23-properties文件和xml文件以及dom4j的基本使用操作
特殊文件
我们利用这些特殊文件来存放我们 java 中的数据信息,当数据量比较大的时候,我们可以利用这个文件对数据进行快速的赋值

对于多个用户数据的存储的时候我们要用这个XML来进行存储
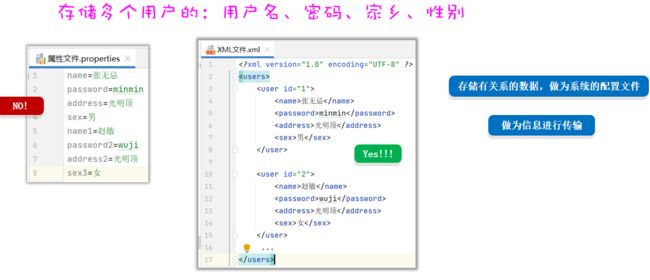
关于这些特殊文件,我们主要学什么
- 了解他们的特点,作用
- 学习使用程序读取他们里面的数据
- 学习使用程序把数据存储到这些文件里
Properties属性文件
了解它们的特点、作用
学习使用程序读取它们里面的数据
学习使用程序把数据存储到这些文件里

是一个Map集合(键值对集合),但是我们一般不会当集合使用。
核心作用:Properties是用来代表属性文件的,通过Properties可以读写属性文件里的内容。
使用Properties读取属性文件里的键值对数据
| 构造器 | 说明 |
|---|---|
| public Properties() | 用于构建 Properties 集合对象(空容器) |
读
我们首先要通过这个文件的字节或者字符输入流来读取这个属性文件中的数据。
| 常用方法 | 说明 |
|---|---|
| public void load(InputStream is) | 通过字节输入流,读取属性文件里的键值对数据 |
| public void load(Reader reader) | 通过字符输入流,读取属性文件里的键值对数据 |
| public String getProperty(String key) | 根据键获取值(其实就是get方法的效果) |
| public Set |
获取全部键的集合(其实就是 ketSet 方法的效果) |
其实它本质作用就是我们用来读取文件中的等号两边的元素
其本质是一个map集合
文件内容,好像中文格式不兼容?
admin=123456
张无忌=minmin
sadf=wuji
asfdaf=wuji
public static void main(String[] args) throws IOException { // 创建这个特殊文件
Properties pt = new Properties();
System.out.println(pt); //输出为空
pt.load(new FileReader("LearnJavaSE\\Learn\\src\\Metamorphosis\\day4\\SpecialFile\\p.properties"));
System.out.println(pt);
System.out.println(pt.getProperty("admin")); //根据键的值来读取数据.
写
| 常用方法 | 说明 |
|---|---|
| public Object setProperty(String key, String value) | 保存键值对数据到Properties对象中去。 |
| public void store(OutputStream os, String comments) | 把键值对数据,通过字节输出流写出到属性文件里去 |
| public void store(Writer w, String comments) | 把键值对数据,通过字符输出流写出到属性文件里去 |
| 属性文件并不是后缀是properties才是属性文件 | |
| 只要满足键值对的书写格式,那么 txt 也是属性文件 |
// 创建这个特殊文件
Properties pt = new Properties();
System.out.println(pt); // 输出为空
pt.load(new FileReader("LearnJavaSE\\Learn\\src\\Metamorphosis\\day4\\SpecialFile\\test.txt"));
System.out.println(pt);
System.out.println(pt.getProperty("admin")); // 根据键的值来读取数据.
XML文件
本质是一种数据的格式,可以用来存储复杂的数据结构,和数据关系。
XML的特点
- XML中的“<标签名>” 称为一个标签或一个元素,一般是成对出现的。
- XML中的标签名可以自己定义(可扩展),但必须要正确的嵌套。
- XML中只能有一个根标签。
- XML中的标签可以有属性。
- 如果一个文件中放置的是XML格式的数据,这个文件就是XML文件,后缀一般要写成.xml。
和HTML文件,惊人的类似
XML的创建
就是创建一个 XML 类型的文件,要求文件的后缀必须使用 xml,如 hello_world.xml, 这一点和这个 properties 文件不太一样,properties 只需要内容的格式满足条件就可以了, 其他的要求不高的
开头文件的格式必须这样写,必须放在第一行
version:XML默认的版本号码、该属性是必须存在的encoding:本XML文件的编码
XML文件中的特殊符号
XML 中可以定义注释信息: 这个和这个 html 文件是一样的.
