C++入门----重要语法详解:命名空间、IO、缺省参数、函数重载、引用、内联函数、auto、范围for、nullptr

前言
C++兼容C语言,但并不只是C的扩充,C++语言特性直接支持四种程序设计风格:过程式程序设计、数据抽象、面向对象程序设计、泛型程序设计。本文将介绍C++的部分语法特性,其中缺省参数、函数重载、引用等是设计类的重要基础,适合所有具有其它编程语言基础的同学进行C++入门学习,特别是C使用者将初步体会到C++的美妙之处。
目录
前言
1 命名空间(namespace)
1.1 命名空间的定义
1.2 显式限定
1.3 using声明
1.4 using指示
1.5 命名空间嵌套
2 I/O 流
2.1 输出
2.2 输入
2.3 std的使用惯例
3 缺省参数(default argument)
4 函数重载
4.1 定义重载函数
4.2 重载与作用域
5 引用
5.1 引用即别名
5.2 常引用
5.3 传引用参数
5.4 引用做返回值
5.5 引用和指针的区别
6 内联函数(inline)
7 auto类型说明符(C++11)
8 范围for语句(C++11)
9 指针空值nullptr(C++11)
9.1 NULL的缺陷
9.2 nullptr常量
1 命名空间(namespace)
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。C++提供了一种称为命名空间(namespace)的机制,一方面表明它们的名字不会与其它命名空间中的名字冲突,另一方面表达某些声明是属于一个整体的。
1.1 命名空间的定义
使用namespace关键字,后面跟命名空间的名字,然后是{},在{}中定义命名空间中的成员。格式如下:
namespace namespace-name
{
// 命名空间中可以声明和定义变量、函数、类型
int a;
int Add(int x, int y)
{
return x + y;
}
struct student
{
int name;
int grade;
}
}
1.2 显式限定
一个命名空间就形成了一个作用域,在命名空间中,稍后的声明可以引用之前定义的成员。在命名空间外使用其成员则需要使用命名空间名称加作用域限定符(::)的语法,即“命名空间名::成员名”。
例如,我们可以在命名空间的定义中声明一个成员,稍后使用“命名空间名::成员名”定义它。
namespace N
{
int Add(int x, int y);// 声明
}
int N::Add(int x, int y) // 定义
{
return x + y;
}
//int val = Add(1, 2); // 错误,没有全局函数Add(int, int);
int val = N::Add(1, 2); // 使用命名空间引入新成员必须使用如下语法:
namespace namespace-name
{
// 声明和定义}
例如:
//int N::Sub(int x, int y); // 语法错误
namespace N
{
int Sub(int x, int y) // 增加成员Sub()
{
return x - y;
}
// 现在N包含Add()和、Sub()两个成员
}全局作用域也是一个命名空间,可以显式使用::来引用。例如:
void f() { // 全局函数
}
int g()
{
int f; // 局部变量
f(); // 错误:不能调用一个整型变量
::f(); // 正确:调用全局函数
}不能通过限定符语法在命名空间之外为其声明一个新成员,这是为了捕获成员使用错误(拼写错误,类型不匹配等错误),以及便于在命名空间中查找所有成员名字。
命名空间是开发放的,即可以在多个分离的命名空间声明中向同一个命名空间添加成员。除了在同一文件中为命名空间增加成员,更重要的是同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
1.3 using声明
当我们需要在命名空间外频繁使用其成员时,反复用显示限定就显得很繁琐。为了缓解这个问题,我们可以使用using声明来指出名字的来源。用法为: using 命名空间名::成员名。
using N::Add; // 用Add表示N::Add,引入全局作用域
int val1 = Add(1, 2); // 使用
int f()
{
using N::Sub; // N::Sub引入局部作用域
int val3 = Sub(1, 2); // 使用
}using声明将一个代用名引入了作用域, 应保持代用名的局部性以避免混淆。当用一个重载名字时,using声明会应用其所有重载版本。见4 函数重载。
1.4 using指示
使用using指示可以在作用域中无须使用限定即可访问一个命名空间中的所有名字。用法为:using namespace 加命名空间名称。例如:
using namespace N;
int val = Add(1, 2);
int val2 = Sub(1, 2);对广泛使用的库中的名字,利用using指示使得它们可以在未加限定的情况下使用,如使用using namespace std 简化代码对标准库的使用(C++标准库特性定义在命名空间std中)。
