【二进制基础篇-2】栈基础
栈在汇编程序中有着非常重要的作用,一般一段代码的完整执行多多少少都是需要在栈的参与下完成。因此,对于栈功能的深刻理解也是有助于我们深入二进制世界的一把利器。
目录
1.调试工具
2.栈
3.内存与栈地址
4.函数与栈
5. 栈平衡
6.函数参数传递
6.1 调用约定
6.2 确定参数个数
6.3 名称修饰约定
7.裸函数
8.变量与寻址方式
8.1 栈寻址
8.2 局部变量
8.3 全局变量
8.4 函数返回值
1.调试工具
通常,我们会用到的对汇编程序的编写与调试方式主要有以下几种(详情见后续推出的工具篇):
MASM32/NASM:MASM32作为编写汇编代码的常用工具,NASM提供命令行方式处理.asm文件,在纯汇编程序开发中常用。
VC++6.0或Virtual Studio:在Windows平台中,可以使用VC++6.0或Virtual Studio来使用__asm{}函数方式嵌入编写汇编代码,或采用设置断点的方式来查看C/C++语言在运行态的汇编代码,逆向调试中较常用。
Ollydbg:也称为OD,作为常用动态调试的逆向工具之一,可以使用Ollydbg来实时的调试、编辑PE文件,较常用。
WinDbg:Windows平台官方的调试器,具有非常强大的实时调试功能。
gdb/pwndbg:GDB是Linux平台常用的调试器,pwndbg作为gdb中的一个功能插件,对原有gdb功能进行扩展的基础上具有良好的可视效果。
Objdump/readelf:在Linux平台中用于对ELF文件的信息展示和获取。
2.栈
通常栈在汇编中也称为堆栈,而堆和栈在高级语言中是两个不同的概念,这里将汇编中的堆栈与高级语言统一称为栈。当我们在一个程序中声明各种变量时,静态全局变量将位于数据段,并且在程序段开始运行时被加载,而程序的动态局部变量则分配在栈里面。
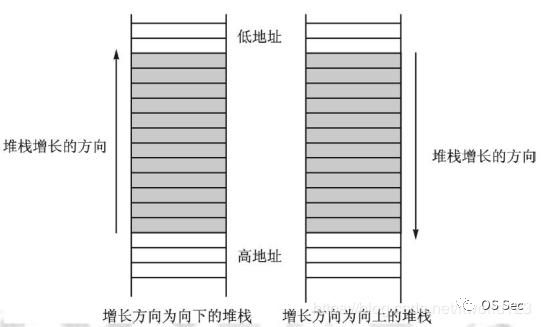
栈是一种抽象数据结构,用于在程序运行时临时存储数据,物理上就是一段连续分配的内存区域,对它的访问操作仅限于在一端进行。地址较大的一端称为栈底,地址较小的一端称为栈顶。对于栈的操作需要遵循“后进先出”原则,所有数据的存入和取出都在栈顶进行。把存入数据的操作称为入栈或压栈,取出数据的操作称为出栈或弹出。如图所示,在32位系统中,每一小格代表4个字节,也就是一个双字(DWORD),一般的入栈、出栈操作都会以四字节为单位进行(当然,也有针对字节、字的操作,只是相对少很多)。
#图来自网络,侵删
上图中显示了栈能够进行的两种增长方式,左侧是从高地址到低地址增长,右侧是从低地址到高地址增长。在一般实际中的栈增长都是以左侧的低地址到高地址增长方式进行,所以EBP(保存栈底)中保存的地址比ESP(保存栈顶)中保存的地址值大。
堆栈段寄存器SS中含有当前栈的段号,指向栈所在区域的位置。ESP寄存器中的偏移地址指向栈顶,EBP寄存器中的偏移地址指向栈底。栈顶由SS和ESP确定,使用push指令进行入栈,并且随着入栈操作的进行,ESP中的偏移地址减小,指向地址更低的内存单元。反之,使用pop指令出栈,随着出栈操作的进行,ESP中的偏移地址增大,指向地址更高的内存单元。另外,pushad和popad分别一次性将8个32位寄存器压栈或出栈。
