Linux 内核x
文章目录
- Linux内核学习
-
- 一、什么是 Linux 内核?
-
- 二、Linux 的体系结构
- 三、Linux上下文切换
-
- 1、常识
- 2、用户空间和内核空间--内核功能模块运行在内核空间,而应用程序运行在用户空间。
- 3、进程上下文与中断上下文
- 四、Linux中断
- 五、系统的进程管理
-
- 1、系统进程的运转方式
-
- (1) 系统时间(jiffies 系统滴答)
- 2、如何进行创建一个新的进程
- 3、进程调度
- 4、进程的切换
- 5、进程的退出,销毁
- 6、进程的通信
- 1、**管道(`pipe`),流管道(`s_pipe`和有名管道(`FIFO`)**
-
- (1)管道
- (2)命名管道**(`named pipe `或`FIFO`)**
- (3)消息队列
- (4)信号量
- (5)共享内存
- 六、Linux文件管理系统------一切都是文件。
-
- 一、**开机过程**
- 二、文件管11理系统
-
- 1、概述
- 2、根文件管理系统
-
- (1)目录设计
- (2)根文件系统作用
- (3)文件管理系统与磁盘文件系统的关系
- (4)虚拟文件系统(VFS)
- (5)硬链接和软连接
- 七、Linux虚拟内存管理系统-----一切都是文件。
-
- MemAvailable
- 1、虚拟内存
- 2、虚拟内存和物理内存的关系
- 3、虚拟内存的优点
- 4、page table
- 5、memory mapping
- 6、其他概念
-
- (1)MMU(Memory Management Unit)
- (2)TLB (Translation Lookaside Buffer)
- (3)访问控制
- (4)huge pages
- (5)Caches
- 7、文件系统缓存和匿名页的交换
-
- (1)swap的含义
- (2)页面回收(reclaim)
- (3)其他相关问题
-
- 1) Linux虚拟地址空间如何分布?32位和64位有何不同?
- 2) malloc是如何分配内存的?
- 3) malloc分配多大的内存,就占用多大的物理内存空间吗?
- 4) 如何查看进程虚拟地址空间的使用情况
- 5) free的内存真的释放了吗(还给OS)?
- 6) 既然堆内内存不能直接释放,为什么不全部使用mmap来分配
- 7) 如何查看进程的缺页中断信息?
- 8) 如何查看堆内内存的碎片情况?
Linux内核学习
一、什么是 Linux 内核?
- Linux 系统的核心是内核。内核控制着计算机系统上的所有硬件和软件,在必要时分配硬件,并根据需要执行软件。
- 系统内存管理
- 应用程序管理
- 硬件设备管理
- 文件系统管理
二、Linux 的体系结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9nE9r4mQ-1616393529705)(C:\Users\Administrator\Desktop\interview_python-master\img\linux体系结构.png)]
- 用户空间(User Space) :用户空间又包括用户的应用程序(User Applications)、C 库(C Library) 。
- 内核空间(Kernel Space) :内核空间又包括系统调用接口(System Call Interface)(系统的服务层)、内核(Kernel)、平台架构相关的代码(Architecture-Dependent Kernel Code) 。
三、Linux上下文切换
1、常识
操作系统运行过程中,时刻进行着各种上下文的相互切换:
- 用户空间和内核空间
- 进程上下文与中断上下文
- 不同进程上下文之间
2、用户空间和内核空间–内核功能模块运行在内核空间,而应用程序运行在用户空间。

- 动机:
- 为了实现系统稳定,对资源的有效利用以及多任务切换等操作,需要操作系统拥有绝对的控制权;这就需要将操作系统与用户进程隔离,使运行在其上的用户进程受限直接执行(LDE,Limited Direct Execution),以防止其长期霸占CPU执行,修改系统敏感资源、配置,窃取其他用户进程的用户信息等;
- 另外如果用户进程发生错误(如除零,解引用空指针等),也希望不会影响到操作系统和其他用户进程的正常运行。
- 用户进程在用户空间和内核空间的区别------一个用户进程运行在用户空间和运行在内核空间有什么区别呢?
- 首先,每个用户进程都拥有自己的用户栈和内核栈,因此需要切换栈;
- 然后,每个用户进程都有进程地址空间,进程地址空间又分别用户地址空间和内核地址空间,
- 所有进程(包括内核线程)共享内核地址空间,但拥有自己的用户地址空间,
- 地址空间就是一套用于翻译虚拟地址到物理地址的页表,全局页目录基地址存放在特定寄存器中(EL0与EL1对应不同的寄存器),因此需要切换硬件MMU翻译时读取的页表基址寄存器;
- 最后,用户进程在进入内核空间,然后返回用户空间时需要恢复之前的状态继续执行,因此需要save和restore硬件上下文信息,比如处理器状态,pc指针等。
- 切换场景有哪些
- 首先,用户进程如果想要主动的执行一些特权操作,如read/write某个设备文件时,便会通过各种系统调用陷入内核,完成对应操作会再次返回用户空间;、
- 如程序调用
malloc函数,调用sbrk()的时候就涉及一次从用户态到内核态的切换
- 如程序调用
- 其次是中断,当用户进程运行在用户空间时,如果此时发生某个外设中断,会马上陷入内核,执行相应的中断处理程序,执行完后会再次返回用户空间;
- 该机制可保证系统对外部事件(如键盘、鼠标)的快速响应,提升系统交互性能,
- 也是操作系统夺回控制权的主要手段之一(时钟中断,也是驱动进程调度的核心);
- 上述的两种场景其实都属于异常,
- 系统调用属于同步异常,除此之外还有数据中止、指令中止和调试异常等;
- 中断属于异步异常,除此之外还有系统错误等,这些异常都会导致用户空间与内核空间的切换
- 以上场景都是用户进程陷入内核然后返回用户空间的模式,我们知道所有的用户进程都是1号用户进程或者其子孙进程
fork出来的,但Linux系统初始化时创建的都是内核线程,因此还有一种场景是1号内核线程演变为1号用户进程时,会装载init程序,然后由内核空间切换到用户空间,从而形成1号用户进程。
- 首先,用户进程如果想要主动的执行一些特权操作,如read/write某个设备文件时,便会通过各种系统调用陷入内核,完成对应操作会再次返回用户空间;、
- 用户态和内核态:
- Intel的X86架构的CPU提供了
0到3四个特权级,数字越小,特权越高。Linux操作系统中主要采用了0和3两个特权级,分别对应的就是内核态和用户态。内核态和用户态有自己的内存映射,即自己的地址空间。- 运行于用户态的进程可以执行的操作和访问的资源都会受到极大的限制,
- 用户态是可以强占
move_to_user_mode()函数将内核从内核态切换到用户态
- 而运行在内核态的进程则可以执行任何操作并且在资源的使用上没有限制。
- 内核态不可抢占,即不能进行进程的切换
- 很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程。
- Intel的X86架构的CPU提供了
- 内核态:
- 运行于进程上下文,内核代表进程运行于内核空间
- 运行于中断上下文,内核代表硬件运行于内核空间
- 用户态:
- 运行于进程上下文,运行于用户空间
3、进程上下文与中断上下文
-
上下文context: 上下文简单说来就是一个环境。
- 用户空间的应用程序,通过系统调用,进入内核空间。这个时候用户空间的进程要传递很多变量、参数的值给内核,内核态运行的时候也要保存用户进程的一些寄存 器值、变量等。
-
进程上下文:用户进程传递给内核的这些参数以及内核要保存的那一整套的变量和寄存器值和当时的环境等。
- 对进程而言:进程执行时的环境。具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件、内存信息等。
- 一个进程的上下文可以分为三个部分:
- 用户级上下文、寄存器上下文以及系统级上下文。
- 用户级上下文: 正文、数据、用户堆栈以及共享存储区;
- 寄存器上下文: 通用寄存器、程序寄存器(
IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP); - 系统级上下文: 进程控制块
task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈。
- 用户级上下文、寄存器上下文以及系统级上下文。
- 当发生进程调度时,进程切换就是上下文切换(context switch)。
- 操作系统必须对上面提到的全部信息进行切换,新调度的进程才能运行。
- 而系统调用进行的模式切换(mode switch)。模式切换与进程切换比较起来,容易很多,而且节省时间,因为模式切换最主要的任务只是切换进程寄存器上下文的切换。
-
硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。
- “ 中断上下文”:硬件传递过来的这些参数和内核需要保存的一些其他环境(主要是当前被打断执行的进程环境)。
- 中断时,内核不代表任何进程运行,它一般只访问系统空间,而不会访问进程空间,内核在中断上下文中执行时一般不会阻塞。
-
运行在中断上下文的代码就要受一些限制,不能做下面的事情(运行于内核态的代码也受同样的限制):
- 睡眠或者放弃CPU。
- 这样做的后果是灾难性的,因为内核在进入中断之前会关闭进程调度,一旦睡眠或者放弃CPU,这时内核无法调度别的进程来执行,系统就会死掉
- 尝试获得信号量
- 如果获得不到信号量,代码就会睡眠,会产生和上面相同的情况
- 执行耗时的任务
- 中断处理应该尽可能快,因为内核要响应大量服务和请求,中断上下文占用CPU时间太长会严重影响系统功能。
- 访问用户空间的虚拟地址
- 中断上下文是和特定进程无关的,它是内核代表硬件运行在内核空间,所以在中断上下文无法访问用户空间的虚拟地址
- 睡眠或者放弃CPU。
四、Linux中断
-
中断:在CPU正常运行期间,由于内,外部事件,由程序预先安排的事件引起的CPU暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。
- Linux中通常分为外部中断(又叫硬件中断)和内部中断(又叫异常)
- 实地址模式中,CPU把内存中从
0开始的1KB空间作为一个中断向量表。- 表中的每一项占4个字节。但是在保护模式中,有这4个字节的表项构成的中断向量表不满足实际需求,于是根据反映模式切换的信息和偏移量的足够使得中断向量表的表项由8个字节组成,
- 中断向量表也叫做了
中断描述符表(IDT)。在CPU中增加了一个用来描述中断描述符表寄存器(IDTR),用来保存中断描述符表的起始地址。
-
Linux中断分为
- 硬中断 :由硬件设备触发的中断。I/O设备要产生硬中断时,会由中断控制器发送一个电信号,内核的设备驱动程序接收到这个电信号,就会调用相应的中断处理函数对这个中断进行处理。
- 硬中断可以在任何时刻到来,它代表的系统必须马上处理的紧急任务,也简称为中断的上半部,
- 处于中断上下文中
- 由硬件产生,如磁盘,网卡,键盘,时钟。
- 软中断:中断下半部(
buttom half),也称为软中断,代表的系统不必马上处理的、没那么紧急的任务。- 软中断处理函数一般在硬中断处理函数的末尾调用
- 处于“进程上下文”
- 进程上下文:每个用户进程都可以分为用户态和内核态,一般情况下进程运行在用户态,当进程调用系统调用函数时,会进入内核态,这个时候进程就处于内核态的“进程上下文”中,当然内核的线程也属于进程上下文,如ksoftirqd线程。所以内核态有两种上下文,
- 通常为
I/O请求,这些请求会调用内核中可以调度I/O的程序
- 硬中断 :由硬件设备触发的中断。I/O设备要产生硬中断时,会由中断控制器发送一个电信号,内核的设备驱动程序接收到这个电信号,就会调用相应的中断处理函数对这个中断进行处理。
-
Linux中断处理
-
系统中断号:系统中断向量表中共可保存256个中断向量入口,即
IDT中包含的256个中断描述符(对应256个中断向量)。-
0-31号中断向用来处理异常事件,不能另作它用。- 对这 0-31号中断向量,操作系统只需提供异常的处理程序,当产生一个异常时,处理机就会自动把控制转移到相应的处理程序的入口,运行相应的处理程序;而
- 对于这32个处理异常的中断向量,2.6版本的 Linux只提供了0-17号中断向量的处理程序,其对应处理程序参见下表、中断向量和异常事件对应表;也就是说,17-31号中断向量是空着未用的。
