Redis入门到精通
Redis入门到精通
-
- 1.1.redis概述
- 1.2 什么是NoSql?
- 1.3 NoSql与传统数据库的比较
- 1.4 在什么场景下使用NoSql
- 1.5 NoSql的数据模型
- 1.6 NoSql数据库的分类
- 1.7 linux安装redis
- 1.8 docker安装redis
- 2.redis必备命令
-
- 2.1 键命令
- 2.2 修改键
- 2.3 键的序列化
- 2.4 键的生存时间
- 2.5 键值对操作
- 2.6 删除键
- 2.7 HyperLogLog命令
- 2.8 脚本命令
- 2.9 客户端与服务器
- 2.10 配置选项
- 2.11 复制
- 2.12 调试
- 3.redis五种数据类型
-
- 3.1 String 类型
- 3.2 HASH 类型
- 3.3 list 数据类型
- 3.4 set 数据类型
- 3.5 sorted set 数据类型
- 4.redis数据库
-
- 4.1 redis数据库的切换
- 4.2 redis删除策略
-
- 4.2.1 定期删除策略
- 4.2.2 惰性删除策略
- 4.2.3 定期删除策略
- 4.2.4 Redis过期删除策略
-
- 4.2.4.1 定期删除
- 4.2.4.2 懒惰删除
- 4.2.4.3 aof/rdb和复制功能对过期键的处理
- 4.3 redis数据库通知
- 5.redis通信协议
-
- 5.1 网络层
- 5.2 请求
- 5.3 新版统一请求协议
- 5.4 回复
- 5.5 状态回复
- 5.6 错误回复
- 5.7 整数回复
- 5.8 批量回复
- 5.9 多条批量回复
- 5.10 多条批量回复中的空元素
- 5.11 多命令和流水线
- 5.12内联命令
- 5.13 高性能 Redis 协议分析器
- 6.redis客户端与服务器
-
- 6.1.redis客户端
-
- 6.1.1 客户端名称,套接字,标志和时间
- 6.1.2 客户端缓冲区
- 6.1.3 客户端的 authenticated 属性
- 6.1.4 客户端的 argv 和 argc 属性
- 6.1.5 关闭客户端
- 6.2 redis服务器
-
- 6.2.1 服务器处理命令请求
- 6.2.2 服务器发送命令
- 6.2.3 服务器执行命令
- 6.2.4 服务器返回命令结果
- 6.3 服务器函数
-
- 6.3.1 serverCron 函数
- 6.3.2 trackOperationsPerSecond 函数
- 6.3.3 sigtermHandler 函数
- 6.3.4 clientsCron 函数
- 6.3.5 databasesCron 函数
- 6.4 服务器属性
-
- 6.4.1 cronloops 属性
- 6.4.2 rdb_child_pid 与 aof_child_pid 属性
- 6.4.3 stat_peak_memory 属性
- 6.4.4 lruclock 属性
- 6.4.5 mstime 与 unixtime 属性
- 6.4.6 aof_rewrite_scheduled 属性
- 6.5 Redis 服务器的启动过程
-
- 6.5.1 服务器状态结构的初始化
- 6.5.2 相关配置参数的加载
- 6.5.3 服务器数据结构的初始化
- 6.5.4 数据库状态的处理
- 6.5.5 执行服务器的循环事件
- 7.redis底层数据结构
-
- 7.1 Redis 简单动态字符串
-
- 7.1.1 SDS 的实现原理
- 7.1.2 SDS API 函数
- 7.2 Redis 链表
-
- 7.2.1 Redis 链表实现原理
- 7.2.2 链表 API 函数
- 7.3 Redis 压缩列表
-
- 7.3.1 压缩列表的实现原理
- 7.3.2 压缩列表 API 函数
- 7.4 Redis 快速列表
-
- 7.4.1 快速列表的实现原理
- 7.4.2 快速列表 API 函数
- 7.5 Redis 字典
-
- 7.5.1 字典的实现原理
- 7.5.2 字典 API 函数
- 7.6 Redis 整数集合
-
- 7.6.1 整数集合的实现原理
- 7.6.2 整数集合 API 函数
- 7.7 Redis 跳表
-
- 7.7.1 跳表的实现原理
- 7.7.2 跳表 API 函数
- 7.8 Redis 中的对象
-
- 7.8.1 对象类型
- 7.8.2 对象的编码方式
- 8.排序
-
- 8.1 SORT 排序命令
- 8.2 升序(ASC)与降序(DESC)
- 8.3 BY 参数的使用
- 8.4 LIMIT 参数的使用
- 8.5 GET 与 STORE 参数的使用
- 8.6 多参数执行顺序
- 9.Redis 事务
-
- 9.1 Redis 事务简介
- 9.2 Redis 事务的 ACID 特性
-
- 9.2.1 事务的原子性
- 9.2.2 事务的一致性
- 9.2.3 事务的隔离性
- 9.2.4 事务的持久性
- 9.3 Redis 事务处理
-
- 9.3.1 事务的实现过程
- 9.3.2 悲观锁和乐观锁
- 9.3.3 事务的 WATCH 命令
- 10.消息订阅
-
- 10.1 消息订阅发布概述
- 10.2 消息订阅发布实现
-
- 10.2.1 消息订阅发布模式命令
- 10.2.2 消息订阅功能之订阅频道
- 10.2.3 消息订阅功能之订阅模式
- 10.3 Redis 消息队列
-
- 10.3.1 消息订阅发布模式的原理
- 10.3.2 消息生产者/消费者模式的原理
- 11.redis持久化
-
- 11.1 Redis 持久化操作概述
-
- 11.2.1 AOF 持久化的配置
- 11.2.2 AOF 持久化的实现
- 11.2.3 AOF 文件重写
- 11.2.5 AOF 持久化的优劣
- 11.3 Redis 持久化机制 RDB
-
- 11.3.1 RDB 持久化
- 11.3.2 RDB 文件
- 11.3.3 RDB 文件的创建与加载
- 11.3.4 创建与加载 RDB 文件时服务器的状态
- 11.3.5 RDB 持久化的配置
- 11.3.6 RDB 持久化的优劣
- 11.4 AOF 持久化与 RDB 持久化抉择
- 12.redis 集群
-
- 12.1 Redis 集群的主从复制模式
-
- 12.1.1 什么是主从复制
- 12.1.2 主从复制配置
- 12.1.3 复制功能的原理
- 12.1.4 复制功能的实现步骤
- 12.1.5 Redis 读写分离
- 12.1.6 Redis 心跳机制
- 12.2 Redis 集群的高可用哨兵模式
-
- 12.2.1 什么是高可用哨兵模式
- 12.2.2 哨兵模式的配置
- 12.2.3 Sentinel 的配置选项
- 12.2.4 哨兵模式的实现原理
- 12.2.5 选择“合适”的 slave 节点作为 master 节点
- 12.2.6 Sentinel 的下线状态
- 12.2.7 Sentinel 内部的定时任务
- 12.3 Redis 集群搭建
-
- 12.3.1 什么是 Redis 集群
- 12.3.2 集群中的节点和槽
- 12.3.3 集群搭建
- 12.3.4 使用 Redis 集群
- 12.3.5 集群中的错误
- 12.3.6 集群的消息
- 13.redis实战
-
- 13.1 java连接redis
1.概述与安装
1.1.redis概述
Redis:REmote DIctionary Server(远程字典服务器)是完全开源免费的,用C语言编写的,遵守BSD协议,是一个高性能的(key/value)分布式内存数据库,基于内存运行 并支持持久化的NoSQL数据库,是当前最热门的NoSql数据库之一,也被人们称为数据结构服务器。
Redis 与其他 key - value 缓存产品有以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储
Redis支持数据的备份,即master-slave模式的数据备份
redis能做什么?
1.内存存储和持久化:redis支持异步将内存中的数据写到硬盘上,同时不影响继续服务
2.取最新N个数据的操作,如:可以将最新的10条评论的ID放在Redis的List集合里面
3.模拟类似于HttpSession这种需要设定过期时间的功能
4.发布、订阅消息系统
5.定时器、计数器
1.2 什么是NoSql?
NoSql不仅仅是SQL,他是Not Only SQL的缩写,也是众多非关系数据库的简称,NoSql和关系型数据库一样,都是用来存储数据的仓库。
1.为什么需要NoSql?
随着互联网的高速发展,数据量,访问量呈爆发式的增长,人们对QQ,微信,微博,网上购物等软件使用的依赖度增高,如 聊天记录,商品信息,微博信息存储在哪里呢?如果全存储在关系型数据库中。然后传统的关系型数据库面对这些大数据量的信息存储,以及事项高访问,高并发,高吞吐量,就会暴露出问题难以克服的问题。为了海量数据的高速缓存存储,NoSQL由此诞生。
2.NoSql的出现解决了高并发读写的问题
web2.0 动态网站需要根据用户的需求来生成动态页面,和提供动态信息,而且无法使用动态页面的静态话技术,因此数据库的并发负载会非常的高,比如微博,朋友圈的实时更新,会出现每秒上万次的读写请求。关系型数据库在每秒上万的SQL查询中还能应对自如,但是如果是每秒上万次的SQL写操作时,就难以招架了,普通BBS系统网站也存在高并发读写的需求,比如实时统计在线人数,记录热门帖子之类的,当面对这些需求的时候,传统的关系型数据库就会出现很大的问题。
3.NoSql的出现解决了海量数据的高效率存储和访问问题
面对实时产生的大量数据的存储与查询,关系型数据库是难以应对的,会显得效率非常的低,而利用NoSql的高效存储和查询能力,就能解决这个问题。
4.NoSql事项了高可用性以及高维护性
在基于web的架构中,关系型数据库难以进行横向扩展,当一个网站系统的用户量和访问量与日俱增的时候,数据库没有办法像web服务器或应用服务器那样通过添加跟多的硬件来搭建负载均衡的服务器,对于很多24小时不间断的非圆舞曲网站来说,对数据库系统的升级和维护是一个非常折磨人的事情,往往需要停机和数据迁移。
随着NoSql的出现,解决了大规模数据库集中和数据种类不同所带来的各种问题,尤其是大数据实现起来非常困难。
NoSql有如下特点:
- 容易扩展,方便失业,数据直接没有关系
- 数据模型非常灵活多变,无需提前为存储的字段建立映射关系,随时可以存储自定义的数据格式
- 适合大数据量,高性能的存储
- 具有高并发,读写,高可用性
1.3 NoSql与传统数据库的比较
相信大家对传统关系型数据库都不陌生,我们常常使用的关系型数据库有MySql,Oracle,Sql Server,SQLite,DB2,Teradata,Infomix,Sybase,PostreSQL,Access,FoxPro等等
我们现在通过以下几个方面来比较NoSql与传统关系型数据库
1.使用成本:
NoSql:NoSql使用简单,容易搭建,大部分是开源软件,比较廉价,任何人都可以免费使用。
关系型数据库:相对于NoSql来说,关系型数据库需要安装和部署,开源的比较少,使用成本比较昂贵,尤其是Oracle数据库,需要花大量资金购买,使用成本比较高。
2.存储形式:
NoSql:NoSql 具有丰富的存储形式,如key-value的形式,图表结构,文档形式,列簇等,因此他可以存储各种数据类型
关系型数据库:关系型数据库采用的关系模型来存储数据,他是行列结构,通过行与列的二元形式表示处理,数据之间有很强大的关联性,采用二维表的结果来进行持久化存储。
3.查询速度:
NoSql:NoSql将数据存储在系统的缓存中,存储在内存,不需要Sql解析,因此查询速度非常的快
关系型数据库:关系型数据库将数据存储在系统的硬盘中,在查询的时候需要经过SQL层的解析,然后读入内存,实现查询,因此查询效率比较低。
4.扩展性:
NoSql:NoSql去掉了传统关系型数据库表与字段之间的关系,实现了真正意义上的扩展,他采用了键值对的形式进行存储,消除了数据之间的耦合性,因此容易扩展。
关系型数据库:由于关系数据库采用了关系数据模型来存储数据,数据与数据直接的关联性非常强,存在耦合性,因此不容易扩展,尤其是存在多表连接的情况,查询机制的限制,使得扩展很难实现。
5.是否支持ACID:
ACID特性指的是数据库事务执行的要素,包含了原子性,一致性,隔离性,持久性
NoSql:NoSql一般不支持事,他具有最终一致性
关系型数据库:支持ACID的特性,具有严格的数据库一致性
6.是否支持SQL语句
NoSql:SQL语句在NoSql中是不支持的,NoSql没有声明性的查询预约,并且没有预定义的模式。
关系型数据库:关系型数据库支持SQL,也支持复查的查询,SQL是结构化数据语言,数据操纵语言,数据定义语言。
NoSql与传统关系型数据库是互补的关系,对方的劣势就是自己的优势,反之亦然。
1.4 在什么场景下使用NoSql
NoSql的使用场景比较广泛,下面简单说一下比较合适使用NoSql的几个场景。
- 对于大数据量,高并发的存储系统相关应用
- 对于一些数据模型比较简单的相关应用
- 对于数据一致性不是很高的业务场景
- 对于指定的key来映射一些复制的业务环境
- 对于一些大型的日志信息存储
- 存储用户信息,大型上传的电商购物车,会话等
- 对于多数据源的数据存储
- 对于容易辩护,热点高频信息,关键字等信息存储
以上这些场景都可以使用NoSql进行存储,NoSql还有很多其他的应用。
1.5 NoSql的数据模型
我们清楚,关系型数据库的数据模型由数据结构,数据操作以及完整性约束条件组成,同样,NoSql也有其他相关的数据模型。NoSql的4种数据模型如下:
1.键值对类型数据:
键值对数据模型就是采用key-value的形式进行存储,将数据存储在一张hash表中,这张hash表具有一个特定的key一个特定指向数据的指针。键值对存储中的值可以是任意类型的值,比如: 数字,字符串,也可以是对象在对象中的新键值对。
2.列数据模型:
列数据类型是将数据按照列簇的形式来统一进行存储,通常用于存储分布式系统的海量数据,他也有键指向多个列,由数据库的列簇来统一安排。
3.文档数据模型:
文档数据模型以文档的形式进行存储,他是键值对数据模型的升级版,是版本化的文档,他可以使用模式来指定某个文档的结构,通常采用特定格式来存储半结构化的文档,最常使用的存储格式是XML,JSON,每个文档都是自包含的数据单元,是一系列数据项的集合。
4.图数据类型:
图数据模型采用图结构形式来存储数据,他是键值对数据模型的升级版,他是最复杂的NoSql,常被用于存储一些社交网络关系,使用与存储高度互联网的数据,他由多个节点和多条边组成,节点表示实体,边表示两个实体之间的关系。
其中,键值对数据模型,列数据模型,文档数据模型,统称为聚合模型,他们有一个共同的特点,可以把一组相互关联的对象看在是一个整体的单元来操作,通常把这个单元称为一个聚合。
1.6 NoSql数据库的分类
NoSql数据库大致可以分为四大类:
1.键值对存储数据库:
主要采用键值对形式存储的数据的数据库,典型的有redis,memcached,voldemort,brekeley,tokyiCabiney等,采用该类数据库做存储时,需要定义数据结构(半结构)才能进行存。
2.面向列存储数据库:
主要按照列存储的一类数据库,典型代表有HBase,Cassandra,Riak等,采用该类数据库存储数据时,需要定义数据结构(半结构)才能进行存。
3.面向文档数据库:
主要用于存储文档的一类数据库,文档是它最小的单元,同一张表中存储的文档属性是多样化的,数据可以采用XML,JSON,JSONB等多种格式存储,典型代表:MongoDB,CouchDb,RavenDB等,采用该类数据库存储数据的时候,不需要定义数据结构(非结构化)就可以进行存储。
4.面向图形数据库:
主要用于存储图片信息的一类数据库,典型代表:Neo4j,InfoGrid,Infinite,Graph等。目前NoSql数据库的使用场景非常广泛,很多企业都会根据自己的业务场景来使用各类NoSql数据库,或者混合使用他们。
各类NoSql数据类型比较:

1.7 linux安装redis
安装redis:
redis中文官网
切换到 /opt目录下 ,新建一个redis目录依次执行以下命令,在/usr/local/bin下新建一个目录redis_config,将redis.config文件复制到这个目录
1: yum install wget
2: wget https://github.com/redis/redis/archive/6.2-rc2.tar.gz --no-check-certificate
3:tar -zxvf 6.2-rc2.tar.gz
4: yum install gcc-c++
5:gcc -v 查看gcc版本
6:make (cd到解压后的redis文件下执行)
7: make install
8:redis默认的安装路径: /usr/local/bin
启动redis:
redis-server redis.config配置文件路径
redis-cli -p 6379
解决redis中文乱码:redis-cli --raw
ps -ef | grep redis 查看redis是否成功启动
redis默认端口号:6379
redis 共有15个数据库 select 索引号 :切换到指定数据库 (索引从0开始 ) 默认打开的就是第一个数据库
get key 获取指定k的值 set key 设置指定k的值
keys * 列出当前数据库的 所有k keys k? 列出k开头的k字段
flushdb :清空当前数据库的所有key
flushall : 清空所有数据库中的key
设置redis密码
1、vim redis.conf 修改requirepass的值 (设置redis密码)
2.config set requirepass admin (设置redis密码)
设置密码后需要执行: auth password 才能操作 redis
1.8 docker安装redis
# 下载
docker run -p 3307:3306 -v /usr/local/mysql/conf:/etc/mysql/conf.d -v /usr/local/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 --name mysql mysql:8.0.1
# 运行
docker run \
--name mysql -d \
-p 3307:3306 \
--privileged=true \
-v /usr/local/mysql/conf:/etc/mysql/conf.d \
-v/usr/local/mysql/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=admin \
mysql:8.0.1
2.redis必备命令
2.1 键命令
1. EXISTS(查询键是否存在)
描述:查询键是否存在,如果存在返回1,不存在返回0
# 命令格式 EXISTS key [key ...]
exists user_id
2. KEYS(查找键)
描述:用于查询指定的模式所有的key 参数可以使用类似正则的方式
# 命令格式: KEYS pattern
# 查询当前数据库中所有的key
keys *
# 查询出 redis radis rxdis 等,?:表示一个占位符
keys r?dis
# 表示匹配 rdis,redis,reedis等 *:表示占位一个或多个字符
keys r*dis
# 表示匹配radis和redis []:表示满足其中一个选项即可
3. OBJECT(查询键的对象)
描述:用于查询给定key的redis对象,该指令主要用于在除错,或者为了节省空间而对于key使用特色编码的情况下
# 命令格式: OBJECT subcommand [arguments [arguments ...]]
REFCOUNT:指定key所存储的引用次数
ENCODING:返回指定key底层所使用的数据结构
IDLETIME:返回指定key存储以来的空闲时间,以秒为单位
4.RANDOMKEY(返回随机key)
描述:从当前数据库中随机返回一个key,并且不会去删除这个key
# 命令格式:RANDOMKEY
2.2 修改键
1.RENAME(修改键的名称)
描述:将指定key进行重命名,如果这个newkey存在的话,新值会覆盖掉旧值
#命令格式:RENAME kye newkey
2.(RENAMENX)修改键的名称
描述:将指定key进行重命名,只有当这个newkey不存在的时候,才可以重命名成功。如果key不存在返回错误
#命令格式:RENAMENX key newkey
2.3 键的序列化
1.DUMP(序列化键)
描述:序列化指定的key,并且返回被序列化之后的值,反正我们可以使用 RESTORE 命令来反序列化这个key
# 命令格式: DUMP key
使用DUMP命令序列化生成的值具有如下特点:
- 这个值具有64位的校验和,用于检测错误,RESTORE 命令在反序列之前,会先检查校验和
- 这个值的编码格式和RDB的编码格式保持一致
- RDB版本会被编码在序列化值中,如果redis版本不同,那么这个rdb文件会存在不兼容的问题,redis也就无法对这个值进行返序列化
- 这个序列化的值中没有生存信息
2.RESTORE(反序列化)
描述:用于将给定的值进行返序列化操作,并且关联一个key,ttl用于给key设置过期时间,单位为毫秒,如果设置为0就表示永不过期,
如果key已经存在,并且给定了REPLACE参数,则将会新值覆盖旧值,如果key已经存在,而没有设置REPLACE参数,则将会返回一个错误,当序列化成功的时候,返回一个ok。
# 命令格式: RESTORE key ttl serialized-value [REPLACE] [ABSTTL] [IDLETIME seconds] [FREQ frequency]
2.4 键的生存时间
1.PTTL(获取键的生存时间,毫秒)
描述:用于以毫秒的形式返回key的生存时间,如果key不存在,返回-2,如果key存在,但是没有设置过期时间,返回-1
# 命令格式: PTTL key
2.TTL(获取键的生存时间,秒)
描述:用于以毫秒的形式返回key的生存时间,如果key不存在,返回-2,如果key存在,但是没有设置过期时间,返回-1
# 命令格式: TTL key
3.EXPIRE(设置键的生存时间,秒)
描述:该指令用于设置key的生存时间,当key的生存时间为0的时候,这个key会被删除掉
# 命令格式: EXPIRE key seconds
4.PEXPIRE(设置键的生存时间,毫秒)
描述:该指令用于设置key的生存时间,当key的生存时间为0的时候,这个key会被删除掉
# 命令格式: PEXPIRE key milliseconds
5.EXPIREAT(设置键的生存时间,时间戳)
描述:该指令用于设置key的生存时间,当key的生存时间为0的时候,这个key会被删除掉
# 命令格式: EXPIREAT key timestamp
2.5 键值对操作
1.MIGRATE(转移键值到远程目标数据库)
描述:该命令将key原子性的移动到目标数据库中一旦移动成功,就会生成当前数据库中的key
- timout 表示超时时间,单位为毫秒
- host 目标主机地址
- port 目标主机端口号
- auth 目标主机密码
- key 移动过去的key是什么?
- copy 参数设置了的时候,表示移动完毕后,不用在源数据库中删除
- replace 表示在移动到目标数据库的过程中,如果目标数据库指定的key已经存在,那么就进行覆盖操作
# 命令格式: MIGRATE host port key| destination-db timeout [COPY] [REPLACE] [AUTH password] [KEYS key]
2.MOVE(转移键值对到本地目标数据库)
描述:将当前数据库中的key转移到指定db数据库中,如果当前数据库中没有指定的key,那么move什么也不做,如果当前数据库和给定的数据库中存在相同的key,move命令不起效果。
# 命令格式: MOVE key db
2.SORT(对键值对进行排序)
描述:SORT命令主要用于排序,他返回或保存给定的列表,集合,有序集合中经过排序的元素,默认以数字作为对象,值会被解析成double类型的浮点数,然后进行比较。
# 命令格式: SORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC|DESC] [ALPHA] [STORE destination]
4.TYPE(获取键值对应的类型)
描述:用于返回key 所对应值的类型
# 命令格式:TYPE key
2.6 删除键
1.DEL(删除键)
描述:该命令可以删除一个或多个指定的key,如果这个key不存在的话会被忽略掉,执行成功后返回删除成功的数量
# 命令格式:DEL key [key...]
2.PERSIST(删除键的生存时间)
描述:用于删除给定key的生存时间,将这个带有生存时间的key,转换为一个不带生存时间的key,永不过期。
# 命令格式: PERSIST key
2.7 HyperLogLog命令
HyperLogLog 是redis用来做技术统计的算法,当redis数据库中数据库特别大的时候,使用HyperLogLog命令来计算相关奇数时,他具有所需空间固定,所占空间小的优点,在redis中每个HyperLogLogkey只需要12kb,就可以计算接近2^64个不同的基数,HyperLogLog不会存储输入的元素,他仅仅只是通过输入的元素来计算基数,因此他不会返回输入的元素。
什么是基数?
也就是说比如像{1,2,3,4,4,5},这样一个数据集,去掉重复后为:{1,2,3,4,5},那么这个数据集的基数就为:5
1.PFADD(添加键值对到HyperLogLog中)
描述:该命令将一个或多个指定的key添加到HyperLogLog中,HyperLogLog内部可能会更新添加进来的key,来反映一个不同唯一元素估计数量,这个数量就是集合的基数。如果HyperLogLog估计近似基数在命令执行后发生了变化,那么命令就返回1,否则返回.,这个给定的key不存在,那么命令先会创建一个空的HyperLogLog,再执行命令。
在执行PFADD命令时,我们可以只设置key,而不设置这个key对应的元素,PFADD命令在执行时,如给定的键已经是一个HyperLogLog,那么这个命令将上面也不做,如果给定的键不存在,那么该命令会先创建一个空的HyperLogLog,然后在返回1、
返回值:如果HyperLogLog内部更新了返回1 ,否则返回0
#命令格式: PFADD key element [element ...]
2.PFCOUNT(获取HyperLogLog基数)
描述:PFCOUNT 指令后面可以跟多个key,当PFCOUNT key [key …]命令作用于单个键时,返回存储在给定键的HyperLogLog的近似基数,如果键不存在,则返回0;当PFCOUNT key [key …]命令作用于多个键时,返回所给定HyperLogLog的并集的近似基数,这个近似基数是通过将索引给定HyperLogLog合并至一个临时HyperLogLog来计算得出的。使用PFCOUNT并不是精准的,而是一个带有0.81%标准错误的近似值。
# 命令格式:PFCOUNT key [key …]
3.PFMERGE (合并HyperLogLog)
描述:将多个HyperLogLog合并到一个HyperLogLog中,合并后HyperLogLog的基数接近于所有输入HyperLogLog的可见集合的并集,合并后得到的HyperLogLog会被存储在destkey键里面,如果该键不存在,那么命令在执行之前,会先为该键创建一个空的HyperLogLog。
# 命令格式:PFMERGE destkey sourcekey [sourcekey …]
2.8 脚本命令
redis脚本使用Lua解释器来执行,使用redis脚本,可以一次性将多个请求命令发送出去,以减少网络开销,使用redis脚本可以实现原子操作,redis会将整个脚本作为一个整体去执行,中间不会去执行其他的指令,以此保证原子性,使用redis可以达到复用的目的,所以其他客户端可以复用这个脚本。
1.SCRIPT LOAD(将脚本添加到缓存)
描述:将脚本 script 添加到脚本缓存中,但并不立即执行这个脚本。返回给定script的SHA1校验和
# 命令格式: SCRIPT LOAD script
2.SCRIPT EXISTS (检测指定脚本是否存在)
描述:给定一个或多个脚本的 SHA1 校验和,返回一个包含 0 和 1 的列表,表示校验和所指定的脚本是否已经被保存在缓存当中。
返回值:一个列表,包含 0 和 1 ,前者表示脚本不存在于缓存,后者表示脚本已经在缓存里面了。 列表中的元素和给定的 SHA1 校验和保持对应关系,比如列表的第三个元素的值就表示第三个 SHA1 校验和所指定的脚本在缓存中的状态。
# 命令格式: SCRIPT EXISTS script
3.EVAL(对脚本求值)
描述:从 Redis 2.6.0 版本开始,通过内置的 Lua 解释器,可以使用 EVAL 命令对 Lua 脚本进行求值。
script 参数是一段 Lua 5.1 脚本程序,它会被运行在 Redis 服务器上下文中,这段脚本不必(也不应该)定义为一个 Lua 函数。
numkeys 参数用于指定键名参数的个数。
键名参数 key [key …] 从 EVAL 的第三个参数开始算起,表示在脚本中所用到的那些 Redis 键(key),这些键名参数可以在 Lua 中通过全局变量 KEYS 数组,用 1 为基址的形式访问( KEYS[1] , KEYS[2] ,以此类推)。
在命令的最后,那些不是键名参数的附加参数 arg [arg …] ,可以在 Lua 中通过全局变量 ARGV 数组访问,访问的形式和 KEYS 变量类似( ARGV[1] 、 ARGV[2] ,诸如此类)。
# 命令格式: EVAL script numkeys key [key ...] arg [arg ...]
4.EVALSHA (对缓存中的脚本求值)
描述:根据给定的 sha1 校验码,对缓存在服务器中的脚本进行求值。
将脚本缓存到服务器的操作可以通过 SCRIPT LOAD script 命令进行。
这个命令的其他地方,比如参数的传入方式,都和 EVAL script numkeys key [key …] arg [arg …] 命令一样。
#命令格式:EVALSHA sha1 numkeys key [key …] arg [arg …]
5.SCRIPT KILL(杀掉或清除正在执行的脚本)
描述:杀死当前正在运行的 Lua 脚本,当且仅当这个脚本没有执行过任何写操作时,这个命令才生效。
这个命令主要用于终止运行时间过长的脚本,比如一个因为 BUG 而发生无限 loop 的脚本,诸如此类。
SCRIPT KILL 执行之后,当前正在运行的脚本会被杀死,执行这个脚本的客户端会从 EVAL script numkeys key [key …] arg [arg …] 命令的阻塞当中退出,并收到一个错误作为返回值。
另一方面,假如当前正在运行的脚本已经执行过写操作,那么即使执行 SCRIPT KILL ,也无法将它杀死,因为这是违反 Lua 脚本的原子性执行原则的。在这种情况下,唯一可行的办法是使用 SHUTDOWN NOSAVE 命令,通过停止整个 Redis 进程来停止脚本的运行,并防止不完整(half-written)的信息被写入数据库中。
# 命令格式:SCRIPT KILL
6.SCRIPT FLUSH(清除缓存中的lua脚本)
描述:清除所有 Lua 脚本缓存。
# 命令格式:SCRIPT FLUSH
2.9 客户端与服务器
1.AUTH (账号登录)
描述:
通过设置配置文件中 requirepass 项的值(使用命令 CONFIG SET requirepass password ),可以使用密码来保护 Redis 服务器。
如果开启了密码保护的话,在每次连接 Redis 服务器之后,就要使用 AUTH 命令解锁,解锁之后才能使用其他 Redis 命令。
如果 AUTH 命令给定的密码 password 和配置文件中的密码相符的话,服务器会返回 OK 并开始接受命令输入。
另一方面,假如密码不匹配的话,服务器将返回一个错误,并要求客户端需重新输入密码。
# 命令格式 : AUTH password
2.QUIT(关闭与服务端的连接)
描述:请求服务器关闭与当前客户端的连接。
一旦所有等待中的回复(如果有的话)顺利写入到客户端,连接就会被关闭。
# 命令格式:QUIT
3.INFO (返回服务端信息)
描述:以一种易于解释(parse)且易于阅读的格式,返回关于 Redis 服务器的各种信息和统计数值。
通过给定可选的参数 section ,可以让命令只返回某一部分的信息:
-
server部分记录了 Redis 服务器的信息,它包含以下域:redis_version: Redis 服务器版本redis_git_sha1: Git SHA1redis_git_dirty: Git dirty flagos: Redis 服务器的宿主操作系统arch_bits: 架构(32 或 64 位)multiplexing_api: Redis 所使用的事件处理机制gcc_version: 编译 Redis 时所使用的 GCC 版本process_id: 服务器进程的 PIDrun_id: Redis 服务器的随机标识符(用于 Sentinel 和集群)tcp_port: TCP/IP 监听端口uptime_in_seconds: 自 Redis 服务器启动以来,经过的秒数uptime_in_days: 自 Redis 服务器启动以来,经过的天数lru_clock: 以分钟为单位进行自增的时钟,用于 LRU 管理
-
clients部分记录了已连接客户端的信息,它包含以下域:connected_clients: 已连接客户端的数量(不包括通过从属服务器连接的客户端)client_longest_output_list: 当前连接的客户端当中,最长的输出列表client_longest_input_buf: 当前连接的客户端当中,最大输入缓存blocked_clients: 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
-
memory部分记录了服务器的内存信息,它包含以下域:used_memory: 由 Redis 分配器分配的内存总量,以字节(byte)为单位used_memory_human: 以人类可读的格式返回 Redis 分配的内存总量used_memory_rss: 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和top、ps等命令的输出一致。used_memory_peak: Redis 的内存消耗峰值(以字节为单位)used_memory_peak_human: 以人类可读的格式返回 Redis 的内存消耗峰值used_memory_lua: Lua 引擎所使用的内存大小(以字节为单位)mem_fragmentation_ratio:used_memory_rss和used_memory之间的比率mem_allocator: 在编译时指定的, Redis 所使用的内存分配器。可以是 libc 、 jemalloc 或者 tcmalloc 。
在理想情况下,
used_memory_rss的值应该只比used_memory稍微高一点儿。当
rss > used,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。内存碎片的比率可以通过
mem_fragmentation_ratio的值看出。当
used > rss时,表示 Redis 的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟。Because Redis does not have control over how its allocations are mapped to memory pages, high
used_memory_rssis often the result of a spike in memory usage.当 Redis 释放内存时,分配器可能会,也可能不会,将内存返还给操作系统。
如果 Redis 释放了内存,却没有将内存返还给操作系统,那么
used_memory的值可能和操作系统显示的 Redis 内存占用并不一致。查看
used_memory_peak的值可以验证这种情况是否发生。 -
persistence部分记录了跟RDB持久化和AOF持久化有关的信息,它包含以下域:loading: 一个标志值,记录了服务器是否正在载入持久化文件。rdb_changes_since_last_save: 距离最近一次成功创建持久化文件之后,经过了多少秒。rdb_bgsave_in_progress: 一个标志值,记录了服务器是否正在创建 RDB 文件。rdb_last_save_time: 最近一次成功创建 RDB 文件的 UNIX 时间戳。rdb_last_bgsave_status: 一个标志值,记录了最近一次创建 RDB 文件的结果是成功还是失败。rdb_last_bgsave_time_sec: 记录了最近一次创建 RDB 文件耗费的秒数。rdb_current_bgsave_time_sec: 如果服务器正在创建 RDB 文件,那么这个域记录的就是当前的创建操作已经耗费的秒数。aof_enabled: 一个标志值,记录了 AOF 是否处于打开状态。aof_rewrite_in_progress: 一个标志值,记录了服务器是否正在创建 AOF 文件。aof_rewrite_scheduled: 一个标志值,记录了在 RDB 文件创建完毕之后,是否需要执行预约的 AOF 重写操作。aof_last_rewrite_time_sec: 最近一次创建 AOF 文件耗费的时长。aof_current_rewrite_time_sec: 如果服务器正在创建 AOF 文件,那么这个域记录的就是当前的创建操作已经耗费的秒数。aof_last_bgrewrite_status: 一个标志值,记录了最近一次创建 AOF 文件的结果是成功还是失败。
如果 AOF 持久化功能处于开启状态,那么这个部分还会加上以下域:
aof_current_size: AOF 文件目前的大小。aof_base_size: 服务器启动时或者 AOF 重写最近一次执行之后,AOF 文件的大小。aof_pending_rewrite: 一个标志值,记录了是否有 AOF 重写操作在等待 RDB 文件创建完毕之后执行。aof_buffer_length: AOF 缓冲区的大小。aof_rewrite_buffer_length: AOF 重写缓冲区的大小。aof_pending_bio_fsync: 后台 I/O 队列里面,等待执行的fsync调用数量。aof_delayed_fsync: 被延迟的fsync调用数量。
-
stats部分记录了一般统计信息,它包含以下域:total_connections_received: 服务器已接受的连接请求数量。total_commands_processed: 服务器已执行的命令数量。instantaneous_ops_per_sec: 服务器每秒钟执行的命令数量。rejected_connections: 因为最大客户端数量限制而被拒绝的连接请求数量。expired_keys: 因为过期而被自动删除的数据库键数量。evicted_keys: 因为最大内存容量限制而被驱逐(evict)的键数量。keyspace_hits: 查找数据库键成功的次数。keyspace_misses: 查找数据库键失败的次数。pubsub_channels: 目前被订阅的频道数量。pubsub_patterns: 目前被订阅的模式数量。latest_fork_usec: 最近一次fork()操作耗费的毫秒数。
-
replication: 主/从复制信息role: 如果当前服务器没有在复制任何其他服务器,那么这个域的值就是master;否则的话,这个域的值就是slave。注意,在创建复制链的时候,一个从服务器也可能是另一个服务器的主服务器。
如果当前服务器是一个从服务器的话,那么这个部分还会加上以下域:
master_host: 主服务器的 IP 地址。master_port: 主服务器的 TCP 监听端口号。master_link_status: 复制连接当前的状态,up表示连接正常,down表示连接断开。master_last_io_seconds_ago: 距离最近一次与主服务器进行通信已经过去了多少秒钟。master_sync_in_progress: 一个标志值,记录了主服务器是否正在与这个从服务器进行同步。
如果同步操作正在进行,那么这个部分还会加上以下域:
master_sync_left_bytes: 距离同步完成还缺少多少字节数据。master_sync_last_io_seconds_ago: 距离最近一次因为 SYNC 操作而进行 I/O 已经过去了多少秒。
如果主从服务器之间的连接处于断线状态,那么这个部分还会加上以下域:
master_link_down_since_seconds: 主从服务器连接断开了多少秒。
以下是一些总会出现的域:
connected_slaves: 已连接的从服务器数量。
对于每个从服务器,都会添加以下一行信息:
slaveXXX: ID、IP 地址、端口号、连接状态
-
cpu部分记录了 CPU 的计算量统计信息,它包含以下域:used_cpu_sys: Redis 服务器耗费的系统 CPU 。used_cpu_user: Redis 服务器耗费的用户 CPU 。used_cpu_sys_children: 后台进程耗费的系统 CPU 。used_cpu_user_children: 后台进程耗费的用户 CPU 。
-
commandstats部分记录了各种不同类型的命令的执行统计信息,比如命令执行的次数、命令耗费的 CPU 时间、执行每个命令耗费的平均 CPU 时间等等。对于每种类型的命令,这个部分都会添加一行以下格式的信息:cmdstat_XXX:calls=XXX,usec=XXX,usecpercall=XXX
-
cluster部分记录了和集群有关的信息,它包含以下域:cluster_enabled: 一个标志值,记录集群功能是否已经开启。
-
keyspace部分记录了数据库相关的统计信息,比如数据库的键数量、数据库已经被删除的过期键数量等。对于每个数据库,这个部分都会添加一行以下格式的信息:dbXXX:keys=XXX,expires=XXX
除上面给出的这些值以外, section 参数的值还可以是下面这两个:
all: 返回所有信息default: 返回默认选择的信息
当不带参数直接调用 INFO 命令时,使用 default 作为默认参数。
#命令格式 : info [selection]
4.SHUTDOWN (停止客户端)
SHUTDOWN 命令执行以下操作:
- 停止所有客户端
- 如果有至少一个保存点在等待,执行 SAVE 命令
- 如果 AOF 选项被打开,更新 AOF 文件
- 关闭 redis 服务器(server)
如果持久化被打开的话, SHUTDOWN 命令会保证服务器正常关闭而不丢失任何数据。
另一方面,假如只是单纯地执行 SAVE 命令,然后再执行 QUIT 命令,则没有这一保证 —— 因为在执行 SAVE 之后、执行 QUIT 之前的这段时间中间,其他客户端可能正在和服务器进行通讯,这时如果执行 QUIT 就会造成数据丢失。
SAVE 和 NOSAVE 修饰符
通过使用可选的修饰符,可以修改 SHUTDOWN 命令的表现。比如说:
- 执行
SHUTDOWN SAVE会强制让数据库执行保存操作,即使没有设定(configure)保存点 - 执行
SHUTDOWN NOSAVE会阻止数据库执行保存操作,即使已经设定有一个或多个保存点(你可以将这一用法看作是强制停止服务器的一个假想的 ABORT 命令)
返回值:执行失败时返回错误。 执行成功时不返回任何信息,服务器和客户端的连接断开,客户端自动退出。
# 命令格式:SHUTDOWN [SAVE|NOSAVE]
5.TIME(返回当前服务器时间)
描述:返回当前服务器时间。一个包含两个字符串的列表: 第一个字符串是当前时间(以 UNIX 时间戳格式表示),而第二个字符串是当前这一秒钟已经逝去的微秒数。
# 命令格式: TIME
6.CLIENT GETNAME(返回当前连接的名称)
描述:返回 CLIENT SETNAME 命令为连接设置的名字。
因为新创建的连接默认是没有名字的, 对于没有名字的连接, CLIENT GETNAME 返回空白回复。
返回值 : 如果连接没有设置名字,那么返回空白回复; 如果有设置名字,那么返回名字。
# 命令格式:CLIENT GETNAME
7.CLIENT KILL(关闭指定客户端连接)
描述:关闭地址为 ip:port 的客户端。
ip:port 应该和 CLIENT LIST 命令输出的其中一行匹配。
因为 Redis 使用单线程设计,所以当 Redis 正在执行命令的时候,不会有客户端被断开连接。
如果要被断开连接的客户端正在执行命令,那么当这个命令执行之后,在发送下一个命令的时候,它就会收到一个网络错误,告知它自身的连接已被关闭。
# 命令格式:CLIENT KILL ip:port
8.CLIENT LIST(返回所有服务器连接到客户端的信息)
描述:以人类可读的格式,返回所有连接到服务器的客户端信息和统计数据。
返回值:
命令返回多行字符串,这些字符串按以下形式被格式化:
- 每个已连接客户端对应一行(以
LF分割) - 每行字符串由一系列
属性=值形式的域组成,每个域之间以空格分开
以下是域的含义:
addr: 客户端的地址和端口fd: 套接字所使用的文件描述符age: 以秒计算的已连接时长idle: 以秒计算的空闲时长flags: 客户端 flag (见下文)db: 该客户端正在使用的数据库 IDsub: 已订阅频道的数量psub: 已订阅模式的数量multi: 在事务中被执行的命令数量qbuf: 查询缓冲区的长度(字节为单位,0表示没有分配查询缓冲区)qbuf-free: 查询缓冲区剩余空间的长度(字节为单位,0表示没有剩余空间)obl: 输出缓冲区的长度(字节为单位,0表示没有分配输出缓冲区)oll: 输出列表包含的对象数量(当输出缓冲区没有剩余空间时,命令回复会以字符串对象的形式被入队到这个队列里)omem: 输出缓冲区和输出列表占用的内存总量events: 文件描述符事件(见下文)cmd: 最近一次执行的命令
客户端 flag 可以由以下部分组成:
O: 客户端是 MONITOR 模式下的附属节点(slave)S: 客户端是一般模式下(normal)的附属节点M: 客户端是主节点(master)x: 客户端正在执行事务b: 客户端正在等待阻塞事件i: 客户端正在等待 VM I/O 操作(已废弃)d: 一个受监视(watched)的键已被修改,EXEC命令将失败c: 在将回复完整地写出之后,关闭链接u: 客户端未被阻塞(unblocked)A: 尽可能快地关闭连接N: 未设置任何 flag
文件描述符事件可以是:
r: 客户端套接字(在事件 loop 中)是可读的(readable)w: 客户端套接字(在事件 loop 中)是可写的(writeable)
# 命令格式:CLIENT LIST
9.CLIENT SETNAME (为当前连接分配一个名称)
描述:
以人类可读的格式,返回所有连接到服务器的客户端信息和统计数据。为当前连接分配一个名字。
这个名字会显示在 CLIENT LIST 命令的结果中, 用于识别当前正在与服务器进行连接的客户端。
举个例子, 在使用 Redis 构建队列(queue)时, 可以根据连接负责的任务(role), 为信息生产者(producer)和信息消费者(consumer)分别设置不同的名字。
名字使用 Redis 的字符串类型来保存, 最大可以占用 512 MB 。 另外, 为了避免和 CLIENT LIST 命令的输出格式发生冲突, 名字里不允许使用空格。
要移除一个连接的名字, 可以将连接的名字设为空字符串 “” 。
使用 CLIENT GETNAME 命令可以取出连接的名字。
新创建的连接默认是没有名字的。
设置成功时返回 OK 。
# 命令格式: CLIENT SETNAME connection-name
2.10 配置选项
1.CONFIG SET(动态调整redis服务器配置)
描述:
CONFIG SET 命令可以动态地调整 Redis 服务器的配置(configuration)而无须重启。
你可以使用它修改配置参数,或者改变 Redis 的持久化(Persistence)方式。
CONFIG SET 可以修改的配置参数可以使用命令 CONFIG GET * 来列出,所有被 CONFIG SET 修改的配置参数都会立即生效。
关于 CONFIG SET 命令的更多消息,请参见命令 CONFIG GET 的说明。
返回值:
当设置成功时返回 OK ,否则返回一个错误。
# 命令格式: CONFIG SET parameter value
2.CONFIG GET (获取redis服务器配置)
描述:
CONFIG GET 命令用于取得运行中的 Redis 服务器的配置参数(configuration parameters),在 Redis 2.4 版本中, 有部分参数没有办法用 CONFIG GET 访问,但是在最新的 Redis 2.6 版本中,所有配置参数都已经可以用 CONFIG GET 访问了。
CONFIG GET 接受单个参数 parameter 作为搜索关键字,查找所有匹配的配置参数,其中参数和值以“键-值对”(key-value pairs)的方式排列。
比如执行 CONFIG GET s* 命令,服务器就会返回所有以 s 开头的配置参数及参数的值:
# 命令格式:CONFIG GET parameter
3.CONFIG RESETSTAT(命令统计)
重置 INFO 命令中的某些统计数据,包括:
- Keyspace hits (键空间命中次数)
- Keyspace misses (键空间不命中次数)
- Number of commands processed (执行命令的次数)
- Number of connections received (连接服务器的次数)
- Number of expired keys (过期key的数量)
- Number of rejected connections (被拒绝的连接数量)
- Latest fork(2) time(最后执行 fork(2) 的时间)
- The
aof_delayed_fsynccounter(aof_delayed_fsync计数器的值)
# 命令格式:CONFIG RESETSTAT
4.CONFIG REWRITE(配置文件同步)
描述:
CONFIG REWRITE 命令对启动 Redis 服务器时所指定的 redis.conf 文件进行改写: 因为 CONFIG_SET 命令可以对服务器的当前配置进行修改, 而修改后的配置可能和 redis.conf 文件中所描述的配置不一样, CONFIG REWRITE 的作用就是通过尽可能少的修改, 将服务器当前所使用的配置记录到 redis.conf 文件中。
重写会以非常保守的方式进行:
- 原有
redis.conf文件的整体结构和注释会被尽可能地保留。 - 如果一个选项已经存在于原有
redis.conf文件中 , 那么对该选项的重写会在选项原本所在的位置(行号)上进行。 - 如果一个选项不存在于原有
redis.conf文件中, 并且该选项被设置为默认值, 那么重写程序不会将这个选项添加到重写后的redis.conf文件中。 - 如果一个选项不存在于原有
redis.conf文件中, 并且该选项被设置为非默认值, 那么这个选项将被添加到重写后的redis.conf文件的末尾。 - 未使用的行会被留白。 比如说, 如果你在原有
redis.conf文件上设置了数个关于save选项的参数, 但现在你将这些save参数的一个或全部都关闭了, 那么这些不再使用的参数原本所在的行就会变成空白的。
即使启动服务器时所指定的 redis.conf 文件已经不再存在, CONFIG REWRITE 命令也可以重新构建并生成出一个新的 redis.conf 文件。
另一方面, 如果启动服务器时没有载入 redis.conf 文件, 那么执行 CONFIG REWRITE 命令将引发一个错误。
原子性重写
对 redis.conf 文件的重写是原子性的, 并且是一致的: 如果重写出错或重写期间服务器崩溃, 那么重写失败, 原有 redis.conf 文件不会被修改。 如果重写成功, 那么 redis.conf 文件为重写后的新文件。
返回值
一个状态值:如果配置重写成功则返回 OK ,失败则返回一个错误。
代码示例
以下是执行 CONFIG REWRITE 前, 被载入到 Redis 服务器的 redis.conf 文件中关于 appendonly 选项的设置:
2.11 复制
1.SYNC(命令)
描述:用于复制功能(replication)的内部命令。
# 命令格式:SYNC
2.SLAVEOF(修改复制)
描述:SLAVEOF 命令用于在 Redis 运行时动态地修改复制(replication)功能的行为。
通过执行 SLAVEOF host port 命令,可以将当前服务器转变为指定服务器的从属服务器(slave server)。
如果当前服务器已经是某个主服务器(master server)的从属服务器,那么执行 SLAVEOF host port 将使当前服务器停止对旧主服务器的同步,丢弃旧数据集,转而开始对新主服务器进行同步。
另外,对一个从属服务器执行命令 SLAVEOF NO ONE 将使得这个从属服务器关闭复制功能,并从从属服务器转变回主服务器,原来同步所得的数据集不会被丢弃。
利用“SLAVEOF NO ONE 不会丢弃同步所得数据集”这个特性,可以在主服务器失败的时候,将从属服务器用作新的主服务器,从而实现无间断运行。
成功返回ok
# 命令格式:SLAVEOF
3.ROLE(查看主从角色)
描述:返回实例在复制中担任的角色, 这个角色可以是 master 、 slave 或者 sentinel 。 除了角色之外, 命令还会返回与该角色相关的其他信息, 其中:
- 主服务器将返回属下从服务器的 IP 地址和端口。
- 从服务器将返回自己正在复制的主服务器的 IP 地址、端口、连接状态以及复制偏移量。
- Sentinel 将返回自己正在监视的主服务器列表。
# 命令格式:ROLE
4.SYNC(用于复制功能)
描述:用于复制功能(replication)的内部命令。
# 命令格式:SYNC
5.PSYNC(用于复制功能)
描述:用于复制功能(replication)的内部命令。
# 命令格式:PSYNC master_run_id offset
2.12 调试
1.PING(测试连通性)
描述:使用客户端向 Redis 服务器发送一个 PING ,如果服务器运作正常的话,会返回一个 PONG 。
通常用于测试与服务器的连接是否仍然生效,或者用于测量延迟值。
# 命令格式:PING
2.ECHO (打印信息)
描述:打印一个特定的信息 message ,测试时使用。
# 命令格式:ECHO
3.SLOWLOG(查看日志)
描述:
什么是 SLOWLOG?
Slow log 是 Redis 用来记录查询执行时间的日志系统。
查询执行时间指的是不包括像客户端响应(talking)、发送回复等 IO 操作,而单单是执行一个查询命令所耗费的时间。
另外,slow log 保存在内存里面,读写速度非常快,因此你可以放心地使用它,不必担心因为开启 slow log 而损害 Redis 的速度。
设置 SLOWLOG
Slow log 的行为由两个配置参数(configuration parameter)指定,可以通过改写 redis.conf 文件或者用 CONFIG GET 和 CONFIG SET 命令对它们动态地进行修改。
第一个选项是 slowlog-log-slower-than ,它决定要对执行时间大于多少微秒(microsecond,1秒 = 1,000,000 微秒)的查询进行记录。
比如执行以下命令将让 slow log 记录所有查询时间大于等于 100 微秒的查询:
CONFIG SET slowlog-log-slower-than 100
而以下命令记录所有查询时间大于 1000 微秒的查询:
CONFIG SET slowlog-log-slower-than 1000
另一个选项是 slowlog-max-len ,它决定 slow log 最多能保存多少条日志, slow log 本身是一个 FIFO 队列,当队列大小超过 slowlog-max-len 时,最旧的一条日志将被删除,而最新的一条日志加入到 slow log ,以此类推。
以下命令让 slow log 最多保存 1000 条日志:
CONFIG SET slowlog-max-len 1000
使用 CONFIG GET 命令可以查询两个选项的当前值:
查看 slow log
要查看 slow log ,可以使用 SLOWLOG GET 或者 SLOWLOG GET number 命令,前者打印所有 slow log ,最大长度取决于 slowlog-max-len 选项的值,而 SLOWLOG GET number 则只打印指定数量的日志。
日志的唯一 id 只有在 Redis 服务器重启的时候才会重置,这样可以避免对日志的重复处理(比如你可能会想在每次发现新的慢查询时发邮件通知你)。
查看当前日志的数量
使用命令 SLOWLOG LEN 可以查看当前日志的数量。
请注意这个值和 slower-max-len 的区别,它们一个是当前日志的数量,一个是允许记录的最大日志的数量。
清空日志
使用命令 SLOWLOG RESET 可以清空 slow log 。
# 命令格式:SLOWLOG subcommand [argument]
4.MONITOR(实时打印接收命令)
描述:实时打印出 Redis 服务器接收到的命令,调试用。
# 命令格式: MONITOR
5.DEBUG SEGFAULT(让 Redis 崩溃)
描述:执行一个不合法的内存访问从而让 Redis 崩溃,仅在开发时用于 BUG 模拟。
# 命令格式: DEBUG SEGFAULT
5.DEBUG OBJECT(查看key相关信息)
描述:当 key 存在时,返回有关信息。 当 key 不存在时,返回一个错误。
# 命令格式:DEBUG OBJECT key
3.redis五种数据类型
-
String(字符串)
- string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
- string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
- string类型是Redis最基本的数据类型,一个redis中字符串value最多可以是512M
-
Hash(哈希,类似java里的Map)
- Redis hash 是一个键值对集合。
- Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
- 类似Java里面的Map
-
List(列表)
- Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)。
- 它的底层实际是个链表
-
Set(集合)
- Redis的Set是string类型的无序集合。它是通过HashTable实现实现的
- Zset(sorted set:有序集合)
- Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
- 不同的是每个元素都会关联一个double类型的分数。
- redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。
-
Sorted Set
- Redis的Sorted Set是string类型的有序集合。但是原生可以重复
- 每个元素对应一个double类型的分数,redis就是通过这个对应的分数来进行从小到大排序的
- 有序集合采用hash表实现,增加,删除,查询,效率特别高,复杂度为o(1)
- 能存储的最大元素个数是 2^32-1个元素
3.1 String 类型
字符串是redis中最基本的数据类型,他是二进制安全的任何形式的字符串都可以存储,包括二进制数据,序列化后的数据,JSON对象,甚至是一张base64编码后的图片,String类型的键最大能存储512KB的数据。string类型的数据也是开发中使用频率最高的,我们来看下基础的一些操作。
| 命令 | 描述 |
|---|---|
| SET key value [EX seconds|PX milliseconds] [NX|XX] [KEEPTTL] | 设置指定key的value 。EX:设置key的过期时间为多少秒,PX:设置key的过期时间为多少毫秒,NX:当key不存在时,才对key进行操作,XX当key存在时才对其进行操作 |
| GET key | 获取指定key的value |
| append key value | 往指定key中添加字符串 |
| MGET key1 [key2…] | 获取所有(一个或多个)给定 key 的值,这个命令是原子性的,所有的key都会在同一时间内更新 |
| SETNX key value | 只有在 key 不存在时设置 key 的值 |
| STRLEN key | 返回 key 所储存的字符串值的长度 |
| APPEND key value | 如果 key 已经存在并且是一个字符串, APPEND 命令将指定的 value 追加到该 key 原来值(value)的末尾 |
| DECRBY key decrement | key 所储存的值减去给定的减量值(decrement) |
| INCRBY key increment | 将 key 所储存的值加上给定的增量值(increment) |
| DECR key | 将 key 中储存的数字值减一 |
| INCR key | 将 key 中储存的数字值增一 |
| INCRBY key increment | 将key存储的value增量increment,如果key不存在,被初始化为0,INCRBY操作的值在64位(bit)的有符号表示范围内 |
| INCRBYFLOAT key increment | 将 key 所储存的值加上给定的浮点增量值(increment) |
| DECRFLOAT key | 将 key 所储存的值减去给定的浮点减量值(increment) |
| MSETNX key value [key value …] | 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在 |
| GETRANGE key start end | 获取键的子字符串值,start从0开始,end取负值的时候,-1表示最后一个字符串,-2表示倒数第二个字符串 |
| SETRANGE key offset value | 从指定的位置(offset)开始,将key值替换为新的字符串 |
| SETBIT key offset value | 指定所存储的字符串值设置或清除指定偏移量上的位,value为 1 或 0,offset设置的值必须大于或等于0,如果其他位没有设置。默认填充为0,大小限制为 512MB,offset的范围是 2^32 |
| GETBIT key offset | 获取键的偏移量值 |
| BITCOUNT key [start end] | 统计位图中位为1的数量,start表示起始位置,end表示结束位置,如果没有指定start和end,那么表示统计整个bit标志位为1的数量 |
| SETEX key seconds value | setex是一个原子性的命令,他设置value和设置生存时间是在同一时间完成的。seconds:秒 |
| PSETEX key milliseconds value | 设置键值对的同时,指定过期时间。milliseconds:毫秒 |
| GETSET key value | 为指定建设置新的value,并且返回原来的value |
| BITOP operation destkey key [key …] | 对一个保存二进制位的字符串进行位运算,operation可以是:AND(求逻辑并),OR(求逻辑或),NOT(求逻辑非),XOR(求逻辑异或),计算完毕后将结果保存到destkey中,返回保存到destkey中的字符串长度 |
3.2 HASH 类型
redis类型的hash是一个string类型的域和值映射表,hash类型常常用于存储对象类型的数据每个hash表可以存储2^32-1个键值对,也就是40多亿的一个数据。
| 命令 | 描述 |
|---|---|
| HSET key field value [field value …] | 使用HEST命令将哈希表key中的filed的值设置为value,当这个key不存在时,将会创建一个新的hash表进行HSET操作,如果key已经存在,那么就进行覆盖 |
| HGET key field | 获取哈希表key中的filed值 |
| HSETNX key field value | 使用HSETNX命令相当于filed不存在时,会将哈希表中filed的值设置为value,如果已经存在,那么这个命令无效。 |
| HGETALL key | 获取hash表中所有的filed和值,此时哈希表返回的长度是哈希表长度的两倍,如果这个key不存在,返回空列表 |
| HMGET key field [field …] | 获取指定哈希表的多个字段值,如果key不存在将会当做空哈希表返回nil,如果指定filed不存在,也会返回nil |
| HKEYS key | 获取指定hash表的所有filed |
| HVALS key | 获取哈希表中所有的value |
| HLEN key | 统计哈希表中所有的filed数量 |
| HSTRLEN key field | 统计哈希表中某个filed的字符串长度 |
| HINCRBY key field increment | 为哈希表中的filed增减一个increment值,increment可以是一个负整数,也可以是一个正整数,负数代表减,正数代表增加,如果key不存在创建一个新的哈希表,如果filed不存在,新建一个filed,并且初始化为0,继续执行HINCRBY操作,返回执行完HINCRBY的值 |
| HINCRBYFLOAT key field increment | 为哈希表中的filed增减一个increment值,increment可以是一个负浮点数,也可以是一个正浮点数,负浮点数代表减,正浮点数代表增加,如果key不存在创建一个新的哈希表,如果filed不存在,新建一个filed,并且初始化为0,继续执行HINCRBY操作,返回执行完HINCRBY的值 |
| HDEL key field [field …] | 删除哈希表中的filed,可以指定多个filed进行同时删除 |
| HEXISTS key field | 检测哈希表中是否有这个filed,有的话返回1,没有的话返回0 |
3.3 list 数据类型
redis的list可以看成一个简单的字符串列表,按照插入顺序进行排序,添加的时候可以从头部添加或尾部添加,也可以看成是一个简单的队列,一个列表大约可以存放2^32-1个元素。
| 命令 | 描述 |
|---|---|
| LPUSH key element [element …] | 将多个value按照顺序插入到列表头部,如果key不存在,则创建一个新的列表然后进行插入 |
| RPUSH key element [element …] | 将多个value按照顺序插入到列表尾部,如果key不存在,则创建一个新的列表然后进行插入 |
| LINSERT key BEFORE|AFTER pivot element | 向列表中插入一个值,可以是在pivot之前或之后,key不存在时,列表无效 |
| LPUSHX key element [element …] | 将一个value插入到列表头部,此时key必须存在 |
| RPUSHX key element [element …] | 将一个value插入到列表尾部部,此时key必须存在 |
| LSET key index element | 修改列表指定索引位置的元素,索引从0开始,如果key为空则返回错误 |
| LLEN key | 统计列表的长度 |
| LINDEX key index | 获取指定列表索引位置的元素,ndex为0表示第一个元素,index为-1表示最后一个元素。为-2表示倒数第二个 |
| LRANGE key start stop | 获取指定列表范围内的元素,start为0表示第一个元素,stop为-1表示最后一个元素。为-2表示倒数第二个 |
| LPOP key | 返回并删除列表头部元素 |
| RPOP key | 返回并删除列表尾部元素 |
| BRPOP key [key …] timeout | 在指定时间内删除列表的尾部元素,时间单位为秒,当这个列表内没有可删除的元素时,该命令会阻塞,一直等到有可删除的元素为止 |
| BLPOP key [key …] timeout | 在指定时间内删除列表的头部元素,时间单位为秒,当这个列表内没有可删除的元素时,该命令会阻塞,一直等到有可删除的元素为止 |
| LREM key count value | 根据count参数删除列表中与指定value相等的元素,如果count=0:删除列表中所有与指定value相同的元素,count>0:从列表头部开始搜索删除列表中所有与指定value相同的元素,count<0:从列表尾部开始搜索删除列表中所有与指定value相同的元素 |
| LTRIM key start stop | 表示对一个列表进行修剪,比如去掉不必要的空格,让列表key值保留指定区间内的元素,不在这个区间内的元素会被删除,start和stop的值超出列表长度位置不会出现错误,如果参数strt比stop大,那么将会清空整个列表,如果stop比整个列表的值还大,那么redis会将这个stop作为这个列表的最大下标值 |
| RPOPLPUSH source destination | 将元素移动到另外一个列中,这个操作是原子性的,会将source中的最后一个元素作为返回值,这个被返回的元素会被插入到destination的头部,当source不存在的时候,将会返回一个nil值,同时后面的操作不执行,如果source和destination是同一个列表,那么列表尾元素将会移动到头部,并且返回该元素,这就是列表的旋转操作 |
| BRPOPLPUSH source destination timeout | 将元素移动到另外一个列中,timeout单位为秒,如果设置为0表示阻塞时间可以无限延长,如果在指定时间内没有任何元素被弹出,则返回nil和等待时长,如果返回的是一个列表,那么列表中的第一个元素是被弹出元素的值,第二个元素是等待时长 |
队列安全:
有时候list经常被看成一个队列来使用,用于在不同程序中进行传输消息,一个客户端通过LPUSH的命令将消息放到列表中,然后另外一个程序通过RPOP或BRPOP命令将元素取出使用,但是这个会容易出现消息丢失的情况,消息被一个客户端取走,但是他未能正确的处理掉这条消息,然后就宕机了,此时消息已经被消费掉,这个消息就丢失掉了。我们可以使用RPOPLPUSH 命令来解决,可以把元素放到一个备份列表,当取出的客户端正常处理完流程,我们在备份列表中删除就可以了,这样就可以避免消息丢失的情况。
循环列表:
我们可以使用RPOPLPUSH 实现循环链表,使用相同的key作为RPOPLPUSH 的参数,客户端采用逐个获取元素列表的方式,取出队列中的元素,这样就避免掉了使用LRANGE命令那样取出列表中所有的元素,当有多哥客户端对同一个列表进行旋转操作来获取不同的元素,直到所有的元素被取完,这个循环列表可以正常工作,还有客户端向列表尾部添加新元素时,这个列表也能正常工作。
基于以上的两种操作,我们可以借助redis服务监控系统,在事项短时间内不断处理一些消息。
3.4 set 数据类型
redis的数据类型集合set是string类型的无需集合。集合中的元素无序且不重复,每个元素都是唯一的,集合通过hash表来实现的,所以使用集合进行增加,删除,查询操作的效率都是特别高的,复杂度为O(1),一个集合能存储的最大数据容量为 2^32-1个元素。
| 命令 | 描述 |
|---|---|
| SADD key member [member …] | 将一个或多个元素添加到这个集合中,如果这个集合中已经存在这个元素,那么这个元素将会被忽略掉,如果key集合不存在,那么就创建一个集合,这个集合只包含这里设置menber元素 |
| SMOVE source destination member | 移动集合元素到另一个集合中,静集合source红的member元素移动到destination中,如果集合source不存在,或者source集合中不存在member元素,则smove命令不会生效,将返回0。如果destination集合中已经包含member元素,那么只会删除掉source中的member,并不会去移动,如果移动成功返回1,移动失败返回0 |
| SUNIONSTORE destination key [key …] | 将多个集合保存到另一个集合中,最终是取这些多个集合的交集然后存储到destination集合中,如果存储成功,返回destination的长度 |
| SISMEMBER key member | 判断某个元素是否存储在集合中,如果存在,则返回1,不存在返回0 |
| SCARD key | 获取集合中元素的数量 |
| SMEMBERS key | 获取集合中所有的元素 |
| SRANDMEMBER key [count] | 随机返回集合中的元素,如果不指定count,那么随机返回集合中的一个元素,如果指定的是一个正整数并且小于集合的基数,则返回一个列表,如果指定的是一个负整数,返回的元素可能是一个重复多次的数组,这个数组的长度是count的绝对值 |
| SUNION key [key …] | 获取多个集合中的元素,返回的是所有key集合的并集,如果集合key不存在当做空集进行处理 |
| SDIFF key [key …] | 获取多个集合的并集,该集合是给定集合之间的差集,集合key不存在就视为是空集合 |
| SDIFFSTORE destination key [key …] | 获取多个集合差集的元素个数,将获取到的元素保存到destination中,这个集合是给定的多个集合key元素的差集,如果集合destination已经存在,则会被新的集合覆盖,如果给定key集合是一个不是多个,那么这个destination集合就是给定的集合key本身 |
| SINTER key [key …] | 获取多个集合元素的交集,如果给定的多个指定集合key中有一个是空集合,那么执行该命令的结果就是一个空集合 |
| SINTERSTORE destination key [key …] | 获取多个集合交集的元素个数,获取给定的集合key的所有元素,保存到destination中,如果destination已经存在则会被覆盖掉,执行完毕后返回destination中的成员数量 |
| SPOP key [count] | 随机删除集合中的一个或多个元素,如果是一个空集合返回nil |
| SREM key member[ member …] | 删除集合key中的一个或多个元素,该命令在执行过程中,会忽略掉不存在的member元素,如果key不是集合类型,则返回错误信息 |
3.5 sorted set 数据类型
redis的数据类型有序集合 sorte也是string类型的集合,有序集合中不存在重复的元素,每个解中的每个元素都对应一个double的分数,redis就是通过这个元素对应的分数来进行大到小的排序,集合中的元素是唯一的,但是元素的分数不是唯一的,可以重复。
有序几个采用hash表事项,当面对增加,删除,查询,操作的时候。时间复杂度为O(1)有序集合所能存储的元素最大个数是 2^32-1个。
| 命令 | 描述/ |
|---|---|
| ZADD key [NX|XX] [CH] [INCR] score member [score member …] | 将一个或读个元素添加到集合中,如果集合中已经存在某个member。那么只需要更新改member的score值,然后重新插入member,以此来确保member元素在正确的位置上。socre可以是一个整数也可以是一个浮点数,添加完毕后返回添加成功的元素数量 |
| ZINCRBY key increment member | 给指定key集合的member元素增加increment分数,increment如果是正数那么就加上对应的分数,如果是负数就减去对应的分数,如果指定的key不存在,则该命令等价于ZADD key increment member |
| ZCARD key | 获取指定key集合中元素的个数,当key不存在时返回0 |
| ZCOUNT key min max | 获取score值在 min-max直接的元素(默认包含score等于min或max) |
| ZLEXCOUNT key min max | 获取指定key集合 source在 min-max之间的元素数量,其中(:表示开区间,[表示闭区间 |
| ZRANGE key start stop [WITHSCORES] | 获取指定区间内的元素(升序),返回的元素按照score从小到大进行排列,start 从0开始,stop -1表示最后一个元素,-2表示倒数第二个元素,超出集合下标范围内集合不会出现错误,当start的值大于stop的值的时候,什么也不做,返回一个空集合,如果stop大于集合的最大下标时,redis会将这个值作为集合的新下标,可以使用WITHSCORES来选择是否返回对应的分数 |
| ZREVRANGE key start stop [WITHSCORES] | 反会指定key集合中区间内的元素,返回的元素按照score从大到小进行排列,start 从0开始,stop -1表示最后一个元素,-2表示倒数第二个元素,超出集合下标范围内集合不会出现错误,当start的值大于stop的值的时候,什么也不做,返回一个空集合,如果stop大于集合的最大下标时,redis会将这个值作为集合的新下标,可以使用WITHSCORES来选择是否返回对应的分数 |
| ZSCORE key member | 获取集合中指定member的score,如果集合中的member不存在则返回nil |
| ZRANGEBYLEX key min max [LIMIT offset count] | 返回指定key集合中score在min-max之间的元素,1.分数必须相同! 如果有序集合中的成员分数有不一致的,返回的结果就不准。 2.成员字符串作为二进制数组的字节数进行比较。 3.默认是以ASCII字符集的顺序进行排列。如果成员字符串包含utf-8这类字符集(比如:汉字)的内容,就会影响返回结果,所以建议不要使用。 4.默认情况下, “max” 和 “min” 参数前必须加 “[” 符号作为开头。”[” 符号与成员之间不能有空格, 返回成员结果集会包含参数 “min” 和 “max” 。 5.“max” 和 “min” 参数前可以加 “(” 符号作为开头表示小于, “(” 符号与成员之间不能有空格。返回成员结果集不会包含 “max” 和 “min” 成员。 可以使用 “-” 和 “+” 表示得分最小值和最大值 |
| ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] | 返回指定key集合中score在min-max之间的元素,集合中的元素按照score值从小到大进行排序,当你不知道min和max的具体参数时,可以使用 -inf表示最小值,+inf表示最大值,也可以在参数前面加上 ( 表示开区间,(默认是闭区间),当具有相同score的元素时,有序集合元素会按照字典进行排序,可以添加参数 WITHSCORES来表示需要返回分数 |
| ZRANK key member | 获取集合key中member的排名,集合会按照从小到大进行排序,score最小的元素排名为0 |
| ZREVRANK key member | 获取集合key中member的排名,集合会按照从大到小进行排序,score最大的元素排名为0 |
| ZINTERSTORE destination numkeys key [key …] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX] | 用于计算给定一个key或多个key的交集,其中给定key的数量必须和numkeys相等,在默认情况下交集结果的某个元素的score的值是给定所有集合中的该元素的score值之和,计算结果为destination集合中元素的数量 |
| ZUNIONSTORE destination numkeys key [key …] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX] | 用于计算给定一个key或多个key的并集,其中给定key的数量必须和numkeys相等,在默认情况下交集结果的某个元素的score的值是给定所有集合中的该元素的score值之和,计算结果为destination集合中元素的数量。使用WEIGHTS可以给所有的集合指定一个乘数,每个集合的所有元素的score在攒底给聚合函数的时候,都会乘以这个数(weight),如果没有指定,默认为1。AGGREGATE的选项:SUM:将所有有序集合中某个元素的score值作为结果集中该元素的score,MIN:这种聚合方式可以将所有集合中某个元素的最小score值作为结果集中该元素的score,MAX:这种聚合方式可以将所有集合中某个元素的最大score值作为结果集中该元素的score |
| ZREM key member [member …] | 删除有序集合中的多个元素,返回删除成功的元素数量 |
| ZREMRANGEBYLEX key min max | 删除集合中 score的值介于 min-max之间score值相同的元素 |
| ZREMRANGEBYRANK key start stop | 删除有序集合在指定排名区间内的元素,start表示开始排名。stop表示结束排名,其中包含start和stop |
| ZREMRANGEBYSCORE key min max | 删除有序集合key中,所有score值介于min到max之间的元素(包含min和max),返回被删除的元素数量 |
4.redis数据库
4.1 redis数据库的切换
redis数据库保存在redis服务器状态server.sh/redosServer结构db数组中,这个数组中的每个元素都是一个server.sh/redosServer结构,而每个redisDb结构就代表一个数据库。
Redis服务器状态有一个dbnum属性,该属性用于在启动redis服务器时,决定创建多少个数据库。redis服务器的database选项决定了dbnum属性的值,在默认的情况下,dbnum的值为16,也就是redis在启动redis服务器的时候,会创建(0-15)个数据库,我们可以通过select index 的方式来进行选择操作具体的某个数据库,index的取值范围默认是(0-15)

在redis服务器内部,有一个db属性,这个属性是客户端状态redisClient中的属性,他是一个执行redisDb结构的指针,用于记录当前客户端操作的目标数据库,redisClient.db指针指向redisServer.db数组中的某个元素,增被指向的元素就是客户端的目标数据库,我们在启动redis服务器与客户端时,默认的目标数据库是0号,这个客户端指向的也是0号数据库。

4.2 redis删除策略
4.2.1 定期删除策略
概念:在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来临时,立即执行对键的删除操作。(创建定时器删除)
优点:
- 对内存最友好:通过使用定时器,可以保证过期的键会尽可能快地被删除,释放所占内存
缺点:
- 对cpu最不友好:在过期键比较多的情况下,删除过期键这一行为可能会占用相当一部分cpu的时间,对服务器的响应时间和吞吐量造成影响。
4.2.2 惰性删除策略
概念:放任键的过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。(使用的时候删除)
优点:
- 对cpu最友好:只有在取出键的时候才会对过期键进行检查,即不需要cpu定期扫描,也不需要创建大量的定时器。
缺点:
- 对内存最不友好:如果一个键已经过期,但是后面不会被访问到的话,那么就一直保留在数据库中。如果这样的键过多,无疑会占用很大的内存。
4.2.3 定期删除策略
概念:每隔一段时间,程序就对数据库进行一次检查,删除里面过期的键。至于要删除多少过期键,以及要检查多少个数据库,则有算法决定。(定期扫描删除)
优点:
- 定期删除每隔一段时间执行一次过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对cpu时间的影响;
- 通过删除过期键,能有效的减少因为过期键而带来的内存浪费
缺点:难以确定删除操作执行的时长和频率
- 如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成定时删除,以至于占用太多cpu的执行时间;
- 如果删除操作执行的时间太少,或执行时间太短,定期删除策略又会和惰性删除一样,出现内存浪费。
4.2.4 Redis过期删除策略
redis实际使用的过期键删除策略是定期删除策略和惰性删除策略:
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定时遍历这个字典来删除到期的 key。除了定时遍历之外,它还会使用惰性策略来删除过期的 key,所谓惰性策略就是在客户端访问这个 key 的时候,redis 对 key 的过期时间进行检查,如果过期了就立即删除。定时删除是集中处理,惰性删除是零散处理。
通过配合使用这两种删除策略,服务器可以很好地合理使用cpu时间和避免浪费内存空间之间取得平衡。
4.2.4.1 定期删除
Redis 默认会每秒进行十次过期扫描,过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
- 从过期字典中随机 20 个 key;
- 删除这 20 个 key 中已经过期的 key;
- 如果过期的 key 比率超过 1/4,那就重复步骤 1;
同时,为了保证过期扫描不会出现循环过度,导致线程卡死现象,算法还增加了扫描时间的上限,默认不会超过 25ms。
如果某一时刻,有大量key同时过期,Redis 会持续扫描过期字典,造成客户端响应卡顿,因此设置过期时间时,就尽量避免这个问题,在设置过期时间时,可以给过期时间设置一个随机范围,避免同一时刻过期。
a. 如何配置定期删除执行时间间隔
redis的定时任务默认是每秒执行10次,如果要修改这个值,可以在redis.conf中修改hz的值。
redis.conf中,hz默认设为10,提高它的值将会占用更多的cpu,当然相应的redis将会更快的处理同时到期的许多key,以及更精确的去处理超时。 hz的取值范围是1~500,通常不建议超过100,只有在请求延时非常低的情况下可以将值提升到100。
b. 单线程的redis,如何知道要运行定时任务?
redis是单线程的,线程不但要处理定时任务,还要处理客户端请求,线程不能阻塞在定时任务或处理客户端请求上,那么,redis是如何知道何时该运行定时任务的呢?
Redis 的定时任务会记录在一个称为最小堆的数据结构中。这个堆中,最快要执行的任务排在堆的最上方。在每个循环周期,Redis 都会将最小堆里面已经到点的任务立即进行处理。处理完毕后,将最快要执行的任务还需要的时间记录下来,这个时间就是接下来处理客户端请求的最大时长,若达到了该时长,则暂时不处理客户端请求而去运行定时任务。
4.2.4.2 懒惰删除
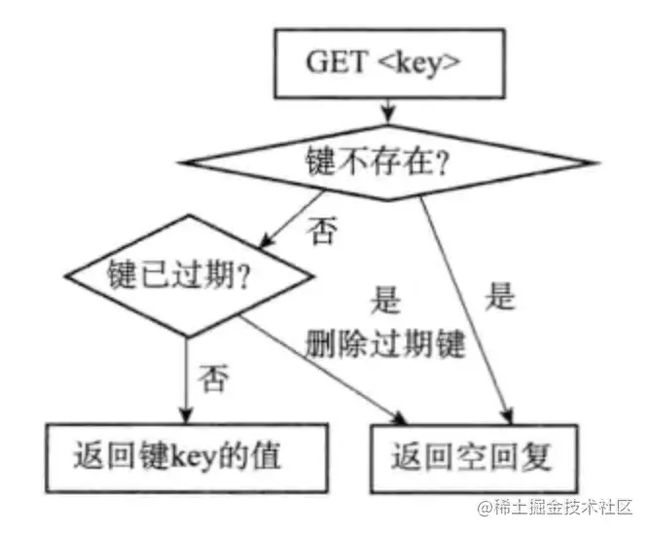
过期键的惰性删除删除策略由db.c/expireIfNeeded函数实现,所有读写数据库的Redis命令在执行之前都会调用expireIfNeed函数对输入键进行检查:
- 如果键已经过期,那么expireIfNeeded函数将键删除
- 如果键未过期,那么expireIfNeeded函数不做操作
命令调用expireIfNeeded函数过程如下图

