【无标题】

去年年初,老苏折腾过 Meilisearch,当时遗留下一个问题,怎么用 Meilisearch 来对老苏的博客进行全文检索,不过很可惜没有成功
文章传送门:开源全文搜索引擎MeiliSearch
帅哥 初冬 最近在部署公司开源项目的帮助文档,老苏发现文档搜索居然采用了 Meilisearch,一番请教之后,老苏决定换个思路,既然自己不会改博文索引,就试试 Meilisearch 官方提供的爬虫 docs-scraper,通过爬虫来生成的博文索引,说干就干。
安装
在群晖上以 Docker 方式安装。
安装 Meilisearch
如果你已经安装过了 Meilisearch ,可以跳到下一个章节
# 新建文件夹 meilisearch 和 子目录
mkdir -p /volume1/docker/meilisearch/data
# 进入 meilisearch 目录
cd /volume1/docker/meilisearch
# 运行容器
# Launch Meilisearch in development mode with a master key
docker run -d \
--restart unless-stopped \
--name meilisearch \
-p 7700:7700 \
-v $(pwd)/data:/meili_data \
-e MEILI_ENV='development' \
-e MEILI_MASTER_KEY='27bb9198372f81f8b95fb75d0252912de061fb6fa90d0ad6eb347cc051f0abe3' \
getmeili/meilisearch:latest
latest对应的版本为v1.3.5
MEILI_ENV:指定为development模式;MEILI_MASTER_KEY:指定master key,至少16字节的UTF-8字符串,老苏一般是用Vaultwarden的密码生成器来生成,这是为了保护Meilisearch实例免遭未经授权的使用,所以必须在启动时提供主密钥;
创建 API Key
实例受到保护后,要访问任何 API 端点,必须向您的请求添加具有适当权限的安全密钥。
而实际上,当您第一次启动实例时,Meilisearch 已经自动生成了两个 API 密钥:Default Search API Key和Default Admin API Key。
其中:
Default Search API Key:只能用于访问搜索路径;Default Admin API Key:可以访问除/keys之外的所有API路由。您应该避免在可公开访问的代码中公开默认的管理密钥。
接下来我们需要做的就是获取到这两个 API Key
v0.24 及以下版本使用
X-MEILI-API-KEY: apiKey, v0.25 及以上版本使用Authorization: Bearer apiKey
# 获取不同权限的 API Key
curl \
-H "Authorization: Bearer 27bb9198372f81f8b95fb75d0252912de061fb6fa90d0ad6eb347cc051f0abe3" \
-X GET 'http://192.168.0.197:7700/keys'
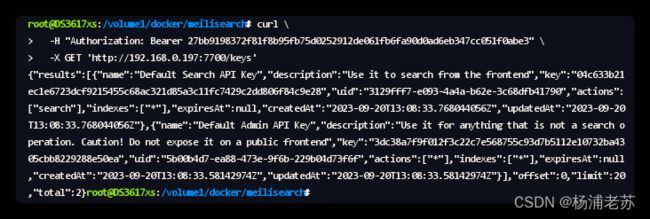
返回的结果在 https://www.json.cn 格式化之后
{
"results":[
{
"name":"Default Search API Key",
"description":"Use it to search from the frontend",
"key":"04c633b21ec1e6723dcf9215455c68ac321d85a3c11fc7429c2dd806f84c9e28",
"uid":"3129fff7-e093-4a4a-b62e-3c68dfb41790",
"actions":[
"search"
],
"indexes":[
"*"
],
"expiresAt":null,
"createdAt":"2023-09-20T13:08:33.768044056Z",
"updatedAt":"2023-09-20T13:08:33.768044056Z"
},
{
"name":"Default Admin API Key",
"description":"Use it for anything that is not a search operation. Caution! Do not expose it on a public frontend",
"key":"3dc38a7f9f012f3c22c7e568755c93d7b5112e10732ba4305cbb8229288e50ea",
"uid":"5b00b4d7-ea88-473e-9f6b-229b04d73f6f",
"actions":[
"*"
],
"indexes":[
"*"
],
"expiresAt":null,
"createdAt":"2023-09-20T13:08:33.58142974Z",
"updatedAt":"2023-09-20T13:08:33.58142974Z"
}
],
"offset":0,
"limit":20,
"total":2
}
创建 config.json
scraper 工具需要一个配置文件来了解您想要抓取的内容。这是通过提供选择器(例如,HTML标记)来实现的。
将下面的文件保存为 config.json,并将其上传到 meilisearch 根目录
{
"index_uid": "blog",
"start_urls": [
"https://laosu.cf"
],
"sitemap_urls": [
"https://laosu.cf/sitemap.xml"
],
"stop_urls": [],
"selectors": {
"lvl0": {
"selector": "h1.post-title",
"global": true,
"default_value": "Documentation"
},
"lvl1": {
"selector": ".post-body h1",
"global": true,
"default_value": "Chapter"
},
"lvl2": ".post-body h2",
"lvl3": ".post-body h3",
"lvl4": ".post-body h4",
"text": ".post-body p, .post-body li, .post-body figure, .post-body table"
}
}
运行 docs-scraper
docs-scraper是Meilisearch提供并维护的一个抓取工具,可以自动读取您网站的内容,并将其存储在Meilisearch的索引中。
现在可以开始抓取了
# 运行容器
docker run -it --rm \
--name meilisearch-scraper \
-v $(pwd)/config.json:/docs-scraper/config.json \
-e MEILISEARCH_HOST_URL='http://192.168.0.197:7700' \
-e MEILISEARCH_API_KEY='27bb9198372f81f8b95fb75d0252912de061fb6fa90d0ad6eb347cc051f0abe3' \
getmeili/docs-scraper:latest pipenv run ./docs_scraper config.json
MEILISEARCH_HOST_URL:指定meilisearch的url地址;MEILISEARCH_API_KEY:老苏用了master key;

在抓取过程中, CPU 可能会飙升

如果网站发布了新的文章,需要重新抓取一次,这样能保持最新的索引
运行
抓取完成后,在浏览器中输入 http://群晖IP:7700 就能看到 Meilisearch 的主界面
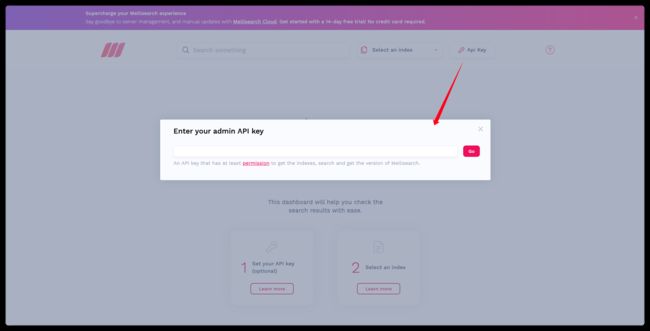
输入 Admin API Key 后就可以开始使用了

搜索 admin@shinobi.video,很快就返回了结果,点链接可以直接打开文章
搜索条
在台式机上新建一个 search-bar.html 文件,内容如下:
DOCTYPE html>
<html>
<head>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/docs-searchbar.js@latest/dist/cdn/docs-searchbar.min.css" />
head>
<body>
<input type="search" id="search-bar-input">
<script src="https://cdn.jsdelivr.net/npm/docs-searchbar.js@latest/dist/cdn/docs-searchbar.min.js">script>
<script>
docsSearchBar({
hostUrl: 'http://192.168.0.197:7700',
apiKey: '04c633b21ec1e6723dcf9215455c68ac321d85a3c11fc7429c2dd806f84c9e28',
indexUid: 'blog',
inputSelector: '#search-bar-input',
debug: true // Set debug to true if you want to inspect the dropdown
});
script>
body>
html>
hostUrl: 是Meilisearch的访问地址,如果远程访问的话可以反代成域名;apiKey:用前面获取的Default Search API Key;indexUid:就是在config.json中设置的index_uid的值;
直接在浏览器中打开 search-bar.html 文件,只会在左上角看个一个文本框

继续搜索 admin@shinobi.video

当然,如果你熟悉 html 的话,完全可以把上面这段 html 嵌入到你自己的页面中
参考文档
meilisearch/docs-scraper: Scrape documentation into Meilisearch
地址:https://github.com/meilisearch/docs-scraper
Meilisearch Documentation
地址:https://www.meilisearch.com/docs/learn/cookbooks/search_bar_for_docs#scrape-your-content
使用MeiliSearch实现Hugo博客搜索 | Jefferywang的烂笔头
地址:https://blog.wangjunfeng.com/post/hugo-meilisearch/