中断向量号 异常事件 Linux的处理程序 0 除法错误 Divide_error 1 调试异常 Debug 2 NMI中断 Nmi 3 单字节,int 3 Int3 4 溢出 Overflow 5 边界监测中断 Bounds 6 无效操作码 Invalid_op 7 设备不可用 Device_not_available 8 双重故障 Double_fault 9 协处理器段溢出 Coprocessor_segment_overrun 10 无效TSS Incalid_tss 11 缺段中断 Segment_not_present 12 堆栈异常 Stack_segment 13 一般保护异常 General_protection 14 页异常 Page_fault 15 (intel保留) Spurious_interrupt_bug 16 协处理器出错 Coprocessor_error 17 对齐检查中断 Alignment_check
-
-
-
中断请求
-
中断请求:外部设备当需要操作系统做相关的事情的时候,会产生相应的中断。
-
过程:
- 设备通过相应的中断线向中断控制器发送高电平以产生中断信号,操作系统则会从中断控制器的状态位取得那根中断线上产生的中断。
- 只有在设备在对某一条中断线拥有控制权,才可以向这条中断线上发送信号
- 也由于现在的外设越来越多,中断线又是很宝贵的资源不可能被一一对应。在使用中断线前,就得对相应的中断线进行申请。
- 无论采用共享中断方式还是独占一个中断,申请过程都是先讲所有的中断线进行扫描,得出哪些没有别占用,从其中选择一个作为该设备的
IRQ。其次,通过中断申请函数申请相应的IRQ。最后,根据申请结果查看中断是否能够被执行。
- 无论采用共享中断方式还是独占一个中断,申请过程都是先讲所有的中断线进行扫描,得出哪些没有别占用,从其中选择一个作为该设备的
- 也由于现在的外设越来越多,中断线又是很宝贵的资源不可能被一一对应。在使用中断线前,就得对相应的中断线进行申请。
-
中断相关结构
-
中断中核心处理数据结构为
irq_desc,它完整的描述了一条中断线,Linux 2.6。22.6中源码如下。 -
struct irqaction { irq_handler_t handler; unsigned long flags; cpumask_t mask; const char *name; void *dev_id; struct irqaction *next; int irq; struct proc_dir_entry *dir; };
-
-
中断请求实现---------上下半部机制
- 让中断处理程序运行得快,并想让它完成的工作量多,这两个目标相互制约,如何解决——上下半部机制。
- 中断处理切为两半。
- 中断处理程序是上半部——接受中断,立即开始执行,但只有做严格时限的工作。
- 能够被允许稍后完成的工作会推迟到下半部去,此后,在合适的时机,下半部会被开终端执行。上半部简单快速,执行时禁止一些或者全部中断。
- 下半部稍后执行,由内核中断,而且执行期间可以响应所有的中断。
- 优点:
- 可以使系统处于中断屏蔽状态的时间尽可能的短,以此来提高系统的响应能力。
- 上半部只有中断处理程序机制,而下半部的实现有软中断实现,
tasklet实现和工作队列实现。
- 实例:
- 当网卡接受到数据包时,通知内核,触发中断,
- 所谓的上半部就是,及时读取数据包到内存,防止因为延迟导致丢失,这是很急迫的工作。
- 读到内存后,对这些数据的处理不再紧迫,此时内核可以去执行中断前运行的程序,而对网络数据包的处理则交给下半部处理。
- 当网卡接受到数据包时,通知内核,触发中断,
-
上下半部划分原则
- 如果一个任务对时间非常敏感,将其放在中断处理程序中执行;
- 如果一个任务和硬件有关,将其放在中断处理程序中执行;
- 如果一个任务要保证不被其他中断打断,将其放在中断处理程序中执行;
- 其他所有任务,考虑放置在下半部执行。
-
-
软中断
- 软中断,下半部机制的代表,是随着SMP(
share memory processor)的出现应运而生的,它也是tasklet实现的基础(tasklet实际上只是在软中断的基础上添加了一定的机制)。 - 软中断一般是可延迟函数的总称,包括了
tasklet。它的出现就是因为要满足上面所提出的上半部和下半部的区别,使得对时间不敏感的任务延后执行,软中断执行中断处理程序留给它去完成的剩余任务,而且可以在多个CPU上并行执行,使得总的系统效率可以更高。它的特性包括:- 产生后并不是马上可以执行,必须要等待内核的调度才能执行。软中断不能被自己打断,只能被硬件中断打断(上半部)。
- 可以并发运行在多个CPU上(即使同一类型的也可以)。所以软中断必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保护其数据结构。
- 软中断,下半部机制的代表,是随着SMP(
-
tasklet
tasklet是通过软中断实现的,所以它本身也是软中断。- 软中断用轮询的方式处理。假如正好是最后一种中断,则必须循环完所有的中断类型,才能最终执行对应的处理函数。显然当年开发人员为了保证轮询的效率,于是限制中断个数为32个。
Tasklet采用无差别的队列机制,有中断时才执行,免去了循环查表之苦。Tasklet作为一种新机制,显然可以承担更多的优点。正好这时候SMP越来越火了,因此又在tasklet中加入了SMP机制,保证同种中断只能在一个cpu上执行。在软中断时代,显然没有这种考虑。因此同一种软中断可以在两个cpu上同时执行,很可能造成冲突。- 总结下tasklet的优点:
- 无类型数量限制;
- 效率高,无需循环查表;
- 支持SMP机制;
- 它的特性如下:
- 一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行。
- 多个不同类型的tasklet可以并行在多个CPU上。
- 软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。
-
下半部实现机制之工作队列(work queue)
- 动机:
- 软中断不能睡眠、不能阻塞。由于中断上下文出于内核态,没有进程切换,所以如果软中断一旦睡眠或者阻塞,将无法退出这种状态,导致内核会整个僵死。但可阻塞函数不能用在中断上下文中实现,必须要运行在进程上下文中,例如访问磁盘数据块的函数。因此,可阻塞函数不能用软中断来实现。但是它们往往又具有可延迟的特性。
- 可阻塞函数不能用软中断来实现。但是它们往往又具有可延迟的特性。而且由于是串行执行,因此只要有一个处理时间较长,则会导致其他中断响应的延迟。为了完成这些不可能完成的任务,于是出现了工作队列,它能够在不同的进程间切换,以完成不同的工作。
- 如果推后执行的任务需要睡眠,那么就选择工作队列,如果不需要睡眠,那么就选择软中断或tasklet。
- 工作队列能运行在进程上下文,它将工作托付给一个内核线程。
- 动机:
-
Linux软中断和工作队列的作用是什么
- Linux中的软中断和工作队列是中断上下部机制中的下半部实现机制。
- 软中断一般是“可延迟函数”的总称,它不能睡眠,不能阻塞,它处于中断上下文,不能进程切换,软中断不能被自己打断,只能被硬件中断打断(上半部),可以并发的运行在多个CPU上。所以软中断必须设计成可重入的函数,因此也需要自旋锁来保护其数据结构。
- 工作队列中的函数处在进程上下文中,它可以睡眠,也能被阻塞,能够在不同的进程间切换,以完成不同的工作。
- 可延迟函数和工作队列都不能访问用户的进程空间,可延时函数在执行时不可能有任何正在运行的进程,工作队列的函数有内核进程执行,他不能访问用户空间地址。
- Linux中的软中断和工作队列是中断上下部机制中的下半部实现机制。
五、系统的进程管理
1、系统进程的运转方式
(1) 系统时间(jiffies 系统滴答)
-
CPU内部有一个系统的内部定时器
RTC,上电时调用mktime函数算出从1970年1月1日0时开始当前开机的时间所过的秒数,给mktime函数传来的时间结构体赋值。是由初始化时从RTC(coms)中读出的参数,转化为时间存入全局变量中,并且会为JIFFIES所用 -
JIFFIES 是一个系统的时钟滴答,一个系统滴答是10ms,定时器
-
每隔10ms会引发一个定时器中断—
timer_interrupt -
中断服务函数中首先进行了
jiffies的自加,调用do_timer函数。-
do_timer-
if (cpl)//CPL变量是内核中用来指示被终端程序的特权,0表示内核进程,1为用户进程 current->utime++;//utime用户程序运行时间 else current->stime++;//内核程序运行时间 -
next_timer是嫁接与jiffies变量的所有定时器的事件链表 -
counter->current,即进程时间片 -
task-struck一个进程task_struck[]进程的向量表,每个进程中都有counter时间片。 -
counter-----在哪儿用:进程的调度,即task_struck[]进程链表中的检索,找时间片counter最大的进程对象,然后进行调用,直到时间片counter为0,退出,之后进行新一轮的调用 -
counter----在哪里被设置。当全部的task_struck[](task[])所有的进程的counter都为0,就进行新一轮的时间片分配 -
分配方式-----优先级分配 :优先级低的时间片小,优先级高的时间片大
-
(*p)-counter = ((*p)->counter>>1)+(*p)->priority
-
-
优先级时间片轮转调度算法:优先级最大分为64级
-
-
-
-
task_struck:进程结构体:state:进程状态counter:时间片counter=counter/ 2 +prioritypriority:进程优先级LDT局部描述符:保存进程所运行的代码段、数据段、TSS进程的状态描述符:在进程运行的过程中,CPU需要知道的进程的状态标识
2、如何进行创建一个新的进程
-
在Linux系统中,除了系统启动之后的第一个进程由系统来创建,其余的进程都必须由已存在的进程来创建。
-
新创建的进程叫做子进程,而创建子进程的进程叫做父进程。那个在系统启动及完成初始化之后,Linux自动创建的进程叫做根进程。根进程是Linux中所有进程的祖宗,其余进程都是根进程的子孙。具有同一个父进程的进程叫做兄弟进程。
-
继承的创建就是对0号进程或者是当前进程的复制
- 0号进程复制:结构体的赋值就是把
task[0]对应的task_struck复制给新创建的task_struck、 - 对于栈堆的拷贝,当进程做创建的时候要复制原有的栈堆,复制后清空
- 0号进程复制:结构体的赋值就是把
-
Linux在初始化的过程中会进行0号进程的创建。
fork函数 -
在内核初始化过程中,会动手创建0号进程。0号进程是所有进程的父继承。
- 在0号进程中,打开标准输入、输出、错误控制台
- 创建01号进程,
- 如果创建成功,则在1号进程中,首先打开
/etc/rc文件 - 执行
shell程序,/bin/sh
- 如果创建成功,则在1号进程中,首先打开
- 0号进程不可能结束
- 只会进行
for(;;),pause()
- 只会进行
fork函数- 在
task链表中找一个进程空位存放当前的进程 - 创建一个
task_struck - 设置
task_struck
- 在
-
继承的创建是系统中断,调用
fork函数-
sys_fork: call find_empty_process .... call copy_process
-
-
创建进程过程
- 给当前要创建的进程分配一个进程号:
find_empty_process - 创建一个子进程的
task_struct结构体 - 将当前的子进程放入整体进程链表中
- 设置创建的
task_struck的属性- 如果父进程打开了某个文件,那么子进程野同样打开这个文件,文件计数也随之加一
- 设置进程的两段,并且结合刚才拷贝过来的,组装成一个进程
- 给程序的状态标志位设置成可运行状态
- 返回新创建进程的PID
- 子进程的继承,
fork出子进程后,子进程都会继承父进程以下信息;- 文件描述符
- 实际用户ID,实际组ID,有效用户ID,有效组ID
- 进程组ID
- 添加组ID
- 对话期ID
- 控制终端
- 设置-用户-ID标志和设置-组-ID标志
- 当前工作目录
- 根目录
- 文件方式创建字
- 信号屏蔽和排列
- 对任意打开文件描述符大的在执行时关闭标志。
- 环境
- 链接的共享存储段
- 资源限制
- 父子进程间的区别
- fork的返回值
- 进程ID
- 不同的父进程ID
- 子进程的
tms_utime,tms_stime,tms_sutime,tms_ustime设置为0 - 父进程设置的锁,子进程不继承
- 子进程的未决告警被清除
- 子进程的未决信号集设置为空集
- 子进程的继承,
- 给当前要创建的进程分配一个进程号:
-
./a.out底层指向过程- linux系统中每个程序都运行在一个进程上下文中,这个进程上下文有自己的虚拟地址空间。当shell运行一个程序时,父shell进程生成一个子进程,它是父进程的一个复制品。
- 子进程通过
execve系统调用启动加载器。加载器删除子进程已有的虚拟存储段,并创建一组新的代码、数据、堆、栈段,新的堆和栈被初始化为零。通过将虚拟地址空间中的页映射到可执行文件的页大小组块,新的代码和数据段被初始化为可执行文件的内容,最后将CUP指令寄存器设置成可执行文件入口,启动运行。 - 执行完上述操作后,其实可执行文件的真正指令和数据都没有别装入内存中。操作系统只是通过可执行文件头部的信息建立起可执行文件和进程虚拟内存之间的映射关系而已。现在程序的入口地址为
