一些可以参考的文档集合1
20211029
MyNikko.com 微處理器博物館 - Intel CPU Museum https://www.mynikko.com/CPU/index.html
https://www.mynikko.com/CPU/index.html
20211021

阿里开源的这个库,让 Excel 导出不再复杂(填充模板的使用指南)你好,我是看山。前文说了写操作,可以实现简单的列表导出,还能定义样式。有时候,我们还需要导出的一个大表单,或者是表单+列表的形式,这个时候,我们就需要填充功能。内容比较多,文内只会列出关键代码,想要完整源码,可以关注公号「看山的小屋」回复“easyexcel”获取。在 EasyExcel 中,写操作可以完成大部分工作,填充的优势在于,可以实现自定义样式的,只要在模板中设置好样式,填充的数据就能够带 https://xie.infoq.cn/article/97a373bcdcf973664e635ab40
https://xie.infoq.cn/article/97a373bcdcf973664e635ab40
可以从横向和纵向来看待低代码平台带来的作用。
横向:强调低代码平台的通用性,是否支持所见即所得,是否支持更复杂的模版,是否支持二次开发。面向不同的用户,则需要不同的能力。例如,面向运营同学使用的营销低代码平台,就会更加依赖所见即所得编辑能力和开箱即用的营销活动模版,使得非技术的业务人员也能方便的使用。
低代码平台的持续运营需要依赖标准化。通过抽象组件规范,定制组件交互,实现不同人开发的组件都满足统一的协议。低代码平台通过编排组件,使业务运转起来。
通常,标准化是比较难执行和推广的,随着团队人员更迭,成本往往越来越高。同时,标准化也是反人性的,用条条框框约束人,且没有对错可言,它带来了不自由,不灵活,易引起抵触情绪。只有低代码平台带来降本增效收益能够大于标准化所带来的“烦恼”,标准化才具备广泛推广的价值。
从平台生态的角度考虑,低代码平台需要强管控,把一些质量不高的组件挡在外面,否则一样会影响整个平台的口碑。这里要强调一下,好的管控不是靠人来实现的,而是靠技术手段来实现的。
纵向:强调的是领域内的业务纵深,比如专注于商品或者供应链等业务领域的前端组件。它们本身对其他业务没有帮助,但在其领域内可以带来极高的价值。
抽象领域内的组件往往需要对业务有深入的理解,并且对业务的“变”与“不变”有深入的思考和判断,这样才能做好判断,抽象和沉淀最体现业务本质的组件。
专访梁士兴:如何巧用低代码平台,避免研发怨声载道-InfoQ低代码一定程度上是把可复用的功能/模块粒度更细化,体积更小,便于引用。其次是可以把应用组件、视觉交互等标准化,便于协作。 因为一个低代码不可能解决所有的业务问题,业务与业务之间千差万别,如果拽过来一个组件,其定制的代码比组件的代码量还多,那样就没意义了。 可以从横向和纵向来看待低代码平台带来的作用。 横向:强调低代码平台的通用性,是否支持所见即所得,是否支持更复杂的模版,是否支持二次开发。面向不同 https://www.infoq.cn/article/sPABHwKCYkMzLFmYtAxJ
https://www.infoq.cn/article/sPABHwKCYkMzLFmYtAxJ
通过 Jenkins Pipeline 与 SonarQube 集成,对代码进行扫描
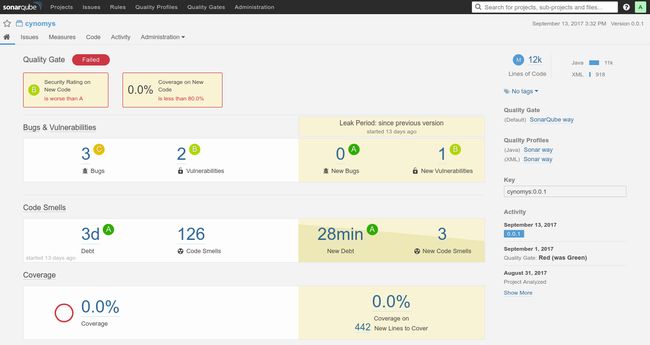
代码质量管理:SonarQube + Jenkins Pipeline配置你好,我是看山。前段时间对自己的项目进行代码质量扫描,曾经以为自己的代码质量算是不错的,结果发现一堆的 bug 或者 smell code,灵魂受到 1w 点伤害。可以想到,在时间紧、任务重的情况下,代码质量绝对是不能够保证的,虽然功能算是完整,但是可能就在某个隐藏的角落,就有无数的 bug 在潜伏着,所以有时间的话都对自己的代码进行代码质量检查吧。虽然不能保证有完美的代码,但是可以把 bug 数https://xie.infoq.cn/article/3dce5ca6c888f890937b16e6e
heap dump 生产 jvm 快照,通过分析快照找到占用内存大的对象,从而找到代码位置。
通过设置-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=heapdump参数来生产快照
20211019
就WINDOWS端的加速原理来说,可以用7个步骤来解释:
- 客户端访问https://github.com
- 客户端向dns查询github.com的ip,FastGithub拦截dns数据包并伪造解析结果为127.0.0.1
- 客户端请求到FastGithub的https://127.0.0.1:443
- FastGithub使用fastgithub.cer颁发服务器证书给客户端
- FastGithub查询和计算github.com最快的ip
- FastGithub与github.com进行无sni的tls连接
