django学习笔记
文章目录
- django简述
-
- django的安装
- 创建项目
- 默认文件介绍
- app的创建和说明
- 快速上手
- 静态文件
- 安装django
- 创建项目
- 创建应用
-
- 解析项目应用文件
- 运行Django
- 关闭服务
- 认识Django
-
- 项目结构
- URL-结构
- 视图函数
- 路由配置
- 请求和响应
- Djano设计模式
- 模板配置和模板层
- url反向解析
- 静态文件
- Django应用及分布式路由
- `模型层即ORM`
- `ORM操作`
- F对象和Q对象
- 聚合查询和原生数据库操作
- admin 后台管理
- 关系映射
- 会话
- Token
- 缓存
- 中间件
- 分页
- 生成csv文件
- 内建用户系统
- 文件上传
- 发送邮件
- DRF(django-restframework)
-
- 前后端分离
- API接口规范
-
- RESTful规范标准
- 幂等性
- 序列化
- Django RestFramework
-
- 介绍
- 安装
- DRF实现基本的API接口
- `反射`
- '多继承'
- CBV源码解析
- APIView源码解析
- DRF的序列化-Serializer
-
- 序列化概述
- 反序列化概述
- Serializer
- ModelSerializer
- 序列化器嵌套
-
- 1
- 2
- 3
- 4自定义模型的属性方法
- 注意点
- HTTP请求和响应(DRF)
-
- 请求
- 响应
- 视图
-
- 普通视图
-
- 2个视图基类
-
- APIView视图基类[基本视图]
- GenericAPIView[通用视图]
- 5个视图扩展类
- 9个视图子类
- 视图集ViewSet
- View
- APIview
- GenericAPIView
- Minin混合类基础封装
- Minin混合类再封装 - 请求方法封装
- ViewSet
- ViewSet结合Minin混合类和genericviewset
- `ModelViewSet`
- 路由组件
- 加路由信息
- DRF组件
-
- 认证 --- Authentication
- 分页 --- Pagination
- 过滤 Filtering
- 自动生成接口文档
- mysql+redis+docker(python+django+uwsgi)
- Ubuntu环境部署项目
-
- 数据库服务环境
- redis环境
- 下载python环境
- 使用docker进行部署
-
- 安装docker
- 执行dockerfile文件
- Uwsgi
-
- 编写uwsgi文件
- 项目部署 -uwsgi
- Nginx
-
- 编写Nginx文件
- 项目部署 -nginx
- uwsgi+nginx排错
- 商城(Store)/ 云笔记项目
-
- 创建项目
- 环境准备
-
- 开发环境和生产环境配置
- 注册DRF
- mysql数据库配置
- redis的数据库配置及集成日志输出器
- 自定义异常捕获(追加数据库的)
- 导入前端文件
- Users
-
- Django自带认证系统用户类
- 跨域问题
- 注册
-
- 短信验证码(aliyun)
- redis的pipeline机制
- Celery
- JWT(json web token)状态保持
- 登录
-
- 发邮箱激活url
- 第三方登录(QQ)
- 个人用户中心
-
- 省市区处理
- 使用redis缓存省市区数据
- 收获地址增删改查
- 商品
-
- SPU && SKU
- FastDFS分布式文件系统
-
- 简介
- 实现原理
- docker使用
- write a custom storage class
-
- Pycharm和浏览器的断点使用
- 注意点
django简述
django的安装
pip install django
创建项目
(1)终端django admin startproject 项目名称(推荐)
(2)pycharm专业版,直接创建,项目的目录不要放在python的安装目录
默认文件介绍
项目名
----manage.py (项目的管理,启动项目,创建app、数据管理)
----项目名文件夹
----init_.py
----asgi.py (接收网络请求)
----settings.py (项目配置)
----urls.py (url和函数的对应关系)
----wsgi.py (接收网络请求)
app的创建和说明
创建:python manage.py startapp app名
app名
----migrations (数据库变更记录)
----init.py
----init.py
----admin.py (django默认提供了admin后台管理)
----apps.py (app启动类)
----models.py (对数据库操作)
----tests.py (单元测试)
----views.py (函数)
快速上手
1.确保app已注册(settings.py)‘app名.apps.App01Config’
2.编写url和视图函数对应关系(urls.py)from appname import views
3.编写试图函数(views.py) from django.shortcuts import render,HttpResponse(request)
4.启动django项目
(1) python manage.py runserver
(2)直接运行
静态文件
1.templates存入html文件
2.static存入图片、css、js、plugins

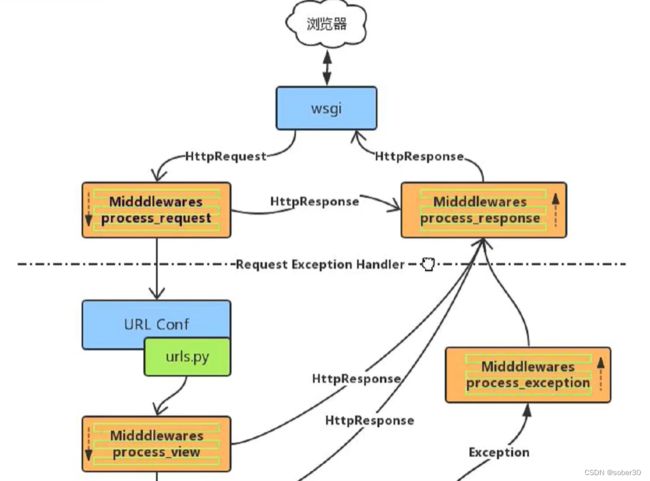
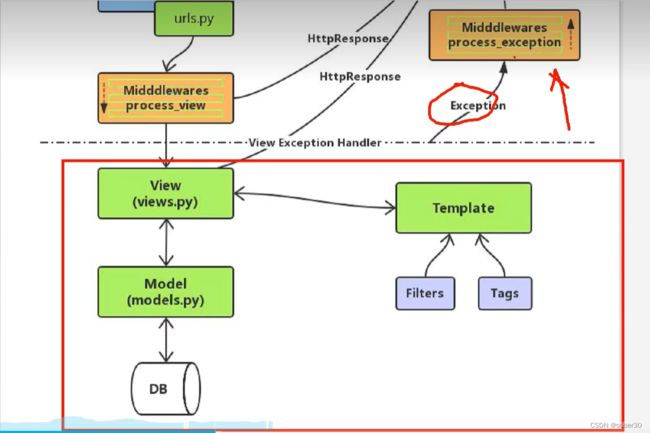
Django官网:https://www.djangoproject.com/
-
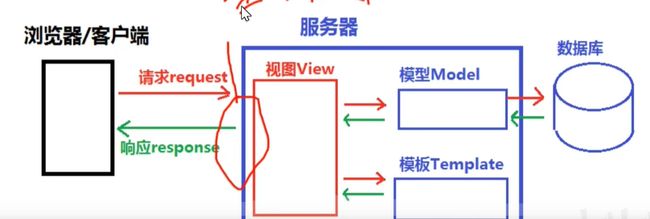
Django 采用了 MVT 的软件设计模式,即模型(Model),视图(View)和模板(Template)。
-
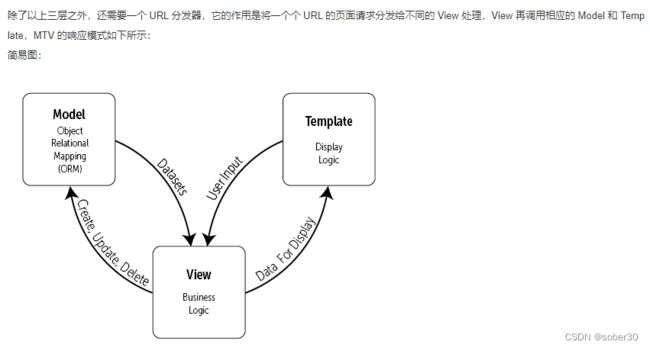
建议图:
-
用户操作流程图:

-
-
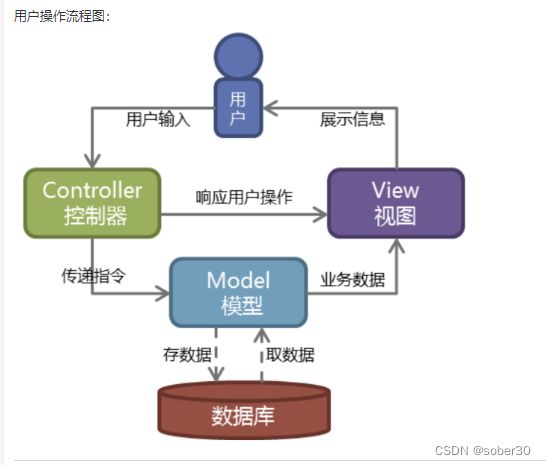
Django 本身基于 MVC 模型,即 Model(模型)+ View(视图)+ Controller(控制器)设计模式
- 优势:
- 低耦合
- 开发快捷
- 部署方便
- 可重用性高
- 维护成本低。。。。。。
-
简易图

-
- 优势:
安装django
pip install django
script:pip.exe\django-admin.exe
[创建django项目中的文件和文件夹]
lib:内置模块:openpyxl\django\time\flask
创建项目
1.打开终端
2.进入某个目录(项目放在哪里)
3.执行命令创建项目
django-admin startproject myproject
#此处myproject为项目名
创建应用
cd 到项目所在目录,即与manage.py同级,输入如下指令来创建应用:
python manage.py startapp appname
#blog为应用名
解析项目应用文件
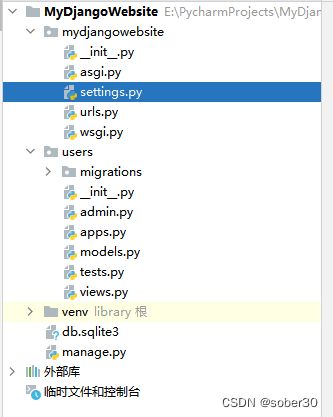
-
manage.py 是一个工具脚本,用作项目管理的。会使用它执行管理操作。
-
里面的 mydjangowebsite/ 目录是python包。 里面包含项目的重要配置文件。这个目录名字不能随便改,因为manage.py 要用到它。
-
mydjangowebsite/settings.py 是 Django 项目的配置文件. 包含了非常重要的配置项,以后我们可能需要修改里面的配置。
-
mydjangowebsite/urls.py 里面存放了 一张表, 声明了前端发过来的各种http请求,分别由哪些函数处理.
-
mydjangowebsite/wsgi.py
要了解这个文件的作用, 我们必须明白wsgi 是什么意思:python 组织制定了 web 服务网关接口(Web Server Gateway Interface) 规范 ,简称wsgi。参考文档 https://www.python.org/dev/peps/pep-3333/
遵循wsgi规范的 web后端系统, 我们可以理解为 由两个部分组成wsgi web server 和 wsgi web application它们通常是运行在一个python进程中的两个模块,或者说两个子系统。wsgi web server(提供高效的http请求处理环境) 接受到前端的http请求后,会调用 wsgi web application (处理 业务逻辑)的接口( 比如函数或者类方法)方法,由wsgi web application 具体处理该请求。然后再把处理结果返回给 wsgi web server, wsgi web server再返回给前端。

运行Django
python manage.py runserver 3344(默认是8000)
python manage.py runserver 0.0.0.0:3344.
ALLOWED_HOSTS = [‘*’]
关闭服务
- 在runserver下按下ctrl+c
sudo lsof -i:5000
sudo kill -9 pid
python manage.py startapp 创建应用
python manage.py migrate 数据库迁移
直接执行python manage.py 可列出所有的Django子命令
认识Django
项目结构
公有配置项 - Django官方提供的基础配置:https://docs.djangoproject.com/en/3.2/ref/settings/
URL-结构
- 定义 - 统一资源定位符Uniform Resource Locator
- protocol协议
- http
- https
- file资源是本地计算机的文件
- hostname(主机名)
- port(端口号)
- path(路由地址)
- query(查询) ?开始
- fragment(信息片断) #开始
- 处理URL请求
- 默认情况下,该文件在项目同名目录下的urls
- Django加载主路由文件中的urlpatterns变量【包含路由的数组】
- 依次匹配urlpatterns中的path,匹配到第一个合适的中断后续匹配
- 匹配成功 - 调用对应的试图函数处理请求,返回响应
- 匹配失败 - 返回404响应
视图函数
语法
from django.http import HttpResponse
def xxx_view(request,[其他参数]):
return HttpResponse对象
# 在url路由模块添加url(url,RegisterView.as_view())
from django.views.generic import View
class RegisterView(View):
def get(self,request):
return render(request,'register.html')
def post(self,request);
return httpresponse('post')
路由配置
from django.urls import path
语法 - path(route,views,name=None)
参数:
1. route:字符串类型,匹配的请求路径
2. views:指定路径所对应的试图处理函数的名称
3. name :为地址起别名,在模板中地址反向解析时使用
- path转换器
语法: <转换器类型:自定义名>
path(‘page/int:page’,views.xxx)
| 转换器类型 | 作用 | 样例 |
|---|---|---|
| str | 匹配除了’/'之外的非空字符串 | username |
| int | 匹配0或任何正整数。返回一个int | 100 |
| slug | 匹配任意由ASCLL字母或数字以及连字符和下划线组成的短标签 | this-is-django |
| path | 匹配非空字段,包括路径分隔符‘/’ | a/c |
-
re_path()
在url的匹配过程中可以使用正则表达式进行精确匹配
语法:- re_path(reg,view,name=xxx)
- 正则表达式为命名分组模式(?Ppattern);匹配提取参数后用关键字传参方式传递给视图函数
XXXX年xx月xx日 re_path(r"^birthday/(?P\d{4})/(?P \d{1,2})/(?P \d{1,2})$",views.birthday_view)
请求和响应
- 请求
path_info: URL字符串
method:字符串,表示HTTP请求方法
get:QueryDict查询字典的对象,包含get请求方式的所有数据
POST:QueryDict查询字典的对象,包含post请求方式的所有数据
FILES:类似于字典的对象,包含所有的上传文件信息
COOKIES:python字典,包含所有的cookie,键和值都为字符串
session:类似于字典对象,表示当前会话
body:字符串,请求体的内容(POST或PUT)
scheme:请求协议(‘http’‘https’)
request.get_full_path():请求的完整路径
request.META:请求中的元数据(消息头)- request.META[‘REMOTE_ADDR’]:客户端IP地址
- 响应
状态码
-200 - 请求成功
-301 - 永久重定向-资源(网页等)被永久转移到其他URL
-302 - 临时重定向
-404 - 请求的资源不存在
-500 - 内部服务器错误
- Django中的响应对象
构造函数格式:
dumps 字典转json字符串
loads json字符串转为dict
content = {
‘msg’: ‘the username already existed’,
‘status’: 205
}
return HttpResponse(json.dumps(content))
HttpResponse(content = 响应体,content_type=响应体类型,status=状态码)
Content_type:
'text/html' (默认,html文件)
‘text/plain’ 纯文本
‘text/css’css 文件
‘text/javascript’js 文件
‘multipart/form-data’ 文件提交
‘application/json’ json传输
‘application/xml’ xml文件
HttpResponseRedirect 301 重定向
HttpResponseNotModified 304
HttpResponseBadRequset 400
HttpResponseNotFound 404
HttpResponseForbidden 403
HttpResponseNotAllowed 405
HttpResponseGone 410
HttpResponseServerError 50
# 直接将dict作为json返回,将content_type直接设为application/json
content = {
'msg': 'invalid method',
}
return JsonResponse(content)
取消csrf验证
禁止settings.py中MIDDLEWARE中的CsrfViewsMiddleWare的中间件
Djano设计模式
- MVC
- M模型层(Model),主要用于对数据层的封装
- V视图层(view),用于向用户展示结果(what+how)
- C控制器(controller,用于处理请求、获取数据、返回结果)
作用:降低模块间的耦合度(解耦)

- MTV - M模型层(model)负责与数据库交互
- T模板层(Template)负责呈现内容到浏览器(how)
- V视图层(view)是核心,负责接收请求、获取数据、返回结果
模板配置和模板层
- BackEND:指定模板的引擎
- DIRS:模板的搜索目录(可以是一个或多个)
- APP_DIRS:是否要在应用中的templates文件夹中搜索模板文件
- OPTIONS:有关模板的选项
from django.shortcuts import render
return render(request,'模板文件名','字典数据')
- 模板的变量
{{变量名}}
{{变量名.index}}
{{变量名.key}}
{{变量名.方法}}
{{函数名}} - 模板标签
-
{% if 条件表达式1 %}
{% elif 条件表达式 %}
{% else %}
{% endif % } -
{% for 变量 in 可迭代对象%}
循环语句
{% empty %}
可迭代对象无数据时填充的语句
{% endfor %}- 内置变量 - forloop
变量 描述 forloop.counter 循环的当前迭代索引(从1开始索引) forloop.counter0 循环的当前迭代索引(从0开始索引) forloop.revcounter counter值得倒序 forloop.revcounter0 recounter值得倒序 forloop.fisrt 如果这是第一次通过循环,则为真 forloop.last 如果这是最后一次循环,则为真 forloop.parentloop 当嵌套循环,parentloop表示外层循环
-
- 模板层-过滤器
官方文档:https://docs.djangoproject.com/en/3.2/ref/templates/builtins/
常用过滤器
| 过滤器 | 说明 |
|---|---|
| lower | 字符串全变为小写 |
| upper | 字符串全变为大写 |
| safe | 默认不对变量内得字符串进行html转义,不变为字符串 |
| add:“n” | 将value值加n |
- 模板层继承
语法:父模板中:- 定义父模板中得快block标签
- 标识出哪些在子模块中时允许被修改得
- block标签:父模板中定义,可以在子模版中覆盖
语法:子模版中: - 继承模板extends标签(写在模板文件得第一行)
例如{% extends ‘base.html’%} - 子模版重写父模板得内容块
{% block block_name %}
子模版块用来覆盖父模板中block_name块得内容
{% endblock %}
{%include block_name %}
url反向解析
用path定义的名称来动态查找或计算出相应的路由
- 在模板中
{% url ‘name’ %}
{% url ‘name’ ‘参数值1’ ‘参数值2’%}
Ex:
{% url ‘page’ ‘400’%}
{% url ‘person’ age=‘18’ name=‘gxn’ %} - 在视图中,调用django的reverse方法
from django.urls import reverse
reverse('别名',args=[],kwargs={})
静态文件
- 静态文件配置-setting.py中
- 配置静态文件的访问路径【该配置默认存在】
通过哪个url地址找静态文件
STATIC_URL = ‘static’ - 配置静态文件的存储路径STATICFILES_DIRS
保存的是静态文件在服务器端的存储位置
#file:setting.py
STATICFILES_DIRS = (
os.path.join(BASE_DIR,"static"),
)
- 模板中访问静态文件
1.加载static{% load static %}
2.使用静态资源-{% static '静态资源路径'%}
Django应用及分布式路由
- 步骤一
用manage.py中的子命令startapp创建应用文件夹
python manage.py startapp music
- 步骤二
在setting.py的INSTALLED_APPS列表中配置安装此应用
INSTALLED_APPS = [
#.....
'user' ,#用户信息模块,
'music',
]
- 分布式路由
Django中,主路由配置文件(urls.py)可以不处理用户具体路由,主路由配置文件的可以做请求的分发(分布式请求处理)。具体请求可以由各自的应用来进行处理
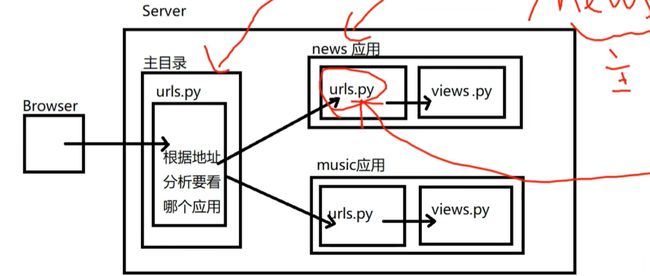
- 主路由中调用include函数
语法:include(‘app名字.url模块名’)
path('music/',include('music.urls'))
- 应用下配置创建urls.py
- 应用下的模板
- 应用下手动创建templates文件夹
- settting.py开启应用模板功能
TEMPLATE配置项中的’APP_DIRS’值为True即可
应用下templates和外层templates都存在时,django得查找模板规则
- 优先查找外层templates目录下的模块
- 按INSTALLED_APPS配置下的应用顺序逐层查找
模型层即ORM
- Django配置mysql
- 安装mysqlclient
- 安装前确认ubuntu是否已安装python3-dev和default-libmysqlclient-dev
1. sudo apt list --install | grep -E 'libmysqlclient-dev | python3-dev' 2. 若命令无输出则需要安装 - sudo apt-get install python3-dev default-libmysqlclient-dev- sudo pip3 install mysqlclient
- 查看是否装上了 sudo pip3 freeze |grep -i ‘mysql’
- 创建数据库
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'django',
'USER': 'root',
'PASSWORD': '123456',
'HOST': '47.97.118.247',
'POST': '3306'
}
}
- 什么是模型
- 模型是一个python类,它是由django.db.models.Model派生出的子类
- 一个模型类代表数据库中的一张数据表
- 模型类中每一个类属性都代表数据库中的一个字段
- 模型是数据交互的接口,是表示和操作数据库的方法和方式
- ORM框架
定义:ORM(Object Relational Mapping)即对象关系映射,它是一种程序技术,它允许你使用类和对象对数据库进行操作,从而避免通过sql语句操作数据库
作用:- 建立模型类和表之间的对应关系,允许我们通过面向对象的方式来操作数据库
- 根据设计的模型类生成数据库中的表格
- 通过简单的配置就可以进行数据库的切换
- 数据库迁移
- 迁移时Django同步您对模型所做更改(添加字段,删除模型等)到您的数据库模式的方式
- 生成迁移文件-执行
python3 manage.py makemigrations将应用下的models.py文件生成一个中间文件,并保存在migrations文件夹中 - 执行迁移脚本程序- 执行
python3 manage.py migrate执行迁移程序实现迁移。将每个应用下的migrations目录中的中间文件同步到数据库中
模型类的创建:
from django.db import models
class 模型类名(models.Model):
字段名 = models.字段类型(字段选项)
-
基础字段及选项
- BooleanField()
数据库类型:tinyint(1)
编程语言中:使用True或False来表示值
在数据库中: 使用1或0表示具体的值 - CharField()
数据库类型:varchar
注意:必须要指定max_length参数值 - DateField()
数据库类型:date
作用:表示日期
参数:- auto_now:每次保存对象时,自动设置该字段为当前时间(取值:True/False) 用update更新数据时时间不会变 使用save会自动更新时间
- auto_now_add :当对象第一次被创建时自动设置当前时间(取值:True/False)
- default:设置当前时间(取值:字符串格式时间如:‘2019-6-1’).