另外因为每个被访问的键都可能被删除,所以每个命令都必须能同时处理键存在以及不存在的情况。 下图表示get命令的执行过程
4.2.4.3 aof/rdb和复制功能对过期键的处理
rdb
- 生成rdb文件:生成时,程序会对键进行检查,过期键不放入rdb文件。
- 载入rdb文件:载入时,如果以主服务器模式运行,程序会对文件中保存的键进行检查,未过期的键会被载入到数据库中,而过期键则会忽略;如果以从服务器模式运行,无论键过期与否,均会载入数据库中,过期键会通过与主服务器同步而删除。
aof
- 当服务器以aof持久化模式运行时,如果数据库中的某个键已经过期,但它还没有被删除,那么aof文件不会因为这个过期键而产生任何影响;当过期键被删除后,程序会向aof文件追加一条del命令来显式记录该键已被删除。
- aof重写过程中,程序会对数据库中的键进行检查,已过期的键不会被保存到重写后的aof文件中。
复制
当服务器运行在复制模式下时,从服务器的过期删除动作由主服务器控制:
- 主服务器在删除一个过期键后,会显式地向所有从服务器发送一个del命令,告知从服务器删除这个过期键;
- 从服务器在执行客户端发送的读命令时,即使碰到过期键也不会将过期键删除,而是继续像处理未过期的键一样来处理过期键;
- 从服务器只有在接到主服务器发来的del命令后,才会删除过期键。
4.3 redis数据库通知
1.事件描述
键空间通知使得客户端可以通过订阅频道或模式, 来接收那些以某种方式改动了 Redis 数据集的事件。
以下是一些键空间通知发送的事件的例子:
- 所有修改键的命令。
- 所有接收到 [LPUSH key value value …] 命令的键。
0号数据库中所有已过期的键。
事件通过 Redis 的订阅与发布功能(pub/sub)来进行分发, 因此所有支持订阅与发布功能的客户端都可以在无须做任何修改的情况下, 直接使用键空间通知功能。
因为 Redis 目前的订阅与发布功能采取的是发送即忘(fire and forget)策略, 所以如果你的程序需要可靠事件通知(reliable notification of events), 那么目前的键空间通知可能并不适合你: 当订阅事件的客户端断线时, 它会丢失所有在断线期间分发给它的事件。
未来将会支持更可靠的事件分发, 这种支持可能会通过让订阅与发布功能本身变得更可靠来实现, 也可能会在 Lua 脚本中对消息(message)的订阅与发布进行监听, 从而实现类似将事件推入到列表这样的操作。
2.事件的类型
对于每个修改数据库的操作,键空间通知都会发送两种不同类型的事件。分别是键空间通知和键事件通知。
比如说,对 0 号数据库的键 mykey 执行 [DEL key key …] 命令时, 系统将分发两条消息, 相当于执行以下两个 PUBLISH channel message 命令:
PUBLISH __keyspace@0__:mykey del
PUBLISH __keyevent@0__:del mykey
订阅第一个频道 __keyspace@0__:mykey 可以接收 0 号数据库中所有修改键 mykey 的事件, 而订阅第二个频道 __keyevent@0__:del 则可以接收 0 号数据库中所有执行 del 命令的键。
以 keyspace 为前缀的频道被称为键空间通知(key-space notification), 而以 keyevent 为前缀的频道则被称为键事件通知(key-event notification)。
当 del mykey 命令执行时:
- 键空间频道的订阅者将接收到被执行的事件的名字,在这个例子中,就是
del。 - 键事件频道的订阅者将接收到被执行事件的键的名字,在这个例子中,就是
mykey。
3.配置
因为开启键空间通知功能需要消耗一些 CPU , 所以在默认配置下, 该功能处于关闭状态。
可以通过修改 redis.conf 文件, 或者直接使用 CONFIG SET 命令来开启或关闭键空间通知功能:
- 当
notify-keyspace-events选项的参数为空字符串时,功能关闭。 - 另一方面,当参数不是空字符串时,功能开启。
notify-keyspace-events 的参数可以是以下字符的任意组合, 它指定了服务器该发送哪些类型的通知:
| 字符 | 发送的通知 |
|---|---|
K |
键空间通知,所有通知以 __keyspace@ 为前缀 |
E |
键事件通知,所有通知以 __keyevent@ 为前缀 |
g |
DEL 、 EXPIRE 、 RENAME 等类型无关的通用命令的通知 |
$ |
字符串命令的通知 |
l |
列表命令的通知 |
s |
集合命令的通知 |
h |
哈希命令的通知 |
z |
有序集合命令的通知 |
x |
过期事件:每当有过期键被删除时发送 |
e |
驱逐(evict)事件:每当有键因为 maxmemory 政策而被删除时发送 |
A |
参数 g$lshzxe 的别名 |
输入的参数中至少要有一个 K 或者 E , 否则的话, 不管其余的参数是什么, 都不会有任何通知被分发。
举个例子, 如果只想订阅键空间中和列表相关的通知, 那么参数就应该设为 Kl , 诸如此类。
将参数设为字符串 "AKE" 表示发送所有类型的通知。
4.命令产生的通知
以下列表记录了不同命令所产生的不同通知:
- [DEL key key …] 命令为每个被删除的键产生一个
del通知。 - RENAME key newkey 产生两个通知:为来源键(source key)产生一个
rename_from通知,并为目标键(destination key)产生一个rename_to通知。 - EXPIRE key seconds 和 EXPIREAT key timestamp 在键被正确设置过期时间时产生一个
expire通知。当 EXPIREAT key timestamp 设置的时间已经过期,或者 EXPIRE key seconds 传入的时间为负数值时,键被删除,并产生一个del通知。 - [SORT key BY pattern] [LIMIT offset count] [GET pattern [GET pattern …]] [ASC | DESC] [ALPHA] [STORE destination] 在命令带有
STORE参数时产生一个sortstore事件。如果STORE指示的用于保存排序结果的键已经存在,那么程序还会发送一个del事件。 - [SET key value EX seconds] [PX milliseconds] [NX|XX] 以及它的所有变种(SETEX key seconds value 、 SETNX key value 和 GETSET key value)都产生
set通知。其中 SETEX key seconds value 还会产生expire通知。 - [MSET key value key value …] 为每个键产生一个
set通知。 - SETRANGE key offset value 产生一个
setrange通知。 - INCR key 、 DECR key 、 INCRBY key increment 和 DECRBY key decrement 都产生
incrby通知。 - INCRBYFLOAT key increment 产生
incrbyfloat通知。 - APPEND key value 产生
append通知。 - [LPUSH key value value …] 和 LPUSHX key value 都产生单个
lpush通知,即使有多个输入元素时,也是如此。 - [RPUSH key value value …] 和 RPUSHX key value 都产生单个
rpush通知,即使有多个输入元素时,也是如此。 - RPOP key 产生
rpop通知。如果被弹出的元素是列表的最后一个元素,那么还会产生一个del通知。 - LPOP key 产生
lpop通知。如果被弹出的元素是列表的最后一个元素,那么还会产生一个del通知。 - LINSERT key BEFORE|AFTER pivot value 产生一个
linsert通知。 - LSET key index value 产生一个
lset通知。 - LTRIM key start stop 产生一个
ltrim通知。如果 LTRIM key start stop 执行之后,列表键被清空,那么还会产生一个del通知。 - RPOPLPUSH source destination 和 BRPOPLPUSH source destination timeout 产生一个
rpop通知,以及一个lpush通知。两个命令都会保证rpop的通知在lpush的通知之前分发。如果从键弹出元素之后,被弹出的列表键被清空,那么还会产生一个del通知。 - HSET hash field value 、 HSETNX hash field value 和 HMSET 都只产生一个
hset通知。 - HINCRBY 产生一个
hincrby通知。 - HINCRBYFLOAT 产生一个
hincrbyfloat通知。 - HDEL 产生一个
hdel通知。如果执行 HDEL 之后,哈希键被清空,那么还会产生一个del通知。 - [SADD key member member …] 产生一个
sadd通知,即使有多个输入元素时,也是如此。 - [SREM key member member …] 产生一个
srem通知,如果执行 [SREM key member member …] 之后,集合键被清空,那么还会产生一个del通知。 - SMOVE source destination member 为来源键(source key)产生一个
srem通知,并为目标键(destination key)产生一个sadd事件。 - SPOP key 产生一个
spop事件。如果执行 SPOP key 之后,集合键被清空,那么还会产生一个del通知。 - [SINTERSTORE destination key key …] 、 [SUNIONSTORE destination key key …] 和 [SDIFFSTORE destination key key …] 分别产生
sinterstore、sunionostore和sdiffstore三种通知。如果用于保存结果的键已经存在,那么还会产生一个del通知。 - ZINCRBY key increment member 产生一个
zincr通知。(译注:非对称,请注意。) - [ZADD key score member [score member] [score member] …] 产生一个
zadd通知,即使有多个输入元素时,也是如此。 - [ZREM key member member …] 产生一个
zrem通知,即使有多个输入元素时,也是如此。如果执行 [ZREM key member member …] 之后,有序集合键被清空,那么还会产生一个del通知。 - ZREMRANGEBYSCORE key min max 产生一个
zrembyscore通知。(译注:非对称,请注意。)如果用于保存结果的键已经存在,那么还会产生一个del通知。 - ZREMRANGEBYRANK key start stop 产生一个
zrembyrank通知。(译注:非对称,请注意。)如果用于保存结果的键已经存在,那么还会产生一个del通知。 - [ZINTERSTORE destination numkeys key key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX] 和 [ZUNIONSTORE destination numkeys key key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX] 分别产生
zinterstore和zunionstore两种通知。如果用于保存结果的键已经存在,那么还会产生一个del通知。 - 每当一个键因为过期而被删除时,产生一个
expired通知。 - 每当一个键因为
maxmemory政策而被删除以回收内存时,产生一个evicted通知。
5.过期通知的发送时间
Redis 使用以下两种方式删除过期的键:
- 当一个键被访问时,程序会对这个键进行检查,如果键已经过期,那么该键将被删除。
- 底层系统会在后台渐进地查找并删除那些过期的键,从而处理那些已经过期、但是不会被访问到的键。
当过期键被以上两个程序的任意一个发现、 并且将键从数据库中删除时, Redis 会产生一个 expired 通知。
Redis 并不保证生存时间(TTL)变为 0 的键会立即被删除: 如果程序没有访问这个过期键, 或者带有生存时间的键非常多的话, 那么在键的生存时间变为 0 , 直到键真正被删除这中间, 可能会有一段比较显著的时间间隔。
因此, Redis 产生 expired 通知的时间为过期键被删除的时候, 而不是键的生存时间变为 0 的时候。
5.redis通信协议
Redis 协议在以下三个目标之间进行折中:
- 易于实现
- 可以高效地被计算机分析(parse)
- 可以很容易地被人类读懂
RESP协议
Redis 是一个 CS 架构的软件,通信一般分两步(不包括 pipeline 和 PubSub):
- 客户端(client)向服务端(server)发送一条命令
- 服务端解析并执行命令,返回响应结果给客户端
因此客户端发送命令的格式、服务端响应结果的格式必须有一个规范,这个规范就是通信协议。
而在 Redis 中采用的是 RESP(Redis Serialization Protocol)协议:
- Redis 1.2 版本引入了 RESP 协议
- Redis 2.0 版本中成为与 Redis 服务端通信的标准,称为 RESP2
- Redis 6.0 版本中,从 RESP2 升级到了 RESP3 协议,增加了更多数据类型并且支持 6.0 的新特性–客户端缓存
但目前,默认使用的依然是 RESP2 协议,也是我们要学习的协议版本(以下简称 RESP)。
在 RESP 中,通过首字节的字符来区分不同数据类型,常用的数据类型包括 5 种:
-
单行字符串:首字节是‘+’,后面跟上单行字符串,以 CRLF(“\r\n”)结尾。例如返回"OK":“+OK\r\n”
-
错误(Errors):首字节是‘-’,与单行字符串格式一样,只是字符串是异常信息,例如:“-Error message\r\n”
-
数值:首字节是‘:’,后面跟上数字格式的字符串,以 CRLF 结尾。例如:“:10\r\n”
-
多行字符串:首字节是‘$’,表示二进制安全的字符串,最大支持 512MB:
- 如果大小为 0,则代表空字符串:“$0\r\n\r\n”
- 如果大小为 -1,则代表不存在:“$-1\r\n”
-
数组:首字节是
‘*’,后面跟上数组元素个数,再跟上元素,元素数据类型不限:
5.1 网络层
客户端和服务器通过 TCP 连接来进行数据交互, 服务器默认的端口号为 6379 。
客户端和服务器发送的命令或数据一律以 \r\n (CRLF)结尾。
5.2 请求
Redis 服务器接受命令以及命令的参数。
服务器会在接到命令之后,对命令进行处理,并将命令的回复传送回客户端。
5.3 新版统一请求协议
新版统一请求协议在 Redis 1.2 版本中引入, 并最终在 Redis 2.0 版本成为 Redis 服务器通信的标准方式。
你的 Redis 客户端应该按照这个新版协议来进行实现。
在这个协议中, 所有发送至 Redis 服务器的参数都是二进制安全(binary safe)的。
以下是这个协议的一般形式:
*<参数数量> CR LF
$<参数 1 的字节数量> CR LF
<参数 1 的数据> CR LF
...
$<参数 N 的字节数量> CR LF
<参数 N 的数据> CR LF
举个例子, 以下是一个命令协议的打印版本:
3
$3
SET
$5
mykey
$7
myvalue
这个命令的实际协议值如下:
"*3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$7\r\nmyvalue\r\n"
稍后我们会看到, 这种格式除了用作命令请求协议之外, 也用在命令的回复协议中: 这种只有一个参数的回复格式被称为批量回复(Bulk Reply)。
统一协议请求原本是用在回复协议中, 用于将列表的多个项返回给客户端的, 这种回复格式被称为多条批量回复(Multi Bulk Reply)。
一个多条批量回复以 * 为前缀, 后跟多条不同的批量回复, 其中 argc 为这些批量回复的数量。
5.4 回复
Redis 命令会返回多种不同类型的回复。
通过检查服务器发回数据的第一个字节, 可以确定这个回复是什么类型:
- 状态回复(status reply)的第一个字节是
"+" - 错误回复(error reply)的第一个字节是
"-" - 整数回复(integer reply)的第一个字节是
":" - 批量回复(bulk reply)的第一个字节是
"$" - 多条批量回复(multi bulk reply)的第一个字节是
"*"
5.5 状态回复
一个状态回复(或者单行回复,single line reply)是一段以 "+" 开始、 "\r\n" 结尾的单行字符串。
以下是一个状态回复的例子:
+OK
客户端库应该返回 "+" 号之后的所有内容。 比如在在上面的这个例子中, 客户端就应该返回字符串 "OK" 。
状态回复通常由那些不需要返回数据的命令返回,这种回复不是二进制安全的,它也不能包含新行。
状态回复的额外开销非常少,只需要三个字节(开头的 "+" 和结尾的 CRLF)。
5.6 错误回复
错误回复和状态回复非常相似, 它们之间的唯一区别是, 错误回复的第一个字节是 "-" , 而状态回复的第一个字节是 "+" 。
错误回复只在某些地方出现问题时发送: 比如说, 当用户对不正确的数据类型执行命令, 或者执行一个不存在的命令, 等等。
一个客户端库应该在收到错误回复时产生一个异常。
以下是两个错误回复的例子:
-ERR unknown command 'foobar'
-WRONGTYPE Operation against a key holding the wrong kind of value
在 "-" 之后,直到遇到第一个空格或新行为止,这中间的内容表示所返回错误的类型。
ERR 是一个通用错误,而 WRONGTYPE 则是一个更特定的错误。 一个客户端实现可以为不同类型的错误产生不同类型的异常, 或者提供一种通用的方式, 让调用者可以通过提供字符串形式的错误名来捕捉(trap)不同的错误。
不过这些特性用得并不多, 所以并不是特别重要, 一个受限的(limited)客户端可以通过简单地返回一个逻辑假(false)来表示一个通用的错误条件。
5.7 整数回复
整数回复就是一个以 ":" 开头, CRLF 结尾的字符串表示的整数。
比如说, ":0\r\n" 和 ":1000\r\n" 都是整数回复。
返回整数回复的其中两个命令是 INCR key 和 LASTSAVE 。 被返回的整数没有什么特殊的含义, INCR key 返回键的一个自增后的整数值, 而 LASTSAVE 则返回一个 UNIX 时间戳, 返回值的唯一限制是这些数必须能够用 64 位有符号整数表示。
整数回复也被广泛地用于表示逻辑真和逻辑假: 比如 EXISTS key 和 SISMEMBER key member 都用返回值 1 表示真, 0 表示假。
其他一些命令, 比如 [SADD key member member …] 、 [SREM key member member …] 和 SETNX key value , 只在操作真正被执行了的时候, 才返回 1 , 否则返回 0 。
以下命令都返回整数回复: SETNX key value 、 [DEL key key …] 、 EXISTS key 、 INCR key 、 INCRBY key increment 、 DECR key 、 DECRBY key decrement 、 DBSIZE 、 LASTSAVE 、 RENAMENX key newkey 、 MOVE key db 、 LLEN key 、 [SADD key member member …] 、 [SREM key member member …] 、 SISMEMBER key member 、 SCARD key 。
5.8 批量回复
服务器使用批量回复来返回二进制安全的字符串,字符串的最大长度为 512 MB 。
客户端:GET mykey
服务器:foobar
服务器发送的内容中:
- 第一字节为
"$"符号 - 接下来跟着的是表示实际回复长度的数字值
- 之后跟着一个 CRLF
- 再后面跟着的是实际回复数据
- 最末尾是另一个 CRLF
对于前面的 GET key 命令,服务器实际发送的内容为:
"$6\r\nfoobar\r\n"
如果被请求的值不存在, 那么批量回复会将特殊值 -1 用作回复的长度值, 就像这样:
客户端:GET non-existing-key
服务器:$-1
这种回复称为空批量回复(NULL Bulk Reply)。
当请求对象不存在时,客户端应该返回空对象,而不是空字符串: 比如 Ruby 库应该返回 nil , 而 C 库应该返回 NULL (或者在回复对象中设置一个特殊标志), 诸如此类。
5.9 多条批量回复
像 LRANGE key start stop 这样的命令需要返回多个值, 这一目标可以通过多条批量回复来完成。
多条批量回复是由多个回复组成的数组, 数组中的每个元素都可以是任意类型的回复, 包括多条批量回复本身。
多条批量回复的第一个字节为 "*" , 后跟一个字符串表示的整数值, 这个值记录了多条批量回复所包含的回复数量, 再后面是一个 CRLF 。
客户端: LRANGE mylist 0 3
服务器: *4
服务器: $3
服务器: foo
服务器: $3
服务器: bar
服务器: $5
服务器: Hello
服务器: $5
服务器: World
在上面的示例中,服务器发送的所有字符串都由 CRLF 结尾。
正如你所见到的那样, 多条批量回复所使用的格式, 和客户端发送命令时使用的统一请求协议的格式一模一样。 它们之间的唯一区别是:
- 统一请求协议只发送批量回复。
- 而服务器应答命令时所发送的多条批量回复,则可以包含任意类型的回复。
以下例子展示了一个多条批量回复, 回复中包含四个整数值, 以及一个二进制安全字符串:
*5\r\n
:1\r\n
:2\r\n
:3\r\n
:4\r\n
$6\r\n
foobar\r\n
在回复的第一行, 服务器发送 *5\r\n , 表示这个多条批量回复包含 5 条回复, 再后面跟着的则是 5 条回复的正文。
多条批量回复也可以是空白的(empty), 就像这样:
客户端: LRANGE nokey 0 1
服务器: *0\r\n
无内容的多条批量回复(null multi bulk reply)也是存在的, 比如当 [BLPOP key key …] timeout 命令的阻塞时间超过最大时限时, 它就返回一个无内容的多条批量回复, 这个回复的计数值为 -1 :
客户端: BLPOP key 1
服务器: *-1\r\n
客户端库应该区别对待空白多条回复和无内容多条回复: 当 Redis 返回一个无内容多条回复时, 客户端库应该返回一个 null 对象, 而不是一个空数组。
5.10 多条批量回复中的空元素
多条批量回复中的元素可以将自身的长度设置为 -1 , 从而表示该元素不存在, 并且也不是一个空白字符串(empty string)。
当 [SORT key BY pattern] [LIMIT offset count] [GET pattern [GET pattern …]] [ASC | DESC] [ALPHA] [STORE destination] 命令使用 GET pattern 选项对一个不存在的键进行操作时, 就会发生多条批量回复中带有空白元素的情况。
以下例子展示了一个包含空元素的多重批量回复:
服务器: *3
服务器: $3
服务器: foo
服务器: $-1
服务器: $3
服务器: bar
其中, 回复中的第二个元素为空。
对于这个回复, 客户端库应该返回类似于这样的回复:
["foo", nil, "bar"]
5.11 多命令和流水线
客户端可以通过流水线, 在一次写入操作中发送多个命令:
- 在发送新命令之前, 无须阅读前一个命令的回复。
- 多个命令的回复会在最后一并返回。
5.12内联命令
当你需要和 Redis 服务器进行沟通, 但又找不到 redis-cli , 而手上只有 telnet 的时候, 你可以通过 Redis 特别为这种情形而设的内联命令格式来发送命令。
以下是一个客户端和服务器使用内联命令来进行交互的例子:
客户端: PING
服务器: +PONG
以下另一个返回整数值的内联命令的例子:
客户端: EXISTS somekey
服务器: :0
因为没有了统一请求协议中的 "*" 项来声明参数的数量, 所以在 telnet 会话输入命令的时候, 必须使用空格来分割各个参数, 服务器在接收到数据之后, 会按空格对用户的输入进行分析(parse), 并获取其中的命令参数。
5.13 高性能 Redis 协议分析器
尽管 Redis 的协议非常利于人类阅读, 定义也很简单, 但这个协议的实现性能仍然可以和二进制协议一样快。
因为 Redis 协议将数据的长度放在数据正文之前, 所以程序无须像 JSON 那样, 为了寻找某个特殊字符而扫描整个 payload , 也无须对发送至服务器的 payload 进行转义(quote)。
程序可以在对协议文本中的各个字符进行处理的同时, 查找 CR 字符, 并计算出批量回复或多条批量回复的长度, 就像这样:
#include 得到了批量回复或多条批量回复的长度之后, 程序只需调用一次 read 函数, 就可以将回复的正文数据全部读入到内存中, 而无须对这些数据做任何的处理。
在回复最末尾的 CR 和 LF 不作处理,丢弃它们。
Redis 协议的实现性能可以和二进制协议的实现性能相媲美, 并且由于 Redis 协议的简单性, 大部分高级语言都可以轻易地实现这个协议, 这使得客户端软件的 bug 数量大大减少。
6.redis客户端与服务器
redis数据库采用I/O多路复用技术实现文件处理器,服务器采用单线程单进程的方式来处理客户端发送过来的请求命令,他同时与多个客户端建立网络通信连接,服务器会与他相连接的客户端创建对应的redis.sh/redisClient结构,在这个结构中保存了当前客户端相关属性以及执行操作。
6.1.redis客户端
6.1.1 客户端名称,套接字,标志和时间
客户端的属性大致可以分为2类,一类是redis特定功能相关的属性,另一类是通用属性,也就是客户端执行什么命令或进行扫什么操作,都会与这些属性相关。
1.名字属性
在默认情况下redis连接到服务端的客户端是没有名字的,我们可以通过CLIENT setname 来进行设置。
127.0.0.1:6379> client list
id=79 addr=127.0.0.1:59216 fd=7 name= age=149949 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client user=default
2.套接字属性
客户端套接字由客户端状态的fd属性记录,他记录了客户端正在使用的套接字相关描述符,不同类型的客户端,fd属性也是不同的,他的值如果是-1表示这个客户端是一个伪客户端,来源是lua脚本或aof文件的,也可能是大于-1的整数。大于-1表示这是一个普通的客户端,查看连接到服务器的所有客户端,可以使用如下命令:
127.0.0.1:6379> CLIENT list
id=79 addr=127.0.0.1:59216 fd=7 name= age=150192 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client user=default
返回值
addr : 客户端的地址和端口
fd : 套接字所使用的文件描述符
age : 以秒计算的已连接时长
idle : 以秒计算的空闲时长
flags : 客户端 flag
db : 该客户端正在使用的数据库 ID
sub : 已订阅频道的数量
psub : 已订阅模式的数量
multi : 在事务中被执行的命令数量
qbuf : 查询缓冲区的长度(字节为单位, 0 表示没有分配查询缓冲区)
qbuf-free : 查询缓冲区剩余空间的长度(字节为单位, 0 表示没有剩余空间)
obl : 输出缓冲区的长度(字节为单位, 0 表示没有分配输出缓冲区)
oll : 输出列表包含的对象数量(当输出缓冲区没有剩余空间时,命令回复会以字符串对象的形式被入队到这个队列里)
omem : 输出缓冲区和输出列表占用的内存总量
events : 文件描述符事件
cmd : 最近一次执行的命令
客户端 flag 可以由以下部分组成:
O : 客户端是 MONITOR 模式下的附属节点(slave)
S : 客户端是一般模式下(normal)的附属节点
M : 客户端是主节点(master)
x : 客户端正在执行事务
b : 客户端正在等待阻塞事件
d : 一个受监视(watched)的键已被修改, EXEC 命令将失败
c : 在将回复完整地写出之后,关闭链接
u : 客户端未被阻塞(unblocked)
A : 尽可能快地关闭连接
N : 未设置任何 flag
文件描述符事件可以是:
r : 客户端套接字(在事件 loop 中)是可读的(readable)
w : 客户端套接字(在事件 loop 中)是可写的(writeable)
查看示例:
redis-cli -h 127.0.0.1 -p 6379 -a 123456 CLIENT LIST | awk '{printf "%-32s| %-16s| %-16s| %-16s| %-16s| %-16s| %s\n", $2,$5,$6,$7,$12,$16,$18}'
3.标志属性
标记属性用来记录客户端的角色,以及客户端目前所处的状态。
flags 属性的取值可以是单个标志,也可以是多个二进制或的组合标志,具体如下。
单个标志:flags=<flag>
组合标志:flags=<flag1>|<flag2>|<flag3>|…
标志使用常量来表示。Redis 所具有的所有标志都定义在 redis.h 文件中。
记录客户端角色的标志有如下几个。
● 在利用 Redis 主从服务器实现复制时,主从服务器会相互成为对方的客户端,也就是从服务器是主服务器的客户端,同时主服务器也是从服务器的客户端。Redis 使用REDIS_MASTER 标志来表示这个客户端是主服务器,而使用 REDIS_SLAVE 标志来表示另一个客户端是从服务器。
● Redis 使用 REDIS_LUA_CLIENT 标志来表示该客户端是一个专门用于处理 Lua 脚本的伪客户端,它主要用于执行 Lua 脚本中包含的 Redis 命令。
● Redis 使用 REDIS_PRE_PSYNC 标志来表示该客户端是一个低于 Redis 2.8 版本的从服务器,此时,对应的主服务器不能使用 PSYNC 命令实现与从服务器的数据同步。只有当 REDIS_SLAVE 标志处于打开状态时,才能使用 REDIS_PRE_PSYNC 标志。
记录客户端当前状态的标志有如下几个。
● REDIS_ASKING 标志表示客户端向运行在集群模式下的服务器节点发送了 ASKING 命令。
● REDIS_CLOSE_ASAP 标志表示客户端的输出缓冲区过大,超出了服务器所允许的范围。当服务器在下一次执行 serverCron 函数时,会关闭这个输出缓冲区过大的客户端,以此来保证服务器的稳定性不受这个客户端影响。在关闭的时候,存储在这个缓冲区中的数据也会被删除,并且不会给客户端返回任何信息。
● REDIS_CLOSE_AFTER_REPLY 标志表示客户端给服务器发送的命令请求中有错误的协议内容,或者用户在客户端中执行了 CLIENT kill 命令。此时服务器会将客户端输出缓冲区中存储的所有数据内容发送给客户端,然后关闭这个客户端。
● REDIS_DIRTY_CAS 标志表示事务使用 WATCH 命令监视的数据库键已经被修改。
● REDIS_DIRTY_EXEC 标志表示事务在命令入队时出现错误。
REDIS_DIRTY_CAS 和 REDIS_DIRTY_EXEC 标志的出现都表示 Redis 事务的安全性已被破坏。只要这两个标志中的任何一个被打开,EXEC 命令都会执行失败。而只有在客户端打开了 REDIS_MULTI 标志的情况下,才能使用这两个标志。
● REDIS_MULTI 标志表示客户端正处于执行事务的状态中。
● REDIS_MONITOR 标志表示客户端正处于执行 MONITOR 命令的状态中。
● REDIS_FORCE_AOF 标志表示让服务器将当前正在执行的命令强制写入 AOF 文件中。在执行 PUBSUB 命令时,会使客户端打开 REDIS_FORCE_AOF 标志。
● REDIS_FORCE_REPL 标志表示强制让主服务器将当前正在执行的命令复制给所有与它连接的从服务器。当执行 SCRIPT LOAD 命令时,会使客户端同时开启 REDIS_FORCE_AOF 和 REDIS_FORCE_REPL 标志。如果要实现主从服务器可以正确地载入 SCRIPT LOAD 命令指定的脚本,那么服务器必须使用 REDIS_FORCE_REPL 标志,让主服务器强制将 SCRIPT LOAD 命令分发给相应的从服务器。
● REDIS_UNIX_SOCKET 标志表示服务器连接客户端使用的是 UNIX 套接字。
● REDIS_BLOCKED 标志表示客户端正处于被 BRPOP、BLPOP 等命令阻塞的状态中。
● REDIS_UNBLOCKED 标志表示客户端不再阻塞,它从 REDIS_BLOCKED 标志的阻塞状态中脱离出来。只有在 REDIS_BLOCKED 标志被打开的情况下,才能使用 REDIS_UNBLOCKED 标志。
● REDIS_MASTER_FORCE_REPLY 标志:在主从服务器进行命令交互的过程中,从服务器需要向主服务器发送 REPLICATION ACK 命令。但是,在发送此命令之前,从服务器必须开启主服务器对应的客户端的 REDIS_MASTER_FORCE_REPLY 标志;否则主服务器会拒绝执行从服务器发送的 REPLCATION ACK 命令。
4.时间属性
● ctime 属性:该属性记录了客户端被创建的时间。利用这个时间可以计算出这个客户端与服务器相连接的时间,单位为秒。在执行 CLIENT list 命令后,返回的 age 域记录了连接秒数
● lastinteraction 属性:该属性记录了客户端与服务器最后一次交互的时间。交互就是两者之间互相发送命令请求与返回结果。利用 lastinteraction 属性可以计算出客户端的空转时间,也就是在进行最后一次交互之前过去了多少时间,单位为秒。CLIENT list 命令返回的 idle 域记录了这个时间。当 idle 的值为 0 时,表示空转时间为 0 秒。
● obuf_soft_limit_reached_time 属性:该属性记录了客户端输出缓冲区第一次达到软性限制的时间
6.1.2 客户端缓冲区
服务器采用软性限制(Soft Limit)和硬性限制(Hard Limit)两种模式来限制客户端缓 冲区的大小。
-
软性限制 如果软性限制所设置的大小小于输出缓冲区的大小,且输出缓冲区的大小不大于硬性限 制所设置的大小,那么服务器会使用客户端状态结构的 obuf_soft_limit_reached_time 属性来 记录客户端达到软性限制的起始时间。之后服务器会继续监视客户端,如果这个缓冲区的大 小一直超出软性限制,并且持续时间超过服务器设定的时长,那么服务器将会关闭这个客户 端。相反地,如果输出缓冲区的大小在指定时间范围之内没有超过软性限制,那么这个客户 端不会被关闭,并且 obuf_soft_limit_reached_time 属性的值也会被设置为 0。 130∣从零开始学 Redis
-
硬性限制
当输出缓冲区的大小超过了硬性限制的大小时,这个客户端会被立即关闭。 我们可以使用 client-output-buffer-limit 选项来为普通客户端、从服务器客户端或执行消 息订阅发布功能的客户端设置软性限制和硬性限制,
具体的格式如下:
client-output-buffer-limit
比如:
client-output-buffer-limit normal 0 0 0 #设置普通客户端的硬性限制和软性限制均为 0,表示这
个客户端的输出缓冲区不限制大小
client-output-buffer-limit slave 512mb 128mb 120 #设置从服务器客户端的硬性限制为 512MB,
软性限制为 128MB,软性限制的时长为 120 秒
client-output-buffer-limit pubsub 64mb 64mb 100 #设置执行消息订阅发布功能的客户端的硬性
限制和软性限制均为 64MB,软性限制的时长为 100 秒
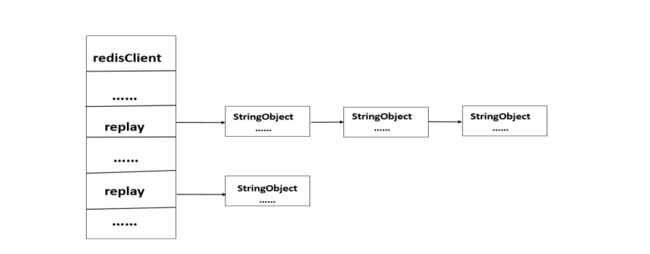
客户端的缓冲区分为输入缓冲区和输出缓冲区
● 输入缓冲区:用于保存客户端发送的命令请求。输入缓冲区的大小是动态变化的, 它会根据输入的内容动态缩小或增大。1GB 是输入缓冲区的最大大小。如果输入缓 冲区的大小超过了 1GB,那么这个客户端将会被关闭。
● 输出缓冲区:用于保存执行客户端请求命令返回的结果或返回值。每个客户端都有 两个输出缓冲区,一个输出缓冲区的大小是固定的,另一个输出缓冲区的大小是可 变的。
-
固定输出缓冲区:用于保存那些长度比较小的返回值,比如常见的 OK、或 者一些短字符串、整数值及错误值等。
-
可变输出缓冲区:用于保存那些长度比较大的返回值,比如一个长度比较大的字 符串、大列表、大集合等。 buf 和 bufpos 属性组成了客户端固定大小的缓冲区。
buf 属性是一个字节数组,数组大小为 REDIS_REPLY_CHUNK_BYTES 字节。REDIS_ REPLY_CHUNK_BYTES 常量的默认值为 16×1024,即 buf 数组的默认大小为 16KB。 bufpos 属性记录了 buf 数组到目前为止已经使用的字节数量。
当 buf 数组已经存满或者回复因为太大而没有办法存入 buf 数组时,服务器就会使用 可变大小的缓冲区。
链表 reply 和一个或多个字符串对象组成可变大小的输出缓冲区。通过使用链表来连接 多个字符串对象,服务器可以为客户端保存一个非常长的命令返回值,而不会受到大小的 限制。如图 6.1 所示为可变大小的输出缓冲区。
如图所示:可变大小缓冲区
6.1.3 客户端的 authenticated 属性
authenticated 属性是客户端身份验证属性,用于记录客户端是否通过了身份验证。这个属性的值为 0 和 1,默认值为 0。
当 authenticated 属性值为 0 时,表示这个客户端的身份验证失败,没有通过。而当authenticated 属性值为 1 时,表示这个客户端的身份验证通过了。只有当服务器启用了客户端身份验证功能时,才能使用 authenticated 属性。如果服务器启用了客户端身份验证功能,同时 authenticated 属性值为 0,那么对于客户端发送过来的所有命令,服务器都不会执行,除 AUTH 命令外。而如果服务器没有启动客户端身份验证功能,同时 authenticated 属性值为 0,那么服务器不会拒绝执行客户端发送过来的命令。
当 authenticated 属性值为 0 时,服务器除执行 AUTH 命令之外,将会拒绝执行客户端
发送过来的其他所有命令。操作如下:
127.0.0.1 6379>PING
(error) NOAUTH Authentication required
127.0.0.1 6379>DEL name
(error) NOAUTH Authentication required
当客户端使用 AUTH 命令成功进行身份验证之后,authentication 属性值将会变为 1,
此时服务器不会拒绝执行客户端发送过来的任何命令,并且会返回相应的结果。
6.1.4 客户端的 argv 和 argc 属性
argv 属性:这是一个数组,数组中的每个元素都是一个字符串对象,其中 argv[0]是要执行的命令,而之后的其他元素是传给这个命令的参数。
argc 属性:用于记录 argv 属性的数组长度。当客户端向服务器发送命令时,服务器会将接收到的命令保存到客户端状态的querybuf 属性中。保存之后,服务器会分析这个命令的内容,并将分析得出的命令参数及
命令参数的个数分别保存到 argv 和 argc 属性中,如图

6.1.5 关闭客户端
在这里再介绍一下普通客户端被关闭的几种方式。
● 当客户端执行了 CLIENT kill 命令时,客户端会被关闭。
● 当客户端进程被杀死时,客户端将会断开与服务器的连接,从而客户端被关闭。
● 当客户端向服务器发送的命令是错误协议格式时,客户端会被关闭。
● 当客户端发送的命令请求的大小超过了输入缓冲区的限制大小时,客户端会被关闭。
● 当发送给客户端的命令执行后返回结果的大小超过了输出缓冲区的限制大小时,客 户端也会被关闭。
● 当为服务器设置了 timeout 参数值,同时客户端的空转时间又超过了 timeout 参数值 时,客户端将会被关闭。而如果这个客户端是主服务器,而从服务器被 BLPOP、 BRPOP 等相关命令阻塞,或者从服务器正在执行与订阅发布相关的命令,此时就算 客户端的空转时间超过了 timeout 参数值,这个客户端也不会被关闭。
6.2 redis服务器
Redis 服务器实现与多个客户端的连接,并处理这些客户端发送过来的请求,同时保存 客户端执行命令所产生的数据到数据库中。Redis 服务器依靠资源管理器来维持自身的运 转,其主要作用是管理 Redis 服务。本节将讲解 Redis 服务器处理命令的过程,以及与服务 器相关的属性、函数的用法,来进一步熟悉 Redis 服务器的工作过程
6.2.1 服务器处理命令请求
在一条命令从客户端发送到服务器端,到服务器处理完这条命令请求,然后返回结果 的这一过程中,客户端与服务器需要完成一系列的操作。
比如,我们向客户端发送了一条命令:SET city “beijing”;服务器接收到命令请求,处 理完之后返回 OK。在这一过程中,客户端与服务器需要完成以下几个步骤。
(1)用户将命令 SET city "beijing"输入客户端,客户端接收到此命令。
(2)客户端将这条命令请求发送给服务器。
(3)服务器接收到客户端发送过来的命令请求并处理它,在数据库中进行操作,这里 的操作为添加新键值对,成功之后返回 OK。
(4)服务器将命令结果 OK 返回给客户端。
(5)客户端接收到服务器返回的命令结果 OK,然后将这个结果展示给用户。 这个过程如图 6.3 所示。

6.2.2 服务器发送命令
Redis 客户端将一条命令请求发送给服务器,也就是说,服务器的命令请求来源于客户端。当用户将一条命令输入客户端后,客户端会先将接收到的命令转化为服务器可以识别的协议格式,然后利用连接到服务器的套接字,将转化为合法协议格式的命令请求发送给服务器。这一过程如图

比如,向客户端输入以下命令:
SET city "beijing"
客户端接收到这条命令之后,会将这条命令转化为服务器可以识别的协议格式。
*3\r\n$3\r\nSET\r\n$3\r\ncity\r\n$5\r\nbeijing\r\n
转化之后,将这个协议内容发送给服务器。
6.2.3 服务器执行命令
当服务器接收到客户端传递过来的协议数据时,客户端与服务器之间的连接套接字就会变得可读,此时,服务器将会调用命令请求处理器执行以下过程。
(1)服务器读取套接字中协议格式的命令请求,然后将读取到的命令请求保存到客户
端状态的输入缓冲区中。
(2)对输入缓冲区中的命令请求进行分析,获取命令请求参数及参数个数,分别保存
到客户端状态的 argv 和 argc 属性中。
(3)调用命令执行器,执行客户端发送过来的命令请求。
命令执行器在执行客户端发送过来的命令请求的过程中,会先根据客户端状态的argv[0]参数,在命令表(Command Table)中查找参数所指定的命令,并将查找到的命令保存到客户端状态的 cmd 属性中,然后进行相关的判断,比如,判断客户端状态的 cmd 指针是否指向 NULL,或者检查客户端的身份,判断是否验证通过等,最后调用命令的实现函数执行相关命令,这就是命令执行器的执行过程。
命令表是一个字典,用于存放 Redis 的命令,字典的键就是一个个命令的名字,比如
“set”“sadd”“zadd”等;而字典的值是一个个 redisCommand 结构,而每个 redisCommand
结构记录了对应命令的实现信息。redisCommand 结构具有多个属性,具体如下。
● name 属性:表示命令的名字,比如 SET、GET,它是 char *类型的。
● proc 属性:它是一个函数指针,用于指向命令的实现函数,比如,指向 SET 命令的实现函数 setCommand,它是 redisCommandProc *类型的,而 redisCommandProc 类型的定义为 typedef void redisCommandProc(redisClient *c)。
● arity 属性:它是一个 int 类型的整数,表示命令参数的个数,用于判断命令请求的格式是否正确。如果 arity 属性的值是一个负数-N,则表示命令参数的数量大于等于 N。请注意,这里所说的参数个数包含命令的名字本身,比如,SET city “beijing”,这条命令的参数个数是 3,分别是“SET”“city”“beijing”。
● sflags 属性:它是一个 char *类型的字符串形式的标识值,具有多个标识符,用于记录这个命令所具有的属性。
● flags 属性:它是一个 int 类型的整数,是对 sflags 标识进行分析得出的二进制标识,这个二进制标识由程序自动生成。当服务器对命令标识进行检查时,使用的是 flags属性。
● calls 属性:该属性用于统计服务器共执行了多少次这个命令,它是一个 long long 类型的整数。
● milliseconds 属性:该属性用于统计服务器执行这个命令所耗费的总时长,它是一个long long 类型的整数。每个 Redis 命令都有其对应的 redisCommand 结构,都有上面的相关属性。
sflags 属性所具有的标识符具体如下:
● a:属性值为 a,表示这个命令是一个 Redis 管理命令。相关的命令有 SAVE、BGSAVE、 SHUTDOWN 等。
● l:属性值为 l,表示这个命令常用于服务器载入数据的过程中。相关的命令有 INFO、 PUBLISH、SUBSCRIBE 等。
● m:属性值为 m,说明这个命令在执行的过程中可能会占用大量内存。在执行之前, 需要判断服务器的内存大小及使用情况,如果服务器的内存资源不足,则将会拒绝 执行这个命令。相关的命令有 SET、SADD、APPEND、RPUSH、LPUSH 等。
● M:属性值为 M,表示这个命令在 Redis 监视器模式下不会被自动传播。相关的命 令有 EXEC。
● p:属性值为p,说明这个命令与Redis的消息订阅发布功能相关。相关的命令有PUBLISH、 PUBSUB、PSUBSCRIBE、PUNSUBSCRIBE、SUBSCRIBE、UNSUBSCRIBE 等。
● r:属性值为 r,只读,说明这是一个只读命令,用于获取相关数据,它不会修改数 据库。相关的命令有 GET、STRLEN、EXISTS 等。
● R:属性值为 R,说明这是一个随机命令,在处理相同的数据集和相同的参数时, 得到的结果是随机的。相关的命令有 SPOP、SSCAN、RANDOMKEY 等。
● s:属性值为 s,表示在 Lua 脚本中不能使用该命令。相关的命令有 BLPOP、BRPOP、 SPOP、BRPOPLPUSH 等。
● S:属性值为 S,表示这个命令在 Lua 脚本中可以使用。在 Lua 脚本中使用这个命令 时,输出的结果会被排序,也就是输出的结果是有序的。相关的命令有 KEYS、 SUNION、SDIFF、SINTER、SMEMBERS 等。
● t:属性值为 t,表示这个命令允许从服务器在带有过期数据时使用。相关的命令有 PING、INFO、SLAVEOF 等。
● w:属性值为 w,可写,说明这是一个写入命令,它可以修改数据库。相关的命令 有 SET、DEL、RPUSH 等。
6.2.4 服务器返回命令结果
命令执行器在执行完相关的实现函数之后,服务器会接着做一些后续工作,然后将命令结果返回给客户端。
服务器所做的后续工作具体过程如下。
(1)在命令执行的过程中会耗费一些时间,需要同步到该命令所对应的 redisCommand
结构中。修改 milliseconds 属性的值,同时将 redisCommand 结构中的 calls 计数器的值加 1。
(2)如果这台服务器启动了慢查询日志功能,那么慢查询日志模块会判断是否需要为
刚执行完的命令添加一条慢查询日志。
(3)如果这台服务器启用了 AOF 持久化功能,那么 AOF 持久化模块会将这条执行完的命令请求写入 AOF 缓冲区里。
(4)如果有其他从服务器正在同步备份当前这台服务器的数据,那么这台服务器会将刚执行完的命令请求转发给与它相连的从服务器。
当服务器完成上述相关后续工作的处理之后,会调用命令回复处理器,此时客户端的套接字变为可写状态。服务器调用命令回复处理器将保存在客户端输出缓冲区中的协议格式的返回结果发送给客户端,客户端接收到返回结果之后,会转化为人类可识别的格式,打印给用户看。
当命令回复处理器将返回结果成功发送给客户端之后,它会删除客户端状态的输出缓冲区,为下一条命令请求的执行腾出空间。
上述这个服务器返回结果到客户端的过程如图 6.5 所示。

前面我们用到了 SET 命令,在执行 SET city "beijing"命令之后,也就是在服务器调用命令执行器之后,会返回一个协议格式的 OK,存入客户端状态的输出缓冲区中,然后服务器调用命令回复处理器将协议格式的命令结果“+OK\r\n”发送给客户端,客户端成功接收并把它转化为“OK\n”,接着打印显示出来。
以上就是 Redis 服务器与客户端交互执行一条命令请求的过程。
6.3 服务器函数
服务器的正常运行离不开底层相关函数的执行。下面介绍几个与 Redis 服务器相关的 函数,看看它们是如何调用执行的,来进一步了解 Redis 服务器的运行过程。
6.3.1 serverCron 函数
serverCron 函数是 Redis 服务器中的一个重要函数。在默认情况下,每隔 100 毫秒执行 一次 serverCron 函数,它负责管理服务器的资源,并维持服务器的正常运行。在执行 serverCron 函数的过程中会调用相关的子函数,如 trackOperationsPerSecond 、 SigtermHandler、clientsCron、databasesCron 等函数,来实现对 Redis 服务器资源的管理。
6.3.2 trackOperationsPerSecond 函数
trackOperationsPerSecond 函数是 serverCron 函数的一个子函数,它以每 100 毫秒一次 的频率被执行,采用抽样计算的方式,计算并记录服务器在最近 1 秒内处理的命令请求数 量。可以通过 INFO stats 命令来查看。在返回的结果中,instantaneous_ops_per_sec 属性记 录了服务器在最近 1 秒内处理的命令请求数量。INFO stats 命令操作如下所示
127.0.0.1:6379> INFO stats
# Stats
total_connections_received:3
total_commands_processed:9
instantaneous_ops_per_sec:0
total_net_input_bytes:252
total_net_output_bytes:31451
instantaneous_input_kbps:0.00
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
evicted_keys:0
keyspace_hits:0
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:0
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
其中,instantaneous_ops_per_sec 属性的值为 0,表示在最近 1 秒内服务器没有处理任何命令请求。instantaneous_ops_per_sec 属性的值是通过计算 REDIS_OPS_SEC_SAMPLES次取样的平均值来计算的,是一个估算值,并不能很准确地统计出服务器在最近 1 秒内处理的命令请求数量。关于这个估算值的计算,感兴趣的读者可以自行查阅相关资料。
6.3.3 sigtermHandler 函数
sigtermHandler 函数是一个 Redis 服务器进程的 SIGTERM 信号关联处理器。在 Redis服务器启动的时候会调用执行 sigtermHandler 函数,它负责在服务器接收到 SIGTERM 信号时,打开服务器状态的 shutdown_asap 标识。
在每次执行服务器资源管理函数 serverCron 的时候,都会先对服务器状态的shutdown_asap 属性的值进行判断,再决定是否关闭服务器。当 shutdown_asap 属性的值为1 时,关闭服务器;当 shutdown_asap 属性的值为 0 时,什么也不做。
6.3.4 clientsCron 函数
clientsCron 函数在每次执行服务器资源管理函数 serverCron 时被调用,它会对一定数量的客户端进行如下检查。
● 检查这个客户端与服务器的连接是否已经超时。如果连接已经超时(在很长一段时间内,客户端与服务器之间没有进行交互),则释放这个客户端的连接。
● 检查这个客户端的输入缓存区的大小,以便对服务器的内存进行管理。如果客户端在上一次执行命令请求后,输入缓冲区的大小超过了一定的限制,那么程序会释放这个客户端的输入缓存区,然后重新为这个客户端创建一个默认大小的输入缓冲区,以此来防止客户端的输入缓冲区消耗更多内存。
6.3.5 databasesCron 函数
databasesCron 函数在每次执行 serverCron 函数时被调用,它的作用是对服务器中的部分数 据库进行检查,查找出过期的键,然后删除它们,并对 Redis 数据字典进行相关的收缩操作等。
6.4 服务器属性
服务器相关属性在服务器运行过程中扮演着重要的角色,它们会与服务器相关函数结 合起来,共同维持服务器的正常运行。服务器的相关属性具体如下
6.4.1 cronloops 属性
cronloops 属性是一个计数器,用于记录服务器的 serverCron 函数被执行的次数,是一个 int 类型的整数。每执行一次 serverCron 函数,cronloops 属性的值就加 1。
6.4.2 rdb_child_pid 与 aof_child_pid 属性
rdb_child_pid 和 aof_child_pid 属性用于检查 Redis 服务器持久化操作的运行状态,它们记录执行 BGSAVE 和 BGREWRITEAOF 命令的子进程的 ID。也常常使用这两个属性来
判断 BGSAVE 和 BGREWRITEAOF 命令是否正在被执行。当执行 serverCron 函数时,会检查 rdb_child_pid 和 aof_child_pid 属性的值,只要其中一个属性的值不等于-1,程序就会调用一次 wait3 函数来判断子进程是否发送信号到服务器中。
如果没有信号到达,则表示服务器持久化操作没有完成,程序不做任何处理。而如果有信号到达,那么,针对 BGSAVE 命令,表示新的 RDB 文件已经成功生成;针对BGREWRITEAOF 命令,表示新的 AOF 文件生成完毕,然后服务器继续执行相应的后续操作。比如,将旧的 RDB 文件或 AOF 文件替换为新的 RDB 文件或 AOF 文件。另外,当 rdb_child_pid 和 aof_child_pid 属性的值都为-1 时,表示此时的服务器没有执行持久化操作,这时程序会做出如下判断。
(1)判断 BGREWRITEAOF 命令的执行是否被延迟了。如果被延迟了,则重新执行一次 BGREWRITEAOF 命令。
(2)判断是否满足服务器的自动保存条件。如果满足服务器的自动保存条件,并且服务器没有执行其他持久化操作,那么服务器将开始执行 BGSAVE 命令。
(3)判断是否满足服务器设置的 AOF 重写条件。如果条件满足,同时服务器没有执行其他持久化操作,那么服务器将重新执行 BGREWRITEAOF 命令。服务器执行持久化操作的过程如图

