软件测试之Python基础学习
目录
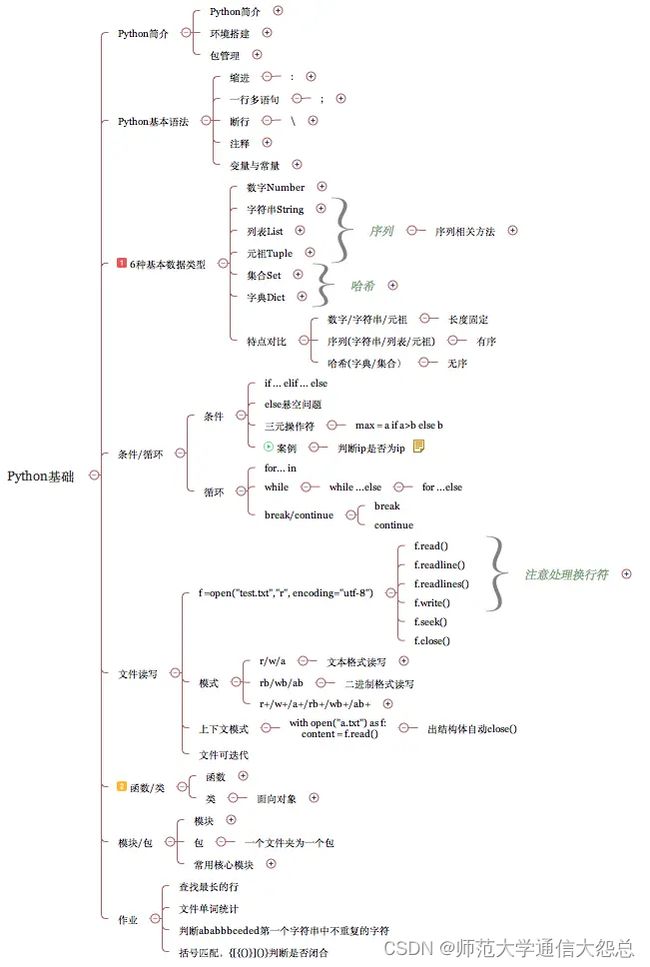
一、Python基础
Python简介、环境搭建及包管理
Python简介
环境搭建
包管理
Python基本语法
缩进(Python有非常严格的要求)
一行多条语句
断行
注释
变量
基本数据类型(6种)
1. 数字Number
2. 字符串String
3. 列表List
4. 元组Tuple
序列相关操作方法
5. 集合Set
6. 字典Dict
条件/循环
条件判断
循环
文件读写(文本文件)
文件操作方法
文件打开模式
函数/类
函数定义和调用
参数和返回值
函数作为参数(如: 装饰器)
函数嵌套(支持闭包)
函数递归(自己调用自己,直到满足需求)
模块/包
模块
包
常用系统模块
常见算法
冒泡排序
快速排序
二分查找
结语:
视图网站推荐
1、Data Structure Visualizations
2、visualgo
3、BinaryTreeVisualiser
4、btree-js
5、Algorithm Visualizer
6、bigocheatsheet
7、Algorithms-DataStructures-BigONotation
8、Vamonos
一、Python基础
大致路线:
Python简介、环境搭建及包管理
Python简介
- 特点:Python是一门动态、解释型、强类型语言
- 动态:在运行期间才做数据检查(不用提前声明变量)- 静态语音(C/Java):编译时检查数据类型(编码时需要声明变量类型)
- 解释型:在执行程序时,才一条条解释成机器语言给计算机执行(无需编译,速度较慢)- 编译型语言(C/Java):先要将代码编译成二进制可执行文件,再执行
- 强类型:类型安全,变量一旦被指定了数据类型,如果不强制转换,那么永远是这种类型(严谨,避免类型错误,速度较慢)- 弱类型(VBScript/JavaScript): 类型在运行期间会转化,如 js中的 1+"2"="12", 1会由数字转化为string
- 编码原则:优雅、明确、简单
- 优点
- 简单易学
- 开发效率高
- 高级语言
- 可移植、可扩展、可嵌入
- 庞大的三方库
- 缺点
- 速度慢
- 代码不能加密
- 多线程不能充分利用多核cpu(GIL全局解释性锁,同一时刻只能运行一个线程)
- 应用领域
- 自动化测试(UI/接口)
- 自动化运维
- 爬虫
- Web开发(Django/Flask/..)
