阿里如何做好双11技术保障?大队长霜波分享4点经验(转自阿里技术)
阿里妹导读:为什么说双11是阿里每年技术保障稳定性最困难的一次?50多个BU一起加入双11,怎么组织和运营?为了保障双11的顺利进行,又有哪些备战方案以及创新技术?在由阿里云CIO学院主办的【2020中国企业数字创新峰会】上,阿里巴巴双11技术大队长、技术安全生产负责人、CTO线技术风险部资深总监陈琴(霜波)从组织和运作、备战方案和技术、当天保障以及复盘总结四个方面分享了阿里巴巴在双11技术保障上的实践经验。
文末福利:七天MySQL和PostgreSQL训练营来了!
每年双11都是一个比较艰难的项目。我现在的职位是阿里集团的技术风险负责人,所谓技术风险就是稳定性的保障是我这边负责的。对阿里巴巴来说,对整个经济体来说,每年技术风险最大的一次就是双11。
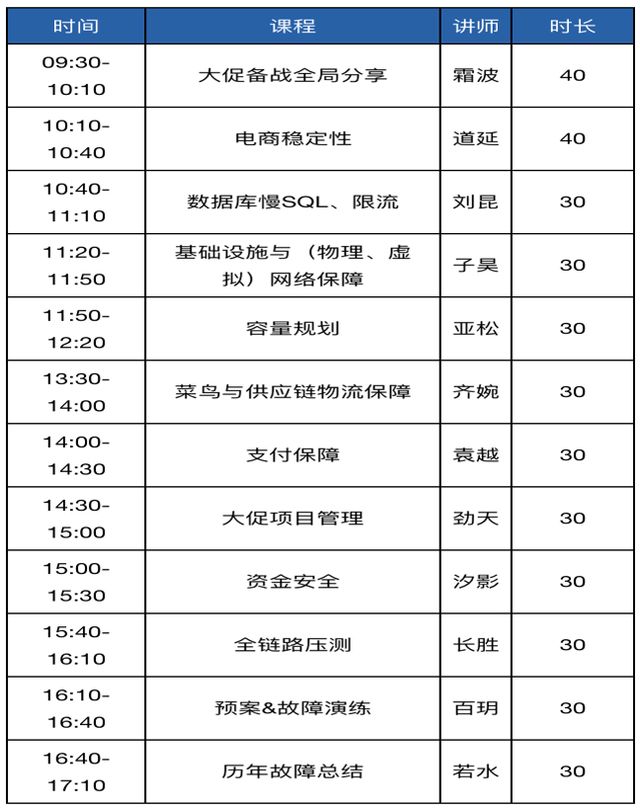
为什么说双11是每年技术保障稳定性最困难的一次?每年双11我们都会向大家分享交易额是多少,连续12年的数字大家可以在各种媒体看到。但是对技术来说,我们其实不看这个,我们看订单创建的量,看订单创建每秒多少QPS,就是每一秒有多少用户请求进来。为什么每年在双11零点的时候都会有人被限流下单会失败?进入量超过系统容量就会被限制住,第二次下单的时候大概率就会成功了。从下图中可以看到,双11的峰值这几年每年都是几万几万的上涨,至少五万五万上涨。当一个非常大的流量到来的时候,对系统来说这是完全没有经历过的。所以当遇见一个不可确定的事情的时候,对技术的挑战是最大的,这就是为什么每年双11都会有不少的同学出现各种各样的问题。
2020年双十一的峰值
以下是整个双11的技术保障目标:

双11保障核心作战目标
对阿里来说,我们不管做一件什么事情,第一先聊KPI,有了KPI之后才知道目标,才可以拆解,每个BU要干什么都是按照KPI分解的。这么多年来第一项KPI一直都是如此,交易限流在多少,我承诺给业务,能够保证每秒钟进来这么多用户,但是如果当天的用户超过这个承诺,其他的用户需要二次下单,一次下单会被限制住,这是第一个承诺。
第二个承诺就是稳定性。对所有稳定性的衡量都是一个,叫故障数。故障对应的就是用户体验和用户期望的差距,差距越大,比如用户的投诉量到达多少,一般四个用户投诉就计为故障。我们要求不能够发生任何系统问题。
第三个承诺就是,要求全过程用户的体验是流畅的。很多用户第一次下单虽然失败,但是第二次你进入限流范围之内,我们要保证你的整个支付行为是没有任何差错的,尤其是金额绝对不能有任何问题。
最后一个,全链路压测百分之百验收成功,这是这两年加上去的目标。
对于双11这么大的项目,尤其对阿里经济体来说,一共有50多个BU一起加入双11,首先要考虑怎么组织和运营。第二,备战方案还有一些技术的创新,最核心的就是让我这个队长放心,说这件事情真的已经成功了,如果没有技术方案保证,每次都是靠人的承诺其实是不靠谱的。第三,双11当天,52个BU同时迎接这个流量高峰的时候,哪里出现了问题,哪里需要去协调,哪里需要去扩容,当天的保障方案。最后还有多年双11这些经验是怎么传承下来的,这是今天要分享的四个环节。
一 组织和运作