0x08048000,刚好是代码段的起始地址。当CPU打算执行这个地址的指令时,发现页面0x8048000~0x08049000(一个页面一般是4K)是个空页面,于是它就认为是个页错误。此时操作系统根据虚拟地址空间与可执行文件间的映射关系找到页面在可执行文件中的偏移,然后在物理内存中分配一个物理页面,并在虚拟地址页面与物理页面间建立映射,最后把文件中页面拷贝到物理页面,进程重新开始执行。
3、进程调度
-
进程的状态:
-
运行状态:可以被运行,就绪状态,进程切换只有在运行状态
-
可中断睡眠状态:可以被信号中断,使其变为
RUNNING -
不可中断睡眠状态:只能被
wakeup唤醒变为RUNNING -
暂停状态:收到信号
SIGSTOP等信号 -
僵死状态:进程停止运行了,但是父进程没有
-
#define TASK_RUNNING 0 #define TASK_INTERRUPTIBLE 1 #define TASK_UNINTERRUPTIBLE 2 #define TASK_ZOMBIE 3 #define TASK_STOPPD 4
-
-
switch_to()进程切换函数- 将需要切换的进程赋值给当前指针
- 进行进程的上下文切换
- 上下文:程序运行时,需要的CPU的特殊寄存器,通用寄存器(TSS)等,+当前堆栈的信息
-
schedule进程调度函数
4、进程的切换
-
进程切换
- 进程切换就是为了控制进程的执行,内核挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的行为。
-
什么时候会切换?
- 发生
schedule()的时候。
- 发生
-
都要切换什么?
- 切换地址空间、内核态堆栈和硬件上下文。
-
硬件上下文是什么?
- 进程切换的时候,要把被切出的进程的一些寄存器信息存起来,等到再切回这个进程的时候,要把这组之前存起来的这组数据再写回寄存器里。包括存储着当前指令地址的eip寄存器,当前栈地址的esp寄存器等等。进程恢复时必须装进寄存器的一组数据,就叫做硬件上下文。
5、进程的退出,销毁
exit()是销毁函数-------系统中断调用函数------do_exit()- 首先该函数会释放进程的代码段和数据段占用的内存
- 关闭打开的所有文件,对当前的目录和innode节点进行同步
- 如果当前要销毁的子进程,就让1号进程作为新的符进程
- 如果当前进程是一个会话头进程,则会终止会话中的所有进程
- 改变当前进程的运行状态,变成僵死状态,并且向其父进程发送
SIGCHLD信号
- 父进程在运行子进程时,运行
wait,waitpid这两个函数- 当父进程收到
SIGCHLD信号时,父进程会终止僵死状态的子进程:- 将子进程的运行时间累加到自己的进程变量中
- 把对应的子进程的进程描述结构体进行释放,置空任务数组中的空槽
- 当父进程收到
6、进程的通信
- 管道(pipe),流管道(s_pipe)和有名管道(FIFO)
- 信号(signal)
- 消息队列
- 共享内存
- 信号量
- 套接字(socket)
1、管道(pipe),流管道(s_pipe和有名管道(FIFO)
(1)管道
-
管道
-
管道(
pipe)是Unix/Linux中最常见的进程间通信方式之一,它在两个进程之间实现一个数据流通的通道,数据以一种数据流的方式在进程间流动。 -
在系统中,管道相当于文件系统上的一个文件,用于缓存所要传输的数据。
-
在某些特性上又不同于文件,例如当数据读出后,管道中就没有数据了,但文件没有这个特性。管道有两个特点:
- 部分系统下的管道是半双工的,数据在同一时间只能向一个方向流动。从实现的角度看,Linux内核采用环形缓冲区实现管道,如果允许同时读写,可能会导致数据冲突,Linux采用锁机制来防止同时读写。
- 管道通常来说只能在具有亲属关系(父子进程、兄弟进程)的进程间使用。
为用户在shell中提供了相应的管道操作符“
|”。操作符“|”将其前后两个命令连接到一起,前一个命令的输出成为后一个命令的输入,且可以支持使用多个“|”连接多个命令
-
-
管道通信的限制:
- 半双工的通信,数据只能单向流动
- 只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
-
实现
-
/** * struct pipe_buffer - a linux kernel pipe buffer * @page: the page containing the data for the pipe buffer * @offset: offset of data inside the @page * @len: length of data inside the @page * @ops: operations associated with this buffer. See @pipe_buf_operations. * @flags: pipe buffer flags. See above. * @private: private data owned by the ops. **/ struct pipe_buffer { struct page *page; unsigned int offset, len; const struct pipe_buf_operations *ops; unsigned int flags; unsigned long _private; }; /** * struct pipe_inode_info - a linux kernel pipe * @mutex: mutex protecting the whole thing * @wait: reader/writer wait point in case of empty/full pipe * @nrbufs: the number of non-empty pipe buffers in this pipe * @buffers: total number of buffers (should be a power of 2) * @curbuf: the current pipe buffer entry * @tmp_page: cached released page * @readers: number of current readers of this pipe * @writers: number of current writers of this pipe * @files: number of struct file referring this pipe (protected by ->i_lock) * @waiting_writers: number of writers blocked waiting for room * @r_counter: reader counter * @w_counter: writer counter * @fasync_readers: reader side fasync * @fasync_writers: writer side fasync * @bufs: the circular array of pipe buffers * @user: the user who created this pipe **/ struct pipe_inode_info { struct mutex mutex; wait_queue_head_t wait; unsigned int nrbufs, curbuf, buffers; unsigned int readers; unsigned int writers; unsigned int files; unsigned int waiting_writers; unsigned int r_counter; unsigned int w_counter; struct page *tmp_page; struct fasync_struct *fasync_readers; struct fasync_struct *fasync_writers; struct pipe_buffer *bufs; struct user_struct *user; }; -
当进程创建一个匿名管道时,Linux内核为匿名管道准备了两个文件描述符:一个用于管道的输入,即在管道中写入数据;另一个用于管道的输出,也就是从管道中读出数据。
-

-
-
Linux的管道操作
-
#include#include #include #include #include int main() { int fd[2]; pid_t pid; char buf[20]; if (pipe(fd) < 0) { std::cerr << "创建管道失败\n"; exit(0); } if ((pid = fork()) < 0) { std::cerr << "创建子进程失败\n"; exit(0); } if (pid == 0) //子进程 { close(fd[1]); //关闭写入端 read(fd[0], buf, sizeof(buf)); std::cout << buf; exit(0); } else { close(fd[0]); //关闭读出端 write(fd[1], "I'm your father.\n", 17); if (waitpid(pid, NULL, 0) != pid) { std::cerr << "销毁进程失败\n"; } } exit(0); } #include #include #include int main() { int fd[2]; //创建文件描述符数组 char writebuf[20] = {"Hello World!"}; //写缓冲区 char readbuf[20]; //读缓冲区 if (pipe(fd) < 0) { std::cerr << "创建管道失败\n"; exit(0); } write(fd[1], writebuf, sizeof(writebuf)); //向管道写入端写入数据 read(fd[0], readbuf, sizeof(readbuf)); //向管道读出端读出数据 std::cout << readbuf << "\n"; std::cout << "管道的读fd是" << fd[0] << "\n写fd是" << fd[1] << std::endl; return 0; }
-
(2)命名管道**(named pipe或FIFO)**
-
命名管道(Named Pipe):不仅可在同一台计算机的任意不同进程之间通信,而且还可以在跨越一个网络的不同计算机的不同进程之间,支持可靠的、单向或双向的数据通信。
-
命名管道不同于管道之处在于它提供一个路径名与之关联,以命名管道的文件形式存在于文件系统中。
- 这样,即使与命名管道的创建进程不存在亲缘关系的进程,只要能够访问该路径,就能够彼此通过命名管道相互通信。
-
虽然管道和命名管道都是实实在在的文件,但前者没有公开的文件名,用户在文件系统中不能直接观察并访问到它;命名管道则是存在于文件系统中的,任何具有访问权限的进程都可以访问。
-
管道和命名管道的区别总结如下:
- 命名管道可以用于任意两个进程间的通信,并不限制这两个进程同源,因此命名管道的使用比管道的使用要灵活方便得多。
- 命名管道作为一种特殊的文件存在于文件系统中,而不像管道一样只存在于内存中(使用完毕就会消失)。当进程对命名管道的使用结束后,命名管道依然存在于与文件系统中,除非对其进行删除操作,否则不会消失。
-
需要注意的是,命名管道是一种严格遵循FIFO规则,不支持lseek函数等文件定位操作。
-
读写规则
- 读
- 如果有进程为写操作打开命名管道,且当前命名管道内没有数据,设置了阻塞标志的读操作将会阻塞。
- 设置了阻塞标志的读操作
- 造成阻塞的原因有两种:
- 当前命名管道内有数据,但有其他进程在读这些数据;
- 命名管道内没有数据,
- 解阻塞的原因
- 命名管道中有新的数据写入,无论新写入数据量的的大小,也不论读操作请求多少数据量
- 造成阻塞的原因有两种:
- 读打开的阻塞标志只对本进程的第一个读操作施加作用
- 如果本进程内有多个读操作,则在第一个读操作被唤醒并完成读后,其他将要执行的读操作将不再阻塞,即使在执行读操作时,命名管道中没有数据也一样(此时读操作返回0)。
- 如果没有进程为写操作打开命名管道,则设置了阻塞标志的读操作会阻塞。
- 写
- 设置了阻塞标志的写操作
- 当要写入的数据量不大于PIPE_BUF时,Linux将保证写入的原子性。如果此时管道的空闲缓冲区不足以容纳要写入的字节数,则进入睡眠(非阻塞模式下出错),直到当缓冲区中能够容纳要写入的数据时,才被唤醒并一次性写入。
- 当要写入的数据量大于PIPE_BUF时,Linux将不再保证写入的原子性,命名管道缓冲区一旦有空闲区域,写进程就会试图向其中写入数据,写操作在写完所有数据后返回。
- 设置了阻塞标志的写操作
- 读
-