在局部作用域如一个函数中,可以安全的使用using指示以方便名字表示,但对全局使用using指示则需要小心,过度使用using指示会导致名字冲突,这样就会和引入命名空间的目的背道而驰。
1.5 命名空间嵌套
语法结构(如分支,循环等)支持嵌套是非常合理的,命名空间也不例外。例如:
void h();
namespace X
{
void f();
namespace Y
{
void g();
void h();
}
}
void X::Y::g()
{
// 定义X::Y::g()
}
void X::f()
{
g(); // 错误:X中无g();
Y::g(); // 正确
}
void h()
{
Y::h(); // 错误 无全局Y
X::Y::h(); // 正确
}另一方面命名空间嵌套满足了实践上的需要,如标准库的chrono(时间库)就使用了命名空间嵌套。
2 I/O 流
标准库iostream提供了格式化字符的输入输出功能。标准库定义了对内置类型的输入输出,并且能够很容易地扩展以支持用户自定义类型的输入输出(涉及类,运算符重载)。本节介绍C++输入输出的基本用法,使用时需要包含
2.1 输出
流插入运算符<<实现输出功能,它作用于ostream类型的对象,cout是标准输出流(控制台),cerr是报告错误的标准流。
使用C++编写第一个程序,输出“hello world!”:
#include
using std::cout;
int main()
{
cout << "hello world!";
cout << "\n";
return 0;
} 结果:

不同类型值的输出可以直观的组合在一起:
#include
using std::cout;
using std::endl; // endl表示换行输出,和cout一样包含在iostream中
int main()
{
int i = 10;
cout << "the value of i is ";
cout << i;
cout << endl;
return 0;
} 输出:

输出多个相关的项,不断重复输出流的名字过于繁琐,好在cout支持连续输出,原因是输出表达式的返回结果是输出流的引用,见5 引用(I/O流涉及类和对象的知识,暂不需要了解)。
因此上个程序的输出语句可以用下面一行代替,结果完全相同。
cout << "the value of i is " << i << endl;2.2 输入
流提取运算符>>实现输入功能,cin是标准输入流(键盘),>>右侧的运算对象决定了输入什么类型的值,以及输入的值保存在哪里。例如:
#include
using namespace std;
int main()
{
int i;
double d;
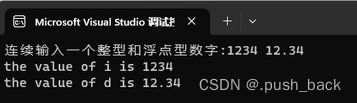
cout << "连续输入一个整型和浮点型数字:";
cin >> i;
cin >> d;
// cin >> i >> d; // cin同样支持连续输入
cout << "the value of i is " << i << endl;
cout << "the value of d is " << d << endl;
return 0;
} 
使用getline()函数可以读取一整行(包括结束时的换行符),需要包含
#include
void hello_line()
{
cout << "Please enter a name\n";
string str; // string类是C++标准库字符串,可以自动扩容空间
getline(cin, str);
cout << "hello," << str << endl;
} 调用hello_line()向C++之父本贾尼(Bjarne Stroustrup)问好:
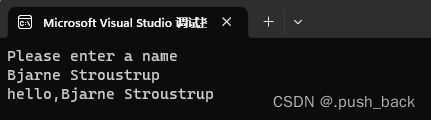
2.3 std的使用惯例
std是C++标准库的命名空间,在日常练习中,直接using namespace std展开即可;在项目开发中代码较多、规模较大,使用using指示容易造成冲突问题,这种情况下,则建议使用显式限定指定来std中的名字和using声明展开常用的库对象和类型。
3 缺省参数(default argument)
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。缺省值作为默认实参,在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
缺省参数分为全缺省参数和半缺省参数(部分缺省),即参数全部给缺省值或部分给缺省值。例如:
1.全缺省
void f(int a = 10, int b = 20, int c = 30) // 全缺省
{
cout << "a = " << a << " ";
cout << "b = " << b << " ";
cout << "c = " << c << " " << endl;
