【linux】多线程概念详述
文章目录
- 一、线程基本概念
-
- 1.1 进程地址空间与页表
- 1.2 页表结构
- 1.3 线程的理解
-
- 1.3.1 如何描述线程
- 1.4 再谈进程
- 1.5 代码理解
-
- 1.5.1 原生库提供线程pthread_create
- 1.6 资源共享问题
- 1.7 资源私有问题
- 二、总结
-
- 2.1 什么是线程
- 2.2 并行与并发
- 2.3 线程的优点
- 2.4 线程的缺点
- 2.5 线程异常
- 2.6 进程与线程的区别
- 2.7 进程ID(tgid)与线程ID(pid)
一、线程基本概念
1.1 进程地址空间与页表
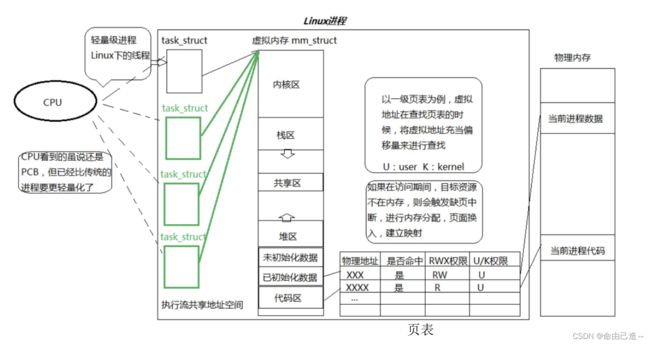
注意这里的页表部分:
在上一章【linux】进程信号——信号的保存和处理中我们讲了页表有用户级页表和内核级页表。如图其实页表还有其他很多属性。
举个例子:当我们对常量区的数据进行修改时,为什么会报错呢?
OS会先通过页表找到物理地址,然后查RWX权限,发现只有R权限,所以地址转换单元MMU会硬件报错,转化成信号,终止进程(段错误)。
而经过U/K权限的时候,如果是U就直接访问,是K就会去CPU查看当前的运行级别,是内核级别才能访问带K的映射关系。
那么该如何看待进程地址空间和页表呢?
1️⃣ 进程地址空间(虚拟内存)是进程能够看到的资源窗口。因为能看到的资源都是通过进程地址空间让我们看到的。
2️⃣ 页表是决定进程真正拥有资源的情况。
3️⃣ 合理的对进程地址空间+页表进行资源划分,就可以对进程的所有资源进行分类。
进程地址空间一共有2^32个地址。那么按道理页表也应该有2^32个条目,我们就当一个条目大小为1byte,也需要4GB的大小,更何况每个条目还得存很多数据。所以页表不可能会这么使用。
那么真实的页表到底是什么样子呢?
1.2 页表结构
首先说明几个点:
1️⃣ 进程地址空间的一个地址我们称为虚拟地址,有32个比特位。
2️⃣ 物理内存实际上也划分成了一个一个的数据页。OS为了管理每个数据页,每个数据页都有一个描述的结构体(非常小),存储内存的属性。每个页框大小为4KB
3️⃣ 磁盘上的可执行程序在被编译的时候也被划分成一个一个的4KB大小的数据块,我们把这种4KB的区域称为页帧。所以从磁盘加载到内存是以4KB为单位加载的。
虚拟地址的32个比特位并不是以一个整体转化的,而是分成10、10、12三块二进制构成。