#include#include #include #include int main(int argc, char *argv[]) { if (argc < 2) { std::cerr << "参数错误\n"; exit(1); } std::ifstream fp(*(argv+1), std::ios::in); std::string s; if (fp.is_open()) { std::cerr << "文件打开失败\n"; exit(1); } fp >> s; std::cout << s << std::endl; fp.close(); return 0; }
(3)消息队列
-
消息队列是一种以链表为结构组织的数据,存放在Linux内核中,是由各进程通过消息队列标识符来引用的一种数据传送方式。每个消息队列都有一个队列头,利用结构
struct msg_queue来描述。- 队列头中包含了该消息队列的基本信息,包括消息队列键值、用户ID、组ID、消息数目等,甚至记录了最近对消息队列读写进程的PID。
- 结构
msqid_ds用来设置或返回消息队列的信息,存在于用户空间中,结构定义如下
-
struct msg_queue { struct ipc_perm q_perm; time_t q_stime; //上一条消息的发送时间 time_t q_rtime; //上一条消息的接收时间 time_t q_ctime; //上一次修改时间 unsigned long q_cbytes; //当前队列中的字节数据 unsigned long q_qnum; //队列中的消息数量 unsigned long q_qbytes; //队列的最大字节数 pid_t q_lspid; //上一条发送消息的PID pid_t q_lrpid; //上一条接收消息的PID struct list_head q_messages; struct list_head q_receivers; struct list_head q_senders; }; struct msqid_ds { struct ipc_perm msg_perm; struct msg *msg_first; //队列中的第一条消息 struct mag *msg_last; //队列中的最后一条消息 time_t q_stime; //上一条消息的发送时间 time_t q_rtime; //上一条消息的接收时间 time_t q_ctime; //上一次修改时间 unsigned long q_cbytes; //当前队列中的字节数据 unsigned long q_qnum; //队列中的消息数量 unsigned long q_qbytes; //队列的最大字节数 pid_t q_lspid; //上一条发送消息的PID pid_t q_lrpid; //上一条接收消息的PID }; struct ipc_perm { //内核中用于记录消息队列的全局数据结构msg_ids能够访问到该结构 key_t key; //该键值唯一对应一个消息队列 uid_t uid; //所有者的有效用户ID gid_t gid; //所有者的有效组ID uid_t cuid; //创建者的有效用户ID gid_t cgid; //创建者的有效组ID mode_t mode; //此对象的访问权限 unsigned long seq; //对象的序号 }; -
#include#include #include #include #include int main(int argc, char *argv[]) { if (argc < 2) { std::cerr << "参数错误\n"; exit(1); } key_t key = ftok(*(argv+1), 1); //ftok函数生成队列键值 if (key < 0) { std::cerr << "获取消息队列键值失败\n"; exit(1); } int qid = msgget(key, IPC_CREATE|0666); //打开或创建队列 if (qid < 0) { std::cerr << "创建消息队列出错\n"; exit(1); } else { std::cout << "创建消息队列成功\n"; } return 0; } int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);//消息队列的发送 int msgrcv(int msqid, const void *msgp, size_t msgsz, long msgtyp, int msgflg);//消息队列的接收 int msgctl(int msgqid, int cmd, struct msqid_ds *buf); /* *参数msqid为消息队列ID(msgget返回的值) *参数cmd为指定要求的操作 */ /* 函数msgctl可以对消息队列进行以下操作: 查看消息队列相连的数据结构 改变消息队列的许可权限 改变消息队列的拥有者 改变消息队列的字节大小 删除一个消息队列 */
(4)信号量
- 信号量
- 信号量(Semaphore)是一种用于实现计算机资源共享的IPC机制之一,其本质是一个计数器。
- 信号量是在多进程环境下实现资源互斥访问或共享资源访问的方法,可以用来保证两个或多个关键代码段不被并发调用。在进入一个关键代码段之前,进程/线程必须获取一个信号量;一旦该关键代码段完成了,那么该进程必须释放信号量。其它想进入该关键代码段的线程必须等待直到第一个进程释放信号量。
- 信号量有两种应用形式:
- 一种用于临界资源的互斥访问,临界资源在同一时刻只允许一个进程使用,此时的信号量是一个二元信号量,它只控制一个资源;
- 另一种应用于处理多个共享资源(例如多台打印机的分配),信号量在其中起到记录空闲资源数目的作用。
- Linux信号量定义
- Linux多进程访问共享资源时,需要按下列步骤进行操作:
- 检测控制这个资源的信号量的值。
- 如果信号量是正数,就可以使用这个资源。进程将信号量的值减一,表示当前进程占用了一份资源。
- 如果信号量是0,那么进程进入睡眠状态,直到信号量的值重新大于0时被唤醒,转入第一步操作。
- Linux多进程访问共享资源时,需要按下列步骤进行操作:
(5)共享内存
-
共享内存是进程间通信中最简单的方式之一。共享内存允许两个或更多进程访问同一块内存,
- 就如同 malloc() 函数向不同进程返回了指向同一个物理内存区域的指针。
- 当一个进程改变了这块地址中的内容的时候,其它进程都会察觉到这个更改。
-
共享内存的特点:
- 共享内存是进程间共享数据的一种最快的方法。一个进程向共享的内存区域写入了数据,共享这个内存区域的所有进程就可以立刻看到其中的内容。
- 使用共享内存要注意的是多个进程之间对一个给定存储区访问的互斥。
- 若一个进程正在向共享内存区写数据,则在它做完这一步操作前,别的进程不应当去读、写这些数据。
-
常用函数
-
创建共享内存
-
/*所需头文件: #include#include int shmget(key_t key, size_t size,int shmflg); 功能: 创建或打开一块共享内存区。 参数: key:进程间通信键值,ftok() 的返回值。 size:该共享存储段的长度(字节)。 shmflg:标识函数的行为及共享内存的权限,其取值如下: IPC_CREAT:如果不存在就创建 IPC_EXCL: 如果已经存在则返回失败 位或权限位:共享内存位或权限位后可以设置共享内存的访问权限,格式和 open() 函数的 mode_t 一 样(open() 的使用请点此链接),但可执行权限未使用。 返回值: 成功:共享内存标识符。 失败:-1。 示例代码如下: */ #include #include #include #include #include #include #include #define BUFSZ 512 int main(int argc, char *argv[]) { int shmid; int ret; key_t key; char *shmadd; //创建key值 key = ftok("../", 2015); if(key == -1) { perror("ftok"); } system("ipcs -m"); //查看共享内存 //打开共享内存 shmid = shmget(key, BUFSZ, IPC_CREAT|0666); if(shmid < 0) { perror("shmget"); exit(-1); } //映射 shmadd = shmat(shmid, NULL, 0); if(shmadd < 0) { perror("shmat"); exit(-1); } //读共享内存区数据 printf("data = [%s]\n", shmadd); //分离共享内存和当前进程 ret = shmdt(shmadd); if(ret < 0) { perror("shmdt"); exit(1); } else { printf("deleted shared-memory\n"); } //删除共享内存 shmctl(shmid, IPC_RMID, NULL); system("ipcs -m"); //查看共享内存 return 0; }
-
六、Linux文件管理系统------一切都是文件。
一、开机过程
- Linux 系统从软件角度看可以分为四个部分:引导加载程序( Bootloader ), Linux 内核,文件系统,应用程序。
- Bootloader
/PC机中的BIOS:初始化处理器及外设,然后调用 Linux 内核。**类似于 PC 机上的 BIOS ** - Linux 内核在完成系统的初始化之后需要挂载某个文件系统做为根文件系统( Root Filesystem )
- 根文件系统是 Linux 系统的核心组成部分,它可以做为 Linux 系统中文件和数据的存储区域,通常它还包括系统配置文件和运行应用软件所需要的库。
- 由PC机中的
BIOS(0xFFFF0是BIOS存储的总线地址)把bootsect.s从某个固定的地址拿到内存的固定地址(0x90000),并且进行了一系列的硬件初始化和参数设置.- 磁盘引导块程序,再磁盘的第一个扇区中的程序(0磁道,0磁头,1扇区)
- 作用:
- 首先将后续的
setup.s代码从磁盘中加载到紧接着bootsect.s的地方。 - 在显式屏上显示
loading system,再将system(操作系统)模块加载到0x10000的地方 - 最后跳转到
setup.s中去执行
- 首先将后续的
setup.s- 解析
BIOS程序中读取系统信息 - 设置系统内核运行的
LDT(局部描述符),IDT(中断描述符寄存器),全局描述符 - 设置中断控制芯片,进入保护模式运行
- 跳转到
system模块的最前面的代码运行(head.s)
- 解析
head.s- 加载内核运行时的各数据段寄存器,重新设置中断描述符
- 开启内核正常运行时的协处理器等资源。
- 开启内存管理的分页机制
- 跳转到
main.c开始运行
二、文件管11理系统
1、概述
-
文件系统
- 是磁盘管理的目录
- 是Linux中操作所有硬件设备的方式
- 系统的功能机制
-
宏观:
- 文件系统包括的重要部分:
- 标准库:
glibc,OpenGLmedia,Framework - 配置文件:如开机画面的设计,开机运行的软件,执行什么命令
- 设备节点
- 架构节点
shell的实现:/bin文件目录
- 标准库:
- 文件系统包括的重要部分:
-
作用
-
文件系统,也叫应用程序,系统的界面,系统的开机画面,系统
ROM,系统的功能,预装的软件均属于文件系统。 -
在 Linux 操作系统中,所有被操作系统管理的资源,例如网络接口卡、磁盘驱动器、打印机、输入输出设备、普通文件或是目录都被看作是一个文件。
- 也就是说在 Linux 系统中有一个重要的概念**:一切都是文件**。在/Linux/Unix 系统中,把一切资源都看作是文件,包括硬件设备。UNIX系统把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。
-
Linux 支持 5 种文件类型,如下图所示:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nX7IvPYA-1616393529712)(C:\Users\Administrator\Desktop\interview_python-master\img\文件类型.png)]
-
2、根文件管理系统
(1)目录设计
Linux 文件系统的结构层次鲜明,就像一棵倒立的树,最顶层是其根目录:
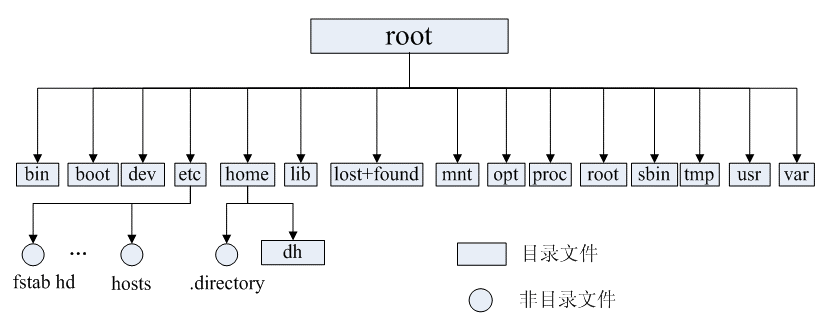
常见目录说明:
- /bin: 存放二进制可执行文件(ls,cat,mkdir等),常用命令一般都在这里;
- /etc: 存放系统管理和配置文件;
- /home: 存放所有用户文件的根目录,是用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示;