}
int main()
{
f(); // f(10,20,30)
f(1); // f(1,20,30)
f(1, 2); // f(1,2,30)
f(1, 2, 3); // f(1,2,3);
return 0;
}运行结果:
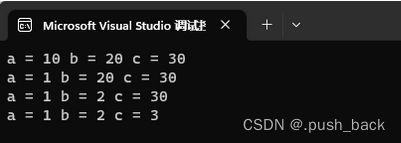
2.半缺省
void g(int a, int b = 10, int c = 20) // 半缺省
{
cout << "a = " << a << " ";
cout << "b = " << b << " ";
cout << "c = " << c << " " << endl;
}
int main()
{
g(1); // g(1,10,20)
g(1, 2); // g(1,2,20)
g(1, 2, 3); // g(1,2,3)
return 0;
}运行结果:
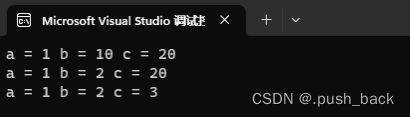
注意:
- 1.由于函数实参从左向右传递,我们只能给参数列表中靠后的位置提供默认值,即半缺省参数只能从右到左依次给出。
- 2.同一作用域下的一系列声明语句中,默认参数不能重定义(缺省值重复或改变不构成函数重载)。
- 2.缺省参数只能在函数声明或定义时给出,不能同时给出,一般在函数声明时给出。
4 函数重载
大多数情况下,我们应该给不同的函数起不同的名字。但如果不同函数是对不同类型执行相同的功能,则给它们起同一个名字是更好的选择。比如加法只有一个名字+,它既可以执行整数的加法,也可以执行浮点数的加法,这就是重载的思想(运算符同样可以重载用于自定义类型的操作)。
4.1 定义重载函数
C++允许同一作用域中的几个函数的名字相同但形参列表不同,这些函数称之为重载函数。形参列表不同指的是参数个数或类型或类型顺序不同。在调用时编译器会根据实参类型自动匹配最合适的重载函数。例如:
// 1.参数类型不同
void Swap(int* x, int* y) // 交换整型
{
int tmp = *x;
*x = *y;
*y = tmp;
}
void Swap(double* x, double* y) // 交换双精度浮点型
{
double tmp = *x;
*x = *y;
*y = tmp;
}
// 2.参数个数不同
void Print(const char* s) // 打印常量字符串
{
cout << s << endl;
}
void Print(int* a, int n) // 打印整型数组
{
for (int i = 0; i < n; i++)
{
cout << a[i] << " ";
}
cout << endl;
}
// 3.参数顺序不同
void Print(int n, int* a)
{
for (int i = 0; i < n; i++)
{
cout << a[i] << " ";
}
cout << endl;
}
int main()
{
int i1 = 10, i2 = 20;
cout << "交换前i1:"<< i1 << " i2:" << i2 << endl;
Swap(&i1, &i2); // 调用Swap(int*,int*)
cout << "交换后i1:" << i1 << " i2:" << i2 << endl;
cout << endl;
double d1 = 10.24, d2 = 3.14;
cout << "交换前d1:" << d1 << " d2:" << d2 << endl;
Swap(&d1, &d2); // 调用Swap(double*,double*)
cout << "交换后d1:" << d1 << " d2:" << d2 << endl;
cout << endl;
const char* str = "abcdefg";
int a[10] = { 1,2,3,4,5,6,7,8,9,10 };
Print(str); // 调用Print(const char*)
Print(a, 10); // 调用Print(int*, int)
Print(10, a); // 调用Print(int, int*)
return 0;
}运行结果:

注意:
1.main()函数不能重载
2.函数仅形参名字不同不构成重载
int Add(int x, int y);
int Add(int y, int x); // 错误:Add(int, int)重定义
3.函数仅返回类型不同不构成重载
void f();
bool f(); // 错误:无法重载仅返回类型区分的函数f()
4.避免调用重载函数二义性
void f(int a);
void f(int a, int b = 1);
f(1); // 错误:调用二义性
4.2 重载与作用域
重载函数应该位于同一作用域内,如全局域,同一命名空间,同一类域。不同的作用域中无法重载函数名。例如:
// 全局::f() 和 N::f()不构成重载
void f(int);
namespace N
{
// ...