而页表也不止一张,分为页目录、和页表。
先拿着虚拟地址的高十位去查页目录,比如如果是0000000001就是第二个位置,映射到指定的页表,再通过中间10个比特位确定物理内存中页框的起始地址,而一个页框的大小是4KB,有2^12字节,刚好对应虚拟地址的低12位比特位,就可以作为页内偏移量找到对应的位置。
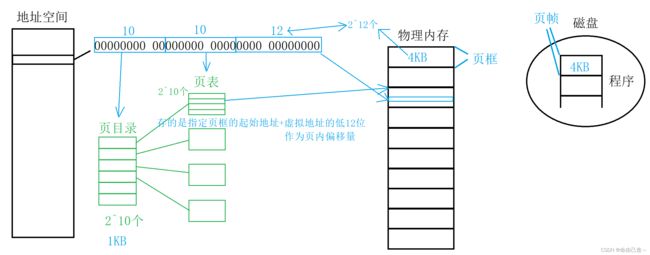
这样我们在使用的时候有可能只使用了几个页表,那么其他的页表就不会加载到内存,只有需要的时候才会创建。由此解决了内存不足的问题。
1.3 线程的理解
首先要知道线程是进程内的一个执行流。
我们知道创建一个进程就会连着创建PCB,虚拟内存、页表。现在我们可以创建一个“进程”(PCB)直接指向虚拟内存,就像下边的绿色的task_struct。

例如代码区有一大段代码,我们现在就可以划分成几个小段代码,分给每个“进程”。这样就实现了资源的分配。
我们可以通过虚拟地址空间和页表对进程进行资源划分,而单个“进程”的执行力度一定要比之前一个进程要细。
1.3.1 如何描述线程
既然有多个线程,那么OS就会采取先描述后组织的方式进行管理。那么怎么描述呢?是创建一个新的结构体来描述吗?
我们知道PCB是用来描述进程的,那么描述线程的结构体我们叫做TCB(线程控制块)。
在windows中,就是新创建了一个结构体来描述线程。
而单纯的从线程调度角度,进程和线程有很多地方是重叠的。
所以在linux中,没有创建针对线程的数据结构,而是直接复用PCB,用PCB来表示线程。
而CPU在进行调度的时候不关注到底是进程还是线程,只看task_struct。
总结一下:线程在进程内部(进程的地址空间内)执行,拥有该进程的一部分资源。
1.4 再谈进程
什么叫做进程呢?
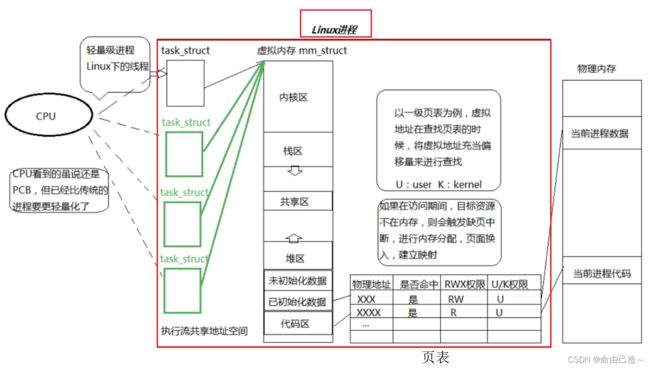
我们把红色框框圈起来的整体叫做进程:
PCB+进程地址空间+页表+加载到物理内存的代码和数据。
从内核角度:进程是承担分配系统资源的基本实体
在linux中:线程是CPU调度的基本单位
而在之前的文章讲过的进程【linux】进程概念详述它讲的是只有一个PCB的进程(只有一个执行流)。
今天所讲述的是一个进程内有多个执行流的情况。
从CPU角度:以前调度的就是一个进程,今天就是调度进程中的一个分支。
所以现在CPU统一把task_struct看作成轻量级进程。
我们知道linux没有正真意义的线程,这相比拥有真正线程的系统有什么优缺点呢?