- 以上三个参数只能多选一
- DateTimeField()
数据库类型:datetime(6)
作用:表示日期和时间
参数同DateField - FloatField()
数据库类型:double
编程语言中和数据库中都使用小数表示值。 - DecimalField()
数据库类型:decimal(X,Y)
编程语言中:使用小数表示该列的值
在数据库中:使用小数
参数:- max_digits:位数总数,包括小数点后的位数。该值必须大于等于decimal_places
- decimal_places:小数点后的数字数量
- EmailField()
数据库类型:varchar
编程语言和数据库中使用字符串 - IntegerField()
数据库类型:Int
编程语言和数据库中使用整数 - ImageField()
数据库类型:varchar(100)
作用:在数据库中为了保存图片的路径
编程语言和数据库中使用字符串 - TextField()
数据库类型:longtext
作用:表示不定长的字符数据
- BooleanField()
-
模型类-字段选项
- 字段选项,指定创建的列的额外的信息
允许出现多个字段选项,多个选项之间使用,隔开 - primary_key
如果设置为True,表示该列为主键,如果指定一个字段为主键,则此数据库不会创建id字段 - blank(表单数据)
设置为True时,字段可以为空。设置为False时,字段必须填写的 - null(数据库)
如果设置为True,表示该列值允许为空。
默认为False,如果此选项为False建议加入default选项来设置默认值,
null=True 表示在数据库层面允许为空。 blank=True 表示在前端表单层面允许为空。所以在使用这两个参数时需要注意搭配,不要使blank为True而null为False,这样的结果就是表单提交成功而操作数据库失败,对用户来说不太友好。- default
设置所在列的默认值,如果字段选项null = False建议添加此选项 - db_index
如果设置为True,表示为该列增加索引 - unique
如果设置为True,表示该字段在数据库中的值必须时唯一的 - db_column
指定列的名称,如果不指定的话则采用属性名作为列名 - verbose_name
设置此字段在admin界面上的显示名称
name = models.CharField(max_length=30, unique = True,null = False,db_index = True) - 字段选项,指定创建的列的额外的信息
修改过字段选项【添加或者修改】均要执行makemigrations 和 migrate
- 模型类-Meta类
使用内部Meta类来给模型赋予属性,Meta类下有很多内建的类属性,可对模型类做一些控制
实例:
class Book(models.Model):
class Meta:
db_table = 'book' #可改变当前模型类对应的表名
verbose_name ='图书' #修改admin模型管理中的表名,后面有s,复数
verbose_name_plural = verbose_name #单数
常见问题- 数据库的迁移文件混乱的解决办法
数据库中django_migrations表记录了migrate的’全过程’,项目各应用中的migrate文件应与之对应,否则migrate会报错 - 解决办法
1.删除所有migrations里所有的000?_xxxx.py(init.py除外)- 删除数据库
drop database mywebdb; - 重新创建数据库
create datebase mywebdb default charset… - 重新生成migrations里所有的000?xxxx.py文件
python3 manage.py makemigrations - 重新更新数据库
python manage.py migrate
- 删除数据库
- 数据库的迁移文件混乱的解决办法
ORM操作
- 管理器对象
每个继承自models.Model的模型类,都会有一个objects对象被同样继承下来。这个对象叫管理器对象
数据库的增删改查可以用过模型的管理器对象实现
class MyModel(models.model):
...
MyModel.objects.create(...) #objects是管理器对象
Django Shell
python3 manage.py Shell
- 创建数据
- 方案一:
MyModel.Oobjects.create(属性1=值1,属性2=值2,)
成功:返回创建好的实体对象
失败:抛出异常 - 方案二:
obj = MyModel(属性=值,属性=值)
obj.属性 = 值
obj = save()
- 方案一:
- ORM-查询操作
| 方法 | 说明 |
|---|---|
| all() | 查询全部记录,返回QuerySet查询对象 |
| get() | 查询符合条件的单一记录 |
| filter() | 查询符合条件的多条记录 |
| exclude() | 查询符合条件之外的全部记录 |
| values(列1’,‘列2’) | 查询部分列的数据并返回一个QuerySet,容器里面是字典 |
| values_list(‘列1’,‘列2’) | 查询部分列的数据,返回的是QuerySet,容器里面是元组 |
| order_by(‘-列’,‘列’) | 默认是按照升序排序,降序排序则需要在列前增加’-'表示 |
- 条件查询-方法
- filter(条件)
语法:MyModel.objects.filter(属性1=值1,属性2=值2)
作用:返回包含此条件的全部的数据集
返回值:QuerySet容器对象,内部存放MyModel实例
说明:当多个属性在一起时为“与”关系 - exclude(条件)
作用:返回不包含此条件的全部数据集 - get(条件)
作用:返回满足条件的唯一一条数据
说明:该方法只能返回一条数据,查询结果多余一条数据则抛出异常。
查询结果如果没有数据则抛出Model.DoesNotExist异常
-查询谓词
定义:做更灵活的条件查询时需要使用查询谓词
说明:每一个查询谓词时一个独立的查询功能- __exact:等值匹配
Author.objects.filter(id__exact=1) #等同于select * from author where id=1- __contains:包含指定值
author.objects.filter(name__contaions='w') #等同于 select * from author where name like '%w%'- __startswith:以xxx开始
- __endswith:以XXX结束
- __get:大于指定值
author.objects.filter(age__gt=50) #等同于 select * from author where age>50- __gte:大于等于
- __lt:小于
- __lte:小于等于
- __in:查找数据是否在指定范围内
author.objects.filter(country__in=['china','japan','korea']) # 等同于select * from author where country in ('china','japan','korea')- range:查找数据是否在指定的区间范围内
#查找年龄在某一区间内的所有作者 author.objects.filter(age__range=(35,50)) # 等同于 select ...where author between 35 and 50;
- filter(条件)
- 更新单个数据
- 查
- 通过get()得到要修改的实体对象
- 改
- 通过对象属性的方式修改数据
- 保存
- 通过对象.save()保存数据
- 批量更新数据
直接调用QuerySet的update(属性=值)实现批量修改
# 将id大于3的所有图书价格定为0元
books = Bookes.objects.filter(id__gt=3)
books.update(price=0)
- ORM-单个删除
- 查找查询结果对应的一个数据对象
- 调用这个数据对象的delete()方法实现删除
try:
auth = author.objects.get(id=1)
auth.delete()
except:
print('删除失败')
- ORM-批量删除
- 查找查询结果集中满足条件的全部QuerySet查询集合对象
- 调用查询集合对象的delete()方法实现删除
# 删除全部作者中,年龄大于65的全部信息
auths = author.objects,filter(age__gt=65)
auths.delete()
伪删除- 通常不会轻易在业务里把数据真正删除,取而代之的是做伪删除,即在表中添加一个布尔型字段(is_active),默认是True;执行删除时,将欲删除数据的is_active字段置为False
- 注意:用伪删除时,确保显示数据的地方,均加is_active=True的过滤查询
在模型类中定义,可以直接打印详细信息
def __str__(self):
return '%S%S'%(self.title,self.pub)
查看sql语句
print(a5.query)
F对象和Q对象
-
F对象
一个F对象代表数据库中某条记录的字段的信息
作用:
- 通常是对数据库中的字段值在不获取的情况下进行的操作
- 用于类属性(字段)之间的比较
语法:from django.db.models import F F('列名')示例:
# 更新Book实例中所有的零食价涨10元 Book.objects.all().update(market_price=F('market_price')+10) sql:'UPDATE' bookstore_book SET 'market_price'=('bookstore_book'.'market_price'+10) # 以上做法好于如下代码 books = Book.objects.all() for book in books: book.market_price = book.market_price+10 #topic.like = F('like')+1 book.save()
-
Q对象
在获取查询结果集使用复杂的逻辑或|、逻辑非~等操作时可以借助于Q对象进行操作
如:想找出定价低于20元或清华大学出版社的全部书,可以写成
from django.db.models import Q
Book.objects.filter(Q(price_lt=20) | Q(pub = “清华大学出版社”))
Q(条件1) | Q(条件2) #条件1成立或条件2成立
Q(条件1) & Q(条件2) #条件1和条件2同时成立
Q(条件1) & ~Q(条件2) #条件1成立且条件2不成立
聚合查询和原生数据库操作
-
整表聚合
导入:from django.db.models import *
聚合函数:Sum,Avg,Count,Max,Min
语法:MyModel.objects.aggregate(结果变量名 = 聚合函数(‘列’))
返回结果:结果变量名和值组成的字典{“结果变量名”:值} -
分组聚合
分组聚合时指通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合。
语法:QuerySet.annotate(结果变量名 = 聚合函数(‘列’))
返回值:QuerySet
1 .通过先用查询结果MYModel.objects.values查找查询要分组聚合的列
pub_set = book.objects.values('pub')
- 通过返回结果的QuerySet.annotate方法分组聚合得到分组结果
QuerySet.annotate(名=聚合函数(‘列’))
pub_set.annotate(mycount = Count('pub'))
- 原生数据库操作
查询:使用mymodel.objects.raw()
语法:使用mymodel.objects.raw(sql语句,拼接参数)
返回值:RawQuerySet集合对象【只支持基础操作,比如循环】 - SQL注入
用户通过数据上传, - cursor
- 导入cursor所在的包
from django.db.import connection - 用创建cursor类的构造函数创建cursor对象,再使用cursor对象。
为保证在出现异常时能释放cursor资源,通常使用with语句进行创建操作
from django.db import connection
with connection.cursor() as cur:
cur.execute('执行SQL语句','拼接参数')
admin 后台管理
- admin配置步骤
- 在项目目录创建后台管理账号 - 该账号为管理后台最高权限
python3 manage.py createsuperuser
- 在项目目录创建后台管理账号 - 该账号为管理后台最高权限
- 注册自定义模型类
若要自己定义的模型类也能在/admin后台管理界中显示和管理,需要将自己的类注册到后台管理界面- 注册步骤:
- 在应用app中的admin.py中导入注册要管理的模型models类,如:from .models import Book
- 调用admin.site.register方法进行注册,如:admin.site.register(自定义模型类)
- 注册步骤:
- 模型管理器类
作用:为后台管理界面添加便于操作的新功能
说明:后台管理器类须继承自django.contrib.admin里的ModelAdmin类 - 使用方法:
- 在《应用app》/admin.py里定义模型管理器类
class XXXXXManager(admin.ModelAdmin): .......见下面实例- 绑定注册模型管理器和模型类
from django.contrib import admin from .models import * admin.site.register(YYYY,XXXXManger)#绑定 YYYY模型 类与管理器类XXXXManager#示例: list_display 哪些字段显示在admin的修改表页面中 list_display_links 可以控制list_display中的字段是否应该链接到对象的“更改”页面 list_filter 设置激活admin修改列表页面右侧栏中的过滤器 search_fields 设置启用admin更改页面上的搜索框 list_editable 设置为模型上的字段名称列表,这将允许在更改列表页面上进行编辑 http://docs.djangoproject.com/en/2.2/ref/contrib/admin/
关系映射
在关系型数据库中,通常不会把所有数据都放在同一张表中,不易扩展,常见关系映射
- 一对一
语法:OneToOneField(类名,- - - -on_delete =XXX)- on_delete - 级联删除
- models.CASCADE 级联删除。Django模拟SQL约束ON DELETE CASCADE的行为,并删除包含ForeignKey的对象
删除主表数据时连通一起删除外键表中数据 - models.PROTECT抛出ProtectedError以阻止被引用对象的删除;【等于mysql默认的RESTRICT】
通过抛出ProtectedError异常,来阻止删除主表中被外键应用的数据 - SET_NULL设置ForeignKey null;需要知道null = True
设置为NULL,仅在该字段null=True允许为null时可用,表示外键允许为空 - SET_DEFAULT 将ForeignKey设置为其默认值;必须设置ForeignKey的默认值
设置为默认值,仅在该字段设置了默认值时可用 - SET()
设置为特定值或者调用特定方法 - DO_NOTHING()不做任何操作
不做任何操作,如果数据库前置指明联级性,此选项会抛出IntegrityError异常
- 正向查询:直接通关外键属性查询,则称为正向查询
- 反向查询 - 没有外键属性的一方,可以调用反向属性查询来关联的另一方。
反向关联属性为’实例对象.引用类名(小写)‘,如作家的反向引用’作家对象.wife’。
一对一的反向,用 对象.小写类名 即可,不用加 _set。
当反向引用不存在时,则会触发异常
- models.CASCADE 级联删除。Django模拟SQL约束ON DELETE CASCADE的行为,并删除包含ForeignKey的对象
- on_delete - 级联删除
- 一对多
语法:属性 = models.ForeignKey("一"的模型类,on_delete= xxx)- 正向查询
通过publisher 属性查询即可
book.publisher - 反向查询
pub = Publisher.objects.get(name=‘清华大学出版社’)
books = pub.book_set.all() #通过book_set获取pub1对应的多个Book数据对象
- 正向查询
- 多对多
语法:在关联的两个类中的任意一个类中,增加:属性 = models.ManyToManyField(MyModel)- 正向和反向查询一致
会话
从打开浏览器访问一个网站,到关闭浏览器结束此次访问,称之为一次会话
http协议是无状态的,导致会话状态难以保持
cookies和session就是为了保持会话状态而诞生的两个存储技术
- Cookies
cookies是保存在客户端浏览器上的存储空间
Chrome浏览器可以通过开发者工具的application >> storage >> cookies 查看和操作浏览器端所有的cookies值
火狐浏览器可以通过开发者工具的存储 ->cookie查看- cookies特点
cookies在浏览器上是以键-值对的形式进行存储的,键和值都是以ASCll字符串的形存储(不能是中文字符串)
存储的数据带有生命周期
cookies中的数据是按域存储隔离的,不同的域之间无法访问
cookies的内部的数据会在每次访问此网址时都会携带到服务器端,如果cookies过大会降低响应速度。 - cookies的使用- 存储
response.set_cookie(key,value) HttpResponse.set_cookie(key,value,max_age(最大保存时间,以秒为单位,默认值是会话关闭时自动删除),expires=None) - key :cookie的名字 - value : cookie的值 - max_age: cookie存活时间,秒为单位 - expires:具体过期时间 - 当不指定max_age和expires时,关闭浏览器时此数据失效。- 获取cookies
通过request.COOKIES绑定的字典(dict)获取客户端的cookies数据
request.COOKIES.keys()
value= request.COOKIES.get(‘cookies名’,‘默认值’) - 删除cookies
HttpResponse.delete_cookie(key)
- cookies特点
- Session
session是在服务器上开辟一段空间用于保留浏览器和服务器交互时的重要数据
实现方式:
session机制需要依赖于cookie机制,使用session需要在浏览器客户端启动cookie,且在cookie中存储sessionid
每个客户端都可以在服务器端有一个独立的Session
注意:
不同的请求者之间不会共享这个数据,与请求者一一对应- session初始配置(默认是存在的)
- 向INSTALLED_APPS列表中添加:
INSTALLED_APPS = [ #启用 sessions应用 'django.contrib.sessions', ]- 向MIDDLEWARE列表中添加:
MIDDLEWARE = [ #启动session中间件 'django.contrib.sessions.middleware.SessionMiddleware' ] - Session存储方式
- SESSION_ENGINE='django.contrib.session.backend.db’这个是默认的配置
可以搜索conf查看django默认的系统设置---双击shift,输入global_settings查看配置
- SESSION_ENGINE='django.contrib.session.backend.db’这个是默认的配置
- session的使用
session能够存储如字符串,整数,字典,列表等- 保存session的值到服务器
request.session[‘KEY’] = VALUE - 获取session的值
value = request.session[‘KEY’]
value = request.session.get(‘KEY’,默认值) - 删除session
del request.session[‘KEY’]
- 保存session的值到服务器
- session的使用(续)
- setting.py中相关配置项
- SESSION_COOKIE_AGE
作用:指定sessionid在cookies中的保存时长(默认是2周),如下:例如:SESSION_COOKIE_AGE = 60 *60 *24 * 7 *2
2.SESSION_EXPIRE_AT_BROWSER_CLOSE = True
设置只要浏览器关闭时,session就失效(默认是False)
注意:Django中的session数据存储在数据库中,所以使用session前需要确保已经执行过migrate
- SESSION_COOKIE_AGE
- setting.py中相关配置项
- Django session的问题
- django_session表是单表设计;且该表数据量持续增持【浏览器故意删除session&过期数据未删除】
- 可以每晚执行python3 manage.py clearsessions【该命令可以删除已过期的session数据】
- session初始配置(默认是存在的)
Token
- 优点
- 减轻用户名密码登录认证的服务器压力
- 完全由服务器控制,安全,防止CSRF攻击
缓存
定义:缓存是一类可以更快的读取数据的介质统称,也指其他可以加快数据读取的存储方式。一般用来存储临时数据,常用介质的是读取数据很快的内存
意义:视图渲染有一定成本,数据库的频繁查询过高;所以对于低频变动的页面可以考虑使用缓存技术,减少实际渲染次数;用户拿到响应的时间成本会更低。
- 数据库缓存
CACHES={
'default':{
'BACKEND':'django.core.cache.backends.db.DatabaseCache',
'LOCATION':'my_cache_table',
'TIMEOUT':300, #缓存保存时间单位秒,默认值为300,
'OPTIONS':{
'MAX_ENTRIES':300, #缓存最大数据条数
'CULL_FREQUENCY':2, #缓存条数达到最大值时删除1/x的缓存数据
}
}
}
- 本地内存缓存。。。
- 文件系统缓存。。。
- 浏览器缓存
不会向服务器发送请求,直接从缓存中读取资源- 响应头-expires
定义:缓存过期时间,用来指定资源到期的时间,是服务器的具体的时间点
样例:Expires:Thu,02 Apr 2030 05:14:08 GMT - 响应头- Cache-Control
在HTTP/1.1中,Cache-Control主要用于控制页面缓存。比如Cache-Control:max-age=120代表请求创建时间后的120秒,缓存失效
说明:目前服务器都会带着这两个头同时响应给浏览器,浏览器优先使用Cache-Control
- 响应头-expires
中间件
-
定义;
- 中间件是Django请求/响应处理的钩子框架。它是一个轻量级的、低级的”插件“系统,用于全局改变Django的输入或输出。
- 中间件以类的形式体现
- 每个中间件组件复杂做一些特定的功能。例如,Djano包含一个中间件组件AuthenticationMiddleware,它使用会话将用户与请求关联起来。
-
自定义中间件
def my_middleware(get_response): print("init中间件初始化") def middleware(request): print("视图处理request之前执行") response = get_response(request) print("视图产生response后执行") return response return middleware -
编写中间件类
- 中间件类须继承自djano.utils.deprecation.MiddlewareMixin类
- 中间件类须实现下列五个方法中的一个或多个:
- process_request(self,request)
执行路由之间之前被调用,在每个请求上调用,返回None或HttpResponse对象 - process_view(self,request,callback,callback_args,callback_kwargs)
调用视图之前被调用,在每个请求上调用,返回None或HttpResponse对象 - process_response(self,request,response)
所有响应返回浏览器被调用,在每个请求上调用,返回None或HttpResponse对象 - process_exception(self,request,exception)
当处理过程中抛出异常时调用,返回一个HttpResponse对象 - process_template_response(self,request,reponse)
在视图函数执行完毕且试图返回的对象中包含render方法时被调用;该方法需要返回实现了render方法的响应对象
注:中间件中的大多数方法在返回None时表示忽略当前操作进行下一项事件,当返回HttpResponse对象时表示此请求结束,直接返回给客户端
- process_request(self,request)
-
注册中间件
新建python文件夹,项目路径下,添加middleware的python文件,且注册在setting中。
中间件的执行顺序:进入试图函数之前(包括),按注册顺序。在试图函数之后,从下向上。犹如栈。 -
CSRF-攻击跨站伪造请求攻击
某些恶意网站上包含链接、表单按钮或者JavaScript,它们会利用登录过的用户在浏览器中的认证信息试图在你的网站上完成某些操作,这就是跨站请求伪造(Cross-Site Request Forgey) -
CSRF防范
- django采用”比对暗号“机制防范攻击
- Cookies中存储暗号1,模板中表单里藏着暗号2,用户只有在本网站下提交数据,暗号2才会随表单提交给服务器,django对比两个暗号,对比成功,则认为i时合法请求,否则是违法请求-403响应码
- 配置步骤
- setting.py中确认MIDDLEWARE中django.middleware.csrf.CsrfViewMiddleware是否打开
- 模板中,form标签下添加如下标签
{% csrf_token%}
- 特殊说明:
如果某个试图不需要django进行csrf保护,可以用装饰器关闭对此视图的检查
样例:from django.views.decorators.csrf import csrf_exempt @csrf_exempt def my_view(request) return HttpResponse("Hello World")
分页
Django提供了Paginator类可以方便的实现分页功能
Paginator类位于’django.core.Paginator’模块中
- Paginator对象
paginator = Paginator(object_list,per_page)- 参数
- object_list 需要分页数据的对象列表
- per_page 每页数据个数
- 返回值:
- Paginator的对象
- Paginator属性
- count:需要分页数据的对象总数
- num_pages:分页后的页面总数
- page_range :从1开始的range对象,用于记录当前面码数
- per_page:每页的数据个数
- paginator方法
paginator对象.page(number)- 参数 number为页码信息(从1开始)
- 返回当前number页对应的页信息
- 如果提供的页码不存在,抛出InvalidPage异常,总的异常基类,包含以下两个异常子类
- PageNotAnlnteger :当前page()传入一个不是整数的值时抛出
- EmptyPage : 当向page()提供一个有效值,但是那个页面上没有任何对象时抛出
- 参数
- page对象
负责具体某一页的数据的管理- 创建对象
paginator对象的page()方法返回page对象
page = paginator.page(页码) - page对象属性
- object_list : 当前页上所有数据对象的列表
- number : 当前页的序号,从1开始
- paginator : 当前page对象相关的paginator对象
- page对象方法
- has_next() : 如果有下一页返回True
- has_previous() : 如果有上一页返回True
- has_other_pages() : 如果有上一页或下一页返回True
- next_page_number():返回下一页的页码,如果下一页不存在,抛出InvalidPage异常
- previous_page_numer(): 返回上一页的页码,如果上一页不存在,抛出InvalidPage异常
- 创建对象
生成csv文件
- python中生csv文件
