Mysql分库分表
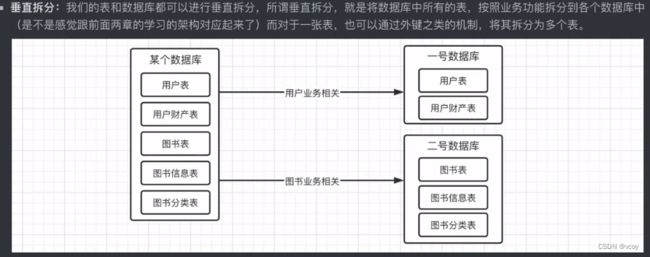
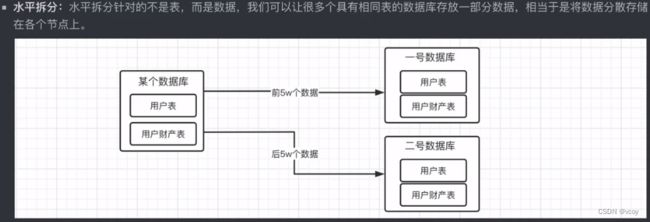
1.原理


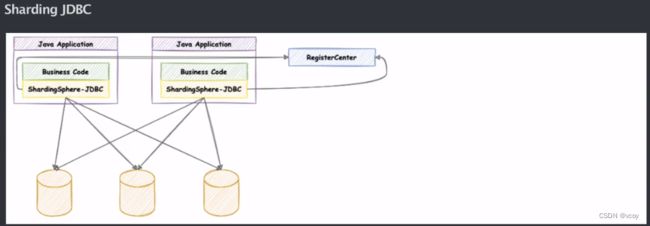
2.Sharding JDBC
官网https://shardingsphere.apache.org/
2.1 水平拆分
创建一个新的springboot项目
导入依赖,直接将原本的dependencies给覆盖掉
<dependencies>
<!-- ShardingJDBC依赖 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.0</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.31</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>

在本地和远端创建数据库
create database yyds;
use yyds;
create table test (
`id` int primary key,
`name` varchar(255) NULL,
`passwd` varchar(255) NULL
);