- /usr : 用于存放系统应用程序;
- /opt: 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把tomcat等都安装到这里;
- /proc: 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
- /root: 超级用户(系统管理员)的主目录(特权阶级o);
- /sbin: 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如ifconfig等;
- /dev: 用于存放设备文件;
- /mnt: 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
- /boot: 存放用于系统引导时使用的各种文件;
- /lib : 存放着和系统运行相关的库文件 ;
- /tmp: 用于存放各种临时文件,是公用的临时文件存储点;
- /var: 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
- /lost+found: 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里。
(2)根文件系统作用
- 提供磁盘管理服务,glibc设备节点,配置文件,应用程序,
shell命令
(3)文件管理系统与磁盘文件系统的关系
- 与处理器相比,磁盘是一种工作速度极其缓慢的外部设备,操作系统很难直接利用磁盘文件系统来对文件进行操作。
- 操作系统必须根据磁盘文件系统提供的各种基本信息在内存中建立必要的缓冲数据结构,
- 一方面为了避免频繁地访问磁盘
- 另一方面也用来记录文件的一些动态信息。
- 与此同时,还要建立一些操作系统自用的文件管理用表。
- 文件管理系统中的管理用表及缓冲区主要有:
- 文件注册表。包含文件系统在磁盘分区中信息的登记表;
- 全局打开文件表。包含每个打开文件的文件控制块(FCB)的附件以及其他信息;
- 进程打开文件表。该表为进程所有,它包含一些指针,这些指针指向全局打开文件表中本进程当前所使用的FCB;
- 目录缓冲区。用来保存近期访问过的目录信息;
- 索引节点缓冲区;
- 文件缓冲区。用来保存当前或近期访问文件的内容。
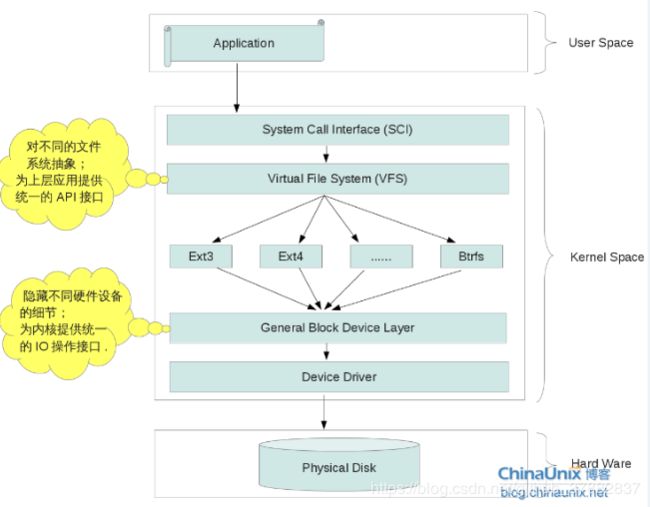
(4)虚拟文件系统(VFS)
-
硬盘驱动
- 常见的硬盘类型有
PATA,SATA和AHCI等, - 在Linux系统中,对不同硬盘所提供的驱动模块一般都存放在内核目录树
drivers/ata中, - 而对于一般通用的硬盘驱动,也许会直接被编译到内核中,而不会以模块的方式出现
- 常见的硬盘类型有
-
General Block Device Layer通用块设备层:I/O体系结构,与外设的通信通常称为输入输出,缩写为I/O。在实现外设的I/O时,内核需要处理好3个问题、
- 根据具体的设备型号和模型,使用各种方法对硬件寻址
- 内核必须向用户应用程序和系统工具提供访问各种设备的方法,应该采用统一的方案
- 用户空间需要知道内核中有哪些设备可用
-
文件系统
-
虚拟文件系统(VFS):是Linux内核的子系统之一,它为用户程序提供文件和文件系统操作的统一接口,屏蔽不同文件系统的差异和操作细节。借助VFS可以直接使用
open()、read()、write()这样的系统调用操作文件,而无须考虑具体的文件系统和实际的存储介质。
Linux启动时,第一个必须挂载的是根文件系统;若系统不能从指定设备上挂载根文件系统,则系统会出错而退出启动。之后可以自动或手动挂载其他的文件系统。因此,一个系统中可以同时存在不同的文件系统。 -
Linux为了实现这种VFS系统,采用面向对象的设计思路,主要抽象了四种对象类型:
- 超级块对象:代表一个已安装的文件系统。
- 索引节点对象:代表具体的文件。
- 目录项对象:代表一个目录项,是文件路径的一个组成部分。
- 文件对象:代表进程打开的文件。
- 每个对象都包含一组操作方法,用于操作相应的文件系统。
-
inode(索引节点)- 文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(
Sector)。每个扇区储存512字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。“块"的大小,最常见的是4KB,即连续八个sector组成一个block。 - 通常情况下,文件系统会将文件的实际内容和属性分开存放:
- 文件的属性保存在
inode中(i 节点)中,每个inode都有自己的编号。每个文件各占用一个inode。不仅如此,inode 中还记录着文件数据所在 block 块的编号; - 文件的实际内容保存在
block中(数据块),类似衣柜的隔断,用来真正保存衣物。每个 block 都有属于自己的编号。当文件太大时,可能会占用多个 block 块。 - 另外,还有一个
super block(超级块)用于记录整个文件系统的整体信息,包括 inode 和 block 的总量、已经使用量和剩余量,以及文件系统的格式和相关信息等。 - 注: 每个
inode都有一个号码,操作系统用inode号码来识别不同的文件。- 表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:
- 首先,系统找到这个文件名对应的inode号码;
- 其次,通过inode号码,获取inode信息;
- 最后,根据inode信息,找到文件数据所在的block,读出数据。
- 表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:
- 文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(
-
inode本质上是一个结构体,定义如下
struct inode {
struct hlist_node i_hash; /* 哈希表 */
struct list_head i_list; /* 索引节点链表 */
struct list_head i_dentry; /* 目录项链表 */
unsigned long i_ino; /* 节点号 */
atomic_t i_count; /* 引用记数 */
umode_t i_mode; /* 访问权限控制 */
unsigned int i_nlink; /* 硬链接数 */
uid_t i_uid; /* 使用者id */
gid_t i_gid; /* 使用者id组 */
kdev_t i_rdev; /* 实设备标识符 */
loff_t i_size; /* 以字节为单位的文件大小 */
struct timespec i_atime; /* 最后访问时间 */
struct timespec i_mtime; /* 最后修改(modify)时间 */
struct timespec i_ctime; /* 最后改变(change)时间 */
unsigned int i_blkbits; /* 以位为单位的块大小 */
unsigned long i_blksize; /* 以字节为单位的块大小 */
unsigned long i_version; /* 版本号 */
unsigned long i_blocks; /* 文件的块数 */
unsigned short i_bytes; /* 使用的字节数 */
spinlock_t i_lock; /* 自旋锁 */
struct rw_semaphore i_alloc_sem; /* 索引节点信号量 */
struct inode_operations *i_op; /* 索引节点操作表 */
struct file_operations *i_fop; /* 默认的索引节点操作 */
struct super_block *i_sb; /* 相关的超级块 */
struct file_lock *i_flock; /* 文件锁链表 */
struct address_space *i_mapping; /* 相关的地址映射 */
struct address_space i_data; /* 设备地址映射 */
struct dquot *i_dquot[MAXQUOTAS]; /* 节点的磁盘限额 */
struct list_head i_devices; /* 块设备链表 */
struct pipe_inode_info *i_pipe; /* 管道信息 */
struct block_device *i_bdev; /* 块设备驱动 */
unsigned long i_dnotify_mask; /* 目录通知掩码 */
struct dnotify_struct *i_dnotify; /* 目录通知 */
unsigned long i_state; /* 状态标志 */
unsigned long dirtied_when; /* 首次修改时间 */
unsigned int i_flags; /* 文件系统标志 */
unsigned char i_sock; /* 可能是个套接字吧 */
atomic_t i_writecount; /* 写者记数 */
void *i_security; /* 安全模块 */
__u32 i_generation; /* 索引节点版本号 */
union {
void *generic_ip; /* 文件特殊信息 */
} u;
};
(5)硬链接和软连接
- 硬连接:一般情况下,文件名和
inode号码是"一一对应"关系,每个inode号码对应一个文件名。Unix/Linux系统允许,多个文件名指向同一个inode号码。- 可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;
- 但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为"硬链接"(hard link)。
ln 源文件 目标文件 - 硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。
- 其原因如上所述,因为对应该目录的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件才会被真正删除。
- 软链接/符号链接
- 文件A和文件B的
inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。文件A就称为文件B的"软链接"(soft link)或者"符号链接(symbolic link)。软链接类似于Windows系统下的快捷方式。 - 我们可以使用ln -s命令来创建一个文件的软链接
ln -s 源文件或目录 目标文件或目录
若文件A是文件B的软链接,意味着文件A依赖于文件B。如果删除了文件B,则文件A会变成无效文件(即使文件A仍然存在)。
- 文件A和文件B的
- 这是软链接与硬链接最大的不同:
- 软链接指向的是文件的路径名而不是文件的
inode号码,文件B的inode号码也不会因为软链接的存在而增加。
- 软链接指向的是文件的路径名而不是文件的
七、Linux虚拟内存管理系统-----一切都是文件。
-
每个进程有独立的虚拟地址空间,进程访问的虚拟地址空间并不是真正的物理地址
-
虚拟地址可通过每个进程上页表与物理地址进行映射,获得真正的物理地址
-
如果虚拟地址所对应的物理地址不在物理内存中,则产生缺页中断,真正分配物理地址,同时更新进程的页表;如果此时物理内存已经耗尽,则根据内存替换算法淘汰部分页面至物理磁盘中。
-
查看内存状态命令:
top,vmstat,free -
MemTotal:一般的是 **MemTotal = MemFree+MemUsed **,MemTotal是去掉kenel占用的剩下的 -
MemAvailable:有些应用程序会根据系统的可用内存大小自动调整内存申请的多少,所以需要一个记录当前可用内存数量的统计值,因为MemFree不能代表全部可用的内存,系统中有些内存虽然已被使用但是可以回收的,比如cache/buffer、slab(内核分配的内存)都有一部分可以回收,所以这部分可回收的内存加上MemFree才是系统可用的内存,即MemAvailable -
Bounce:有些设备只能访问低端内存,比如16M以下的内存,当应用程序发出一个
I/O请求,DMA的目的地址却是高端内存时(比如在16M以上),内核将在低端内存中分配一个临时buffer作为跳转,把位于高端内存的缓存数据复制到此处。这种额外的数据拷贝被称为**bounce buffering**,会降低I/O 性能。大量分配的bounce buffers 也会占用额外的内存。 -
Buffers:表示
块设备(block device)所占用的缓存页,包括:直接读写块设备、以及文件系统元数据(metadata)比如SuperBlock所使用的缓存页。它与“Cached”的区别在于,”Cached”表示普通文件所占用的缓存页。“Buffers”所占的内存同时也在LRU list中,被统计在Active(file)或Inactive(file)。 -