优点:简单,维护成本大大降低,即可靠又高效。
缺点:linux无法直接提供线程的基本调用接口,只能提供创建轻量级进程的接口。
1.5 代码理解
1.5.1 原生库提供线程pthread_create
#include 参数说明:
thread:线程id
attr:线程属性,直接设为null
start_routine:函数指针
arg:这个参数会传递进start_routine的void*参数中。
这里在链接的时候要注意link到系统给的原生线程库-lpthread。

说明一下这个原生线程库:
因为用户只关注线程,但是OS不提供线程的接口,只提供创建轻量级进程的接口。所以在用户和OS之间加了一个用户级线程库。 向上提供各种线程接口,向下把对线程的各种操作转化为对轻量级进程的各种操作。
这个库在任何linux操作系统都默认存在。
// Makefile
mythread:mythread.cc
g++ -o $@ $^ -lpthread -std=c++11
.PHONY:clean
clean:
rm -f mythread
// mythread.cc
#include 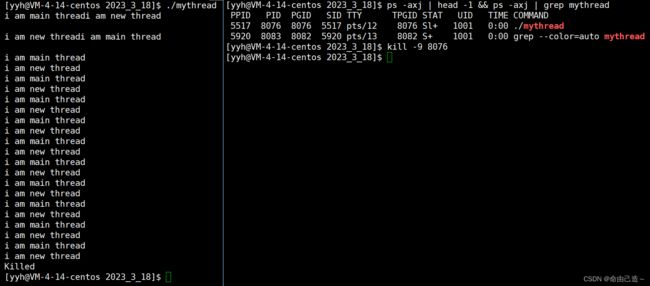
现象:运行了两个执行流,查看只有一个进程,杀死进程两个执行流全部被杀死。
如果想看到这两个轻量级线程:
使用指令:ps -aL
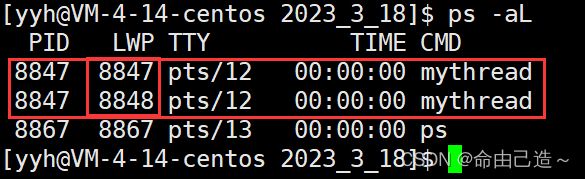
可以看到两个PID一样,说明属于同一个进程。而这里可以看到LWP不同,这里的LWP就表示轻量级进程ID。
细节:主线程的PID和LWP一样。
所以CPU在调度的时候用的就是LWP来作为标识符表示特定的执行流。
当只有一个单进程的时候PID和LWP是等价的。
那么这个tid到底是什么呢?
我们可以修改一下代码进行验证:
int main()
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, thread_stream, (void*)"thread one ");
assert(n == 0);
(void)n;
// 主线程
while(true)
{
char buf[64];
snprintf(buf, sizeof(buf), "0x%x", tid);
cout << "i am main thread " << "tid: " << buf << endl;
sleep(1);
}
return 0;
}
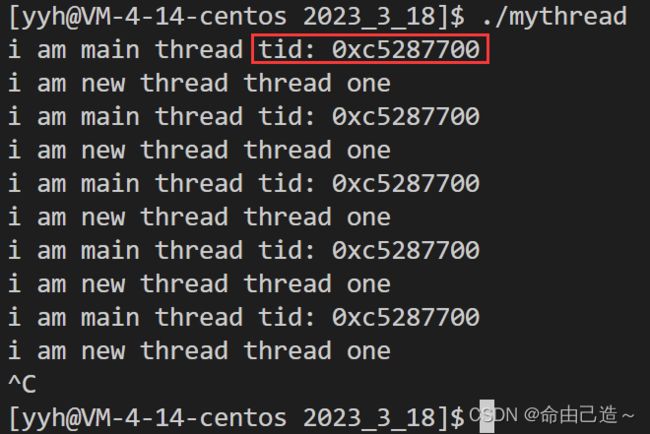
这里只需要知道tid就是一个地址,后面会详细介绍。
1.6 资源共享问题
线程一旦被创建,几乎所有的资源都是被所有线程共享的。
比如:
文件描述符表
每种信号处理方式(SIG,IGN,SIG_DFL或者自定义信号处理函数)
当前工作目录
用户id和组id
#include 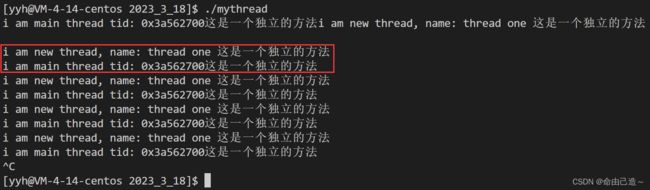
可以看到这个函数可以被多个线程同时访问。
那么全局变量呢?