python提供了内建库 -csv;可直接通过该库操作csv文件
案例:
import csv
with open('eggs.csv','w',newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['a','b','c'])
writer.writerow(['d','e','freeze'])
- csv文件下载
在网站中,实现下载csv,注意如下:- 响应Content-Type类型需要修改为text/CSV.这告诉浏览器该文档时CSV文件,而不是HTML文件
- 响应会获得一个额外的Content-Disposition标头,其中包含CSV文件的名称。它将被浏览器用于开启”另存为…“对话框,response[“Content-Disposition”] = ‘attachment;filename=“mybook.csv”’
内建用户系统
定义:django带有一个用户认证系统。他处理用户长账号、组、权限以及基于cookie的用户会话。用户可以直接使用django自带的用户表
- 基本字段
模型类位置 from django.contrib.auth.models import User
数据库中的auth_user - 创建普通用户 create_user
- 创建超级用户 create_superuser
- 校验密码
from django.contrib.auth import authenticate
user = authenticate(usernma=username,password = password)
正确返回user对象,错误返回None - 修改密码
user.set_password(‘111’) - 登录状态保持
from django.contrib.auth import login
def login_view(request):
判断登录
login(request,user) #存session - 登录状态校验
from django,contrib.auth.decorators import login_required
@login_required
def index_view(request):
# 未登录跳转到setting.LOGIN_URL,在setting中配置
#当前登录用户可通过request.user获取
login_user = request.user
- 登录状态取消
from django.contrib.auth import logout
def logout_view(request):
logout(request) - 内建用户表-扩展字段
- 方案一:通过建立新表,跟内建表做1对1
操作麻烦 - 方案二:继承内建的抽象user模型类
- 1.添加新的饿应用
-
- 定义模型类 继承AbstractUser
-
- setting.py中指明AUTH USER MODEL = ‘应用名.类名’
注意:此操作要在第一次migrate之前进行
- setting.py中指明AUTH USER MODEL = ‘应用名.类名’
- 方案一:通过建立新表,跟内建表做1对1
文件上传
定义:用户可以通过浏览器将图片等文件传至网站
场景:用户上传头像;上传流程性的文档【pdf,txt等】
- 上传规范- 前端【HTML】
文件上传必须为POST提交方式:表单文件上传时必须带有enctype="multipart/form-data"时才会包含文件内容数据。
表单中用到标签上传文件 - 上传规则 -后端[Django]
file = request.FILES[‘xxx’] - 说明:
- 1.FILES的key对应页面中file框的name值
- 2.file绑定文件流对象
- 3.file.name文件名
- 4.file.file文件的字节流数据
- 配置文件的访问路径和存储路径
- 在setting中设置MEDIA相关配置;Django把用户上传的文件,统称为media资源
#file : setting.py MEDIA_URL = '/media/' MEDIA_ROOT = [BASE_DIR,'media']- MEDIA_URL 和 MEDIA_ROOT需要手动绑定
说明:等价于做了MEDIA_URL开头的路由,Django接到该特征请求后去MEDIA_ROOT路径查找资源#主路由中添加路由 from django.conf import settings from django.conf.urls.static import static urlpatterns += static(setting.MEDIA_URL,document_root=settings.MEDIA_ROOT) - 文件写入
- 方案1:传统的open方式,可能会重复命名
- 方案2:表加一个字段,解决重复命令问题
在模型类 picture = models.FileField(upload_to ='picture')
发送邮件
- SMTP
simple mail transfer protocol,简单邮件传输协议(25端口),它是一组用于从源地址到目的地址传输邮件的规范,通过它来控制邮件的中转。属于推送协议 - IMAP
internet mail access protocol,即交互式邮件访问协议,是一个应用层协议(143).用来从本地邮件访问远程服务器上的邮件。属于拉取协议 - POP3
post office protocol 3 的简称,即邮局协议的第三个版本,是TCP/IP协议族中的一员(默认是110),本协议主要用于支持使用客户端远程管理在服务器上的电子邮件。属于拉取协议 - IMAP 和 POP3的区别
- IMAP具备摘要浏览功能,可预览部分摘要,再下载整个邮件;IMAP为双向协议,客户端操作可反馈给服务器
- POP3必须下载全部邮件,无摘要功能;POP3为单向协议,客户端操作无法同步服务器
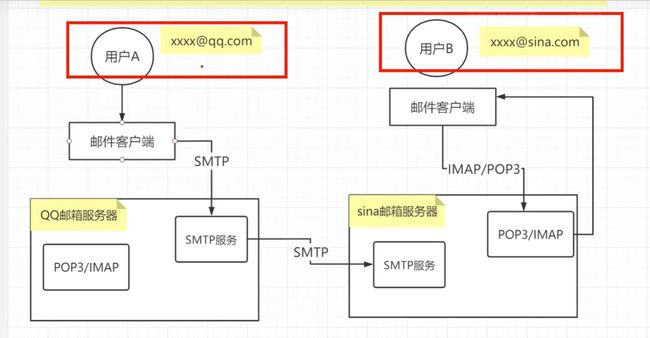
- Django发邮件
- Django中配置邮件功能,主要为SMTP协议,负责发邮件
- 原理:
- 给Django授权一个邮箱
- Django用该邮箱给相应收件人发送邮件
- django.core.mail封装了电子邮件的自动发送SMTP协议
- Django配置
EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend' EMAIL_HOST = 'smtp.qq.com' #腾讯qq邮箱smtp服务器地址 EMAIL_PORT = 25 #SMTP服务的端口号 EMAIL_HOST_USER = '[email protected]' #发送邮件的qq邮箱 EMAIL_HOST_PASSWORD = '****' #在pop3/IMAP的密钥 EMAIL_USE_TLS = False #与SMTP服务通信时,是否启动TLS链接(安全)默认是False
DRF(django-restframework)
前后端分离

API接口规范
-
RPC(Remote Processdure Call)
远程过程调用[远程服务调用],这种接口一般以服务或者过程式代码提供。
基本的数据格式:protobuf(gRPC)、json、xml
缺点:rpc接口多了,对应函数名和参数就多了,前端在请求api接口时就难找,对于年代久远的rpc服务端的代码也容易出现重复的接口 -
restful(Representational State Transfer)
资源状态转换(表征性状态转移)
1.把资源的名称写在url地址
2.http请求动词来说明对该资源进行哪一种操作,post、get、delete、put、patch -
区别:
1.restful是以资源为主的api接口规范,(url不同,url相同的动作区分)
2.rpc则以动作为主的api接口规范,(url全部一样,操作都写在参数中)
RESTful规范标准
1.域名
应该尽量将api部署在专用域名之下。
https://www.example.com/api
https://api.example.com
2.版本(version)
应该将api的版本号放在url中
http://www.example.com/api/v1/foo
http://www.example.com/api/v2/foo
3.路径(Endpoint)
表示api的具体网址,每个网址代表一种资源(resource)
使用名词,不要用动词;名词最好用复数
4.HTTP动词
GET=select
POST=create
PUT = UPDATE
DELETE = DELETE
不常用:patch(更新部分信息)、head(获取资源的元数据)、options(获取可以可以更改的属性)
CURD create、update、read、delete 增删改查,这四个数据库的常用操作
5.过滤信息(Filtering)
完整的url地址格式:
协议://域名(ip):端口/app/?查询字符串(query_string)#锚点
6.状态码(status codes)
1XX 表示当前本次请求还是持续,没结束
2XX 表示当前本次请求成功/完成了
3XX 表示当前本次请求成功,但是服务器进行代理操作/重定向
4xx 表示当前本次请求失败,主要是客户端发生了错误
5xx 表示当前本次请求失败,主要是服务器发生了错误
7.错误处理(Error handling)
{
error: “xxxx”
}
8.返回结果
GET /collections:返回资源对象的列表(数组)
GET /collection/ID: 返回单个资源的对象或字典(json)
POST /collections: 返回新生成的资源对象(json)
PUT /collection/ID: 返回修改后的资源对象(json)
DELETE /collection/ID: 返回一个空文档(空字符串,空字典)
9.超媒体(Hypermedia API)
RESTful API最好做到Hypermedia(即返回结果中提供链接,连向其他API方法),使得用户不查文档,也知道下一步应该做什么。
10.其他
服务器返回的数据格式,应该尽量使用json,避免使用XML。
XML(eXtend Markup Language,可扩展标记语言)是W3C为了替换HTML研发出来的,但是现在很明显失败了。
语法:
1.xml常用场景:配置文件、微信开发、小程序、安卓
2.xml是网页文档,文件以.xml结尾
3.xml文档必须以文档声明开头,所有的xml文档内容都必须写在自定义的根标签内,xml文档有且只有一个根标签。
<根标签>
.....xml文档内容
4.xml里面是由标签组成页面的。标签分单标签和双标签。其中,
单标签写法:<标签名/>
双标签写法: <标签名>
5.xml标签名除了文档声明,其他标签名和属性全部是开发人员自己自定义的
6.标签有0个或多个属性,属性必须有属性值。而且属性值必须使用引号圈起来。
<标签名 属性名="属性值" .../>
<标签名 属性名="属性值" ...>标签内容
json是目前市面上最流行的数据传输格式。javaScript Object Notation js对象表示法
语法:
# 1.json文件以.json结尾,一个json文件中只能保存一个json对象或者一个json数组
# 2.json中的属性类型:
数组 []
对象 {}
数值 整型,浮点型,布尔值
字符串 双引号圈起来的文本内容
null 空
# 3. 数组和对象的成员之间必须以英文逗号隔开,并且最后一个子成员后面不能出现逗号
# 4. json对象只能有属性不能出现方法,而且属性名必须以字符串格式来编写
幂等性
接口实现过程中,会存在幂等性。所谓幂等性是指代客户端发送多次同样请求时,是否对于服务端里面的资源产生不同结果。如果多次请求,服务端结果还是一样,则属于幂等接口,如果多次请求,服务端产生结果是不一样的,则属于非幂等接口。
| 请求方式 | 是否幂等 | 是否安全 |
|---|---|---|
| GET | 幂等 | 安全 |
| POST | 不幂等 | 不安全 |
| PUT/PATCH | 幂等 | 不安全 |
| DELETE | 幂等 | 不安全 |
对于非幂等和不安全的请求需要添加防抖操作(再次验证操作)
序列化
- 序列化:把我们识别的数据转换成指定的格式提供给别人
例如:在django中获取到的数据默认是模型对象,但是模型对象数据无法直接提供给前端或别的平台使用,所以我们需要把数据进行序列化,变成字符串或者json数据,提供给别人。 - 反序列化:把别人提供的数据还原成我们需要的数据
json–> 字典 --> 模型对象,最后保存到数据库中。
Django RestFramework
介绍
Django RestFramework 是一个建立在django基础之上的web应用开发框架,可以快速的开发REST API接口应用。在REST framework中,提供了序列化器Serialzier的定义,可以帮助我们简化序列化与反序列化的过程,不仅如此,还提供丰富的类视图、扩展类、视图集来简化视图的编写工作。REST Framework还提供了认证、权限、过滤、分页、接口文档等功能支持。REST framework还提供了一个调试API接口的Web可视化界面来方便查看测试接口。
- 特点:
1.提供了定义序列化器Serializer的方法,可以快速根据Django ORM或其他库自动序列化。
2.提供了丰富的类视图、Mixin扩展类,简化视图的编写
3.丰富的定制层级:函数试图、类视图、视图集合到自动生成API,满足各种需要
4.多种身份认证和权限认证方式的支持;[JWT]
5.内置了限流系统
6.直观的APIweb界面;【方便我们调试开发api接口】
7.可拓展性,插件丰富
安装
# 必须有django的情况下安装
# conda create -n center python=3.10
# pip install django=4.1 -i 镜像
pip install djangorestframework -i ..
最后,在settings.py 的INSTALLED_APPS加入’rest_framework’,
接下来就可以使用DRF提供的功能进行api接口开发了。在项目中如果使用rest_framework框架实现api接口,主要有以下三个步骤:
1.将请求的数据(如json格式)转换为模型类对象
2.操作数据库
3.将模型类对象转换为响应的数据(如json格式)
DRF实现基本的API接口
1.首先创建一个序列化.py文件StudentModelSerializer用于序列化与反序列化
# 创建序列化器类,回头会在视图中被调用
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = User
# fields = "__all__"
fields = ["id", "realname"]
# model指明该序列化器处理的数据字段从模型类Bookinfo参考生成
# fields指明该序列化器包含模型类中的哪些字段,“all”指明包含所以字段
2.编写视图
# DRFTest
from rest_framework.viewsets import ModelViewSet
from .serializer import *
class UserModelViewSet(ModelViewSet):
query =User.objects.all()
serializer_class = UserModelSerializer
# queryset指明该视图集在查询数据时使用的查询集
# serializer_class 指明该视图在进行序列化或反序列化时使用的序列化器
3.定义路由
# DRFTest
from rest_framework.routers import DefaultRouter
router = DefaultRouter() # 可以处理视图的路由器
router.register("user2",UserModelViewSet,basename="user2") # 向路由器中注册视图集
# urlpatterns += router.urls 将路由器中的所有路由信息追加到django的路由列表中
4.将子应用中的路由文件加载到总路由中
5. 运行测试
python manage.py runserver 0.0.0.0:3344
在浏览器中输入网址127.0.0.1:3344,可以看到DRF提供的API Web浏览页面
反射
字符串反射为一个函数,再去调用函数的方法
class Animal(object):
def __init__(self,func_str)
func=getattr(self.func_str) # self.sleep
func()
def sleep(self):
print("睡觉....")
alex = Animal("sleep")
‘多继承’
class Fly(object):
def fly(self):
print("fly...")
class Animal(object):
def sleep(self):
print("睡觉....")
class Bird(Fly,Animal) #同时继承了Fly类和Animal类的属性和方法
pass
bird= Bird()
bird.fly
bird.sleep
CBV源码解析
# self\cls:谁调用的这个函数或者类,那么self就是谁,self.func()就是从谁开始,一层一层的往父类去找。所以如果在调用的类中,重写与父类一样的函数,那么就会覆盖父类中的同名函数。
# 一旦用户get访问user,访问的 /user =》 view() =》return self.dispatch() => return get()
class Userview(View):
def dispatch(self,request,*args,**kwargs):
print("hello world")
ret = super().dispatch(request,*args,**kwargs)
return ret
def get(self,request):
return HttpResponse("get")
def post(self,request):
return HttpResponse("post")
APIView源码解析
‘contentType:urlencoded \r\n\r\na=1&b=2’ # request.POST
‘contentType:json \r\n\r\n{“a”:1,“b”:2}’ # request.POST不解析json数据
class APIView:
#重写了as_view函数
def as_view(cls):
# 调用了父类的as_view()函数
view = super().as_view()
return view()
# 重写了dispatch方法
def dispatch(self,reqeust,*args,**kwargs):
# 构建新的request对象!!!!!!!!
# post:变为request.data
# get : request.query_params
# django原生: request._request
request= self.initialize_request(request.*args.**kwargs)
self.request = request
# 初始化:认证、权限、限流组件三件套
self.initial(request,*args,**kwargs)
# 分发逻辑与父类一样,只是改变了request结构体
DRF的序列化-Serializer
序列化概述
# DRFtest
# from rest_framework import serializers
# """
# serializers 是drf提供给开发者调用的序列化器模块,里面声明了所有的可用序列化器的基类:
# Serializer 序列化基类,drf中所有的序列化器类都必须继承于Serializer
# ModelSerializer 模型序列化器基类,是序列化器基类的子类,在工作中,除了Serializer基类以外,最常用的序列化器基类
# """
# # 创建序列化器类,回头会在视图中被调用
# class UserModelSerializer(serializers.ModelSerializer):
# 1.转换的字段声明
# 字段 = serializers.字段类型(选项=选项值,)
# 2.如果当前序列化器类继承的是ModelSerializer,则需要声明调用的模型信息
# class Meta:
# model = 模型
# fields = [“字段1”,“字段2”]
# # exlucde = ["pub_date"] # 排除哪些字段,注意fields和exclude不能同时使用
# model指明该序列化器处理的数据字段从模型类参考生成
# fields指明该序列化器包含模型类中的哪些字段,“__all__”指明包含所以字段
# 3.验证代码的对象方法
def validate(self,attrs):# validate是固定的
"""验证所有字段"""
pass
return attrs # 必须返回
def validate_<字段名>(self,data):#方法名的格式必须以validate_<字段名为名称>,否则序列化器不识别!
"""验证单个字段"""
if 不满足条件:
# 在序列化器中,验证失败可以通过抛出异常的方式来告知 is_valid()
raise serializer.ValidationError(detail="...",code="validate_name")
return data #!!!必须返回,不然在最终的验证结果中,就不会出现这个数据了
# 4.模型操作的方法
# def create(self,validated_date): # 添加数据操作,添加数据以后,就自动实现了从字典变成模型对象的过程
# pass
#
# def update(self,instance,validate_data): # 更新数据操作,更新数据以后,就自动实现了从字典变成模型对象的过程
# pass
反序列化概述
-
字段选项
id = serializer.IntegerField(read_only=True) # 在客户端提交数据【反序列化阶段不会要求id字段】
requied=True # 反序列化阶段必填
default=True # 反序列化阶段,客户端没有提交,则默认为True
max_value=100,min_value=0 #必须是0<=age<=100
allow_null=True,allow_blank=True # 允许客户端不填写内容(None),或者值为“”
error_messages: {
‘min_length’: ‘仅允许6-20个字符的密码’,
‘max_length’: ‘仅允许6-20个字符的密码’,
} # 自定义校验出错后的错误信息提示
validators=[check_name] #validators外部验证函数选项,值是一个列表,列表得到成员是函数名,不能是字符串 -
验证
validate_字段名
validate
validator:写在字段选项中
def check_name(data):
“”“外部验证函数”“”
if …:
raise
return data
Serializer
from rest_framework import serializers
from rest_framework response import Respose
# 针对模型涉及序列化器
class UserSerializers(serializers.Serializer):
# name = models.name date = model.pub_date
# 括号中可以写传入数据的校验规则和数据库中对应序列化的字段,也可以将变量的名字直接写的和数据库中的字段名一样,即无需再指定source。
name = serializers.CharField(max_length=32)
price = serializers.IntegerField(required=False) # 可以为空
date = serializers.DateField(source="pub_date")
# 重写父类(ModelSerializer)的create方法,继承的是Serializer需要自己写
def create(self,validated_data):
# 添加数据
new_user = User.objects.create(**self.validated_data)
return new_user # 给self.instance赋值
# 重写父类(ModelSerializer)的update方法,继承的是Serializer需要自己写
def update(self,instance,validated_data):
# 更新逻辑
user= User.objects.filter(pk=id).update(**serializer.validated_date)
updated_book = Book.objects.get(pk=id)
return updated_book # 给self.instance赋值
- urls
from django.urls import path,re_path
from .views import *
urlpatterns=[
# 序列化器
path("sers/user",UserView.as_view()),
re.path("sers/user/(\d+) ",UserDetailView.as_view())
]
ModelSerializer
不需要再自己重写create、update,因为ModelSerializer已经帮我们写了,而且更好
# serializers 是drf提供给开发者调用的序列化器模块,里面声明了所有的可用序列化器的基类:
# Serializer 序列化基类,drf中所有的序列化器类都必须继承于Serializer
# ModelSerializer 模型序列化器基类,是序列化器基类的子类,在工作中,除了Serializer基类以外,最常用的序列化器基类
# # 创建序列化器类,回头会在视图中被调用
# class UserModelSerializer(serializers.ModelSerializer):
# date = serializers.DateField(source="pub_date") #自定义返回字段的key
# nickname = serializers.CharField(read_only=True) # 数据库中没有的,序列化器中有的,只执行序列化。
# class Meta:
# model = User
# # fields = "__all__"
# # exlucde = ["pub_date"] # 排除哪些字段,注意fields和exclude不能同时使用
# fields = ["id", "realname",'password']
#
# model指明该序列化器处理的数据字段从模型类Bookinfo参考生成
# fields指明该序列化器包含模型类中的哪些字段,“all”指明包含所以字段
序列化器嵌套
1
class AchievementModelSerializer(serializers.ModelSerializer):
class Meta:
model =Achievement
fields=["id","course_id"]
class StudentModelSerializer(serializers.ModelSerializer):
s_achievment = AchievementModelSerializer(many=True) # s_achievment是模型中声明的外键字段,非外键字段不能指定序列化器字段releated_name
class Meta:
model = Student
fields = ['id','s_achievment']
2
class AchievementModelSerializer(serializers.ModelSerializer):
course_name = serializer.CharField(source="course.name")
teacher_name = serializer.CharField(source="course.teacher.name")
class Meta:
model =Achievement
fields=["id","course_id","course_name","teacher_name"]
3
class AchievementModelSerializer(serializers.ModelSerializer):
class Meta:
model =Achievement
fields=["id","course_id"]
depth =1 #显示的外键深度1、2、3
4自定义模型的属性方法
class StudentModelSerializer(serializers.ModelSerializer):
class Meta:
model = Student
fields = ['id','achievment']
# models.py
class Student(models.Model):
pass
# 属性方法
@property
def achievement(self):
# return self.s_achievement.all() 不行,模型对象不是json
# return self.s_achievement.values()
return self.s_achievement.values("id","name","...")