MemAvailable
有些应用程序会根据系统的可用内存大小自动调整内存申请的多少,所以需要一个记录当前可用内存数量的统计值,MemFree并不适用,因为MemFree不能代表全部可用的内存,系统中有些内存虽然已被使用但是可以回收的,比如cache/buffer、slab都有一部分可以回收,所以这部分可回收的内存加上MemFree才是系统可用的内存,即MemAvailable。/proc/meminfo中的MemAvailable是内核使用特定的算法估算出来的,要注意这是一个估计值,并不精确。
作者:zjfclimin
链接:https://www.jianshu.com/p/391f42f8fb0d
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1、虚拟内存
- 虚拟内存是
Linxu管理内存的一种技术,它使得每个应用程序都认为自己拥有独立且连续完整的可用内存空间,而实际上,它通常是被映射到多个物理内存段,还有部分暂时存储在外部磁盘存储器上,在需要时再加载到内存中来。 - 每个进程所能使用的虚拟地址大小和cpu位数有关,32位的系统上,虚拟地址空间大小为
4G,64位为2^64,当然实际的物理内存大小可能远远小于虚拟地址空间的大小,
注:虚拟地址空间大小并不等同于交换空间,交换空间只能算其中的一部分。
2、虚拟内存和物理内存的关系
进程X 进程Y
+-------+ +-------+
| VPFN7 |--+ | VPFN7 |
+-------+ | 进程X的 进程Y的 +-------+
| VPFN6 | | Page Table Page Table +-| VPFN6 |
+-------+ | +------+ +------+ | +-------+
| VPFN5 | +----->| .... |---+ +-------| .... |<---+ | | VPFN5 |
+-------+ +------+ | +------+ | +------+ | | +-------+
| VPFN4 | +--->| .... |---+-+ | PFN4 | | | .... | | | | VPFN4 |
+-------+ | +------+ | | +------+ | +------+ | | +-------+
| VPFN3 |--+ | | .... | | | +--->| PFN3 |<---+ +----| .... |<---+--+ | VPFN3 |
+-------+ | | +------+ | | | +------+ | +------+ | +-------+
| VPFN2 | +-+--->| .... |---+-+-+ | PFN2 |<------+ | .... | | | VPFN2 |
+-------+ | +------+ | | +------+ +------+ | +-------+
| VPFN1 | | | +----->| FPN1 | +----| VPFN1 |
+-------+ | | +------+ +-------+
| VPFN0 |----+ +------->| PFN0 | | VPFN0 |
+-------+ +------+ +-------+
虚拟内存 物理内存 虚拟内存
PFN(the page frame number): 页编号
- 当一个程序开始运行时,需要先到内存中读取该进程的指令,获取指令是用到的就是虚拟地址,该地址是程序链接时确定的。
-
为了获取到实际的指令和数据,cpu需要借助进程的页表(page table)将虚拟地址转换为物理地址,
-
页表里面的数据由操作系统维护。
-
注意:linux内核代码访问内存用的都是实际的物理地址,不存在虚拟地址到物理地址的转换,只有应用程序才需要。
-
为了方便转换,Linux将虚拟内存和物理内存的
page都拆分为固定大小的页,一般是4k,每个页都会分配一个唯一的编号,就是页编号PFN。 -
虚拟内存和物理内存的
page之间通过page table进行映射。- 进程X和Y的虚拟内存是相互独立的,他们的页表也是相互独立的,不同进程共享物理内存。进程可以随便访问自己的虚拟地址空间,
- 页表和物理内存由内核维护,当进程需要访问内存时,cpu会根据进程的页表将虚拟地址翻译成物理地址,然后进行访问。
- 并不是每个虚拟地址空间的
page都有对应的Page Table相关联,只有虚拟地址被分配给进程后,也即进程调用类似malloc函数之后,系统才会为相应的虚拟地址在Page Table中添加记录,如果进程访问一个没有和Page Table关联的虚拟地址,系统将会抛出SIGSEGV信号,导致进程退出,换句话说,虽然每个进程都有4G(32位系统)的虚拟地址空间,但只有向系统申请了的那些地址空间才能用,访问未分配的地址空间将会出segmentfault错误。Linux会将虚拟地址0不映射到任何地方,这样我们访问空指针就一定会报segmentfault错误。
- 并不是每个虚拟地址空间的
-
3、虚拟内存的优点
- 更大的地址空间:并且是连续的,使得程序编写、链接更加简单
- 进程隔离:不同进程的虚拟地址之间没有关系,所以一个进程的操作不会对其它进程造成影响
- 数据保护:每块虚拟内存都有相应的读写属性,这样就能保护程序的代码段不被修改,数据块不能被执行等,增加了系统的安全性
- 内存映射:有了虚拟内存之后,可以直接映射磁盘上的文件(可执行文件或动态库)到虚拟地址空间,这样可以做到物理内存延时分配,只有在需要读相应的文件的时候,才将它真正的从磁盘上加载到内存中来,而在内存吃紧的时候又可以将这部分内存清空掉,提高物理内存利用效率,并且所有这些对应用程序来说是都透明的
- 共享内存:比如动态库,只要在内存中存储一份就可以了,然后将它映射到不同进程的虚拟地址空间中,让进程觉得自己独占了这个文件。进程间的内存共享也可以通过映射同一块物理内存到进程的不同虚拟地址空间来实现共享
- 其它:有了虚拟地址空间后,交换空间和COW(copy on write)等功能都能很方便的实现
4、page table
page table可以简单的理解为一个memory mapping的链表(当然实际结构很复杂),里面的每个memory mapping都将一块虚拟地址映射到一个特定的资源(物理内存或者外部存储空间)。每个进程拥有自己的page table,和其它进程的page table没有关系。- 注:请把
Page Table与Page Frame(页帧)区分开,物理内存的最小单位是page frame,每个物理页对应一个描述符(struct page),在内核的引导阶段就会分配好、保存在mem_map[]数组中,mem_map[]所占用的内存被统计在dmesg显示的reserved中,/proc/meminfo的MemTotal是不包含它们的。(在NUMA系统上可能会有多个mem_map数组,在node_data中或mem_section中)。
- 注:请把
5、memory mapping
- 每个
memory mapping就是对一段虚拟内存的描述,包括虚拟地址的起始位置,长度,权限(比如这段内存里的数据是否可读、写、执行), 以及关联的资源(如物理内存page,swap空间上的page,磁盘上的文件内容等)。- 延时分配/按需分配:当进程申请内存时,系统将返回虚拟内存地址,同时为相应的虚拟内存创建
memory mapping并将它放入page table,但这时系统不一定会分配相应的物理内存,系统一般会在进程真正访问这段内存的时候才会分配物理内存并关联到相应的memory mapping,。每个memory mapping都有一个标记,用来表示所关联的物理资源类型,一般分两大类,那就是anonymous和file backed。
- 延时分配/按需分配:当进程申请内存时,系统将返回虚拟内存地址,同时为相应的虚拟内存创建
file backed(有文件背景的页面):- 这种类型表示对应的物理资源存放在磁盘上的文件中,它所包含的信息包括文件的位置、
offset、rwx权限等。当进程第一次访问对应的虚拟page的时候,由于在memory mapping中找不到对应的物理内存,CPU会报page fault中断,然后操作系统就会处理这个中断并将文件的内容加载到物理内存中,然后更新memory mapping,这样下次CPU就能访问这块虚拟地址了。 - 以这种方式加载到内存的数据一般都会放到
page cache中。一般程序的可执行文件,动态库都是以这种方式映射到进程的虚拟地址空间的。 - 程序去读文件时,可以通过
read也可以通过memory mapping去读。当你通过任何一种方式从磁盘读文件时,内核都会给你申请一个page cache,来缓存硬盘上的内容。这样的话,读过一遍的数据,本进程或其他进程下次再读的时候就直接从page cache里去拿,就很快了,提升系统的整体性能。因此用户的read/write实际上是跟page cache的相互拷贝。- 用户的
memory mapping则会将一段虚拟地址(3G)以下映射到page cache上,这样的话,用户就可以通过读写这段虚拟地址来修改文件内容,省去了内核和用户之间的拷贝。
- 用户的
- 这种类型表示对应的物理资源存放在磁盘上的文件中,它所包含的信息包括文件的位置、
anonymous类型(匿名页): 程序自己用到的数据段和堆栈空间,以及通过mmap分配的共享内存,它们在磁盘上找不到对应的文件,所以这部分内存页被叫做anonymous page。比如用户进程通过malloc()申请的内存页anonymous page和file backed最大的差别是当内存吃紧时,系统会直接删除掉file backed对应的物理内存,因为下次需要的时候还能从磁盘加载到内存,但anonymous page不能被删除,只能被swap out。- 如果发生
swapping换页,它们没有关联的文件进行回写,所以只能写入到交换区里。- 交换区可以包括一个或多个交换区设备(裸盘、逻辑卷、文件都可以充当交换区设备),
- 每一个交换区设备在内存里都有对应的
swap cache,可以把swap cache理解为交换区设备的”page cache”:page cache对应的是一个个文件,swap cache对应的是一个个交换区设备,kernel管理swap cache与管理page cache一样,用的都是radix-tree,- 区别是:
page cache与文件的对应关系在打开文件时就确定了,而一个匿名页只有在即将被swap-out的时候才决定它会被放到哪一个交换区设备,即匿名页与swap cache的对应关系在即将被swap-out时才确立。
- 并不是每一个匿名页都在swap cache中,只有以下情形之一的匿名页才在:
- 匿名页即将被
swap-out时会先被放进swap cache,但通常只存在很短暂的时间,因为紧接着在page out完成之后它就会从`swap cache 中删除, - 曾经被
swap-out现在又被swap-in的匿名页会在swap cache中,直到页面中的内容发生变化、或者原来用过的交换区空间被回收为止。
- 匿名页即将被
shared: 不同进程的page table里面的多个memory mapping可以映射到相同的物理地址,通过虚拟地址可以访问到相同的内容,当一个进程修改内存的内容后,在另一个进程可以立即读取到,这种方式一般用来实现进程间高速的共享数据。- 当标记为
shared的memory mapping被删除回收时,需要更新物理page上的引用计数,当物理page的计数变0后被回收。
- 当标记为
- copy on write: 它是基于shared技术,当读这种类型的内存时,系统不需要做任何特殊的操作,而当要写这块内存时,系统将会生成一块新的内存并拷贝原来内存中的数据到新内存中,然后将新内存关联到相应的
memory mapping,接着执行写操作,linux很多功能都依赖于copy on write技术来提高性能,最常见的是fork。 - 内存的使用过程:
- 进程向系统发出内存申请请求
- 系统会检查进程的虚拟地址空间是否用完,如果有剩余,给进程分配虚拟地址
- 系统为这块虚拟地址创建相应的memory mapping,并把它放进进程的page table
- 系统返回虚拟地址给进程,进程开始访问虚拟地址
- cpu根据虚拟地址在该进程的page table找到对应的memory mapping,但是该mapping没有和物理内存关联,于是产生缺页中断
- 操作系统收到缺页中断后,分配真正的物理内存并将它关联到对应的memory mapping
- 中断处理完成后,cpu就可以访问内存了。
- 当然缺页中断不是每次都会发生,只有系统觉得有必要延迟分配内存的时候才用的着, 也就是说上面第三步很多时候系统会分配真正的物理内存并关联memory mapping
6、其他概念
(1)MMU(Memory Management Unit)
- MMU是cpu的一个用来将进程的虚拟地址转换为物理地址的模块,它的输入是进程的page table和虚拟地址,输出是物理地址。将虚拟地址转换成物理地址的速度直接影响着系统的速度,所有cpu包含了这个硬件模块用来加速。