XML中书写”<”、“&”等,可能会出现冲突,导致报错,此时可以用如下特殊字符替代。
` < < 小于
> > 大于
& & 和号
' ' 单引号
" " 引号
XML中可以写一个叫CDATA的数据区: ,里面的内容可以随便写。**此时的小于号还有大于号就不用再用特殊符号了**
<users>
<use id="1">
<name>张无忌name>
<sex>男sex>
use>
<use id="2">
<name>任盈盈name>
<sex>女sex>
use>
users>
作用
本质是一种数据格式,可以存储复杂的数据结构,和数据关系。
应用场景:经常用来做为系统的配置文件;或者作为一种特殊的数据结构,在网络中进行传输。
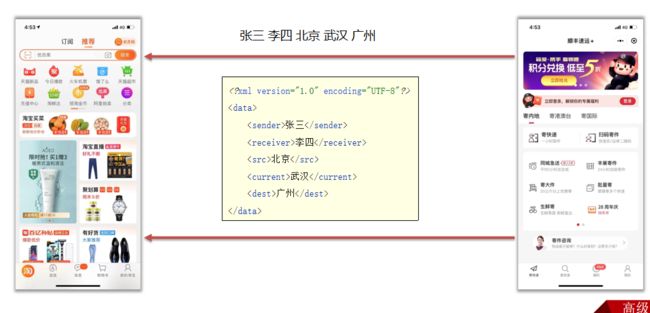
XML文件的解析
注意:程序员并不需要自己写原始的IO流代码来解析XML,难度较大!也相当繁琐!
其实,有很多开源的,好用的,解析XML的框架,最知名的是:Dom4j(第三方研发的)
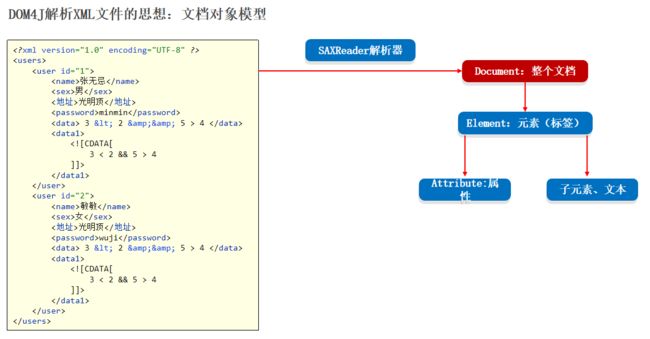
SAXReader:Dom4j 提供的解析器,可以认为是代表整个 Dom4j 框架
| 构造器/方法 | 说明 |
|---|---|
| public SAXReader() | 构建Dom4J的解析器对象 |
| public Document read(String url) | 把XML文件读成Document对象 |
| public Document read(InputStream is) | 通过字节输入流读取XML文件 |
| 使用方法 |
SAXReader sr = new SAXReader();
Document doc = sr.read("LearnJavaSE\\Learn\\src\\Metamorphosis\\day4\\SpecialFile\\xmlTest.xml");
Document doc2 = sr.read(new FileReader("LearnJavaSE\\Learn\\src\\Metamorphosis\\day4\\SpecialFile\\xmlTest.xml"));
| 方法名 | 说明 |
|---|---|
| Element getRootElement() | 获得根元素对象 |
| 获取根节点,根节点是这个 xml 分析的开始,任何 xml 分析工作都要从这个根开始 |
Element root = doc.getRootElement();
注意这个文件名字不能有中文
解析的核心操作
| 方法名 | 说明 |
|---|---|
| public String getName() | 得到元素名字 |
| public List |
得到当前元素下所有子元素 |
| public List |
得到当前元素下指定名字的子元素返回集合 |
| public Element element(String name) | 得到当前元素下指定名字的子元素,如果有很多名字相同的返回第一个 |
| public String attributeValue(String name) | 通过属性名直接得到属性值 |
| public String elementText(子元素名) | 得到指定名称的子元素的文本 |
| public String getText() | 得到文本 |
xml 的基本操作如下
<users>
<use id="1">
<name>张无忌name>
<sex>男sex>
use>
<use id="2">
<name>任盈盈name>
<sex>女sex>
use>
users>
// 我们首先要读取这个xml文件
SAXReader sr = new SAXReader();
Document doc = sr.read("LearnJavaSE\\Learn\\src\\Metamorphosis\\day4\\SpecialFile\\xmlTest.xml");
// Document doc2 = sr.read(new
// FileReader("LearnJavaSE\\Learn\\src\\Metamorphosis\\day4\\SpecialFile\\xmlTest.xml"));
Element root = doc.getRootElement();
System.out.println(root.getName()); // 根节点名称
List<Element> elements = root.elements();
for (Element elements2 : elements) {
System.out.println(elements2.getName()); // 根节点下的节点名,只能是一层,第二层的节点名比如说这个name和sex是无法读取的
//根据属性名来获取这个id对象的值
