milvus 结合Thowee 文本转向量 ,新建表,存储,搜索,删除
1.向量数据库科普
【上集】向量数据库技术鉴赏
【下集】向量数据库技术鉴赏
milvus连接
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
connections.connect(host='124.****', port='19530')
2.milvus + Thowee 文本转向量 使用
@app.route("/es",methods=["GET","POST"])
def es_sous():
ans_pipe = (
pipe.input('subject')
.map('subject', 'vector', ops.text_embedding.dpr(model_name="facebook/dpr-ctx_encoder-single-nq-base"))#将输入的问题文本转换为向量表示,使用名为 "facebook/dpr-ctx_encoder-single-nq-base" 的预训练模型进行文本嵌入。
.map('vector', 'vector', lambda x: x / np.linalg.norm(x, axis=0))#对上一步得到的向量进行归一化处理,使得向量的每个维度都被缩放到相同尺度。
.output('vector')
)
param = request.args.get('prop')#传入一个文本
ans = ans_pipe(param)#文本转向量
ans = DataCollection(ans)#格式化
ans.show() #
print(type(ans[0].vector))
list1 = ans[0].vector.tolist()
return list1

3.milvus + openai 文本转向量 使用
import openai
OPENAI_ENGINE = 'text-embedding-ada-002'#使用哪种嵌入模型
openai.api_key = 'sk-*****'#您的 OpenAI 帐户密钥
def embed(texts): #返回 向量
embeddings = openai.Embedding.create(
input=texts,
engine=OPENAI_ENGINE
)
return [x['embedding'] for x in embeddings['data']]
4. milvus + 微软openai 文本转向量 使用
import openai
openai.api_key = "0**********" # Azure 的密钥
openai.api_base = "https://zhan.op*****" # Azure 的终结点
openai.api_type = "azure"
openai.api_version = "2023-03-15-preview" # API 版本,未来可能会变
model = "text" # 模型的部署名
def embed(texts):
embeddings = openai.Embedding.create(
input=texts,
engine=model
)
return [x['embedding'] for x in embeddings['data']]
5.milvus 新建表
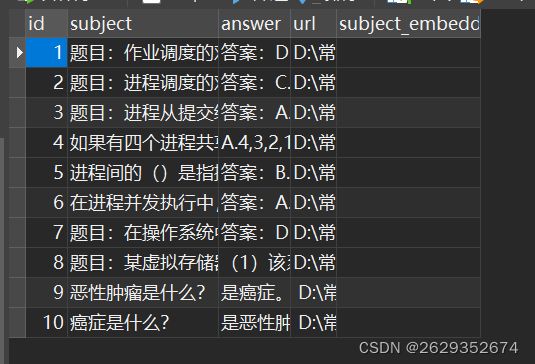
def create_milvus_collection(collection_name,dim):
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
fields = [
FieldSchema(name = 'id',dtype=DataType.INT64,description='ids',is_primary=True),
FieldSchema(name='answer',dtype=DataType.VARCHAR,max_length = 2000,description='答案'),
FieldSchema(name='subject',dtype=DataType.VARCHAR,max_length = 1000,description='题目'),
FieldSchema(name='subject_embedding', dtype=DataType.FLOAT_VECTOR, dim=dim,description = '题目矢量'),
FieldSchema(name='url', dtype=DataType.VARCHAR, max_length = 255,description = '路径')
]
# CollectionSchema:这是一个用于定义数据表结构的类。
schema = CollectionSchema(fields = fields,description='Test')
collection = Collection(name=collection_name,schema=schema)
index_params = {
'metric_type': 'L2',
'index_type': "IVF_FLAT",
'params': {"nlist": 2048}
}
collection.create_index(field_name="subject_embedding",index_params=index_params)
return collection
collections = create_milvus_collection('Test',768) # 表名 , 模型维度
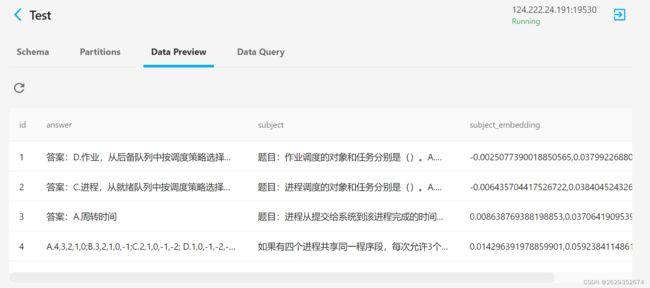
6.milvus存储
1.milvus存储 和 thowee 管道
insert = (
pipe.input('id','subject','answer','url','subject_embedding')
#将输入的问题文本转换为向量表示,使用名为 "facebook/dpr-ctx_encoder-single-nq-base" 的预训练模型进行文本嵌入。
.map('subject','vec',ops.text_embedding.dpr(model_name='facebook/dpr-ctx_encoder-single-nq-base'))