- FastGithub将请求反向代理到https://github.com
https://github.com/dotnetcore/FastGithub/https://github.com/dotnetcore/FastGithub/
20211018
Spring 提供的 ResolvableType API,提供了更加简单易用的泛型操作支持
sping激活profile
写测试用例时,可以指定我们使用哪个 Profile:
@ActiveProfiles("remote")
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:spring-config.xml")
public class ServiceTest {
@Autowired
private UserService userService;
}
业务类
public abstract class UserService extends BaseService{ } @Profile("local") @Service public class LocalUserService extends UserService {} @Profile("remote") @Service public class RemoteUserService extends UserService {}
Spring 对 Java8 的时间类型支持
对 jsr310 的支持,只要能发现 java.time.LocalDate,DefaultFormattingConversionService 就会自动注册对 jsr310 的支持,只需要在实体/Bean 上使用 DateTimeFormat 注解:
class Entity{ @DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") private LocalDateTime dateTime; @DateTimeFormat(pattern = "yyyy-MM-dd") private LocalDate date; @DateTimeFormat(pattern = "HH:mm:ss") private LocalTime time;
}
@RequestMapping("/test")public String test(@ModelAttribute("entity") Entity entity) {return "test";}
当前端页面请求:
localhost:9080/spring4/test?dateTime=2013-11-11 11:11:11&date=2013-11-11&time=12:12:12
会自动进行类型转换
另外 spring4 也提供了对 TimeZone 的支持,比如在 springmvc 中注册了 LocaleContextResolver 相应实现的话(如 CookieLocaleResolver),我们就可以使用如下两种方式得到相应的 TimeZone:
RequestContextUtils.getTimeZone(request)LocaleContextHolder.getTimeZone()
不过目前的缺点是不能像 Local 那样自动的根据当前请求得到相应的 TimeZone,如果需要这种功能需要覆盖相应的如 CookieLocaleResolver 中的如下方法来得到:
protected TimeZone determineDefaultTimeZone(HttpServletRequest request) {return getDefaultTimeZone();}
-
另外还提供了 DateTimeContextHolder,其用于线程绑定 DateTimeContext;而 DateTimeContext 提供了如:Chronology、ZoneId、DateTimeFormatter 等上下文数据,如果需要这种上下文信息的话,可以使用这个 API 进行绑定。
-
比如在进行日期格式化时,就会去查找相应的 DateTimeFormatter,因此如果想自定义相应的格式化格式,那么使用 DateTimeContextHolder 绑定即可。
【Spring技术特性】带你看看那些可能你还不知道的特性技巧哦!前提介绍本文主要介绍相关Spring框架的一些新特性问题机制,包含了一些特定注解方面的认识。@Lazy可以延迟依赖注入@Lazy注解修饰在类层面!@Lazy@Servicepublic class UserService extends BaseService { }可以把@Lazy放在@Autowired之上,即依赖注入也是延迟的;当我们调用userService时才会注入。即延https://xie.infoq.cn/article/84322a29088d7b1e78866d5b6