System.out.println(elements2.attributeValue("id"));
// 获取这个use类中的名称为name的所有子元素,并返回集合,然后可以读取这个text文本了
List<Element> elements3 = elements2.elements("name");
for (Element elements32 : elements3) {
System.out.println(elements32.getText());
}
得到当前元素下指定名字的子元素,如果有很多名字相同的返回第一个
Element people = rootElement.element("people");
System.out.println(people.getText());
把程序中的数据写入到XML文件中
StringBuilder sb = new StringBuilder();
sb.append("\r\n");
sb.append("\r\n" );
sb.append("" ).append("从入门到跑路").append("\r\n");
sb.append("" ).append("dlei").append("\r\n");
sb.append("" ).append("从入门到跑路").append("\r\n");
sb.append("");
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter("src/day5/newtest.xml"));
bufferedWriter.write(sb.toString());
bufferedWriter.close();
我们如果不用这个 dom4库来进行写,我们还可以通过这个 IO 流的读写方式来进行读写,但是没有必要,用别人封装好的就行,java 只需要 nb 就是因为这些别人封装好的库,这些库使得大多数的 java 操作变得简单了
约束XML文件的书写
顾名思义就是限制 XML 文件只能按照某种格式进行书写。
专门用来限制xml书写格式的文档,比如:限制标签、属性应该怎么写。
约束文档的分类
DTD文档
Schema文档
XML文档约束-DTD的使用(了解)
需求:利用DTD约束文档,约束一个XML文件的编写。
①:编写DTD约束文档,后缀必须是.dtd
可以约束XML文件的编写
不能约束具体的数据类型
②:在需要编写的XML文件中导入该DTD约束文档
③:然后XML文件,就必须按照DTD约束文档指定的格式进行编写,否则报错!
//表示这个根元素是书架,然后根元素的子元素是书,+加号表示不止只有一个子元素
//子元素的子元素
DOCTYPE 书架 SYSTEM "data.dtd">
<书架>
<书>
<书名>从入门到删库书名>
<作者>小猫作者>
<售价>很便宜售价>
书>
<书>
<书名>从入门到删库书名>
<作者>小猫作者>
<售价>9.9售价>
书>
<书>
<书名>从入门到删库书名>
<作者>小猫作者>
<售价>9.9售价>
书>
书架>
XML文档约束-schema的使用(了解)
可以约束XML文件的编写、和数据类型
需求:利用schema文档约束,约束一个XML文件的编写。
①:编写schema约束文档,后缀必须是.xsd,具体的形式到代码中观看。
②:在需要编写的XML文件中导入该schema约束文档
③:按照约束内容编写XML文件的标签。
//xmln后面的网址表示这个xsd文档本身也是受到别人约束的
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itcast.cn"
elementFormDefault="qualified" > //这个不用管,直接把这个复制到xsd文档开头就行了.
<element name='书架'>
<complexType>
<sequence maxOccurs='unbounded'>
<element name='书'>
<complexType>
<sequence>
<element name='书名' type='string'/>
<element name='作者' type='string'/>
<element name='售价' type='double'/>
sequence>
complexType>
element>
sequence>
complexType>
element>
schema>
<书架 xmlns="http://www.itcast.cn" //声明一个包名,和xsd的里面的那个targetNamespace中的内容一样
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn data.xsd">
<书>
<书名>从入门到删除书名>
<作者>dlei作者>
<售价>9.9售价>
书>
<书>
<书名>从入门到删除书名>
<作者>dlei作者>
<售价>0.9售价>
书>
书架>