3.内存与栈地址
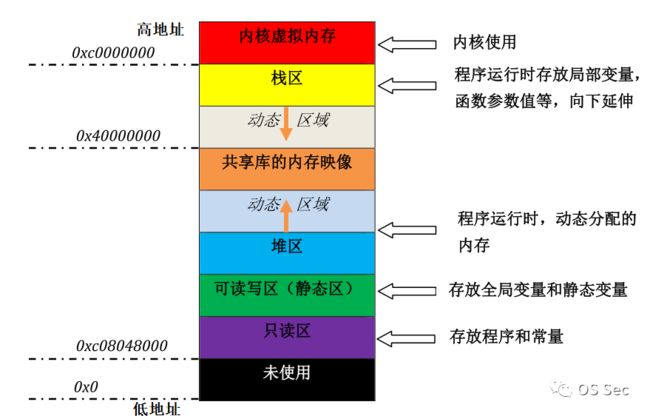
在默认情况下,32位Windows操作系统的地址空间在4GB以内。Win32的平坦内存模式使每个进程都拥有自己的虚拟空间,也称为虚拟内存。对于32位进程来说,这个地址空间是4GB,因为32位指针拥有00000000h~FFFFFFFFh的任何值。虚拟内存不是真正的内存,它通过映射的方法使可用虚拟地址达到4GB,一般每个应用程序可以获得2GB的用户空间虚拟地址,剩下的2GB属于内核空间,留给操作系统自用。在WindowsNT中,应用程序甚至可以获得3GB的虚拟地址。
一般情况下,可编程内存部分分为静态存储区、堆区、栈区(此处仅关注开发过程中会用到的内存区域),具体功能分别如下:
1)静态存储区:内存在程序编译的时候就已经分配完毕,在程序的整个运行期间都存在。该区域主要用于存放静态数据、全局数据和常量,在进程结束后,由操作系统释放。
2)栈区:程序执行时,函数参数、局部变量(包括const局部变量),函数返回地址等都在栈上创建并存储,当前函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
3)堆区:采用动态内存分配的方式实现。通常是程序在运行时用malloc或new申请任意大小的内存,程序员自己负责在适当的时候用free或 delete释放内存。动态内存的生存期可以由开发者自行决定,如果我们不释放内存,程序将在最后才释放掉动态内存。但是,良好的编程习惯应是,如果某动态内存不再使用,就需要将其释放掉。
一般程序的4GB内存的详细使用分配如下图所示:
#图来自网络,侵删
从中我们可以看到,在程序的虚拟内存空间中,栈区地址从高地址向低地址增长,堆区地址从低地址向高地址增长。因此,在汇编中,对于栈来说,常见的两种逻辑表示方式如下图所示:
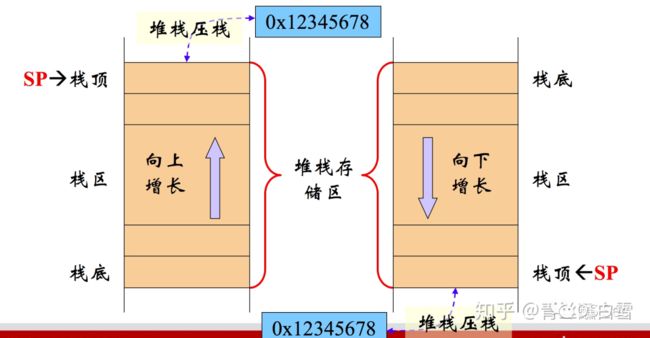 #图来自网络,侵删
#图来自网络,侵删
因此,通常使得初学者容易犯错误的便是如下图所示的情况。通常,在关注栈增长方向的同时,地址增长方向正好是相反的,所以只要记住栈是往内存地址减小的方向增长即可。
#图来自网络,侵删
4.函数与栈
函数作为C/C++语言的重要结构模块,而且程序都是由具有不同功能的函数组成的,因此,对于函数在汇编层面的分析就显得非常重要了。而在函数的代码的执行过程中,栈是用来承载函数所需的计算资源的容器之一,所以本小节将函数和栈一起来举例说明。
函数是一个程序模块,用来实现一个特定的功能,主要由函数名、入口参数、函数体、返回值等部分组成。一般情况下,函数功能的执行需要外部程序对其进行调用,然后在函数功能执行完毕之后,由函数将返回值返回给调用者。在汇编层面,编译器使用call指令来实现对函数的调用,使用ret指令将函数执行结果作为返回值返回给调用者。因此,可以通过对call指令或ret指令的定位与分析来识别一个函数。示例如下:
C源代码如下:
#includevoid test_print(int i){printf("Hello World!\n");}int main(int argc, char* argv[]){test_print(1);return 0;}