void f();
}
// A.g() 和 B.g()不构成重载
class A
{
public:
void g();
};
class B
{
public:
void g();
};如果在内层作用域声明名字,它将隐藏外层的同名实体。例如:
void f(int);
void h();
namespace N
{
// ...
void f();
}
void g()
{
int h = 1; // 隐藏了全局的h
h(); // 错误:h是int值,不是函数
::h(); // 正确:调用全局h();
using N::f; // 隐藏了全局的f
f(); // N::f()
}名字隐藏除非是精心设计,否则将出现意外的后果,特别地,一般不在局部作用域声明函数。
5 引用
本节介绍的引用是左值引用(&),C++11新增了右值引用(&&),本节暂不介绍。通过类型加&加名称定义一个引用名。例如:
int x = 1;
int& refx = x;// refx是x的引用
int& a; // 错误:引用必须初始化5.1 引用即别名
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。一个变量可以有多个引用,引用名也可以被引用,对其中一个引用名操作,实际是作用在引用的变量上。例如:
int i = 123;
int& a = i;
int& b = i;
int& c = a;
// a,b,c都是i的别名
int main()
{
cout << "i:" << &i << endl;
cout << "a:" << &a << endl;
cout << "b:" << &b << endl;
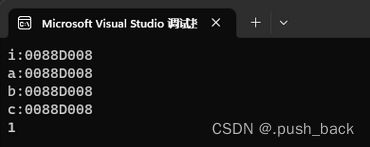
cout << "c:" << &c << endl;
a = 1;
cout << i << endl;
return 0;
}运行结果:i,a,b,c地址相同,改变a的值,i的值改变。
5.2 常引用
我们知道通过别名可以修改它引用的对象,那么如果引用的对象是常量,也就是说该对象不能被修改,则引用的类型前需要加const修饰。例如:
const int a = 10; // const修饰的常量
//int& ra = a; // 错误
const int& ra = a; // 正确
const int& ref = 10; // 引用常量5.3 传引用参数
引用参数和其它引用一样,是对初始化它的对象的别名。通过使用引用形参,函数可以改变实参的值,和传指针相同。例如:
void Swap(int& x, int& y)
{
int tmp = x;
x = y;
y = tmp;
}
int main()
{
int a = 10, b = 20;
Swap(a, b);
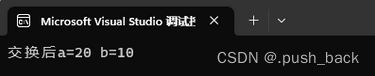
cout << "交换后a=" << a << " b=" << b << endl;
return 0;
}
传引用参数和传指针一样,比传值效率更高。
5.4 引用做返回值
引用可以作为函数返回值,用返回引用的函数初始化引用类型,该引用同样是返回对象的别名。例如:
int a = 0;
int& test(int& x)
{
x = 123;
return x;
}
int b = test(a); // a的引用的值(a的值)赋值给b
int& c = test(a);// 用a的引用为c初始化,c现在是a的别名引用做返回值,需要注意出了函数作用域,该返回值引用的对象仍存在。
5.5 引用和指针的区别
从语法形式上看,引用比指针更简洁,不过在底层引用也是用指针的方式实现的。引用和指针的主要区别如下:
- 引用在定义时必须初始化,指针没有要求,指针可以初始化为空。
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体。
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小。
- 有多级指针,但是没有多级引用。
- 访问实体方式不同,指针存储一个变量地址,需要显式解引用,引用是实体的别名可以直接访问。
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节) 。
6 内联函数(inline)
在函数返回值前用inline关键字修饰的函数称为内联函数,它将告诉编译器在编译时,调用该函数的地方应该“内联地”展开函数体,而非使用正常的函数调用机制。例如:
inline int Add(int a, int b)
{
return a + b;
}
int a = 10, b = 20;
int val = Add(a, b);