Kafka 生产环境部署指南https://xie.infoq.cn/article/d57f83779490c7ff62b6b59ae
时间轮
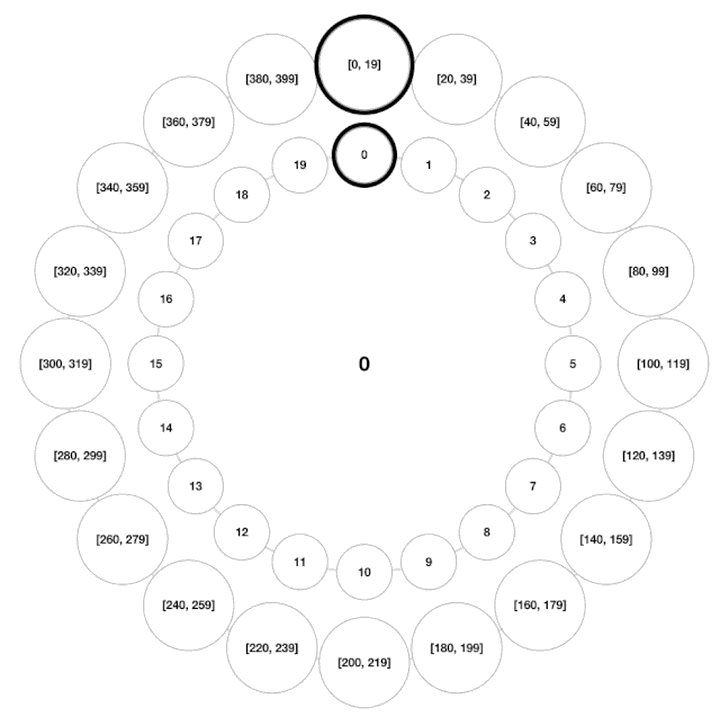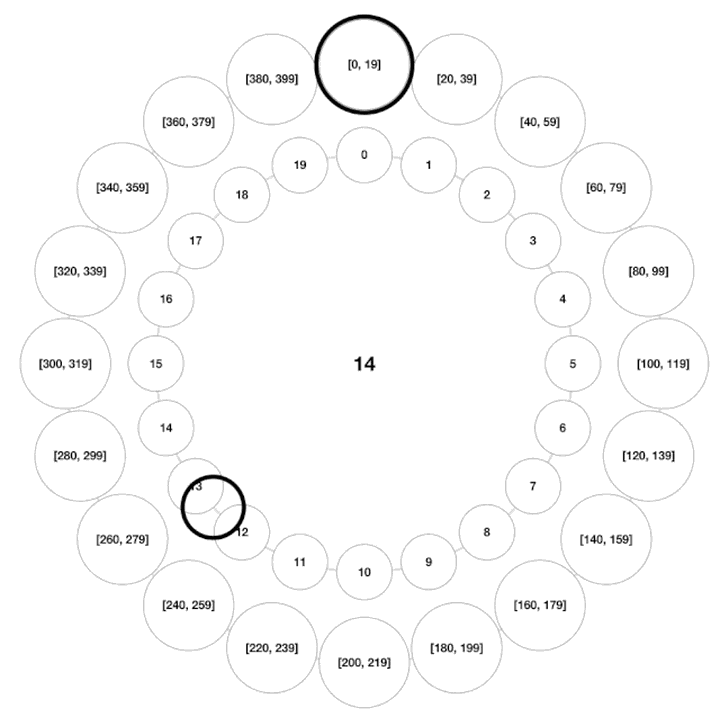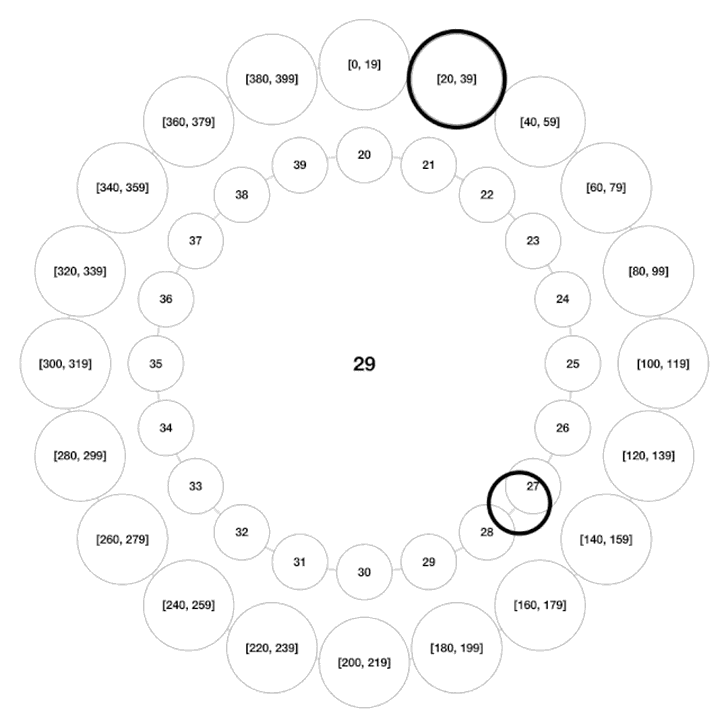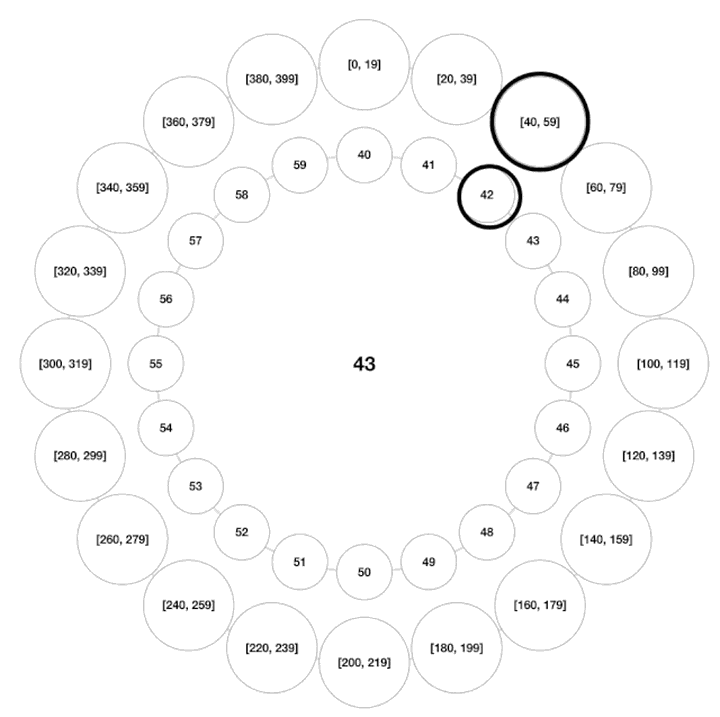
一张图理解Kafka时间轮(TimingWheel),看不懂算我输! - 知乎本文是【字节可视化系列】Kafka专栏文章。 通过本文你将了解到时间轮算法思想,层级时间轮,时间轮的升级和降级。 时间轮,是一种实现延迟功能(定时器)的巧妙算法,在Netty,Zookeeper,Kafka等各种框架中,甚至… https://zhuanlan.zhihu.com/p/121483218
https://zhuanlan.zhihu.com/p/121483218
java 核心线程大小与线程池最大大小的区别
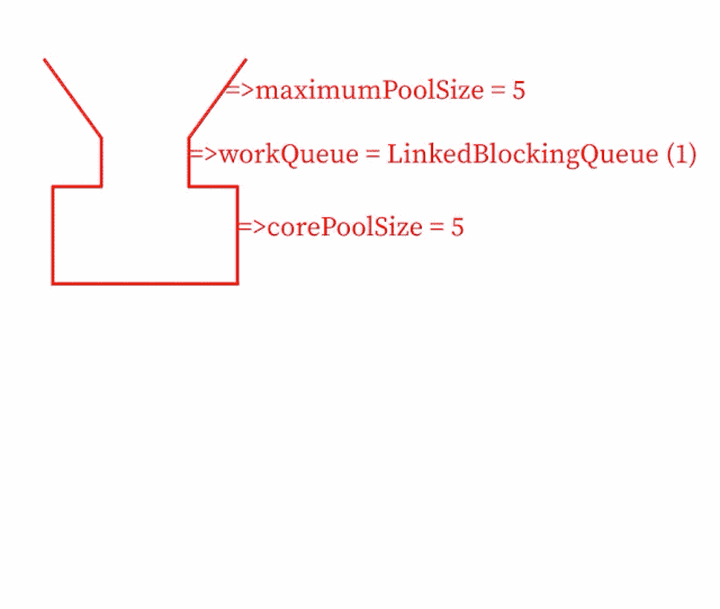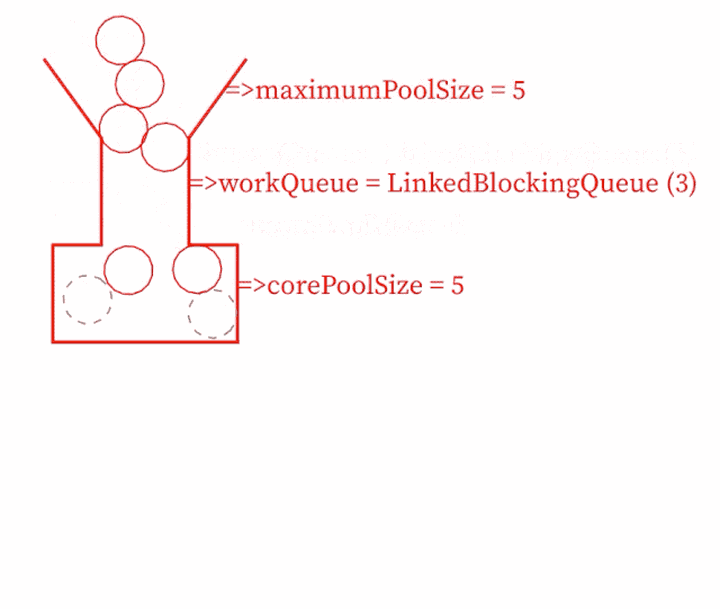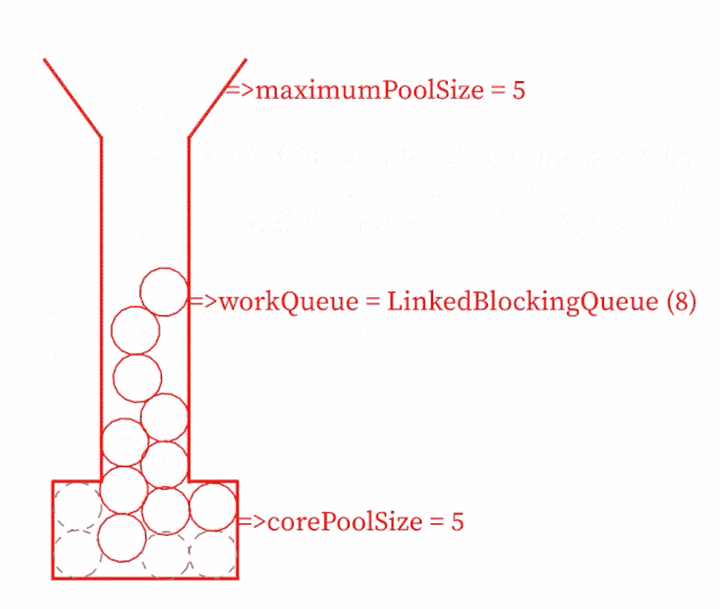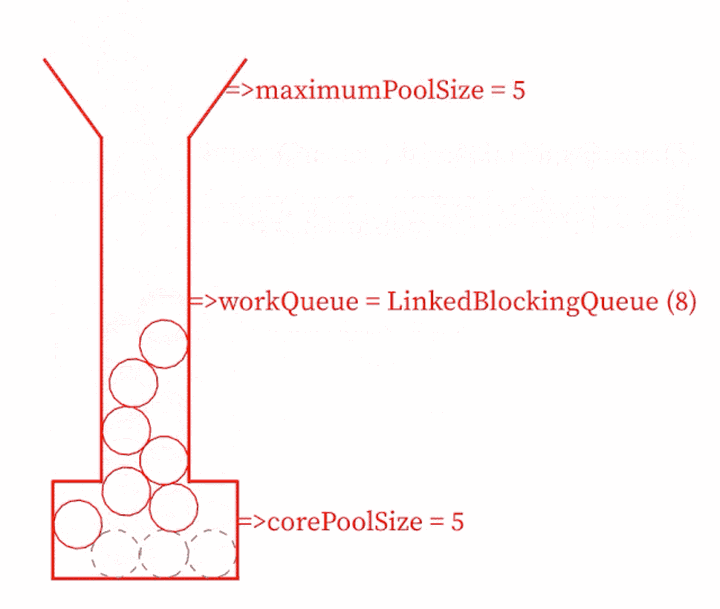
1、当提交一个新任务到线程池时首先线程池判断基本线程池(corePoolSize)是否已满?没满,创建一个工作线程来执行任务。满了,则进入下个流程;其次线程池判断工作队列(workQueue)是否已满?没满,则将新提交的任务存储在工作队列里。满了,则进入下个流程;最后线程池判断整个线程池(maximumPoolSize)是否已满?没满,则创建一个新的工作线程来执行任务,满了,则交给饱和策略来处理这个任务;如果线程池中的线程数量大于 corePoolSize 时,如果某线程空闲时间超过keepAliveTime,线程将被终止,直至线程池中的线程数目不大于corePoolSize;如果允许为核心池中的线程设置存活时间,那么核心池中的线程空闲时间超过 keepAliveTime,线程也会被终止。
核心线程池的线程在idle的时候不会被终止,其他的线程会终止
2、饱和策略:
Abort策略:默认策略,新任务提交时直接抛出未检查的异常RejectedExecutionException,该异常可由调用者捕获。
CallerRuns策略:为调节机制,既不抛弃任务也不抛出异常,而是将某些任务回退到调用者。不会在线程池的线程中执行新的任务,而是在调用exector的线程中运行新的任务。
Discard策略:新提交的任务被抛弃。
DIscardOld策略:和最老的线程尝试竞争,竞争不过就被抛弃。
Java线程池的核心线程数和最大线程数总是容易混淆怎么办 - 知乎Java的线程池就像是一个花瓶容器。 而把任务提交给线程池就像是把小球塞进花瓶。 整个过程就像下面这个有趣的动画: 下面我们先来了解一下Java线程池的参数。 希望看完这篇文章后, 再提起线程池的时候, 你脑海首先…https://zhuanlan.zhihu.com/p/112527671
20211015
探究Presto SQL引擎(1)-巧用Antlr文本介绍了antlr的基本用法以及如何使用antlr4实现解析SQL查询CSV数据,更加深入理解Presto查询引擎支持的SQL语法以及实现思路。 https://mp.weixin.qq.com/s/oYsCmTg4OVlIuB9a8Eu1Vw
https://mp.weixin.qq.com/s/oYsCmTg4OVlIuB9a8Eu1Vw
支持完整的SQL语法是一个庞大的工程。在presto中有完整的SqlBase.g4文件,定义了presto支持的所有SQL语法,涵盖了DDL语法和DML语法。该文件体系较为庞大,并不适合学习探究某个具体的细节点。
为了探究SQL解析的过程,理解SQL执行背后的逻辑,在简单地阅读相关资料文档的基础上,我选择自己动手编码实验。为此,定义一个小目标:实现一个SQL解析器。用该解析器实现select field from table语法,从本地的csv数据源中查询指定的字段。
20211014
独一无二的「MySQL调优金字塔」相信也许你拥有了它,你就很可能拥有了全世界。开发俏皮话【让我996不算啥,我只怕测试也996给我提bug!】笔者瞩望你好,无论我们在现实生活中是否相识,在InfoQ的世界里终会快乐相遇,在此提前预祝国庆节快乐,并且在属于我们的“1024”那天不在加班,早点回家陪陪老婆和孩子啊。技术金字塔本篇文章会按照自上而下以及自下而上的两种方向去“游览”【MySQL技术金字塔】,两个方向分别是从成本出发的(潜台词就是便宜越好,照顾公司成本哦!),本章内容https://xie.infoq.cn/article/5e1aec4933a497f773d5406e6