- 图形GUI开发
- 游戏脚本
- 金融、量化交易
- 数据分析,大数据
- 人工智能、机器学习、NLP、计算机视觉
- 云计算
环境搭建
Windows Python3环境搭建
- 下载Python3.*.exe安装包
- 双击安装,第一个节目选中Add Python3.*.* to PATH,点击Install Now(默认安装pip),一路下一步
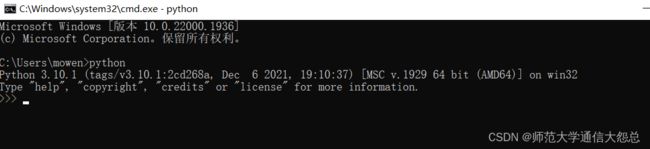
- 验证:打开cmd命令行,输入python,应能进入python shell 并显示为Python 3.*.*版本
包管理
- pip安装
- pip install 包名 - 卸载: pip uninstall 包名
- pip install 下载的whl包.whl
- pip install -r requiements.txt(安装requirements.txt中的所有依赖包)
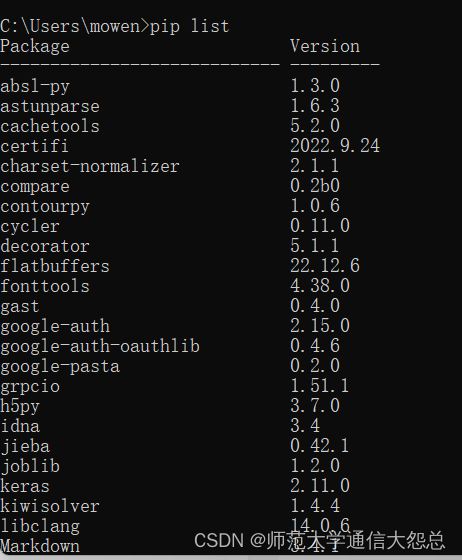
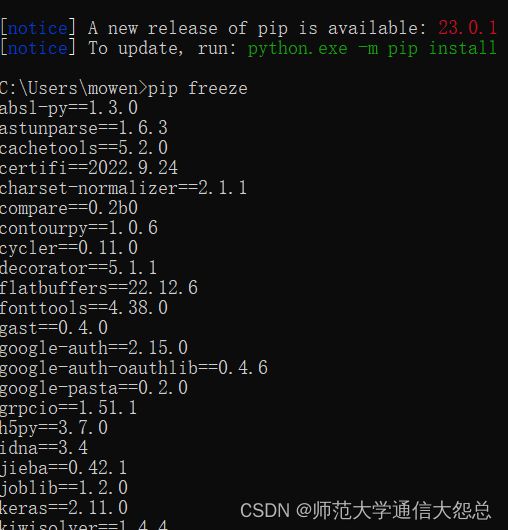
- 查看已安装的三方包,pip freeze 已文件格式显示已安装的三方包(用于导出requiremnts.txt文件)
- 源码安装
- 下载源码包,解压,进入解压目录
- 打开命令行,执行
python setup.py install - 验证:进入python shell,输入import 包名,不报错表示安装成功
- 三方包默认安装路径:Python3.*.*/Lib/site-packages/ 下
说明:网上有非常多的安装教程大家自由选择,这个不像FPGA和Qt那样难安装(个人觉得)
Python基本语法
-
缩进(Python有非常严格的要求)
x=int(input("请输入一个数\n"))
y=int(input("请输入一个数\n"))
if x > 0:
print("正数")
elif x == 0:
print("0")
else:
print("负数")
def add(x,y):
return x+y
-
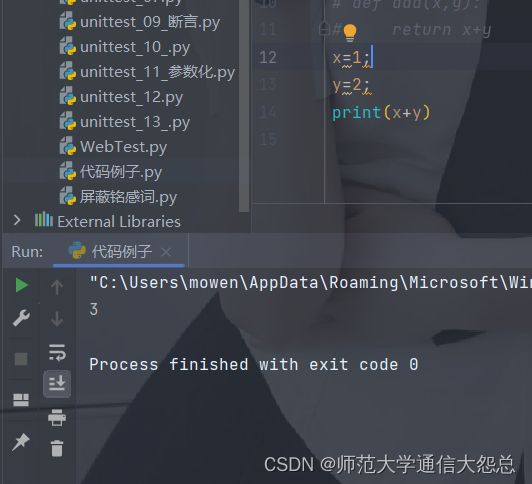
一行多条语句
x=1; y=2; print(x+y)
-
断行
print("this line is too long, \
so I break it to two lines")
-
注释
# 单行注释
a = 1
'''这是一段
多行注释'''
def add(x, y):
"""加法函数:这是docstring(函数说明)"""
pass
-
变量
- 变量类型(局部变量、全局变量、系统变量)
- 变量赋值
- 多重赋值
x=y=z=1 - 多元赋值
x,y = y,x
- 多重赋值
- 变量自增
x+=1x-=1(不支持x++,x--)
Python3中没有常量
基本数据类型(6种)
1. 数字Number
- 种类
- 整型int(Python3中没有长整型,int长度几乎没有限制)
- 浮点型float
- 布尔型bool
- False: 0,0.0,'',[],(),{}
- True: 除False以外,['']或[[],[]]不是False
- 复数型complex
- 操作符: +,-,*,/,//(地板除),**(乘方) - Python3中的/是真实除,1/2=0.5
- 类型转
- str(): 其他类型转为字符串, 如
str(12) - int(): 字符串数字转为整型(字符串不是纯整数会报错), 如
int("12") - float(): 字符串转换为浮点数,如
float("1.23")
- str(): 其他类型转为字符串, 如
2. 字符串String