6.4.3 stat_peak_memory 属性
stat_peak_memory 属性用于记录 Redis 服务器的内存峰值大小。在每次执行 serverCro
函数时,程序都会检查服务器当前内存的使用情况,并与 stat_peak_memory 属性保存的上一次内存峰值大小进行比较。如果当前的内存峰值大小大于 stat_peak_memory 属性保存的值,就将当前最新的内存峰值大小赋给 stat_peak_memory 属性。在执行 INFO memory 命令后,返回的 used_memory_peak 和 used_memory_peak_human属性分别以两种格式记录了服务器的内存峰值大小。在执行 INFO memory 命令后,返回的
结果如下所示:
127.0.0.1:6379> INFO memory
# Memory
used_memory:871216
used_memory_human:850.80K
used_memory_rss:2703360
used_memory_rss_human:2.58M
used_memory_peak:871216
used_memory_peak_human:850.80K
used_memory_peak_perc:100.01%
used_memory_overhead:853560
used_memory_startup:786472
used_memory_dataset:17656
used_memory_dataset_perc:20.83%
total_system_memory:16725729280
total_system_memory_human:15.58G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:3.10
mem_allocator:jemalloc-4.0.3
active_defrag_running:0
lazyfree_pending_objects:0
6.4.4 lruclock 属性
lruclock 属性是一种服务器时间缓存,它记录了服务器的 LRU 时钟。在默认情况下,serverCron 函数会以每 10 秒一次的频率更新 lruclock 属性的值。LRU 时钟不是实时的,它只是一个模糊的估计值。
Redis 的每个对象都有一个 lru 属性,该属性记录了这个对象最后一次被命令访问的时间。使用 lruclock 属性的值减去 lru 属性的值,就能计算出这个对象的空转时间。可以使用 INFO server 命令的 lru_clock 属性来查看当前 LRU 时钟的时间,操作如下:
127.0.0.1:6379> INFO server
# Server
redis_version:4.0.9
redis_git_sha1:00000000
第 6 章 Redis 客户端与服务器∣141
redis_git_dirty:0
redis_build_id:c706c7a026bd863d
redis_mode:standalone
os:Linux 2.6.32-431.el6.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:sync-builtin
gcc_version:4.4.7
process_id:25154
run_id:047838576c9b61b823008a5d7d462bd1fb36d459
tcp_port:6379
uptime_in_seconds:2379
uptime_in_days:0
hz:10
lru_clock:13975323
executable:/home/redis/redis-4.0.9/src/./redis-server
config_file:
6.4.5 mstime 与 unixtime 属性
mstime 和 unixtime 属性记录了服务器当前的时间。在默认情况下,serverCron 函数会以每 100 毫秒一次的频率更新 mstime 和 unixtime 属性,它们记录的时间值并不是最准确的。
6.4.6 aof_rewrite_scheduled 属性
aof_rewrite_scheduled 属性用于记录服务器中 BGREWRITEAOF 命令执行是否被延迟。当aof_rewrite_scheduled 属性的值为 1 时,表示执行 BGREWRITEAOF 命令超时了。在服务器执行 BGSAVE 命令时,如果客户端发送了 BGREWRITEAOF 命令请求,那么服务器在接收到命令请求之后,会将 BGREWRITEAOF 命令延迟到 BGSAVE 命令执行成功后再执行。
在每次执行 serverCron 函数时,都会判断 BGSAVE 或 BGREWRITEAOF 命令是否正在被执行。如果它们没有被执行,同时 aof_rewrite_scheduled 属性的值为 1,那么被延迟的BGREWRITEAOF 命令将会被执行。
6.5 Redis 服务器的启动过程
一台 Redis 服务器从启动到能够接收客户端的命令请求,需要经过一系列的初始化和 设置过程,大致需要经过以下几步。
6.5.1 服务器状态结构的初始化
服务器状态结构的初始化会创建一个 struct redisServer 类型的实例变量 server 作为服务器的状态,同时为结构中的其他属性设置默认值。由 redis.c/initServerConfig 函数来初始化server 变量。initServerConfig 函数的主要任务是设置服务器的运行 ID、默认运行频率、默认配置文件路径、运行架构、默认端口、默认 RDB 持久化条件和 AOF 持久化条件及初始化 LRU 时钟,同时创建命令表,为服务器的后续运行做好准备。initServerConfig 函数设置的服务器属性都是最基本的,这些属性的值都是一些整数、浮点数或字符串值。该函数除创建命令表之外,并不会创建其他,比如,它不会创建数据库。
6.5.2 相关配置参数的加载
在服务器的 initServerConfig 函数完成 server 变量的初始化后,就会开始加载配置参数,同时根据用户指定的配置参数,对 server 变量的属性进行修改。比如,我们在启动 Redis 服务器之前,修改 redis.conf 配置文件,修改的内容如下:
#修改数据库的默认数量为 20 个
databases 20
#关闭 RDB 文件的压缩功能
rdbcompression no
在修改完配置文件之后,启动服务器,服务器中的数据库数量就会变为 20 个,同时 RDB 持久化压缩功能就会被关闭。
6.5.3 服务器数据结构的初始化
在加载完相关配置参数之后,服务器会调用 initServer 函数为以下服务器数据结构分配内存及设置初始化值。
● server.clients 链表:该链表用于记录所有与服务器相连的客户端的状态结构,链表的每个节点都包含一个 redisClient 结构的实例。
● server.pubsub_channels 字典:该字典用于保存频道订阅消息。
● server.pubsub_patterns 链表:该链表用于保存模式订阅消息。
● server.lua 属性:该属性用于执行 Lua 脚本的运行环境。
● server.slowlog 属性:该属性用于保存慢查询日志。
服务器在初始化的过程中,分别调用了 initServerConfig 和 initServer 函数,其中,initServerConfig 函数主要用于初始化一些基本属性,initServer 函数主要用于初始化一些数据结构。在初始化的过程中,要考虑到用户的输入情况,所以服务器必须先加载用户输入的配置信息,再按照用户的意愿来初始化相关的数据结构。而如果在执行 initServerConfig函数时就对数据结构进行初始化,此时用户恰好修改了和数据结构有关的服务器状态属性,那么服务器又要重新修改已创建的数据结构。为了避免此类情况的发生,服务器将初始化过程拆分为两步。
服务器的 initServer 函数除初始化数据结构之外,还执行以下相关操作。
● 设置服务器的进程信号处理器。
● 初始化服务器的后台 I/O 模块,为 I/O 操作做准备。
● 创建相关的共享对象。这些共享对象在服务器中常常用到,比如,创建返回值为“OK”或“ERR”的字符串对象,创建包含整数 1~10000 的字符串对象等。这些共享对象的创建避免了服务器的反复创建。
● 打开服务器的监听端口,并为监听套接字关联连接应答事件处理器,等待服务器正式运行时接收客户端的连接。
● 为 serverCron 函数创建时间事件,等待服务器正式运行时执行 serverCron 函数。
● 为 AOF 文件的写入做好准备。如果已经打开了 AOF 持久化功能,那么直接打开已
经存在的 AOF 文件;如果 AOF 文件不存在,则创建一个新的 AOF 文件,并打开它。当 initServer 函数执行完这些操作之后,服务器将会采用 ASCII 字符在日志中打印出Redis 的图标,以及 Redis 的版本号、端口号等信息,如图 6.7 所示。
6.5.4 数据库状态的处理
当服务器的 initServer 函数完成初始化工作之后,需要加载 RDB 文件或 AOF 文件,并按照文件记录的相关内容来还原数据库状态。根据是否启用了 AOF 持久化功能,服务器加载数据时所使用的目标文件也会不同。
● 如果 AOF 持久化功能被开启了,服务器就会使用 AOF 文件来还原数据库状态
● 如果 AOF 持久化功能没有被开启,服务器就会使用 RDB 文件来还原数据库状态。 服务器在完成数据库状态还原之后,就会打印出加载目标文件及还原数据库状态所用 的时间。日志信息如下: 20990:M 11 Jun 07:44:57.165 * DB loaded from disk: 0.000 seconds
6.5.5 执行服务器的循环事件
最后,服务器打印出如下日志:
20990:M 11 Jun 07:44:57.165 * Ready to accept connections
至此,表示服务器已经成功启动了,它将开始执行服务器的循环事件,并开始接收客户端的命令请求。到这里, Redis 客户端与服务器的相关知识点就讲解完了,相信读者已经有了深入的了解。加油!你的付出不会白费,它将会以另一种形式回报给你!
7.redis底层数据结构
本章将深入 Redis 的底层实现,讲解 Redis 中字符串、链表、字典、对象的底层实现原 理,剖析它们底层实现的数据结构,帮助读者熟悉它们的实现过程、相关的 API,以及对 象的编码方式等。
7.1 Redis 简单动态字符串
我们已经知道,Redis 数据库是由 C 语言编写实现的,它底层实现的代码具有 C 语言的特点及语法。C 语言中具有字符串数据类型,Redis 数据库中也有。但是 Redis 数据库并没有直接使用 C 语言中的字符串表示,而是自己重新构建了一种名为简单动态字符串(SDS)的抽象类型,并将其用作 Redis 的默认字符串表示。
7.1.1 SDS 的实现原理
在 Redis 中,C 语言字符串通常用作字符串字面量,用在对字符串值不需要修改的地方,比如打印日志。当 Redis 需要一个可以被修改的字符串值时,它就会使用 SDS 来表示字符串值。Redis 数据库采用 SDS 实现底层字符串值的键值对。执行以下命令:
127.0.0.1:6379>SET userName "liuhefei"
OK
在将字符串 userName 的值添加到 Redis 数据库的过程中,会创建一个新的键值对,这个键值对的键是一个字符串对象,其底层实现是一个保存着字符串“userName”的 SDS;而这个键值对的值也是一个字符串对象,其底层实现是一个保存着字符串“liuhefei”的 SDS。
SDS 不仅可以用来保存数据库中的字符串值,还可以用于实现 AOF 模块下的 AOF 缓冲区(Buffer),以及实现客户端状态的输入缓冲区。
SDS 是一个 C 语言结构体,位于 Redis 安装包的 src 目录下,每个 sds.h/sdshdr 结构表
示一个 SDS 值,它的底层源代码如下:
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
通过 SDS 的底层源代码可以看出,它定义了多个不同类型的结构体,来适应不同场景需求。它的结构体有 4 个参数,分别如下。
● len:len 属性记录了 buf 数组中已使用的字节数量,也就是 SDS 所保存字符串的长度。比如,len 属性值为 7,表示这个 SDS 中保存了一个 7 字节长的字符串。
● alloc:alloc 属性记录了 buf 数组中没有使用的字节数量。比如,alloc 属性值为 0,表示没有为这个 SDS 分配任何使用空间。
● flags:flags 属性是一个标识。
● buf[]:buf 属性是一个 char 类型的数组,用于以二进制的形式保存字符串。比如,保存的字符串是“liuhefei”,buf 数组的保存形式是’l’、‘i’、‘u’、‘h’、‘e’、‘f’、‘e’、‘i’ 8 个字符,而最后 1 字节用于保存空字符 ‘\0’。
SDS 采用了 C 语言中以空字符结尾的形式来保存字符串,保存空字符的 1 字节空间不计算到 SDS 的 len 属性中。在 Redis 中,SDS 函数会为这个空字符另外分配 1 字节空间,并且会将这个空字符添加到字符串的结尾。Redis 采用 C 语言字符串结尾添加空字符的优点是,SDS 函数可以直接使用一部分 C 语言字符串库函数中的函数。
C 语言字符串中的字符必须符合某种编码(如 ASCII)方式,并且字符串中除末尾可以有空字符之外,其他地方不能出现空字符。如果出现空字符,那么这个空字符将会被认为是一个字符串的结束标识。这些限制导致 C 语言字符串只能保存文本数据,而不能保存二进制文件,如音频、视频、图片及压缩文件等。因此,我们可以知道,C 语言是二进制不安全的。而 Redis 作为一个键值对存储数据库,为了适应不同的存储需求,它不能原模原样地采用 C 语言的字符串语法格式,而是自己重新构建了简单动态字符串(SDS)的抽象类型,所以 SDS 对应的 API 是二进制安全的。所有 SDS API 在处理数据时,都会以二进制的方式来处理 SDS 存储到 buf 数组中的数据,这些数据在保存的过程中不会受到任何限制、过滤,数据写入时是什么样的,读取出来就是什么样的。
C 语言字符串与 SDS 的区别总结如下:
(1)C 语言字符串的 API 是二进制不安全的,可能会存在缓冲区溢出;它只能保存文本数据;可以使用
(2)SDS 的 API 是二进制安全的,它不会造成缓冲区溢出;它可以存储文本数据或二进制数据;可以使用
7.1.2 SDS API 函数
SDS API 函数列举如下。
● sdsnew 函数:使用该函数创建一个 SDS,这个 SDS 中包含给定的 C 语言字符串。
● sdsempty 函数:使用该函数创建一个空的 SDS,它里面没有任何东西。
● sdslen 函数:该函数用于获取 SDS 中已经使用完的空间字节数。它可以通过 SDS的 len 属性获取。
● sdsfree 函数:该函数用于释放指定的 SDS。
● sdsclear 函数:该函数用于清空(删除)SDS 中保存的字符串。
● sdsdup 函数:该函数用于创建一个指定的 SDS 的副本,也就是复制一份。
● sdscat 函数:该函数用于在 SDS 字符串的结尾拼接一个给定的 C 语言字符串。
● sdscatsds 函数:该函数用于将给定的 SDS 字符串拼接到另一个 SDS 字符串的结尾。
● sdsavail 函数:该函数用于获取 SDS 字符串空间未使用的字节数。这个值可以通过读取 SDS 的 alloc 属性来获取。
● sdscmp 函数:该函数用于比较两个 SDS 字符串是否相同。
● sdstrim 函数:该函数具有两个参数,一个参数是 SDS 字符串,另一个参数是 C 语言字符串。sdstrim 函数会从 SDS 字符串中移除所有在 C 语言字符串中出现过的字符。
● sdscpy 函数:该函数用于将指定的 C 语言字符串复制到 SDS 里面,它会覆盖原有的字符串。
● sdsrange 函数:该函数用于保留给定区间内的 SDS 数据,不在这个区间内的数据将 会被删除或覆盖。 ● sdsgrowzero 函数:该函数用于将 SDS 字符串扩展到指定的长度,采用空字符填充。
7.2 Redis 链表
链表是一种最常用的数据结构,它由多个离散分配的节点组成,节点之间通过指针相 连,每个节点都有一个前驱节点和后继节点,但第一个头节点没有前驱节点,最后一个尾 节点没有后继节点。很多计算机高级语言都内置了链表结构,但是 C 语言中没有内置链表 结构,因此 Redis 自己构建了链表结构,用于适应不同的业务类型。
7.2.1 Redis 链表实现原理
在 Redis 中,多处用到了链表结构,比如,列表键的底层实现,就是当一个列表键包含了许多元素,或者列表键包含的元素都是一些比较长的字符串时,Redis 就会使用链表结构来作为列表键的底层实现。又如,Redis 消息订阅发布、监视器、慢查询等相关功能的底层实现都采用了链表结构。除此之外,Redis 服务器也使用链表来保存多个客户端的状态信息,以及采用链表来构建客户端的输出缓冲区等。
下面我们将多个学生的姓名添加到列表键 students 中,列表键 students 所包含的内容底层就是采用链表结构实现的,操作如下:
127.0.0.1:6379> DEL students
(integer) 1
127.0.0.1:6379> LPUSH students "liuyi" "xiaoer" "zhangsan" #添加多个学生
(integer) 3
127.0.0.1:6379> LPUSH students "lisi" "wangwu" "zhaoliu"
(integer) 6
127.0.0.1:6379> LPUSH students "tianqi" "huba" "lijiu"
(integer) 9
127.0.0.1:6379> LLEN students #获取学生的人数
(integer) 9
127.0.0.1:6379> LRANGE students 0 -1 #遍历所有的学生
1) "lijiu"
2) "huba"
3) "tianqi"
4) "zhaoliu"
5) "wangwu"
6) "lisi"
7) "zhangsan"
8) "xiaoer"
9) "liuyi"
1.链表的组成
每个链表节点都使用一个 adlist.h/listNode 结构来表示。
adlist.h 源码位于 Redis 安装目 录的 src 文件夹下,部分源码为:
typedef struct listNode {
struct listNode *prev; //表示头节点,或者上一个节点
struct listNode *next; //表示下一个节点
void *value; //节点的值
} listNode;
多个 listNode 节点通过 prev 和 next 指针相连接,组成单向链表 list,它们也可以组成 双向链表,Redis 采用的就是双向链表,如图 7.1 所示。
typedef struct list {
listNode *head; //表示链表头节点
listNode *tail; //表示链表尾节点
void *(*dup)(void *ptr); //链表节点值复制函数
void (*free)(void *ptr); //链表节点值释放函数
int (*match)(void *ptr, void *key); //对比函数,用于对比链表的节点值
unsigned long len; //表示链表所含有的节点数量,也就是链表的长度
} list;
多个节点组成一个链表 list,这个链表中含有表头指针 head、表尾指针 tail、链表长度len,以及 dup 函数、free 函数、match 函数。其中,
● dup 函数用于复制链表节点所保存的值。
● free 函数用于释放链表节点所保存的值。
● match 函数根据输入的值来和链表中保存的节点值进行比较,看是否相等。
2.链表的特点键表具有以下特点:
● 带有表头指针 head、表尾指针 tail 及链表长度计数器 len,这样获取链表的头节点、尾节点、长度就会比较方便。
● Redis 链表是双向链表,链表节点带有 prev 和 next 指针,可以很容易地获取到链表中的某个节点。
● 表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL。在访问链表的过程中,如果遇到 NULLL,则表示链表访问结束。
● Redis 链表可以保存各种不同类型的值,链表节点使用 void*指针来保存节点的值,链表中的 dup、free、match 函数可以为节点值设置类型特定函数,实现节点值的复制、释放、比较操作。
7.2.2 链表 API 函数
链表 API 函数列举如下。
● listCreate 函数:该函数用于创建一个空的新链表,它不包含任何节点元素。
● listFirst 函数:该函数用于获取链表的表头节点,也可以通过链表的 head 属性获得。
● listLast 函数:该函数用于获取链表的表尾节点,也可以通过链表的 tail 属性获得。
● listLength 函数:该函数用于获取链表的长度,也可以通过链表的 len 属性获得。
● listPrevNode 函数:该函数用于获取给定节点的上一个节点,也可以通过节点的 prev属性获得。
● listNextNode 函数:该函数用于获取给定节点的下一个节点,也可以通过节点的 next属性获得。
● listNodeValue 函数:该函数用于获取给定节点中保存的值,也可以通过节点的 value属性获得。
● listAddNodeHead 函数:该函数用于在指定链表的表头插入一个给定的节点。
● listAddNodeTail 函数:该函数用于在指定链表的表尾插入一个给定的节点。
● listInsertNode 函数:该函数用于将一个包含给定值的新节点插入指定节点的前面或后面。
● listIndex 函数:该函数用于返回链表在给定索引上的节点。
● listSearchKey 函数:该函数用于在链表中查找给定的节点,查找到就将它返回。
● listRotate 函数:该函数用于获取链表的表尾节点,然后将获取到的节点插入链表的表头,成为新的表头节点。
● listDelNode 函数:该函数用于删除链表中指定的节点。
● listDup 函数:该函数用于复制一个给定链表的副本。
● listRelease 函数:该函数用于释放指定的链表,包含这个链表的全部节点。
● listSetDupMethod 函数:该函数用于将指定的函数设置为链表的节点值复制函数。这个复制函数可以使用链表的 dup 属性获得。
● listGetDupMethod 函数:该函数用于获取链表中正在使用的节点值复制函数。
● listSetFreeMethod 函数:该函数用于将指定的函数设置为链表的节点值释放函数。这个释放函数可以使用链表的 free 属性获得。
● listGetFree 函数:该函数用于获取链表中正在使用的节点值释放函数。
● listSetMatchMethod 函数:该函数用于将指定的函数设置为链表的节点值对比函数。这个对比函数可以使用链表的 match 属性获得。
● listGetMatchMethod 函数:该函数用于获取链表中正在使用的节点值对比函数。
7.3 Redis 压缩列表
Redis 的压缩列表(ziplist)是列表键和哈希键的底层实现之一。
7.3.1 压缩列表的实现原理
当一个列表键包含的元素比较少时,且这些列表元素要么是小整数值,要么是短字符串, Redis 就会采用压缩列表来实现这个列表键的底层。
当一个哈希键包含的键值对比较少时,且每个键值对的键和值要么是小整数值,要么是短字符串,Redis 就会采用压缩列表来实现这个哈希键的底层。
向 Redis 数据库中添加一条用户信息,用于创建一个底层采用压缩列表实现的哈希键,操作如下:
27.0.0.1:6379> HMSET user userName "liuhefei" passWord "123456" age 24 height 172
weight 140 #向数据库中添加一条用户信息,包括用户名、密码、年龄、身高、体重
OK
127.0.0.1:6379> HMGET user userName passWord age height weight #获取用户的用户名、密
码、年龄、身高、体重
1) "liuhefei"
2) "123456"
3) "24"
4) "172"
5) "140"
127.0.0.1:6379> OBJECT ENCODING user #查看键 user 的底层实现
"ziplist" #压缩列表
1.压缩列表模型图
在 Redis 中,压缩列表是一个顺序型数据结构,它由一系列特殊编码的连续内存块组成,它是为节省内存而开发的。一个压缩列表可以包含任意多个节点,每个节点都可以保存一个整数值或者一个字节数组。压缩列表模型图如图 7.2 所示。

●zlbytes 属性:该属性记录了整个压缩列表所占用的内存字节数,是一个 uint32_t 类型的4 字节数值。压缩列表在进行内存分配或计算 zlend 的位置时,才会使用 zlbytes 属性。
● zltail 属性:该属性记录了压缩列表的表尾节点距离压缩列表的起始地址有多少字节,是一个 uint32_t 类型的 4 字节数值。通过 zltail 属性的值,程序不需要遍历整个压缩列表,就可以确定表尾节点的地址。
● zllen 属性:该属性记录了整个压缩列表所包含的节点数量,它是一个 uint16_t 类型的 2 字节数值。当 zllen 属性的值小于 UINT16_MAX(65535)时,这个属性的值就是压缩列表所包含的节点数量。当 zllen 属性的值等于 UINT16_MAX 时,需要遍历这个压缩列表才能计算出压缩列表所包含的节点数量。
● entry 属性:该属性表示压缩列表的节点,一个压缩列表有任意多个节点,节点的长度取决于节点保存的内容。
● zlend 属性:该属性是一个特殊值 0xFF(对应的十进制数是 255),用于标识压缩列表的末端,是一个 uint8_t 类型的 1 字节数值。
2.压缩列表节点模型图
每个压缩列表节点都可以保存一个整数值或一个字节数组。
可以保存的整数值有多种,具体如下:
● 4 位长、介于 0~12 之间的无符号整数。
● 1 字节长的有符号整数。
● 3 字节长的有符号整数。
● int16_t 类型整数。
● int32_t 类型整数。
● int64_t 类型整数。
可以保存的字节数组可以是以下 3 种长度中的一种:
● 长度小于或等于 63(2^6-1)字节的字节数组。
● 长度小于或等于 16 383(2^14-1)字节的字节数组。
● 长度小于或等于 4 294 967 295(2^32-1)字节的字节数组。
如图 7.3 所示为压缩列表节点模型图

每个压缩列表节点都有 previous_entry_length、encoding、content 3 个属性。
● previous_entry_length 属性:用于记录压缩列表中前一个节点的长度,这个长度可以是 1 字节,也可以是 5 字节。该属性以字节为单位。
当压缩列表的前一个节点的长度小于 254 字节时,previous_entry_length 属性的长度为1 字节,这个字节保存了前一个节点的长度。
当压缩列表的前一个节点的长度大于或等于 254 字节时,previous_entry_length 属性的长度为 5 字节,其中第一个字节会被设置为 0xFF(对应十进制数 255),后面的 4 个字节用于保存前一个节点的长度。
● encoding 属性:该属性记录了节点的 content 属性所保存数据的类型及长度。
-
1 字节、2 字节或 5 字节长,这些字节数组编码的值的最高位是 00、01 或 10。以这种编码方式表示节点的 content 属性保存的是字节数组,这个字节数组的长度由编码除去最高两位之后的其他位记录。
-
以 00 开头的编码方式,1 字节,表示 content 属性保存的值是长度小于或等于 63 字节的字节数组。
-
以 01 开头的编码方式,2 字节,表示 content 属性保存的值是长度小于或等于 16 383字节的字节数组。
-
以 10 开头的编码方式,5 字节,表示 content 属性保存的值是长度小于或等于 4 294 967 295
字节的字节数组。 -
1 字节长,值的最高位以 11 开头的整数编码,表示 content 属性保存的数据是整数数值,整数数值的类型和长度由编码除去最高两位之后的其他位记录。
编码方式不同,content 属性保存的整数值的类型也就不同。
如表 7.1 所示为 1 字节整数编码对应的 content 属性中保存的值类型

● content 属性:该属性用于保存压缩列表节点的值。节点的值可以是一个整数,也可以是一个字节数组,而节点的 encoding 属性决定了这个值的类型和长度。
7.3.2 压缩列表 API 函数
压缩列表 API 函数列举如下。
● ziplistNew 函数:该函数用于创建一个新的压缩列表。
● ziplistInsert 函数:该函数用于将包含给定值的新节点插入压缩列表指定节点的后面。
● ziplistPush 函数:该函数用于创建一个包含给定值的新节点,并将这个新节点插入压缩列表的表头或表尾。
● ziplistNext 函数:该函数用于获取压缩列表指定节点的下一个节点。
● ziplistPrev 函数:该函数用于获取压缩列表指定节点的上一个节点。
● ziplistIndex 函数:该函数用于获取压缩列表在给定索引上的节点。
● ziplistFind 函数:该函数用于在压缩列表中查找,并返回包含了指定值的节点。
● ziplistGet 函数:该函数用于获取给定节点所保存的值。
● ziplistDelete 函数:该函数用于在压缩列表中删除指定的值。
● ziplistDeleteRange 函数:该函数用于删除压缩列表在给定索引上的连续多个节点。
● ziplistLen 函数:该函数用于获取压缩列表所包含的节点数量。
● ziplistBlobLen 函数:该函数用于获取压缩列表目前所占用的内存字节数。
7.4 Redis 快速列表
在 Redis 3.2 版本中引入了新的数据结构——快速列表(quicklist),用于列表的底层实现。
7.4.1 快速列表的实现原理
将多个学生的数学成绩添加到数据库的列表 math-score 中,并使用命令查看列表的底层实现,操作如下
127.0.0.1:6379> RPUSH math-score 79 100 99 76 88 67 84 91 78 88 #添加学生成绩到列表
math-score 中
(integer) 10
127.0.0.1:6379> LRANGE math-score 0 -1 #遍历学生成绩
1) "79"
2) "100"
3) "99"
4) "76"
5) "88"
6) "67"
7) "84"
8) "91"
9) "78"
10) "88"
127.0.0.1:6379> OBJECT ENCODING math-score #查看列表键 math-score 的底层实现
"quicklist" #快速列表
快速列表是由压缩列表组成的双向链表,链表的每个节点都以压缩列表的结构来保存数据。压缩列表有任意多个 entry 节点,用于保存数据,因此快速列表可以保存更多的数据,你可以理解为它保存的是一片数据。
快速列表的定义位于 Redis 安装目录下 src 文件夹中的 quicklist.h 文件中,定义如下:
typedef struct quicklist {
//指向头部(最左边)quicklist 节点的指针
quicklistNode *head;
//指向尾部(最右边)quicklist 节点的指针
quicklistNode *tail;
//ziplist 中的 entry 节点计数器
unsigned long count; /* total count of all entries in all ziplists */
//quicklist 的 quicklistNode 节点计数器
unsigned int len; /* number of quicklistNodes */
//保存 ziplist 的大小,配置文件设定,占 16bits
int fill : 16; /* fill factor for individual nodes */
//保存压缩程度值,配置文件设定,占 16bits,0 表示不压缩
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
在快速列表的定义结构中,有 fill 和 compress 两个属性,其中“:”是位域运算符,表示 fill 占 int 类型 32 位中的 16 位,而 compress 也占 int 类型 32 位中的 16 位。fill 和 compress 属性在 Redis 的配置文件 redis.conf 中进行设置。
● fill 属性对应的配置参数是 list-max-ziplist-size -2。
list-max-ziplist-size 属性具有多个值,具体含义如下。
- 当设置为-1 时,表示每个 quicklistNode 节点的 ziplist 字节大小不能超过 4KB(建议使用)。
- 当设置为-2 时,表示每个 quicklistNode 节点的 ziplist 字节大小不能超过 8KB(默认配置)。
- 当设置为-3 时,表示每个 quicklistNode 节点的 ziplist 字节大小不能超过 16KB(一般不建议使用)。
- 当设置为-4 时,表示每个 quicklistNode 节点的 ziplist 字节大小不能超过 32KB(不建议使用)。
- 当设置为-5 时,表示每个 quicklistNode 节点的 ziplist 字节大小不能超过 64KB(正常工作量不建议使用)。
- 当设置为正数时,表示 ziplist 结构最多包含的 entry 节点个数,最大值为 215。
- compress 属性对应的配置参数是 list-compress-depth 0。list-compress-depth 属性具有多个值,具体含义如下。
- 当设置为 0 时,表示列表不压缩(默认设置)。
- 当设置为 1 时,表示快速列表除两端各有 1 个节点不压缩之外,其他的节点都压缩。
- 当设置为 2 时,表示快速列表除两端各有 2 个节点不压缩之外,其他的节点都压缩。
- 当设置为 3 时,表示快速列表除两端各有 3 个节点不压缩之外,其他的节点都压缩。
快速列表节点的结构定义如下:
typedef struct quicklistNode {
struct quicklistNode *prev; //前驱节点指针
struct quicklistNode *next; //后继节点指针
//当不设置压缩数据参数 recompress 时指向 ziplist 结构
//当设置压缩数据参数 recompress 时指向 quicklistLZF 结构
unsigned char *zl;
//压缩列表 ziplist 的总长度
unsigned int sz; /* ziplist size in bytes */
//ziplist 中包含的节点数,占 16bits 长度
unsigned int count : 16; /* count of items in ziplist */
//表示是否采用了 LZF 压缩算法压缩 quicklist 节点,1 表示压缩了,2 表示没压缩,占 2bits 长度
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
//表示一个 quicklistNode 节点是否采用 ziplist 结构保存数据,2 表示压缩了,1 表示没压缩,默认是 2,占 2bits 长度
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
//标记 quicklist 节点的 ziplist 之前是否被解压缩过,占 1bit 长度
//如果 recompress 为 1,则等待被再次压缩
unsigned int recompress : 1; /* was this node previous compressed? */
//测试时使用
unsigned int attempted_compress : 1; /* node can't compress; too small */
//额外扩展位,占 10bits 长度
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
7.4.2 快速列表 API 函数
快速列表 API 函数列举如下。
● quicklistCreate 函数:该函数用于创建一个新的快速列表。
● quicklistSetCompressDepth 函数:该函数用于对指定的快速列表设置压缩程度。
● quicklistSetFill 函数:该函数用于对指定的快速列表设置 ziplist 结构的大小。
● quicklistSetOptions 函数:该函数用于为给定的快速列表设置压缩列表表头的 fill 和compress 属性。
● quicklistNew 函数:该函数用于创建一个新的快速列表,并为其设置默认的参数。
● quicklistCreateNode 函数:该函数用于创建一个快速列表的节点(quicklistNode),并初始化。
● quicklistCount 函数:该函数用于统计 ziplist 结构中 entry 节点的个数。
● quicklistRelease 函数:该函数用于释放给定的快速列表。
● quicklistPushHead 函数:该函数用于追加一个 entry 节点到快速列表的头部。
● quicklistPushTail 函数:该函数用于追加一个 entry 节点到快速列表的尾部。如果追加失败,则新创建一个 quicklistNode 节点。
● quicklistAppendZiplist 函数:该函数用于为给定的快速列表追加一个 quicklist 节点。
● quicklistDelEntry 函数:该函数用于删除 ziplist 结构中的 entry 节点。
● quicklistReplaceAtIndex 函数:该函数用于在给定的快速列表中,将下标为 index 的值替换为 data 值。
● quicklistDelRange 函数:该函数用于在给定的快速列表中删除某个范围内的 entry 节点,返回 1 表示全部被删除,返回 0 表示删除败。
● quicklistRotate 函数:该函数用于将尾 quicklistNode 节点的尾 entry 节点旋转到头quicklistNode 节点的头部。
7.5 Redis 字典
Redis 字典是一种用于保存 Redis 键值对的抽象数据结构,它是一种键值对的映射,有时也被称为符号表、关联数组等。在字典中,一个键与一个值进行关联,键与值是一一对应的,你可以理解为键映射为值,键与值进行关联,就称为键值对。字典中的每个键都是唯一的,不可能存在两个相同的键,我们可以根据这个键来查找它对应的值,也可以通过这个键来修改、删除它对应的值。
7.5.1 字典的实现原理
字典作为一种常用的数据结构,内置在多种高级计算机语言中,但是 C 语言并没有内置字典数据结构,因此 Redis 根据需要构建了自己的字典。字典在 Redis 中得到了广泛应用,其中 Redis 数据库的底层就是采用字典实现的,对数据库中数据的增、删、改、查操作就是建立在字典的基础上的。同时,Redis 哈希键的底层也是采用字典实现的。当一个哈希键包含的键值对比较多,或者键值对中的元素是比较长的字符串时,Redis 就会采用字典作为哈希键的底层实现。比如,执行以下命令:
127.0.0.1:6379>SET name "liuhefei"
OK
键“name”和值“liuhefei”在数据库中就是以键值对的形式存储在字典中的。下面向 Redis 数据库中再添加一条用户的详细信息,这条信息具体包含用户的用户名、密码、年龄、生日、身高、体重、电话号码、地址等多个键值对信息,操作如下:
127.0.0.1:6379> HMSET user1 userName "zhangsan" passWord "123456" age 20 birthday
"1994-01-01" #添加用户信息到哈希表 user1 中
OK
127.0.0.1:6379> HMSET user1 height 172 weight 140 mobile "18296666666" address
"beijing"
OK
127.0.0.1:6379> HGETALL user1 #获取哈希表 user1 中的键值对信息
1) "userName" #键
2) "zhangsan" #值
3) "passWord"
4) "123456"
5) "age"
6) "20"
7) "birthday"
8) "1994-01-01"
9) "height"
10) "172"
11) "weight"
12) "140"
13) "mobile"
14) "18296666666"
15) "address"
16) "beijing"
127.0.0.1:6379> HLEN user1 #获取哈希表 user1 的长度
(integer) 8
当哈希表 user1 中的键值对数量足够多时,Redis 就会使用字典来存储这些信息,这个字典中包含多个键值对,例如,键值对的键为“userName”,值为“zhangsan”。
Redis 采用哈希表实现了字典的底层。一个哈希表中有多个哈希表节点,而每个哈希表节点中就保存了字典中的一个键值对。Redis 字典所使用的哈希表由 dict.h/dictht 结构定义,dict.h 文件位于 Redis 安装包的 src 目录下,部分源码如下:
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
结构元素说明如下。
● table 属性:这是一个哈希表数组,数组中的每个元素都是一个指向 dict.h/dictEntry结构的指针,每个 dictEntry 结构中保存一个键对。
● size 属性:该属性用于记录 table 数组的长度,也就是哈希表的大小。
● sizemask 属性:这是哈希表大小掩码,用来计算索引值,它的值总是等于 size-1。sizemask 属性与哈希值共同决定一个键应该放到 table 数组的哪个索引上。
● used 属性:该属性用于记录哈希表上已经存在的节点(键值对)数量。使用 dictEntry 结构表示哈希表节点,一个键值对保存在一个 dictEntry 结构中。dictEntry
结构的部分源码如下:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
结构元素说明如下。
● key 属性:该属性用于保存键值对中的键。
● v 属性:该属性用于保存键值对中的值。键值对中的值可以是一个指针(*val),也可以是一个无符号的 64 位整数(u64),也可以是一个 64 位的整数(s64),还可以是一个 double 类型的值(d)。
● next 属性:该属性是一个指针,用于指向另一个哈希表节点。这个指针可以将多个
哈希值相同的键值对连接在一起,还可以解决键冲突问题。
Redis 中的字典由 dict.h/dict 结构表示,位于 Redis 安装包的 src 目录下,源码如下:
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
结构元素说明如下。
● type 属性:该属性用于指向 dictType 结构,它是一个指针。每个 dictType 结构中保存一组用于操作特定类型键值对的函数。Redis 会根据用途不同的字典,设置不同的类型特定函数。
● privdata 属性:该属性用于保存需要传递给那些类型特定函数的可选参数。type 和 privdata 属性是为创建多态字典而设置的,二者针对不同类型的键值对。
● ht[2]属性:该属性是一个包含两个数组元素的数组,数组中的每个元素都是一个dictht 哈希表。通常,字典只使用 ht[0]哈希表,而只有在对 ht[0]哈希表进行 rehash重新散列)时,才会用到 ht[1]哈希表。
● rehashids 属性:该属性用于记录 rehash 目前的进度。如果现在没有进行 rehash,那么它的值为-1。
● iterators 属性:该属性表示当前运行的迭代器数。
dictType 结构的源码定义如下:
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
结构元素说明如下。
● uint64_t (*hashFunction)(const void *key);:该函数用于计算哈希值,返回值类型为无符号整型。
● void *(*keyDup)(void *privdata, const void *key);:该函数用于复制键,返回值类型为void(空类型)。
● void *(*valDup)(void *privdata, const void *obj);:该函数用于复制值,返回值类型为 void。
● int (*keyCompare)(void *privdata, const void *key1, const void *key2);:该函数用于比对键值对中的键,看是否相同,返回值类型为 void。
● void (*keyDestructor)(void *privdata, void *key);:该函数用于销毁键值对中的键,返回值类型为 void。
● void (*valDestructor)(void *privdata, void *obj);:该函数用于销毁键值对中的值,返回值类型为 void。
如果要将一个新的键值对添加到字典中,那么程序需要先根据键值对中的键计算出哈希值和索引值,再根据索引值将包含新键值对的哈希表节点放到哈希表数组的指定索引上。
Redis 计算哈希值和索引值的步骤如下。
(1)使用字典设置的哈希函数,计算出键值对中键的哈希值。
hash = dict -> type ->hashFunction(key);
(2)利用哈希表的 sizemask 属性和哈希值,计算出索引值。
index = hash & dict ->ht[x].sizemask;
其中,ht[x]可以是 ht[0],也可以是 ht[1]。
这就是 Redis 的哈希算法。
当数据库或哈希键的底层采用字典实现时,Redis 计算键的哈希值会使用 MurmurHash2算法实现。关于 Redis 哈希键及哈希表的更多相关底层知识,请读者自行查阅相关资料。
7.5.2 字典 API 函数
字典 API 函数列举如下。
● dictCreate 函数:该函数用于创建一个新的字典。
● dictAdd 函数:该函数用于添加一个给定的键值对到字典中。
● dictDelete 函数:该函数根据给定的键删除字典中与之对应的键值对。
● dictFetchValue 函数:该函数用于获取字典中给定键所对应的值。
● dictGetRandomKey 函数:该函数用于从字典中随机返回一个键值对。
● dictReplace 函数:该函数用于将给定的键值对添加到字典中。如果这个字典中已经存在给定的键,那么旧值将会被新值覆盖。
● dictRelease 函数:该函数用于释放给定的字典,包含字典中的所有键值对。换句话说,就是清空字典中的所有键值对
7.6 Redis 整数集合
Redis 集合键的底层实现有多种方式,其中一种是整数集合(intset)。当一个集合只包含整数值元素,同时这个集合中的元素数量不是太多时,Redis 就会采用整数集合来实现这个集合键的底层。
下面将多个学生的成绩添加到集合 score 中,并查看集合 score 的底层实现,操作如下:
127.0.0.1:6379> SADD score 60 75 70 80 89 90 100 92 81 73 #添加学生成绩到集合score 中
(integer) 10
127.0.0.1:6379> SMEMBERS score #获取集合 score 中的所有元素
1) "60"
2) "70"
3) "73"
4) "75"
5) "80"
6) "81"
7) "89"
8) "90"
9) "92"
10) "100"
127.0.0.1:6379> OBJECT ENCODING score #查看集合 score 的底层实现
"intset"
执行 OBJECT ENCODING score 命令后,返回 intset,说明集合 score 的底层实现采用的是整数集合。
7.6.1 整数集合的实现原理
Redis 底层使用整数集合来保存整数值类型的集合键(set 集合)。整数集合(intset)可以保存 int16_t、int32_t、int64_t 类型的整数值,且整数集合元素不可重复。位于 Redis 安装包的 src 目录下的 intset.h/intset 结构表示一个整数集合,该结构的定义如下:
//整数集合结构
typedef struct intset {
//编码方式
uint32_t encoding;
//集合中所包含的元素数量
uint32_t length;
//保存集合元素的数组
int8_t contents[];
} intset;
属性说明如下。
● encoding 属性:该属性用于定义整数集合的编码方式,不同的编码方式决定了整数集合可以保存什么类型的集合元素。它具有多个属性值,具体有 INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT64。
● length 属性:该属性记录了整数集合所包含的元素数量,也就是 contents 数组的长度。
● contents 属性:该属性是一个声明为 int8_t 类型的数组,但是它并不保存任何 int8_t类型的值。contents 数组所能保存的集合元素的类型取决于 encoding 属性的值。
- 当 encoding 属性的值为 INTSET_ENC_INT16 时,contents 数组的类型为 int16_t,数组中的每个元素都是一个 int16_t 类型的整数值,此时 contents 数组的大小为sizeof(int16_t)×length。这个数组所能存放的整数值范围是:最小值为-32 768,最大值为 32 767。
- 当 encoding 属性的值为 INTSET_ENC_INT32 时,contents 数组的类型为 int32_t,数组中的每个元素都是一个 int32_t 类型的整数值,此时 contents 数组的大小为sizeof(int32_t) ×length。这个数组所能存放的整数值范围是:最小值为-2 147 483 648,最大值为 2 147 483 647。
- 当 encoding 属性的值为 INTSET_ENC_INT64 时,contents 数组的类型为 int64_t,数组中的每个元素都是一个 int64_t 类型的整数值,此时 contents 数组的大小是sizeof(int64_t) ×length。这个数组所能存放的整数值范围是:最小值为-9 223 372 136 854 775 808,最大值为9 223 372 036 854 775 807。
如图 7.4 所示为一个含有 6 个 int32_t 类型整数值的整数集合。