注意点
1.使用序列化器的时候一定要注意,序列化器声明了以后,不会自动执行,需要我们在视图中进行调用才可以
2.序列化器无法接收数据,需要我们在视图中实例化序列化器对象时把使用的数据传递过来
3.序列化器的字段声明类似于我们前面使用过的模型
4.开发restful api时,序列化器会帮我们把模型对象转换为字典
5.如果数据从mysql中获取,那么就用modelSerializer,否则就用serializer
HTTP请求和响应(DRF)
请求
- django提供的view视图,在视图方法中传入的request变量是WSGIHttpRequest
WSGIHttpRequest—>父类 —>django.http.request.HttpRequest - rest_framework.request.Request是属于drf单独声明的请求处理对象,与django提供的HttpRequest不是同一个,甚至没有任何的继承关系
# post:变为request.data
# get : request.query_params
# django原生: request._request
响应
REST framework提供了一个响应类Response,使用该类构造响应对象时,响应的具体数据内容会被转换(renderer渲染器)成符合前端需求的类型。
RESR framework提供了Renderer渲染器,用来根据请求中的Accept(接收数据类型声明)来自的转换响应数据对应格式。如果前端请求中未进行声明Accept,则会采用Content-Type方式处理响应数据,我们可以通过配置来修改响应格式。
可以在rest_framework.settings查找所有的drf默认配置项
REST_FRAMEWORK={
'DEFAULT_RENDERER_CLASSES':{#默认响应渲染类
'rest_framework.renderers.JSONRenderer', #json渲染器,返回json数据
'rest_framework.renderers.BrowsableAPIRenderer', # 浏览器API渲染器,返回调试界面。
}
}
- 参数说明
data:
status:状态码,默认是200, # 使用from rest_framework import status
template_name:模板名称,如果使用HTMLRender时需指明;
hearders:用于存放响应头信息
content_type: - 属性
视图
普通视图
2个视图基类
APIView视图基类[基本视图]
- 传入到视图方法中的是REST framework的Request对象,而不是Django的HttpRequest对象;
- 视图方法可以返回的REST framework的Response对象,视图会为响应数据设置(render)符合前端期望要求的格式
- 任何Exception异常都会被捕获到,并且处理成合适的响应信息返回给客户端(django的view是以htm格式显示,apiview会根据客户端的accept进行转换)
- 重新声明了一个新的as_view方法并在dispatch()进行路由分发前,会对请求的客户端进行身份验证、权限检查、流量控制。
增加了类属性
authentication_classes列表或元组,身份认证类
permission_classes列表或元组,权限检查类
throrrle_classes列表或元组,流量控制类
GenericAPIView[通用视图]
只需要重写两个变量:
queryset = Publish.objects.all() # 模型类queryset
serializer_class = PublishSerializers # 序列化器
新增一个表单提交
5个视图扩展类
from rest_framework.mixins import …
CreateModelMixin,
ListModelMixin,
DestroyModelMixin,
RetrieveModelMixin,
UpdateModelMixin
9个视图子类
视图子类是通用视图类和模型扩展类的子类:drf在使用GenericAPIView和Mixins进行组合以后,还提供了视图子类,提供了各种的视图方法调用mixins操作
ListAPIView = GenericAPIView + ListModelMixin
CreateAPIView = GenericAPIView + CreateModelMixin
RetrieveAPIView = GenericAPIView + RetrieveModelMixin
UpdateAPIView = GenericAPIView + UpdateModelMixin
DestroyAPIView = GenericAPIView + DestroyModelMixin
组合视图子类
ListCreateAPIView
RetrieveUpdateAPIView
RetrieveDestroyAPIView
RetrieveUpdateDestroyAPIView
视图集ViewSet
1.路由的合并问题
2.get方法重复问题
ViewSet --->基本视图集 解决APIView中的代码重复问题
GenericViewSet ---> 通过是图集 解决APIView中的代码重复问题同时让代码更加通用
View
class DemoView(View):
def get(self, request):
"""序列化"""
# 1.获取数据集
studentqueryset_list = 模型.objects.all()
# 2.实例化序列化器,得到序列化对象【传递到序列化器的模型对象如果是多个,务必使用many=True】
# 序列化时,传instance,反序列化传data,
# 在构造serilizer对象时,还可通过context参数额外添加数据,通过context参数附加的数据,可以通过serializer对象的context属性获取
serializer = 序列化器(instance=studentqueryset_list,many=True,context={‘request’:request})
serializer = 序列化器(instance=studentqueryset_list, many=True)
# 3. 调用序列化对象的data属性方法获取转换后的数据
data = serializer.data
# 4. 响应数据(django原生的view:safe=False)
def post(self,request):
"""反序列化,采用字段选项来验证数据,并写入数据库"""
1.接收客户端提交的数据
data = json.dumps(reqeust.body)
2.实例化序列化器,获取序列化对象
serializer = 序列化器(data=data)
3.调用序列化器的方法进行数据验证
ret = serializer.is_valid() # serializer.is_valid(raise_exception=True) 错误会自己抛出异常,正常就写return Response(serializer.validated_data)
4.获取结果,如果验证通过,就操作数据库,不通过就返回错误
if ret:
serializer.save() #会根据实例化序列化器的时候,是否传入instance属性来自动调用create或者update方法。传入instance属性,自动调用update方法;没有传instance属性,则调用create。
# serializer.save(ower=request.user) 可以在save中,传递一些不需要验证的数据到模型里面 requset.user是django记录当前登录用户的模型对象
return Response(serializer.validated_data)
else:
return Response(serializer.errors)
def put(self,request):
""反序列化,验证成功后,更新数据入库"
1.根据客户端访问的url地址,获取pk值,查找数据库中的数据
student = filter(id=pk)
2.获取客户端提交的数据
data
3.修改操作中的实例化序列化器对象
serializer = 序列化器(instance=student,data=data)# 只更新name,不需要验证其他的字段,可以设置(instance=student,partial=True)
4.验证数据
serializer.is_valid()
5.入库
serializer.save() # 不是模型类的save()
APIview
from rest_framework.views import APIView
class Userview(APIView):
def get(self,request):
# 获取所有
users = User.objects.all() # queryset
# 构建序列化对象(如果是多个对象,那么many=True)(istance是序列化,data是反序列化)
serializer = UserSerializers(instance=users,many=True)
return Response(serializer.data)
def post(self,request):
# 获取请求数据
# 构建序列化器对象(转化为model模型类queryset)
serializer = UserSerializers(data=request.data)
# 校验数据
if serializer.is_valid(): #返回一个布尔值,所有字段皆通过才返回True。正确的数据会保存在serializer.validated_data,错误的字段key和错误信息会存入serializer.errors
# 数据校验通过,将数据插入到数据库中
# new_user = User.objects.create(**serializer.validated_data)
# 但是这样的话代码有耦合性
serializer.save() # 会调用serializer父类(UserSerializers)重写的create函数,其中返回值就是instance
return Response(serializer.data)
pass
else:
# 校验失败
return Response(serializer.errors)
class UserDetailview(APIView):
def put(self.request,id):
# 获取提交数据
# 构建序列化对象
serializer = UserSerializers(instance=update_book,data=reqeust.data) # 两个都传,因为这样save()的话,instance不为空,那么就会走update方法,为空会走create方法
if serializer.is_valid():
# 更新逻辑
#user= User.objects.filter(pk=id).update(**serializer.#validated_date)
#updated_book = Book.objects.get(pk=id)
#serializer.instance = updated_book # 没有这句话,返回的是旧的serializer的instance
serializer.save()
return Response(serializer.date) # 针对seializer.instance序列化
else:
return Response(serializer.errors)
def delete(self,request,pk):
userdetailquery_list = User.objects.filter(id=pk)
userdetailquery_list.delete()
return Response(status=status.HTTP_204_NO_CONTENT)
GenericAPIView
from rest_framework.generics import GenericAPIView
class PublishSerializers(serializers.ModelSerializer):
class Meta:
model = Publish
fields = "__all__"
class PublishView(GenericAPIView):
# 这两个的变量名不能变,因为GenericAPIView写了关于这两个变量的方法,写其他的表方法,只需要改变这两个变量的值就行了。
## 1.指定查询集
## 2.指定序列化器
queryset = Publish.objects.all() # 模型类queryset
serializer_class = PublishSerializers # 序列化器
def get(self,request):
serializer = self.get_serializer(instance=self.get_queryset(),many=True)
return Response(serializer.data) # 针对serializer.instance
def post(self,request):
# 获取请求数据
# 构建序列化器对象(转化为model模型类queryset)
serializer = self.get_serializer(data=request.data)
# 校验数据
if serializer.is_valid(): #返回一个布尔值,所有字段皆通过才返回True。正确的数据会保存在serializer.validated_data,错误的字段key和错误信息会存入serializer.errors
# 数据校验通过,将数据插入到数据库中
# new_user = User.objects.create(**serializer.validated_data)
# 但是这样的话代码有耦合性
serializer.save() # 会调用serializer父类(UserSerializers)重写的create函数,其中返回值就是instance
return Response(serializer.data)
pass
else:
# 校验失败
return Response(serializer.errors)
# url的有名分组,根据pk分组
re.path(r"^sers/user/(?P\d+)$ ",UserDetailView.as_view())
# re.path(r"^sers/user/(?P\d+)$ ",UserDetailView.as_view())
class PublishDetailview(GenericAPIView):
query = Publish.objects.all() # 模型类queryset
serializer_class = PublishSerializers # 序列化器
lookup_field = "title" # 可以作为get_object()的对象。
def get(self,reqeust,pk):
# self.get_object()在源代码中,等于
# try:
user = User.objects.get(pk=pk)
# except User.DoesNotExist:
return Response(status=status.HTTP_404_NOT_FOUND)
serializer =self.get_serializer(instance=self.get_object(),many=False)
return Response(serializer.data)
def put(self.request,pk):
# 1.根据pk获取模型对象
# 2.获取客户端提交的数据
# 3.反序列化保存
# 4.返回
serializer = self.get_serializer(instance=self.get_object(),data= reqeust.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data)
else:
return Response(serializer.errors)
def delete(self,request,pk):
self.get_object().delete()
return Response()
</code></pre>
<h5>Minin混合类基础封装</h5>
<pre><code>from rest_framework.generics import GenericAPIView
from rest_framework.mixins import ListModelMixin,CreateModelMixin,UPdateModelMixin,DestroyModelMixin
class PublishDetailview(GenericAPIView,listModelMixin,CreateModelMixin):
query = Publish.objects.all() # 模型类queryset
serializer_class = PublishSerializers # 序列化器
def get(self,request):
return self.list(request)
def post(self,request):
return self.create(request)
class PublishDetailview(RetrieveModelMixin,UpdateModelMixin,DestroyModelMixin,GenericAPIView):
query = Publish.objects.all() # 模型类queryset
serializer_class = PublishSerializers # 序列化器
def get(self,request,pk)
return self.retrieve(request,pk)
def put(self,request,pk)
return self.update(request,pk)
def delete(self,request,pk)
return self.destroy(request,pk)
</code></pre>
<h5>Minin混合类再封装 - 请求方法封装</h5>
<pre><code>class PublishDetailview(ListCreateAPIView):
queryset = Publish.objects.all() # 模型类queryset
serializer_class = PublishSerializers # 序列化器
# RetriveUpdateAPIView代表检索、更新,
# RetriveUpdateDestroyAPIView代表检索、更新、删除
class PublishDetailview(RetrieveUpdateAPIView):
queryset = Publish.objects.all() # 模型类queryset
serializer_class = PublishSerializers # 序列化器
</code></pre>
<h5>ViewSet</h5>
<pre><code>path("sers/publish",PublishView.as_view({"get":"get_all","post":"add"})),
re_path("sers/publish/(?<pk>\d+)"),PublishView.as_view({"get":"get_one"})
</code></pre>
<pre><code>class PublishView(ViewSet):
def get_all(self,request):
pass
def add(self,request):
pass
def get_one(self,request,pk):
pass
def update(self,request,pk):
pass
def delete(self,request,pk):
pass
</code></pre>
<h5>ViewSet结合Minin混合类和genericviewset</h5>
<pre><code>path("sers/publish",PublishView.as_view({"get":"list","post":"create"})),
re_path("sers/publish/(?<pk>\d+)"),PublishView.as_view({"get":"retrieve",""....})
</code></pre>
<pre><code>class PublishView(genericviewset、listmodelmixin,createmodelmixin........):
queryset = Publish.objects.all() # 模型类queryset
serializer_class = PublishSerializers # 序列化器
</code></pre>
<h5><code>ModelViewSet</code></h5>
<pre><code># from rest_framework.viewsets import ReadOnlyModelViewSet
#ReadOnlyModelViewSet
class UserModelViewSet(ModelViewSet):
queryset = User.objects.all()
serializer_class = UserModelSerializer
</code></pre>
<h5>路由组件</h5>
<pre><code>注意:基于视图类使用的!!
### 这样等于上面写的url路由
# from rest_framework.routers import DefaultRouter
# router = DefaultRouter() # 可以处理视图的路由器
# SimpleRouter()少一个 api.root 的urlpatterns
# router.register("user2",UserModelViewSet,basename="user2") # 向路由器中注册视图集
# urlpatterns += router.urls 将路由器中的所有路由信息追加到django的路由列表中
</code></pre>
<h5>加路由信息</h5>
<p>在视图集中附加action的声明:<br> 在视图集中,如果想要让Router自动帮助我们为自定义的动作生成路由信息,需要使用rest_framework.decorators.action 装饰器。<br> 以action装饰器装饰的方法名会作为action动作名,与list、retrieve等同。<br> action装饰器可以接收两个参数:</p>
<ul>
<li>methods:声明该action对应的请求方式,列表传递</li>
<li>detail:声明该action的路径是否与单一资源对应<br> 路由前缀//action方法名/
<ul>
<li>True表示路径格式是xxx//action方法名</li>
<li>False表示路径格式是xxx/action方法名</li>
</ul> </li>
<li>url_path:声明该action的路由尾缀</li>
</ul>
<pre><code># 路由对象给视图集生成路由信息时,只会生成5个基本api接口,这主要时router只识别5个混入类的原因。
# 而针对我们开发者自定义的视图方法,路由对象不会自动生成路由信息
# 所以下面这个login,如果希望被外界访问到,则必须通过action装饰器告诉路由对象要给她生成一个路由信息。
@action(methods=["get","post"],detail=False,url_path="login")
# methods,列表,指定允许哪些http请求方法可以访问当前视图方法
# detail ,bool值,告诉路由对象在生成路由信息时,是否要自动生成pk值,True表示需要,False表示不需要
# url_path, 字符串,访问视图的url地址,如果不设置,则默认采用方法名作为访问后缀
def login(self.request):
"""登录视图"""
return Response(xxx)
</code></pre>
<h4>DRF组件</h4>
<p>认证权限和限流在dispatch之前完成</p>
<pre><code># 在视图类中配置的是局部优先的 1
# 在settings中配置的是全局的 2
# 不配置是默认的 3
</code></pre>
<h5>认证 — Authentication</h5>
<h5>分页 — Pagination</h5>
<pre><code>只对genericapiview及其继承的子类有作用,apiview需要自己写
</code></pre>
<ul>
<li>全局配置</li>
</ul>
<pre><code>REST_FRAMEWORK={
'DEFAULT_PAGINATION_CLASS':'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE':8 # 每页数目
}
</code></pre>
<ul>
<li>视图局部设置</li>
</ul>
<pre><code>class SetPagination(PageNumberPagination)
page_size = 2 # 默认每页显示多少条数据
max_page_size = 5 # 前端在控制每页显示多少条时,最多不超过5
# page_query_param = 'page' # 前端在查询字符串的关键字,指定显示第几页,默认是page
page_size_query_param ='page_size' # 前端在查询字符串关键字名字,是用来控制每页显示多少条
class BookView(ModeiViewSet):
# 指定分页类
# pagination_class = None 关闭分页功能
pagination_class = SetPagination
</code></pre>
<h4>过滤 Filtering</h4>
<pre><code># 下载
pip install django-filter
# 配置文件中增加过滤后端的设置
INSTALLED_APPS=[
...,
'django_filters', # 需要注册应用
]
## 指定过滤后端
REST_FRAMEWORK= {
'DEFAULT_FILTER_BACKENDS':['django_filters.rest_framework.DjangoFilterBackend',]
}
# 在视图中添加filter_fields属性,指定可以过滤的字段
class BookView(ModeiViewSet):
# 过滤
filterset_fields=('pk','name')
</code></pre>
<h4>自动生成接口文档</h4>
<p>pip install coreapi</p>
<pre><code># 指定用于支持coreapi的Schema
'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.coreapi.AutoSchema',
</code></pre>
<pre><code>from rest_framework.documentation import include_docs_urls
url(r'^docs/',include_docs_urls(title="API文档"))