(2)TLB (Translation Lookaside Buffer)
- MMU的输入是page table,而page table又存在内存里,和cpu的cache相比,内存的速度很慢,为了进一步加快虚拟地址到物理地址的转换速度,Linux发明了TLB,它存在于cpu的L1cache里面,用来缓存已经找到的虚拟地址和物理地址的映射,这样下次转换前先排查一下TLB,如果已经在里面了就不需要使用MMU进行转换了。
(3)访问控制
- page table里面的每条虚拟内存到物理内存的映射记录(memory mapping)都包含一份控制信息,当进程要访问一块虚拟内存时,系统可以根据这份控制信息来检查当前的操作是否是合法的。
(4)huge pages
- 由于CPU的cache有限,所以TLB里面缓存的数据也有限,而采用了huge page后,由于每页的内存变大(比如由原来的4K变成了4M),虽然TLB里面的纪录数没变,但这些纪录所能覆盖的地址空间变大,相当于同样大小的TLB里面能缓存的映射范围变大,从而减少了调用MMU的次数,加快了虚拟地址到物理地址的转换速度。
(5)Caches
- 为了提高系统性能,Linux使用了一些跟内存管理相关的cache,并且尽量将空闲的内存用于这些cache。这些cache都是系统全局共享的:
- Buffer Cache:用来缓冲块设备上的数据,比如磁盘,当读写块设备时,系统会将相应的数据存放到这个cache中,等下次再访问时,可以直接从cache中拿数据,从而提高系统效率。它里面的数据结构是一个块设备ID和block编号到具体数据的映射,只要根据块设备ID和块的编号,就能找到相应的数据。
- Page Cache: 这个cache主要用来加快读写磁盘上文件的速度。它里面的数据结构是文件ID和offset到文件内容的映射,根据文件ID和offset就能找到相应的数据
7、文件系统缓存和匿名页的交换
(1)swap的含义
- 没有文件背景的页面,即匿名页(anonymous page),如堆,栈,数据段等,不是以文件形式存在,因此无法和磁盘文件交换,但可以通过硬盘上划分额外的swap交换分区或使用交换文件进行交换。即上面Swap作为名词的意思。
Swap分区可以将不活跃的页交换到硬盘中,缓解内存紧张。- 注意,即使没有swap分区,也会存在swap行为,因为有文件背景的页面(file-backed page)也会有
swap,即第1点的磁盘和内存之间的交换。
- 注意,即使没有swap分区,也会存在swap行为,因为有文件背景的页面(file-backed page)也会有
(2)页面回收(reclaim)
-
回收时机
-
有文件背景的数据实际上就是page cache,内核中有一个水位控制的机制,在系统内存不够用的时候,会触发页面回收。
-
对于没有文件背景的页面即匿名页,比如堆、栈、数据段,如果没有swap分区,不能与磁盘交换,就要常驻内存了。但是常驻内存的话,就会吃内存,可以通过给硬盘搞一个swap分区或硬盘中创建一个交换文件(swapfile)让匿名页也能交换到磁盘上。可认为是为匿名页伪造的文件背景。swap分区或swap文件实际上最终是到达了增大内存的效果。
-
内核通过
kswapd内核线程慢慢回收,回收的时机由水位控制。 -
水位(watermark)控制
-
内核中有三个水位:
- low:当剩余内存慢慢减少,触到这个水位时,就会触发
kswapd线程的内存回收。 - min:如果剩余内存减少到触及这个水位,可认为内存严重不足,当前进程就会被堵住,
kernel会直接在这个进程的进程上下文里面做内存回收(direct reclaim)。 - high: 进行内存回收时,内存慢慢增加,触到这个水位时,就停止回收。
- low:当剩余内存慢慢减少,触到这个水位时,就会触发
回收的过程是依据LRU,即最近最少使用的页会被回收,Linux内核一直在评估哪些是LRU的页面即最不活跃的页面。
root@none:~# cat /proc/meminfo
MemTotal: 254316 kB
MemFree: 185748 kB
Buffers: 6676 kB
Cached: 22716 kB
SwapCached: 0 kB
Active: 25472 kB <----
Inactive: 23164 kB <----
Active(anon): 19684 kB <----
Inactive(anon): 456 kB <----
Active(file): 5788 kB <----
Inactive(file): 22708 kB <----
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 0 kB
Writeback: 0 kB
AnonPages: 19272 kB
…… ……
(3)其他相关问题
1) Linux虚拟地址空间如何分布?32位和64位有何不同?
-
Linux使用虚拟地址空间,大大增加了进程的寻址空间,由低地址到高地址分别是:
- 只读段:该部分空间只能读,不能写,包括代码段,rodata段(C常量字符和#define定义的常量)
- 数据段:保存全局变量、静态空间变量
- 堆:就是平时所说的动态内存,malloc/new大部分都源于此。其中堆顶的位置可以通过brk和sbrk进行动态调整
- 文件映射区域:如动态库,共享内存等映射物理空间的内存,一般是mmap函数所分配的虚拟地址空间
- 栈:用于维护函数调用的上下文空间,一般为8M,可以通过ulimit -s查看
- 内核虚拟空间:用户代码不可见的区域,由内核管理
-
可以通过以下代码验证进程的地址空间分布,其中sbrk(0)函数用于返回栈顶指针。
-
#include#include #include #include int global_num = 0; char global_str_arr[65536] = { 'a' }; int main(int argc, char** argv) { char* heap_var = NULL; int local_var = 0; printf("Address of function main 0x%lx\n", main); printf("Address of global_num 0x%lx\n", &global_num); printf("Address of global_str_arr 0x%lx ~ 0x%lx\n", &global_str_arr[0], &global_str_arr[65535]); printf("Top of stack is 0x%lx\n", &local_var); printf("Top of heap is 0x%lx\n", sbrk(0)); heap_var = malloc(sizeof(char)* 127 * 1024); printf("Address of heap_var is 0x%lx\n", heap_var); printf("Top of heap after malloc is 0x%lx\n", sbrk(0)); free(heap_var); heap_var = NULL; printf("Top of heap after free is 0x%lx\n", sbrk(0)); return 1; } -
32位系统的结果如下,
-
Address of function main 0x8048474 Address of global_num 0x8059904 Address of global_str_arr 0x8049900 ~ 0x80598ff Top of stack is 0xbfd0886c Top of heap is 0x805a000 Address of heap_var is 0x805a008 Top of heap after malloc is 0x809a000 Top of heap after free is 0x807b000 -
64位系统的结果400594
-
Address of global_num 0x610b90 Address of global_str_arr 0x600b80 ~ 0x610b7f Top of stack is 0x7fff2e9e4994 Top of heap is 0x8f5000 Address of heap_var is 0x8f5010 Top of heap after malloc is 0x935000 Top of heap after free is 0x916000
-
2) malloc是如何分配内存的?
malloc是glibc中的内存分配函数,也是最常用的动态内存分配函数,其内存必须通过free进行释放,否则导致内存泄漏。关于malloc获得虚拟空间的表现,与glibc的版本有关,但大体逻辑上:- 若分配内存小于128K,调用sbrk(),将堆顶指针向高地址移动,获得新的虚拟空间;
- 若分配内存大于128K,调用mmap(),在文件映射区域中分配匿名虚拟空间;
- 其中
sbrk()就是修改栈顶指针位置,而mmap可用于生成文件的映射以及修改匿名页面的内存,这里指的是匿名页面。
而这个128K,是glibc的默认配置,可通过函数mallopt来设置,可通过以下例子来说明:
-
#include#include #include #include #include #include void print_info( char* var_name, char* var_ptr, size_t size_in_kb ) { printf("Address of %s(%luk) 0x%lx, now heap top is 0x%lx\n", var_name, size_in_kb, var_ptr, sbrk(0)); } int main(int argc, char** argv) { char *heap_var1, *heap_var2, *heap_var3 ; char *mmap_var1, *mmap_var2, *mmap_var3 ; char *maybe_mmap_var; printf("Orginal heap top is 0x%lx\n", sbrk(0)); heap_var1 = malloc(32*1024); print_info("heap_var1", heap_var1, 32); heap_var2 = malloc(64*1024); print_info("heap_var2", heap_var2, 64); heap_var3 = malloc(127*1024); print_info("heap_var3", heap_var3, 127); printf("\n"); maybe_mmap_var = malloc(128*1024); print_info("maybe_mmap_var", maybe_mmap_var, 128); //mmap mmap_var1 = malloc(128*1024); print_info("mmap_var1", mmap_var1, 128); // set M_MMAP_THRESHOLD to 64k mallopt(M_MMAP_THRESHOLD, 64*1024); printf("set M_MMAP_THRESHOLD to 64k\n"); mmap_var2 = malloc(64*1024); print_info("mmap_var2", mmap_var2, 64); mmap_var3 = malloc(127*1024); print_info("mmap_var3", mmap_var3, 127); return 1; } -
下面是 Linux 64 位机器的执行结果(后文所有例子都是通过 64 位机器上的测试结果):
-
Orginal heap top is 0x17da000 Address of heap_var1(32k) 0x17da010, now heap top is 0x1803000 Address of heap_var2(64k) 0x17e2020, now heap top is 0x1803000 Address of heap_var3(127k) 0x17f2030, now heap top is 0x1832000 Address of maybe_mmap_var(128k) 0x1811c40, now heap top is 0x1832000 Address of mmap_var1(128k) 0x7f4a0b1f2010, now heap top is 0x1832000 set M_MMAP_THRESHOLD to 64k Address of mmap_var2(64k) 0x7f4a0b1e1010, now heap top is 0x1832000 Address of mmap_var3(127k) 0x7f4a0b1c1010, now heap top is 0x1832000
3) malloc分配多大的内存,就占用多大的物理内存空间吗?