对应汇编代码如下(已省略函数堆栈生成部分):
1: #include2: int test_print(int i){3: printf("Hello World!\n");00401038 push offset string "Hello World!\n" (0042201c)0040103D call printf (004010c0)00401042 add esp,44: return i;00401045 mov eax,dword ptr [ebp+8]5: }00401058 ret6: int main(int argc, char* argv[])7: {8: test_print(1);00401088 push 10040108A call @ILT+10(test_print) (0040100f)0040108F add esp,49: return 0;00401092 xor eax,eax10: }004010A4 ret
在该例子中可以看到,使用test_print()函数实现了一个非常简单的输出hello world的功能。在main函数中调用了test_print(),而test_print()中又调用了printf()函数,两次调用过程均使用了call指令来实现。在test_print()函数汇编指令的最后,ret指令作为返回指令返回到main()函数调用处。
5. 栈平衡
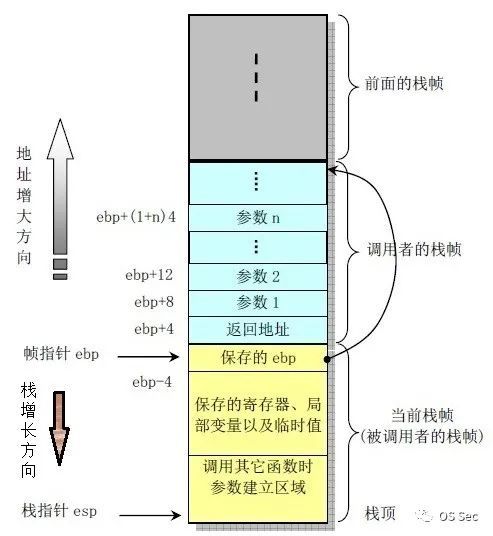
栈平衡的核心是使得函数在调用之前和调用之后的栈空间大小不会发生任何改变。当一个函数在使用call调用另一个函数时,需要对另一个函数进行栈空间的分配和释放。例如,如果被调用的函数有参数、有局部变量,那么在使用call指令开始调用时,需要将参数压栈,初始化为新函数分配的栈空间,并为局部变量分配栈空间。在函数功能执行完毕时,需要对已经分配的栈空间资源进行释放,也就是实现栈平衡(汇编中也称堆栈平衡)。
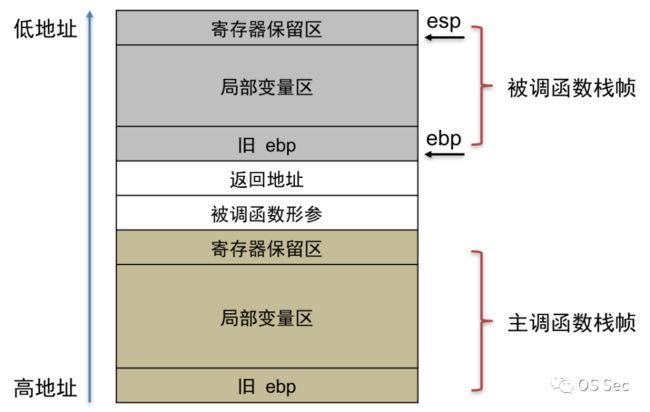
#图来自网络,侵删
如图所示,被调用函数在调用前,主调函数会将其参数压入栈,然后call指令会在改变EIP的同时将返回地址压入栈中(这个返回地址的内容是主调函数中call指令下方的待执行指令,在被调函数遇到ret指令时返回该地址)。接着会保存主调函数的旧EBP地址,然后完成被调函数相关资源分配与命令执行,并在退出被调函数时释放栈空间资源。注意,在C/C++中对栈空间资源的释放,仅仅是在函数执行结束时恢复ESP和EBP为调用前的情况,对于已经使用过的栈空间的遗留数据并不做处理(这既是没有对变量等进行初始化而产生乱码的原因之一,同样也给二进制安全学习者带来了可以进行数据泄露的机会)。
初学者一般接触一门开发语言的时候都会编写一个Hello World测试程序。在这里,我们将C语言的hello world以汇编的方式展现,并通过汇编语言对栈地址空间的影响来分析最基本的汇编代码。示例如下:
我们同样以4.1节中的C语言代码为例,主要分析一个函数在调用前后的栈空间变化。main()函数是主调函数,test_print()函数是被调函数,所以只需要主要关注test_print()函数对应的汇编代码即可(main()函数情况类似,所以不做过多解释)。下方是完整版的汇编代码:
1: #include2: int test_print(int i){00401020 push ebp00401021 mov ebp,esp00401023 sub esp,40h00401026 push ebx00401027 push esi00401028 push edi00401029 lea edi,[ebp-40h]0040102C mov ecx,10h00401031 mov eax,0CCCCCCCCh00401036 rep stos dword ptr [edi]3: printf("Hello World!\n");00401038 push offset string "Hello World!\n" (0042201c)0040103D call printf (004010b0)00401042 add esp,44: return i;00401045 mov eax,dword ptr [ebp+8]5: }00401048 pop edi00401049 pop esi0040104A pop ebx0040104B add esp,40h0040104E cmp ebp,esp00401050 call __chkesp (00401130)00401055 mov esp,ebp00401057 pop ebp00401058 ret---------------------------------------------------------------------6: int main(int argc, char* argv[])7: {00401070 push ebp00401071 mov ebp,esp00401073 sub esp,40h00401076 push ebx00401077 push esi00401078 push edi00401079 lea edi,[ebp-40h]0040107C mov ecx,10h00401081 mov eax,0CCCCCCCCh00401086 rep stos dword ptr [edi]8: test_print(1);00401088 push 10040108A call @ILT+15(test_print) (00401014)0040108F add esp,49: return 0;00401092 xor eax,eax10: }00401094 pop edi00401095 pop esi00401096 pop ebx00401097 add esp,40h0040109A cmp ebp,esp0040109C call __chkesp (00401130)004010A1 mov esp,ebp004010A3 pop ebp004010A4 ret
根据汇编代码画出下方栈空间变化图:
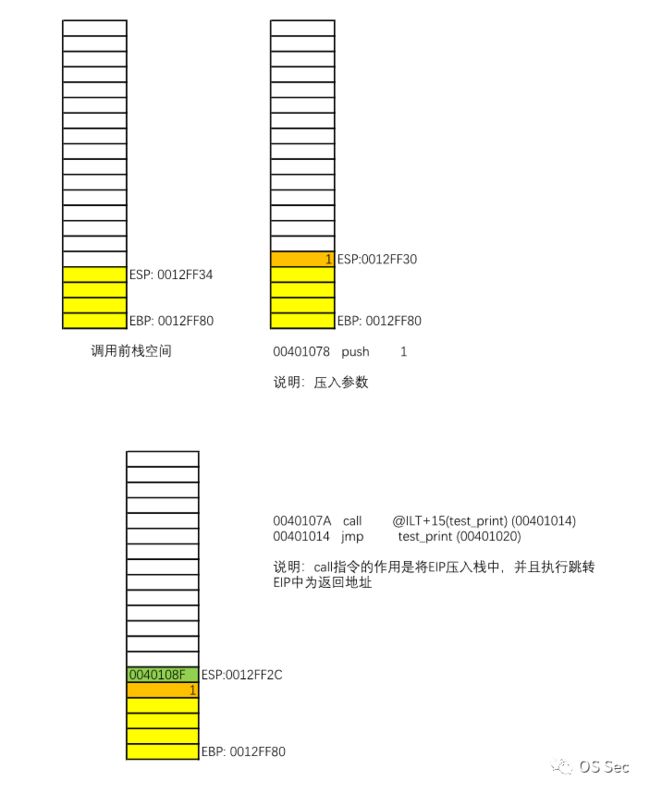