- 字符串系统方法
- len(): 计算字符串长度,如
len("abcdefg") - find()/index(): 查找字符串中某个字符第一次出现的索引(index()方法查找不到会报错), 如
"abcdefg".find("b"); "abcedfgg".index("g") - lower()/upper(): 将字符串转换为全小写/大写,如
"AbcdeF".lower();"abcedF".upper() - isdigit()/isalpha()/isalnum(): 判断字符串是否纯数字/纯字母/纯数字字母组合, 如
isdigit("123"),结果为 True - count(): 查询字符串中某个元素的数量,如
"aabcabc".count("a") - join(): 将列表元素按字符串连接,如
"".join(["a","b","c"])会按空字符连接列表元素,得到"abc" - replace(): 替换字符串中的某已部分,如
"hello,java".replace("java", "python"),将java 替换为 python - split(): 和join相反,将字符串按分隔符分割成列表, 如
"a,b,c,d".split(",")得到["a", "b", "c", "d"] - strip()/lstrip()/rstrip(): 去掉字符串左右/左边/右边的无意字符(包括空格,换行等非显示字符),如
" this has blanks \n".strip()得到"this has balnks"
- len(): 计算字符串长度,如
- 字符串格式化
- %: 如
"Name: %s, Age: %d" % ("Lily", 12)或"Name: %(name)s, Age: %(age)d" % {"name": "Lily", "age": 12} - format: 如
"Name: {}, Age: {}".format("Lily", 12)或"Name: {name}, Age: {age}".format(name="Lily",age=12) - substitude(不完全替换会报错)/safe_substitude: 如
"Name: ${name}, Age: ${age}".safe_substitude(name="Lily",age=12)
- %: 如
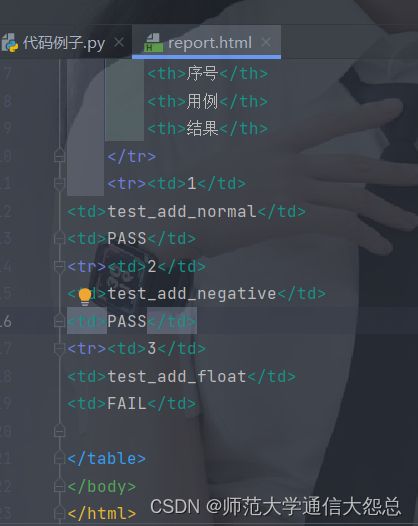
- 案例: 利用format生成自定义html报告
tpl='''
{title}
{title}
序号
用例
结果
{trs}
'''
tr='''{sn}
{case_name}
{result}
'''
title="自动化测试报告"
case_results = [("1", "test_add_normal", "PASS"),("2", "test_add_negative", "PASS"), ("3", "test_add_float", "FAIL")]
trs=''
for case_result in case_results:
tr_format = tr.format(sn=case_result[0], case_name=case_result[1], result=case_result[2])
trs += tr_format
html = tpl.format(title=title, trs=trs)
f = open("report.html", "w")
f.write(html)
f.close()
运行这个*.html文件:
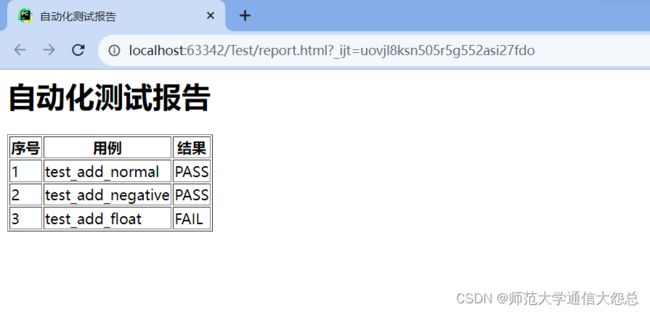
运行就可以在网页看到结果:
3. 列表List
列表元素支持各种对象的混合,支持嵌套各种对象,如["a", 1, {"b": 3}, [1,2,3]]
- 列表操作
- 赋值:
l = [1, "hello", ("a", "b")]
- 获取:
a = l[0] # 通过索引获取
- 增:
l.append("c");l.extend(["d","e"]);l+["f"]
- 删:
l.pop() # 按索引删除,无参数默认删除最后一个;l.remove("c") # 按元素删除
- 改:
l[1]="HELLO" # 通过索引修改
- 查: 遍历
for i in l: print(i)
- 列表系统方法
- append()/insert()/extend(): 添加/插入/扩展(连接)
- index(): 获取元素索引
- count(): 统计元素个数
- pop()/remove(): 按索引/元素删除
- sort()/reverse(): 排序/反转
- 案例: 字符串反转
s="abcdefg"; r=''.join(reversed(a))
4. 元组Tuple
- 不可改变,常用作函数参数(安全性好)
- 同样支持混合元素以及嵌套
- 只有一个元素时,必须加","号,如
a=("hello",) - 因为Python中()还有分组的含义,不加","会识别为字符串
字符串/列表/元组统称为序列, 有相似的结构和操作方法
序列相关操作方法
1. 索引 - 正反索引: ```l[3];l[-1]``` - 索引溢出(IndexError): 当索引大于序列的最大索引时会报错,如[1,2,3,4]最大索引是3,引用l[4]会报IndexError 2. 切片 - l[1:3] # 从列表索引1到索引3(不包含索引3)进行截取, 如 l = [1, 2, 3, 4, 5], l[1:3]为[2, 3] - l[:5:2] # 第一个表示开始索引(留空0), 第二个表示结束索引(留空为最后一个,即-1), 第三个是步长, 即从开头到第5个(不包含第5个),跳一个取一个 - *案例*: 字符串反转 ```s="abcdefg";r=s[::-1]``` 3. 遍历 - 按元素遍历: ```for item in l: print(item)``` - 按索引遍历: ```for index in range(len(l)): print(l[index])``` - 按枚举遍历: ```for i,v in enumerate(l): print((i,v))``` 4. 扩展/连接(添加多个元素): extend()/+ ```"abc"+"123";[1,2,3]+[4,5];[1,2,3].extend([4,5,6,7])``` 5. 类型互转: str()/list()/tuple() >list转str一般用join(), str转list一般用split()
- 系统函数
- len(): 计算长度
- max()/min(): 求最大/最小元素
- sorted()/reversed(): 排序/反转并生成新序列(sort()/reverse()直接操作原序列)
l_new=sorted(l);l_new2=reversed(l)
5. 集合Set
- 集合可以通过序列生成
a = set([1,2,3])
- 集合无序,元素不重复(所有元素为可哈希元素)
- 集合分为可变集合set和不可变集合frozenset
- 操作方法: 联合|,交集&,差集-,对称差分^
- 系统函数: add()/update()/remove()/discard()/pop()/clear()
- 案例1: 列表去重:
l=[1,2,3,1,4,3,2,5,6,2];l=list(set(l)) (由于集合无序,无法保持原有顺序)