Apache ftpserver 相关特性
-
100%纯 Java,免费的开源可恢复 FTP 服务器。
-
多平台支持和多线程设计。
-
用户虚拟目录,写入权限,空闲超时和上载/下载带宽限制支持。
-
匿名登录支持。
-
上传和下载文件都是可恢复的。
-
处理 ASCII 和二进制数据传输。
-
支持 IP 限制以禁止 IP。
-
数据库和文件可用于存储用户数据。
-
所有 FTP 消息都是可定制的。
-
隐式/显式 SSL / TLS 支持。
-
MDTM 支持-您的用户可以更改文件的日期时间戳。
-
“模式 Z”支持更快地上传/下载数据。
-
可以轻松添加自定义用户管理器,IP 限制器,记录器。
-
可以添加用户事件通知(Ftplet)。
【SpringBoot技术专题】「FtpServer文件服务」教你如何基于Springboot开发一个”可移植“的轻量级文件服务项目系统!可移植且纯Java开发的FTP服务器引擎之【Apache FtpServer】Apache ftpserver相关简介Apache FtpServer是100%纯Java FTP服务器。它被设计为基于当前可用的开放协议的完整且可移植的FTP服务器引擎解决方案。FtpServer可以作为Windows服务或Unix / Linux守护程序独立运行,也可以嵌入Java应用程序中。还提供对Spring应https://xie.infoq.cn/article/42b4d9e59f2741a5e1ebe3725
评:Streaming System(简直炸裂,强势安利) - 知乎(最近会在这个专栏: 用谁都能看懂的方法解释分布式系统,更新一些关于流式系统的论文,比如Flink的Global Snapshot, 敬请期待)( 预警:本文中英夹杂:作者想到一个概念想要表达的时候,想到的是英文就用英文想到…https://zhuanlan.zhihu.com/p/43301661
新的时代和它给的解
大数据处理这个领域本身,正在发生着一些革命性的变化。。。
首先, 当数据库开始变的像message queue,很多数据库比如DyanamoDB,开始提供Change Data Capture把对表的更改变成Data Stream供别的系统使用;另一方方面,message queue开始变的像一个可以持久化数据的数据库,当我们也有了可以从任意点replay的可以长期存储的Stream(kafka),Database和Message queue的概念开始变的模糊。Kafka的出现,直接解决了replayable的数据框架的问题。但它的意义不仅如此。
多数据存储之间的consistency的问题,本质上与分布式数据库的replication问题一致,而分布式数据库的replica可以通过total order broadcast,来广播主节点的WriteAheadLog或者changelog到replica节点,由于total order broadcast保证了所有replica节点收到的message是绝对相同的顺序,那么只要replica节点按照受到message的顺序作出对数据相同的更改,我们就实现了分布式数据库对数据的replication,而WriteAheadLog或changelog本质就是data stream;如果我们把数据库的total order broadcast的这项技术应用到分布式业务系统的设计中去,那么我们就可以解决分布式系统中最难点一个问题:消息时序,而kafka可以说为分布式数据(change)提供了一个logic clock和total order,任何数据生产者只需要把数据输入Kafka,任何Kafka的consumer都保证会以相同的顺序接收同一个partition上的message,同时利用Kafka的replayable特性,数据可以写一次,而重新以任意形式apply在其他存储形式上(cache, elastic search, datawarehouse, keyvalue DB等)。这样,我们就解决了多存储的一致性问题。
更进一步,如果我们在replay message的时候,不是简单的原原本本的照抄replica,而是加入业务逻辑处理,把任何业务逻辑的执行,都看成是从raw data得到的derived data问题,那么把业务逻辑加入到流中,我们就得到了一个经过变化的流,如果我们把这个流写入到一个表里,而这个表又可以产生流(通过类似Change Data Capture这种技术,比如AWS DynamoDB Stream), 而我们又有多个业务processor接收这个新流,经过处理,写入Kafka这种流系统,或者写入可以生成流的table…. 如此循环,我们就得到了一个以Kafka的message index为logical clock的全局eventually consistent的分布式流处理系统。