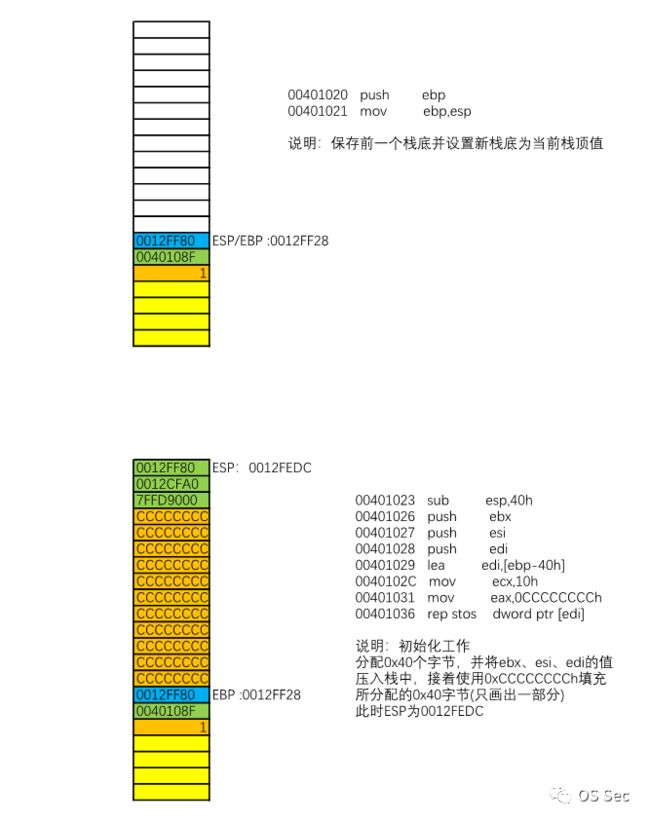

通过这三个图可以看出,一个函数在调用之前和调用完成后,栈空间大小和地址是不会发生改变的,但被调函数执行完毕后的遗留数据是存在于栈中的。
6.函数参数传递
函数传递参数有3种方式,即栈方式传递、寄存器方式传递以及通过全局变量进行隐含参数传递等方式。如果参数是通过栈传递的,就需要定义参数在栈中的顺序,并约定函数被调用后由谁来平衡栈。如果参数是通过寄存器传递的,就要确定参数存放在哪个寄存器中。每种机制都有其优缺点,且与使用的编译语言有关。
6.1 调用约定
在将源代码进行编译的过程中,函数的调用需要遵循一定的规则,确定参数的入栈顺序和谁来平衡栈的问题。将源代码编译为汇编代码时,由于编译版本的不同和从效率方面的考虑,存在多种调用约定。因此,存在以下几种常见的调用约定:

#图来自网络,侵删
在对汇编程序进行分析时,熟悉这些调用约定能够帮助我们正确的分析程序结构和逻辑关系。通常__cdecl是C/C++程序默认的调用约定,将函数的参数按照从右到左的方式入栈,由调用者平衡栈空间(外平栈)。pascal将参数按照从左到右的方式入栈,由被调函数平衡栈空间(内平栈)。stdcall是win32 API采用的调用约定方式,将参数从右到左入栈,由被调函数平衡栈空间(内平栈)。下图为这三种调用约定的比较:

#图来自网络,侵删
fastcall采用寄存器和栈相结合的方式传递参数,若参数少于指定个数,如2个时,那么这些参数均通过寄存器来传递,若多于指定参数个数时,多出来的部分使用栈传递参数,以此进一步提高效率。fastcall也是将参数从右至左入栈,多于寄存器个数的参数使用栈空间传递,不同的编译器在实现fastcall时稍有不同,所以指定用于传递参数的寄存器个数有所不同(VC++中使用的寄存器是ECX和EDX,即将两个参数放入寄存器中传递)。
6.2 确定参数个数
通常,在分析汇编代码时是无法看到任何有关源代码的重要信息的,而且汇编代码需要一次性浏览多行代码,进而从其中分析出逻辑结构。在分析一个被调用的函数时,参数个数的确定是很重要的一步,由此才能确定栈内存空间的具体使用情况和汇编代码逻辑结构。
关于参数个数的确定,那么首先需要考虑的就是6.1中提到的调用约定。因为在不同的调用约定下,寄存器、栈空间以及平衡栈操作的不同,会造成不同的现象。我们可以看到,除了fastcall之外的其他三种调用约定都是不使用寄存器传参的,而调用一个函数时会使用call指令,这个被调函数的参数往往是在这个call指令之前使用push指令完成的。参数个数的确定,第一步需要对push指令(下方紧接着call指令)的计数来大致了解参数的范围,不过准确的参数个数确定需要看被调函数的ret指令或call指令下方紧接着的add指令中的数据。
因此,具体被调函数参数个数的通用方法可以通过如下步骤完成(当然,最稳妥的办法也只能是逐行分析)。首先,查看被调函数中的寄存器使用情况,如果寄存器使用前没有在函数中进行被赋值等类似操作,却直接拿来使用,那么这些直接使用的寄存器极有可能是用来参数传递的,确定其个数。其次,确定ret指令或call指令下方add指令的数值,除去数据宽度即为栈中的参数个数。最后,将寄存器中的个数和栈中的个数相加即为被调函数的参数个数。