每年双11都会成立一个集团技术大促小分队。对阿里巴巴经济体来说,是一个很大很大的BG,在下面会有很多很多BU。每个技术部门归属是不同的BU,但是双11今年是52个BU共同参加,这些BU怎么协同起来,每个时间点怎么把它整体运作起来,这里的组织方式首先会有一个技术团长,会任命出来,在团长之后会有大队长的角色,过去几年我都是技术大队长的角色,技术大队长之后就是每个BU都会有一个技术队长,技术队长之下每个BU的人员都会固定下来加入这个BU的队长。

集团技术大促小分队:52个BU
在此之后,我们就开始整体的运作。从7月份的时候就要开始方案尤其是PRD今年采取什么样的营销玩法,哪些BU参加,参加的时间点,比如今年要做双波动,8月的时候可能就要开始决定双波动怎么做,怎么通知到商家,怎么通知到用户,所以7月、8月就结束了。8到9月是集中开发上线的环节,会有技术备战的汇报,同时这里都是用双周会的形式运作,到10月的时候就会有作战手册的汇报。作战手册也是很关键的环节,每年双11等到10号的时候,我们会做很多之前的预操作,因为为了应付零点,我们会有很多其他的功能的降级,机器的协调,所有的预热,这些情况都是在头两天必须完成的,这里甚至一个降级开关如果没有成功,有可能当天的双11就会面对很大的风险。今年我们提前降级的开关有两千多个,如何保证全部都是降级成功,不能够出一点问题,基本上是每个降级开关执行最后都有人验证。我是2008年加入的阿里,是广告技术部的质量负责人,2012年的时候收到组织调动,去做天猫质量负责人,调动的时候大概是6月份,完全不知道,为什么突然之间组织调动了。

2020双11技术队长沟通节奏
二 备战方案和技术
我们一直以为商家想要的一定是给我更多的流量,让我卖更多的货,赚更多的钱,这应该是商家的选择。但是2011年,90%的商家在填问卷调查的时候,选择的是系统稳定。有一个商家解释了为什么会选择系统稳定。他说2011年我参加双11,零点的时候收到天猫的电话,告诉我所有的商品下架,当时全部公司的员工都在值班,听从你们的话把商品下架,一直等到早上6:30,没有一个人敢回家,因为回家之后对家里人说的一句话就是我的公司要破产了。每年大家为了双11商家特别辛苦,要准备平时十几倍的量,之前要做大量采购、库存,如果这些在双11当天卖不出去,对商家来说是风险很大的一件事情。直到早上6:30的时候,接到天猫的通知说你们现在可以重新上架。所以听到这个故事的时候,我心里确实压力很大。
这些年,平台的稳定性已经变成了商家对我们的一个基本要求,如果平台不行的话对商家的影响是非常大。我回去之后想了解为什么在2011年的时候会出现这样的情况,必须在零点的时候通知商品下架,后来知道了那一年出现了一个功能性的错误。虽然之前我们做了很多的验证操作,但是在那天晚上8点的时候,收到商家反馈,说他把折扣填错了。折扣是这样的,报名参加了几折,3折就填3,但是有商家填成了0.3,这个时候系统×0.03,他就会卖亏。我们当时一听说就担心很多商家会发生这样的情况,就做了一个决策,把所有的商品的属性导了出来,低于1折的商品恢复到原价,然后再写进系统里去。这个写进系统的所有的商品的库存,写进去的时候漏了一个参数,把SKU弄没了,那个SKU比如说是衣服的话,就是大小、颜色都没有了,全部写成空。所以那一年零点的时候商家告诉我,我货卖出去了,但是我不知道卖的什么大小,如果发不出去货天猫又是30%的赔付,所以最后集体包括业务和技术再一次做决策,把所有SKU的商品全部下架。我们修了很久,修到早上6点半。那个时候量很大,白天虽然晚了6个小时,但是白天还卖的可以,最后商家的反弹不是很大。听到这个时候,我就觉得系统保障一定要做好,再也不能出现这种功能性的BUG。