顺着这个思路,任意一个公司的数据处理系统的本质,都可以看成是一个超大的流处理网络。这个思路把一个分布式数据库维护consistency的各种手段,write ahead log,change log shipment,state replication,materialized view分解开来应用到分布式业务系统的设计里,这就是名为Turn Database Inside Out,Database Unbundled的设计和构架大型分布式企业级应用体系的新思路。
从数据库中来,到数据库中去,从数据流来到数据库中去,从对数据库的更改来,到流或数据库中去。当source,computation和sink全都在云上,我们的业务逻辑本质上就是数据库产生任何变化之后trigger的逻辑,而这就是Streaming processor as a database的思路。
当我们有了replayable的source,自动failover的计算节点(由K8S这种保活), 当我们需要写入的sink也已和我们的整个流框架整合,而使用者只需要提供数据处理逻辑的时候,framework就可以通过插入logical id作为fencing token来最终实现sink的commit的幂等(特别是当所有资源都serverless化由云服务商提供),这就最终使得点到点的exactly once处理成为可能,克服了end2end argument对于中间件的限制(具体限制看这个答案,阿莱克西斯:为什么Akka(Actor模型)在中国不温不火?),因为现在framework不再是中间件了,而是从end2end都由framework本身全权控制,用户的程序只是插入到数据流的计算节点中的一步而已;这个发展,解决了分布式框架usability的本质问题, 而这也从本质上消灭了Lambda Architecture要解决的问题(即用不准确的Streaming提供更早的estimation,而利用稳定consistent的batch处理来fix streaming的不准确问题),因为我们现在也可以用streaming来得到consistent的计算结果了!(其实没有解决,只是我们发现batch和stream本质是一样的,而stream可以做到跟batch至少一样好,这样我们就没必要维护两套系统实现了。Latency和Consistency的trade-off,本质上是liveness和safety的trade-off,FLP impossibility决定了再share nothing的异步环境,safety和liveness不可能同时保证。)
Streaming处理系统其实是batch处理系统的超集,即batch只是固定process/event time window下,利用atWaterMark trigger的数据处理模型而已。所以基本上你可以用这套理论体系来分析目前的几乎”任何分布式数据处理系统“。去思考他们的能力和在各个关键节点所做出的trade-off
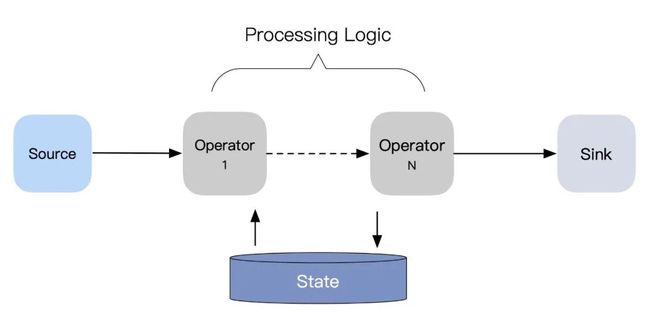
本文从流计算的本质出发,推导出了在流处理中实现端到端一致性的通用解法,同时结合通用解法,分析了目前几种主流流计算引擎在一致性上的实现思路。有「财大气粗」型的 Google MillWheel,背靠强大的基础架构用于状态管理;有「心灵手巧」型的 Apache Flink,巧妙地结合了分布式一致性快照和两阶段事务实现一致性;也有「重剑无锋」型的 Apache Kafka Streams,直接将流处理过程事务化,屏蔽复杂的底层逻辑,编程模型和理解成本都更简单(当然也一定程度上限制其使用的场景);也有 「蓬勃发展」中的 Apache Spark (Structured)Streaming,底层的一些实现构想和 Apache Flink 愈加趋同,可以期待它将来能达到类似 Apache Spark 在批处理流域中的地位。
流计算的输入数据是没有边界的,这符合我们传统上对流计算认知。在《System Streaming》一书中,作者提出了一个将流批统一考虑的流计算理论抽象,即,任意的数据的处理都是「流(Stream)」 和「表(Table)」间的互相转换,其中流用来表征运动中的数据,表用来表征静止的数据:
-
流 -> 流:没有聚合操作的数据处理过程;
-
流 -> 表:存在聚合操作的数据处理过程;
-
表 -> 流:触发输出表数据变化的情况;
-
表 -> 表:不存在这样的数据处理逻辑。
流计算引擎数据一致性的本质本篇文章从流计算的本质出发,重点分析流计算领域中数据处理的一致性问题,同时对一致性问题进行简单的形式化定义,提供一个一窥当下流计算引擎发展脉络的视角,让大家对流计算引擎的认识更为深入,为可能的流计算技术选型提供一些参考。https://mp.weixin.qq.com/s/DSf4By9c7Bblmfbbef32PA
20211013
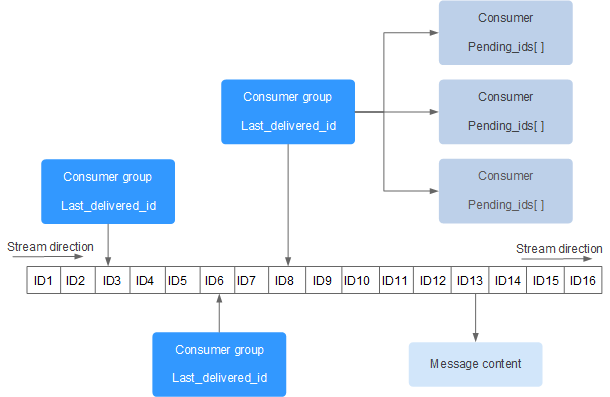
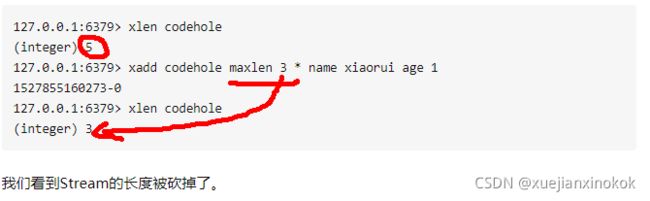
要是消息积累太多,Stream的链表岂不是很长,内容会不会爆掉就是个问题了。xdel指令又不会删除消息,它只是给消息做了个标志位。
Redis自然考虑到了这一点,所以它提供了一个定长Stream功能。在xadd的指令提供一个定长长度maxlen,就可以将老的消息干掉,确保最多不超过指定长度。
//PEL如何避免消息丢失
在客户端消费者读取Stream消息时,Redis服务器将消息回复给客户端的过程中,客户端突然断开了连接,消息就丢失了。
但是PEL里已经保存了发出去的消息ID。待客户端重新连上之后,可以再次收到PEL中的消息ID列表。不过此时xreadgroup的起始消息ID 不能为参数 >,而必须是任意有效的消息ID,一般将参数设为0-0,表示读取所有的PEL消息以及自last_delivered_id之后的新消息。
如何看待Redis5.0的新特性stream? - 知乎感觉没有kafka好用。redis的原来的消息队列感觉用的人就少,是否有必要用steam再把redis搞的大而不精。相…https://www.zhihu.com/question/279540635
grpc
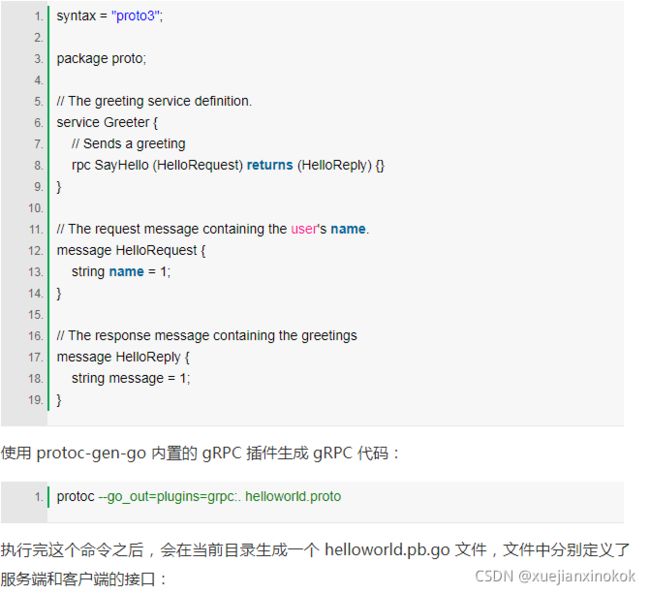
gRPC 这项技术真是太棒了,爆赞 - 51CTO.COMhttps://developer.51cto.com/art/202110/685433.htm
20211012
为什么要限流
日常生活中,有哪些需要限流的地方?
为什么要限流呢?假如景区能容纳一万人,现在进去了三万人,势必摩肩接踵,整不好还会有事故发生,这样的结果就是所有人的体验都不好,如果发生了事故景区可能还要关闭,导致对外不可用,这样的后果就是所有人都觉得体验糟糕透了。
回到网络上,同样也是这个道理,例如某某明星公布了恋情,访问从平时的50万增加到了500万,系统最多可以支撑200万访问,那么就要执行限流规则,保证是一个可用的状态,不至于服务器崩溃导致所有请求不可用。
如果这时候有特殊情况,比如有些赶时间的志愿者啦、或者高三要高考啦,这种情况就是突发情况,如果也用漏桶算法那也得慢慢排队,这也就没有解决我们的需求,对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。
令牌桶好处就是,如果某一瞬间访问量剧增或者有突发情况,可以通过改变桶中令牌数量来改变连接数,就好比那个食堂排队吃饭的问题,如果现在不是直接去窗口排队,而是先来楼外拿饭票然后再去排队,那么有高三的学生时可以将增加饭票数量或者优先将令牌给高三的学生,这样比漏桶算法更加灵活。
限流思路
对系统服务进行限流,一般有如下几个模式:
熔断
系统在设计之初就把熔断措施考虑进去。当系统出现问题时,如果短时间内无法修复,系统要自动做出判断,开启熔断开关,拒绝流量访问,避免大流量对后端的过载请求。
系统也应该能够动态监测后端程序的修复情况,当程序已恢复稳定时,可以关闭熔断开关,恢复正常服务。常见的熔断组件有Hystrix以及阿里的Sentinel,两种互有优缺点,可以根据业务的实际情况进行选择。
服务降级
将系统的所有功能服务进行一个分级,当系统出现问题需要紧急限流时,可将不是那么重要的功能进行降级处理,停止服务,这样可以释放出更多的资源供给核心功能的去用。
例如在电商平台中,如果突发流量激增,可临时将商品评论、积分等非核心功能进行降级,停止这些服务,释放出机器和CPU等资源来保障用户正常下单,而这些降级的功能服务可以等整个系统恢复正常后,再来启动,进行补单/补偿处理。除了功能降级以外,还可以采用不直接操作数据库,而全部读缓存、写缓存的方式作为临时降级方案。
延迟处理
这个模式需要在系统的前端设置一个流量缓冲池,将所有的请求全部缓冲进这个池子,不立即处理。然后后端真正的业务处理程序从这个池子中取出请求依次处理,常见的可以用队列模式来实现。这就相当于用异步的方式去减少了后端的处理压力,但是当流量较大时,后端的处理能力有限,缓冲池里的请求可能处理不及时,会有一定程度延迟。后面具体的漏桶算法以及令牌桶算法就是这个思路。
特权处理
这个模式需要将用户进行分类,通过预设的分类,让系统优先处理需要高保障的用户群体,其它用户群的请求就会延迟处理或者直接不处理。
缓存、降级、限流区别
- 缓存是用来增加系统吞吐量,提升访问速度提供高并发。
- 降级是在系统某些服务组件不可用的时候、流量暴增、资源耗尽等情况下,暂时屏蔽掉出问题的服务,继续提供降级服务,给用户尽可能的友好提示,返回兜底数据,不会影响整体业务流程,待问题解决再重新上线服务
- 限流是指在使用缓存和降级无效的场景。比如当达到阈值后限制接口调用频率,访问次数,库存个数等,在出现服务不可用之前,提前把服务降级。只服务好一部分用户。
亿级流量架构的服务限流思路与方法 - 51CTO.COM限流算法很多,常见的有三类,分别是计数器算法、漏桶算法、令牌桶算法,下面逐一讲解。https://news.51cto.com/art/202110/685344.htm
三极管,它就是一种晶体管,特性是从一端通电,另外两端的电流就可以通过,不通电,另外两端的电流就不能通过。

这特性不就是一个开关么?
它和下面这个东西差不多,只不过不需要手动开关,而是通过通电来控制开关。

开和关,就是 1 和 0。计算机世界的组成单元 1 和 0 就是这么实现的。
你觉得用不上的位运算里,隐藏着 CPU 实现的秘密 - 51CTO.COM我们学 JS 的时候都会了解下位运算,在 React、Typescript 等源码中也频繁见到位运算的踪影,但在业务代码中从来不会这么写,它好像离我们很遥远。https://biz.51cto.com/art/202110/685243.htm
为什么 Go 语言把类型放在后面?
Go 官方核心思想是:这种声明方式(从左到右的风格)的一个优点是,当类型变得更加复杂时,它的效果非常好(One merit of this left-to-right style is how well it works as the types become more complex)。
Go 的变量名总是在前,在人的代码阅读上可以保持从左到右阅读,不需要像 C 语言一样在一大堆声明中用技巧找变量名对应的类型。
比如以下两个例子:
c语言
int (*(*fp) ( int (*)(int, int), int) ) (int, int)
fp 是个函数指针,该函数指针
第一参数为 int (*)(int, int), 是一个返回int 且有2个int 参数的函数指针
第二个参数为 int
返回值是 一个函数指针 int (*) (int,int)
go语言
fp func(func(int,int) int, int) func(int, int) int
fp是一个函数,该函数参数有两个
第一个是 func(int,int) int 这是一个返回int 类型且参数为 int int 的函数
第二个参数是int
fp 返回值是一个函数 func(int, int) int
为什么 Go 语言把类型放在后面? - 51CTO.COMGo 的变量名总是在前,在人的代码阅读上可以保持从左到右阅读,不需要像 C 语言一样在一大堆声明中用技巧找变量名对应的类型。https://developer.51cto.com/art/202110/685145.htm
怎么快速正确的读取c语言的类型声明?
Clockwise/Spiral Rule http://c-faq.com/decl/spiral.anderson.html
http://c-faq.com/decl/spiral.anderson.html
20211011
0. 项目介绍-Redisson 使用手册-面试哥Redisson项目介绍Redisson项目介绍Redisson是架设在Redis基础上的一个Java驻内存数据网格(In-MemoryDataGrid)。充分的利用了Redis键值数据库提供的一系列优势,基于Java实http://www.mianshigee.com/tutorial/redisson-wiki-zh/redisson%E9%A1%B9%E7%9B%AE%E4%BB%8B%E7%BB%8D.md
Redis watch命令——监控事务在 Redis 中使用 watch 命令可以决定事务是执行还是回滚。一般而言,可以在 multi 命令之前使用 watch 命令监控某些键值对,然后使用 multi 命令开启事务,执行各类对数据结构进行操作的命http://c.biancheng.net/view/4544.htmlredis watch命令实现秒杀demo - 简书1.思路 在redis提供了incr命令进行递增操作,可以保证原子性。利用watch实现也可以实现递增递减的操作。WATCH命令可以监控一个或多个键,一旦其中有一个键被修改(...https://www.jianshu.com/p/93cd65d07b56
在 Spring 中要使用同一个连接操作 Redis 命令的场景,这个时候我们借助的是 Spring 提供的 SessionCallback 接口Redis的基础事务和常用操作和其他大部分的 NoSQL 不同,Redis 是存在事务的,尽管它没有数据库那么强大,但是它还是很有用的,尤其是在那些需要高并发的网站当中,使用 Redis 读/写数据要比数据库快得多,如果http://c.biancheng.net/view/4540.html
现实中 Redis 执行读/写速度十分快,而系统的瓶颈往往是在网络通信中的延时,为了解决这个问题,可以使用 Redis 的流水线,但是 Redis 的流水线是一种通信协议使用流水线(pipelined)提高Redis的命令性能
20210930
如何改写分页查询?
查询条件放到二级索引子查询中,在子查询列表中中只查询id 这是防止回表的关键
通过二级索引返回的id再和主表关联
select id,name,balance FROM account where id >= (select a.id from account a where a.update_time >= '2020-09-19' limit 100000, 1) LIMIT 10;
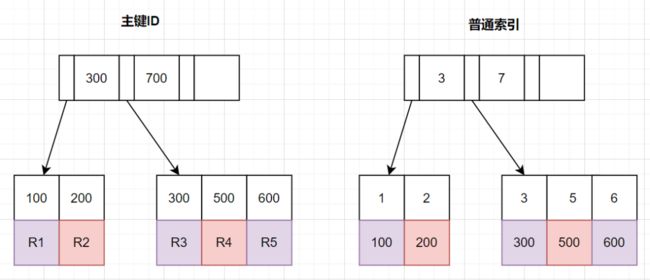
实战!聊聊如何解决MySQL深分页问题 - 文章详情前言我们日常做分页需求时,一般会用limit实现,但是当偏移量特别大的时候,查询效率就变得低下。本文将分四个方案,讨论如何优化MySQL百万数据的深分页问题,并附上最近优化生产慢SQL的实战案例。limit深分页为什么会变慢?先看下表结构哈:CREATETABLEaccount(idint(11)Nhttps://z.itpub.net/article/detail/7A8671242BC0BA4F0D53CC6D485C0EF9
Redis HyperLogLog 的应用场景
鉴于 HyperLogLog 不保存数据内容的特性,所以,它只适用于一些特定的场景。我这里给出一个最常遇到的场景需要:计算日活、7日活、月活数据。
分析:如果我们通过解析日志,把 ip 信息(或用户 id)放到集合中,例如:HashSet。如果数量不多则还好,但是假如每天访问的用户有几百万。无疑会占用大量的存储空间。且计算月活时,还需要将一个整月的数据放到一个 Set 中,这随时可能导致我们的程序 OOM。
Redis HyperLogLog - 知乎关于 Redis HyperLogLog 在说明 HyperLogLog 之前,我们需要先了解一个概念:基数统计。维基百科中的解释是:cardinality of a set is a measure of the “number of elements“ of the set 它的意思是:一个集合…https://zhuanlan.zhihu.com/p/58358264
20210923
Spring 声明式事务应该怎么学? - 文章详情1、引言Spring的声明式事务极大地方便了日常的事务相关代码编写,它的设计如此巧妙,以至于在使用中几乎感觉不到它的存在,只需要优雅地加一个@Transactional注解,一切就都顺理成章地完成了!毫不夸张地讲,Spring的声明式事务实在是太好用了,以至于大多https://z.itpub.net/article/detail/986FAFC148E47CD4878AE4AB25D90C27
这才是 Redis 分布式锁的正确实现方式https://mp.weixin.qq.com/s/cdmwI-H9NUHUQNvr_6DQgQ
20210917
redis 实现布隆过滤器
牛哄哄的布隆过滤器,有什么用? - 51CTO.COM日常开发中,大家经常使用缓存,但是你知道大型的互联网公司面对高并发流量,要注意缓存穿透问题吗?https://developer.51cto.com/art/202109/680514.htm