int cnt = 0;
void* thread_stream(void *str)
{
while(true)
{
cout << "i am new thread, name: " << (const char*)str << " cnt: " << cnt++ << " &cnt: " << &cnt << endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, thread_stream, (void*)"thread one ");
assert(n == 0);
(void)n;
// 主线程
while(true)
{
char buf[64];
snprintf(buf, sizeof(buf), "0x%x", tid);
cout << "i am main thread " << "tid: " << buf << " cnt: " << cnt << " &cnt: " << &cnt << endl;
sleep(1);
}
return 0;
}
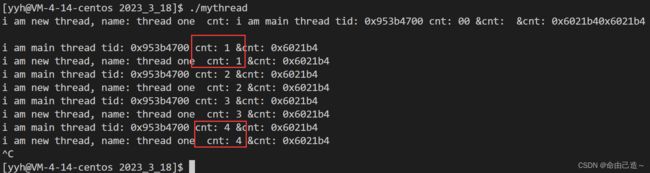
只要有一个线程中改变了,也会影响另一个进程。
由此可见线程之间通信非常容易。
但是这样又会引发另一个问题。
1.7 资源私有问题
线程也要有自己的私有资源,那么什么资源应该是线程所私有的呢?
1️⃣ PCB的属性(优先级,上下文(线程动态切换),状态……)。
2️⃣ 每一个线程都有自己独立的栈结构保存私有数据。
二、总结
2.1 什么是线程
笼统的讲:线程是在进程内部运行的一个执行分支(执行流),属于进程的一部分,粒度要比进程更加细致和轻量化。
- 在一个程序里的一个执行路线叫做线程,更准确的定义是:线程是”一个进程内部的控制序列“
- 一切进程至少都有一个执行线程
- 线程在进程内部运行,本质是在进程地址空间内运行
- 在Linux系统中,在CPU眼里,看到的PCB都要比传统的进程更加轻量化
- 透过进程虚拟地址空间,可以看到进程大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流。
2.2 并行与并发
并行:多个执行流在同一刻拿着不同的CPU进行运算。
并发:多个执行流在同一时刻只有一个执行流拥有CPU进行运算。
2.3 线程的优点
1️⃣ 创建线程的代价比创建进程小得多。因为不用创建地址空间、页表、加载代码数据,只用创建一个PCB指向进程地址空间就够了。
2️⃣ 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多。
进程要切换 页表、PCB、虚拟地址空间……
而线程切换只用切换PCB
那么他们做的工作量到底差距在哪里呢?
在CPU中有一块高速缓存cache,它的效率比寄存器慢,但比内存快。它有局部性原理:当前访问代码附近的代码数据也会被加载进来,有较大的概率被访问到。CPU不会从内存中直接读取数据,而是从cache中获取,没有命中就再从内存中加载数据到cache。而一个已经运行一段时间的进程cache内部会有很多“热点数据”,线程切换的时候并不会更新chche的数据(因为这些热点数据本来就是被线程所共享的),但是进程切换的时候chache内的数据立刻更新。这样chache又得重新缓存数据。
3️⃣ 线程的占有资源比进程小得多。
4️⃣ 能充分利用多处理器的可并行数量。
5️⃣ 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务。
6️⃣ 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现。计算密集型应用最常见的情况有:加密,大数据运算等—主要使用的是CPU资源。
7️⃣ I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
2.4 线程的缺点
1️⃣ 性能损失
一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
2️⃣ 健壮性(鲁棒性)降低
编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
验证:一个线程出现异常会影响其他线程吗?