到了2012年的时候,其实我做了特别多的工作,就是所有的功能测试下单有没有SKU肯定要一个个验证,价格不能出错。我还做了很多的预案,防止一旦容量过大的时候,我们有哪些降级方案。还做了性能测试,但是性能测试那个时候都是叫缩容测试,缩容测试就是比如线上是400台机器在扛一个系统,它的QPS是4,用线下4台机器搭一个环境,看看上市之后能不能成功。基本上那个时候质量团队能够用的方法全部用了,当时的天猫技术负责人每天问我,因为大家都特别紧张,我就告诉他不会有问题了,功能测试我都是自己一个一个去验证的,保证不会有问题。
2012年,当时系统成功率只有50%,也就是说一个用户进来有50%的概率是要失败的,一直持续了一个小时之后,系统成功率才慢慢回来。我当时作为质量负责人看到各种各样的错误页面,浏览的时候就失败了,确认订单失败了,下单失败了,支付失败了,那是我看到的最多的一次错误页面,各种各样的错误页面。回去之后其实就复盘,我们就在想确定究竟哪里出了问题,最后是网卡被打满,商品中心是IC,商品中心网卡被打满,网卡是50%被打满,导致50%的用户下单失败,但是商品中心是一个特别核心的系统,因为你浏览的时候要调商品,下单都要调商品,都要去商品中心确认一下,一旦网卡被打满的情况下就会出现这种情况。
复盘的时候大家心情都很沉重,为什么沉重?当时我们就想,针对这个问题我们明年有什么样的解法?当时在技术上没有一个好的解法,因为我们所有的压测,是缩容压测,可以把机器缩10倍,可以在线下去搭。但是我的网卡能不能缩?网卡就是千兆网卡,所以这个情况下怎么办呢,那个时候复盘的时候提出一个方案,我们必须到线上做真实的全链路压测,不能在下面搭一个测试环境压,必须到线上把所有的容量模拟双11的峰值直接压上去,这是当时提出来的方案。

这个方案提出来容易,但是实现是很难的。很多东西之所以前人没有做只有一个原因,就是太难了。为什么不敢做呢,很简单,因为线上压测的时候都是测试数据,测试数据一写到线上的生长库,用户的数据马上就会被污染掉。所以那一年第一个退出这个项目的是支付宝,支付宝的同学跟我们说,如果用户发现他的钱出错了,多了几个0,影响面太大了。2012年的复盘会议上,人就分了两派,一派这个太难了,线上做不出来。还有一派人,没有办法做不出来也得做。作为队长,实际上这个时候是没有退路的,因为我心里很清楚,用原来的方法是不可能保障双11系统稳定性的,所以在第二年一直讨论方案,讨论方案的时候提出来,为了不影响线上的用户,我们再做一套数据库。方案想出来了就要开始实行,实行的时候改造量是非常大的。因为从刚开始的CR系统,到后面所有的应用系统,每个应用系统都必须加一个测试标,必须要判断一下什么是测试标,什么是真实流量。还有中间件,中间件全部要进行改造,底层还有数据库,阿里所有核心系统全部要针对全链路压测做改造,几千个应用系统,几十个中间件,现在是几十万的数据库全部进行改造,工作量是非常大的。但是当时既然成立了这个团队,从6月份的时候就开始做,一直做到10月第一周,距离双11只差一个月,到了10月第一周的时候我们还没有压测上去一次。
