示使用该机器上所有 GPU 进行训练。
多机多 GPU 代码示例
代码参考:multinode.py
首先明晰一下 Local Rank 和 Gobal Rank 两个概念。
- Local Rank:每台机器上 GPU 编号都从 0 开始
- Gobal Rank:对所有机器上的所有 GPU 进行统一编号


相比于单机使用 torchrun 的代码:
class Trainer:
def __init__(...)
+ self.local_rank = int(os.environ["LOCAL_RANK"])
+ self.global_rank = int(os.environ["RANK"])
...
def _run_epoch(self, epoch):
b_sz = len(next(iter(self.train_data))[0])
+ print(f"[GPU{self.global_rank}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")
双机多 GPU 训练,在两台机器上分别用 torchrun 运行脚本:

torchrun --nproc_per_node=4 --nnodes=2 --node_rank=0 \
--rdzv_id=456 --rdvz_backend=c10d --rdvz_endpoint=172.31.43.139:29603 \
multigpu.py 50 10
torchrun --nproc_per_node=2 --nnodes=2 --node_rank=1 \
--rdzv_id=456 --rdvz_backend=c10d --rdvz_endpoint=172.31.43.139:29603 \
multigpu.py 50 10
参数解析:
-
nproc_per_node:在该机器上使用多少 GPU -
nnodes:一共有多少台机器 -
node_rank:这台机器的编号 -
rdzv_id:rendez-vous id(会合 id),唯一的 job id。参与这个 job 的所有机器应该拥有同样的会合 id,这样它们才能互相发现、互相通信。这里为所有机器选一个随机数即可。 -
rdzv_backend:机器间通讯的后端实现,建议使用 c10d -
rdzv_endpoint:某台机器的 IP地址:端口号host:port的形式。可以选择任务中的任何一台机器,但由于rdzv_backend托管在这台机器上,所以建议选择带宽高的机器。
除了
nproc_per_node和node_rank, 其余参数均应该保持一致。
如果机器数量庞大,上面这种方式就不适用了。这时可以利用工作调度工具(如 Slurm),在计算集群上部署 DDP。
仓库中提供了利用 Slurm 在AWS 计算集群上部署的范例:Setup AWS cluster with pcluster
参考:
- 官方视频教程:WHAT IS DISTRIBUTED DATA PARALLEL (DDP) —— 强推
- 示例代码仓库:ddp-tutorial-series
- Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
- [源码解析] PyTorch 分布式(4)------分布式应用基础概念
- 【深度学习】— 分布式训练常用技术简介
- TORCHRUN (ELASTIC LAUNCH)