# 对上一步得到的向量进行归一化处理,使得向量的每个维度都被缩放到相同尺度。
.map('vec', 'vec', lambda x: x / np.linalg.norm(x, axis=0))
.map(('id','answer','subject','vec','url'),'insert_status',ops.ann_insert.milvus_client(host='124。*****', port='19530', collection_name='Test'))#进行存储
.output()#返回
)
2.milvus存储 和 原始的存储方案
milvus = Milvus(host=HOST, port=PORT) # milvus 连接
data1 = [
[],
[],# subject
[],# option
[],# answer
[],#knowledgepoints
[],#img
[],#video
[],#parse
]
data1[0].append(None)
data1[1].append(request.args.get('subject'))
data1[2].append(request.args.get('option'))
data1[3].append(request.args.get('answer'))
data1[4].append(request.args.get('knowledgepoints'))
data1[5].append(request.args.get('img'))
data1[6].append(request.args.get('video'))
data1[7].append(request.args.get('parse'))
data1.append(embed(data1[1]))# 转向量
milvus.insert(collection_name=COLLECTION_NAME,entities=data1)# 调用 insert 新增 表名+数据
return "ok"
7.milvus 搜索
# milvus 搜索
# 搜索 索引
QUERY_PARAM = {
"metric_type": "L2",
"params": {"ef": 64},
}
collection.search()
res = collection.search(embed(request.args.get('subject')), anns_field='subject_embedding', param=QUERY_PARAM, limit = 1, output_fields=['id', 'subject', 'answer','option'])
# 向量 , 指定被搜索字段,索引,top1,返回字段
______________________________________________例子
import openai
from pymilvus import connections, utility, FieldSchema, Collection, CollectionSchema, DataType
HOST = '124.**********'
PORT = 19530
COLLECTION_NAME = 'mo'#在 Milvus 中如何命名
DIMENSION = 1536 #嵌入的维度
OPENAI_ENGINE = 'text-embedding-ada-002'#使用哪种嵌入模型
openai.api_key = 'sk-***************'#您的 OpenAI 帐户密钥
QUERY_PARAM = {
"metric_type": "L2",
"params": {"ef": 64},
}
connections.connect(host=HOST, port=PORT)
def embed(texts):
embeddings = openai.Embedding.create(
input=texts,
engine=OPENAI_ENGINE
)
return [x['embedding'] for x in embeddings['data']]
collection = Collection(COLLECTION_NAME)
def query(query, top_k = 5):
text = query
res = collection.search(embed(text), anns_field='subject_embedding', param=QUERY_PARAM, limit = top_k, output_fields=['id', 'subject', 'answer'])
print(res)
my_query = ('P、V操作是一种')
query(my_query)
![]()
milvus 搜索 + thowee管道 搜索
ans_pipe = (
pipe.input('subject')
.map('subject', 'vector', ops.text_embedding.dpr(model_name="facebook/dpr-ctx_encoder-single-nq-base"))#将输入的问题文本转换为向量表示,使用名为 "facebook/dpr-ctx_encoder-single-nq-base" 的预训练模型进行文本嵌入。
.map('vector', 'vector', lambda x: x / np.linalg.norm(x, axis=0))#对上一步得到的向量进行归一化处理,使得向量的每个维度都被缩放到相同尺度。
.flat_map('vector', ('id','score', 'answer','subject'), ops.ann_search.milvus_client(host='124.222.24.191',
port='19530',
collection_name='Test',
output_fields=['answer','subject']))
.output('subject','id','score','answer')
)
ans = ans_pipe('恶性肿瘤是什么?')
ans = DataCollection(ans)
ans.show()
8.milvus 删除
emb_collection.delete(expr=f"id == [{emb_id}]") # failed
emb_collection.delete(expr=f"id in [{emb_id}]") # Success