-
malloc分配的内存是虚拟地址空间,而虚拟地址空间和物理地址空间使用进程页表进行映射,那么分配了空间就是占用物理内存空间了吗?
-
首先,进程使用了多少内存可通过
ps -aux命令查看,其中关键的两个信息(第五,六列)为:-
VSZ,virtual memory size,表示进程总共使用的虚拟地址空间大小,包括进程地址空间的代码段,数据段,堆,文件映射区域,栈,内核空间等所有虚拟地址使用的总和,单位为K。
-
RSS,resident set size,表示进程实际使用的物理空间大小,RSS总小于VSZ。
-
#include#include #include #include #include #include char ps_cmd[1024]; void print_info( char* var_name, char* var_ptr, size_t size_in_kb ) { printf("Address of %s(%luk) 0x%lx, now heap top is 0x%lx\n", var_name, size_in_kb, var_ptr, sbrk(0)); system(ps_cmd); } int main(int argc, char** argv) { char *non_set_var, *set_1k_var, *set_5k_var, *set_7k_var; pid_t pid; pid = getpid(); sprintf(ps_cmd, "ps aux | grep %lu | grep -v grep", pid); non_set_var = malloc(32*1024); print_info("non_set_var", non_set_var, 32); set_1k_var = malloc(64*1024); memset(set_1k_var, 0, 1024); print_info("set_1k_var", set_1k_var, 64); set_5k_var = malloc(127*1024); memset(set_5k_var, 0, 5*1024); print_info("set_5k_var", set_5k_var, 127); set_7k_var = malloc(64*1024); memset(set_1k_var, 0, 7*1024); print_info("set_7k_var", set_7k_var, 64); return 1; } -
执行结果为:
-
Address of non_set_var(32k) 0x502010, now heap top is 0x52b000 mysql 12183 0.0 0.0 2692 452 pts/3 S+ 20:29 0:00 ./test_vsz Address of set_1k_var(64k) 0x50a020, now heap top is 0x52b000 mysql 12183 0.0 0.0 2692 456 pts/3 S+ 20:29 0:00 ./test_vsz Address of set_5k_var(127k) 0x51a030, now heap top is 0x55a000 mysql 12183 0.0 0.0 2880 464 pts/3 S+ 20:29 0:00 ./test_vsz Address of set_7k_var(64k) 0x539c40, now heap top is 0x55a000 mysql 12183 0.0 0.0 2880 472 pts/3 S+ 20:29 0:00 ./test_vsz -
由以上结果可知:
- VSZ并不是每次malloc后都增长,是与上一节说的堆顶没发生变化有关,因为可重用堆顶内剩余的空间,这样malloc是很轻量和快速的;
- 如果VSZ发生变化,基本与分配内存量相当,因为VSZ是计算虚拟地址空间总大小;
- RSS的增量很少,是因为malloc分配的内存并不就马上分配实际的存储空间,只有第一次使用,如第一个memset后才分配;
- 由于每个物理页面大小是4K,不管memset其中的1K,还是5K,7K,实际占用物理内存总是4K的倍数。所以RSS的增量总是4K的倍数;
-
因此,不是malloc后马上占用实际内存,而是第一次使用时发现虚存对应的物理页面未分配,产生缺页中断,才真正分配物理页面,同时更新进程页表的映射关系。这也是Linux虚拟内存管理的核心概念之一。
-
4) 如何查看进程虚拟地址空间的使用情况
-
Linux提供了
pmap命令来查看这些信息,通常使用pmap -d pid(高版本可提供pmap -x pid)查询,如下所示: -
mysql@ TLOG_590_591:~/vin/test_memory> pmap -d 17867 17867: test_mmap START SIZE RSS DIRTY PERM OFFSET DEVICE MAPPING 00400000 8K 4K 0K r-xp 00000000 08:01 /home/mysql/vin/test_memory/test_mmap 00501000 68K 8K 8K rw-p 00001000 08:01 /home/mysql/vin/test_memory/test_mmap 00512000 76K 0K 0K rw-p 00512000 00:00 [heap] 0053e000 256K 0K 0K rw-p 0053e000 00:00 [anon] 2b3428f97000 108K 92K 0K r-xp 00000000 08:01 /lib64/ld-2.4.so 2b3428fb2000 8K 8K 8K rw-p 2b3428fb2000 00:00 [anon] 2b3428fc1000 4K 4K 4K rw-p 2b3428fc1000 00:00 [anon] 2b34290b1000 8K 8K 8K rw-p 0001a000 08:01 /lib64/ld-2.4.so 2b34290b3000 1240K 248K 0K r-xp 00000000 08:01 /lib64/libc-2.4.so 2b34291e9000 1024K 0K 0K ---p 00136000 08:01 /lib64/libc-2.4.so 2b34292e9000 12K 12K 12K r--p 00136000 08:01 /lib64/libc-2.4.so 2b34292ec000 8K 8K 8K rw-p 00139000 08:01 /lib64/libc-2.4.so 2b34292ee000 1048K 36K 36K rw-p 2b34292ee000 00:00 [anon] 7fff81afe000 84K 12K 12K rw-p 7fff81afe000 00:00 [stack] ffffffffff600000 8192K 0K 0K ---p 00000000 00:00 [vdso] Total: 12144K 440K 96K
5) free的内存真的释放了吗(还给OS)?
-
malloc使用mmap分配的内存(大于128K),free会调用unmap系统调用马上还给OS,实现真正释放。
-
堆内的内存,只有释放堆顶的空间,同时堆顶总连续空间大于128K才使用sbrk(-SIZE)回收内存,真正归还OS。
-
堆内的空闲空间,是不会归还给OS的。
6) 既然堆内内存不能直接释放,为什么不全部使用mmap来分配
- 由于堆内碎片不能直接释放,
mmap分配的内存可以通过unmap进行free,实现真正释放。既然堆内碎片不能直接释放,导致疑似“内存泄漏”问题, - 为什么malloc不全部使用mmap来实现呢?而仅仅对于大于128K的大块内存才使用mmap?
- 进程向OS申请和释放紧致空间的接口
sbrk/mmap/unmap都是系统调用,频繁的系统调用都比较消耗系统资源。并且,mmap申请的内存被unmap后,重新申请会产生更多的缺页中断。缺页中断属于内核行为,会导致内核态 CPU 消耗较大。 - 另外,使用 mmap 分配小内存,会导致地址空间的分片更多,内核的管理负担更大。
- 进程向OS申请和释放紧致空间的接口
7) 如何查看进程的缺页中断信息?
- 可通过以下命令查看缺页中断信息:
ps -o majflt,minflt -Cps -o majflt,minflt -p
8) 如何查看堆内内存的碎片情况?
-
glibc提供了以下结构和接口来查看堆内内存和 mmap 的使用情况: -
struct mallinfo { int arena; /* non-mmapped space allocated from system */ int ordblks; /* number of free chunks */ int smblks; /* number of fastbin blocks */ int hblks; /* number of mmapped regions */ int hblkhd; /* space in mmapped regions */ int usmblks; /* maximum total allocated space */ int fsmblks; /* space available in freed fastbin blocks */ int uordblks; /* total allocated space */ int fordblks; /* total free space */ int keepcost; /* top-most, releasable (via malloc_trim) space */ }; -
/* 返回 heap(main_arena) 的内存使用情况,以 mallinfo 结构返回 */ struct mallinfo mallinfo(); /* 将 heap 和 mmap 的使用情况输出到 stderr */ void malloc_stats(); -
可通过以下例子来验证 mallinfo 和 malloc_stats 输出结果:
-
#include#include #include #include #include #include size_t heap_malloc_total, heap_free_total, mmap_total, mmap_count; void print_info() { struct mallinfo mi = mallinfo(); printf("count by itself:\n"); printf("\theap_malloc_total=%lu heap_free_total=%lu heap_in_use=%lu\n\ \tmmap_total=%lu mmap_count=%lu\n", heap_malloc_total*1024, heap_free_total*1024, heap_malloc_total*1024 - heap_free_total*1024, mmap_total*1024, mmap_count); printf("count by mallinfo:\n"); printf("\theap_malloc_total=%lu heap_free_total=%lu heap_in_use=%lu\n\ \tmmap_total=%lu mmap_count=%lu\n", mi.arena, mi.fordblks, mi.uordblks, mi.hblkhd, mi.hblks); printf("from malloc_stats:\n"); malloc_stats(); } #define ARRAY_SIZE 200 int main(int argc, char** argv) { char** ptr_arr[ARRAY_SIZE]; int i; for( i = 0; i < ARRAY_SIZE; i++) { ptr_arr[i] = malloc(i * 1024); if ( i < 128) heap_malloc_total += i; else { mmap_total += i; mmap_count++; } } print_info(); for( i = 0; i < ARRAY_SIZE; i++) { if ( i % 2 == 0) continue; free(ptr_arr[i]); if ( i < 128) heap_free_total += i; else { mmap_total -= i; mmap_count--; } } printf("\nafter free\n"); print_info(); return 1; } -
下面是一个执行结果:
-
count by itself: heap_malloc_total=8323072 heap_free_total=0 heap_in_use=8323072 mmap_total=12054528 mmap_count=72 count by mallinfo: heap_malloc_total=8327168 heap_free_total=2032 heap_in_use=8325136 mmap_total=12238848 mmap_count=72 from malloc_stats: Arena 0: system bytes = 8327168 in use bytes = 8325136 Total (incl. mmap): system bytes = 20566016 in use bytes = 20563984 max mmap regions = 72 max mmap bytes = 12238848 after free count by itself: heap_malloc_total=8323072 heap_free_total=4194304 heap_in_use=4128768 mmap_total=6008832 mmap_count=36 count by mallinfo: heap_malloc_total=8327168 heap_free_total=4197360 heap_in_use=4129808 mmap_total=6119424 mmap_count=36 from malloc_stats: Arena 0: system bytes = 8327168 in use bytes = 4129808 Total (incl. mmap): system bytes = 14446592 in use bytes = 10249232 max mmap regions = 72 max mmap bytes = 12238848- 程序统计和 mallinfo 得到的信息基本吻合,
- 其中
heap_free_total表示堆内已释放的内存碎片总和。 - 如果想知道堆内片究竟有多碎 ,可通过
mallinfo结构中的fsmblks、smblks、ordblks值得到,这些值表示不同大小区间的碎片总个数,这些区间分别是0~80字节,80~512字节,512~128k 。 - 如果
fsmblks、smblks的值过大,那碎片问题可能比较严重了。 mallinfo结构有一个很致命的问题,就是其成员定义全部都是int,在 64 位环境中,其结构中的uordblks/fordblks/arena/usmblks很容易就会导致溢出。
-