void* thread_stream(void *str)
{
while(true)
{
cout << "i am new thread, name: " << (const char*)str << endl;
sleep(1);
// 一个线程出现异常
int* p = nullptr;
*p = 100;
}
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, thread_stream, (void*)"thread one ");
assert(n == 0);
(void)n;
// 主线程
while(true)
{
char buf[64];
snprintf(buf, sizeof(buf), "0x%x", tid);
cout << "i am main thread " << "tid: " << buf << endl;
sleep(1);
}
return 0;
}
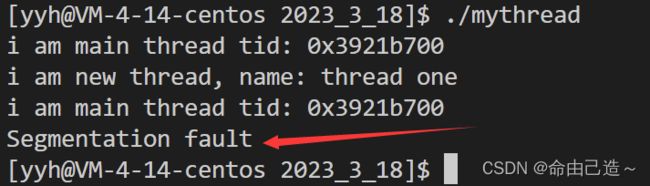
原因:线程出现了异常,OS就会发送信号到进程中,这个信号是发送给进程整体的,所以所有线程都会退出。
3️⃣ 缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
4️⃣ 编程难度提高
编写与调试一个多线程程序比单线程程序困难得多
2.5 线程异常
1️⃣ 单线程如果出现除零或野指针问题导致线程崩溃,进程也会跟着崩溃。
2️⃣ 因为进程具有独立性,导致其他进程最多只是对该进程只读但是不能写。而线程共用的是一个进程的地址空间,线程与线程之间的数据可以互相访问,当一个线程数据出错了,操作系统对该线程发信号,发信号只能发送给该线程对应的进程,进程跟着崩溃了,导致进程内的所有数据被释放,该进程内的其他线程也跟着销毁了(因为线程的数据是进程给的)。所以一个线程崩溃就会导致整个进程崩溃,这也造成了线程的健壮性降低的原因。
2.6 进程与线程的区别
资源分配和管理: 每个进程都有自己独立的地址空间、文件描述符、打开的文件、信号处理器等系统资源。而线程是在进程内创建的,它们共享同一个进程的资源,包括内存空间、文件描述符等。
调度和执行: 操作系统以进程为单位进行调度和执行,每个进程都有自己的执行环境和调度优先级。线程是在进程内调度和执行的,操作系统将进程中的线程分配给可用的处理器执行。
并发性和并行性: 由于每个进程都有自己独立的地址空间和资源,不同进程之间可以并发执行,即多个进程可以在同一时间段内执行。线程是进程内的执行单元,同一进程中的多个线程可以并发执行,实现多任务并行处理。
通信和同步: 进程之间的通信需要通过进程间通信(IPC)机制,如管道、共享内存、消息队列等。而线程之间共享同一进程的地址空间和资源,它们可以直接访问共享的内存,通过共享变量实现线程间的通信和同步。
创建和销毁开销: 创建和销毁进程的开销通常比创建和销毁线程的开销大,因为进程需要分配独立的资源和地址空间。线程的创建和销毁开销相对较小,因为它们共享进程的资源和地址空间。
2.7 进程ID(tgid)与线程ID(pid)
没有线程之前,一个进程对应内核里的一个进程描述符,对应一个进程ID。但是引入线程概念之后,情况发生了变化,一个用户进程下管辖N个用户态线程,每个线程作为一个独立的调度实体在内核态都有自己的进程描述符,进程和内核的描述符一下子就变成了1:N关系,POSIX标准又要求进程内的所有线程调用getpid函数时返回相同的进程ID,如何解决上述问题呢?
所以引入了线程组的概念。
多线程的进程,又被称为线程组,线程组内的每一个线程在内核之中都存在一个进程描述符(task_struct)与之对应。进程描述符结构体中的pid,表面上看对应的是进程ID,其实不然,它对应的是线程ID;进程描述符中的tgid,含义是Thread Group ID,该值对应的是用户层面的进程ID。现在介绍的线程ID,不同于pthread_t类型的线程ID,和进程ID一样,线程ID是pid_t类型的变量,是用来唯一标识线程的一个整型变量。
我们要清楚,在系统层面只有两个编号:pid、tgid。
不妨拿出task_struct结构体(进程PCB)看一看:
pid_t pid;
pid_t tgid;
我们知道,在linux中进程和线程都使用task_struct结构体实现。
在task_struct中:
pid即线程id。也就是task_struct的编号,每个task_struct各不相同。
tgid叫线程组id。也就是一个进程的id。同一个进程里每一个线程的task_struct中tgid值都一样。