在图 7.4 中,eccoding 属性的属性值为 INTSET_ENC_INT32,表示这个整数集合的底
层实现为 int32_t 类型的数组,而这个数组中保存的元素都是 int32_t 类型的。
length 属性的值为 6,表示这个整数集合包含 6 个集合元素。
contents 数组按照从小到大的顺序依次存储整数集合的元素,contents 数组的大小为sizeof(int32_t) ×length = 32×6 = 192(位)。
现有一个类型为 int16_t 的整数集合,如果要向这个集合中添加类型为 int64_t 的集合元素,那么 Redis 的底层是如何实现的呢?
这个过程涉及整数集合元素的类型转化问题。int16_t 类型的整数元素要转化为 int64_t类型的整数元素,Redis 的底层是这样实现的:
(1)根据新添加元素的类型(这里为 int64_t),扩展这个整数集合底层数组的空间大小,同时为这个新元素分配空间。
(2)将底层数组原有的所有元素都转化为与新元素相同的类型(这里是将 int16_t 类型的元素转化为 int64_t 类型的元素),并将类型转化后的元素按照从小到大的顺序依次放置到正确的位置上,以保证底层数组的有序性。
(3)将新元素添加到底层数组中,这个整数集合类型就由最初的 int16_t 类型转化为int64_t 类型了。
以上这个过程就是将一个低类型的整数集合转化为高类型的整数集合的过程。整数集合的类型由高到低为:int64_t > int32_t > int16_t。
注意:Redis 整数集合的底层并不支持高类型的整数集合转化为低类型的整数集合。一旦整数集合由低类型转化为高类型之后,整数集合的编码就会一直保持为转化后的状态,就不可能再转化为低类型的整数集合了。
7.6.2 整数集合 API 函数
整数集合 API 函数列举如下。
● intsetNew 函数:该函数用于创建一个新的整数集合。
● intsetAdd 函数:该函数用于将指定的整数元素添加到整数集合中。
● intsetGet 函数:该函数用于获取底层数组在给定索引上的元素。
● intsetLen 函数:该函数用于获取整数集合所包含的元素数量。
● intsetRemove 函数:该函数用于删除整数集合中指定的元素。
● intsetFind 函数:该函数用于判断给定的元素是否存在于整数集合中。
● intsetRandom 函数:该函数用于从整数集合中随机返回一个元素。
● intsetBlobLen 函数:该函数用于返回整数集合所占用的内存字节数。
7.7 Redis 跳表
Redis 跳表是一种有序数据结构,它的每个节点中具有多个指向其他节点的指针,利用这些指针可以实现快速访问节点的目的。它不仅支持快速节点查找,还可以通过顺序性操作批量处理节点。
7.7.1 跳表的实现原理
Redis 采用跳表实现了有序集合的底层。如果一个有序集合包含的元素数量众多,或者有序集合元素的成员是比较长的字符串,Redis 就会采用跳表作为这个有序集合的底层实现。下面的有序集合 citys 记录了中国 600 座城市的名称,以各城市的 GDP(亿元)作为分值,列举部分城市如下
127.0.0.1:6379> ZRANGE citys 0 5 WITHSCORES
1) "haerbin-GDP"
2) "8645"
3) "dalian-GDP"
4) "9897"
5) "nanjing-GDP"
6) "10034"
7) "tianjin-GDP"
8) "11203"
9) "wuhan-GDP"
10) "12654"
11) "shenzhen-GDP"
12) "14321"
有序集合citys的所有数据都保存在一个跳表中,每个跳表节点都保存一座城市的GDP信息。跳表数据结构主要用在 Redis 的有序集合和集群节点中。Redis 的跳表由 redis.h/zskiplistNode 和 redis.h/zskiplist 结构定义,其中 zskiplistNode 结构用于表示跳表的节点,zskiplist 结构用于保存跳表节点的相关信息,比如,保存节点的数量,以及指向表头节点和表尾节点的指针等。zskiplist 结构具有如下属性。
● header 属性:该属性用于指向跳表的表头节点。
● tail 属性:该属性用于指向跳表的表尾节点。
● level 属性:该属性用于记录在目前的跳表内,除表头节点所在层数之外,层数最大的节点层数。
● length 属性:该属性用于记录跳表的长度,也就是跳表中的节点数量,不包含表头节点。
zskiplistNode 结构的定义如下
typedef struct zskiplistNode {
//层
struct zskiplistLevel {
struct zskiplistNode *forward; //前进指针
unsigned int span; //跨度
}level[];
//后退指针
struct zskiplistNode *backward;
//分数
double score;
//成员对象
robj *obj;
} zskiplistNode;
属性说明如下。
● level 属性:该属性是一个数组,表示跳表中的层。数组中可以包含多个元素,每个元素都包含一个指向其他节点的指针,程序通过这些层可以快速地访问到其他节点,层数越多,访问其他节点的速度越快。在创建新的跳表节点的时候,程序会根据幂次定律(越大的数,出现的概率越小)随机生成一个介于 1~32 之间的随机数作为level 数组的大小(数组长度),它也是层的高度。
每个层都带有两个属性:前进指针和跨度。
前进指针:level[i].forward 属性,它指向跳表的表尾,用于访问位于表尾方向的其他节点。
跨度:level[i].span 属性,层的跨度,它记录了前进指针所指向节点和当前节点的距离。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。两个节点之间的跨度越大,它们相距就越远。如果跨度为 0,则表示前进指针指向 NULL,它们没有连向任何节点。使用前进指针来实现遍历操作。使用跨度来计算排位(rank),就是在查找某个节点时,将访问过的所有层的跨度累计起来(累加和),这个结果数值就是目标节点在跳表中的排位。
● backward 属性:节点的后退指针,指向当前节点的前一个节点,它在程序从表尾向表头遍历节点时使用。每个节点只有一个后退指针,与前进指针有所不同,因此每次只能后退到前一个节点。
● score 属性:该属性表示跳表节点的分数,是一个双精度类型的浮点数。在跳表中,节点按各自所保存的分值从小到大进行排序。
● obj 属性:该属性表示跳表中节点所保存的成员对象,是一个指针,它指向一个保存着 SDS 值的字符串对象。
跳表的表头节点和其他节点的结构是一样的,比如,后退指针、分数和成员对象在表头节点中同样存在,但是表头的这些属性都不会被用到。在一个跳表中,各个节点所保存的成员对象必须是唯一的,但是多个节点的分数值却可以是相同的。如果多个节点的分数值是相同的,那么这些节点将会按照成员对象在字典序中的大小来进行排序,成员对象的
字典序比较小的节点会排在跳表的前面,而成员对象的字典序比较大的节点会排在跳表的后面。
多个跳表节点组成跳表。Redis 使用 zskiplist 结构来管理这些跳表节点,使得程序可以很
方便地对整个跳表进行处理,比如,快速访问跳表节点、快速获取跳表中的节点数量等。
zskiplist 结构的定义如下:
typedef struct zskiplist {
//跳表的表头节点和表尾节点
structz skiplistNode *header, *tail;
//跳表中的节点数量
unsigned long length;
//跳表中层数最大的节点层数
int level;
}zskiplist;
属性说明如下。
● header 指针用于指向跳表的表头节点,而 tail 指针用于指向跳表的表尾节点。通过header 和 tail 指针,程序可以快速查找跳表中的任何一个节点。
● length 属性:该属性是一个无符号的长整型(long)数值,用于记录跳表中的节点数量。
● level 属性:该属性是一个 int 类型的数值,用于获取跳表中层数最大的节点层数,不计算表头节点的层高。
7.7.2 跳表 API 函数
跳表 API 函数列举如下。
● zslCreate 函数:该函数用于创建一个新的跳表。
● zslInsert 函数:该函数用于将包含给定成员和分数值的新节点插入跳表中。
● zslDelete 函数:该函数用于删除跳表中指定成员和分数值的节点。
● zslFree 函数:该函数用于释放指定的跳表,包含跳表中的所有节点,也就是清空跳表。
● zslGetRank 函数:该函数用于获取指定成员和分数值的节点在跳表中的排位。
● zslGetElementByRank 函数:该函数用于获取跳表在指定排位上的节点。
● zslFirstInRange 函数:该函数用于返回跳表中第一个符合给定一个分数值范围的节点。
● zslLastInRange 函数:该函数用于返回跳表中最后一个符合给定一个分数值范围的节点。
● zslIsInRange 函数:给定一个分数值范围(range),如 11~19,如果跳表中有至少一个节点的分数值在这个范围内,就返回 1;否则返回 0。换句话说,如果 zslIsInRange函数返回 1,则表示跳表中至少有一个节点符合给定范围的分数值。
● zslDeleteRangeByScore 函数:该函数用于给定一个分数值(score)范围,删除跳表中所有在这个分数值范围内的节点。
● zslDeleteRangeByRank 函数:该函数用于给定一个排位(rank)范围,删除跳表中所有在这个排位范围内的节点。
7.8 Redis 中的对象
前面几节介绍了 Redis 用到的几类数据结构,如简单动态字符串、链表、压缩列表、快速列表、字典、整数集合及跳表等。在 Redis 中,并没有直接使用这些数据结构来实现键值对存储数据库,而是在这些数据结构的基础上,创建了一个对象系统,这个对象系统中包含了 Redis 的 5 种数据对象,分别是字符串对象、列表对象、哈希对象、集合对象及有序集合对象。Redis 的每种数据对象都用到了前面介绍的至少一种数据结构。
通过这 5 种不同的数据对象,我们可以针对不同的使用场景,来为对象设置多种不同的数据结构的实现。Redis 在执行命令之前,一个对象是否可以执行给定的命令是根据对象的类型来判断的;Redis 的对象系统实现了基于引用计数技术的内存回收机制,当某个对象不再被程序使用的时候,这个对象所占用的内存空间就会被系统自动回收。
为了节省内存空间,使得多个数据库键可以共享同一个对象,Redis 通过引用计数技术实现了对象共享机制来解决这一问题。
Redis 的对象带有访问时间记录信息,它用于计算数据库键的空转时间。如果服务器启动了 maxmemory 功能,则空转时间较大的键可能会被服务器优先删除,以此来达到优化系统的目的。
7.8.1 对象类型
Redis 数据库中的键和值是由对象来表示的。每当我们在数据库中创建一个键值对时,系统至少会创建两个对象:一个对象用作键值对中的键(键对象);另一个对象用作键值对中的值(值对象)。比如,执行以下命令:
127.0.0.1 6379>SET username "liuhefei"
OK
上述命令将会创建两个对象:一个对象是键值对中的键对象,也就是包含了字符串值“username”的对象;而另一个对象是键值对中的值对象,也就是包含了字符串值“liuhefei”的对象。
对象结构体定义如下:
typedef struct redisObject {
//对象类型
unsigned type:4;
//对象编码
unsigned encoding:4;
//指向底层实现数据结构的指针
void *ptr;
// ...
}robj;
这里的对象结构体中省略了部分属性的定义,只定义了结构体中与保存数据有关的 3
个属性。
● type 属性:该属性用于记录对象的类型。Redis 中对象的类型如下。
- REDIS_STRING:字符串对象。
- REDIS_LIST:列表对象。
- REDIS_HASH:哈希对象。
- REDIS_SET:集合对象。
- REDIS_ZSET:有序集合对象。
Redis 数据库中保存的键值对中的键总是一个字符串对象,而值可以是字符串对象、列
表对象、哈希对象、集合对象及有序集合对象中的任意一种。
当一个数据库键为“字符串键”时,这个键所对应的值是字符串对象。
当一个数据库键为“列表键”时,这个键所对应的值是列表对象。
通常可以使用 Redis 的 TYPE 命令来查看一个数据库键对应的值对象的类型。
使用 TYPE 命令查看数据库键对应的值对象的类型,操作如下:
127.0.0.1:6379> SELECT 1 #切换到 1 号数据库
OK
127.0.0.1:6379[1]> SET username "liuhefei" #设置字符串键值对
OK
127.0.0.1:6379[1]> TYPE username
string #字符串类型
127.0.0.1:6379[1]> RPUSH numbers 6 8 2 4 9 #添加多个整数到列表 numbers 的表尾
(integer) 5
127.0.0.1:6379[1]> TYPE numbers
list #列表类型
127.0.0.1:6379[1]> HMSET color R "red" G "green" B "blue" #添加多个键值对到哈
希表 color 中
OK
127.0.0.1:6379[1]> TYPE color
hash #哈希类型
127.0.0.1:6379[1]> SADD citys beijing shanghai wuhan shenzhen #添加多个城市到
集合 citys 中
(integer) 4
127.0.0.1:6379[1]> TYPE citys
set #集合类型
127.0.0.1:6379[1]> ZADD score 98 "xiaoming" 86 "zhangsan" 100 "lisi" #添加多个学生
与成绩到有序集合 score 中
(integer) 3
127.0.0.1:6379[1]> TYPE score
zset #有序集合类型
使用 TYPE 命令查看数据库键对应的值对象的类型总结为表 7.2。
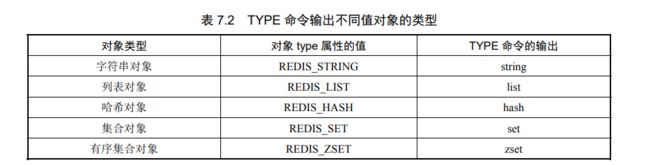
encoding 属性:该属性记录了对象使用何种编码方式,也就是这个对象底层使用了
什么数据结构来实现。
● ptr 属性:该属性是一个指针,用于指向对象的底层实现数据结构,而这些数据结构
由对象的 encoding 属性决定。
对象的编码常量及对应的底层数据结构如下。
● 当编码常量为 REDIS_ENCODING_INT 时,对应的底层数据结构是 long 类型的整数。
● 当编码常量为 REDIS_ENCODING_EMBSTR 时,对应的底层数据结构是采用 embstr编码的简单动态字符串。
● 当编码常量为REDIS_ENCODING_RAW时,对应的底层数据结构是简单动态字符串。
● 当编码常量为 REDIS_ENCODING_HT 时,对应的底层数据结构是字典。
● 当编码常量为REDIS_ENCODING_LINKEDLIST 时,对应的底层数据结构是双向链表。
● 当编码常量为 REDIS_ENCODING_ZIPLIST 时,对应的底层数据结构是压缩列表。
● 当编码常量为 REDIS_ENCODING_INTSET 时,对应的底层数据结构是整数集合。
● 当编码常量为REDIS_ENCODING_SKIPLIST时,对应的底层数据结构是字典和跳表。
每种对象 type 属性的值都会对应不同的编码方式,因此对象的底层实现也就不一样。
如表 7.3 所示展示了不同 type 类型编码及对象的底层实现。

使用命令 OBJECT ENCODING key 可以查看一个数据库键对应的值对象的编码,操作 如下:
127.0.0.1:6379> SELECT 2 #切换到 2 号数据库
OK
127.0.0.1:6379[2]> SET message "good luck!" #设置一条短消息
OK
127.0.0.1:6379[2]> OBJECT ENCODING message
"embstr" #采用 embstr 编码的简单动态字符串
127.0.0.1:6379[2]> SET article "Learning is easy, learning hard, learning and
cherishing." #设置一个长字符串
OK
127.0.0.1:6379[2]> OBJECT ENCODING article
"raw" #简单动态字符串
127.0.0.1:6379[2]> LPUSH numbers 78 89 90 100 70 60 76 80 #将多个整数添加到列
表 numbers 中
(integer) 8
127.0.0.1:6379[2]> OBJECT ENCODING numbers
"quicklist" #快速列表
127.0.0.1:6379[2]> HMSET user userName "liuhefei" passWord "123456" age 24 #将一条
用户信息添加到哈希表 user 中
OK
127.0.0.1:6379[2]> OBJECT ENCODING user
"ziplist" #压缩列表
127.0.0.1:6379[2]> SADD nums 1 4 8 16 32 64 #将多个整数值添加到集合 nums 中
(integer) 6
127.0.0.1:6379[2]> OBJECT ENCODING nums
"intset" #整数集合
127.0.0.1:6379[2]> SADD news "There will be rain tomorrow" #添加一个字符串到
集合 nuws 中
(integer) 1
127.0.0.1:6379[2]> OBJECT ENCODING news
"hashtable" #字典
#添加多个学生与分数到有序集合 score 中
127.0.0.1:6379[2]> ZADD score 70 "lisi" 80 "zhangsan" 90 "wangwu" 100 "tianqi"
(integer) 4
127.0.0.1:6379[2]> OBJECT ENCODING score
"ziplist" #压缩列表
以上操作列举出了不同对象的编码常量所对应的 OBJECT ENCODING 命令的输出形 式,总结如表 7.4 所示。

7.8.2 对象的编码方式
Redis 有 5 种数据类型,每种数据类型都有对应的对象,具体有字符串对象、哈希对象、列表对象、集合对象及有序集合对象。每种对象都有其不同的编码方式,以适应不同的应用场景,同时提高了 Redis 的灵活性和效率。下面列举出每种对象可能使用的编码方式。
● 字符串对象的编码方式可能是 int、raw 或 embstr。
● 哈希对象的编码方式可能是 ziplist 或 hashtable。
● 列表对象的编码方式可能是 ziplist、quicklist 或 linkedlist。
● 集合对象的编码方式可能是 intset 或 hashtable。
● 有序集合对象的编码方式可能是 ziplist 或 skiplist。
每种对象都有多种编码方式,那么在什么时候使用何种编码方式呢?下面我们逐一介绍。
- 字符串对象
● 如果字符串对象保存的是一个 long 类型的整数值,那么这个字符串对象将会把这个整数值保存到字符串对象结构的 ptr 属性里,同时设置为 int 编码方式。
● 如果字符串对象保存的是一个长度超过 32 字节的字符串值,那么这个字符串对象将会使用简单动态字符串来保存这个字符串值,同时设置为 raw 编码方式。
● 如果字符串对象保存的是一个长度小于或等于 32 字节的字符串值(短字符串),那么这个字符串对象将会使用 embstr 编码方式来保存这个字符串值。字符串对象的 int 和 embstr 编码在满足一定条件的情况下,会转化为 raw 编码。 - 哈希对象
● 采用压缩列表作为底层实现了 ziplist 编码的哈希对象,每当要将新的键值对添加到列表中时,程序会将键值对中的键对象和值对象依次保存到压缩列表的表尾。
● 采用字典作为底层实现了 hashtable 编码的哈希对象,它的每个键值对都使用一个字典键值对保存。字典中的每个键和值都是一个字符串对象;字典中的键保存键值对中的键,字典中的值保存键值对中的值。
如果哈希对象同时满足以下两个条件:
- 哈希对象保存的所有键值对中的键和值的字符串长度不超过 64 字节。
- 哈希对象保存的键值对的个数在 512 个之内。则哈希对象将会使用 ziplist 编码方式。而如果哈希对象不满足上述条件,则将会使用hashtable 作为哈希对象的编码方式。
- 列表对象
● 采用 ziplist 编码的列表对象使用压缩列表作为其底层实现,每个列表元素都保存在一个压缩列表节点中。
● 采用 quicklist 编码的列表对象使用快速列表作为其底层实现,每个快速列表的节点又是一个压缩列表。
● 采用 linkedlist 编码的列表对象在底层使用双向链表实现,每个双向链表的节点都保存了一个字符串对象。
如果列表对象满足以下条件,列表对象就会使用 ziplist 编码方式。
- 列表对象保存的所有字符串元素的长度都小于 64 字节。
- 列表对象保存的元素个数少于 512 个。
如果列表对象不能满足上述条件,则将会使用 linkedlist 编码方式。
- 集合对象
● 采用整数集合作为底层实现了 intset 编码的集合对象,这个集合对象所包含的所有
元素都会被保存到这个整数集合中。
● 采用字典作为底层实现了 hashtable 编码的集合对象,字典中的每个键都是一个字符串对象,每个字符串对象都包含一个集合元素,而字典的值被全部设置为 NULL。如果集合对象满足以下两个条件,则将会使用 intset 编码方式。
- 集合对象中的所有元素都是整数值。
- 集合对象的所有元素个数之和在 512 个之内。
如果集合对象不满足上述条件,则将会使用 hashtable 编码方式。
- 有序集合对象
● 采用压缩列表作为底层实现了 ziplist 编码的有序集合对象,每个有序集合的元素使用两个相连的压缩列表节点来保存,第一个压缩列表的节点保存有序集合元素的成员(member),第二个压缩列表的节点保存有序集合元素的分数值(score)。压缩列表内的集合元素会根据分数值的大小,按从小到大的顺序进行排序,分数值较小的元素会被放置在靠近表头的一端,而分数值较大的元素会被放置在靠近表尾的一端。
● 采用 zset 结构作为底层实现了 skiplist 编码的有序集合对象,一个 zset 结构同时包含
一个跳表和一个字典。
如果有序集合对象同时满足以下两个条件:
- 有序集合所保存的元素个数之和在 128 个之内。
- 有序集合保存的所有元素的长度小于 64 字节。
则有序集合对象使用 ziplist 编码方式。 如果有序集合对象不满足上述条件,则使用 skiplist 编码方式。Redis 底层数据结构对应的源码文件如表 7.5 所示。

8.排序
本章的主题为 Redis 的排序功能。众所周知,排序功能是每个数据库应该有且必须有 的功能。在实际应用中,数据库存储大量信息后,为了获得有用的数据信息,我们必须对 这些海量的数据进行筛选排序,进而查找出我们需要的数据。试想一下,如果数据库没有 排序功能,我们为了获得一个有序的数据集,需要人工来排序,这将会是一件痛苦的事。 本章将会深入讲解 Redis 的排序功能,以及与排序功能相关的每个参数(ASC、DESC、 LIMIT、STORE、BY、GET)的用法等。
8.1 SORT 排序命令
Redis 的 SORT 命令用于对相关数据进行排序,具体可以对有序集合键的值及集合键、
列表键进行排序。
使用 SORT 命令实现列表键的排序,具体操作步骤如下:
(1)RPUSH score 92 81 85 60 52 77 94 83(RPUSH 命令用于将多个学生的分数插入列表 score 中)。
(2)LRANGE score 0 -1(LRANGE 命令用于获取列表 score 中指定区间的元素)。
(3)SORT score(SORT 命令用于对列表 score 的值进行排序)。
操作如下:
127.0.0.1:6379> RPUSH score 92 81 85 60 52 77 94 83
(integer) 8
127.0.0.1:6379> LRANGE score 0 -1
1) "92"
2) "81"
3) "85"
4) "60"
5) "52"
6) "77"
7) "94"
8) "83"
127.0.0.1:6379> SORT score #对分数进行排序
1) "52"
2) "60"
3) "77"
4) "81"
5) "83"
6) "85"
7) "92"
8) "94"
SORT 是 SORT 命令最简单的形式,用于实现对列表 key 的排序,这个列表 key包含数字值。
在使用 SORT 命令对有序集合进行排序时,会忽略有序集合元素的分数,而只对元素
的值进行排序。具体操作步骤如下:
(1)ZADD myset 20 9 60 3 34 1 52 8 100 7 30 2(ZADD 命令用于将多个元素及元素的分数加入有序集合 myset 中,20、60、34、52、100、30 是分数,9、3、1、8、7、2 是元素)。
(2)ZRANGE myset 0 -1(ZRANGE命令用于获取指定区间内的有序集合myset的元素)。
(3)SORT myset(SORT 命令用于对有序集合 myset 进行排序)。
操作如下:
127.0.0.1:6379> ZADD myset 20 9 60 3 34 1 52 8 100 7 30 2
(integer) 6
127.0.0.1:6379> ZRANGE myset 0 -1
1) "9"
2) "2"
3) "1"
4) "8"
5) "3"
6) "7"
127.0.0.1:6379> SORT myset
1) "1"
2) "2"
3) "3"
4) "7"
5) "8"
6) "9"
以上涉及的 SORT 排序实例都是针对数字值进行的排序。读者可能会问:Redis 的 SORT
命令是不是只能对数字值进行排序?
显然不是的,我们通过为 SORT 命令设置 ALPHA 参数,就可以实现对含有字符串值
的键进行排序。命令格式为:
SORT ALPHA
为 SORT 命令设置 ALPHA 参数可以实现按照字典顺序来排序字符串值。
使用 SORT 命令实现对字符串列表进行排序,操作步骤如下:
(1)LPUSH color red black purple white blue orange brown green(LPUSH 命令用于将多个颜色字符串元素添加到列表 color 中)。
(2)LRANGE color 0 -1(返回列表 color 中指定区间的元素)。
(3)SORT color(SORT 命令用于对字符串列表 color 进行排序,将会报错)。 (4)SORT color ALPHA(SORT 命令用于设置 ALPHA 参数对字符串列表 color 进行排序)。 操作如下:
127.0.0.1:6379> LPUSH color red black purple white blue orange brown green
(integer) 8
127.0.0.1:6379> LRANGE color 0 -1
1) "green"
2) "brown"
3) "orange"
4) "blue"
5) "white"
6) "purple"
7) "black"
8) "red"
127.0.0.1:6379> SORT color
(error) ERR One or more scores can't be converted into double
127.0.0.1:6379> SORT color ALPHA
1) "black"
2) "blue"
3) "brown"
4) "green"
5) "orange"
6) "purple"
7) "red"
8) "white"
在没有为 SORT 命令设置 ALPHA 参数的条件下,如果使用 SORT 命令对字符串值进行排序,则将会报错,错误信息为:(error) ERR One or more scores can’t be converted into double。
可以看出,SORT 命令会尝试将所有元素转化为双精度浮点数来进行比较,如果转化错误就会报错。
8.2 升序(ASC)与降序(DESC)
在默认情况下,使用 SORT 命令排序后,排序结果将会按照从小到大的顺序排列。在实际应用中,我们常常需要对一些数据进行降序(从大到小)排列,此时可以为 SORT 命令设置 DEAS 参数,DEAS 参数的设置可以让排序结果降序排列;与 DEAS 参数功能相反的是 ASC 参数,ASC 参数的设置可以让排序结果按照从小到大的顺序排列。
在使用 SORT 命令实现从小到大的排序过程中,我们常常会省略 ASC 参数,其实 SORT 命令等价于 SORT ASC 命令。为 SORT 命令设置 ASC 或 DESC 参数实现排序,操作步骤如下:
(1)RPUSH height 156 172 171 165 182 160 171(RPUSH 命令用于将多个学生的身高添加到 height 列表中)。
(2)SORT height ASC(为 SORT 命令显式设置 ASC 参数实现排序)。
(3)SORT height DESC(为 SORT 命令设置 DESC 参数实现降序排序)。
操作如下:
127.0.0.1:6379> RPUSH height 156 172 171 165 182 160 171
(integer) 7
127.0.0.1:6379> SORT height
1) "156"
2) "160"
3) "165"
4) "171"
5) "171"
6) "172"
7) "182"
127.0.0.1:6379> SORT height ASC
1) "156"
2) "160"
3) "165"
4) "171"
5) "171"
6) "172"
7) "182"
127.0.0.1:6379> SORT height DESC
1) "182"
2) "172"
3) "171"
4) "171"
5) "165"
6) "160"
7) "156"
Redis 的升序排序与降序排序都是由相同的快速排序算法实现的,二者的区别在于:
● 在进行升序排序时,快速排序算法使用的排序对比函数产生升序的排列结果。
● 在进行降序排序时,快速排序算法使用的排序对比函数产生降序的排列结果。 升序对比和降序对比的结果正好相反,因此产生的排序结果也是正好相反的。
8.3 BY 参数的使用
在默认情况下,使用 SORT 命令进行排序,它会按照元素本身的值进行排序,元素本身决定了元素在排序之后所处的位置。比如,使用 SORT 命令按照学生的姓名进行排序,操作如下:
#添加多个学生姓名到集合 stuName 中
127.0.0.1:6379> SADD stuName "zhangsan" "lisi" "wangwu" "xiaosan" "ouyang" "meizi"
(integer) 6
127.0.0.1:6379> SMEMBERS stuName #返回集合中的所有元素
1) "zhangsan"
2) "lisi"
3) "ouyang"
4) "xiaosan"
5) "wangwu"
6) "meizi"
127.0.0.1:6379> SORT stuName ALPHA #排序
1) "lisi"
2) "meizi"
3) "ouyang"
4) "wangwu"
5) "xiaosan"
6) "zhangsan"
我们使用 ALPHA 参数来对集合 stuName 进行排序。事实上,排序结果是按照元素在字典中的顺序得出的,也就是元素本身已经确定了元素所在的位置。但是,如果我们想按照其他键来排序,则可以通过 BY 参数来实现。使用 BY 参数,SORT 命令可以指定某些字符串键,或者某个哈希键所具有的某些域来作为排序依据,对这个键进行排序。
比如,我们采用颜色的 RGB 值(256,256,256)对颜色进行排序,操作步骤如下:
(1)SADD color green blue red orange(将多个颜色元素添加到集合 color 中)。
(2)MSET green-RGB 91 blue-RGB 234 red-RGB 80 orange-RGB 155(MSET 命令用于同时设置多个键值对)。
(3)MGET green-RGB blue-RGB red-RGB orange-RGB(MGET 命令用于同时取出多个键对应的值)。
(4)SORT color BY -RGB(为 SORT 命令设置 BY 参数,按照指定的-RGB 字符串键进行排序)。
操作如下:
127.0.0.1:6379[3]> SADD color green blue red orange
(integer) 4
127.0.0.1:6379[3]> MSET green-RGB 91 blue-RGB 234 red-RGB 80 orange-RGB 155
OK
127.0.0.1:6379[3]> MGET green-RGB blue-RGB red-RGB orange-RGB
1) "91"
2) "234"
3) "80"
4) "155"
127.0.0.1:6379[3]> SORT color BY *-RGB
1) "red"
2) "green"
3) "orange"
4) "blue"
服务器执行 SORT color BY *-RGB 命令的过程如下:
1.服务器接收到命令之后,进行解析,它会根据命令创建一个 redisSortObject 结构的数组,数组的长度就是 color 集合的大小(长度)。
2.遍历这个数组,将每个数组元素的 obj 指针分别指向 color 集合中的每个元素。然后根据每个数组元素的 obj 指针所指向的集合元素,以及 BY 参数所指定的字符串键*-RGB,查找相对应的权重键。比如,“green”元素对应的权重键就是“green-RGB”,其他元素类似。
3.服务器会将这些元素的权重键所对应的权重值转化为双精度浮点数,然后保存到相应数组项的 u.score 属性中。这里“green”元素的权重键“green-RGB”的值转化为浮点数后为“91.0”,其他元素类似。
4.以数组项 u.score 属性的值为权重,按照从小到大的顺序对数组进行排序,将会得到一个升序的数组。
5.遍历这个新数组,依次将数组项的 obj 指针所指向的集合元素返回给客户端。
在默认情况下,BY 参数排序的权重键保存的值为数字值。如果这些权重键中保存的值
是字符串值,那么,要实现对这些权重键的排序,除使用 BY 参数之外,还需要使用 ALPHA参数。
命令格式如下:
SORT BY ALPHA
比如,使用 BY 和 ALPHA 参数对带有 RGB 值的颜色进行排序,操作步骤如下:
(1)SADD color “red” “black” “green” “yellow”(SADD 命令用于将多个颜色元素添加到集合 color 中)。
(2)MSET red-rgb “RGB-170” black-rgb “RGB-210” green-rgb “RGB-90” yellow-rgb “RGB-140”(MSET 命令用于同时设置多个键值对)。
(3)MGET red-rgb black-rgb green-rgb yellow-rgb(MGET 命令用于同时取出多个键对应的值)。
(4)SORT color BY *-rgb ALPHA(SORT 命令结合 BY 和 ALPHA 参数,使用颜色的-rgb 为权重,对颜色进行排序)。
127.0.0.1:6379[3]> SADD color "red" "black" "green" "yellow"
(integer) 4
127.0.0.1:6379[3]> MSET red-rgb "RGB-170" black-rgb "RGB-210" green-rgb "RGB-90"
yellow-rgb "RGB-140"
OK
127.0.0.1:6379[3]> MGET red-rgb black-rgb green-rgb yellow-rgb
1) "RGB-170"
2) "RGB-210"
3) "RGB-90"
4) "RGB-140"
127.0.0.1:6379[3]> SORT color BY *-rgb ALPHA
1) "yellow"
2) "red"
3) "black"
4) "green"
127.0.0.1:6379[3]> SORT color BY *-rgb
(error) ERR One or more scores can't be converted into double
通过以上实例不难看出,当权重键中存储的是字符串值时,使用 BY 参数是不能实现排序的,必须结合 ALPHA 参数才能实现排序。
将一个不存在的键作为参数传递给 BY 参数,可以让 SORT 命令跳过排序操作,直接返回结果。接着对集合 color 进行操作,如下:
127.0.0.1:6379[3]> SORT color ALPHA
1) "black"
2) "green"
3) "red"
4) "yellow"
127.0.0.1:6379[3]> SORT color BY *-rgb ALPHA
1) "yellow"
2) "red"
3) "black"
4) "green"
127.0.0.1:6379[3]> SORT color BY no-key ALPHA #将一个不存在的键传递给 BY 参数进行排序
1) "yellow"
2) "green"
3) "black"
4) "red"
在实际应用中,请读者根据实际情况选择合适的参数相结合进行排序。
8.4 LIMIT 参数的使用
在使用 SORT 命令进行排序时,不管有多少个元素,排序后都会返回所有的元素到客户端。
比如,使用 SORT 命令对英文字母进行排序,操作步骤如下:
(1)SADD letter a b c d e f g(SADD 命令用于将多个英文字母添加到集合 letter 中)。
(2)SMEMBERS letter(SMEMBERS 命令用于获取集合 letter 中的所有元素,是乱序的)。
(3)SORT letter ALPHA(SORT 命令用于对集合 letter 进行排序)。
操作如下:
127.0.0.1:6379[3]> SADD letter a b c d e f g
(integer) 7
127.0.0.1:6379[3]> SMEMBERS letter
1) "c"
2) "b"
第 8 章 Redis 排序∣181
3) "d"
4) "a"
5) "g"
6) "f"
7) "e"
127.0.0.1:6379[3]> SORT letter ALPHA
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
7) "g"
如果使用 SORT 命令对一个很大的集合(有很多元素)进行排序,同时又不希望 SORT命令返回这个集合排序结果的所有元素,而只需要其中的一部分元素即可,则可以使用SORT 命令的 LIMIT 参数来实现。在使用 LIMIT 参数之后,可以返回排序结果的部分元素。
命令格式如下:
LIMIT
● offset 参数:表示要跳过的已排序元素数量。
● count 参数:表示在跳过 offset 个已排序的元素之后,要返回多少个已排序的元素。
比如,对上一个实例中的 letter 集合进行排序,在跳过 2 个已排序的元素之后,返回 3 个已排序的元素。操作如下:
127.0.0.1:6379[3]> SORT letter ALPHA LIMIT 2 3
1) "c"
2) "d"
3) "e"
Redis 的 SORT 命令的 LIMIT 参数有点类似于 MySQL 数据库的 LIMIT 参数,它们的 功能相似,都是返回部分结果。
8.5 GET 与 STORE 参数的使用
使用 SORT 命令对键进行排序后,在默认情况下,总是返回被排序键本身所包含的元素。如果想要得到这些排序键所对应的值,则可以使用 GET 参数。GET 参数不参与排序,它的作用是使 SORT 命令的返回结果不再是元素自身的值,而是 GET 参数所指定的模式匹配的值。GET 参数与 BY 参数一样,也支持字符串类型和散列类型的键,并使用“*”作为模式匹配符。
比如,我们使用 SORT 命令对 citys 集合进行排序,然后根据排序结果,使用 GET 参
数返回这些城市的全名,操作步骤如下:
(1)SADD citys shenzhen hangzhou chengdu wuhan(SADD 命令用于同时添加多个元素到 citys 集合中)。
(2)SORT citys ALPHA(SORT 命令结合 ALPHA 参数实现字符串集合排序)。
(3)SET shenzhen-name “guangdong-shenzhen” SET hangzhou-name “zhejiang-hangzhou” SET chengdu-name “sichuan-chengdu” SET wuhan-name “hubei-wuhan” (SET 命令用于设置多个字符串键值对,即 citys集合)。
(4)SORT citys ALPHA GET -name(使用 GET 参数按照-name 返回城市的全名,
即值)。
操作如下:
127.0.0.1:6379[3]> SADD citys shenzhen hangzhou chengdu wuhan
(integer) 4
127.0.0.1:6379[3]> SORT citys ALPHA
1) "chengdu"
2) "hangzhou"
3) "shenzhen"
4) "wuhan"
127.0.0.1:6379[3]> SET shenzhen-name "guangdong-shenzhen"
OK
127.0.0.1:6379[3]> SET hangzhou-name "zhejiang-hangzhou"
OK
127.0.0.1:6379[3]> SET chengdu-name "sichuan-chengdu"
OK
127.0.0.1:6379[3]> SET wuhan-name "hubei-wuhan"
OK
127.0.0.1:6379[3]> SORT citys ALPHA GET *-name
1) "sichuan-chengdu"
2) "zhejiang-hangzhou"
3) "guangdong-shenzhen"
4) "hubei-wuhan"
一个 SORT 命令可以带有多个 GET 参数,但只能带有一个 BY 参数。但是,随着 GET参数的增多,SORT 命令要执行的查找操作也会增多。
比如,对 citys 集合中的城市设置 GDP(亿元),然后使用两个 GET 参数分别取出 citys
集合中城市的全名及对应的 GDP 值,操作步骤如下:
(1)SET shenzhen-GDP 8965 ;SET hangzhou-GDP 6877; SET chengdu-GDP 4312; SET wuhan-GDP 5234(SET 命令用于设置各个城市的 GDP)。
(2)SORT citys ALPHA GET *-name GET *-GDP(使用 SORT 命令结合 GET 参数实现排序,并获取城市的全名及对应的 GDP 值)。
操作如下:
127.0.0.1:6379[3]> SET shenzhen-GDP 8965
OK
127.0.0.1:6379[3]> SET hangzhou-GDP 6877
OK
127.0.0.1:6379[3]> SET chengdu-GDP 4312
OK
127.0.0.1:6379[3]> SET wuhan-GDP 5234
OK
127.0.0.1:6379[3]> SORT citys ALPHA GET *-name GET *-GDP
1) "sichuan-chengdu"
2) "4312"
3) "zhejiang-hangzhou"
4) "6877"
5) "guangdong-shenzhen"
6) "8965"
7) "hubei-wuhan"
8) "5234"
接着使用 GET 参数返回排序元素本身的值,操作如下:
127.0.0.1:6379[3]> SORT citys ALPHA GET *-name GET *-GDP GET #
1) "sichuan-chengdu"
2) "4312"
3) "chengdu"
4) "zhejiang-hangzhou"
5) "6877"
6) "hangzhou"
7) "guangdong-shenzhen"
8) "8965"
9) "shenzhen"
10) "hubei-wuhan"
11) "5234"
12) "wuhan"
组合使用 BY 与 GET 参数,让排序结果以更直观的方式显示出来,如下:
127.0.0.1:6379[3]> SORT citys ALPHA BY *-* GET *-name GET *-GDP
1) "zhejiang-hangzhou"
2) "6877"
3) "hubei-wuhan"
4) "5234"
5) "sichuan-chengdu"
6) "4312"
7) "guangdong-shenzhen"
8) "8965"
除将字符串键作为 GET 或 BY 参数之外,还可以使用哈希表作为 GET 或 BY 参数。比如,对于用户信息表(见表 8.1),你可能会想到分别把用户名和用户年龄保存到user_name_{uid}和 user_age_{uid}两个字符串键中,这种做法显然不好。我们可以用一个带有 name 和 age 属性的哈希表 user_info_{uid}来存放这些用户的信息,然后使用 BY 和 GET 参数来获取这个哈希表的键和值。