</code></pre>
<h2>mysql+redis+docker(python+django+uwsgi)</h2>
<pre><code># 建立 python3.7 环境
FROM python:3.10.1
# 镜像作者sobermh
MAINTAINER sobermh
# 设置容器内工作目录
WORKDIR /home
# 将项目文件拷贝到工作目录下(拷贝的主机内容,最好是相对路径,绝对路径会有报错 )
COPY ./djangoProject /home/djangoProject
# 安装项目所包含的库
# pip install upgrade
RUN cd /home/djangoProject \
&& pip install --upgrade pip \
&& pip freeze >requirement.txt \
&& pip install -r requirement.txt
# 在容器内安装django
# RUN pip install Django==4.0.4 -i https://pypi.douban.com/simple/
# 在容器内安装uwsgi
RUN pip install uwsgi -i https://pypi.douban.com/simple/
#对外暴露端口
EXPOSE 80 8080 8000 5000
# #用uwsgi运行django项目(这里运行的进程不要以后台运行比如nohup,uwsgi -d等)
# #为什么不要用后台方式运行? 因为后台运行方式启动,容器会认为服务没起来,从而导致容器停止
# ENTRYPOINT uwsgi /home/djangoProject/uwsgi.ini
# docker build -f ./dockerfile -t python:1.0 .
# docker run --name 容器name -d 镜像name
[uwsgi]
# 使用Nginx连接时使用,Django程序所在服务器地址(docker + nginx uwsgi_pass 127.0.0.1:8000; include uwsgi_params; 只能通过nginx转发才能访问)
#socket=0.0.0.0:8000
# 直接做web服务器使用,Django程序所在服务器地址(proxy_pass http://127.0.0.1:8000;nginx转发端口和直接宿主机ip端口都可以访问)
http=0:5000
# 项目目录,manage.py 同级目录
chdir=/home/djangoProject
# 项目中wsgi.py文件的目录,相对于项目目录
wsgi-file=/home/djangoProject/djangoProject/wsgi.py
# 进程数
processes=2
# 线程数
threads=2
# uwsgi服务器的角色
master=True
# 存放进程编号的文件
pidfile=uwsgi.pid
# 日志文件
daemonize=uwsgi.log
# 指定依赖的虚拟环境
#virtualenv=/home/python/Python-3.8.6/bin/crm_test/
# 静态文件,先执行python manage.py collectstatic ,setting中指定静态文件STATIC_ROOT=os.path.join(BASE_DIR, 'static')
#static-map=/static=/home/python/crm_django/crm_management/static
#uwsgi --ini uwsgi.ini 启动uwsgi
#uwsgi --stop uwsgi.pid 关闭uwsgi 若报错,执行ps -ef|grep uwsgi 将pid写进uwsgi.pid再执行
#uwsgi --reload uwsgi.pid 重启uwsgi 若报错,执行ps -ef|grep uwsgi 将pid写进uwsgi.pid再执行,注意只有开启uwsgi才能重启
</code></pre>
<h2>Ubuntu环境部署项目</h2>
<h3>数据库服务环境</h3>
<ol>
<li><code>单独放在服务器上</code></li>
<li><code>和django项目放在一个docker容器中,需要把文件挂载出来,因为docker关闭,文件就丢失了</code></li>
<li><code>单独放在一个docker容器中,需要配置网络,才可以让另一个容器访问到,且文件最好挂载出来</code></li>
</ol>
<p>一.进入mysql官网进行mysql服务器的下载<br> 二.使用压缩包进行安装</p>
<pre><code>1.wget 压缩包下载位置(或传入压缩包)
2.解压:tar -zxvf 压缩包 -C /usr/local/
3.重命名:mv /usr/local/解压后的名字 /usr/local/mysql
</code></pre>
<p><code>登录mysql并开启远程连接</code>:见csdn博客</p>
<h3>redis环境</h3>
<ol>
<li>进入redis官网下载redis环境,最好与django项目放在一起</li>
</ol>
<h3>下载python环境</h3>
<pre><code># 先查看当前python的指向
ls -l /usr/bin | grep python
1.wget python官网的指定版本压缩包的下载地址
$ wget https://www.python.org/ftp/python/3.10.11/Python-3.10.11.tgz
2.解压 tar -zxvf 压缩包 -C /usr/local
sudo tar -zxvf Python-3.10.11.tgz -C /usr/local
3.检查安装依赖:设置编译参数,即输出文件目录:
sudo ./configure --prefix=/usr/local/Python-3.10.11 --enable-optimizations
4.预编译&编译与安装
make && make install
sudo make 、make install、(出现问题就使用:sudo make altinstall)
5.修改pip源
在家目录(~)创建文件夹.pip,然后创建文件pip.conf
~/.pip/pip.conf
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
6.删除之前的python和pip的软链接
# 删除python软链接
$ rm -rf /usr/bin/python
# 删除pip软链接
$ rm -rf /usr/bin/pip
7.添加软链接(快捷访问方式)
ln -s /usr/local/Python-3.10.11/bin/python3.10 /usr/bin/python
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
8.如果没有下载到pip
sudo apt-get install python3-pip
</code></pre>
<h3>使用docker进行部署</h3>
<h4>安装docker</h4>
<p>进入docker官网安装服务器环境进行安装<br> docker images 查看docker镜像</p>
<h4>执行dockerfile文件</h4>
<pre><code># 建立 python3.7 环境
FROM python:3.10.1
# 镜像作者sobermh
MAINTAINER sobermh
# 设置容器内工作目录
WORKDIR /home
# 将项目文件拷贝到工作目录下(拷贝的主机内容,最好是相对路径,绝对路径会有报错 )
COPY ./djangoProject /home/djangoProject
# 安装项目所包含的库
# pip install upgrade
RUN cd /home/djangoProject \
&& pip install --upgrade pip \
&& pip freeze >requirement.txt \
&& pip install -r requirement.txt
# 在容器内安装django
# RUN pip install Django==4.0.4 -i https://pypi.douban.com/simple/
# 在容器内安装uwsgi
RUN pip install uwsgi -i https://pypi.douban.com/simple/
#对外暴露端口
EXPOSE 80 8080 8000 5000
# #用uwsgi运行django项目(这里运行的进程不要以后台运行比如nohup,uwsgi -d等)
# #为什么不要用后台方式运行? 因为后台运行方式启动,容器会认为服务没起来,从而导致容器停止
# ENTRYPOINT uwsgi /home/djangoProject/uwsgi.ini
# docker build -f ./dockerfile -t python:1.0 .
# docker run --name 容器name -d 镜像name
</code></pre>
<h3>Uwsgi</h3>
<h4>编写uwsgi文件</h4>
<p>在项目同级目录下:vim uwsgi.ini</p>
<pre><code>[uwsgi]
# 使用Nginx连接时使用,Django程序所在服务器地址(docker + nginx uwsgi_pass 127.0.0.1:8000; include uwsgi_params; 只能通过nginx转发才能访问)
#socket=0.0.0.0:8000
# 直接做web服务器使用,Django程序所在服务器地址(proxy_pass http://127.0.0.1:8000;nginx转发端口和直接宿主机ip端口都可以访问)
http=0.0.0.0:5000
# 项目目录,manage.py 同级目录
chdir=/home/djangoProject
# 项目中wsgi.py文件的目录,相对于项目目录
wsgi-file=/home/djangoProject/djangoProject/wsgi.py
# 进程数
processes=2
# 线程数
threads=2
# uwsgi服务器的角色
master=True
# 指定socker文件,但是我没用这个也可以启动,所以猜测可能是用nginx启动时才需要吧
# socket = uwsgi.sock
# 存放进程编号的文件
pidfile=uwsgi.pid
# 日志文件
daemonize=uwsgi.log
# 指定依赖的虚拟环境
#virtualenv=/home/python/Python-3.8.6/bin/crm_test/
# 静态文件,先执行python manage.py collectstatic ,setting中指定静态文件STATIC_ROOT=os.path.join(BASE_DIR, 'static')
#static-map=/static=/home/python/crm_django/crm_management/static
#uwsgi --ini uwsgi.ini 启动uwsgi
#uwsgi --stop uwsgi.pid 关闭uwsgi 若报错,执行ps -ef|grep uwsgi 将pid写进uwsgi.pid再执行
#uwsgi --reload uwsgi.pid 重启uwsgi 若报错,执行ps -ef|grep uwsgi 将pid写进uwsgi.pid再执行,注意只有开启uwsgi才能重启
</code></pre>
<h4>项目部署 -uwsgi</h4>
<ul>
<li>生产环境搭建
<ul>
<li>
<ol>
<li>在安装机器上安装和配置同版本的环境【py,数据库】</li>
</ol> </li>
<li>
<ol start="2">
<li>django项目迁移</li>
</ol> </li>
</ul> <pre><code>sudo scp /home/** root@47.77.66.66:/home/XXX
</code></pre>
<ul>
<li>
<ol start="3">
<li>uwsgi代替python3 manage.py runserver</li>
</ol> </li>
<li>
<ol start="4">
<li>配置nginx反向代理服务器</li>
</ol> </li>
<li>
<ol start="5">
<li>用nginx配置静态文件路径,解决静态路径问题</li>
</ol> </li>
</ul> </li>
<li>WSGI定义(<code>先走wsgi再走中间件</code>)<br> Web Server GateWway Interface web服务网关接口,是python应用程序或框架和web服务器之间的一种接口,被广泛使用。<br> 使用python manage.py runserver 通常只在开发和测试环境中使用。完善的项目代码需要在一个高效稳定的环境中运行,这时就是wsgi。<br> <a href="http://img.e-com-net.com/image/info8/3a4f66beddd345efa8f1e4a7f635d745.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/3a4f66beddd345efa8f1e4a7f635d745.jpg" alt="django学习笔记_第16张图片" width="650" height="290" style="border:1px solid black;"></a><br> <a href="http://img.e-com-net.com/image/info8/8bfb4da859a647a0b91e98d2696d3f5c.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/8bfb4da859a647a0b91e98d2696d3f5c.jpg" alt="django学习笔记_第17张图片" width="650" height="305" style="border:1px solid black;"></a></li>
<li>uWSGI(<code>注意大小写</code>)<br> uWSGI是WSGI的一种,它实现http协议 WSGI协议以及uwsgi协议(二进制)<br> uWSGI功能完善,支持协议众多,在python web圈热度极高<br> uWSGI主要以学习配置为主。
<ul>
<li>uWSGIA安装
<ul>
<li>Ubuntu执行sudo pip3 install uwsgi== 2.0.18 -i http://pypi.tuna.tsinghua.edu.cn/simple/</li>
<li>检查是否安装成功:sudo pip3 freeze |grep -i ‘uwsgi’</li>
</ul> </li>
</ul> </li>
<li>配置uWSGI<br> 添加配置文件在 项目同名文件夹/uwsgi.ini<br> 如:mysite/mysite/uwsgi.ini<br> 文件以[uwsgi]开头,有如下配置:
<ul>
<li>套接字方式 IP 地址:端口号【此模式需要ngnix】<br> socket = 127.0.0.1:8000</li>
<li>http通信方式IP地址:端口号<br> http:127.0.0.1:8000</li>
<li>项目当前工作目录<br> chdir = /home/***/myproject</li>
<li>项目中wsgi.py文件的目录,相对于当前工作目录<br> wsgi-file = myproject/wsgi.py</li>
<li>进程个数:<br> process= 4</li>
<li>每个进程的线程个数<br> threads =2</li>
<li>服务的pid记录文件<br> pidfile = uwsgi.pid</li>
<li>服务的日志文件位置(默认为后台启动)<br> daemonize = uwsgi.log</li>
<li>开启主进程管理模式<br> master = true<br> <code>特殊说明:django的setting.py需要关闭DEBUG模式,ALLOWED_HOST改为['网站域名']或['服务监听的ip地址']</code></li>
</ul> </li>
<li>uWSGI的运行管理
<ul>
<li>启动uwsgi<br> cd 到uWSGI配置文件所在目录<br> uwsgi --ini uwsgi.ini</li>
<li>停止uwsgi<br> cd 到uWSGI配置文件所在目录<br> uwsgi --stop uwsgi.pid</li>
</ul> </li>
<li>uWSGI运行说明
<ul>
<li>ps aux | grep 'uwsgi’查看运行进程</li>
<li>启动成功后,进程在后台执行,所有日志均输出在配置文件所在目录的uwsgi.log中</li>
<li>django中代码有任何修改,需要重启uwsgi</li>
</ul> </li>
<li><code>uWSGI常见问题</code>
<ul>
<li>启动失败:端口被占用<br> 原因:有其他进程占用uWSGI启动的端口;解决方案:可执行sudo lsof -i:端口号 查询出具体进程;杀掉进程后,重新启动uWSGI即可。</li>
<li>停止失败:stop无法关闭uWSGI<br> 原因: 重复启动uWSGI,导致pid文件中的进程号失准<br> 解决方案:ps出uWSGI进程,手动kill掉</li>
</ul> </li>
</ul>
<h3>Nginx</h3>
<h4>编写Nginx文件</h4>
<p>正向代理:为了从目标服务器取得内容,客户端向代理服务器发送一个请求,并且指定目标服务器,之后代理向目标服务器转发请求,将获得的内容返回给客户端。正向代理是代理客户端,为客户端收发请求,使真实客户端对服务器不可见。</p>
<p>反向代理:客户端访问代理服务器,代理服务器从提供内容的服务器获取内容,并返回给客户端,这就是反向代理,对客户端完全透明。好处:一个端口,代理多个服务,达到负载均衡的效果。反向代理是代理服务器,为服务器收发请求,使真实服务器对客户端不可见。</p>
<p>负载均衡:将负载较为平均分配到各服务器。<br> 1.先下载nginx<br> /etc/nginx/nginx.conf</p>
<pre><code>
# 需要实现负载均衡时
# 负载均衡的服务器,写在server外面
# upstream ego {
# server 192.168.30.44:3333;
# server 192.168.30.43.:3355;
# }
server{
listen 3355 ;# 监听端口号
server_name 0.0.0.0; # 访问ip
charset utf-8 # nginx编码
# 指定项目路径uwsgi
location / {
include uwsgi_params; # 导入一个nginx模块用来和uwsgi进行通讯
# 指定uwsgi的sock文件,所有动态请求都会直接丢给它
uwsgi_pass unix:/home/uwsgi.sock
uwsgi_read_timeout 30 # 设置连接uwsgi超时时间
# 需要实现负载均衡时
# proxy_pass http://ego
}
# 指定静态文件路径
location /static {
alias /home/static/
}
}
</code></pre>
<h4>项目部署 -nginx</h4>
<p>nginx是轻量级的高性能web服务器,提供了诸如http代理和反向代理、负载均衡等一系列中重要特性。c语言编写,执行效率高</p>
<ul>
<li>nginx作用
<ul>
<li>负载均衡,多台服务器轮流处理请求</li>
<li>方向代理</li>
</ul> </li>
<li>原理
<ul>
<li>客户端请求nginx,再由nginx将请求转发uWSGI运行的<br> <a href="http://img.e-com-net.com/image/info8/a6c0139dc3544b3cb8069ab601ffe3af.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/a6c0139dc3544b3cb8069ab601ffe3af.jpg" alt="django学习笔记_第18张图片" width="650" height="333" style="border:1px solid black;"></a></li>
</ul> </li>
<li>安装
<ul>
<li>sudo apt install nginx</li>
<li>如果下载速度很慢,考虑更换为国内源<pre><code>vim etc/apt/sources.list
更改国内源
sudo apt-get update
</code></pre> </li>
<li>安装完毕后,ubuntu终端中输入ngnix -v显示如下:nginx version :ngnix /1.14.0(ubuntu)</li>
</ul> </li>
<li>配置 - 修改ngnix的配置文件 /etc/nginx/sites-enabled/default;sudo vim 该文件</li>
</ul>
<pre><code>#在server 节点中添加新的location项,指向uwsgi的ip端口。
将try_file $uri $uri/ =404 #####
server {
...
location / {
uwsgi_pass 127.0.0.1:8000; #重定向到127.0.0.1的8000端口
include / etc/nginx/uwsgi_params; #将所有的参数转到uwsgi下
}
...
}
</code></pre>
<ul>
<li>启动/停止
<ul>
<li>sudo /etc/init.d/nginx start | stop |restart | status</li>
<li>sudo service nginx start | stop |restart|status</li>
<li>启动:sudo /etc/init.d/ngnix start</li>
<li>停止: sudo /etc/init.d/nginx stop</li>
<li>重启:sudo /etc/init.d/nginx restart</li>
<li>检查语法是否有问题: sudo nginx -t</li>
<li>注意:nginx配置只要修改,就需要重新启动,否则配置不生效。</li>
</ul> </li>
<li>修改uWSGI配置<br> 说明nginx负责接收请求,并把请求转发给后面的uWSGI此模式下,uWSGI需要以socket模式启动</li>
</ul>
<pre><code>[uwsgi]
# 去掉如下
# http= 127.0.0.1:8000
# 改为
socket =127.0.0.1:8000
</code></pre>
<ul>
<li>验证是否成功:访问80是否成功</li>
</ul>
<h3>uwsgi+nginx排错</h3>
<ul>
<li>看日志
<ul>
<li>nginx日志位置:
<ul>
<li>异常信息 /var/log/nginx/error.log</li>
<li>正常访问信息 /var/log/nginx/access/log</li>
</ul> </li>
<li>uwsgi日志位置
<ul>
<li>项目同名目录下,uwsgi.log</li>
</ul> </li>
</ul> </li>
<li>常见问题
<ul>
<li>502响应<br> 502代表nginx方向代理配置成功,但是对应的uWSGI未启动</li>
<li>404响应
<ul>
<li>路由的确不存在django配置中</li>
<li>nginx配置错误,未禁止掉try_files(不禁止会默认到/var/www/html中去找文件)</li>
</ul> </li>
<li>nginx静态文件配置<br> 1.创建新路径-主要存放Django所有静态文件 如:/home/项目_static/<br> 2.在django settings.py 中添加新配置</li>
</ul> <pre><code>STATIC_ROOT = '/home/项目_static/static'
#注意 此配置路径为存放所有正式环境中需要的静态文件
</code></pre> 3.进入项目,执行python3 manage.py collectstatic 执行该命令后,django将项目所有的静态文件复制到STATIC_ROOT中,包括Django内建的静态文件<br> 4.nginx配置中添加新配置<pre><code># file :/etc/nginx/sites-enabled/default
# 新添加location /static 路由配置,重定向到指定的 第一步创建的路径即可
server{
...
location /static{
#root 第一步创建文件夹的绝对路径,如:
root /home/项目_static;
}
...
}
</code></pre> </li>
<li>邮箱告警<br> 当正式服务器上代码运行有报错时,可将错误追溯信息发至指定的邮箱<br> setting.py中添加</li>
</ul>
<pre><code># 关闭调试模式
DEBUG = False
#错误报告接收方
ADMINS = [('guoxiaonano','XXXX@qq.com'),('dsad','dsad@qq.com')]
#发送错误报告方,默认是root@localhost账户,所以要修改
SERVER_EMAIL = 'email配置中的邮箱'
</code></pre>
<pre><code>- 过滤敏感信息(局部变量)
```
from django.views.decorators.debug import sensitive_variables
@sensitive_variables('user','pw','cc')
def process_info(user):
pw = user.pass_word
cc = dsa
```
说明:
1.局部变量的值会被替换成****
2.多个装饰器时,需要将其放在最顶部
3.若不传参,则过滤所有局部变量
</code></pre>
<h2>商城(Store)/ 云笔记项目</h2>
<h3>创建项目</h3>
<ol>
<li>创建项目</li>
</ol>
<pre><code>django=admin startproject cloud_note
</code></pre>
<pre><code>- 配置常规配置项
- 禁止csrf[post提交403问题]
- 语言、时区
- 数据库配置
</code></pre>
<ol start="2">
<li>创建/注册功能模块</li>
</ol>
<pre><code>python manage.py startapp user
</code></pre>
<ol start="3">
<li>创建数据库</li>
</ol>
<pre><code>create database wx_wcx default charset utf8;
</code></pre>
<ol start="4">
<li>启动服务</li>
</ol>
<pre><code>python manage.py runserver 3344
</code></pre>
<h3>环境准备</h3>
<pre><code>conda create -n store python=3.10
conda activate store
pip install django
django-admin startproject store
python manage.py runserver 0.0.0.0:9999
pip freeze > requirements.txt
pip install -r requirements.txt
</code></pre>
<ul>
<li>新建gitignore文件</li>
</ul>
<pre><code>.idea/
db.sqlite3
#bin/: 忽略当前路径下的bin文件夹,该文件夹下的所有内容都会被忽略,不忽略 bin 文件
#/bin: 忽略根目录下的bin文件
#/*.c: 忽略 cat.c,不忽略 build/cat.c
#debug/*.obj: 忽略 debug/io.obj,不忽略 debug/common/io.obj 和 tools/debug/io.obj
#**/foo: 忽略/foo, a/foo, a/b/foo等
#a/**/b: 忽略a/b, a/x/b, a/x/y/b等
#!/bin/run.sh: 不忽略 bin 目录下的 run.sh 文件
#*.log: 忽略所有 .log 文件
#config.php: 忽略当前路径的 config.php 文件
## 为注释
#*.txt #忽略所有.txt结尾的文件
#!lib.txt #但lib.txt除外
#/temp # 仅忽略项目根目录下的TODO文件,不包括其他目录temp
#build/ # 忽略build/目录下的所有文件
#doc/*.txt # 会忽略doc/noes.txt 但不包括doc/server/arch.txt
</code></pre>
<h4>开发环境和生产环境配置</h4>
<p>由于在开发环境用的是manage.py 启动环境,而生产环境使用的是uwsgi部署之后,使用的是wsgi.py启动环境。两个启动方式的settings的文件相同,所以重新设置启动的settings文件路径</p>
<pre><code>- settings
- dev.py
- prod.py
# 将setting的文件复制到上面上个文件之后,删除原来的setting文件,然后
manage.py中修改为:os.environ.setdefault("DJANGO_SETTINGS_MODULE", "store.settings.dev")
wsgi.py中修改为:os.environ.setdefault("DJANGO_SETTINGS_MODULE", "store.settings.prod")
</code></pre>
<h4>注册DRF</h4>
<pre><code>pip install djangorestframework
# 注册应用
INSTALLED_APPS = [
...