真实的压测是一个脉冲上去然后看系统的情况,但是到十月第一周的时候还没有成功一次。所有的队长在一起,各个BU的队长也加入进来讨论,这个时候应该做一个什么样的决策。有一部分同学就提出来,说这个时候我们应该赶快回到老的方法,就是原来的缩容压测。当时我是第二派,这个时候兵分两路,一些人做线下,一些人做线上。我还记得很清楚,那个时候是天猫的技术队长叫南天,他当时拍着桌子非常强硬地说我们线上全链路压测只许成功,不许失败,虽然我们当时分了三派,但是大家开会的时候一般谁胜出?谁说话声音最大谁就赢,他当时真的是拍着桌,只差站在桌子上,要求每个BU的核心系统再投入一个同学加入压测团队,因为他特别强势,大家都被他吓着了,赶快交人。几十个同学就加入了,原来就是十几个同学,现在一下子几十个同学加入,一周之后全链路压测成功了,那一年线上全链路压测最后发现的BUG有六百多个。
所以通过这全链路的压测学会一个问题,就是真正的创新其实就像我们长跑一样,刚开始的时候会觉得特别难,做到中期的时候发现更难,但是一定要相信自己可以成功,在最后的时候不放弃,总会有跑到的那一天,所有的创新基本都是这样来的。
可以看到这就是2011年系统功能BUG,通知商家下架,2012年双11有了预演,2016年把预演变成了系统,2012年成功率低于50%,2013年诞生了交易全链路线上压测。2014年的时候这个量更大了,大到杭州机房,一个机房已经装不下这么多机器,这个时候就必须开始分机房,但是分机房的问题是,用户如果在不同的机房,延迟是很大的。这个时候我们就做了异地双活,有一个用处,当出现问题的时候,杭州的机房出现问题,比如说断网立刻可以切到另外一个机房,但是这个时候对系统同样有要求,必须是单元封闭,保证所有的用户在一个机房之内运行。
接下来,等到2013年、2014年,我们叫稳定性的两年。到了2015年、2016年我们又出现问题了。当时做了所有的线上交易全链路的压测,但是2015年出现了一个很大的变化,就是双11的时候,有50%的用户从以前的PC全部转到了手机,2016年90%的用户全部到了手机端。这是用户行为的变化,是我们始料未及的,刚开始的时候更多是关注PC端,手机那边的流量猛增超出预期,导致出现了问题。
2016年是自己系统出现了问题,这个问题就是一个冷库和热库。那时候我也是技术队长,我发现这两个曲线挺好的,但是对比2014年这两个曲线爬坡爬得特别慢,什么原因呢,头两年的时候我们没有看,2016年的时候就变成下滑的一个坑,一分钟一个坑慢慢下去。为什么会慢慢爬,就是一个程序的问题,程序有预热,刚刚上线的时候本身预热是不够的,当到了一个大流量的时候,热了,对数据库来说也是的。当你去调用它的时候,如果它的数据是热的,会提前写到缓存马上能够读,但是如果冷存就要调用所有的数据库。为什么有全链路压测还会出现这些问题,全链路压测每次的数据都是一批的数据,之前就已经是热的数据。这就是为什么在2016年的时候头2分钟下去然后自己会起来,是一个冷库下去了,但是当热起来的时候自己又会爬起来,系统不做任何的操作。2017年就做了预热平台,2017年的时候取得了非常好的效果。
这是双11的一些故事。等到2018年的时候又出现了一个问题,我们那年的KPI没有完成,因为2018年的时候修改收货地址出了问题,系统直接挂了,就是寄到默认地址,不能改变地址,很多同学把大米寄到了厂房,原因也很简单,当你忽视任何一个系统压力测试的时候,一个系统没测试到,风险其实就会特别大。
但是2019年、2020年这两年还是比较稳定的,所以今年大家可以体验一下,今年是这么多年来限流最少,用户体验最好的一次。
下图就是我们当时做线上全链路压测的照片,每次都是几百号技术在一个房间里面,一旦哪个系统有问题,大家就叫一下什么系统出问题,压的时候大家也还比较紧张,因为随着峰值越来越上去的时候,我们特别想看到究竟是哪个系统第一个挂掉,大家就想着我不要做第一个挂掉的系统。

全链路压测
整体上来说,第一要改造的就是施压的来源,现在施压来源为了真实的模拟线上,采用的CDN在全国两千多个节点的机器,如果是在一个机房施压,是模拟不了那么多场地的,包括我的网络来源,但是现在CDN在全国都有部署,来源比较准确。然后是模型的预测,基本上所有的线上用户去取出来,还有流量的隔离,就是我的流量如何保证是进入线上影子库的,最后是线上真实的施压。
这是整体的全链路压测的架构图。下面就是我们模型数据,比较核心的就是模型一定要准确,到现在为止,如果压测和真实出了问题基本就是模型出了问题,比如说优惠券有多少,用户买的商品,一个商品有多少下单。

全链路压测的架构图
下图是全链路压测在第一年发现的各种性能问题,这些问题在线下压测很难发现。第一是硬件问题。因为在线下那4台机器大概率是最新的机器,但是线上有些老旧的网卡和机器,还有小内存和中间件的问题,基础服务比如系统大规模发布在那天会出现问题,还有限流。虽然前面说限制了60万的数值,但是这个限流只要调一次就有可能是不对的,你怎么保证是对的?还有容量的问题,领取的容量不够,包括业务系统,业务系统超时的时候,在上下游超时情况下,会出现哪些问题,都只有在全链路压测的时候才能够发现。

全链路压测发现的问题
第二个技术是全链路功能。这个更晚一些,它的特点就是在做压测的时候不能验证一样东西,用户下单是不是成功,只能验证容量是够的。那个时候很多人反馈我从购物车选择全选一键下单是很难成功的,甚至有人得出来双11零点抢货的攻略,就是一件一件下单成功率比较高,如果包含很多订单,只要一笔订单失败,全部的订单都会失败,确实会有一部分订单会失败。怎么样保证双11当天所有的订单下单都是成功的呢?这里就提出了全链路的功能。全链路功能是,在大家下单之前基本上会把在购物车里面的商品,所有的提前下单,就是全链路的功能。其实订单已经被系统下单过一次,确定这些订单下单的时候都是成功的。在下单的时候就要检测用户的优惠券有没有正确使用,最后的支付有没有成功。其实就是靠一个线上的环境,第一是在隔离的环境,第二是线上全量的数据,几千万的商品、几千万的用户,基于线上的模型,所有的时间会放在11月11号,因为所有的优惠都是11号生效,一旦改了时间,这些优惠才能够使用,这是功能的图表。下面是数据的转换,上面是测试运力的生成,下面是分析,就是每笔订单产生止损,下单的金额和预想的金额是否一致,全部在这里检测出来,这就是全链路的功能。

全链路功能