6.3 名称修饰约定
为了允许使用操作符和函数重载,C++编译器往往会按照某种规则改写每一个入口点的符号名,从而允许同一个名字(具有不同的参数类型或者不同的作用域)有多个用法且不会破坏现有的基于C的链接器。这项技术通常称为名称改变或名称修饰,许多C++编译器厂商都制定有自己的名称修饰方案。在VC++中,函数修饰名由编译类型(C或C++)、函数名、类名、调用约定、返回类型、参数等因素共同决定。
C语言编译时函数名修饰约定规则如下:
1. stdcall调用约定在输出函数名前面加一个下划线前缀,在后面加一个“@”符号和其参数的字节数,格式为“_functionname@number”;
2.__cdecl调用约定尽在输出函数名前面加一个下划线前缀,格式为“_functionname”;
3.Fastcall调用约定在输出函数名前面加一个“@”符号,在后面加一个“@”符号和参数的字节数,格式为“@functionname@number”。
它们均不改变输出函数名中的字符大小写。这与pascal不同,pascal调用约定输出的函数名不能有任何修饰且全部为大写。
C++编译时函数名修饰约定规则如下:
1.stdcall以“?”表示函数名的开始,后跟函数名;在函数名后面,以“@@YG”表示参数表的开始,后跟参数表;参数表的第一项为该函数的返回值类型,其后依次为参数的数据类型,指针表示在其所指数据两类型前;在参数表后面,以“@Z”表示整个名字的结束(如果该函数没有参数,则以“Z”标识结束)。其格式为“?functionname@@YG*****@Z”或“?functionname@@YG*XZ“。
2.__cdecl与fastcall与stdcall的规则相同,只是__cdecl参数表的开始标识由“@@YG”变为“@@YA”,fastcall参数表开始变为“@@YI”。
7.裸函数
在C/C++中,一个函数里面没有任何执行语句时,编译器也会为这个函数生成栈空间初始化指令和平衡栈空间指令,这样做的能够防止内存泄露和一定程度上的程序稳定运行。如下所示:
1: #include2: int test_print(){00401020 push ebp00401021 mov ebp,esp00401023 sub esp,40h00401026 push ebx00401027 push esi00401028 push edi00401029 lea edi,[ebp-40h]0040102C mov ecx,10h00401031 mov eax,0CCCCCCCCh00401036 rep stos dword ptr [edi]3:}00401048 pop edi00401049 pop esi0040104A pop ebx0040104B add esp,40h0040104E cmp ebp,esp00401050 call __chkesp (00401130)00401055 mov esp,ebp00401057 pop ebp00401058 ret
