Transformer在小目标检测上的应用
本篇文章是博主在AI、无人机、强化学习等领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对人工智能等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在AI学习笔记:
AI学习笔记(1)---《Transformer在小目标检测上的应用》
Transformer在小目标检测上的应用
目录
1 小目标检测介绍
2 引入transformer
3 用于小目标检测的Transformer
4 基于Transformer的端到端目标检测算法
4.1 DETR(ECCV2020)
4.2 Pix2seq(谷歌Hinton)
4.3 稀疏注意力Deformable DETR(ICLR 2021)
原文/论文出处:
- 题目:
- 1.《Transformers in Small Object Detection: A Benchmark and Survey of State-of-the-Art》
- 2.《小目标检测的福音 | 一文全览3年来Transformer是怎么在小目标领域大杀四方的?》
- 3.《大规模小目标检测》
- 4.《Transformer用于小目标检测有哪些文献或者方法?》
- 时间:2023-09-12
- 来源:IEEE、AI视界引擎、知乎-自动驾驶之心,龟壳
1 小目标检测介绍
小目标检测(Small Object Detection, SOD)作为通用目标检测的一个子领域,专注于对小尺寸目标的检测,在监控、无人机场景分析、行人检测、自动驾驶中的交通标志检测等各种场景中都具有重要的理论和现实意义。
虽然在一般目标检测方面已经取得了长足的进展,但SOD的研究进展相对缓慢。更具体地说,即使是领先的检测器,在检测小尺寸物体和正常大小物体方面仍然存在巨大的性能差距。
目标检测,尤其是小目标检测(SOD),长期以来一直依赖于基于CNN的深度学习模型。
参考论文原文:
Towards Large-Scale Small Object Detection: Survey and Benchmarks
2 引入transformer
Transformer模型首次作为一种新颖的机器翻译技术被引入。该模型旨在超越传统的循环网络和CNN,通过引入一种完全基于注意力机制的新网络架构,从而消除了对循环和卷积的需求。
Transformer模型由两个主要模块组成:编码器和解码器。
现有的基于新型Transformer的检测器可以通过以下一个或几个角度进行分析:目标表示、对高分辨率或多尺度特征图的快速关注、完全基于Transformer的检测、架构和块修改、辅助技术、改进的特征表示和时空信息。
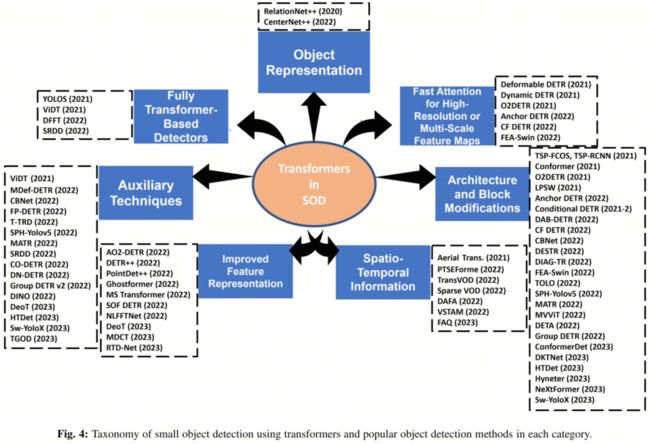
3 用于小目标检测的Transformer
分类法将基于Transformer的小目标检测器分为7个主要类别:目标表示、快速注意力(适用于高分辨率和多尺度特征图)、架构和块修改、时空信息、改进的特征表示、辅助技术以及完全基于Transformer的检测器。
3.1 目标表示
通过一个称为 Bridging Visual Representations (BVR) 的模块,将各种异构的视觉表示连接起来,并通过关键采样和共享位置嵌入等新技术结合它们的优势。BVR 依赖于一个注意力模块,将一种表示形式指定为“主表示”(或Query),而将其他表示形式指定为“辅助表示”(或键)。
3.2 快速注意力
保持高分辨率的特征图对于保持SOD的高性能是必要的。与CNN相比,Transformer本质上具有更高的复杂性,因为它们与Token数量(例如像素数)的数量呈二次增长的复杂性。这种复杂性来自于需要在所有Token之间进行成对相关性计算的要求。
3.3 其他
通用应用方法分为3组:
-
基于CNN的方法
-
混合方法
-
仅基于Transformer的方法
预训练和多尺度学习是在小目标检测中取得卓越性能最有效的策略。
原文出处: AI视界引擎
《小目标检测的福音 | 一文全览3年来Transformer是怎么在小目标领域大杀四方的?》
4 基于Transformer的端到端目标检测算法
4.1 DETR(ECCV2020)
开山之作!DETR! 代码链接:https://github.com/facebookresearch/detr
论文提出了一种将目标检测视为直接集预测问题的新方法。DETR简化了检测流程,有效地消除了对许多人工设计组件的需求,如NMS或anchor生成。新框架的主要组成部分,称为DEtection TRansformer或DETR,是一种基于集合的全局损失,通过二分匹配强制进行一对一预测,以及一种transformer encoder-decoder架构。
给定一组固定的学习目标查询,DETR分析了目标和全局图像上下文之间的关系,以直接并行输出最后一组预测。与许多其他检测器不同,新模型概念简单,不需要专门的库。DETR在具有挑战性的COCO目标检测数据集上展示了与成熟且高度优化的Faster RCNN基线相当的准确性和运行时间。此外,DETR可以很容易地推广到以统一的方式输出全景分割。
DETR的网络结构如下图所示,从图中可以看出DETR由四个主要模块组成:backbone,编码器,解码器以及预测头。主干网络是经典的CNN,输出降采样32倍的feature。

性能不错,训练太慢,300 epochs。
4.2 Pix2seq(谷歌Hinton)
代码链接:https://github.com/google-research/pix2seq
一个简单而通用的目标检测新框架,其将目标检测转换为语言建模任务,大大简化了pipeline,性能可比肩Faster R-CNN和DETR!还可扩展到其他任务。
4.3 稀疏注意力Deformable DETR(ICLR 2021)
代码链接:https://github.com/fundamentalvision/Deformable-DETR
DETR以消除在物体检测中对许多手动设计部件的需要,同时证明了良好的性能。然而,由于Transformer注意力模块在处理图像特征图时的限制,它存在收敛速度慢和特征空间分辨率有限的问题。
为了缓解这些问题,论文提出了Deformable DETR,其注意力模块只关注参考周围的一小组关键采样点。Deformable DETR可以实现比DETR更好的性能(特别是在小目标上),训练时间减少10倍。COCO基准的大量实验证明了算法的有效性。
还有好多,具体请看原文,链接如下:
Transformer用于小目标检测有哪些文献或者方法?
文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者关注VX公众号:Rain21321,联系作者。