操作步骤如下:
(1)LPUSH uid 1 2 3 4(LPUSH 命令用于将多个值添加到列表中)。
(2)HMSET user_info_1 name zhangsan age 23 ;HMSET user_info_2 name lisi age 19 ; ;HMSET user_info_3 name tianqi age 24 ; HMSET user_info_4 name wangwu age 18(HMSET 命令用于同时将多个键值对添加到哈希表 user_info_{uid}中)。
(3)SORT uid BY user_info_-> age(SORT 命令结合 BY 参数获取哈希表的 age 值)。
(4)SORT uid BY user_info_-> age GET user_info_* -> name(SORT 命令结合 BY 和
GET 参数获取哈希表的 age 和 name 值)。
操作如下:
127.0.0.1:6379[3]> LPUSH uid 1 2 3 4
(integer) 4
127.0.0.1:6379[3]> HMSET user_info_1 name zhangsan age 23
OK
127.0.0.1:6379[3]> HMSET user_info_2 name lisi age 19
OK
127.0.0.1:6379[3]> HMSET user_info_3 name tianqi age 24
OK
127.0.0.1:6379[3]> HMSET user_info_4 name wangwu age 18
OK
127.0.0.1:6379[3]> SORT uid BY user_info_*->age
1) "4"
2) "2"
3) "1"
4) "3"
127.0.0.1:6379[3]> SORT uid BY user_info_*->age GET user_info_*->name
1) "wangwu"
2) "lisi"
3) "zhangsan"
4) "tianqi"
在默认情况下,使用 SORT 命令进行排序,只会向客户端返回排序的结果,并不会保存这些排序结果。如果想把排序结果保存起来,则可以使用 STORE 参数。通过使用 STORE参数,可以把排序结果保存到指定的键中,在需要的时候从这个键中取出。
比如,对多个城市名进行排序,然后将排序结果保存到指定的键中,操作步骤如下:
(1)SADD citys “beijing” “hangzhou” “wuhan” “kunming” “zhengzhou”(SADD 命令用于同时添加多个元素到 citys 集合中)。
(2)SORT citys ALPHA(SORT 命令用于对字符串集合进行排序)。
(3)SORT citys ALPHA STORE china_citys(使用 STORE 参数将 SORT 命令排序的结果保存到指定键 china_citys 中)。
(4)LRANGE china_citys 0 4(LRANGE 命令用于取出键 china_citys 中索引为 0~4的元素)。
操作如下:
127.0.0.1:6379[4]> SADD citys "beijing" "hangzhou" "wuhan" "kunming" "zhengzhou"
(integer) 5
127.0.0.1:6379[4]> SORT citys ALPHA
1) "beijing"
2) "hangzhou"
3) "kunming"
4) "wuhan"
5) "zhengzhou"
127.0.0.1:6379[4]> SORT citys ALPHA STORE china_citys
(integer) 5
127.0.0.1:6379[4]> LRANGE china_citys 0 4
1) "beijing"
2) "hangzhou"
3) "kunming"
4) "wuhan"
5) "zhengzhou"
127.0.0.1:6379[4]> LRANGE china_citys 1 3
1) "hangzhou"
2) "kunming"
3) "wuhan"
STORE 参数保存的键是列表类型的,如果这个键已经存在,则新的键会覆盖旧的键。在加上 STORE 参数后,SORT 命令的返回值为结果的个数。
8.6 多参数执行顺序
在使用 Redis 的 SORT 命令进行排序的时候,一般会携带多个参数,而这些参数的执行顺序是分先后的。按照参数的执行顺序,SORT 命令的执行过程可以划分为以下几步:
(1)进行排序。在这一步中,可以使用 ALPHA 参数、ASC 或 DESC 参数及 BY 参数实现排序,并返回排序结果。
(2)对排序结果集的长度限制。在这一步中,可以使用 LIMIT 参数对排序结果进行限制,返回部分排序结果,并保存到排序结果集中。
(3)获取外部键。在这一步中,可以使用 GET 参数,根据排序结果集中的元素及 GET参数所指定的模式进行匹配,查找出符合要求的键值,同时将这些键值作为新的排序结果集。
(4)将排序结果集返回给客户端。在这一步中,排序结果集被遍历,并返回给客户端。SORT 命令的这 4 步执行过程环环紧扣,只有当前一步完成之后,才会执行下一步。
这 4 步执行过程用命令解释如下:
SORT ALPHA ASC | DESC BY LIMIT GET
STORE
这个命令的执行过程如下(拆分命令)。
(1)进行排序。命令为:
SORT ALPHA ASC | DESC BY
(2)对排序结果集的长度限制。命令为:
LIMIT
(3)获取外部键。命令为:
GET
(4)将排序结果集返回给客户端。命令为:
STORE
在使用 SORT 命令携带多个参数进行排序时,除 GET 参数之外,其他参数的摆放顺序并不会影响到排序结果。如果排序命令中含有多个 GET 参数,则必须保证 GET 参数的摆放顺序正确,才能得出我们想要的排序结果。
至此,我们全面讲解了 Redis 的排序功能,相信读者已经学会。同时也希望读者多动手实践,这样才能熟练掌握 Redis 的排序功能。
9.Redis 事务
我们都知道,数据库是一个面向多用户的共享管理系统,它具备并发控制和封锁机制, 用于保证数据库的正常运行,同时保证数据的完整性。而保证数据完整性的单位就是事务。 那么,什么是事务呢?事务就是由一系列数据库命令组成的集合单元。事务可以保证数据 库数据的一致性。事务是并发控制和封锁机制的基本单位。在关系型数据库中,事务可以 由一条或多条 SQL 语句组成,可以把它看作一个程序。不仅在关系型数据库中存在事务, 在非关系型数据库中也存在事务。本章将着重讲解 Redis 事务的原理及实现过程,以及它 的相关特性、相关命令等。
9.1 Redis 事务简介
Redis 事务的基本功能由 MULTI、EXEC、DISCARD 及 WATCH 等命令实现。其中,
● MULTI 命令用于启动 Redis 的事务,将客户端置为事务状态。
● EXEC 命令用于提交事务,执行从 MULTI 到此命令前面的命令队列,此时客户端变为非事务状态。
● DISCARD 命令用于取消事务,命令执行后,将会清空事务队列中的所有命令,并且客户端从事务状态中退出。
● WATCH 命令用于监视键值对,它使得 EXEC 命令需要有条件地执行,在所有被监视键都没有被修改的前提下,事务才能正常被执行。如果这个被监视的键值对发生了改变,那么事务就不会被执行。
Redis 事务一次可以执行多个命令,其本质是一组命令的集合,一个事务中的所有命令都会被系列化,然后一次性、按顺序、排他性地串行(逐个)执行一系列命令。在事务的执行过程中,Redis 事务不会被打断,Redis 服务器不会在执行事务的途中去执行其他客户端命令,而是等待整个事务执行完毕后,才会执行其他客户端发送过来的命令请求。
目前,Redis 对事务的支持还比较简单,它只能保证一个客户端请求的事务中的命令可以连续地被执行,而在中间过程中不会执行其他客户端发送过来的命令请求。当一个客户端在连接中发出 MULTI 命令时,这个连接就会启动一个事务上下文,该连接后续请求的命令都会先放到一个命令队列中。这些命令并不会立即被执行,而是当服务器接收到 EXEC
命令并执行时,它才会顺序地执行这个队列中的所有命令。
9.2 Redis 事务的 ACID 特性
在关系型数据库中,事务具有 ACID(原子性、一致性、隔离性、持久性)特性,我们常常使用数据库的 ACID 特性来衡量一个关系型数据库事务的安全性与可靠性。同样地,Redis数据库也具有ACID特性,Redis事务一次可以执行多个命令,在这个过程中具有ACID特性。下面我们来详细说明。
9.2.1 事务的原子性
Redis 事务的原子性说的是,事务一次可以执行多个命令,在开启事务后,多个命令逐个入队,当遇到 EXEC 命令时,入队的命令会被看作一个整体来执行,Redis 服务器对这个整体命令要么全部执行成功,要么全部执行失败。
Redis 事务是一个原子操作。EXEC 命令主要负责触发并执行这组事务中的所有命令:当客户端使用MULTI命令成功开启一个事务上下文后,成功入队了多个命令,并执行EXEC命令,此时发生断线,因而导致 EXEC 命令并没有执行成功,那么事务中的所有命令都不会执行成功。另外,如果客户端在成功启动事务之后执行了 EXEC 命令,那么这个事务中的所有命令都会执行成功。这就是 Redis 事务的原子性,即一个事务中的所有命令要么全部执行成功,要么全部执行失败。
下面开启一个事务,然后将一个用户的多条信息添加到事务队列中,在提交事务之后,
成功执行这个事务中的所有命令。操作如下:
127.0.0.1:6379> SET name "xiaoming" #设置用户名为“xiaoming”,在开启事务之前
OK
127.0.0.1:6379> SET age 10 #设置用户年龄为 10,在开启事务之前
OK
127.0.0.1:6379> MULTI #开启事务
OK
127.0.0.1:6379> SET name "liuhefei" #命令入队,设置用户名为“liuhefei”,将会覆盖旧值
QUEUED
127.0.0.1:6379> SET age 23 #命令入队,设置用户年龄为 23,将会覆盖旧值
QUEUED
127.0.0.1:6379> INCRBY age 2 #命令入队,将用户的年龄加 2
QUEUED
127.0.0.1:6379> SET birthday "1994-01-01" #命令入队,设置用户的生日
QUEUED
127.0.0.1:6379> EXEC #触发执行事务
1) OK
2) OK
3) (integer) 25
4) OK
127.0.0.1:6379> GET name #查看新值
"liuhefei"
127.0.0.1:6379> GET age
"25"
127.0.0.1:6379> GET birthday
"1994-01-01"
解释:使用 MULTI 命令来启动一个事务上下文,在执行该命令后,总是以 OK 作为返回值。在执行 MULTI 命令之后,客户端可以继续向服务器发送任意多条命令,服务器接收到这些命令后,先将它们逐个放入一个队列中,而不是立即执行它们,然后对这个队列中的命令进行序列化,当调用 EXEC 命令时,才会按顺序一次性执行队列中的命令。
当客户端处于事务开启状态时,每进入一条命令,都会返回一个内容为 QUEUED 的结果回复,表示这条命令成功进入 Redis 服务器事务的队列中,这些命令将会在调用执行 EXEC命令后被执行。
在执行 EXEC 命令后,将会以数组的方式返回执行的结果,数组中的每个元素都是事务中的命令执行结果。结果的输出顺序与开启事务后命令进入队列的先后顺序一致。
下面开启一个事务,再次添加一个用户的多条信息到事务队列中,有意输入错误命令,使得这个事务执行失败,进而导致整个事务中的其他命令也执行失败。操作如下:
127.0.0.1:6379> SET name "zhangsan" #设置用户名为“zhangsan”,在开启事务之前
OK
127.0.0.1:6379> SET age 20 #设置用户年龄为 20,在开启事务之前
OK
127.0.0.1:6379> MULTI #开启事务
OK
127.0.0.1:6379> SET name "lisi" #命令入队,修改用户名为“lisi”
QUEUED
127.0.0.1:6379> SET age 21 #命令入队,修改用户年龄为 21
QUEUED
127.0.0.1:6379> INCRBY name 5 #命令入队,让用户名加 5(命令类型错误,执行后将会
报错,但并不会影响整个事务中其他命令的执行)
QUEUED
127.0.0.1:6379> INCRBY age 5 #命令入队,让用户年龄加 5
QUEUED
127.0.0.1:6379> SET #命令格式错误,入队失败,它的执行将会导致整个事务执行失败
(error) ERR wrong number of arguments for 'set' command
127.0.0.1:6379> SET birthday "1993-09-09"
QUEUED
127.0.0.1:6379> EXEC #触发执行事务,报错,因为事务队列中存在错误命令,因此执行失败
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> GET age #因为事务执行失败,因此用户年龄和用户名还是最初的
"20"
127.0.0.1:6379> GET name
"zhangsan"
在通常情况下,关系型数据库的事务是支持回滚的,然而 Redis 数据库并不支持事务回滚。通过上面的实例,我们可以清楚地知道,在开启事务上下文后,向事务队列中插入命令,如果遇到命令格式错误,入队失败,则会导致整个事务执行失败。如果遇到事务中某个命令的语法格式正确,但在执行时因为类型或者键不存在而报错,那么它的整个事务也会继续执行下去,而不是终止执行,直到这个事务的所有命令执行完毕为止。操作如下:
127.0.0.1:6379> MULTI #开启事务
OK
127.0.0.1:6379> SET name "lisi" #设置用户名为“lisi”
QUEUED
127.0.0.1:6379> INCRBY name 10 #给用户名加 10。这条命令的语法格式正确,但 name 是字符
串,加 10,存在类型错误,执行之后将会报错,但它并不会影响事务中其他命令的执行
QUEUED
127.0.0.1:6379> SET age 100 #将用户年龄设置为 100
QUEUED
127.0.0.1:6379>INCRBY age 10 #再将用户的年龄加 10,100+10
QUEUED
127.0.0.1:6379> EXEC #触发执行事务
1) OK
2) (error) ERR value is not an integer or out of range
3) OK
127.0.0.1:6379> GET name #获取用户名为“lisi”,事务执行成功
"lisi"
127.0.0.1:6379> GET age #获取用户年龄为 110,事务执行成功
"110"
前面的实例使用 INCRBY 命令分别给键 name、age 加上增量值 10,因为 INCRBY 命 令只能对数值类型的值进行增量的加操作,所以执行 INCRBY name 10 命令将会报错,而 INCRBY age 10 命令将会执行成功。然而,Redis 事务并不会因为 INCRBY name 10 命令执 行失败而影响其他命令执行成功。因为 Redis 不具有事务回滚机制,即使遇到错误,也会 继续执行下去。
9.2.2 事务的一致性
事务的一致性说的是,数据库在执行事务之前是一致的,在执行事务之后,不管事务是执行成功还是执行失败,数据库中的数据也应该具有一致性。这里的一致性指的是,数据库从当前状态变为一种新的状态,数据在变化前后符合数据本身的定义和要求,同时不包含非法或无效的脏数据。
Redis 事务具有一致性,它通过对命令执行的错误检测和简单的设计来保证事务执行前后数据的一致性。
在使用 Redis 事务的过程中,可能会遇到如下类型的错误。
● 事务在执行 EXEC 命令之前,命令入队错误。比如,通过客户端输入的命令不存在,或者输入的命令语法格式错误(如参数错误、参数数量错误、参数顺序错误),都 会导致命令入队失败,进而导致这个事务执行失败。
下面开启事务上下文,之后输入不存在的命令,或者输入错误的语法格式,使得命令 入队错误,从而导致事务执行失败。操作如下:
127.0.0.1:6379> MULTI #开启事务
OK
127.0.0.1:6379> SADD citys "hangzhou" "suzhou" "nanjing" "dali"
QUEUED
127.0.0.1:6379> SDD
(error) ERR wrong number of arguments for 'sadd' command
127.0.0.1:6379> SADD "lijiang"
(error) ERR wrong number of arguments for 'sadd' command
127.0.0.1:6379> SADD citys "zhengzhou"
QUEUED
127.0.0.1:6379> SMEMBERS citys
QUEUED
127.0.0.1:6379> SPOP citys
QUEUED
127.0.0.1:6379> EXEC
(error) EXECABORT Transaction discarded because of previous errors.
解释:
- SADD citys “hangzhou” “suzhou” “nanjing” “dali”:使用 SADD 命令将多个城市添加到 citys 集合中,入队成功。
- SDD:在 Redis 中不存在这个命令,入队失败。
- SADD “lijiang”:SADD 命令错误的语法格式,导致入队失败。
- SMEMBERS citys:SMEMBERS 命令返回集合中的所有元素,正确的命令,入队成功。
- SPOP citys:SPOP 命令移除并返回集合 citys 中的一个随机元素,入队成功。
因为存在命令入队错误,所以服务器会拒绝执行入队过程中出现错误的事务,导致了事务执行失败,从而保证了数据库的一致性。
● 命令入队成功,但在执行过程中发生了错误。在执行过程中发生的错误都是一些不能在入队时被服务器检测到的错误,这类错误往往是在命令执行的时候才会被发现的,如 INCRBY username 8 命令,只有在执行时才会被发现。
在执行事务的过程中,如果发生了错误,那么事务也会继续执行下去,其他命令也会继续执行,并且不会受到错误命令的影响。
在执行事务的过程中,发生命令执行错误,但并不会影响事务的继续执行。操作如下:
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> DEL name age #删除键 name、age
QUEUED
127.0.0.1:6379> SET name "liuhefei" #重新设置用户名为“liuhefei”
QUEUED
127.0.0.1:6379> SET age 20 #设置用户年龄为 20
QUEUED
127.0.0.1:6379> INCR name #用户名 name 加 1,类型错误,将会执行失败
QUEUED
127.0.0.1:6379> INCR age #用户年龄 age 加 1
QUEUED
127.0.0.1:6379> INCRBY name -5 #用户名 name 减 5,类型错误,将会执行失败
QUEUED
127.0.0.1:6379> INCRBY age -5 #用户年龄 age 减 5
QUEUED
127.0.0.1:6379> GET name #获取用户名
QUEUED
127.0.0.1:6379> GET age #获取用户年龄
QUEUED
127.0.0.1:6379> EXEC #触发执行失败
1) (integer) 2
2) OK
3) OK
4) (error) ERR value is not an integer or out of range
5) (integer) 21
6) (error) ERR value is not an integer or out of range
7) (integer) 16
8) "liuhefei"
9) "16"
在执行事务的过程中,执行错误的命令会被服务器检测出来,并做相应的错误处理,所以这些执行错误的命令并不会影响其他命令的执行,也不会修改数据库,对事务的一致性并不会产生影响。
● 在执行事务的过程中,发生突发情况(如断电、服务器停机、服务器崩溃等),导致事务执行出错。此时常常会根据服务器所使用的持久化方式来保证数据库的一致性,
具体如下。
- 服务器没有开启持久化,在服务器重启时,数据库中将没有任何数据,此时可以保证数据库的一致性。
- 服务器开启了 RDB 或 AOF 持久化,在执行事务的过程中,发生故障,不会引起数据库的不一致性。RDB 或 AOF 文件中保存了数据库数据,可以根据 RDB或 AOF 文件来将数据还原到事务执行之前的状态。如果开启了 RDB 或 AOF持久化方式,但是找不到 RDB 或 AOF 文件,那么在服务器重启后,数据库会是空白的,也能保证数据库的一致性。
总之,无论 Redis 服务器在执行事务的过程中发生上述何种错误,或者服务器使用何种持久化方式,都不会影响数据库的一致性。
9.2.3 事务的隔离性
事务的隔离性说的是,当有多个用户并发(同时)访问数据库时,比如,同时操作一张数据表,数据库会为每个用户单独开启一个事务,每个用户的单独事务的执行互不干扰,它们之间相互隔离,实现了在并发状态下执行的事务和串行执行的事务所产生的结果完全相同。
Redis 数据库是采用单进程单线程模型实现的键值对存储数据库,它在执行事务命令及其他相关命令时,采用的就是单线程方式。在执行事务的过程中,服务器可以保证这个事务不会被中断,所以 Redis 事务总是以串行方式实现的,在上一个事务没有执行完之前,其他命令是不会被执行的,这就是 Redis 事务的隔离性。
9.2.4 事务的持久性
事务的持久性说的是,当一个事务正确执行完成后,它对数据库的改变是永久性的,不会因为其他操作而发生改变,即使在数据库遇到故障的情况下,事务执行完成后的操作也不会丢失。
事实上,Redis 数据库事务是不具有持久性的,它的事务只是简单地将一些事务命令组装到一个队列中,在进行序列化之后,按顺序执行。Redis 服务器所使用的持久化方式决定了 Redis 事务的持久性。在 Redis 的持久化方式中,不管是 AOF 持久化方式,还是 RDB
持久化方式,都是异步执行的。下面具体说明 Redis 的持久化方式。
● 如果 Redis 服务器没有采用任何持久化方式,那么事务不具有持久性。假如服务器发生故障(如停机、断电、崩溃),将会丢失服务器上包括事务数据在内的所有数据。
● 如果 Redis 服务器使用了 AOF 持久化方式:
- 当 Redis 配置文件(redis.conf)中的 appendfsync 属性的值为 always 时,可以保证 Redis 事务具有持久性。每当服务器执行完相关命令后,包括事务命令在内,程序都会调用执行 sync 同步函数,将命令数据及时保存到系统硬盘中,这就保证了事务的持久性。
- 当 Redis 配置文件中的 appendfsync 属性的值为 everysec 时,服务器程序会每隔 1秒执行一次数据同步操作,并将数据保存到硬盘中。如果服务器发生停机故障,可能刚好发生在数据等待同步的那 1 秒之内,就会导致数据丢失,因此无法保证事务的持久性。
- 当 Redis 配置文件中的 appendfsync 属性的值为 no 时,服务器命令数据同步保存到硬盘中的操作将由操作系统来控制,因此,事务数据在同步的过程中,可能会因为一些原因而丢失,这种情况也不能保证事务的持久性。后面的章节将会详细介绍 Redis 的持久化。
appendfsync 属性在 redis.conf 配置文件中的配置如图 9.1 所示。

● 如果 Redis 服务器使用了 RDB 持久化方式,那么,只有在特定的保存条件被满足时,服务器才会执行 BGSAVE 命令,实现数据的保存。而如果是异步执行 BGSAVE 命令,那么服务器并不能保证在第一时间将事务数据保存到硬盘中,因此也就不能保证事务的持久性。换句话说,RDB 持久化方式不能保证事务具有持久性。
9.3 Redis 事务处理
前面简单介绍了 Redis 事务及 Redis 事务的 ACID 特性,本节主要讲解 Redis 事务的实 现过程。Redis 事务是通过 MULTI、EXEC、DISCARD、WATCH 等命令实现的,大致分为 3 个步骤:使用 MULTI 命令开启事务;事务命令入队;使用 EXEC 命令执行事务。下面介 绍具体过程。
9.3.1 事务的实现过程
事务的实现过程大致分为 3 个步骤,具体如下。
1.使用 MULTI 命令开启事务执行 MULTI 命令之后总是返回 OK,表示事务状态开启成功,它会将执行该命令的客户端从非事务状态转化为事务状态。客户端状态的 flags 属性通过打开 REDIS_MULTI 标识来实现这一转化过程。MULTI 命令执行如下:
127.0.0.1:6379> MULTI
OK
2.事务命令入队 在没有执行 MULTI 命令之前,也就是没有开启事务之前,这个客户端处于非事务状态, 它发送过去的命令会被服务器立即执行,并返回相应的结果。操作如下:
x127.0.0.1:6379> SELECT 1
OK
127.0.0.1:6379[1]> keys *
(empty list or set)
127.0.0.1:6379[1]> SET name "liuhefei"
OK
127.0.0.1:6379[1]> GET name
"liuhefei"
127.0.0.1:6379[1]> SADD user "zhangsan" "lisi" "liuhefei"
(integer) 3
127.0.0.1:6379[1]> SMEMBERS user
1) "lisi"
2) "liuhefei"
3) "zhangsan"
127.0.0.1:6379[1]> LRANGE user 0 -1
(error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379[1]> LPUSH userName "lisi" "zhangsan"
(integer) 2
127.0.0.1:6379[1]> LRANGE userName 0 -1
1) "zhangsan"
2) "lisi"
通过上面的实例可以看出,当客户端处于非事务状态时,执行命令不管对与错都会立即返回结果。与此不同的是,这个客户端在开启事务之后,客户端状态就会变为事务状态,服务器会根据客户端发送过来的不同命令执行不同的操作。
● 当服务器接收到客户端发送过来的命令是 MULTI、EXEC、WATCH、DISCARD 4 个命令中的任意一个时,服务器会立即执行这个命令。
● 相反,当服务器接收到客户端发送过来的命令是 MULTI、EXEC、WATCH、DISCARD 4 个命令以外的其他命令时,服务器不会立即执行这个命令,而是将该命令放入一个事务队列中,然后返回 QUEUED 标识给客户端。
以上这两个过程转化为流程图如图 9.2 所示。
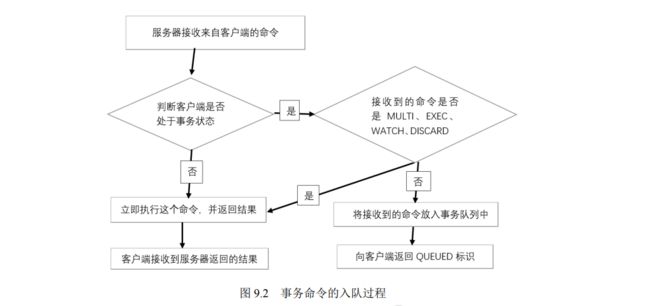
图 9.2 就是事务命令的入队过程,每个 Redis 客户端都有自己的事务状态,而 mstate属性就保存了这个客户端的事务状态。事务状态由一个事务队列和一个入队命令的计数器组成。其中,事务队列是一个 multiCmd 类型的结构体数组,它采用先进先出(FIFO)的方式保存入队的命令,先入队的命令将会被放到数组的前面,先执行;而后入队的命令则被放到数组的后面,后执行。这个数组中的每个 multiCmd 结构都保存了一个入队命令的信息,具体包括指向命令实现函数的指针、命令的参数及参数数量等。
在开启一个事务后,命令逐个入队,并返回 QUEUED 标识。操作如下:
127.0.0.1:6379[1]> MULTI
OK
127.0.0.1:6379[1]> LPUSH userName "liuhefei"
QUEUED
127.0.0.1:6379[1]> LPUSH age 24
QUEUED
127.0.0.1:6379[1]> LLEN userName
QUEUED
在命令入队的过程中,如果想要放弃执行该事务,则可以使用 DISCARD 命令。当处于事务状态的服务器接收到 DISCARD 命令后,它会放弃执行这个事务,并清空事务中的命令队列,然后退出事务上下文,客户端状态变为非事务状态。你可以把它理解为事务回滚,但是 Redis 数据库并不具有事务回滚机制。
在开启事务之后,向事务队列中插入多条命令,然后使用 DISCARD 命令放弃执行该事务。操作如下
127.0.0.1:6379[1]> MULTI #开启事务
OK
#添加多个城市及对应的 GDP 到有序集合 citys-GDP 中
127.0.0.1:6379[1]> ZADD citys-GDP 9765 "beijing" 8799 "shanghai" 8543 "shenzhen"
QUEUED
127.0.0.1:6379[1]> ZRANGE citys-GDP 0 -1 WITHSCORES
QUEUED
127.0.0.1:6379[1]> ZCOUNT citys-GDP 8800 9500
QUEUED
127.0.0.1:6379[1]> DISCARD #取消执行事务
OK
127.0.0.1:6379[1]> ZRANGE citys-GDP 0 -1 WITHSCORES
(empty list or set)
可以看到,当入队的是 DISCARD 命令时,服务器会放弃执行这个事务,并返回 OK,所以之前入队的命令并不会被执行,如 ZADD citys-GDP 9765 “beijing” 8799 “shanghai” 8543 “shenzhen” 命令并没有被执行。因此,citys-GDP 有序集合也是空集合,当使用 ZRANGE citys-GDP 0 -1 WITHSCORES 命令获取这个有序集合的内容时,返回的是空集合。
- 使用 EXEC 命令执行事务
在客户端开启事务,在命令入队的过程中,当服务器接收到来自客户端的 EXEC 命令时,这个 EXEC 命令会被立即执行。服务器在接收到 EXEC 命令后,会遍历这个客户端的事务队列,然后按顺序、逐条执行这个队列中的所有命令,最后将执行返回的结果以列表的形式返回给客户端。
开启事务,事务命令入队,当服务器接收到 EXEC 命令时,就开始执行事务命令,并按照命令的入队顺序返回结果。操作如下:
127.0.0.1:6379[1]> MULTI
OK
127.0.0.1:6379[1]> LPUSH userName "lisi" #将用户名“lisi”添加到列表 userName 中
QUEUED
127.0.0.1:6379[1]> LPUSH age 23
QUEUED
127.0.0.1:6379[1]> LPUSH userName "zhangsan" "xiaohua" "xiaohong" #添加多个用户名到
列表中
QUEUED
127.0.0.1:6379[1]> LRANGE userName 0 -1
QUEUED
127.0.0.1:6379[1]> LINDEX userName 2 #返回列表 userName 中下标为 2 的用户名
QUEUED
127.0.0.1:6379[1]> EXEC #触发执行事务
1) (integer) 4
2) (integer) 2
3) (integer) 7
4) 1) "xiaohong"
2) "xiaohua"
3) "zhangsan"
4) "lisi"
5) "liuhefei"
6) "zhangsan"
7) "lisi"
5) "zhangsan"
9.3.2 悲观锁和乐观锁
悲观锁,顾名思义,就是很悲观,它的疑心比较重,喜欢多虑,它每次去数据库中取数据的时候都会认为别人会修改这些数据,所以它每次取数据的时候都会给这些数据加锁,不让别人使用,别人想拿这些数据就会阻塞直到它释放锁、别人获得锁为止。在传统的关系型数据库中,使用了大量的悲观锁,如行锁、表锁、读锁、写锁等,这些锁都是在操作数据之前加上的。
乐观锁,顾名思义,就是很乐观,它拥有开阔的胸襟,每次去数据库中取数据的时候,都认为别人不会修改这些数据,所以它不会给这些数据加锁。但是它也很细心,每次在更新这些数据的时候,都会判断一下在此期间有没有别人更新过这些数据。如果别人更新过这些数据,它就会放弃本次更新;相反,如果别人没有更新过这些数据,它就会更新这些数据。乐观锁比较适用于多读的应用类型,可以提高吞吐量。
乐观锁的实现策略:使用版本号(version)机制实现。就是为相关的数据设置一个版本标识。在基于数据库表的版本解决方案中,在通常情况下,通过为数据库表设置一个“version”字段,来实现在读取数据时,将此版本号一同读出,更新之后,对此版本号加1。此时,用数据库表对应记录的当前版本号与你提交的版本号进行比较,如果提交的版本号高于当前版本号,则执行更新操作;否则认为是过期数据,不进行更新。换句话说,就是提交的版本号必须高于当前版本号才能执行更新操作。
9.3.3 事务的 WATCH 命令
事务的WATCH命令用于监视事务中的命令。有了WATCH命令的监视,就会使得EXEC命令需要有条件地执行,只有在所有被 WATCH 命令监视的数据库键都没有被修改的前提下,这个事务才能执行成功。如果所有被监视的数据库键中有任意一个数据库键被修改,那么这个事务都会执行失败。下面详细介绍 WATCH 命令的用法及如何触发 WATCH 命令。
- WATCH 命令的用法
其实,WATCH 命令就是一个乐观锁。在执行 EXEC 命令之前,可以使用 WATCH 命令来监视任意数量的数据库键。当执行 EXEC 命令时,服务器会检查被 WATCH 命令监视的数据库键是否至少有一个已经被修改过,如果发现其中的某个数据库键被修改过,那么这个事务将会被服务器拒绝执行,并向客户端返回表示事务执行失败的空回复。
使用 WATCH 命令来监视数据库键,并执行事务。操作如下:
127.0.0.1:6379[1]> SET name "lisi"
OK
127.0.0.1:6379[1]> SET age 23
OK
127.0.0.1:6379[1]> WATCH name age
OK
127.0.0.1:6379[1]> MULTI
OK
127.0.0.1:6379[1]> SET name "zhangsan"
QUEUED
127.0.0.1:6379[1]> SET age 25
QUEUED
127.0.0.1:6379[1]> INCRBY age 3
QUEUED
127.0.0.1:6379[1]> GET name
QUEUED
127.0.0.1:6379[1]> GET age
QUEUED
127.0.0.1:6379[1]> EXEC
1) OK
2) OK
3) (integer) 28
4) "zhangsan"
5) "28"
以上代码展示的是一个使用 WATCH 命令监视数据库键并成功执行事务的例子。下面开启两个客户端,一个客户端正常执行事务,另一个客户端修改其中的 name 键,就会导致事务执行失败。
客户端 1:
127.0.0.1:6379> WATCH name age
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> SET name "zhangsan"
QUEUED
127.0.0.1:6379> GET name
QUEUED
127.0.0.1:6379> SADD user "liuhefei" 24
QUEUED
127.0.0.1:6379> SMEMBERS user
QUEUED
127.0.0.1:6379> SPOP user
QUEUED
127.0.0.1:6379> EXEC
(nil)
127.0.0.1:6379> GET name
"xiaosan"
客户端 2:
127.0.0.1:6379> SET name "xiaosan"
OK
两个客户端执行命令的过程如下。
客户端 1:
(1)WATCH name age #WATCH 命令同时监视 name 键和 age 键
(2)MULTI #开启事务上下文
(3)SET name “zhangsan” #修改 name 键的值
(4)GET name #获取 name 键的值
(5)SADD user “liuhefei” 24 #SADD 命令将多个元素添加到 user 集合中
(6)SMEMBERS user #SMEMBERS 命令返回集合中的所有键
(7)SPOP user #SPOP 命令随机移除 user 集合中的一个元素客户端 2:
(8)SET name “xiaosan” #修改 name 键的值
客户端 1
(9)EXEC #执行事务
(10)GET name #获取到客户端 1 设置的值,为“xiaosan”
在使用 WATCH 命令监视 name 键后,客户端 1 开启事务修改了 name 键的值,之后客户端 2 又修改了 name 键的值,在执行 EXEC 命令之后事务执行失败,原因是 WATCH 命令监视的 name 键被修改了,也就破坏了事务的一致性。
一个 WATCH 命令可以被多次调用,它也能同时监视多个数据库键。对数据库键的监视从 WATCH 命令执行之后开始,直到 EXEC 命令执行完毕为止。当 EXEC 命令被执行后,不管这个事务是否执行成功,WATCH 命令都会取消监视所有的数据库键。当客户端与服务器断开连接时,该客户端对数据库键的监视也会被取消。
也可以手动取消对数据库键的监视,只要使用 UNWATCH 命令就可以实现。UNWATCH命令不带任何参数,使用它可以取消 WATCH 命令对所有数据库键的监视。如果在执行了WATCH 命令后,EXEC 或 DISCARD 命令也被提前执行了,就不需要执行 UNWATCH 命令了。所以,除了 UNWATCH 命令可以清除连接中的所有监视,EXEC、DISCARD 命令也可以清除连接中的所有监视。
使用 UNWATCH 命令取消 WATCH 命令对数据库键的监视,返回 OK。操作如下:
127.0.0.1:6379> LPUSH citys "wuhan" "changsan" "kunming"
(integer) 3
127.0.0.1:6379> WATCH citys #监视列表 citys
OK
127.0.0.1:6379> LPUSH citys "hangzhou"
(integer) 4
127.0.0.1:6379> UNWATCH #取消监视
OK
在服务器与客户端的连接过程中,被 WATCH 命令监视的数据库键都是有效的,事务也是一样的。如果断开了它们之间的连接,那么监视和事务都会被自动取消,然后被清除。
每个 Redis 数据库都有一个 watched_keys 字典,这个字典中的键就是某个被 WATCH命令监视的数据库键,而字典中的值是一个链表,用于记录所有监视数据库键的客户端。服务器通过查看 watched_keys 字典,就能知道被监视的数据库键,以及哪些客户端正在监视这些数据库键。
2.触发 WATCH 命令监视机制
我们在使用 SET、HSET、LPUSH、RPUSH、SADD、SREM、ZADD、DEL、FLUSHALL、FLUSHDB 等命令对数据库进行修改时,在执行命令后都会调用 multi.c/touchWatchKey 函数对 watched_keys 字典进行检查,以此来判断是否有其他客户端正在监视刚被命令修改过的数据库键。如果发现这些数据库键被客户端监视,那么 touchWatckKey 函数将会打开监视被修改数据库键的客户端的 REDIS_DIRTY_CAS 标识,它表示该客户端的事务安全已经被破坏。这就是 WATCH 命令的监视机制。
当客户端将 EXEC 命令发送给服务器时,服务器在接收到 EXEC 命令后,会判断这个
客户端是否打开了 REDIS_DIRTY_CAS 标识,进而决定是否执行这个事务。如果客户端打开了 REDIS_DIRTY_CAS 标识,就说明在客户端所监视的数据库键中,至少存在一个数据库键已经被修改了,也就是事务安全已经被破坏了,此时服务器会拒绝执行客户端提交的这个事务。
如果客户端没有打开 REDIS_DIRTY_CAS 标识,就说明客户端所监视的数据库键没有被修改过,事务是安全的,服务器将会继续执行客户端提交的这个事务。
我们使用流程图来表示服务器判断是否执行这个事务的过程,如图 9.3 所示。
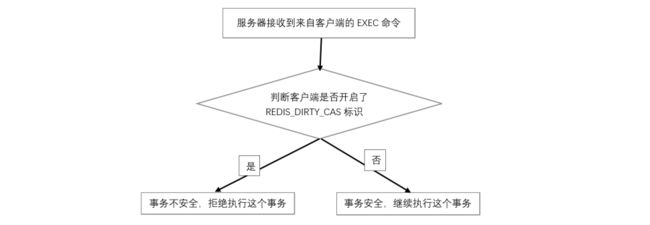
目前,Redis 数据库有两种处理事务的方法:事务功能和脚本功能。其实,脚本本身就是一种事务,在事务中可以完成的事情,同样能在脚本中完成。脚本使用方便,速度也更快。以上就是 Redis 的全部事务功能,相信读者已经学会了。学习是一种态度,也是一种习惯,唯有坚持,你才会变得更优秀
10.消息订阅
本章的主题为 Redis 的订阅发布,我们主要围绕订阅发布模式来讲解,首先为读者介 绍什么是消息订阅发布模式,然后介绍 Redis 消息订阅的相关知识,如何实现 Redis 的消息 订阅功能,以及 Redis 队列的相关知识。
10.1 消息订阅发布概述
什么是消息订阅发布模式呢?消息订阅发布模式一种常用的设计模式,它具有一对多的依赖关系,它有 3 个角色:主题(Topic)、订阅者(Subscriber)、发布者(Publisher)。简单来说,就是让多个订阅者对象同时监听某个发布者发布的主题对象,当这个主题对象的状态发生变化时,所有订阅者对象都会收到通知,使它们自动更新自己的状态。这里所说的主题就是一条消息内容,每条消息可以被多个订阅者订阅。发布者与订阅者具有一对多的关系,它们之间存在依赖性,订阅者必须订阅主题后才能接收到发布者发布的消息,在订阅前发布的消息,订阅者是接收不到的。这就是消息订阅发布模式,如图 10.1 所示。
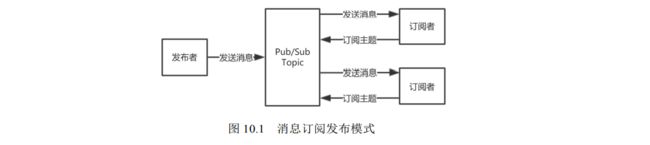
Redis 的消息订阅发布功能主要由 PSUBSCRIBE 、 PUBLISH 、 PUBSUB 、PUNSUBSCRIBE、SUBSCRIBE、UNSUBSCRIBE 等命令实现。当一个客户端使用 PUBLISH命令向订阅者发布消息内容时,这个客户端就是消息发布者。而当另一个或多个客户端使用 SUBSCRIBE 或 PSUBSCRIBE 命令接收消息的时候,这个客户端就是消息订阅者。通过执行 SUBSCRIBE 命令,客户端(消息订阅者)可以同时订阅多个频道(Channel),当有其他客户端(消息发布者)向被订阅的频道发送消息时,所有订阅这个频道的消息订阅者都会接收到这条消息。
这里所说的频道就是一个中介,因为消息发布者与消息订阅者之间存在依赖关系,为了解耦两者之间的关系,就使用了频道作为中介。消息发布者将消息发送给频道,而这个频道在接收到消息后,负责把这条消息发送给所有订阅过这个频道的消息订阅者。消息发布者不需要知道具体有多少消息订阅者,一个消息订阅者可以订阅一个或多个消息频道,并且它只能接收已订阅过的频道中的消息。同理,消息订阅者也不需要知道具体有哪些消息发布者,它们之间不存在相互关系,也不需要知道对方是否存在,这就做到了很好的解耦。
10.2 消息订阅发布实现
10.2.1 消息订阅发布模式命令
下面介绍几个与消息订阅发布有关的命令。
1.PUBLISH 消息发布者将消息发送给指定的频道,返回一个整数,表示接收到这条消息的客户端 的数量。 命令格式如下: PUBLISH channel message
2.SUBSCRIBE
客户端订阅指定的消息频道。一旦客户端进入订阅状态,它就不能运行除 SUBSCRIBE、
PSUBSCRIBE、UNSUBSCRIBE 和 PUNSUBSCRIBE 命令之外的其他命令了。
# 命令格式如下:
SUBSCRIBE channel [channel …]
具体操作如下。
客户端 1:消息发布者发布消息。
127.0.0.1:6379> PUBLISH infomation "The harder you work,the luckier you get"
(integer) 0 #为 0,表示没有订阅者
127.0.0.1:6379> PUBLISH infomation "who are you?"
(integer) 1 #为 1,表示有一个订阅者
127.0.0.1:6379> PUBLISH infomation "where is this?"
(integer) 1
127.0.0.1:6379> PUBLISH infomation "My name is liuhefei"
(integer) 1
127.0.0.1:6379> PUBLISH infomation "I like girl"
(integer) 1
127.0.0.1:6379> PUBLISH infomation "hello redis!"
(integer) 2 #为 2,表示有两个订阅者
客户端 2:消息订阅者订阅消息。
127.0.0.1:6379> SUBSCRIBE infomation
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "infomation"
3) (integer) 1
1) "message"
2) "infomation"
3) "who are you?"
1) "message"
2) "infomation"
3) "where is this?"
1) "message"
2) "infomation"
3) "My name is liuhefei"
1) "message"
2) "infomation"
3) "I like girl"
1) "message"
2) "infomation"
3) "hello redis!"
客户端 3:消息订阅者订阅消息
127.0.0.1:6379> SUBSCRIBE infomation
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "infomation"
3) (integer) 1
1) "message"
2) "infomation"
3) "hello redis!"
3.PSUBSCRIBE
客户端根据指定的模式来订阅符合这个模式的频道。该命令可以重复订阅一个频道,它支持 glob 风格的模式。
● h?llo:可以订阅 hello、hallo 和 hxllo 频道(?表示单个任意字符)。
● h*llo:可以订阅 hllo 和 heeeello 频道(*表示多个任意字符,包括空字符)。
● h[ae]llo:可以订阅 hello 和 hallo 频道,但是不能订阅 hillo 频道(选择[和]之间的任
意一个字符)。
如果?、*、[、]等符号不是通配符,而只是简单的字符,则需要使用“\”符号进行转义。比如,h?llo:表示消息订阅者只能订阅 h?llo 频道。
命令格式如下:
PSUBSCRIBE pattern [pattern …]
该命令的用法具体如下。
客户端 1:消息发布者给不同频道发送消息。
127.0.0.1:6379> PUBLISH infomation "Lucky today"
(integer) 3 #表示有 3 个订阅者
127.0.0.1:6379> PUBLISH infomation "Beautiful girl"
(integer) 3
127.0.0.1:6379> PUBLISH message "There is good news"
(integer) 1
127.0.0.1:6379> PUBLISH mess "If so"
(integer) 1
127.0.0.1:6379> PUBLISH info "with grief"
(integer) 1
127.0.0.1:6379> PUBLISH messy "It was a messy job"
(integer) 1
客户端 2:消息订阅者同时订阅多个频道的消息。
127.0.0.1:6379> PSUBSCRIBE info* mess*
Reading messages... (press Ctrl-C to quit)
1) "psubscribe"
2) "info*"
3) (integer) 1
1) "psubscribe"
2) "mess*"
3) (integer) 2
1) "pmessage"
2) "info*"
3) "infomation"
4) "Lucky today"
1) "pmessage"
2) "info*"
3) "infomation"
4) "Beautiful girl"
1) "pmessage"
2) "mess*"
3) "message"
4) "There is good news"
1) "pmessage"
2) "mess*"
3) "mess"
4) "If so"
1) "pmessage"
2) "info*"
3) "info"
4) "with grief"
1) "pmessage"
2) "mess*"
3) "messy"
4) "It was a messy job"
- PUNSUBSCRIBE
客户端根据指定的模式退订符合该模式的所有频道。如果不指定任何模式,则默认退订所有的频道。
命令格式:
PUNSUBSCRIBE [pattern [pattern …]]
该命令的用法具体如下:
127.0.0.1:6379> PUNSUBSCRIBE info* #退订符合 info*模式的频道
1) "punsubscribe"
2) "info*"
3) (integer) 0
127.0.0.1:6379> PUNSUBSCRIBE mess* #退订符合 mess*模式的频道
1) "punsubscribe"
2) "mess*"
3) (integer) 0
127.0.0.1:6379> PUNSUBSCRIBE #退订所有的频道
1) "punsubscribe"
2) (nil)
3) (integer) 0
注意:使用 PUNSUBSCRIBE 命令只能退订通过 PSUBSCRIBE 命令订阅的模式,它不会影响直接通过 SUBSCRIBE 命令订阅的频道,也不会影响通过 PSUBSCRIBE 命令订阅的模式。
5.UNSUBSCRIBE
客户端退订指定的频道。如果没有指定任何频道参数,那么所有已订阅的频道都会被退订。
命令格式如下:
UNSUBSCRIBE [channel [channel …]]
该命令的用法具体如下:
127.0.0.1:6379> UNSUBSCRIBE info*
1) "unsubscribe"
2) "info*"
3) (integer) 0
127.0.0.1:6379> UNSUBSCRIBE mess*
1) "unsubscribe"
2) "mess*"
3) (integer) 0
127.0.0.1:6379> UNSUBSCRIBE *
1) "unsubscribe"
2) "*"
3) (integer) 0
注意:如果客户端是在 Redis 命令行(redis-cli)中进入消息订阅监听状态的,那么使 用 PUNSUBSCRIBE 命令退订消息模式和使用 UNSUBSCRIBR 命令退订消息频道的操作都 会执行失败,也就是消息订阅退订失败。必须通过 telnet 之类的工具才能在消息订阅监听 状态下执行退订操作。
- PUBSUB 命令
PUBSUB 命令是一个自检命令,可用于检查发布/订阅子系统的状态。这个命令是由几个子命令组成的,命令格式如下:
PUBSUB [argument [argument …]]
● PUBSUB CHANNELS [pattern]:该命令用于返回服务器被订阅的有效频道。有效频道是具有一个或多个订阅者(不包括订阅模式的客户端)的发布/订阅频道。
如果没有指定任何模式,也就是没有 pattern 参数,则默认列举出所有的有效频道。如果指定了模式,也就是设置了 pattern 参数,则会列举出符合这个模式规则的所有频道(使用 glob 风格模式)。
这个命令的返回值是一个数组,通过遍历服务器 pubsub_channels 字典中的所有键,它会列出所有的有效频道,包括匹配指定模式的有效频道。时间复杂度为 O(N),N 是有效频
道的数量。
该命令的用法具体如下。
客户端 1:消息发布者向多个频道发送消息。
127.0.0.1:6379> PUBLISH messy "don't worry"
(integer) 3
127.0.0.1:6379> PUBLISH message "Life is a messy and tangled business"
(integer) 4
127.0.0.1:6379> PUBLISH infos "come on"
(integer) 2
127.0.0.1:6379> PUBLISH infomation "You look very nice"
(integer) 5
客户端 2:使用 PUBSUB 命令列出当前活跃的消息频道。
127.0.0.1:6379> PUBSUB CHANNELS
1) "message"
2) "messy"
3) "infomation"
127.0.0.1:6379> PUBSUB CHANNELS 2
(empty list or set)
127.0.0.1:6379> PUBSUB CHANNELS *
1) "message"
2) "infomation"
PUBSUB NUMSUB [channel-1 … channel-N]:该命令接收多个频道作为输入参数,用于获取指定频道的订阅者的数量。它通过在 pubsub_channels 字典中找到频道对应的订阅者链表,然后返回订阅者链表的长度,这个长度值就是频道订阅者的数量,它不包括订阅模式的客户端。它返回一个数组,用于列出参数指定的所有频道,以及每个频道的订阅者的数量。返回值的格式为频道、数量、频道、数量、……因此,这个列表是扁平的。返回值列出的频道排列顺序和命令调用时指定频道的排列顺序是相同的。注意,在调用这个命令时可以不指定频道,此时返回值是一个空列表。当返回 0时,表示这个频道没有任何订阅者。时间复杂度为 O(N),N 是命令中指定的频道数量。
使用 PUBSUB 命令获取指定频道订阅者的数量,操作如下:
127.0.0.1:6379> PUBSUB NUMSUB infomation infos message mess messy
1) "infomation"
2) (integer) 5
3) "infos"
4) (integer) 2
5) "message"
6) (integer) 4
7) "mess"
8) (integer) 0
9) "messy"
10) (integer) 3
● PUBSUB NUMPAT :该命令用于获取模式的订阅数量(所有客户端运行 PSUBSCRIBE 命令的总次数)。这个子命令是通过返回 pubsub_patterns 链表的长度 来实现的,返回的这个长度就是服务器被订阅模式的数量。注意,这个数量不是订 阅模式的客户端的数量,而是所有客户端订阅的模式的总数量。它返回一个整数, 表示所有客户端订阅的模式的总数量。
使用 PUBSUB 命令统计当前模式的订阅数量,操作如下:
127.0.0.1:6379> PUBSUB NUMPAT
(integer) 6
10.2.2 消息订阅功能之订阅频道
当一个客户端执行 SUBSCRIBE 命令订阅一个或多个频道时,这个客户端与被订阅的频道之间就建立了一种订阅频道关系,这个订阅频道关系将会被保存到服务器状态的pubsub_channels 字典里面。这个字典也是一个键值对,字典中的键就是某个被订阅的频道,而字典中的值就是一个链表,这个链表记录了所有订阅这个频道的客户端。这个字典的示意图如图 10.2 所示。

当客户端订阅某个频道时,服务器会将这个频道与客户端在 pubsub_channels 字典中进行关联。这个关联操作可以分为两步,具体根据这个频道是否已经有其他订阅者来划分。
● 如果这个频道被其他订阅者订阅,那么这个订阅者链表信息一定会在pubsub_channels 字典中,此时相关的程序就要把订阅这个频道的客户端添加到链表的末尾。
● 如果这个频道没有任何订阅者订阅,那么 pubsub_channels 字典中就不存在订阅关系,此时需要程序为这个频道在 pubsub_channels 字典中创建一个键,并把这个键对应的值设为空链表,最后将这个客户端添加到链表中,成为链表的第一个元素。
当客户端执行 UNSUBSCRIBE 命令来退订某个或某些频道时,服务器将从pubsub_channels 字典中删除被退订频道与客户端之间的关联关系。程序会根据被退订频道的名称,在 pubsub_channels 字典中进行查找,找到这个频道后,会将与这个频道相关联的退订客户端的链表信息删除。删除退订客户端之后,频道的订阅者链表变为空链表,此时说明已经没有任何订阅者订阅这个频道了,程序接着会删除 pubsub_channels 字典中这个频道所对应的键。
所有订阅频道与客户端的关系都记录在服务器状态的 pubsub_channels 字典中。在使用PUBLISH 命令将消息发送给所有订阅这个频道的订阅者时,PUBLISH 命令要做的就是在pubsub_channels 字典中查找到所有订阅这个频道的订阅者名单(订阅者链表),然后将消息发送给名单中的所有订阅者。这个过程就是 PUBLISH 命令将消息发送给频道订阅者。订阅频道推送消息的格式有以下几种。
-
subscribe 消息subscribe 消息表示客户端已经成功地订阅了指定的频道。返回信息的第一个值是subscribe 字符串,表示指定的频道订阅成功;第二个值是订阅成功的频道名称;第三个值是目前已经成功订阅的频道数量。
-
unsubscribe 消息unsubscribe 消息表示客户端已经成功取消订阅指定的频道。返回信息的第一个值是unsubscribe 字符串,表示已经成功退订指定的频道;第二个值是要退订的频道名称;第三个值是当前客户端订阅的频道数量。如果第三个值为 0,则表示这个客户端没有订阅任何频道。
-
message 消息message 消息表示订阅频道的客户端已经成功地收到了另一个客户端向这个频道发送过来的消息。换句话说,就是消息订阅者成功地收到了消息发布者向频道发送的消息。返回信息的第一个值是 message 字符串,表示返回值的类型是消息;第二个值是发送消息的频道名称;第三个值是消息的内容
10.2.3 消息订阅功能之订阅模式
当客户端执行 PSUBSCRIBE 命令订阅某个或某些消息模式时,这个客户端与被订阅的消息模式之间就建立了一种订阅模式关系,这个订阅模式关系将会被保存到服务器状态的pubsub_patterns 属性里面。pubsub_patterns 属性是一个链表,这个链表中的每个节点都包含着一个 pubsubPattern 结构体,这个结构体具有 client 和 pattern 两个属性,client 属性表示订阅模式的客户端,而 pattern 属性表示被订阅的模式。
每当消息订阅者订阅某个或某些消息模式时,服务器总会对每个被订阅的消息模式执行下面的操作:
● 重新创建一个 pubsubPattern 结构体,并为这个结构体的 client 和 pattern 属性赋值,client 属性被赋值为订阅模式的客户端,pattern 属性被赋值为被订阅的模式。
● 将这个新建的 pubsubPattern 结构体添加到 pubsub_patterns 链表的表尾。以上两步操作的具体过程用链表结构表示如图 10.3 所示。
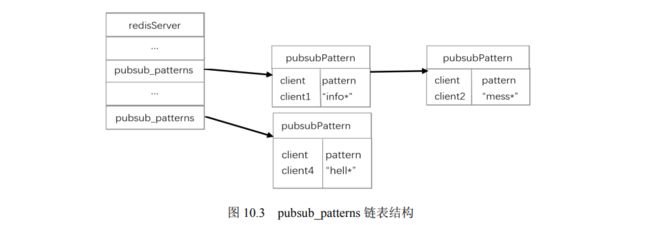
当客户端执行 PUNSUBSCRIBE 命令来退订某个或某些订阅模式时,服务器将会从pubsub_patterns 链表中,根据 PUNSUBSCRIBE 命令指定的模式来查找与这个模式相匹配的订阅模式,然后删除 pattern 属性为退订模式,并且 client 属性为执行退订模式的客户端的 pubsubPattern 结构体。
服务器状态中的 pubsub_patterns 链表记录了所有消息订阅模式的订阅关系。在使用PUBLISH 命令将消息发送给所有与消息频道模式相匹配的订阅者时,PUBLISH 命令需要遍历整个 pubsub_patterns 链表,查找出与消息频道相匹配的模式,然后将消息发送给订阅了这些模式的客户端。这个过程就是 PUBLISH 命令将消息发送给模式订阅者。
如果某个客户端同时订阅了多个消息模式,或者多个消息模式和消息频道,并且这些模式都能匹配到同一条消息,那么这个客户端将会收到多条相同的消息。订阅模式推送消息的格式有以下几种。
1.psubscribe 消息
psubscribe 消息表示客户端已经成功订阅了指定的模式。返回信息的第一个值是 psubscribe字符串;第二个值是订阅的模式名称;第三个值是客户端当前已经订阅的模式数量。
2.punsubscribe 消息
punsubscribe 消息表示客户端已经成功退订了指定的消息模式。返回信息的第一个值是punsubscribe 字符串,表示成功退订了指定的模式;第二个值是想要退订的模式名称;第三个值是客户端当前已经订阅的模式数量。如果第三个值为 0,则表示这个客户端没有订阅任何模式。
3.pmessage 消息
pmessage 消息表示订阅模式的客户端已经成功地收到了另一个客户端向这个模式所对应的频道发送的消息。换句话说,就是消息订阅者成功收到了消息发布者所发送的与之模式相匹配的消息。
10.3 Redis 消息队列
常见的消息队列有两种模式,分别是消息订阅发布模式和消息生产者/消费者模式。Redis 的消息队列也是基于这两种模式实现的。下面我们来具体介绍。
10.3.1 消息订阅发布模式的原理
消息发布者将消息发送到相应的频道(这里的频道也可以理解为队列),消息订阅者通过订阅这个消息频道,就能接收到消息发布者所发送的消息。只要是订阅了这个消息频道的订阅者,它们接收到的消息都是一样的,也就是消息发布者将消息发送给了每位订阅者。在前面的小节中已经详细介绍了消息订阅发布模式,这里不再多说。
消息订阅发布模式原理图如图 10.4 所示。
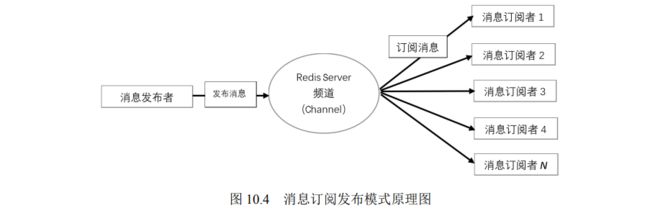
说明:当消息发布者发送一条消息到 Redis Server 后,只要消息订阅者订阅了该频道,就可以接收到这样的信息。同时,消息订阅者可以订阅不同的频道。
消息订阅发布模式的适用场景:微信公众号、订阅号的推送,新闻 App 的推送,商城系统的信息推送等。
10.3.2 消息生产者/消费者模式的原理
消息生产者将生产的消息放入消息队列里,多个消息消费者同时监听这个消息队列,谁先抢到消息,谁就从消息队列中取走消息去处理,即对于每条消息,只能被最多一个消费者消费。消息订阅发布模式不需要抢夺消息,每个订阅者得到的消息都是一样的。而消息生产者/消费者模式是一种“抢”的模式,就是消息生产者每生产并发送一条消息,只有一个消息消费者可以获得消息,谁的网速快、人品好,谁就可以获得那条消息。消息生产者/消费者模式原理图如图 10.5 所示。

说明:消息生产者/消费者模式也有多个消费者来消费,但是只能有一个消费者可以获得消息,其他消息消费者就只能继续监听消息队列,等待下一次抢消息。消息生产者/消费者模式的适用场景:用户系统登录注册接收短信注册码、登录码,订单系统下单成功的短信,抢红包等。
以上就是 Redis 的消息订阅与消息队列的相关知识,在后面的实战章节中,我们还会给出相应的例子,期待大家继续学习。
11.redis持久化
本章讲解 Redis 的持久化功能,解读 Redis 的持久化方式——AOF 持久化和 RDB 持久 化,并介绍这两种方式的配置、用法及优缺点,因为只有深入了解它们的用法与特点,才 能更好地应用它们,进而解决更多问题。
11.1 Redis 持久化操作概述
AOF(Append Only File)持久化保存服务器执行的所有写操作命令到单独的日志文件 中,在服务器重启时,通过加载日志文件中的这些命令并执行来恢复数据。这个日志文件 就是 AOF 文件,Redis 将会以 Redis 协议格式来保存 AOF 文件中的所有命令,新命令会被 追加到文件的结尾。在服务器的后台,AOF 文件还会被重写(Rewrite),使得 AOF 文件 的体积不会大于保存数据集状态所需的实际大小。
当使用 Redis 来存储一些需要长久保存的数据时,一般需要打开 AOF 持久化来降低进 程突然中止,导致数据丢失的风险。
11.2.1 AOF 持久化的配置
在默认情况下,AOF 持久化没有被开启。而如果我们要采用 AOF 持久化方式来保存数据,就要开启 AOF 持久化。可以通过修改配置文件 redis.conf 中的 appendonly 参数开启,如下:
appendonly yes
在开启 AOF 持久化后,服务器每执行一条写命令,Redis 就会把该命令写入硬盘的 AOF 文件中。AOF 文件位置可以通过 dir 参数来设置。AOF 文件的默认名称是 appendonly.aof, 可以通过 appendfilename 参数来修改 AOF 文件的名称,如下:
appendfilename "appendonly.aof"
与 AOF 持久化相关的配置总结如下。
● appendonly no:是否开启 AOF 持久化,默认为 no,不开启,设置为 yes 表示开启AOF 持久化。
● appendfilename “appendonly.aof”:AOF 文件名,可以修改它。
● dir ./:AOF 文件和 RDB 文件所在目录。
● appendfsync everysec:fsync 持久化策略。
● no-appendfsync-on-rewrite no:在重写 AOF 文件的过程中,是否禁止 fsync。如果这个参数值设置为 yes(开启),则可以减轻重写 AOF 文件时 CPU 和硬盘的负载,但同时可能会丢失重写 AOF 文件过程中的数据;需要在负载与安全性之间进行平衡。
● auto-aof-rewrite-percentage 100:指定 Redis 重写 AOF 文件的条件,默认为 100,它会对比上次生成的 AOF 文件大小。如果当前 AOF 文件的增长量大于上次 AOF 文件的 100%,就会触发重写操作;如果将该选项设置为 0,则不会触发重写操作。
● auto-aof-rewrite-min-size 64mb:指定触发重写操作的 AOF 文件的大小,默认为64MB。如果当前 AOF 文件的大小低于该值,此时就算当前文件的增量比例达到了auto-aof-rewrite-percentage 选项所设置的条件,也不会触发重写操作。换句话说,只有同时满足以上这两个选项所设置的条件,才会触发重写操作。
● auto-load-truncated yes:当 AOF 文件结尾遭到损坏时,Redis 在启动时是否仍加载AOF 文件。
11.2.2 AOF 持久化的实现
在开启 AOF 持久化之后,Redis 服务器每执行一条写命令,AOF 文件都会记录这条写命令。因为需要实时记录 Redis 的每条写命令,因此 AOF 不需要触发就能实现持久化。AOF 持久化的实现过程如下。
(1)命令追加(append):Redis 服务器每执行一条写命令,这条写命令都会被追加到缓存区 aof_buf 中。在追加命令的过程中,Redis 并没有直接将命令写入文件中,而是将命令追加到缓存区aof_buf 的末尾。这样做的目的是避免每次执行的命令都直接写入硬盘中,会导致硬盘 I/O的负载过大,使得性能下降。
命令追加的格式使用 Redis 命令请求的协议格式,它是一种纯文本格式,具有很多优点,如兼容性好、易处理、易读取、操作简单、可避免二次开销等。比如,执行以下命令:
127.0.0.1:6379>SET name redis
OK
服务器在接收到客户端发送过来的 SET 命令之后,会将下面的协议格式内容追加到缓 存区 aof_buf 的末尾:
*3\r\n$3\r\nSET\r\n$3\r\nname\r\n$5\r\nredis\r\n
以上就是 AOF 持久化追加命令的原理。在 AOF 文件中,除了用于切换数据库的 select 命令是由 Redis 添加的,其他写命令都是客户端发送过来的。
(2)AOF 持久化文件写入(write)和文件同步(sync):根据 appendfsync 参数设置的不同的同步策略,将缓存区 aof_buf 中的数据内容同步到硬盘中。
Redis 为 AOF 缓存区的同步提供了多种策略,策略涉及操作系统的 write 和 fsync 函数。为了提高文件的写入效率,当用户调用 write 函数将数据写入文件中时,操作系统会将这些数据暂存到一个内存缓存区中,当这个缓存区被填满或者超过了指定时限后,才会将缓存区中的数据写入硬盘中,这样做既提高了效率,又保证了安全性。
Redis 的服务器进程是一个事件循环(loop),这个事件循环中的文件事件负责接收客户端的命令请求,处理之后,向客户端发送命令回复;而其中的时间事件则负责执行像serverCron 函数这样需要定时运行的函数。
服务器在处理文件事件时,可能会执行客户端发送过来的写命令,使得一些命令被追加到缓存区 aof_buf 中。因此,在服务器每次结束一个事件循环之前,都会调用
flushAppendOnlyFile 函数,来决定是否将缓存区 aof_buf 中的数据写入和保存到 AOF 文件中。flushAppendOnlyFile 函数的运行与服务器配置的 appendfsync 参数有关。appendfsync 参数具有多个值,具体如下。
当 appendfsync 参数的值为 always 时,flushAppendOnlyFile 函数会将缓存区 aof_buf中的所有内容写入并同步到 AOF 文件中。
服务器的文件事件每循环一次,都要将缓存区 aof_buf 中的所有内容写入 AOF 文件中,并同步 AOF 文件,这个过程在无形中加大了硬盘 I/O 的负载,使得硬盘 I/O 成为性能瓶颈,从而严重降低 Redis 的性能。所以使用 always 的效率比较低,但从安全性考虑,使用 always 是最安全的。即使 Redis 服务器出现故障,AOF 持久化也只会丢失最近一次事件循环中的命令数据。
● 当 appendfsync 参数的值为 no 时,flushAppendOnlyFile 函数会将缓存区 aof_buf 中的所有内容写入 AOF 文件中,但不会同步 AOF 文件,至于什么时候同步则交给操作系统来决定,通常同步周期为 30 秒。在使用 no 时,AOF 文件的同步不可控,且缓存区中的内容会越来越多,一旦发生故障,将会丢失大量数据。因为不用执行 AOF同步操作,所以 AOF 写入数据的速度总是最快的,效率也很高。
● 当 appendfsync 参数的值为 everysec 时,flushAppendOnlyFile 函数会将缓存区 aof_buf中的所有内容写入 AOF 文件中。而 AOF 文件的同步操作则由一个专门的文件同步线程负责,每秒执行一次。如果上次同步 AOF 文件的时间距离现在超过了 1 秒,同步线程就会再次对 AOF 文件进行同步。在使用 everysec 时,AOF 文件的写入与同步效率非常高,它是前面两种策略的折中,是性能和数据安全性的平衡,既满足了效率要求,又考虑了安全性,推荐使用。
在 Redis 配置文件 redis.conf 中的配置如下:
# appendfsync always
appendfsync everysec #默认使用 everysec
# appendfsync no
11.2.3 AOF 文件重写
1.AOF 文件重写的目的 定期重写 AOF 文件,以达到压缩的目的。
AOF 持久化的实现是通过保存被执行的写命令来保存数据库数据的。随着服务器运行时间的增加,AOF 文件的内容数据会越来越大,文件所占据的内存也会变大。过大的 AOF文件会影响服务器的正常运行,在执行数据恢复时,将会耗费更多的时间。
为了解决 AOF 文件体积过大的问题,Redis 提供了 AOF 文件重写的功能,就是定期重写 AOF 文件,以减小 AOF 文件的体积。其实,AOF 文件重写就是把 Redis 进程内的数据转化为写命令,然后同步到新的 AOF 文件中。在重写的过程中,Redis 服务器会创建一个新的 AOF 文件来替代现有的 AOF 文件,新、旧两个 AOF 文件所保存的数据库状态相同,但是新的 AOF 文件不会包含冗余命令。
Redis 将生成新的 AOF 文件替换旧的 AOF 文件的功能命名为“AOF 文件重写”。实际上,AOF 文件重写并不会对旧的 AOF 文件进行读取、写入操作,这个功能是通过读取服务器当前的数据库状态来实现的。
通过客户端向服务器端发送多条 RPUSH 命令,向列表中添加多个颜色元素,并成功执行。操作如下:
127.0.0.1:6379> RPUSH color "red" "blue" #向列表 color 中添加多个颜色元素
(integer) 2
127.0.0.1:6379> RPUSH color "yellow" "green" "black"
(integer) 5
127.0.0.1:6379> LPOP color #移除并返回列表 color 的头元素
"red"
127.0.0.1:6379> LPOP color
"blue"
127.0.0.1:6379> RPUSH color "pink" "white"
(integer) 5
Redis 服务器在开启了 AOF 持久化之后,就会保持当前列表 color 键的状态,在 AOF文件中写入 5 条命令。如果服务器想用最少的命令来保存列表 color 键的状态,就要利用AOF 文件重写功能。最简单的方法不是去读取和分析现有 AOF 文件的内容,而是直接从数据库中读取出列表 color 键的值,用一条 RPUSH color “yellow” “green” “black” “pink” "white"命令来代替保存在 AOF 中的 5 条命令,这样就实现了 AOF 文件重写功能。除上面所说的列表键之外,其他类型的键也可以用同样的方法去减少 AOF 文件中的命令数量,也就是直接去数据库中读取该键所存储的值,然后用一条命令记录来代替之前这个键值对的多条写命令,这就是 AOF 文件重写功能的原理。此时,聪明的读者可能会问:为什么 AOF 文件重写可以压缩 AOF 文件?
原因有如下几点:
● AOF 文件重写功能会丢弃过期的数据,也就是过期的数据不会被写入 AOF 文件中。
● AOF 文件重写功能会丢弃无效的命令,无效的命令将不会被写入 AOF 文件中。无效命令包括重复设置某个键值对时的命令、删除某些数据时的命令等。
● AOF 文件重写功能可以将多条命令合并为一条命令,然后写入 AOF 文件中。在实际应用中,Redis 为了防止在执行命令时造成客户端缓存区溢出,重写程序在处理列表、哈希表、集合及有序集合这 4 种可能会带有多个元素的键时,会提前检查这些键所
包含的元素个数。
假如键所包含的元素个数大于 redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD 常量的值,那么重写程序会使用多条命令来记录这个键的值。REDIS_AOF_REWRITE_ITEMS_PER_CMD 常量的值为 64。比如,一个列表键或集合键所包含的元素个数大于 64 个,那么重写程序会使用多条RPUSH 或 SADD 命令来记录这个列表或集合,每条命令设置的元素个数为 64 个,超出部分用另一条命令继续保存。
2.AOF 文件重写的触发方式
AOF 文件重写的触发有两种方式:手动触发和自动触发。
● 手动触发:执行 BGREWRITEAOF 命令触发 AOF 文件重写。该命令与 BGSAVE 命令相似,都是启动(fork)子进程完成具体的工作,且都在启动时阻塞。
如图 11.1 所示为执行 BGREWRITEAOF 命令触发 AOF 文件重写。

自动触发:自动触发 AOF 文件重写是通过设置 Redis 配置文件中 auto-aof-rewritepercentage 和 auto-aof-rewrite-min-size 参数的值,以及 aof_current_size 和 aof_base_size状态来确定何时触发的。
auto-aof-rewrite-percentage 参数是在执行 AOF 文件重写时,当前 AOF 文件的大小(aof_current_size)和上一次 AOF 文件重写时的大小(aof_base_size)的比值,默认为 100。auto-aof-rewrite-min-size 参数设置了执行 AOF 文件重写时的最小体积,默认为 64MB。使用 CONFIG GET 命令来查看上述参数的值,操作如下:
127.0.0.1:6379> CONFIG GET auto-aof-rewrite-percentage
1) "auto-aof-rewrite-percentage"
2) "100"
127.0.0.1:6379> CONFIG GET auto-aof-rewrite-min-size
1) "auto-aof-rewrite-min-size"
2) "67108864"
使用 INFO PERSISTENCE 命令来查看 AOF 持久化的相关状态,操作如下:
127.0.0.1:6379> INFO PERSISTENCE
# Persistence
…
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:0
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:184320
只有当 Redis 服务器同时满足 auto-aof-rewrite-percentage 和 auto-aof-rewrite-min-size 参 数值时,才会触发 AOF 文件重写。
- AOF 文件后台重写
在实现 AOF 文件重写的过程中,会调用 aof_rewrite 函数创建一个新的 AOF 文件,同时将旧的 AOF 文件的命令重写到新的 AOF 文件中,在这个过程中会执行大量的写入操作,就会使得这个函数的线程被长时间阻塞。Redis 服务器使用单线程来处理命令请求。如果让服务器直接调用 aof_rewrite 重写函数,那么在 AOF 文件重写期间,服务器将不能继续执行其他命令,就会一直处于阻塞状态。显然,对于这样的情况,我们是不希望看到的。因此,Redis 将 AOF 文件重写程序放到了一个子进程中执行,这样做的好处是:
● 子进程在执行AOF文件重写的过程中,Redis服务器进程可以继续处理新的命令请求。
● 子进程带有服务器进程的数据副本,使用子进程可以在使用锁的情况下,保证数据的安全性。
使用子进程会导致数据库状态不一致,原因是:当子进程进行 AOF 文件重写的时候,Redis 服务器可以继续执行来自客户端的命令请求,就会有新的命令对现有数据库状态进行修改,进而使得服务器当前的数据库状态与重写的 AOF 文件所保存的数据库状态不一致。
为了解决使用子进程导致数据库状态不一致的问题,Redis 服务器设置了一个 AOF 文件重写缓存区。这个 AOF 文件重写缓存区在服务器创建子进程之后开始使用,可以利用它来解决数据库状态不一致的问题。当 Redis 服务器成功执行完一条写命令后,它会同时将这条写命令发送给 AOF 文件缓存区(aof_buf)和 AOF 文件重写缓存区。子进程在执行 AOF 文件重写的过程中,服务器进程的执行过程如下:
(1)服务器接收到来自客户端的命令请求,并成功执行。
(2)服务器将执行后的写命令转化为对应的协议格式,然后追加到 AOF 文件缓存区(aof_buf)中。
(3)服务器再将执行后的写命令追加到 AOF 文件重写缓存区中。
以上过程用流程图表示如图 11.2 所示。

有了 AOF 文件重写缓存区,就可以保证数据库状态的一致性。AOF 文件缓存区的内容会被定期写入和同步到 AOF 文件中,AOF 文件的写入和同步不会因为 AOF 文件重写缓存区的引入而受到影响。当服务器创建子进程之后,服务器执行的所有写命令都会同时被追加到 AOF 文件缓存区和 AOF 文件重写缓存区中。
如果子进程完成了 AOF 文件重写的工作,它就会发送一个完成信号给父进程。当父进程接收到这个信号后,就会调用信号处理函数,继续执行以下工作:
(1)将 AOF 文件重写缓存区中的所有内容写入新的 AOF 文件中。新的 AOF 文件所保存的数据库状态与服务器当前的数据库状态保持一致。
(2)修改新的 AOF 文件的文件名,新生成的 AOF 文件将会覆盖现有(旧)的 AOF文件,完成新、旧两个文件的互换。
在完成上述两个步骤之后,就完成了一次 AOF 文件后台重写工作。在整个 AOF 文件后台重写的过程中,只有在信号处理函数执行的过程中,服务器进程才会被阻塞,在其他时候不存在阻塞情况。
11.2.4 AOF 文件处理
如果我们开启了 AOF 持久化,那么在 Redis 服务器启动的时候,就会首先加载 AOF文件中的数据来恢复数据库数据。因为 AOF 文件中保存了数据库状态所需的所有写命令,所以服务器读取并执行 AOF 文件中的写命令,就可以还原服务器关闭之前的数据库状态。
这个过程具体如下:
(1)创建一个伪客户端,用于执行 AOF 文件中的写命令。这个伪客户端是一个不带网络连接的客户端。因为只能在客户端的上下文中才能执行 Redis 的命令,而在 AOF 文件中包含了 Redis 服务器启动加载 AOF 文件时所使用的所有命令,而不是网络连接,所以服务器创建了一个不带网络连接的伪客户端来执行 AOF 文件中的写命令。
(2)读取 AOF 文件中的数据,分析并提取出 AOF 文件所保存的一条写命令。
(3)使用伪客户端执行被读取出的写命令。
(4)重复执行步骤(2)和(3),直到将 AOF 文件中的所有命令读取完毕,并成功执行为止。这个过程完成之后,就可以将服务器的数据库状态还原为关闭之前的状态。
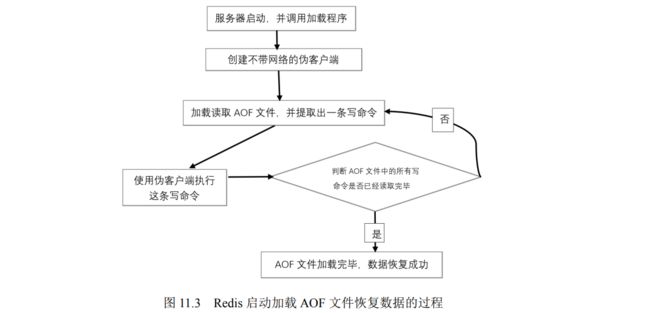
如果在 Redis 服务器启动加载 AOF 文件时,发现 AOF 文件被损坏了,那么服务器会拒绝加载这个 AOF 文件,以此来确保数据的一致性不被破坏。而 AOF 文件被损坏的原因可能是程序正在对 AOF 文件进行写入与同步时,服务器出现停机故障。如果 AOF 文件被损坏了,则可以通过以下方法来修复。
● 及时备份现有 AOF 文件。
● 利用 Redis 自带的 redis-check-aof 程序,对原来的 AOF 文件进行修复,命令如下:$ redis-check-aof –fix
● 使用 diff -u 来对比原始 AOF 文件和修复后的 AOF 文件,找出这两个文件的不同之处。
● 修复 AOF 文件之后,重启 Redis 服务器重新加载,进行数据恢复。
11.2.5 AOF 持久化的优劣
AOF 持久化具有以下优点:
● 使用 AOF 持久化会让 Redis 持久化更长:通过设置不同的 fsync 策略来达到更长的
持久化。具体有 3 种策略。
- 当有新的写命令追加到 AOF 文件末尾时,就执行一次 fsync。这种方式虽然速度
比较慢,但是很安全。 - 设置为每秒执行一次 fsync。这种方式速度比较快,如果发生故障,则只会丢失 1
秒内的数据,即兼顾了效率与安全性,推荐使用。 - 从不执行 fsync,而是直接将数据交给操作系统来处理。这种方式虽然速度比较
快,但是安全性比较差,不建议使用。
● 兼容性比较好:AOF 文件是一个日志文件,它的作用是记录服务器执行的所有写命令。当文件因为某条写命令写入失败时,可以使用 redis-check-aof 进行修复,然后继续使用。
● 支持后台重写:当 AOF 文件的体积过大时,在后台可以自动地对 AOF 文件进行重写,因此数据库当前状态的所有命令集合都会被重写到 AOF 文件中。重写完成后,Redis 就会切换到新的 AOF 文件,继续执行写命令的追加操作。
● AOF 文件易于读取和加载:AOF 文件保存了对数据库的所有写命令,这些写命令采用 Redis 协议格式追加到 AOF 文件中,因此非常容易读取和加载。
AOF 持久化具有以下缺点:
● AOF 文件的体积会随着时间的推移逐渐变大,导致在加载时速度会比较慢,进而影响数据库状态的恢复速度,性能快速下降。
● 根据所使用的 fsync 策略,使用 AOF 文件恢复数据的速度可能会慢于使用 RDB 文件恢复数据的速度。
● 因为 AOF 文件的个别命令,可能会导致在加载时失败,从而无法进行数据恢复。
11.3 Redis 持久化机制 RDB
Redis 持久化机制 RDB 与持久化机制 AOF 类似,都是为了避免 Redis 服务器在内存中 的数据因为服务器进程的退出而丢失而建立的一种持久化机制。RDB 持久化生成的 RDB 文件是一个经过压缩的二进制文件,也可以称之为快照文件,通过该文件可以还原生成 RDB 文件时的数据库状态。因为 RDB 文件保存在硬盘上,所以,就算服务器停止服务, 也可以利用 RDB 文件来还原数据库状态。
11.3.1 RDB 持久化
在指定的时间间隔内,RDB 持久化可以生成数据集的时间点快照。换句话说,就是可以通过快照来实现 RDB 持久化。在指定的时间间隔内,Redis 会自动将内存中的所有数据生成一份副本并存储在硬盘上,这个过程就是“快照”。
- 快照处理的发生条件当出现以下几种情况时,Redis 会对数据进行快照处理。
● 根据 Redis 配置文件 redis.conf 中的配置自动进行快照(自动触发)。在 Redis 中,用户可以根据实际需要自行定义快照条件,当符合快照条件时,服务器会自动执行快照操作。快照条件是在 Redis 配置文件 redis.conf 中设置的,用户可以自定义,格式为:save m n。它由两个参数构成:时间 m 和被修改的键的个数 n。当在时间 m 内被
修改的键的个数大于 n 时,就会触发 BGSAVE 命令,服务器就会自动执行快照操作。Redis 配置文件 redis.conf 中的默认设置如下:
save 900 1
save 300 10
save 60 10000
以上 3 个快照条件都是以 save 属性开头的,它们之间是“或”的关系,也就是每次只有其中一个快照条件会被执行。
- save 900 1:表示在 900 秒内有 1 个或 1 个以上的键被修改就会进行快照处理。
- save 300 10:表示在 300 秒内有 10 个或 10 个以上的键被修改就会进行快照处理。
- save 60 1000:表示在 60 秒内有 1000 个或 1000 个以上的键被修改就会进行快照处理。
Redis 的 save m n 命令是通过 serverCron 函数、dirty 计数器及 lastsave 时间戳来实现的。
serverCron 函数:这是 Redis 服务器的周期性操作函数,默认每隔 100 毫秒执行一次,它主要的作用是维护服务器的状态。其中一项工作就是判断 save m n 配置的条件是否满足,如果满足就会触发执行 BGSAVE 命令。
dirty 计数器:这是 Redis 服务器维持的一种状态,它主要用于记录上一次执行 SAVE或 BGSAVE 命令后,服务器进行了多少次状态修改(执行添加、删除、修改等操作);当SAVE 或 BGSAVE 命令执行完成后,服务器会将 dirty 重新设置为 0。dirty 计数器记录的是服务器进行了多少次状态修改,而不是客户端执行了多少次修改数据的命令。
比如,执行以下命令:
127.0.0.1:6379>SADD color red blue green yellow
(integer) 4
程序会将 dirty 计数器的值增加 4。
lastsave 时间戳:主要用于记录服务器上一次成功执行 SAVE 或 BGSAVE 命令的时间,它是 Redis 服务器维持的一种状态。
dirty 计数器和 lastsave 时间戳属性都保存在服务器状态的 redisServer 结构中。
save m n 命令的实现原理:服务器每隔 100 毫秒执行一次 serverCron 函数;serverCron函数会遍历 save m n 配置的保存条件,判断是否满足。如果有一个条件满足,就会触发执行 BGSAVE 命令,进行快照保存。
对于每个 save m n 条件,只有以下两个条件同时满足才算满足:
- 当前服务器时间减去 lastsave 时间戳大于 m。
- 当前 dirty 计数器的个数大于等于 n。
● 用户在客户端执行 SAVE 或 BGSAVE 命令时会触发快照(手动触发)。
● 如果用户定义了自动快照条件,则执行 FLUSHALL 命令也会触发快照。当执行 FLUSHALL 命令时,会清空数据库中的所有数据。如果用户定义了自动快照条件,则在使用 FLUSHALL 命令清空数据库的过程中,就会触发服务器执行一次快照。
● 如果用户为 Redis 设置了主从复制模式,从节点执行全量复制操作,则主节点会执行 BGSAVE 命令,将生产的 RDB 文件发送给从节点完成快照操作。
2.快照的实现过程
(1)Redis 调用执行 fork 函数复制一份当前进程(父进程)的副本(子进程),也就是同时拥有父进程和子进程。
(2)父进程与子进程各自分工,父进程继续处理来自客户端的命令请求,而子进程则将内存中的数据写到硬盘上的一个临时 RDB 文件中。
(3)当子进程把所有数据写完后,也就表示快照生成完毕,此时旧的 RDB 文件将会被这个临时 RDB 文件替换,这个旧的 RDB 文件也会被删除。这个过程就是一次快照的实现过程。当 Redis 调用执行 fork 函数时,操作系统会使用写时复制策略。也就是在执行 fork 函数的过程中,父、子进程共享同一内存数据,当父进程要修改某个数据时(执行一条写命令),操作系统会将这个共享内存数据另外复制一份给子进程使用,以此来保证子进程的正确运行。因此,新的 RDB 文件存储的是执行 fork 函数过程中的内存数据。
写时复制策略也保证了在执行 fork 函数的过程中生成的两份内存副本在内存中的占用量不会增加一倍。但是,在进行快照的过程中,如果写操作比较多,就会造成 fork 函数执行前后数据差异较大,此时会使得内存使用量变大。因为内存中不仅保存了当前数据库数据,还会保存 fork 过程中的内存数据。
在进行快照生成的过程中,Redis 不会修改 RDB 文件。只有当快照生成后,旧的 RDB文件才会被临时 RDB 文件替换,同时旧的 RDB 文件会被删除。在整个过程中,RDB 文件是完整的,因此我们可以使用 RDB 文件来实现 Redis 数据库的备份。
11.3.2 RDB 文件
在默认情况下,Redis 将数据库快照保存在名为 dump.rdb 的文件中,这个文件被称为RDB 文件,它是一个经过压缩的二进制文件。使用 RDB 文件可以还原生成 RDB 文件的数据库状态,也可以备份数据库数据。
RDB 文件的存储路径可以在启动前配置,也可以通过命令来直接修改。配置文件配置:在 Redis 的配置文件 redis.conf 文件中,dir 用于指定 RDB 文件、AOF文件所在的目录,默认存放在 Redis 根目录下;dbfilename 用于指定文件名称。
命令修改:在 Redis 服务器启动后,也可以通过命令来修改 RDB 文件的存储路径,命令格式如下:
CONFIG SET dir {文件路径}
CONFIG SET dbfilename {新文件名}