而在使用汇编语言时,我们可以使用__declspec(naked)关键字创建裸函数,在被这个关键字修饰时,编译器不会对其进行任何处理,其中的全部汇编层面代码自行编写,可配合__asm结构用于特殊环境需求下和学习汇编时使用。

8.变量与寻址方式
在逆向分析过程中,数据结构的确定是算法分析的基础,而最基本的数据结构就是变量。
8.1 栈寻址
在栈空间中,通常对于参数、变量等具体内容的获取会通过相对寻址的方式来得到,如基于ebp或基于esp的方式寻址得到。如下图所示,向上为栈地址增长方向,向下为栈空间增长方向。在函数被调用前,主调函数会将被调函数的参数入栈,此时会使用[ebp+xxxx]的形式寻址,因为参数是从右向左入栈的,所以[ebp+08]为第一个参数,[ebp+0C]为第二个参数,以此类推。相对的,使用[ebp-xxxx]的形式表示局部变量。
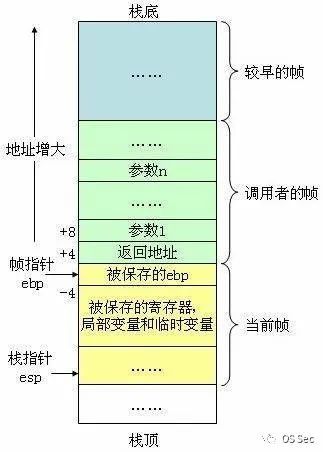
#图来自网络,侵删
8.2 局部变量
局部变量是在函数内部定义的变量,其作用域和生命周期局限于所在函数之内。从汇编的角度看,局部变量分配空间时通常会使用栈和寄存器。编译器在优化模式时,通过esp寄存器直接对局部变量和参数进行寻址。当函数退出时,使用类似于“add esp,8”的指令来平衡栈,以释放局部变量占用的内存。
除了栈占用的esp、ebp寄存器之外,编译器会利用剩下的6个通用寄存器尽可能的有效存放局部变量,这样可以减少代码,提高效率。若寄存器不够时,编译就会扩展到栈中,因为局部变量生存周期较短,所以通常在分析时需要及时的确定才行。栈中的局部变量一般不会出现源代码中的变量名称,会通过[ebp-xxxx]的形式进行调用。
8.3 全局变量
全局变量作用于整个程序,它一直存在,放在全局变量的内存区中。局部变量则存在于函数的栈区中,函数调用结束后便会消失。在大多数程序中,常数一般放在全局变量中,例如注册版标记、测试版标记等。全局变量通常位于数据区块(.data)的一个固定地址处,当程序需要访问全局变量时,一般会用一个固定的硬编码地址直接对内存进行寻址,如下所示:
mov eax, dword ptr [4084c0h]全局变量可以被同一个文件中的所有函数修改,如果某个函数改变了全局变量的值,就能影响其他函数(相当于函数间传递通道),因此,可以利用全局变量来传递参数和函数返回值等。全局变量在执行的整个执行过程中占用内存单元,而不像局部变量那样在需要时才开辟内存单元。
与全局变量类似的是静态变量,他们都可以按直接方式寻址。但不同的是,静态变量的作用范围是有限的,尽在定义这些变量的函数内有效。
8.4 函数返回值
函数被调执行后,会向主调函数返回执行结果,即是函数返回值。通常,函数的返回值都是放在eax寄存器中返回,在被调函数执行结束前,会将需要返回的数据或地址放到eax中,然后再清理栈空间。如果要返回结果的大小超过eax寄存器的宽度(4字节),其高32位就会放在edx中。
参考资料:
-
《新概念汇编语言》,杨季文,2017
-
《黑客防线2009》缓冲区溢出攻击与防范专辑
-
《加密与解密(第4版)》,段钢,2018
-
https://www.it610.com/article/1187272755171663872.htm
博客与公众号同步发文,欢迎关注:
