用数据观测Page Cache
与 Page Cache 有关的场景:
服务器的 load 飙高;
服务器的 I/O 吞吐飙高;
业务响应时延出现大的毛刺;
业务平均访问时延明显增加
上边这些问题,很可能是由于 Page Cache管理不到位引起的,因为 Page Cache 管理不当除了会增加系统 I/O 吞吐外,还会引起业务性能抖动。

通过上图可以看到,红色的部分就是Page Cache,而它是内核管理的内存,属于内核。观察Page Cache可以使用free这个命令,也可以读取/proc/meminfo和/proc/vmstat这两个文件。
cat /proc/meminfo可以看一下文件里边的内容:
[root@Sea1 ~]# cat /proc/meminfo
MemTotal: 16266392 kB
MemFree: 6835992 kB
MemAvailable: 14248884 kB
Buffers: 2088 kB
Cached: 8005488 kB
SwapCached: 0 kB
Active: 5181348 kB
Inactive: 3308564 kB
Active(anon): 1017616 kB
Inactive(anon): 277244 kB
Active(file): 4163732 kB
Inactive(file): 3031320 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 24 kB
Writeback: 0 kB
AnonPages: 482340 kB
Mapped: 97068 kB
Shmem: 812524 kB
Slab: 620676 kB
SReclaimable: 556080 kB
SUnreclaim: 64596 kB
KernelStack: 4032 kB
PageTables: 7456 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 8133196 kB
Committed_AS: 2494392 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 36284 kB
VmallocChunk: 34359695100 kB
HardwareCorrupted: 0 kB
AnonHugePages: 270336 kB
CmaTotal: 0 kB
CmaFree: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
DirectMap4k: 294764 kB
DirectMap2M: 13336576 kB
DirectMap1G: 5242880 kB
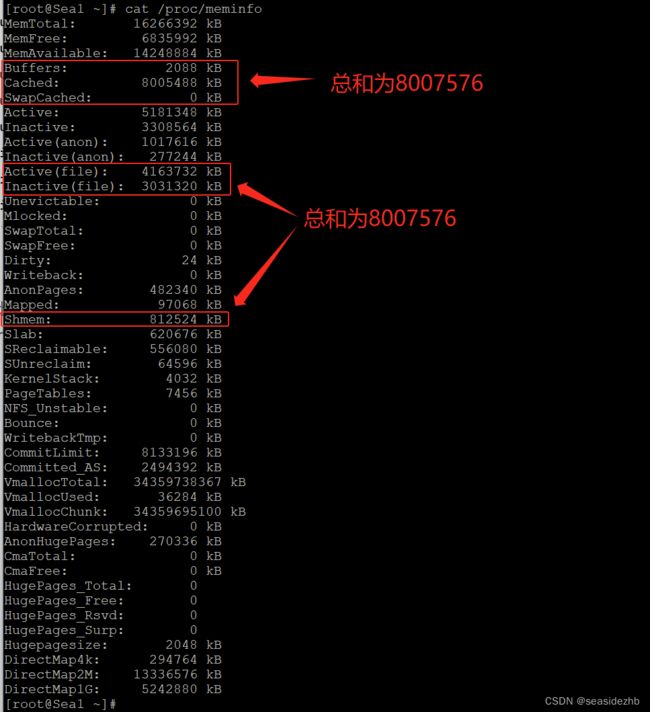
可以得出下边的公式(上图中,两边公式之和都是8007576):
Buffers + Cached + SwapCached = Active(file) + Inactive(file) + Shmem + SwapCached
等式两边的内容就是我们常说的Page Cache,两边都有 SwapCached,之所以要把它放在等式里,就是说它也是 Page Cache 的一部分。
接下来分析一下这些项的具体含义。
等式右边这些项把Buffers和Cached做了一下细分,分为了 Active(file),Inactive(file) 和 Shmem,因为Buffers更加依赖于内核实现,在不同内核版本中它的含义可能有些不一致,而等式右边和应用程序的关系更加直接,所以从等式右边来分析。
在 Page Cache 中,Active(file)+Inactive(file) 是 File-backed page(与文件对应的内存页),是你最需要关注的部分。因为你平时用的mmap()内存映射方式和buffered I/O来消耗的内存就属于这部分,最重要的是,这部分在真实的生产环境上也最容易产生问题。
而SwapCached是在打开了 Swap 分区后,把Inactive(anon)+Active(anon) 这两项里的匿名页给交换到磁盘(swap out),然后再读入到内存(swap in)后分配的内存。由于读入到内存后原来的Swap File还在,所以 SwapCached 也可以认为是 File-backed page,即属于Page Cache。这样做的目的也是为了减少 I/O。
除了SwapCached,Page Cache中的Shmem是指匿名共享映射这种方式分配的内存(free命令中shared这一项),比如 tmpfs(临时文件系统),这部分在真实的生产环境中产生的问题比较少。
free命令也可以用来查看系统中有多少 Page Cache,可以根据buff/cache来判断存在多少 Page Cache。如果你对 free命令有所了解的话,肯定知道free命令也是通过解析 /proc/meminfo 得出这些统计数据的,这些都可以通过 free 工具的源码来找到。free 命令的源码是开源,你可以去看下procfs里的 free.c 文件,源码是最直接的理解方式,会加深你对 free 命令的理解。

buff/cache的计算公式是buff/cache = Buffers + Cached + SReclaimable。
这里你要注意,你在做比较的过程中,一定要考虑到这些数据是动态变化的,而且执行命令本身也会带来内存开销,所以这个等式未必会严格相等,不过你不必怀疑它的正确性。
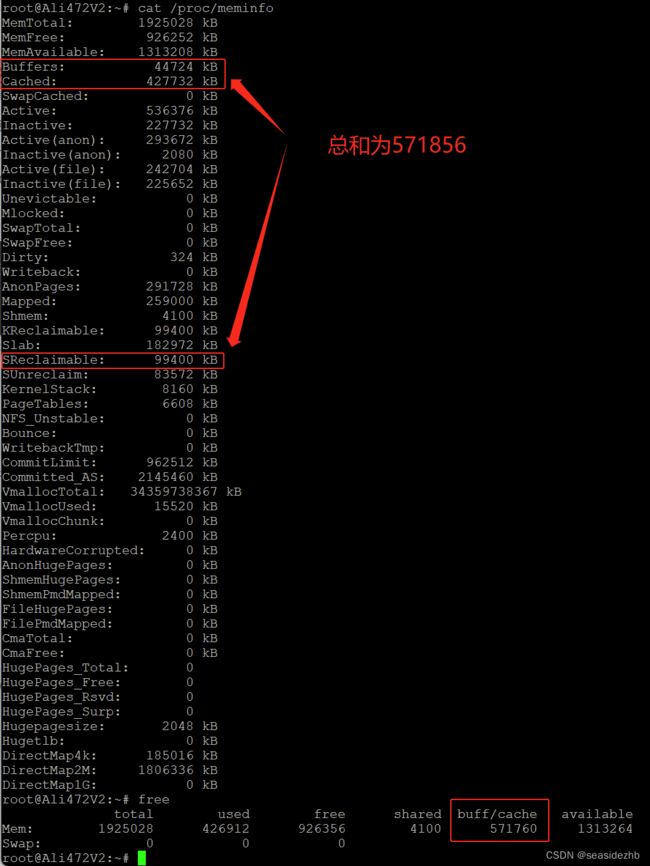
从这个公式中,你能看到free命令中的buff/cache是由Buffers、Cached 和SReclaimable这三项组成的,它强调的是内存的可回收性,也就是说,可以被回收的内存会统计在这一项。其中SReclaimable是指可以被回收的内核内存,包括dentry和inode等。
掌握了 Page Cache 具体由哪些部分构成之后,在它引发一些问题时,你就能够知道需要去观察什么。比如说,应用本身消耗内存(RSS)不多的情况下,整个系统的内存使用率还是很高,那不妨去排查下是不是 Shmem(共享内存) 消耗了太多内存导致的。
如果不用内核管理的 Page Cache,那有两种思路来进行处理:
第一种,应用程序维护自己的 Cache 做更加细粒度的控制,比如 MySQL 就是这样做的,你可以参考MySQL Buffer Pool ,它的实现复杂度还是很高的。对于大多数应用而言,实现自己的 Cache 成本还是挺高的,不如内核的 Page Cache 来得简单高效。
第二种,直接使用 Direct I/O 来绕过 Page Cache,不使用 Cache 了,省的去管它了。
我们看一个具体的例子来解释为什么需要Page Cache。首先,我们来生成一个 1G 大小的新文件,然后把 Page Cache 清空,确保文件内容不在内存中,以此来比较第一次读文件和第二次读文件耗时的差异。具体的流程如下:
1.dd if=/dev/zero of=/root/dd.out bs=4096 count=262144生成一个1G 的文件。
2.sync && echo 3 > /proc/sys/vm/drop_caches先执行一下 sync 来将脏页同步到磁盘再去drop cache,这样的话,清空 Page Cache。

第一次读取文件的耗时如下:
[root@Sea1 ~]# time cat /root/dd.out &> /dev/null
real 0m6.705s
user 0m0.010s
sys 0m0.414s
第二次读取文件的耗时如下:
[root@Sea1 ~]# time cat /root/dd.out &> /dev/null
real 0m0.233s
user 0m0.007s
sys 0m0.226s
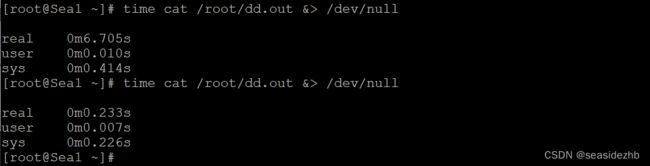
通过这样详细的过程你可以看到,第二次读取文件的耗时远小于第一次的耗时,这是因为第一次是从磁盘来读取的内容,磁盘 I/O 是比较耗时的,而第二次读取的时候由于文件内容已经在第一次读取时被读到内存了,所以是直接从内存读取的数据,内存相比磁盘速度是快很多的。这就是 Page Cache 存在的意义:减少 I/O,提升应用的 I/O 速度。
此文章为9月Day 24学习笔记,内容来源于极客时间《Linux 内核技术实战课》