- 案例2: 100w条数据,用列表和集合哪个性能更好? - 集合性能要远远优于列表, 集合是基于哈希的, 无论有多少元素,查找元素永远只需要一步操作, 而列表长度多次就可能需要操作多少次(比如元素在列表最后一个位置)
6. 字典Dict
- 字典是由若干key-value对组成, 字典是无序的, 字典的key不能重复,而且必须是可哈希的,通常是字符串
- 字典操作
- 赋值:
d = {"a":1, "b":2}
- 获取:
a = d['a']或a = d.get("a") # d中不存在"a"元素时不会报错
- 增:
d["c"] = 3; d.update({"d":5, "e": 6}
- 删:
d.pop("d");d.clear() # 清空
- 查:
d.has_key("c")
- 遍历:
- 遍历key:
for key in d:或for key in d.keys():
- 遍历value:
for value in d.values():
- 遍历key-value对:
for item in d.items():
- 案例: 更新接口参数 api = {"url": "/api/user/login": data: {"username": "张三", "password": "123456"}},将username修改为"李四"
api['data']['username'] = "李四" 或 api['data'].update({"username": "李四"})
哈希与可哈希元素(一般来说可哈希就是不可变)
- 哈希是通过计算得到元素的存储地址(映射), 这就要求不同长度的元素都能计算出地址,相同元素每次计算出的地址都一样, 不同元素计算的地址必须唯一, 基于哈希的查找永远只需要一步操作, 计算一下得到元素相应的地址, 不需要向序列那样遍历, 所以性能较好
- 可哈希元素: 为了保证每次计算出的地址相同, 要求元素长度是固定的, 如数字/字符串/只包含数字,字符串的元组, 这些都是可哈希元素
6种类型简单的特点总结
- 数字/字符串/元祖: 长度固定
- 序列(字符串/列表/元祖): 有序
- 集合/字典: 无序, 不重复/键值不重复
条件/循环
条件判断
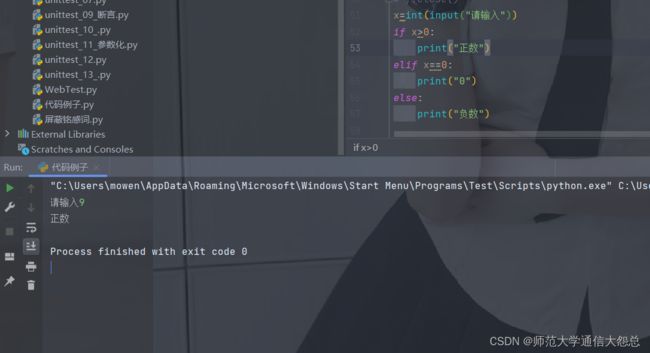
- 示例:
x=int(input("请输入"))
if x>0:
print("正数")
elif x==0:
print("0")
else:
print("负数")
-
三元表达式: max = a if a > b else b
-
案例: 判断一个字符串是不ip地址
ip_str = '192.168.100.3'
ip_list = ip_str.split(".") # 将字符串按点分割成列表
is_ip = True # 先假设ip合法
if len(ip_list) != 4:
is_ip= False
else:
for num in ip_list:
if not isdigit(num) or not 0 <= int(num) <= 255:
is_ip = False
if is_ip:
print("是ip")
else:
print("不是ip")
使用map函数的实现方法(参考):

循环
- for in 循环
- while 循环
文件读写(文本文件)
html/xml/config/csv也可以按文本文件处理
文件操作方法
- open(): 打开
f =open("test.txt")或f =open("test.txt","r", encoding="utf-8")或with open("test.txt) as f: # 上下文模式,出结构体自动关闭文件