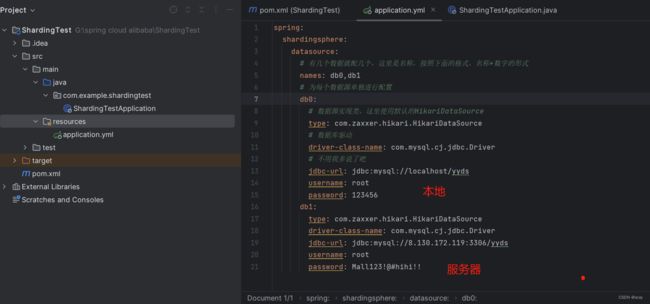
配置两个数据源
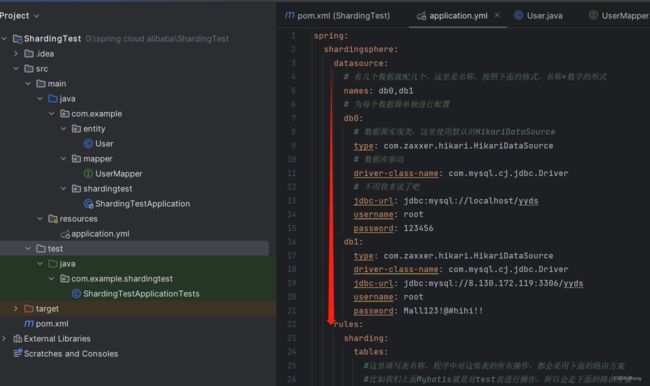
spring:
shardingsphere:
datasource:
# 有几个数据就配几个,这里是名称,按照下面的格式,名称+数字的形式
names: db0,db1
# 为每个数据源单独进行配置
db0:
# 数据源实现类,这里使用默认的HikariDataSource
type: com.zaxxer.hikari.HikariDataSource
# 数据库驱动
driver-class-name: com.mysql.cj.jdbc.Driver
# 不用我多说了吧
jdbc-url: jdbc:mysql://192.168.0.8:3306/yyds
username: root
password: 123456
db1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://192.168.0.13:3306/yyds
username: root
password: 123456
添加实体类和mapper
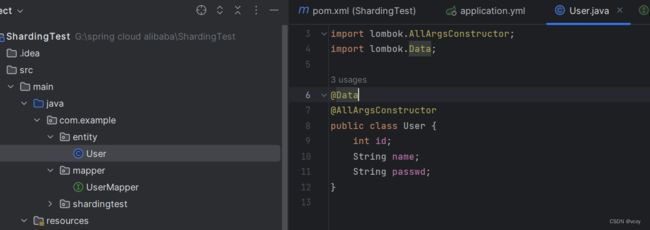
@Data
@AllArgsConstructor
public class User {
int id;
String name;
String passwd;
}
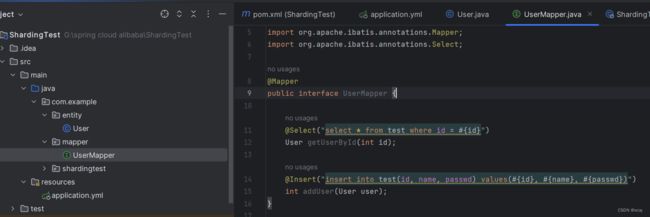
@Mapper
public interface UserMapper {
@Select("select * from test where id = #{id}")
User getUserById(int id);
@Insert("insert into test(id, name, passwd) values(#{id}, #{name}, #{passwd})")
上述代码都是正常业务。现在需要编写配置文件,告诉ShardingJDBC要如何进行分片。首先明确:现在是两个数据库都有test表存放用户数据,目标是将用户信息分别存放到这两个数据库的表中。
进行配置
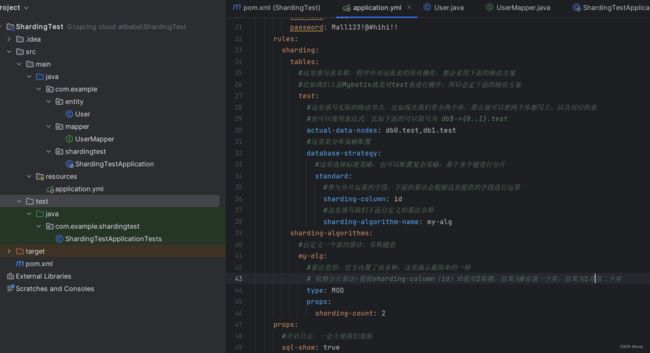
spring:
shardingsphere:
rules:
sharding:
tables:
#这里填写表名称,程序中对这张表的所有操作,都会采用下面的路由方案
#比如我们上面Mybatis就是对test表进行操作,所以会走下面的路由方案
test:
#这里填写实际的路由节点,比如现在我们要分两个库,那么就可以把两个库都写上,以及对应的表
#也可以使用表达式,比如下面的可以简写为 db$->{0..1}.test
actual-data-nodes: db0.test,db1.test
#这里是分库策略配置
database-strategy:
#这里选择标准策略,也可以配置复杂策略,基于多个键进行分片
standard:
#参与分片运算的字段,下面的算法会根据这里提供的字段进行运算
sharding-column: id
#这里填写我们下面自定义的算法名称
sharding-algorithm-name: my-alg
sharding-algorithms:
#自定义一个新的算法,名称随意
my-alg:
#算法类型,官方内置了很多种,这里演示最简单的一种
# 取模分片算法-根据sharding-column(id)的值对2取模,结果为0存第一个库,结果为1存第二个库
type: MOD
props:
sharding-count: 2
props:
#开启日志,一会方便我们观察
sql-show: true