一个简单的 JS 库,用来使用脚本进行网页绘图。它基于 Canvas,可以绘制文字、矩形、圆形、图片、HTML 片段和 SVG 文件iDraw Playgroundhttps://idraw.js.org/playground/?demo=elem-html

利用redis zset 来实现超时
面试官:说出订单超时取消订单的5种实现方案!生成订单30分钟未支付,则自动取消,该怎么实现?https://mp.weixin.qq.com/s/0EUytOr7J-UmSbyQ2SbZQA
20210916
Redis 到底是怎么实现“附近的人”这个功能的呢? http://mp.weixin.qq.com/s?__biz=MzAxODcyNjEzNQ==&mid=2247538725&idx=2&sn=804e5f12e184ee8a92b244b15daf2adf&chksm=9bd3f5bdaca47cab326dbb99581810becd604640802ccd340a1e0cc8c6f37d9135a38add398b&mpshare=1&scene=24&srcid=0804Qtmq2rZgFhw4cKFArYHo&sharer_sharetime=1628053638855&sharer_shareid=3e190772201d8c1259d3e5ee138cea6e#rd 16个Redis常见使用场景总结http://mp.weixin.qq.com/s?__biz=MzI4Njc5NjM1NQ==&mid=2247510130&idx=2&sn=a88ce0b70f28acb6bf2a29d6b5fe2065&chksm=ebd5975edca21e486ec50959ba8aca07eecabf5550ecb67a5e678c306e2bf1df42d1184329a8&mpshare=1&scene=24&srcid=07270fTZkf7k7OkNIgx7K9s9&sharer_sharetime=1627385272392&sharer_shareid=3e190772201d8c1259d3e5ee138cea6e#rd
http://mp.weixin.qq.com/s?__biz=MzAxODcyNjEzNQ==&mid=2247538725&idx=2&sn=804e5f12e184ee8a92b244b15daf2adf&chksm=9bd3f5bdaca47cab326dbb99581810becd604640802ccd340a1e0cc8c6f37d9135a38add398b&mpshare=1&scene=24&srcid=0804Qtmq2rZgFhw4cKFArYHo&sharer_sharetime=1628053638855&sharer_shareid=3e190772201d8c1259d3e5ee138cea6e#rd 16个Redis常见使用场景总结http://mp.weixin.qq.com/s?__biz=MzI4Njc5NjM1NQ==&mid=2247510130&idx=2&sn=a88ce0b70f28acb6bf2a29d6b5fe2065&chksm=ebd5975edca21e486ec50959ba8aca07eecabf5550ecb67a5e678c306e2bf1df42d1184329a8&mpshare=1&scene=24&srcid=07270fTZkf7k7OkNIgx7K9s9&sharer_sharetime=1627385272392&sharer_shareid=3e190772201d8c1259d3e5ee138cea6e#rd
Spring Boot 监听 Redis Key 失效事件实现定时任务http://mp.weixin.qq.com/s?__biz=MzAxODcyNjEzNQ==&mid=2247505528&idx=2&sn=e91166a340b15976ef128e84b4baa4de&chksm=9bd37be0aca4f2f6114c1a37a7f6a24fadb5bb779365d655b46fb0ff12e1a63be469491ed2cb&mpshare=1&scene=24&srcid=1023f79bTq50QtANw2WJ0EzE&sharer_sharetime=1603426585487&sharer_shareid=3e190772201d8c1259d3e5ee138cea6e#rd 要想用活Redis,Lua脚本是绕不过去的坎 !【附源码】_Java_程_序_员_51CTO博客要想用活Redis,Lua脚本是绕不过去的坎 !【附源码】,Redis当中提供了许多重要的高级特性,比如发布与订阅,Lua脚本等。Redis当中也提供了自增的原子命令,但是假如我们需要同时执行好几个命令的同时又想让这些命令保持原子性,该怎么办呢?这时候就可以使用本文介绍的Lua脚本来实现。https://blog.51cto.com/u_15360778/3905326
分布式事务 Seata Saga 模式首秀以及三种模式详解 | Meetup#3 回顾 · SOFAStackSOFAStack is a Scalable Open Financial Architecture for building cloud native applications https://www.sofastack.tech/blog/sofa-meetup-3-seata-retrospect/
https://www.sofastack.tech/blog/sofa-meetup-3-seata-retrospect/
SOFAChannel#10:分布式事务 Seata 长事务解决方案 Saga 模式详解蚂蚁金服金融科技 - 活动蚂蚁金融科技 数字金融新原力 https://tech.antfin.com/community/live/1076
https://tech.antfin.com/community/live/1076
20210914
Hazelcast集群服务(1)——Hazelcast介绍 - 云+社区 - 腾讯云 “分布式”、“集群服务”、“网格式内存数据”、“分布式缓存“、“弹性可伸缩服务”——这些牛逼闪闪的名词拿到哪都是ITer装逼的不二之选。在Javaer的...https://cloud.tencent.com/developer/article/1185863 hazelcast是 一个类似redis的内存数据库
Minio的使用_Jarvis's Blog-CSDN博客_minio初识MinioMinio官方文档地址:https://min.io/最近公司做了一个分布式项目,文档存储这块儿,选型没选 FasDFS ,而选了Minio。自己下来查找了一些资料对比了一下:1.安装部署(运维)复杂度我记得以前用FastDFS的时候,我自己下去试着去部署了一下,特别复杂,什么 Tracker和Storage的关系,主从,完了当时还部署失败了Minio官方文档提供出来了部署方式:Windows:Linux:(其他请参考官方文档…)2.就是Minio有官方文档,FastDFShttps://blog.csdn.net/weixin_43582499/article/details/113315387 文档存储
TypeItThe most versatile JavaScript typewriter effect library on the planet.https://typeitjs.com/打字效果的js 类库