'rest_framework', # DRF]
</code></pre>
<h4>mysql数据库配置</h4>
<pre><code># 连接数据库
mysql -uroot -P
create database store charset =utf8mb4;
# 为本项目创建数据库用户(不使用root账户)
# 创建不成功可能是用户已经存在,(可以使用drop user 'sober'@'%';删除用户)
create user sober identified by '123456';
# 给sober授权所有的store库的权限,且在所有的ip上都可以连接
grant all on store.* to 'sober'@'%';
flush privileges;
</code></pre>
<pre><code>DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'store',
'USER': 'root',
'PASSWORD': '123456',
'HOST': '47.97.118.247',
'POST': '3306'
}
}
# 报错errror:django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb module.
pip install pymysql
# 在store-store-__init__.py中写入
import pymysql
pymysql.install_as_MySQLdb()
# 报错errror:'cryptography' package is required for sha256_password or caching_sha2_password auth methods
pip install cryptography
</code></pre>
<h4>redis的数据库配置及集成日志输出器</h4>
<ul>
<li>redis</li>
</ul>
<pre><code>pip install django-redis
# redis配置
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/0",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 1000},
"password": "" # redis密码
}
},
## session引擎
"session": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/1",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {
"max_connections": 1000,
"encoding": 'utf-8'
},
"password": "" # redis密码
}
},
}
# session设置
# 设置admin用户登录时,登录信息session保存到redis(加上下面两句,才能生效)
SESSION_ENGINE = "django.contrib.sessions.backends.cache"
# 配置生效
SESSION_CACHE_ALIAS = "session"
# REDIS_TIMEOUT = 7 * 24 * 60 * 60
# CUBES_REDIS_TIMEOUT = 60 * 60
# NEVER_REDIS_TIMEOUT = 365 * 24 * 60 * 60
</code></pre>
<ul>
<li>log</li>
</ul>
<pre><code># 配置日志系统
LOGGING = {
'version': 1, # 指明dictConfig的版本
'disable_existing_loggers': False, # 设置已存在的logger不失效
# 'incremental': True, # 默认为False。True:是将配置解释为现有配置的增量。False:配置会覆盖已有默认配置。一般此项不用配置
'filters': {
'require_debug_true': { # django在debug模式下才输出
'()': 'django.utils.log.RequireDebugFalse',
},
},
# 'filters': { # 过滤器:用于提供对日志记录从logger传递到handler的附加控制
# # 'require_debug_true': {
# # '()': 'django.utils.log.RequireDebugTrue',
# # },
'formatters': { # 格式器
'standard': {
'format': '[%(asctime)s][%(levelname)s][%(filename)s:%(lineno)d:%(funcName)s]:%(message)s',
'datefmt': '%Y-%m-%d %H:%M:%S'
},
'simple': {
'format': '[%(asctime)s][%(levelname)s]:%(message)s',
'datefmt': '%Y-%m-%d %H:%M:%S'
# style:'%','{' 或 '$',3选一:
# # '%':默认是这个,使用python的%格式化 , 如: %(levelname)s
# # '{':使用 str.format格式化(django框架使用这个), 如:{levelname}
# # '$':使用类string.Template格式化,如:\$levelname
# # datefmt:日期格式化字符串,为None则使用ISO8601格式化,如:'2010-01-01 08:03:26,870'
# # %(name)s:记录器logger的名称
# # %(levelno)s:日志级别对应的数字
# # %(levelname)s:日志级别名称
# # %(pathname)s:日志记录调用的源文件的完整路径
# # %(filename)s:日志记录调用的源文件名
# # %(module)s:模块名
# # %(lineno)d:日志调用的行数
# # %(funcName)s:函数名
# # %(created)f:日志创建时间,time.time()
# # %(asctime)s:日志创建时间,文本类型
# # %(msecs)d:日志创建时间的毫秒部分
# # %(relativeCreated)d:日志创建时间 - 加载日志模块的时间 的 毫秒数
# # %(thread)d:线程ID
# # %(threadName)s:线程名
# # %(process)d:进程ID
# # %(processName)s:进程名
# # %(message)s:日志消息
}
},
'handlers': { # 处理器
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler',
'formatter': 'simple'
'filters': ['require_debug_true'],
},
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler',
'filename': os.path.join(os.path.dirname(BASE_DIR), 'log/info.log'), # 日志文件的位置
'maxBytes': 1024 * 1024 * 50, # 日志大小50M
'backupCount': 5,
'formatter': 'standard',
'encoding': 'utf-8',
},
# 处理程序类的名称
# # StreamHandler:输出到stream,未指定则使用sys.stderr输出到控制台
# # FileHandler:继承自StreamHandler,输出到文件,默认情况下,文件无限增长
# # 初始化参数:filename,mode ='a',encoding = None,delay = False
# # delay如果为True,那么会延迟到第一次调用emit写入数据时才打开文件
# # RotatingFileHandler:自动按大小切分的log文件(常用)
# # 初始化参数:filename,mode ='a',maxBytes = 0,backupCount = 0,encoding = None,delay = False
# # maxBytes:最大字节数,超过时创建新的日志文件,如果backupCount或maxBytes有一个为0,那么就一直使用一个文件
# # backupCount:最大文件个数,新文件的扩展名是指定的文件后加序号".1"等,譬如:backupCount=5,基础文件名为:app.log,
# # 那么达到指定maxBytes之后,会关闭文件app.log,将app.log重命名为app.log.1,如果app.log.1存在,那么就顺推,
# # 先将 app.log.1重命名为app.log.2,再将现在的app.log命名为app.log.1,最大创建到app.log.5(旧的app.log.5会被删除),
# # 然后重新创建app.log文件进行日志写入,也就是永远只会对app.log文件进行写入。
# # TimedRotatingFileHandler:按时间自动切分的log文件,文件后缀 %Y-%m-%d_%H-%M-%S
# # 初始化参数:filename, when='h', interval=1, backupCount=0, encoding=None, delay=False, utc=False, atTime=None
# # when:时间间隔类型,不区分大小写
# # interval:间隔的数值
# # backupCount: 文件个数
# # encoding:编码
# # delay:True是写入文件时才打开文件,默认False,实例化时即打开文件
# # utc:False则使用当地时间,True则使用UTC时间
# # atTime:必须是datetime.time实例,指定文件第一次切分的时间,when设置为S,M,H,D时,该设置会被忽略
# # SMTPHandler:通过email发送日志记录消息
# # 初始化参数:mailhost, fromaddr, toaddrs, subject, credentials=None, secure=None, timeout=5.0
# # mailhost:发件人邮箱服务器地址(默认25端口)或地址和指定端口的元组,如:('smtp.163.com', 25)
# # fromaddr:发件人邮箱
# # toaddrs:收件人邮箱列表
# # subject:邮件标题
# # credentials:如果邮箱服务器需要登录,则传递(username, password)元组
# # secure:使用TLS加密协议
},
'loggers': { # 记录器
'django': {
'handlers': ['console', 'default'],
'level': 'INFO',
'propagate': True,
},
# # level:指定记录日志的级别,没有配置则处理所有级别的日子
# # propagate:设置该记录器的日志是否传播到父记录器,不设置则是True
# # filters:指定过滤器列表
# # handlers:指定处理器列表
# # 'django.request': { # django记录器的子记录器,处理ERROR级别及以上的日志,propagate设置为 False,
# # # 表明不传播日志给 "django",该logger传递日志到mail_admins控制器
# # 'handlers': ['mail_admins'],
# # 'level': 'ERROR',
# # 'propagate': False,
# # },
},
}
</code></pre>
<h4>自定义异常捕获(追加数据库的)</h4>
<pre><code># 在utils文件夹下新建一个exceptions.py的文件
import logging
from django.db import DatabaseError
from redis.exceptions import RedisError
from rest_framework.response import Response
from rest_framework import status
from rest_framework.views import exception_handler as drf_exception_handler
# 获取在配置文件中定义的logger,用来记录日志
logger = logging.getLogger('django')
def exception_handler(exc,context):
# 调用drf框架原生的异常处理方法pi
response = drf_exception_handler(exc,context)
if response is None:
view = context['view']
if isinstance(exc,DatabaseError) or isinstance(exc,RedisError):
# 数据库异常
logger.error('[%s]%s'%(view,exc))
response = Response({'msg':'服务器内部错误'},status=status.HTTP_507_INSUFFICIENT_STORAGE)
return response
</code></pre>
<pre><code># DRF配置
REST_FRAMEWORK = {
# 异常处理
'EXCEPTION_HANDLER' : 'utils.exceptions.exception_handler'
}
</code></pre>
<h4>导入前端文件</h4>
<pre><code># 下载live-server
npm install -g live-server
# 进入前端html文件夹
cd front_end_pc
# live-server
</code></pre>
<h3>Users</h3>
<pre><code># manage.py同级目录下新建一个apps放子应用
cd apps
python ../manage.py startapp users
</code></pre>
<pre><code># 注册apps
print(sys.path) # 查看导包路径
INSTALLED_APPS = [
....
'apps.users',
]
# 修改apps.users.apps.py 的name = "apps.users"
</code></pre>
<pre><code># 对导包路径进行操作
sys.path.insert(0,os.path.join(BASE_DIR.parent,'apps')) # 向第一个位置插入导包路径,防止过多的递归带来的加载过慢
print(os.path.join(BASE_DIR.parent,'apps'))
print(sys.path)
</code></pre>
<h4>Django自带认证系统用户类</h4>
<pre><code># user的模型
from django.db import models
from django.contrib.auth.models import AbstractUser
# Create your models here.
class User(AbstractUser):
"""自定义用户模型类"""
mobile = models.CharField(max_length=11,unique=True,verbose_name="手机号")
class Meta: #配置数据库表名,及设置配置在admin站点显示的中文名
db_table = 'users_user'
verbose_name = '用户'
verbose_name_plural = verbose_name
</code></pre>
<pre><code>sys.path.insert(0,os.path.join(BASE_DIR.parent,'apps')) # 向第一个位置插入导包路径,防止过多的递归带来的加载过慢
# 修改Django认证系统的用户模型类 应用.模型名
AUTH_USER_MODEL = 'users.User'
# ValueError: Dependency on app with no migrations: users
这个代表已经将Django认证系统的用户模型类修改为自己自定义的user类了
python ..manage.py makemigrations
python ..manage.py migrate
</code></pre>
<h4>跨域问题</h4>
<p>同源 ---- 协议:ip/域名:端口<br> 如:http://127.0.0.1:8080 ----> 请求源 http://127.0.01:8000 跨域 请求方法就是options</p>
<p>跨域是因为<code>浏览器</code>默认遵守<code>同源策略</code>(后端不存在跨域,跨域是浏览器请求,接受不到响应)。</p>
<p>NO “Access-Control-Allow- Origin:*” 使用cors(跨域资源共享)解决办法</p>
<pre><code>pip install django-cors-headers
# 设置settings
INSTALLED_APPS = [
'corsheaders', # 解决跨域
]
MIDDLEWARE = [
"corsheaders.middleware.CorsMiddleware", # 解决跨域,必须放最前面"
]
# 跨域配置
# ORS_ORIGIN_WHITELIST = [ #只有localhost:8000才可以跨域访问
# # 'localhost:8000'
# ]
CORS_ALLOW_CREDENTIALS = True # 运行跨域携带cookie
CORS_ORIGIN_ALLOW_ALL = True # 所有域名都可以跨域访问
</code></pre>
<h4>注册</h4>
<h5>短信验证码(aliyun)</h5>
<p>1.编写路由<br> 2.编写视图函数<br> (1) 连接redis,判断60s内是否已经发过短信了<br> (1) 生成验证码<br> (2) 连接redis,存入验证码<br> (3) 调用aliyun的func发送短信<br> 3.<code>解决用户60s刷新页面,导致的频繁发送短信</code><br> 通过在redis中对手机号存一个标记,过期时间为60秒,在发送短信之前验证,,如果存在该标记,直接返回错误。不存在,则执行下面的代码<br> 4. 创建一个constants.py文件,存放此子应用所有的常量</p>
<h5>redis的pipeline机制</h5>
<ol start="5">
<li><code>使用redis的管道减少redis的操作次数,一般只对写入操作用管道技术,查看操作不用管道</code>(将redis连接操作存入管道中,再一起执行)</li>
</ol>
<pre><code># 创建redis管道
pl = conn.pipeline()
pl.set(mobile, str_sms_code, SMS_CODE_REDIS_EXPIRES)
# 存储一个标记,表示此手机号已发送过短信,有效期为60s
pl.setex('send_flag_%s' % mobile, SMS_CODE_SEND_FLAG_INTERVAL, 1)
# 执行管道
pl.execute()
</code></pre>
<h5>Celery</h5>
<p>类似于消费者生产者模式<br> <a href="http://img.e-com-net.com/image/info8/1ac9d2331c864d6fbf946893db916059.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/1ac9d2331c864d6fbf946893db916059.jpg" alt="django学习笔记_第19张图片" width="650" height="351" style="border:1px solid black;"></a></p>
<p>1.新建python文件夹<br> celery_tasks<br> -sms文件夹 异步任务包<br> -tasks.py (Mandatory name)任务会自动找tasks的文件<br> -config.py celery配置文件(arbitrary name)<br> -main.py celery启动文件(arbitrary name)</p>
<pre><code>## 启动!!!!!!!
# celery -A celery_tasks.main worker -l info
# -A add
# -l 输出日志级别
## windows注意:如果是windos系统需要先安装pip install eventlet ,然后celery -A celery_tasks.main worker -l info -P eventlet
</code></pre>
<h5>JWT(json web token)状态保持</h5>
<p>pip install djangorestframework-jwt<br> <em>但是好像用simple-jwt好一些</em><br> session和cookies不适合前后端分离,且多服务器的系统。(容易收到CSRF攻击,以及session验证不方便)<br> header+payload+signature</p>
<pre><code>echo -n xxxxx | base64 -D
解密base64加密的内容
</code></pre>
<ul>
<li>优点<br> 1.因为json的通用性,所以JWT是支持跨语言的<br> 2.因为有payload,可以存一些业务逻辑所必要的非敏感信息<br> 3.构成简单,字节占用小,便于传输<br> 4.不需要在服务端保存会话信息,易于拓展<br> <code>对于signature中的secret,该私有出现泄露,马上更换,最好半夜的时候换。</code></li>
</ul>
<p><a href="http://img.e-com-net.com/image/info8/71da298fec5f4210897861dc48fda67f.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/71da298fec5f4210897861dc48fda67f.jpg" alt="django学习笔记_第20张图片" width="650" height="374" style="border:1px solid black;"></a></p>
<p>local storage永远都在<br> session storge关闭页面就消失了</p>
<pre><code>localStorage.a = 20 # 存储
localStorage.a # 取值
</code></pre>
<h4>登录</h4>
<p>使用simplejwt进行状态保持<br> https://blog.csdn.net/qq_52385631/article/details/126840331</p>
<h5>发邮箱激活url</h5>
<pre><code>from django.core.mail import send_mail
from djangoProject.settings import EMAIL_HOST_USER
# send_mail的参数分别是 邮件标题,邮件内容,发件箱(settings.py中设置过的那个),收件箱列表(可以发送给多个人),失败静默(若发送失败,报错提示我们)
send_mail(subject,message,from_email,recipient_list,html_message=None)
message:普通邮件正文,普通字符串
html_message 多媒体邮件正文,可以时html字符串
send_mail('authcode', str_email_code, EMAIL_HOST_USER,
[revicename], fail_silently=False)
</code></pre>
<p>1.发送激活邮箱的url(‘http://127.0.0.1:8080/success_verify_email.html?access=’ + access)<br> 2.根据点击url,对access进行解码处理,找到jwt中封装的email和id<br> 3.去数据库查找是否存在该用户,并激活邮箱的状态。</p>
<h5>第三方登录(QQ)</h5>
<p>1.先成为开发者<br> 2.申请appid和appkey<br> 3.获取access token<br> 4.获取到用户的openid</p>
<h4>个人用户中心</h4>
<h5>省市区处理</h5>
<p>全部放在一个表,用自关联外键的方式处理</p>
<pre><code># 直接导入sql文件
mysql -uroot -p123456 store < areas.sql
</code></pre>
<h5>使用redis缓存省市区数据</h5>
<p>用用户查询一次,就将结果保存到redis中,后面的用户直接去redis中找,减少I/O缓存,</p>
<pre><code>pip install drf-extensions
</code></pre>
<p>1.可以使用装饰器</p>
<pre><code>@cache_response(timeout=60*60,cache='default')
如果未指明timeout和cache参数,则会使用配置文件中的默认配置
## DRF扩展
REST_FRAMEWORK_EXTENSIONS = {
# 缓存时间
'DEFAULT_CACHE_RESPONSE_TIMEOUT':60*60,
# 缓存存储
'DEFAULT_USER_CACHE':'default',
}
注意:cache_response装饰器都是装饰在get方法上的,既可以装饰在类试图的get方法上,也可以装饰在REST FRAMEWORK扩展类提供的list或retrieve方法上。且不需要使用method_decorator进行转换
</code></pre>
<p>2.使用drf-extensions提供的扩展类</p>
<pre><code>from rest_framework_extentions.cache.mixins
ListCacheResponseMiXin
#用于缓存返回列表数据的视图,与ListModelMixin扩展类配合使用,实际是为list方法添加了cache_response装饰器
RetrieveCacheResponseMiXin
#用于缓存返回列表数据的视图,与RetrieveModelMixin扩展类配合使用,实际是为retrieve方法添加了cache_response装饰器
CacheResponseMixin
# both上者
</code></pre>
<pre><code># 继承的CacheResponseMixin需要放在最前面
class AreaListView(CacheResponseMixin,ReadOnlyModelViewSet):
pass
</code></pre>
<h5>收获地址增删改查</h5>
<h4>商品</h4>
<h5>SPU && SKU</h5>
<ul>
<li>SPU = Standard Product Unit(标准产品单位)<br> SPU是商品信息聚合的最小单位,是一组可服用、易检索的标准化信息的集合,该集合描述了一个产品的特性。<br> 相当于面向对象中的类</li>
<li>SKU = Stock Keeping Unit(库存量单位)<br> SKU即库存进出计量的单位,可以是以件、盒、托盘为单位,是物理上不可分割的最小存货单元。在使用时,要根据不同业态,不同管理模式来处理。<br> 相当于面向对象中的类的实例对象</li>
</ul>
<h5>FastDFS分布式文件系统</h5>
<h6>简介</h6>
<p>FastDFS是用c语言编写的一款开源的分布式文件系统,FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。</p>
<p>FastDFS架构包括Tracker server 和Storage server,客户端请求Tracker server进行文件上传、下载,通过Tracker server调度最终由Storage server完成文件上传和下载。</p>
<ul>
<li>Tracker Server作用是负载均衡和调度,通过Tracker server在文件上传时可以根据一些策略找到Storage server提供文件上传服务,可以将tracker称为追踪服务器或调度服务器。</li>
<li>Storage server作用是文件存储,客户端上传的文件最终存储在Storage服务器上,Storage server没有实现自己的文件系统而是利用操作系统的文件系统来管理文件。可以将storage称为存储服务器。</li>
</ul>
<h6>实现原理</h6>
<p><a href="http://img.e-com-net.com/image/info8/c8bbf51887ad4cf2833e8cf252ea23da.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/c8bbf51887ad4cf2833e8cf252ea23da.jpg" alt="django学习笔记_第21张图片" width="650" height="383" style="border:1px solid black;"></a></p>
<p><a href="http://img.e-com-net.com/image/info8/82beeae5841742899cbd5d85bb9ed56e.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/82beeae5841742899cbd5d85bb9ed56e.jpg" alt="django学习笔记_第22张图片" width="650" height="365" style="border:1px solid black;"></a></p>
<p><a href="http://img.e-com-net.com/image/info8/13cd3a0a8b264703a2ade971e8347442.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/13cd3a0a8b264703a2ade971e8347442.jpg" alt="django学习笔记_第23张图片" width="650" height="239" style="border:1px solid black;"></a></p>
<h6>docker使用</h6>
<p><a href="http://img.e-com-net.com/image/info8/55b39e2da06244b58159b8326e4b3c58.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/55b39e2da06244b58159b8326e4b3c58.jpg" alt="django学习笔记_第24张图片" width="650" height="281" style="border:1px solid black;"></a></p>
<pre><code># 避免每次命令都输入sudo,可以设置用户权限,注意执行后须重新登录
sudo usermod -a -G docker $USER
</code></pre>
<h5>write a custom storage class</h5>
<h6>Pycharm和浏览器的断点使用</h6>
<h2>注意点</h2>
<p>1.数据库中的charfield在进行order_by时,'100’反而比’22’小。所以需要比较的字段,在数据库最好设置为IntegerField。</p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1708508980575285248"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(学习笔记,django,学习,笔记)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1943993659967991808.htm"
title="系统学习Python——并发模型和异步编程:进程、线程和GIL" target="_blank">系统学习Python——并发模型和异步编程:进程、线程和GIL</a>
<span class="text-muted"></span>
<div>分类目录:《系统学习Python》总目录在文章《并发模型和异步编程:基础知识》我们简单介绍了Python中的进程、线程和协程。本文就着重介绍Python中的进程、线程和GIL的关系。Python解释器的每个实例都是一个进程。使用multiprocessing或concurrent.futures库可以启动额外的Python进程。Python的subprocess库用于启动运行外部程序(不管使用何种</div>
</li>
<li><a href="/article/1943991261279088640.htm"
title="C++ 11 Lambda表达式和min_element()与max_element()的使用_c++ lamda函数 min_element((1)" target="_blank">C++ 11 Lambda表达式和min_element()与max_element()的使用_c++ lamda函数 min_element((1)</a>
<span class="text-muted">2401_84976182</span>
<a class="tag" taget="_blank" href="/search/%E7%A8%8B%E5%BA%8F%E5%91%98/1.htm">程序员</a><a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a><a class="tag" taget="_blank" href="/search/c%2B%2B/1.htm">c++</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a>
<div>既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上CC++开发知识点,真正体系化!由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新如果你需要这些资料,可以戳这里获取#include#include#includeusingnamespacestd;boolcmp(int</div>
</li>
<li><a href="/article/1943991262029869056.htm"
title="C++ 11 Lambda表达式和min_element()与max_element()的使用_c++ lamda函数 min_element(" target="_blank">C++ 11 Lambda表达式和min_element()与max_element()的使用_c++ lamda函数 min_element(</a>
<span class="text-muted"></span>
<div>网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。需要这份系统化的资料的朋友,可以添加戳这里获取一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!intmain(){vectormyvec{3,</div>
</li>
<li><a href="/article/1943989244456398848.htm"
title="冒泡、选择、插入排序:三大基础排序算法深度解析(C语言实现)" target="_blank">冒泡、选择、插入排序:三大基础排序算法深度解析(C语言实现)</a>
<span class="text-muted">xienda</span>
<a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95/1.htm">排序算法</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/1.htm">数据结构</a>
<div>在算法学习道路上,排序算法是每位程序员必须掌握的基石。本文将深入解析冒泡排序、选择排序和插入排序这三种基础排序算法,通过C语言代码实现和对比分析,帮助读者彻底理解它们的差异与应用场景。算法原理与代码实现1.冒泡排序(BubbleSort)工作原理:通过重复比较相邻元素,将较大元素逐步"冒泡"到数组末尾。voidbubbleSort(intarr[],intn){ for(inti=0;iarr[</div>
</li>
<li><a href="/article/1943987101301272576.htm"
title="精通Canvas:15款时钟特效代码实现指南" target="_blank">精通Canvas:15款时钟特效代码实现指南</a>
<span class="text-muted">烟幕缭绕</span>
<div>本文还有配套的精品资源,点击获取简介:HTML5的Canvas是一个用于绘制矢量图形的API,通过JavaScript实现动态效果。本项目集合了15种不同的时钟特效代码,帮助开发者通过学习绘制圆形、线条、时间更新、旋转、颜色样式设置及动画效果等概念,深化对Canvas的理解和应用。项目中的CSS文件负责时钟的样式设定,而JS文件则包含实现各种特效的逻辑,通过不同的函数或类处理时间更新和动画绘制,提</div>
</li>
<li><a href="/article/1943986975048527872.htm"
title="高效批量单词翻译工具的设计与应用" target="_blank">高效批量单词翻译工具的设计与应用</a>
<span class="text-muted"></span>
<div>本文还有配套的精品资源,点击获取简介:在信息技术飞速发展的今天,批量单词翻译工具通过计算机的数据处理能力,大大提高了语言学习和文字处理的效率。用户通过简单输入单词列表到一个文本文件,并运行翻译程序,即可获得翻译结果并保存至指定文件。该工具集成了内置或外部翻译引擎,利用自然语言处理技术实现快速准确的翻译,并可能提供词性识别等附加功能。尽管机器翻译无法完全取代人工校对,但它为用户提供了一种高效的翻译解</div>
</li>
<li><a href="/article/1943985460749594624.htm"
title="FPGA小白到项目实战:Verilog+Vivado全流程通关指南(附光学类岗位技能映射)" target="_blank">FPGA小白到项目实战:Verilog+Vivado全流程通关指南(附光学类岗位技能映射)</a>
<span class="text-muted">阿牛的药铺</span>
<a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95%E7%A7%BB%E6%A4%8D%E9%83%A8%E7%BD%B2/1.htm">算法移植部署</a><a class="tag" taget="_blank" href="/search/fpga%E5%BC%80%E5%8F%91/1.htm">fpga开发</a><a class="tag" taget="_blank" href="/search/verilog/1.htm">verilog</a>
<div>FPGA小白到项目实战:Verilog+Vivado全流程通关指南(附光学类岗位技能映射)引言:为什么这个FPGA入门路线能帮你快速上岗?本文设计了一条**"Verilog语法→工具链操作→光学项目实战→岗位技能对标"的阶梯式学习路径。不同于泛泛而谈的FPGA教程,我们聚焦光学类产品开发**核心能力(时序接口设计、图像处理算法移植、高速接口应用),通过3个递进式项目(从LED闪烁到图像边缘检测),</div>
</li>
<li><a href="/article/1943985461282271232.htm"
title="PyTorch & TensorFlow速成复习:从基础语法到模型部署实战(附FPGA移植衔接)" target="_blank">PyTorch & TensorFlow速成复习:从基础语法到模型部署实战(附FPGA移植衔接)</a>
<span class="text-muted">阿牛的药铺</span>
<a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95%E7%A7%BB%E6%A4%8D%E9%83%A8%E7%BD%B2/1.htm">算法移植部署</a><a class="tag" taget="_blank" href="/search/pytorch/1.htm">pytorch</a><a class="tag" taget="_blank" href="/search/tensorflow/1.htm">tensorflow</a><a class="tag" taget="_blank" href="/search/fpga%E5%BC%80%E5%8F%91/1.htm">fpga开发</a>
<div>PyTorch&TensorFlow速成复习:从基础语法到模型部署实战(附FPGA移植衔接)引言:为什么算法移植工程师必须掌握框架基础?针对光学类产品算法FPGA移植岗位需求(如可见光/红外图像处理),深度学习框架是算法落地的"桥梁"——既要用PyTorch/TensorFlow验证算法可行性,又要将训练好的模型(如CNN、目标检测)转换为FPGA可部署的格式(ONNX、TFLite)。本文采用"</div>
</li>
<li><a href="/article/1943983696184930304.htm"
title="基于链家网的二手房数据采集清洗与可视化分析" target="_blank">基于链家网的二手房数据采集清洗与可视化分析</a>
<span class="text-muted">Mint_Datazzh</span>
<a class="tag" taget="_blank" href="/search/%E9%A1%B9%E7%9B%AE/1.htm">项目</a><a class="tag" taget="_blank" href="/search/selenium/1.htm">selenium</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/1.htm">网络爬虫</a>
<div>个人学习内容笔记,仅供参考。项目链接:https://gitee.com/rongwu651/lianjia原文链接:基于链家网的二手房数据采集清洗与可视化分析–笔墨云烟研究内容该课题的主要目的是通过将二手房网站上的存量与已销售房源,构建一个二手房市场行情情况与房源特点的可视化平台。该平台通过HTML架构和Echarts完成可视化的搭建。因此,该课题的主要研究内容就是如何利用相关技术设计并实现这样</div>
</li>
<li><a href="/article/1943983064304644096.htm"
title="算法学习笔记:17.蒙特卡洛算法 ——从原理到实战,涵盖 LeetCode 与考研 408 例题" target="_blank">算法学习笔记:17.蒙特卡洛算法 ——从原理到实战,涵盖 LeetCode 与考研 408 例题</a>
<span class="text-muted"></span>
<div>在计算机科学和数学领域,蒙特卡洛算法(MonteCarloAlgorithm)以其独特的随机抽样思想,成为解决复杂问题的有力工具。从圆周率的计算到金融风险评估,从物理模拟到人工智能,蒙特卡洛算法都发挥着不可替代的作用。本文将深入剖析蒙特卡洛算法的思想、解题思路,结合实际应用场景与Java代码实现,并融入考研408的相关考点,穿插图片辅助理解,帮助你全面掌握这一重要算法。蒙特卡洛算法的基本概念蒙特卡</div>
</li>
<li><a href="/article/1943983064719880192.htm"
title="分布式学习笔记_04_复制模型" target="_blank">分布式学习笔记_04_复制模型</a>
<span class="text-muted">NzuCRAS</span>
<a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F/1.htm">分布式</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a><a class="tag" taget="_blank" href="/search/%E6%9E%B6%E6%9E%84/1.htm">架构</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a>
<div>常见复制模型使用复制的目的在分布式系统中,数据通常需要被分布在多台机器上,主要为了达到:拓展性:数据量因读写负载巨大,一台机器无法承载,数据分散在多台机器上仍然可以有效地进行负载均衡,达到灵活的横向拓展高容错&高可用:在分布式系统中单机故障是常态,在单机故障的情况下希望整体系统仍然能够正常工作,这时候就需要数据在多台机器上做冗余,在遇到单机故障时能够让其他机器接管统一的用户体验:如果系统客户端分布</div>
</li>
<li><a href="/article/1943983063352537088.htm"
title="算法学习笔记:15.二分查找 ——从原理到实战,涵盖 LeetCode 与考研 408 例题" target="_blank">算法学习笔记:15.二分查找 ——从原理到实战,涵盖 LeetCode 与考研 408 例题</a>
<span class="text-muted">呆呆企鹅仔</span>
<a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95%E5%AD%A6%E4%B9%A0/1.htm">算法学习</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a><a class="tag" taget="_blank" href="/search/%E8%80%83%E7%A0%94/1.htm">考研</a><a class="tag" taget="_blank" href="/search/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE/1.htm">二分查找</a>
<div>在计算机科学的查找算法中,二分查找以其高效性占据着重要地位。它利用数据的有序性,通过不断缩小查找范围,将原本需要线性时间的查找过程优化为对数时间,成为处理大规模有序数据查找问题的首选算法。二分查找的基本概念二分查找(BinarySearch),又称折半查找,是一种在有序数据集合中查找特定元素的高效算法。其核心原理是:通过不断将查找范围减半,快速定位目标元素。与线性查找逐个遍历元素不同,二分查找依赖</div>
</li>
<li><a href="/article/1943968187112550400.htm"
title="OpenWebUI(12)源码学习-后端constants.py常量定义文件" target="_blank">OpenWebUI(12)源码学习-后端constants.py常量定义文件</a>
<span class="text-muted">青苔猿猿</span>
<a class="tag" taget="_blank" href="/search/AI%E5%A4%A7%E6%A8%A1%E5%9E%8B/1.htm">AI大模型</a><a class="tag" taget="_blank" href="/search/openwebui/1.htm">openwebui</a><a class="tag" taget="_blank" href="/search/constants%E5%B8%B8%E9%87%8F%E5%AE%9A%E4%B9%89/1.htm">constants常量定义</a>
<div>目录文件名:`constants.py`功能概述:主要功能点详解1.**MESSAGES枚举类**2.**WEBHOOK_MESSAGES枚举类**3.**ERROR_MESSAGES枚举类**✅默认错误模板✅认证与用户相关错误✅资源冲突与重复错误✅验证失败类错误✅权限限制类错误✅文件上传与格式错误✅模型与API错误✅请求频率与安全限制✅数据库与配置错误4.**TASKS枚举类**✅总结实际应用场</div>
</li>
<li><a href="/article/1943964406694080512.htm"
title="RocketMQ 基础教程-应用篇-死信队列" target="_blank">RocketMQ 基础教程-应用篇-死信队列</a>
<span class="text-muted">码炫课堂-码哥</span>
<a class="tag" taget="_blank" href="/search/rocketmq%E4%B8%93%E9%A2%98/1.htm">rocketmq专题</a><a class="tag" taget="_blank" href="/search/rocketmq/1.htm">rocketmq</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬学习必须往深处挖,挖的越深,基础越扎实!阶段1、深入多线程阶段2、深入多线程设计模式阶段3、深入juc源码解析阶段4、深入jdk其余源码解析</div>
</li>
<li><a href="/article/1943963776244051968.htm"
title="入门html这篇文章就够了" target="_blank">入门html这篇文章就够了</a>
<span class="text-muted">ξ流ぁ星ぷ132</span>
<a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>HTML笔记文章目录HTML笔记html介绍什么是htmlhtml的作用HTML标签介绍常用标签标签and标签and标签u标签del删除线br标签用于换行pre标签,预处理标签span标签div标签sub标签andsup标签hr标签h1,h2...h6标签:HTML5中的语义标签:特殊字符img标签a标签第一种用法:超链接第二种用法:锚点video标签表格标签:form标签input标签selec</div>
</li>
<li><a href="/article/1943956589136375808.htm"
title="OKHttp3源码分析——学习笔记" target="_blank">OKHttp3源码分析——学习笔记</a>
<span class="text-muted">Sincerity_</span>
<a class="tag" taget="_blank" href="/search/%E6%BA%90%E7%A0%81%E7%9B%B8%E5%85%B3/1.htm">源码相关</a><a class="tag" taget="_blank" href="/search/Okhttp/1.htm">Okhttp</a><a class="tag" taget="_blank" href="/search/%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90/1.htm">源码解析</a><a class="tag" taget="_blank" href="/search/%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0/1.htm">读书笔记</a><a class="tag" taget="_blank" href="/search/httpclient/1.htm">httpclient</a><a class="tag" taget="_blank" href="/search/cache/1.htm">cache</a>
<div>文章目录1.HttpClient与HttpUrlConnection的区别2.OKHttp源码分析使用步骤:dispatcher任务调度器,(后面有详细说明)Request请求RealCallAsyncCall3.OKHttp架构分析1.异步请求线程池,Dispather2.连接池清理线程池-ConnectionPool3.缓存整理线程池DisLruCache4.Http2异步事务线程池,http</div>
</li>
<li><a href="/article/1943950163496202240.htm"
title="JavaScript 基础09:Web APIs——日期对象、DOM节点" target="_blank">JavaScript 基础09:Web APIs——日期对象、DOM节点</a>
<span class="text-muted">梦想当全栈</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>JavaScript基础09:WebAPIs——日期对象、DOM节点进一步学习DOM相关知识,实现可交互的网页特效能够插入、删除和替换元素节点。能够依据元素节点关系查找节点。一、日期对象掌握Date日期对象的使用,动态获取当前计算机的时间。ECMAScript中内置了获取系统时间的对象Date,使用Date时与之前学习的内置对象console和Math不同,它需要借助new关键字才能使用。1.实例</div>
</li>
<li><a href="/article/1943949027624153088.htm"
title="【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(Advanced RAG[1])基于历史对话重新生成Query?" target="_blank">【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(Advanced RAG[1])基于历史对话重新生成Query?</a>
<span class="text-muted">985小水博一枚呀</span>
<a class="tag" taget="_blank" href="/search/AI%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%AD%A6%E4%B9%A0%E8%B7%AF%E7%BA%BF/1.htm">AI大模型学习路线</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/langchain/1.htm">langchain</a><a class="tag" taget="_blank" href="/search/RAG/1.htm">RAG</a>
<div>【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(AdvancedRAG[1])基于历史对话重新生成Query?【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(AdvancedRAG[1])基于历史对话重新生成Query?文章目录【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(AdvancedRAG[1])基于历史对话重新生成Q</div>
</li>
<li><a href="/article/1943949028291047424.htm"
title="【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(Advanced RAG[1])其他Query优化相关策略?" target="_blank">【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(Advanced RAG[1])其他Query优化相关策略?</a>
<span class="text-muted">985小水博一枚呀</span>
<a class="tag" taget="_blank" href="/search/AI%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%AD%A6%E4%B9%A0%E8%B7%AF%E7%BA%BF/1.htm">AI大模型学习路线</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/langchain/1.htm">langchain</a>
<div>【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(AdvancedRAG[1])其他Query优化相关策略?【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(AdvancedRAG[1])其他Query优化相关策略?文章目录【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(AdvancedRAG[1])其他Query优化相关策略?一</div>
</li>
<li><a href="/article/1943941591924273152.htm"
title="传奇修改map地图教程_传奇技能第三祭:NPC的增加、隐藏和脚本修改" target="_blank">传奇修改map地图教程_传奇技能第三祭:NPC的增加、隐藏和脚本修改</a>
<span class="text-muted">垃圾箱博物馆</span>
<a class="tag" taget="_blank" href="/search/%E4%BC%A0%E5%A5%87%E4%BF%AE%E6%94%B9map%E5%9C%B0%E5%9B%BE%E6%95%99%E7%A8%8B/1.htm">传奇修改map地图教程</a>
<div>技能献祭,Get新技能:传奇技能——NPC功能与实现跟航家学技能,用干货带你飞,现学现用,底部有配套学习资源本篇内容简介:通过对游戏内NPC的控制,可以让NPC出现在地图中的任意位置,还可以控制外观显示、自定义命名,新增与隐藏以及脚本功能的实现。一、NPC总控制文本所在路径:D:MirServerMir200EnvirEnvir目录下,找到NPC总控制文本:Merchant,游戏内的所有NPC都在</div>
</li>
<li><a href="/article/1943940204628865024.htm"
title="LangChain中的向量数据库接口-Weaviate" target="_blank">LangChain中的向量数据库接口-Weaviate</a>
<span class="text-muted">洪城叮当</span>
<a class="tag" taget="_blank" href="/search/langchain/1.htm">langchain</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E7%BB%8F%E9%AA%8C%E5%88%86%E4%BA%AB/1.htm">经验分享</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a><a class="tag" taget="_blank" href="/search/%E4%BA%A4%E4%BA%92/1.htm">交互</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1/1.htm">知识图谱</a>
<div>文章目录前言一、原型定义二、代码解析1、add_texts方法1.1、应用样例2、from_texts方法2.1、应用样例3、similarity_search方法3.1、应用样例三、项目应用1、安装依赖2、引入依赖3、创建对象4、添加数据5、查询数据总结前言 Weaviate是一个开源的向量数据库,支持存储来自各类机器学习模型的数据对象和向量嵌入,并能无缝扩展至数十亿数据对象。它提供存储文档嵌</div>
</li>
<li><a href="/article/1943932395958890496.htm"
title="深度学习模型表征提取全解析" target="_blank">深度学习模型表征提取全解析</a>
<span class="text-muted">ZhangJiQun&MXP</span>
<a class="tag" taget="_blank" href="/search/%E6%95%99%E5%AD%A6/1.htm">教学</a><a class="tag" taget="_blank" href="/search/2024%E5%A4%A7%E6%A8%A1%E5%9E%8B%E4%BB%A5%E5%8F%8A%E7%AE%97%E5%8A%9B/1.htm">2024大模型以及算力</a><a class="tag" taget="_blank" href="/search/2021/1.htm">2021</a><a class="tag" taget="_blank" href="/search/AI/1.htm">AI</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/embedding/1.htm">embedding</a><a class="tag" taget="_blank" href="/search/%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B/1.htm">语言模型</a>
<div>模型内部进行表征提取的方法在自然语言处理(NLP)中,“表征(Representation)”指将文本(词、短语、句子、文档等)转化为计算机可理解的数值形式(如向量、矩阵),核心目标是捕捉语言的语义、语法、上下文依赖等信息。自然语言表征技术可按“静态/动态”“有无上下文”“是否融入知识”等维度划分一、传统静态表征(无上下文,词级为主)这类方法为每个词分配固定向量,不考虑其在具体语境中的含义(无法解</div>
</li>
<li><a href="/article/1943929867959595008.htm"
title="AI Agent开发学习系列 - langchain之Chains的使用(7):用四种处理文档的预制链轻松实现文档对话" target="_blank">AI Agent开发学习系列 - langchain之Chains的使用(7):用四种处理文档的预制链轻松实现文档对话</a>
<span class="text-muted">alex100</span>
<a class="tag" taget="_blank" href="/search/AI/1.htm">AI</a><a class="tag" taget="_blank" href="/search/Agent/1.htm">Agent</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/langchain/1.htm">langchain</a><a class="tag" taget="_blank" href="/search/prompt/1.htm">prompt</a><a class="tag" taget="_blank" href="/search/%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B/1.htm">语言模型</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>在LangChain中,四种文档处理预制链(stuff、refine、mapreduce、mapre-rank)是实现文档问答、摘要等任务的常用高阶工具。它们的核心作用是:将长文档切分为块,分步处理,再整合结果,极大提升大模型处理长文档的能力。stuff直接拼接所有文档内容到prompt,一次性交给大模型处理。适合文档较短、token不超限的场景。refine递进式摘要。先对第一块文档生成初步答案</div>
</li>
<li><a href="/article/1943929866940379136.htm"
title=".NET 一款基于BGInfo的红队内网渗透工具" target="_blank">.NET 一款基于BGInfo的红队内网渗透工具</a>
<span class="text-muted">dot.Net安全矩阵</span>
<a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a><a class="tag" taget="_blank" href="/search/.net/1.htm">.net</a><a class="tag" taget="_blank" href="/search/%E5%AE%89%E5%85%A8/1.htm">安全</a><a class="tag" taget="_blank" href="/search/.netcore/1.htm">.netcore</a><a class="tag" taget="_blank" href="/search/web%E5%AE%89%E5%85%A8/1.htm">web安全</a><a class="tag" taget="_blank" href="/search/%E7%9F%A9%E9%98%B5/1.htm">矩阵</a>
<div>01阅读须知此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的直接或间接后果和损失,均由使用者本人负责。本文所提供的工具仅用于学习,禁止用于其他方面02基本介绍在内网渗透过程中,白名单绕过是红队常见的技术需求。Sharp4Bginfo.exe是一款基于微软签名工具</div>
</li>
<li><a href="/article/1943926464663580672.htm"
title="vue3面试题(个人笔记)" target="_blank">vue3面试题(个人笔记)</a>
<span class="text-muted">武昌库里写JAVA</span>
<a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95%E9%A2%98%E6%B1%87%E6%80%BB%E4%B8%8E%E8%A7%A3%E6%9E%90/1.htm">面试题汇总与解析</a><a class="tag" taget="_blank" href="/search/%E8%AF%BE%E7%A8%8B%E8%AE%BE%E8%AE%A1/1.htm">课程设计</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/vue.js/1.htm">vue.js</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a>
<div>vue3比vue2有什么优势?性能更好,打包体积更小,更好的ts支持,更好的代码组织,更好的逻辑抽离,更多的新功能。描述Vue3生命周期CompositionAPI的生命周期:onMounted()onUpdated()onUnmounted()onBeforeMount()onBeforeUpdate()onBeforeUnmount()onErrorCaptured()onRenderTrac</div>
</li>
<li><a href="/article/1943920162180755456.htm"
title="Python学习笔记5|条件语句和循环语句" target="_blank">Python学习笔记5|条件语句和循环语句</a>
<span class="text-muted">iamecho9</span>
<a class="tag" taget="_blank" href="/search/Python%E4%BB%8E0%E5%88%B01%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/1.htm">Python从0到1学习笔记</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a>
<div>一、条件语句条件语句用于根据不同的条件执行不同的代码块。1、if语句基本语法:if布尔型语句1:代码块#语句1为True时执行的代码示例:age=int(input("请输入你的年龄:"))ifage>=18:print("你已成年")2、if-else语句如果if条件不成立,则执行else代码块:if布尔型语句1:代码块#语句1为True时执行的代码else:代码块#语句1为False时执行的代</div>
</li>
<li><a href="/article/1943920035919622144.htm"
title="2025年渗透测试面试题总结-2025年HW(护网面试) 43(题目+回答)" target="_blank">2025年渗透测试面试题总结-2025年HW(护网面试) 43(题目+回答)</a>
<span class="text-muted">独行soc</span>
<a class="tag" taget="_blank" href="/search/2025%E5%B9%B4%E6%8A%A4%E7%BD%91/1.htm">2025年护网</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95/1.htm">面试</a><a class="tag" taget="_blank" href="/search/%E8%81%8C%E5%9C%BA%E5%92%8C%E5%8F%91%E5%B1%95/1.htm">职场和发展</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/%E7%A7%91%E6%8A%80/1.htm">科技</a><a class="tag" taget="_blank" href="/search/%E6%B8%97%E9%80%8F%E6%B5%8B%E8%AF%95/1.htm">渗透测试</a><a class="tag" taget="_blank" href="/search/%E5%AE%89%E5%85%A8/1.htm">安全</a><a class="tag" taget="_blank" href="/search/%E6%8A%A4%E7%BD%91/1.htm">护网</a>
<div>安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。目录2025年HW(护网面试)431.自我介绍与职业规划2.Webshell源码级检测方案3.2025年新型Web漏洞TOP54.渗透中的高价值攻击点5.智能Fuzz平台架构设计6.堆栈溢出攻防演进7.插桩技术实战应用8.二进制安全能力矩阵9.C语言内存管理精要10.Pyth</div>
</li>
<li><a href="/article/1943917011268595712.htm"
title="Javaweb学习之Vue模板语法(三)" target="_blank">Javaweb学习之Vue模板语法(三)</a>
<span class="text-muted">不要数手指啦</span>
<a class="tag" taget="_blank" href="/search/vue.js/1.htm">vue.js</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>目录学习资料前情回顾本期介绍(vue模板语法)文本插值Vue的Attribute绑定使用JavaScript表达式综合实例代码:学习资料Vue.js-渐进式JavaScript框架|Vue.js(vuejs.org)前情回顾项目的创建大家可以看这篇文章Vue学习之项目的创建-CSDN博客本期介绍(vue模板语法)首先,找到我们编写代码的地方找到自己项目的src文件夹,打开之后点击component</div>
</li>
<li><a href="/article/1943914995217657856.htm"
title="swagger【个人笔记】" target="_blank">swagger【个人笔记】</a>
<span class="text-muted">撰卢</span>
<a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>文章目录swagger导入mave坐标在配置类(WebMvcConfiguration)中加入knife4j相关配置设置静态资源映射,主要是让拦截器放行swagger常用注解@Api(tags="\[描述这个类的作用]")@ApiModel(description="\[描述这个类的作用]")@ApiModelProPerty("描述这个类的作用")@ApiOperation("\[描述方法的作用</div>
</li>
<li><a href="/article/1943913603195269120.htm"
title="【个人笔记】负载均衡" target="_blank">【个人笔记】负载均衡</a>
<span class="text-muted">撰卢</span>
<a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a><a class="tag" taget="_blank" href="/search/%E8%B4%9F%E8%BD%BD%E5%9D%87%E8%A1%A1/1.htm">负载均衡</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a>
<div>文章目录nginx反向代理的好处负载均衡负载均很的配置方式均衡负载的方式nginx反向代理的好处提高访问速度进行负载均衡保证后端服务安全负载均衡负载均衡,就是把大量的请求按照我们指定的方式均衡的分配给集群中的每台服务器负载均很的配置方式upstreamwebservers{server192.168.100.128:8080server192.168.100.129:8080}server{lis</div>
</li>
<li><a href="/article/57.htm"
title="多线程编程之join()方法" target="_blank">多线程编程之join()方法</a>
<span class="text-muted">周凡杨</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/JOIN/1.htm">JOIN</a><a class="tag" taget="_blank" href="/search/%E5%A4%9A%E7%BA%BF%E7%A8%8B/1.htm">多线程</a><a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B/1.htm">编程</a><a class="tag" taget="_blank" href="/search/%E7%BA%BF%E7%A8%8B/1.htm">线程</a>
<div>现实生活中,有些工作是需要团队中成员依次完成的,这就涉及到了一个顺序问题。现在有T1、T2、T3三个工人,如何保证T2在T1执行完后执行,T3在T2执行完后执行?问题分析:首先问题中有三个实体,T1、T2、T3, 因为是多线程编程,所以都要设计成线程类。关键是怎么保证线程能依次执行完呢?