// 编译时直接将Add(a, b)展开成 类似(a + b)的形式内联函数避免了函数调用时创建栈帧的开销,一般用于规模较小、频繁使用的函数。不同编译器实现内联的机制可能不同,很多编译器都不支持内联递归函数,同时一个较大的函数很可能不会被当做内联处理。
注意:内联函数被展开后就没有函数地址了,因此声明和定义内联函数不应该分离。
7 auto类型说明符(C++11)
C++11标准引入了auto类型说明符,使用auto定义的变量与为该变量赋值的表达式的类型相同,显然auto定义的变量必须有初始值。例如:
int a = 123;
double b = 12.3;
auto c = a + b; // a和b相加的结果推断c的类型为double
auto并非实际声明类型,只是一种“占位”,编译器在编译时会用变量的实际类型替换auto。简单表达式的类型是显然的,auto似乎没有什么用,但变量类型比较复杂时,使用auto能极大地简化代码。
使用auto声明指针类型时auto和auto*没有区别,用auto声明引用须加&。例如:
int a;
auto p1 = &a;
auto* p2 = &a;
auto& refa = a;使用auto声明多个变量时,这些变量的初始类型需要一致。例如:
auto b = 1, * p = &b; // 正确:d为整型 p为整型地址
auto i = 0, d = 1.0; // 错误:i和d类型不一致注意:
1.auto不能作为函数参数类型
void test(auto x); // 错误
2.auto不能直接声明数组
int a[3] = { 1,2,3 };
auto b = a; // 正确:b为int*auto c[3] = { 1,2,3 };// 错误
8 范围for语句(C++11)
在C++98标准中,使用for循环遍历数组和C语言的方式相同,即控制下标范围依次访问数组元素。例如:
int a[] = { 1,2,3,4,5 };
for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
cout << a[i] << " ";
}遍历一个有范围的序列,人为控制范围是多余的,有时还容易犯错,于是C++11标准引入了范围for,语法形式:
for ( 循环变量:迭代对象 )
语句
:前需要声明一个循环变量,它的类型与迭代对象的元素类型相同,最简单的方法是使用auto类型说明符;迭代对象是数组或一种容器的对象等,它们都支持迭代器(暂时了解)。for循环内的语句可以是一条语句,也可以是语句块{},与正常的for循环使用相同。例如:
int a[] = { 1,2,3,4,5 };
for (auto i : a)
{
cout << i << " ";
}如需要对迭代对象中的元素更改,循环变量必须是引用(或指针)类型,例如:
int a[] = { 1,2,3,4,5 };
for (auto& i : a)
{
i *= 2;
}
// 数组a中的元素都变成原来的2倍9 指针空值nullptr(C++11)
访问未初始化的变量将引发不可预计的后果,良好的编程习惯是在声明一个变量时给它一个合适的初始值。在C和C++98标准中可以使用NULL(须包含头文件 stdlib.h)为暂时没有指向的指针初始化,C++11标准则引入了nullptr关键字替代NULL。
9.1 NULL的缺陷
NULL其实是一个预处理阶段定义的宏常量,在传统的C头文件(stddef.h)中可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif可以看到,NULL可能被定义为字面常量0,也可能被定义为无类型指针(void*)的常量。但是不论采取何种定义,在使用空值的指针时,都不可避免的会遇到一些麻烦,例如:
void f(int)
{
cout << "f(int)" << endl;
}
void f(int*)
{
cout << "f(int*)" << endl;
}
int main()
{
f(0);
f(NULL);
f((int*)NULL);
return 0;
}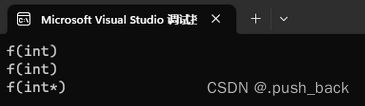
可以发现,我们本想让f(NULL)调用f(int*),结果它调用了f(int),原因是在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void*)0。
9.2 nullptr常量
nullptr是C++11引入的一种特殊类型的字面常量,它可以被强转成任何其他的指针类型。使用nullptr不会出现上面NULL的问题。使用nullptr不需要包含头文件,因为它是一个关键字。现在的C++程序最好使用nullptr,而避免使用NULL。

如果本文内容对你有帮助,可以点赞收藏,感谢支持,期待你的关注。
下篇预告:C++ 类和对象(一)类、访问限定符、this指针