编写测试类测试
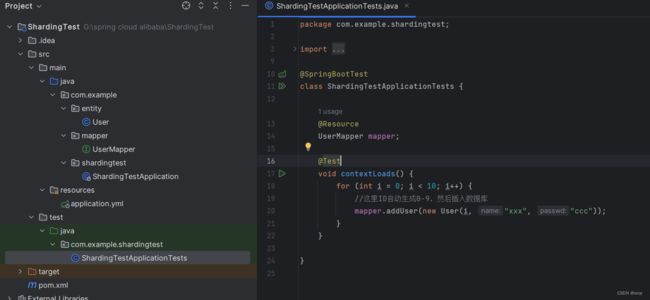
@Resource
UserMapper mapper;
@Test
void contextLoads() {
for (int i = 0; i < 10; i++) {
//这里ID自动生成0-9,然后插入数据库
mapper.addUser(new User(i, "xxx", "ccc"));
}
}
这里出现注入错误,需要在启动类上加上@MapperScan(“com.example.mapper”)注解。分析日志往往在最后一句,不需要将所有报错信息都进行查找。
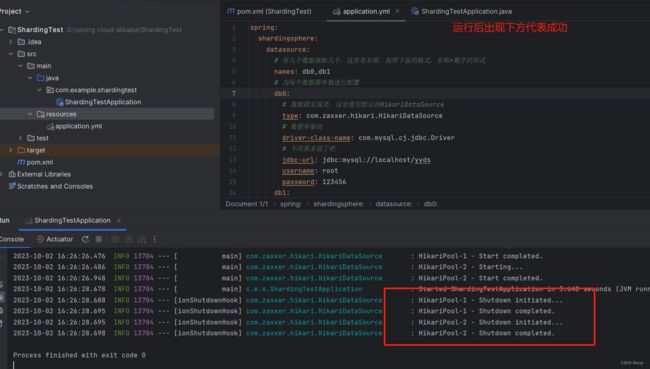
运行测试类后结果
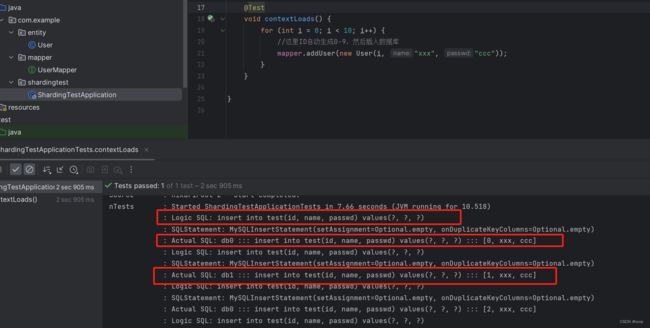

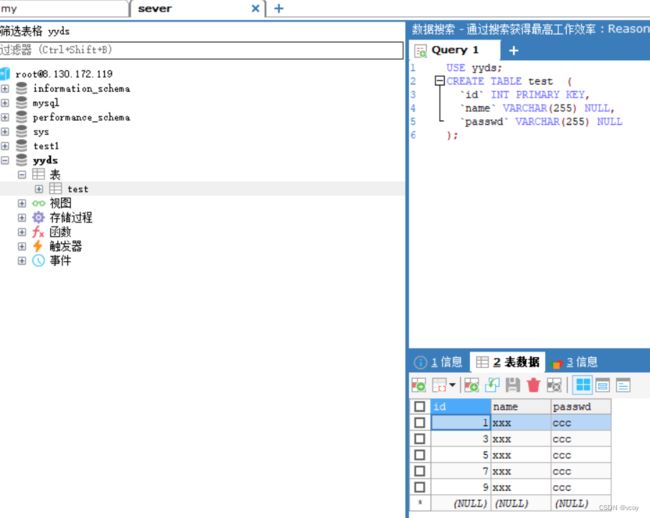
这样就实现了分库策略。
实现分表策略

以本地数据库为例,创建两张表
create table test_0 (
`id` int primary key,
`name` varchar(255) NULL,
`passwd` varchar(255) NULL
);
create table test_1 (
`id` int primary key,
`name` varchar(255) NULL,
`passwd` varchar(255) NULL
);

在分库策略基础上只修改配置文件内容
rules:
sharding:
tables:
test:
#db0.test_$->{0..1}
actual-data-nodes: db0.test_0,db0.test_1
#现在我们来配置一下分表策略,注意这里是table-strategy上面是database-strategy
table-strategy:
#基本都跟之前是一样的
standard:
sharding-column: id
sharding-algorithm-name: my-alg
sharding-algorithms:
my-alg:
#这里我们演示一下INLINE方式,我们可以自行编写表达式来决定
type: INLINE
props:
#比如我们还是希望进行模2计算得到数据该去的表
#只需要给一个最终的表名称就行了test_,后面的数字是表达式取模算出的
#实际上这样写和MOD模式一模一样
algorithm-expression: test_$->{id % 2}
#没错,查询也会根据分片策略来进行,但是如果我们使用的是范围查询,那么依然会进行全量查询
#这个我们后面紧接着会讲,这里先写上吧,false代表不允许全量查询
allow-range-query-with-inline-sharding: false
props:
#开启日志,一会方便我们观察
sql-show: true

再次测试
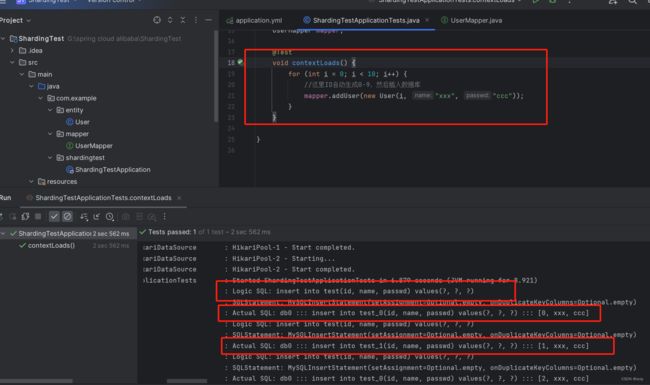
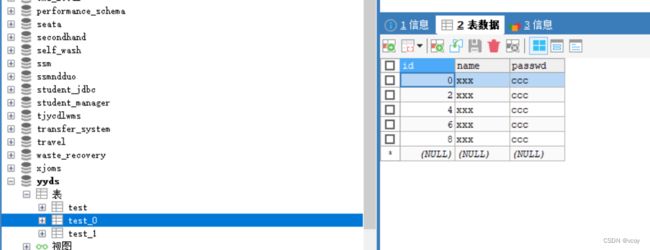
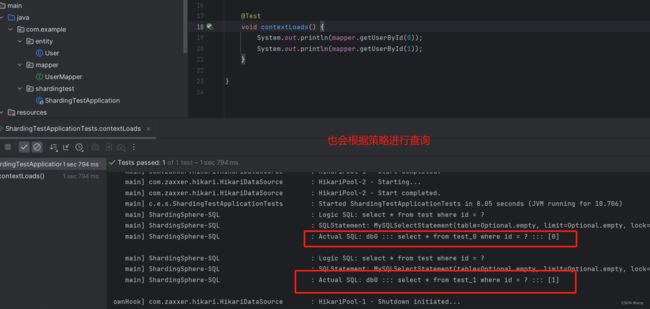
测试查询
@Test
void contextLoads() {
System.out.println(mapper.getUserById(0));
System.out.println(mapper.getUserById(1));
}
测试范围查询
@Select("select * from test where id between #{start} and #{end}")
List<User> getUsersByIdRange(int start, int end);

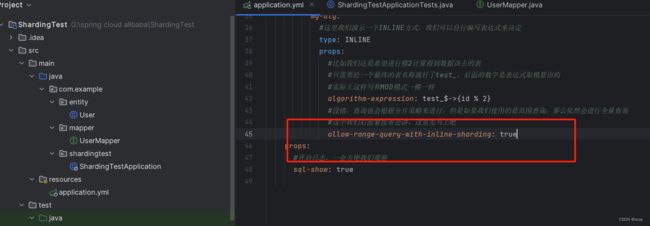
将配置文件的允许范围查询改为allow-range-query-with-inline-sharding改为true
测试范围查询
@Test
void contextLoads() {
System.out.println(mapper.getUsersByIdRange(3, 5));
}
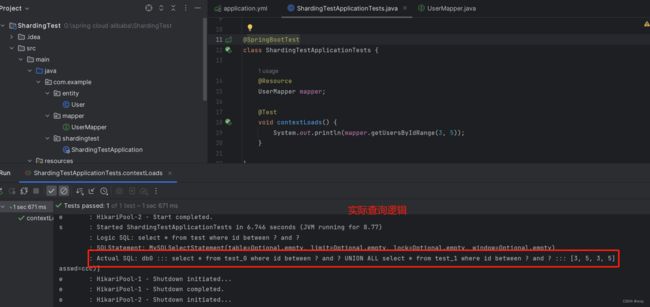

最终得出来的sql语句是直接对两个表都进行查询,然后求出一个并集算出来作为最后的结果。