- read()/readline()/readlines(): 读取所有内容/读取一行/读取所有行(返回列表) - 注意: 内容中包含\n换行符,可以通过strip()去掉
- f.write()/f.save(): 写文件/保存文件
- f.seek(): 移动文件指针,如f.seek(0), 移动到文件开头
- f.close(): 关闭文件(打开文件要记得关闭)
文件打开模式
- r/w/a: 只读/只写/追加模式
- rb/wb/ab: 二进制只读/只写/追加模式(支持图片等二进制文件)
- r+/rb+, w+/wb+, a+/ab+: 读写,区别在于, r+/w+会清空文件再写内容, r+文件不存在会报错, a+不清空原文件,进行追加, w+/a+文件不存在时会新建文件
文件是可迭代的,可以直接用 for line in f: 遍历
函数/类
函数定义和调用
def add(x, y): # 定义函数
return x+y
print(add(1,3)) # 调用函数
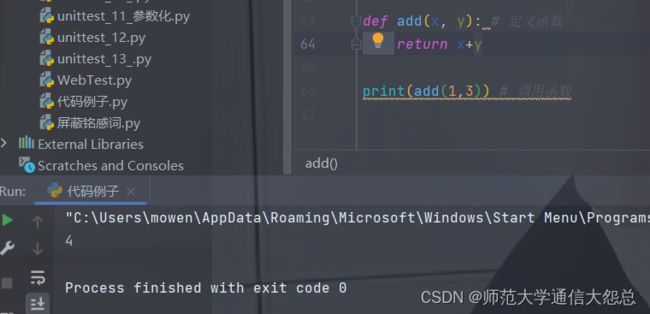
举例: 用户注册/登录函数
users = {"张三": "123456"}
def reg(username, password):
if users.get(username): # 如果用户中存在username这个key
print("用户已存在")
else:
users[username] = password # 向users字典中添加元素
print("添加成功")
def login(username, password)
if not users.get(username):
print("用户不存在")
elif users['username'] == password:
print("登录成功")
else:
print("密码错误")
参数和返回值
- 函数没有return默认返回None
- 参数支持各种对象,包含数字,支付串,列表,元组,也可以是函数和类
- 参数默认值: 有默认值的参数必须放在最后面, 如```def add(x, y=1, z=2):
- 不定参数: *args和**kwargs, 如
def func(*args, **kwargs):可以接受任意长度和格式的参数
- 参数及返回值类型注释(Python3)
def add(x:int, y:int) -> int: # x,y为int型,函数返回为int型,只是注释,参数格式非法不会报错
return x+y
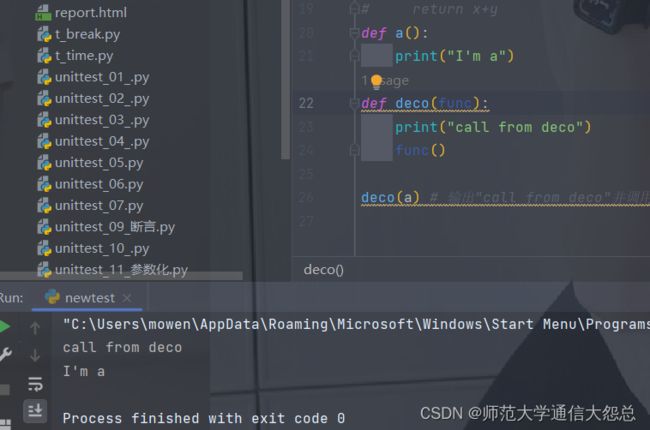
函数作为参数(如: 装饰器)
def a():
print("I'm a")
def deco(func):
print("call from deco")
func()
deco(a) # 输出"call from deco"并调用a(),输出"I'm a"
函数嵌套(支持闭包)
def a():
a_var = 1
def b():
nonlocal a_var
a_var += 1
b() # 调用函数 b
print(a_var) # 输出结果为 2
函数递归(自己调用自己,直到满足需求)
案例: 求N!
def factorial(n):
return 1 if n == 0 or n == 1 else n * factorial(n-1)
print(factorial(39))
输入测试
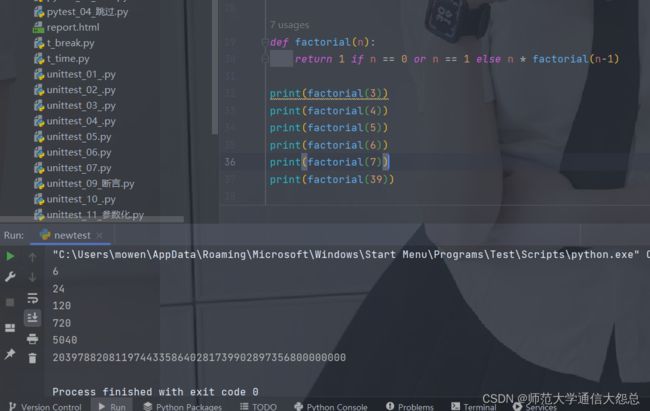
蓝桥杯的填空题我就遇到过,遇到这种直接用Py比较好,因为py没有大数限制
模块/包
模块
- 一个py文件为一个模块
- 模块导入
- import os # 需要通过os调用相关方法, 如os.mkdir(),
- form configparser import ConfigParser: 可以直接使用CinfigParser()
- 支持一次导入多个
包
- 一个文件夹为一个包(Python3,文件夹中不需要建立__init__.py文件)
常用系统模块
- os: 与操作系统交互
- os.name/os.sep/os.linesep: 系统名称/系统路径分隔符/系统换行符
- os.makedir()/os.makedirs(): 建立目录/建立多级目录
- os.getenv("PATH"): 获取系统PATH环境变量的设置
- os.curdir/os.prdir: 获取当前路径/上级路径
- os.walk(): 遍历文件夹及子文件
- os.path.basename()/os.path.abspath()/os.path.dirname(): 文件名/文件绝对路径/文件上级文件夹名
- os.path.join()/os.path.split(): 按当前系统分隔符(os.sep)组装路径/分割路径
- os.path.exists()/os.path.isfile()/os.path.isdir(): 判断文件(文件夹)是否存在/是否文件/是否文件夹
- 案例: 用例发现, 列出文件夹及子文件夹中所有test开头的.py文件,并输出文件路径2
for root,dirs,files in os.walk("./case/"):
for file in files:
if file.startswith("test") and file.endswith(".py"):
print(os.path.join(root, file))
- sys: 与Python系统交互
- sys.path: 系统路径(搜索路径)
- sys.platform: 系统平台,可以用来判断是python2还是3
- sys.argv: py脚本接受的命令行参数
- sys.stdin/sys.stdout/sys.stderr: 标准输入/输出/错误
常见算法
冒泡排序
def buddle_sort(under_sort_list):
l = under_sort_list
for j in range(len(l)):
for i in range(len(l)-j-1):
if l[i] > l[i+1]:
l[i], l[i+1] = l[i+1], l[i]
快速排序
def quick_sort(l):
if len(l) < 2:
return l # 如果列表只有一个元素, 返回列表(用于结束迭代)
else:
pivot = l[0] # 取列表第一个元素为基准数
low = [i for i in l[1:] if i < pivot] # 遍历l, 将小于基准数pivot的全放入low这个列表
high = [i for i in l[1:] if i >= pivot ]
return quick_sort(low) + [pivot] + quick_sort(high) # 对左右两部分分别进行迭代
二分查找
def bin_search(l, n): # l为有序列表
low, high = 0, len(l) - 1 # low,high分别初始化为第一个/最后一个元素索引(最小/最大数索引)
while low < high:
mid = (high-low) // 2 # 地板除,保证索引为整数
if l[mid] == n:
return mid
elif l[mid] > n: # 中间数大于n则查找前半部分, 重置查找的最大数
high = mid -1
else: # 查找后半部分, 重置查找的最小数
low = mid + 1