应对这种大促,我们怎么样做好稳定性的保障?其实对于系统来说,最高危的问题都是变更导致的,但是双11那一天,我们是不能够允许出现一点点错误,这个时候就会提前封网,封网最早的时候只做应用类的封网,把发布系统封了。但是底层更惨,现在底层在云产品上,从第一层基础设施开始,第二层云产品,计算、存储、网络、调度、数据库、中间件,一层一层全部有一个集中的管控,这样能够保证双11当天,之前所有测试验证过的结果和当天是一样的。
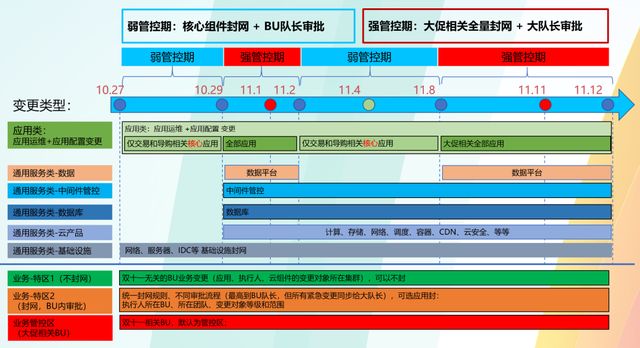
封网管控
攻防演练是这样的,我们其实很担心双11当天会不会出现什么问题,出现问题之后,我们能够做什么?所以在这之前就要模拟各种会出现的问题,包括网络掉电、服务器硬件设施故障等。在这种情况之下,我们能够做什么?所以对于攻防演练来说,就是历史所有的故障只要发生过高可用故障都会记录下来,接下来进行模拟,当再发生这个问题的时候我们能否快速恢复。给所有经济体提的一个目标,叫做:1、5、10,要保证所有的系统10分钟之内恢复,如果不能恢复这个系统要进行改造,所有的故障近期都有突袭,现在所有的系统都是在阿里云之上,阿里云的断电断网,最多模拟800台容器同时断掉,还有机房整体挂掉的模拟,我是怎么样逃逸的,通过这场逃逸才能够让这个机房真正使用起来。只有这些突袭和演练才能够把这个系统出现故障的时候能够快速恢复。

突袭与演练 – 红蓝军
三 当天保障
双11当天信息会特别多,有很多人问我,双11当天钉钉是不是会爆掉?确实,双11当天钉钉肯定是爆掉的,每个BU所有的操作所有的变更同一时间去了解,还要了解系统的情况。双11当天怎么组织所有的问题的收集?第一就是前线,前线就是问题的来源,CCO会收录所有客户反馈的问题,如果是技术问题就计入云顶,云顶就是大促指挥台,云顶会自动同步,一旦计入云顶的问题,根据涉及是哪一个BU,自动拉群,BU情报员和通信员会马上处理相关的问题。还有重大故障,一旦到P2以上就是重大故障,队长优先级第一处理所有的重大的故障,在重大故障里面做所有的决策。BU的值班人还有应急协同群,还有高级情报员,觉得涉及比较大的风险,就直接到指挥部,指挥部一般会给出最终的决策,比如说这个项目你要不要修复,还是舆情上怎么处理,商家怎么通知等等,这些所有的应急通信全部是在这一个系统上做出来的。
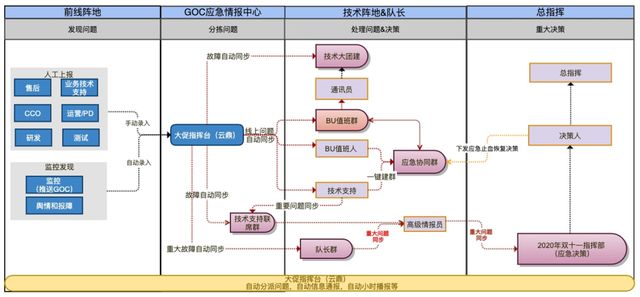
双11应急协同流程
下图是我们稳助大促一系列运营序列。大家可以看到从最早的要点提醒到作战手册,这是各种专项,突破演练,破坏性的报告,云顶怎么样使用,全部通过直播的方式进行开课,所有技术同学能够知道双11当天我们要处理什么样的流程。

稳助大促系列运营
四 复盘总结
对双11来说,每年都有新的BU加入。前几年的时候我们就发现,每年出现的新故障总是在新加入的BU里面,之前的经验没有传承下来。所以在复盘和总结的时候,我们也做了一个系统,叫大促指挥台,这里面会列出各个BU每年每次活动所有的复盘报告,大家如果想知道去年是怎么做的,发生了哪些问题,在这里面全部都能找到。
针对每年的大促,比如618、双11,会有新的队长,这个时候也有一个传承,就是新人大促培训营,一旦队长确定了,大促培训营所有的课程讲师就会每年都上课,告诉大家应该要怎么做,做好哪些系统和限流。