Java实现过程如下:
public class T1 implements Runnabl</div>
</li>
<li><a href="/article/184.htm"
title="java中switch的使用" target="_blank">java中switch的使用</a>
<span class="text-muted">bingyingao</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/enum/1.htm">enum</a><a class="tag" taget="_blank" href="/search/break/1.htm">break</a><a class="tag" taget="_blank" href="/search/continue/1.htm">continue</a>
<div>java中的switch仅支持case条件仅支持int、enum两种类型。
用enum的时候,不能直接写下列形式。
switch (timeType) {
case ProdtransTimeTypeEnum.DAILY:
break;
default:
br</div>
</li>
<li><a href="/article/311.htm"
title="hive having count 不能去重" target="_blank">hive having count 不能去重</a>
<span class="text-muted">daizj</span>
<a class="tag" taget="_blank" href="/search/hive/1.htm">hive</a><a class="tag" taget="_blank" href="/search/%E5%8E%BB%E9%87%8D/1.htm">去重</a><a class="tag" taget="_blank" href="/search/having+count/1.htm">having count</a><a class="tag" taget="_blank" href="/search/%E8%AE%A1%E6%95%B0/1.htm">计数</a>
<div>hive在使用having count()是,不支持去重计数
hive (default)> select imei from t_test_phonenum where ds=20150701 group by imei having count(distinct phone_num)>1 limit 10;
FAILED: SemanticExcep</div>
</li>
<li><a href="/article/438.htm"
title="WebSphere对JSP的缓存" target="_blank">WebSphere对JSP的缓存</a>
<span class="text-muted">周凡杨</span>
<a class="tag" taget="_blank" href="/search/WAS+JSP+%E7%BC%93%E5%AD%98/1.htm">WAS JSP 缓存</a>
<div> 对于线网上的工程,更新JSP到WebSphere后,有时会出现修改的jsp没有起作用,特别是改变了某jsp的样式后,在页面中没看到效果,这主要就是由于websphere中缓存的缘故,这就要清除WebSphere中jsp缓存。要清除WebSphere中JSP的缓存,就要找到WAS安装后的根目录。
现服务</div>
</li>
<li><a href="/article/565.htm"
title="设计模式总结" target="_blank">设计模式总结</a>
<span class="text-muted">朱辉辉33</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/1.htm">设计模式</a>
<div>1.工厂模式
1.1 工厂方法模式 (由一个工厂类管理构造方法)
1.1.1普通工厂模式(一个工厂类中只有一个方法)
1.1.2多工厂模式(一个工厂类中有多个方法)
1.1.3静态工厂模式(将工厂类中的方法变成静态方法)
&n</div>
</li>
<li><a href="/article/692.htm"
title="实例:供应商管理报表需求调研报告" target="_blank">实例:供应商管理报表需求调研报告</a>
<span class="text-muted">老A不折腾</span>
<a class="tag" taget="_blank" href="/search/finereport/1.htm">finereport</a><a class="tag" taget="_blank" href="/search/%E6%8A%A5%E8%A1%A8%E7%B3%BB%E7%BB%9F/1.htm">报表系统</a><a class="tag" taget="_blank" href="/search/%E6%8A%A5%E8%A1%A8%E8%BD%AF%E4%BB%B6/1.htm">报表软件</a><a class="tag" taget="_blank" href="/search/%E4%BF%A1%E6%81%AF%E5%8C%96%E9%80%89%E5%9E%8B/1.htm">信息化选型</a>
<div>引言
随着企业集团的生产规模扩张,为支撑全球供应链管理,对于供应商的管理和采购过程的监控已经不局限于简单的交付以及价格的管理,目前采购及供应商管理各个环节的操作分别在不同的系统下进行,而各个数据源都独立存在,无法提供统一的数据支持;因此,为了实现对于数据分析以提供采购决策,建立报表体系成为必须。 业务目标
1、通过报表为采购决策提供数据分析与支撑
2、对供应商进行综合评估以及管理,合理管理和</div>
</li>
<li><a href="/article/819.htm"
title="mysql" target="_blank">mysql</a>
<span class="text-muted">林鹤霄</span>
<div>转载源:http://blog.sina.com.cn/s/blog_4f925fc30100rx5l.html
mysql -uroot -p
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
[root@centos var]# service mysql</div>
</li>
<li><a href="/article/946.htm"
title="Linux下多线程堆栈查看工具(pstree、ps、pstack)" target="_blank">Linux下多线程堆栈查看工具(pstree、ps、pstack)</a>
<span class="text-muted">aigo</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>原文:http://blog.csdn.net/yfkiss/article/details/6729364
1. pstree
pstree以树结构显示进程$ pstree -p work | grep adsshd(22669)---bash(22670)---ad_preprocess(4551)-+-{ad_preprocess}(4552) &n</div>
</li>
<li><a href="/article/1073.htm"
title="html input与textarea 值改变事件" target="_blank">html input与textarea 值改变事件</a>
<span class="text-muted">alxw4616</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a>
<div>// 文本输入框(input) 文本域(textarea)值改变事件
// onpropertychange(IE) oninput(w3c)
$('input,textarea').on('propertychange input', function(event) {
console.log($(this).val())
});
</div>
</li>
<li><a href="/article/1200.htm"
title="String类的基本用法" target="_blank">String类的基本用法</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/String/1.htm">String</a>
<div>
字符串的用法;
// 根据字节数组创建字符串
byte[] by = { 'a', 'b', 'c', 'd' };
String newByteString = new String(by);
1,length() 获取字符串的长度
&nbs</div>
</li>
<li><a href="/article/1327.htm"
title="JDK1.5 Semaphore实例" target="_blank">JDK1.5 Semaphore实例</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/thread/1.htm">thread</a><a class="tag" taget="_blank" href="/search/java%E5%A4%9A%E7%BA%BF%E7%A8%8B/1.htm">java多线程</a><a class="tag" taget="_blank" href="/search/Semaphore/1.htm">Semaphore</a>
<div>Semaphore类
一个计数信号量。从概念上讲,信号量维护了一个许可集合。如有必要,在许可可用前会阻塞每一个 acquire(),然后再获取该许可。每个 release() 添加一个许可,从而可能释放一个正在阻塞的获取者。但是,不使用实际的许可对象,Semaphore 只对可用许可的号码进行计数,并采取相应的行动。
S</div>
</li>
<li><a href="/article/1454.htm"
title="使用GZip来压缩传输量" target="_blank">使用GZip来压缩传输量</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/GZip/1.htm">GZip</a>
<div> 启动GZip压缩要用到一个开源的Filter:PJL Compressing Filter。这个Filter自1.5.0开始该工程开始构建于JDK5.0,因此在JDK1.4环境下只能使用1.4.6。
PJL Compressi</div>
</li>
<li><a href="/article/1581.htm"
title="【Java范型三】Java范型详解之范型类型通配符" target="_blank">【Java范型三】Java范型详解之范型类型通配符</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>
定义如下一个简单的范型类,
package com.tom.lang.generics;
public class Generics<T> {
private T value;
public Generics(T value) {
this.value = value;
}
} </div>
</li>
<li><a href="/article/1708.htm"
title="【Hadoop十二】HDFS常用命令" target="_blank">【Hadoop十二】HDFS常用命令</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/hadoop/1.htm">hadoop</a>
<div>1. 修改日志文件查看器
hdfs oev -i edits_0000000000000000081-0000000000000000089 -o edits.xml
cat edits.xml
修改日志文件转储为xml格式的edits.xml文件,其中每条RECORD就是一个操作事务日志
2. fsimage查看HDFS中的块信息等
&nb</div>
</li>
<li><a href="/article/1835.htm"
title="怎样区别nginx中rewrite时break和last" target="_blank">怎样区别nginx中rewrite时break和last</a>
<span class="text-muted">ronin47</span>
<div>在使用nginx配置rewrite中经常会遇到有的地方用last并不能工作,换成break就可以,其中的原理是对于根目录的理解有所区别,按我的测试结果大致是这样的。
location /
{
proxy_pass http://test; </div>
</li>
<li><a href="/article/1962.htm"
title="java-21.中兴面试题 输入两个整数 n 和 m ,从数列 1 , 2 , 3.......n 中随意取几个数 , 使其和等于 m" target="_blank">java-21.中兴面试题 输入两个整数 n 和 m ,从数列 1 , 2 , 3.......n 中随意取几个数 , 使其和等于 m</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>
import java.util.ArrayList;
import java.util.List;
import java.util.Stack;
public class CombinationToSum {
/*
第21 题
2010 年中兴面试题
编程求解:
输入两个整数 n 和 m ,从数列 1 , 2 , 3.......n 中随意取几个数 ,
使其和等</div>
</li>
<li><a href="/article/2089.htm"
title="eclipse svn 帐号密码修改问题" target="_blank">eclipse svn 帐号密码修改问题</a>
<span class="text-muted">开窍的石头</span>
<a class="tag" taget="_blank" href="/search/eclipse/1.htm">eclipse</a><a class="tag" taget="_blank" href="/search/SVN/1.htm">SVN</a><a class="tag" taget="_blank" href="/search/svn%E5%B8%90%E5%8F%B7%E5%AF%86%E7%A0%81%E4%BF%AE%E6%94%B9/1.htm">svn帐号密码修改</a>
<div>问题描述:
Eclipse的SVN插件Subclipse做得很好,在svn操作方面提供了很强大丰富的功能。但到目前为止,该插件对svn用户的概念极为淡薄,不但不能方便地切换用户,而且一旦用户的帐号、密码保存之后,就无法再变更了。
解决思路:
删除subclipse记录的帐号、密码信息,重新输入</div>
</li>
<li><a href="/article/2216.htm"
title="[电子商务]传统商务活动与互联网的结合" target="_blank">[电子商务]传统商务活动与互联网的结合</a>
<span class="text-muted">comsci</span>
<a class="tag" taget="_blank" href="/search/%E7%94%B5%E5%AD%90%E5%95%86%E5%8A%A1/1.htm">电子商务</a>
<div>
某一个传统名牌产品,过去销售的地点就在某些特定的地区和阶层,现在进入互联网之后,用户的数量群突然扩大了无数倍,但是,这种产品潜在的劣势也被放大了无数倍,这种销售利润与经营风险同步放大的效应,在最近几年将会频繁出现。。。。
如何避免销售量和利润率增加的</div>
</li>
<li><a href="/article/2343.htm"
title="java 解析 properties-使用 Properties-可以指定配置文件路径" target="_blank">java 解析 properties-使用 Properties-可以指定配置文件路径</a>
<span class="text-muted">cuityang</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/properties/1.htm">properties</a>
<div>#mq
xdr.mq.url=tcp://192.168.100.15:61618;
import java.io.IOException;
import java.util.Properties;
public class Test {
String conf = "log4j.properties";
private static final</div>
</li>
<li><a href="/article/2470.htm"
title="Java核心问题集锦" target="_blank">Java核心问题集锦</a>
<span class="text-muted">darrenzhu</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%9F%BA%E7%A1%80/1.htm">基础</a><a class="tag" taget="_blank" href="/search/%E6%A0%B8%E5%BF%83/1.htm">核心</a><a class="tag" taget="_blank" href="/search/%E9%9A%BE%E7%82%B9/1.htm">难点</a>
<div>注意,这里的参考文章基本来自Effective Java和jdk源码
1)ConcurrentModificationException
当你用for each遍历一个list时,如果你在循环主体代码中修改list中的元素,将会得到这个Exception,解决的办法是:
1)用listIterator, 它支持在遍历的过程中修改元素,
2)不用listIterator, new一个</div>
</li>
<li><a href="/article/2724.htm"
title="1分钟学会Markdown语法" target="_blank">1分钟学会Markdown语法</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/markdown/1.htm">markdown</a>
<div>markdown 简明语法 基本符号
*,-,+ 3个符号效果都一样,这3个符号被称为 Markdown符号
空白行表示另起一个段落
`是表示inline代码,tab是用来标记 代码段,分别对应html的code,pre标签
换行
单一段落( <p>) 用一个空白行
连续两个空格 会变成一个 <br>
连续3个符号,然后是空行</div>
</li>
<li><a href="/article/2851.htm"
title="Gson使用二(GsonBuilder)" target="_blank">Gson使用二(GsonBuilder)</a>
<span class="text-muted">eksliang</span>
<a class="tag" taget="_blank" href="/search/json/1.htm">json</a><a class="tag" taget="_blank" href="/search/gson/1.htm">gson</a><a class="tag" taget="_blank" href="/search/GsonBuilder/1.htm">GsonBuilder</a>
<div>转载请出自出处:http://eksliang.iteye.com/blog/2175473 一.概述
GsonBuilder用来定制java跟json之间的转换格式
二.基本使用
实体测试类:
温馨提示:默认情况下@Expose注解是不起作用的,除非你用GsonBuilder创建Gson的时候调用了GsonBuilder.excludeField</div>
</li>
<li><a href="/article/2978.htm"
title="报ClassNotFoundException: Didn't find class "...Activity" on path: DexPathList" target="_blank">报ClassNotFoundException: Didn't find class "...Activity" on path: DexPathList</a>
<span class="text-muted">gundumw100</span>
<a class="tag" taget="_blank" href="/search/android/1.htm">android</a>
<div>有一个工程,本来运行是正常的,我想把它移植到另一台PC上,结果报:
java.lang.RuntimeException: Unable to instantiate activity ComponentInfo{com.mobovip.bgr/com.mobovip.bgr.MainActivity}: java.lang.ClassNotFoundException: Didn't f</div>
</li>
<li><a href="/article/3105.htm"
title="JavaWeb之JSP指令" target="_blank">JavaWeb之JSP指令</a>
<span class="text-muted">ihuning</span>
<a class="tag" taget="_blank" href="/search/javaweb/1.htm">javaweb</a>
<div>
要点
JSP指令简介
page指令
include指令
JSP指令简介
JSP指令(directive)是为JSP引擎而设计的,它们并不直接产生任何可见输出,而只是告诉引擎如何处理JSP页面中的其余部分。
JSP指令的基本语法格式:
<%@ 指令 属性名="</div>
</li>
<li><a href="/article/3232.htm"
title="mac上编译FFmpeg跑ios" target="_blank">mac上编译FFmpeg跑ios</a>
<span class="text-muted">啸笑天</span>
<a class="tag" taget="_blank" href="/search/ffmpeg/1.htm">ffmpeg</a>
<div>1、下载文件:https://github.com/libav/gas-preprocessor, 复制gas-preprocessor.pl到/usr/local/bin/下, 修改文件权限:chmod 777 /usr/local/bin/gas-preprocessor.pl
2、安装yasm-1.2.0
curl http://www.tortall.net/projects/yasm</div>
</li>
<li><a href="/article/3359.htm"
title="sql mysql oracle中字符串连接" target="_blank">sql mysql oracle中字符串连接</a>
<span class="text-muted">macroli</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/SQL+Server/1.htm">SQL Server</a>
<div>有的时候,我们有需要将由不同栏位获得的资料串连在一起。每一种资料库都有提供方法来达到这个目的:
MySQL: CONCAT()
Oracle: CONCAT(), ||
SQL Server: +
CONCAT() 的语法如下:
Mysql 中 CONCAT(字串1, 字串2, 字串3, ...): 将字串1、字串2、字串3,等字串连在一起。
请注意,Oracle的CON</div>
</li>
<li><a href="/article/3486.htm"
title="Git fatal: unab SSL certificate problem: unable to get local issuer ce rtificate" target="_blank">Git fatal: unab SSL certificate problem: unable to get local issuer ce rtificate</a>
<span class="text-muted">qiaolevip</span>
<a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0%E6%B0%B8%E6%97%A0%E6%AD%A2%E5%A2%83/1.htm">学习永无止境</a><a class="tag" taget="_blank" href="/search/%E6%AF%8F%E5%A4%A9%E8%BF%9B%E6%AD%A5%E4%B8%80%E7%82%B9%E7%82%B9/1.htm">每天进步一点点</a><a class="tag" taget="_blank" href="/search/git/1.htm">git</a><a class="tag" taget="_blank" href="/search/%E7%BA%B5%E8%A7%82%E5%8D%83%E8%B1%A1/1.htm">纵观千象</a>
<div>// 报错如下:
$ git pull origin master
fatal: unable to access 'https://git.xxx.com/': SSL certificate problem: unable to get local issuer ce
rtificate
// 原因:
由于git最新版默认使用ssl安全验证,但是我们是使用的git未设</div>
</li>
<li><a href="/article/3613.htm"
title="windows命令行设置wifi" target="_blank">windows命令行设置wifi</a>
<span class="text-muted">surfingll</span>
<a class="tag" taget="_blank" href="/search/windows/1.htm">windows</a><a class="tag" taget="_blank" href="/search/wifi/1.htm">wifi</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0%E6%9C%ACwifi/1.htm">笔记本wifi</a>
<div>还没有讨厌无线wifi的无尽广告么,还在耐心等待它慢慢启动么
教你命令行设置 笔记本电脑wifi:
1、开启wifi命令
netsh wlan set hostednetwork mode=allow ssid=surf8 key=bb123456
netsh wlan start hostednetwork
pause
其中pause是等待输入,可以去掉
2、</div>
</li>
<li><a href="/article/3740.htm"
title="Linux(Ubuntu)下安装sysv-rc-conf" target="_blank">Linux(Ubuntu)下安装sysv-rc-conf</a>
<span class="text-muted">wmlJava</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/ubuntu/1.htm">ubuntu</a><a class="tag" taget="_blank" href="/search/sysv-rc-conf/1.htm">sysv-rc-conf</a>
<div>安装:sudo apt-get install sysv-rc-conf 使用:sudo sysv-rc-conf
操作界面十分简洁,你可以用鼠标点击,也可以用键盘方向键定位,用空格键选择,用Ctrl+N翻下一页,用Ctrl+P翻上一页,用Q退出。
背景知识
sysv-rc-conf是一个强大的服务管理程序,群众的意见是sysv-rc-conf比chkconf</div>
</li>
<li><a href="/article/3867.htm"
title="svn切换环境,重发布应用多了javaee标签前缀" target="_blank">svn切换环境,重发布应用多了javaee标签前缀</a>
<span class="text-muted">zengshaotao</span>
<a class="tag" taget="_blank" href="/search/javaee/1.htm">javaee</a>
<div>更换了开发环境,从杭州,改变到了上海。svn的地址肯定要切换的,切换之前需要将原svn自带的.svn文件信息删除,可手动删除,也可通过废弃原来的svn位置提示删除.svn时删除。
然后就是按照最新的svn地址和规范建立相关的目录信息,再将原来的纯代码信息上传到新的环境。然后再重新检出,这样每次修改后就可以看到哪些文件被修改过,这对于增量发布的规范特别有用。
检出</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html><script data-cfasync="false" src="/cdn-cgi/scripts/5c5dd728/cloudflare-static/email-decode.min.js"></script>