return None # 循环结束没有return mid 则说明没找到
结语:
目前本人也就预习到这里了,欢迎各位同学分享交流,同时也欢迎大佬给我这个小白推荐路线学习
视图网站推荐
下面推荐几个学习数据结构和算法的可视化工具。
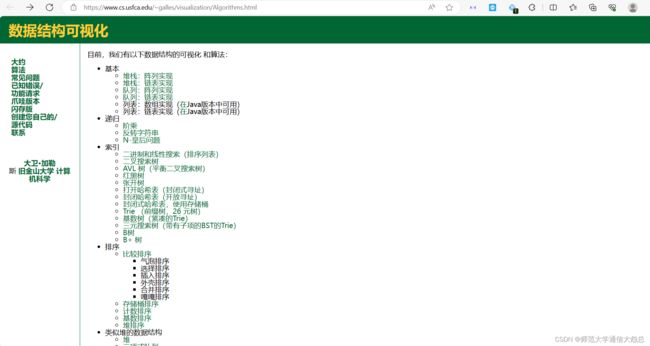
1、Data Structure Visualizations
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
这是一个在线数据可视化工具,可以手动创建各种数据结构,包括队列、栈、堆、树等等,并且支持递归、排序、搜索等算法的动态演示。该工具由旧金山大学开发。
这个工具通过可视化的方式展现了数据结构和算法,方便我们理解其中的原理。网站容易操作、内容丰富且容易理解,非常nice~虽然网站是英文的,不过都是些容易理解的术语,英文不好的小伙伴也不会有很大的阅读障碍。
2、visualgo
https://visualgo.net/en
https://visualgo.net/zh
该网站由 Steven Halim 博士开发,对于理解数据结构与算法非常有帮助。网站里面包含了排序、链表、哈希表、二叉搜索树、递归树、循环查找等常见算法动画。
在动画执行的过程中,还会在网站右下角高亮展示动画的代码逻辑。非常适合初学者学习巩固自己的算法知识。
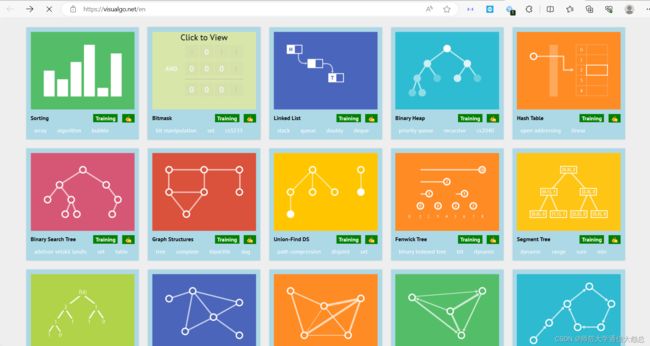
3、BinaryTreeVisualiser
http://www.btv.melezinek.cz/home.html
一款二叉树可视化的工具,可以用来学习二叉树,超级好用。
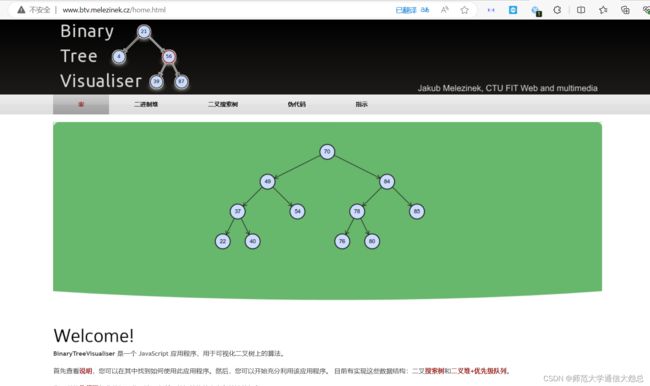
4、btree-js
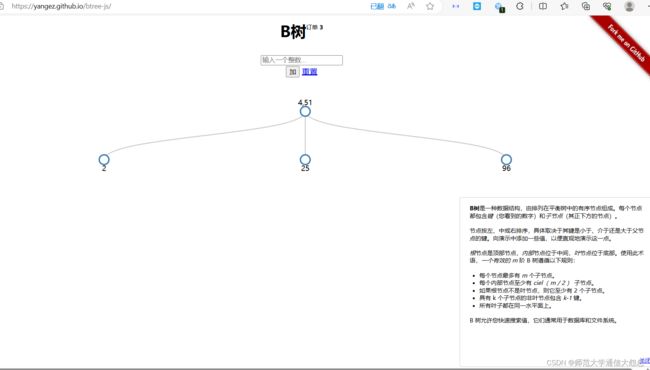
https://yangez.github.io/btree-js/
这是一个专门演示B树的工具,可以在上面插入节点模拟B树的构建过程,对于理解B树这种数据结构非常有帮助。
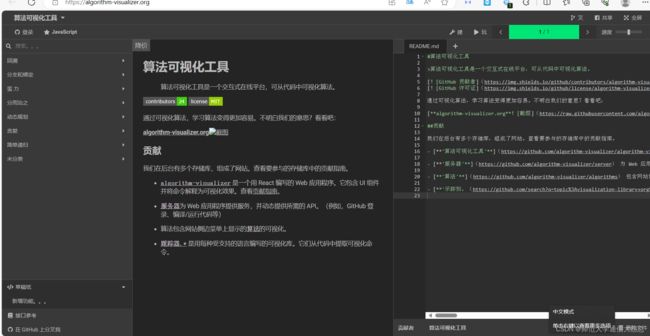
5、Algorithm Visualizer
https://algorithm-visualizer.org/
Algorithm Visualizer 是一个可视化代码算法的交互式平台,内含多种算法(回溯、动态规划、贪心等)并进行了可视化动画呈现,让学习算法和数据结构更加直观。
目前支持的算法包括回溯法、动态规划、贪婪算法、排序算法、搜索算法等。
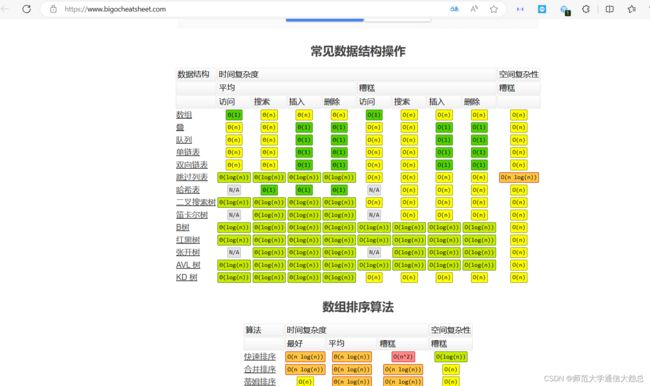
6、bigocheatsheet
https://www.bigocheatsheet.com/
这个网站总结了常用算法的时空Big-O复杂性,常见数据结构操作的时间复杂度。
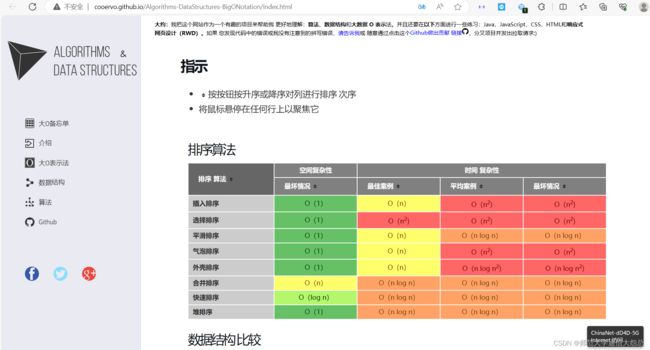
7、Algorithms-DataStructures-BigONotation
http://cooervo.github.io/Algorithms-DataStructures-BigONotation/index.html
这也是一个可以查看算法分析的网站工具,功能相比bigocheatsheet,更丰富一些。
8、Vamonos
http://rosulek.github.io/vamonos/
http://rosulek.github.io/vamonos/demos/index.html
有常用的数据结构与算法的演示:栈、队列、二叉树、红黑树、B树、拓扑排序、广度优先算法。
你可能感兴趣的:(python,学习,开发语言)