在 RDB 文件结构中,通常使用大写字母表示常量,使用小写字母表示变量和数据。
RDB 文件主要由图 11.4 中的几个常量和变量组成,具体说明如下。
● REDIS 常量:该常量位于 RDB 文件的头部,它保存着“REDIS”5 个字符,它的长度是 5 字节。在 Redis 服务器启动加载文件时,程序会根据这 5 个字符判断加载的文件是不是 RDB 文件。
● db_version 常量:该常量用于记录 RDB 文件的版本号,它的值是一个用字符串表示的整数,占 4 字节,注意区分它不是 Redis 的版本号。
● databases 数据:它包含 0 个或多个数据库,以及各个数据库中的键值对数据。
如果它包含 0 个数据库,也就是服务器的数据库状态为空,那么 databases 也是空的,其长度为 0 字节;如果它包含多个数据库,也就是服务器的数据库状态不为空,那么databases 不为空,根据它所保存的键值对的数量、类型和内容不同,其长度也是不一样的。如果 databases 不为空,则 RDB 文件结构如图 11.5 所示。

其中,SELECTDB 是一个常量,表示其后的数据库编号,这里的 0 和 1 是数据库编号。pairs 数据:它存储了具体的键值对信息,包括键(key)、值(value)、数据类型、内部编码、过期信息、压缩信息等。
SELECT 0 pairs 表示 0 号数据库;SELECT 1 pairs 表示 1 号数据库。当数据库中有键值对时,RDB 文件才会记录该数据库的信息;而如果数据库中没有键值对,这一部分就会被 RDB 文件省略。
● EOF 常量:该常量是一个结束标志,它标志着 RDB 文件的正文内容结束,其长度为 1 字节。在加载 RDB 文件时,如果遇到 EOF 常量,则表示数据库中的所有键值对都已经加载完毕。
● check_sum 变量:该变量用于保存一个校验和,这个校验和是通过对 REDIS、db_version、databases、EOF 4 部分的内容进行计算得出的,是一个无符号整数,其长度为 8 字节。
当服务器加载 RDB 文件时,会将 check_sum 变量中保存的校验和与加载数据时所计算出来的校验和进行比对,从而判断加载的 RDB 文件是否被损坏,或者是否有错误。
关于更多 RDB 文件的知识,请读者自行查阅相关资料。
在默认情况下,Redis 服务器会自动对 RDB 文件进行压缩。在 Redis 配置文件 redis.conf中,默认开启压缩。配置如下:
rdbcompression yes #默认为开启压缩
如果不想开启压缩,则可以将 yes 值改为 no。也可以通过命令来修改,命令格式如下:
CONFIG SET rdbcompression no
在默认情况下,Redis 采用 LZF 算法进行 RDB 文件压缩。在压缩 RDB 文件时,不要误认为是压缩整个 RDB 文件。实际上,对 RDB 文件的压缩只是针对数据库中的字符串进行的,并且只有当字符串达到一定长度(20 字节)时才会进行压缩。
11.3.3 RDB 文件的创建与加载
前面说了很多 RDB 文件的相关知识,读者可能还没有明白 RDB 文件是怎么来的,下面将详细介绍。
RDB 文件可以使用命令直接生成。在 Redis 中,有 SAVE 和 BGSAVE 命令可以生成RDB 文件。
在执行 SAVE 命令的过程中,会阻塞 Redis 服务器进程,此时 Redis 服务器将不能继续执行其他命令请求,直到 RDB 文件创建完毕为止。执行 SAVE 命令:
127.0.0.1:6379>SAVE
OK
返回 OK 表示 RDB 文件保存成功。
在执行 BGSAVE 命令的过程中,BGSAVE 命令会派生出一个子进程,交由子进程将内存中的数据保存到硬盘中,创建 RDB 文件;而 BGSAVE 命令的父进程可以继续处理来自客户端的命令请求。
执行 BGSAVE 命令:
127.0.0.1:6379>BGSAVE
Background saving started
返回 Background saving started 信息,但我们并不能确定 BGSAVE 命令是否已经成功执行,此时可以使用 LASTSAVE 命令来查看相关信息。执行 LASTSAVE 命令:
127.0.0.1:6379> LASTSAVE
(integer) 1531998138
返回一个 UNIX 格式的时间戳,表示最近一次 Redis 成功将数据保存到硬盘中的时间。其实,真正创建 RDB 文件的不是 SAVE 或 BGSAVE 命令,而是 Redis 中的 rdb.c/rdbSave函数。在执行 SAVE 或 BGSAVE 命令后,会以不同的方式调用执行这个函数,进而完成RDB 文件的创建。
RDB 文件的创建可用于在启动 Redis 服务器的时候恢复数据库的状态,起到备份数据库的作用。RDB 文件只有在启动服务器的时候才会被加载。当启动服务器时,它会检查RDB 文件是否存在,如果存在,就会自动加载 RDB 文件。除此之外,RDB 文件不会被加载,因为 Redis 中没有提供用于加载 RDB 文件的命令。

其中的信息 DB loaded from disk: 0.000 seconds 就是服务器在加载完 RDB 文件之后打印的,这里的时间为 0.000,是因为 RDB 文件过小,加载几乎不耗费时间。
聪明的读者可能会有疑问:在启动 Redis 服务器的时候,到底是先加载 AOF 文件,还是先加载 RDB 文件呢?
在通常情况下,AOF 文件的更新频率比 RDB 文件的更新频率高得多,服务器每执行一条写命令,就会更新一次 AOF 文件。其实,在启动 Redis 服务器的时候,会执行一个加载程序,这个加载程序会根据 Redis配置文件中是否开启了 AOF 持久化,来判断是加载 AOF 文件还是加载 RDB 文件。
● 如果在 Redis 配置文件中开启了 AOF 持久化(appendonly yes),那么在启动服务器的时候会优先加载 AOF 文件来还原数据库状态。
● 如果在 Redis 配置文件中关闭了 AOF 持久化(appendonly no),那么在启动服务器的时候会优先加载 RDB 文件来还原数据库状态。
加载 RDB 文件的实际工作由 rdb.c/rdbLoad 函数完成。服务器启动加载 AOF 文件或 RDB 文件的过程如图 11.7 所示。

11.3.4 创建与加载 RDB 文件时服务器的状态
在创建文件时,服务器的状态具体如下:
当执行 SAVE 命令的时候,将会阻塞 Redis 服务器,客户端发送过来的命令请求将会被拒绝执行。只有当 SAVE 命令执行结束之后,服务器才能再次接收并执行来自客户端的命令请求。
当执行 BGSAVE 命令的时候,将会启动一个子进程来创建并保存 RDB 文件,在子进程创建 RDB 文件的过程中,父进程仍然可以处理来自客户端的命令请求。
如果在服务器执行 BGSAVE 命令的过程中,客户端向服务器发送过来的命令是 SAVE、BGSAVE 或 BGREWRITEAOF,就会有不同的执行策略,具体说明如下。
● 在执行 BGSAVE 命令的过程中,如果客户端发送过来的命令是 SAVE,那么该命令会被服务器拒绝执行。因为在执行 SAVE 命令的时候,服务器会被阻塞,这个时候子进程也在执行,就会造成父进程和子进程同时调用 rdbSave 函数,产生竞争条件。为了避免这种情况的发生,服务器就会拒绝执行 SAVE 命令。
● 在执行 BGSAVE 命令的过程中,如果客户端发送过来的命令是 BGSAVE,那么服务器会拒绝执行 BGSAVE 命令。因为服务器如果同时执行两个 BGSAVE 命令,则也会产生竞争条件。
● 在执行 BGSAVE 命令的过程中,如果客户端发送过来的命令是 BGREWRITEAOF,那么这个命令会推迟到 BGSAVE 命令执行完成之后才会被执行。相反地,如果在执行 BGREWRITEAOF 命令的过程中,客户端发送过来的命令是 BGSAVE,那么服务器会拒绝执行 BGSAVE 命令。BGSAVE 和 BGREWRITEAOF 命令都是采用子进程来完成任务的,所以这两个命令不能同时执行。
服务器在加载 RDB 文件时,会一直处于阻塞状态,直到 RDB 文件加载完毕,才会变
为运行状态。
使用 INFO PERSISTENCE 命令来查看 RDB 持久化的相关状态,操作如下:
127.0.0.1:6379> INFO PERSISTENCE
# Persistence
loading:0
rdb_changes_since_last_save:12
rdb_bgsave_in_progress:0
rdb_last_save_time:1541692112
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:-1
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:0
11.3.5 RDB 持久化的配置
RDB 持久化的配置具体如下。
save m n:表示在时间 m 内被修改的键的个数大于 n 时,会触发 BGSAVE 命令的执行。它是 BGSAVE 命令自动触发的条件;如果没有设置该配置,则表示自动的 RDB持久化被关闭。
● stop-writes-on-bgsave-error yes:当执行 BGSAVE 命令出现错误时,Redis 是否终止执行写命令。参数的值默认被设置为 yes,表示当硬盘出现问题时,服务器可以及时发现,及时避免大量数据丢失;当设置为 no 时,就算执行 BGSAVE 命令发生错误,服务器也会继续执行写命令;当对 Redis 服务器的系统设置了监控时,建议将该参数值设置为 no。
● rdbcompression yes:是否开启 RDB 压缩文件,默认为 yes 表示开启,不开启则设置为 no。
● rdbchecksum yes:是否开启 RDB 文件的校验,在服务器进行 RDB 文件的写入与读取时会用到它。默认设置为 yes。如果将它设置为 no,则在服务器对 RDB 文件进行写入与读取时,可以提升性能,但是无法确定 RDB 文件是否已经被损坏。
● dbfilename dump.rdb:用于设置 RDB 文件名,可以通过命令来修改它,命令格式如下:
CONFIG SET dbfilename RDB 文件名
● dir ./:RDB 文件和 AOF 文件所在目录,默认为 Redis 的根目录。
11.3.6 RDB 持久化的优劣
RDB 持久化具有以下优点:
● RDB 文件是一个经过压缩的二进制文件,文件紧凑,体积较小,非常适用于进行数据库数据备份。
● RDB 持久化适用于灾难恢复,而且恢复数据时的速度要快于 AOF 持久化。
● Redis 采用 RDB 持久化可以很大程度地提升性能。父进程在保存 RDB 文件时会启动一个子进程,将所有与保存相关的功能交由子进程处理,而父进程可以继续处理其他相关的操作。
RDB 持久化具有以下缺点:
● 在服务器出现故障时,如果没有触发 RDB 快照执行,那么它可能会丢失大量数据。RDB 快照的持久化方式决定了必然做不到实时持久化,会存在大量数据丢失。
● 当数据量非常庞大时,在保存 RDB 文件的时候,服务器会启动一个子进程来完成相关的保存操作。这项操作比较耗时,将会占用太多 CPU 时间,从而影响服务器的性能。
● RDB 文件存在兼容性问题,老版本的 Redis 不支持新版本的 RDB 文件。
11.4 AOF 持久化与 RDB 持久化抉择
面对 AOF 持久化和 RDB 持久化,应该选择使用哪一个呢?
在实际的应用场景中,由于存在各种风险因素,你不知道服务器在什么时候会出现故障,也不知道在什么时候可能会断电,又或者有其他一些意想不到的事情发生,这些事情的发生可能会导致 Redis 数据库丢失大量数据,进而造成一些经济损失。为了避免这些情况的发生,强烈建议同时使用 AOF 持久化和 RDB 持久化,以便最大限度地保证数据的持久化与安全性。
你也可以只使用 RDB 持久化,因为 RDB 持久化能够定时生成 RDB 快照,便于进行数据库数据备份,同时也能提高服务器的性能,而且 RDB 恢复数据的速度要快于 AOF 恢复数据的速度;但是,你必须承受如果服务器出现故障,则会丢失部分数据的风险。很多用户只使用 AOF 持久化,但我们并不推荐使用这种方式,因为 AOF 持久化产生的 AOF 文件体积较大,在恢复数据时会比较慢,会严重影响服务器的性能,在生成AOF 文件的时候还可能会出现 AOF 程序 Bug。
如果你现在使用的是 RDB 持久化,想切换到 AOF 持久化,则可以执行以下几步操作:
(1)备份 RDB 文件(dump.rdb),并将备份文件放到一个安全的地方。
(2)在不重启服务器的情况下,执行以下命令:
CONFIG SET appendonly yes #开启 AOF 持久化,服务器开始初始化 AOF 文件,此时 Redis 服务器会
发生阻塞,直到 AOF 文件创建完毕为止,之后服务器才会继续处理来自客户端的命令请求,将写命令追加到 AOF 文
件中。同时需要手动修改 Redis 的配置文件 redis.conf 中的 appendonly 参数值为 yes,否则在下一次重启的
时候,并不会切换使用 AOF 持久化
CONFIG SET save " " #关闭RDB 持久化。也可以不执行该命令,同时使用RDB 持久化和AOF 持久化
(3)执行上述命令后,需要检查数据库中的键数量有没有改变,同时确保写命令会被追加到 AOF 文件中。
至此,Redis 持久化的相关知识点就介绍完了,相信聪明的读者已经熟练掌握了 Redis持久化的应用与相关原理。
12.redis 集群
本章的主题为多数据库之间的集群操作,具体包括 Redis 集群的主从复制模式、哨兵 模式及 Redis 集群模式。Redis 集群在实际中用途广泛,一些大型分布式系统离不开 Redis 集群的支撑,使用 Redis 集群在大流量访问的情况下,能够提供稳定的服务。本章将会一 一介绍主从复制模式、哨兵模式,以及集群的相关概念、配置和它们的实现原理,以此来 帮助读者在实际应用中解决更多的问题,实现更多的业务功能。
12.1 Redis 集群的主从复制模式
在实际应用中,使用单台 Redis 服务器可能会出现服务器故障停机、容量瓶颈、QPS 瓶颈等问题,进而影响系统及网站的正常服务,从而造成不必要的经济损失。为了避免使 用单机出现的问题,引入了 Redis 集群的主从复制模式。
12.1.1 什么是主从复制
在 Redis 中,通过执行 SLAVEOF 命令,或者通过配置文件设置 slaveof 选项,就可以 让一台服务器去复制另一台服务器,其中被复制的服务器叫主服务器(master),而对主 服务器进行复制的服务器叫从服务器(slave),从而实现当主服务器中的数据更新后,根 据配置和策略自动同步到从服务器上。其中,master 以写为主,slave 以读为主。
1.一个简单的主从复制
一个简单的主从复制如图 12.1 所示。

在实现主从复制之后,两台服务器中的数据是一样的。
举一个例子,有 3 台 Redis 服务器 A、B、C,地址分别如下。
● A:127.0.0.1:6379,对应的配置文件为 redis6379.conf。
● B:127.0.0.1:6380,对应的配置文件为 redis6380.conf。
● C:127.0.0.1:6381,对应的配置文件为 redis6381.conf。
执行以下命令启动 3 台服务器:
./redis-server /home/redis/redis-4.0.9/redis6379.conf
./redis-server /home/redis/redis-4.0.9/redis6379.conf
./redis-server /home/redis/redis-4.0.9/redis6379.conf
执行以下命令进入客户端:
./redis-cli -p 6379
./redis-cli -p 6380
./redis-cli -p 6381
进入 6380 客户端向服务器 B 发送以下命令:
127.0.0.1:6380>SLAVEOF 127.0.0.1 6379
OK
进入 6381 客户端向服务器 C 发送以下命令:
127.0.0.1:6381>SLAVEOF 127.0.0.1 6379
OK
如果在主服务器 A 上执行以下命令:
127.0.0.1:6379>SET name "liuhefei"
OK
那么在 A、B、C 3 台服务器上都可以获取到键 name 的值,如下:
127.0.0.1:6379>GET name
"liuhefei"
127.0.0.1:6380> GET name
"liuhefei"
127.0.0.1:6381>GET name
"liuhefei"
如果我们在主服务器 A 上删除了键 name,那么 A、B、C 3 台服务器上的 name 键都会 被删除,如下:
127.0.0.1:6379>DEL name
(integer) 1
127.0.0.1:6379> GET name
(nil)
127.0.0.1:6380> GET name
(nil)
127.0.0.1:6381> GET name
(nil)

可以使用 INFO replication 命令来查看当前服务器的主从复制信息,命令格式如下:
127.0.0.1:6379>INFO replication
主从复制的作用如下:
● 为一个数据提供多个副本,使得高可用、分布式成为可能。
● 扩展 Redis 的读性能,可以实现读写分离。
- 主从复制功能的重要说明
● 一个 master 可以有多个 slave。
● 一个 slave 只能有一个 master。
● 数据流向是单向的,从 master 到 slave。
● 自 Redis 2.8 版本以后,Redis 采用异步复制,从服务器会以每秒一次的频率向主服务器报告复制流的处理进度。
● 除主服务器可以有从服务器之外,从服务器也可以有自己的从服务器,多个从服务器之间可以构成一个网状结构,它们之间具有传递关系。
● 在进行复制的时候,复制功能不会阻塞主服务器,即使有多个从服务器正在进行初次同步时,主服务器也可以继续处理来自客户端的命令请求;同理,复制功能也不会阻塞从服务器,只要在配置文件 redis.conf 中进行了设置,即使从服务器正在进行初次同步,主服务器也可以使用旧版本的数据集来处理命令请求。当从服务器删除旧版本数据集并加载新版本数据集的时候,连接请求会被阻塞,直到加载完毕。
● 如果一个主节点 B 成为另一个主节点 A 的从节点,那么主节点 B 之前保存的数据将会被清除,而同步主节点 A 的数据,数据库状态将与主节点 A 保持一致。
常见的一主多从如图 12.3 所示。
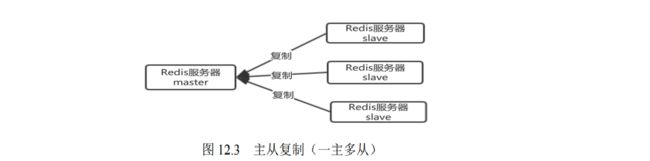
从服务器也可以有自己的从服务器,一台从服务器只能有一台主服务器,如图 12.4 所示。

12.1.2 主从复制配置
Redis 要实现主从复制功能,就必须通过命令或者修改配置文件来实现。
1.SLAVEOF 命令实现主从复制
使用 SLAVEOF ip 端口命令来配置主从复制,这个过程如图 12.5 所示。

127.0.0.1:6380>SLAVEOF 127.0.0.1 6379
OK
其中,127.0.0.1:6380 是从服务器,127.0.0.1:6379 是主服务器。在一般情况下,主、从服务器不建议在一台服务器上,这样做没有任何意义,在这里只是为了演示需要。
如果从服务器不希望成为主服务器的一个从节点,而是希望成为一个主节点,则可以取消复制,使用命令:SLAVEOF no one。命令执行之后,从服务器与主服务器就会断开连接,从服务器就会变为主服务器,之前的数据并不会丢失,只是在断开连接以后,数据不会再继续同步。
127.0.0.1:6380>SLAVEOF no one
OK
从服务器 127.0.0.1:6380 与主服务器 127.0.0.1:6379 断开连接,这个过程如图 12.6 所示。
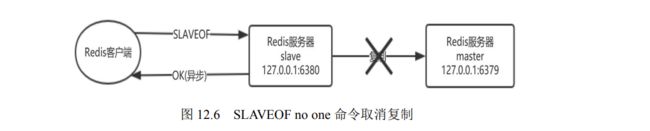
2.修改配置文件实现主从复制
在实际应用中,不可能使用同一台 Redis 服务器来做主从复制,因为那样做没有任何意义。使用多台 Redis 服务器来做主从复制,需要分别修改每台服务器的配置文件 redis.conf。这里以 6380 端口为例,具体需要修改的选项如下:
port 6380 #设置端口
daemonize yes #开启后台进程运行 Redis
pidfile /var/run/redis_6380.pid #设置进程 ID 文件
logfile "6380.log" #设置日志文件名
#save 900 1 #需要关闭,主从复制不需要
#save 300 10
#save 60 10000
dbfilename dump6380.rdb #设置 RDB 文件名
- 与主从复制相关的配置信息
● slaveof :slaveof 复制选项,slave 复制对应的 master,是 master 的 IP 地址,是 master 的端口。该选项默认不开启,
在进行主从复制配置时,在 slave 中需要开启,在 master 中不需要开启。假如 master 的 IP 地址和端口分别为 192.168.1.68:6379,那么 slave 的配置就应该是slaveof 192.168.1.68 6379。
● masterauth :用于配置 master 的密码,在 slave 连接的时候进行认证。如果 master 设置了密码,那么 slave 要连接到 master 上,就需要有 master 的密码。
● slave-serve-stale-data yes:当 slave 与 master 断开连接或者复制正在进行时,slave 有两种运行方式。当值为 yes 时,表示服务器会继续处理来自客户端的命令请求;当值为 no 时,表示服务器对除 INFO 和 SLAVEOF 命令之外的任何命令请求都会返回一个错误。默认值为 yes。
● slave-read-only yes:slave 是否为只读,不建议设置为 no。
● repl-diskless-sync no:是否使用 socket 方式复制数据。Redis 提供了两种复制方式:disk 和 socket。如果新的 slave 连上来或者重连的 slave 无法实现部分同步,就会执行全量同步,master 会生成 RDB 文件。
- 当使用 disk 方式时,master 会创建一个新的进程,先把 RDB 文件保存到硬盘中,再把硬盘中的 RDB 文件传递给 slave。在保存 RDB 文件的过程中,多个 slave 能共享这个 RDB 文件。
- 当使用 socket 方式时,master 会创建一个新的进程,直接把 RDB 文件以 socket 方式发送给 slave。socket 方式就是一个个 slave
顺序复制。 在硬盘读/写速度缓慢、网速快的情况下,推荐使用 socket 方式。
● repl-diskless-sync-delay 5:复制的延迟时间,默认为 5s;不建议设置为 0,因为复制一旦开始,节点不会再接收新 slave 的复制请求,直到下一个 RDB 传输。
● repl-ping-slave-period 10:slave 根据指定的时间间隔向 master 发起 ping 请求,默认时间间隔为 10s。
● repl-timeout 60:复制连接超时时间,默认为 60s。master 和 slave 都有超时时间的设置。如果 master 检测到 slave 上次发送的时间超过 repl-timeout 所设置的值,就会认为 slave 已经处于离线状态,就会清除该 slave 的信息。相反,如果 slave 检测到上次和 master 交互的时间超过了 repl-timeout 所设置的值,就会认为 master 离线。注意:repl-timeout 所设置的值一定要比 repl-ping-slave-period 所设置的值大,否则会常常出现超时。
● repl-disable-tcp-nodelay no:是否禁止复制 TCP 链接的 tcp nodelay 参数,默认为 no,表示允许使用 tcp nodelay。如果 master 将 repl-disable-tcp-nodelay 选项的值设置为yes,以此来禁止使用 tcp nodelay,那么在把数据复制给 slave 的时候,会减少包的数量和网络带宽,同时也可能带来数据的延迟。当传输的数据量较大的时候,推荐设置为 yes。
● repl-backlog-size 1mb:用于设置复制缓冲区的大小,保存复制的命令。当 slave 离线的时候,不需要完全复制 master 的数据。如果可以执行部分同步,则只需要把缓冲区的部分数据复制给 slave,就能保证数据正常恢复。缓冲区的大小越大,slave离线的时间就可以更长。只有在 slave 连接的时候,复制缓冲区才分配内存。当 slave离线的时候,内存会被释放出来。默认缓冲区的大小为 1MB。
● repl-backlog-ttl 3600:设置一段时间,在这段时间内,master 和 slave 断开连接会释放复制缓冲区的内存。默认为 3600s。
● slave-priority 100:设置 slave 的优先级,默认为 100。当 master 出现故障(宕机)不能使用时,Sentinel 会根据 slave 的优先级选举一个新的 master。slave-priority 的值设置得越小,就越有可能被选中成为 master。当 slave-priority 的值为 0 时,表示这个 slave 永远不可能被选中。
● min-slaves-to-write 3:Redis 提供了可以让 master 停止写入的方式。如果配置了min-slaves-to-write 选项,那么,当健康的 slave 的个数小于 N 时,master 就会禁止写入。默认 min-slaves-to-write 选项的值为 3,表示 master 最少要有 3 个健康的 slave存活才能执行写命令。
● min-slaves-max-lag 10:延迟时间小于 min-slaves-max-lag 秒的 slave 才被认为是健康的 slave。默认为 10s,表示只有延迟时间小于 10s 的 slave 才被认为是健康的 slave。
以上相关选项就是 Redis 主从复制的设置,在实际应用中,请根据相关业务场景的需要进行设置。
命令方式与配置方式的优缺点如下。
● 命令方式:优点在于不需要重启服务器,就能实现主从复制;缺点是不便于管理。
● 配置方式:优点在于可以进行统一配置,便于管理;缺点就是配置之后需要重启服务器,相关的配置才能生效。
12.1.3 复制功能的原理
Redis 2.8 版本以后,开始使用 PSYNC 命令代替 SYNC 命令来执行复制时的同步操作。PSYNC 命令具有全量同步(也叫全量复制)和部分同步(也叫部分复制)两种模式。
1.全量同步与部分同步
● 全量同步:用于处理第一次复制的情况,它通过让主服务器创建并发送 RDB 文件,以及向从服务器发送保存在缓冲区里面的写命令来进行同步。
● 部分同步:用于处理从服务器离线后重新连接的复制情况。当从服务器在离线后重新连接到主服务器时,如果条件允许,那么主服务器可以将在从服务器断开连接期间执行的最新写命令发送给从服务器,从服务器在接收并执行这些写命令后,就可以将数据库更新到与主服务器相同的状态,从而达到主从服务器数据库状态的一致性。
PSYNC 命令的部分同步模式解决了 Redis 2.8 以前版本的复制功能在处理离线后重复制时出现的低效问题。
SYNC 和 PSYNC 命令都可以实现让离线的主从服务器重新回到一致性状态,但是,在执行部分同步操作时,使用 PSYNC 命令所需要的资源远远少于使用 SYNC 命令所需的资源,并且完成同步的速度也快很多。执行 SYNC 命令需要生成、发送和加载整个 RDB文件;而执行 PSYNC 命令进行部分同步时,只需要将从服务器缺少的写命令发送过来就可以了。
2.部分同步模式的组成
1)主服务器的复制偏移量(Replication Offset)和从服务器的复制偏移量在执行复制操作的时候,主从服务器都会有一个复制偏移量。当主服务器每次向从服务器发送 N 字节的数据时,就会将自己的复制偏移量的值加上N。而当从服务器每次接收到主服务器发送过来的 N 字节数据时,就会将自己的复制偏移量的值加上 N。
使用 INFO replication 命令来查看主服务器的复制信息,操作如下:
127.0.0.1:6379> INFO replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=101457,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=101457,lag=1
master_replid:d1e198e005ebe1e1a55797120589c6d891c95c38
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:101457
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:101457
选项 master_repl_offset 为主服务器的复制偏移量,这里为 101457。同时我们可以看到 它有两台从服务器,从服务器的复制偏移量都为 101457。 如果主服务器执行如下命令:
127.0.0.1:6379>SET age 20
OK
主服务器会向两台从服务器发送长度为 100 字节的数据,那么主服务器的复制偏移量 将会更新为 101457 + 100 = 101557,而两台从服务器在接收到主服务器发送过来的 100 字 节长度的数据时,也会更新复制偏移量为 101457 + 100 = 101557。命令操作如下:
127.0.0.1:6379> SET age 20
OK
127.0.0.1:6379> INFO replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=101557,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=101557,lag=1
master_replid:d1e198e005ebe1e1a55797120589c6d891c95c38
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:101557
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:101557
通过查看主从服务器的复制偏移量,可以确认主从服务器的数据库是否处于一致状态。如果主从服务器的数据库状态保持一致性,那么主从服务器两者的复制偏移量总是相等的;相反,如果主从服务器的复制偏移量不相等,则说明主从服务器的数据库并未处于一致状态。
2)主从服务器的运行 ID 每台 Redis 服务器都会有自己的运行 ID,运行 ID 在服务器启动的时候会自动生成。运行 ID 由 40 个十六进制字符随机组成,如 1dbe7f0c16dcd87c7596351c1afbfa3ab1dc5eca。
当从服务器对主服务器进行初次复制同步时,主服务器会将自己的运行 ID 发送给从服务器,从服务器接收到主服务器的运行 ID 时,会将它保存起来。如果从服务器发生离线,那么,当再次连接到主服务器时,从服务器将向主服务器发送之前保存的运行 ID,进行身份验证。
● 如果从服务器保存的运行 ID 与当前所连接的主服务器的运行 ID 相同,则说明从服务器离线之前连接的就是这台主服务器,主服务器可以继续执行部分同步操作。
● 如果从服务器保存的运行 ID 与当前所连接的主服务器的运行 ID 不相同,则说明从服务器离线之前连接的并不是这台主服务器,此时主服务器会对这台从服务器执行
全量同步操作。
3)复制缓冲区
复制缓冲区是由主服务器维护的一个固定长度、先进先出的队列。在默认情况下,复制缓冲区的大小为 1MB。
主服务器在执行写命令后,会将写命令发送给所有与它连接的从服务器,同时将这些写命令入队到复制缓冲区中。复制缓冲区中保存了最近发送的写命令,同时会记录队列中的每个字节所对应的复制偏移量。当从服务器发生离线后又重新连接到主服务器时,从服务器会通过 PSYNC 命令将自己的复制偏移量发送给主服务器,主服务器会根据这个复制
偏移量来决定对从服务器是执行全量同步操作,还是执行部分同步操作。
● 如果从服务器的复制偏移量之后的数据存在于复制缓冲区中,那么主服务器会对这台从服务器执行部分同步操作。
● 如果从服务器的复制偏移量之后的数据在复制缓冲区中不存在,那么主服务器会对这台从服务器执行全量同步操作。
3.PSYNC 命令的实现过程
PSYNC 命令有两种调用方式,分别如下。
● 如果从服务器之前没有复制过任何主服务器,或者执行过取消复制的命令SLAVEOF no one,那么从服务器在与主服务器正常连接的情况下,在开始一次新的复制时,从服务器会向主服务器发送 PSYNC ? -1 命令,主动请求主服务器执行全量同步操作,此时不能执行部分同步操作。
● 如果从服务器已经复制过某台主服务器,那么从服务器在开始一次新的复制时,会向主服务器发送 PSYNC 命令,其中,runid 是上一次复制的主服务器的运行 ID,保存在从服务器中;offset 是从服务器当前的复制偏移量。主服务器在接收到从服务器发送过来的命令时,会通过 runid 和 offset 这两个参数来判断应该对从服务器执行哪种同步操作。
主服务器在接收到 PSYNC 命令时,会根据 PSYNC 命令的参数进行判断,向从服务器返回以下 3 种回复中的一种。
- 如果主服务器向从服务器返回+FULLRESYNC ,则表示主服务器将对从服务器执行全量同步操作,其中返回的 runid 是主服务器的运行 ID,从服务器会保存这个运行 ID,以便下次发送 PSYNC 命令时使用;而返回的 offset 是主服务器当前的复制偏移量,从服务器会将这台主服务器的复制偏移量作为自己的初始化偏移量。
- 如果主服务器向从服务器返回+CONTINUE,则表示主服务器将对从服务器执行部分同步操作,从服务器只需等待主服务器将自己缺少的那部分数据发送过来进行部分同步即可。
- 如果主服务器向从服务器返回-ERR,则表示主服务器的版本过低,低于 Redis 2.8版本,它识别不了 PSYNC 命令,此时从服务器会向主服务器发送 SYNC 命令,并与主服务器执行完同步操作。
PSYNC 命令执行全量同步或部分同步时的过程如图 12.7 所示。

图 12.7 将全量同步和部分同步合并在一起,执行的过程不是很具体。下面我们把全量
同步和部分同步的过程拆分开来,具体说明这个过程的原理。
对于一个存储了很多数据的 master 节点,如果有一个 slave 节点来做复制,那么我们会把 master 节点之前的数据同步到 slave 节点,在同步期间,我们先将最近写的数据保存到复制缓冲区中,之后再同步过来,这样就能实现数据完全同步。Redis 为我们提供了全量复制的功能来完成这个过程。它首先将本身的 RDB 文件,也就是当前状态同步给 slave,在此期间,它写入的命令会单独记录下来保存在复制缓冲区中;当这个 RDB 文件加载完成之后,它会通过复制偏移量的对比,将在此期间产生的写命令同步给 slave,完成同步操作。
全量同步的原理如图 12.8 所示。
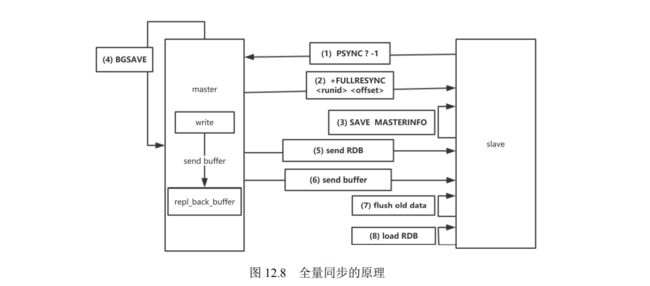
过程说明如下。
(1)slave 发送同步命令 PSYNC ? -1 给 master。PSYNC 命令有两个参数:runid(master的运行 ID)和 offset(复制偏移量)。因为是第一次复制,不知道 master 的运行 ID 是多少,也不知道复制偏移量是多少,所以使用?来代替 runid,使用-1 来代替 offset。
(2)master 接收到 slave 发送过来的同步命令之后,判断 slave 要做全量复制,会把自己的 runid 和 offset 发送给 slave。
(3)slave 接收到 master 返回的 runid 和 offset 之后,会及时保存。
(4)之后 master 会执行 BGSAVE 命令生成 RDB 文件,在此期间,会将新的写命令保存到复制缓冲区(repl_back_buffer)中,复制缓冲区中记录了最新写入的命令。
(5)在 master 生成 RDB 文件之后,会将 RDB 文件发送给 slave。
(6)master 同时将复制缓冲区(repl_back_buffer)中的最新数据发送给 slave。
(7)slave 在接收 RDB 文件和复制缓冲区中的数据之前,会清空自身原有的数据。
(8)slave开始加载RDB文件和复制缓冲区中的数据,这样就能保持slave节点和master节点的数据一致性,最终实现全量同步。在执行全量同步的过程中,会存在很多时间开销,如下:
● 执行 BGSAVE 命令的耗时。
● RDB 文件网络传输时间。
● slave 节点清空自身数据的时间。
● slave 节点加载 RDB 文件的时间。
● 可能的 AOF 文件重写的时间。
全量同步除了存在大量的时间开销问题,还可能存在数据丢失问题。假如master和slave之间的网络发生抖动,在一段时间内,就会存在 master 数据丢失问题。对于 slave 节点来说,这段时间 master 节点丢失数据,它是不知道的。而为了实现同步功能,最简单的办法就是再做一次全量同步,把最新的数据同步过来。这是 Redis 2.8 版本以前的做法。
在 Redis 2.8 版本以后,Redis 提供了部分同步的功能,这样就避免了时间开销,在发生网络抖动的情况下,会将损失降到最低。
部分同步的原理如图 12.9 所示。
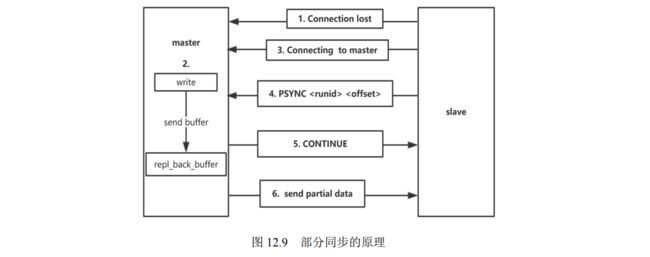
过程说明如下。
(1)如果 master 和 slave 之间的网络发生了抖动,则相当于连接断开了。
(2)master 在写命令的时候,会将最新的命令写入复制缓冲区中。
(3)当网络抖动结束之后,slave 会继续连接 master。
(4)之后 slave 会发送命令 PYSNC 到 master。
(5)master 根据 slave 传递过来的复制偏移量进行判断。如果传递过来的复制偏移量在 buffer(buffer 的大小默认为 1MB)之内,则会返回 CONTINUE,它会将从 offset 开始到这个队列结尾的数据进行同步。如果这个 offset 不在 buffer 之内,则说明 slave 已经错过了很多数据,就需要进行全量同步。
(6)master 把最近的数据逐步同步到 slave 中,最终实现部分同步。
12.1.4 复制功能的实现步骤
复制功能的实现步骤如下。
(1) 通过 SLAVEOF 命令设置主服务器的 IP 地址和端口号。
客户端向从服务器发送以下命令:
127.0.0.1:6380>SLAVEOF 127.0.0.1 6379
OK
从服务器将客户端发送过来的主服务器 IP 地址 127.0.0.1 和端口号 6379 保存到服务器状态的 masterhost 和 masterport 属性中
SLAVEOF 命令是一个异步命令,在将主服务器的 IP 地址和端口号保存到 masterhost和 masterport 属性中后,从服务器会返回 OK,表示复制命令已经被接收,复制工作也正式开始。
(2)主从服务器之间建立套接字连接。
在执行 SLAVEOF 命令之后,从服务器会根据主服务器的 IP 地址和端口号与主服务器建立套接字连接。
如果主服务器创建的套接字与从服务器连接成功,那么从服务器将会为这个套接字关联一个专用于处理复制工作的文件事件处理器。这个文件事件处理器负责执行复制工作,比如,接收 RDB 文件。主服务器在接收到从服务器创建的套接字之后,会为这个套接字创建客户端状态,将从服务器视为一个客户端来处理,此时从服务器具有两重身份,既是服务器,又是客户端。从服务器可以向主服务器发送命令请求,主服务器在接收到命令请求后,会给从服务器发送命令回复。
(3)从服务器向主服务器发送 PING 命令。当从服务器作为主服务器的客户端之后,会向主服务器发送 PING 命令,用于检查套接字的读写状态是否正常,以及检查主服务器是否可以正常处理命令请求。主服务器在接收到 PING 命令后,会有不同的返回结果,具体如下。
● 如果主服务器向从服务器返回一个命令回复,此时如果从服务器在规定的时间内不能读取出这条命令,就表示主从服务器之间的网络连接状态不好,不能继续完成复制工作。出现这种情况,从服务器会断开与主服务器的连接,就需要重新建立套接字连接。
● 如果主服务器向从服务器返回一个错误,就表示主服务器暂时不能处理从服务器发送过来的命令请求,不能继续完成复制工作。出现这种情况,从服务器会断开与主服务器的连接,就需要重新建立套接字连接。
● 如果主服务器向从服务器返回“PONG”,就表示主从服务器之间的网络连接状态良好,同时主服务器可以正常处理从服务器发送过来的命令请求,并能完成复制工作。从服务器向主服务器发送 PING 命令的过程如图 12.10 所示。
(4)根据从服务器的配置决定是否进行身份验证。在从服务器接收到主服务器返回的“PONG”之后,就会根据从服务器的配置信息来决定是否进行身份验证。
● 如果从服务器没有配置 masterauth 属性,就不需要进行身份验证了,可以继续完成后面的复制工作。
● 如果从服务器配置了 masterauth 属性,就需要进行身份验证。此时从服务器会向主服务器发送一条 AUTH 命令,该命令的参数为从服务器 masterauth 属性的值。只有当从服务器发送的密码和主服务器 requirepass 属性所设置的密码相同时,才表示身份验证通过,就可以继续完成复制工作了。而如果出现其他情况,比如,主从服务器密码不一致等,则会导致从服务器停止复制工作,并从创建套接字开始重新执行复制操作,直到身份验证通过,或者从服务器放弃完成复制工作为止。
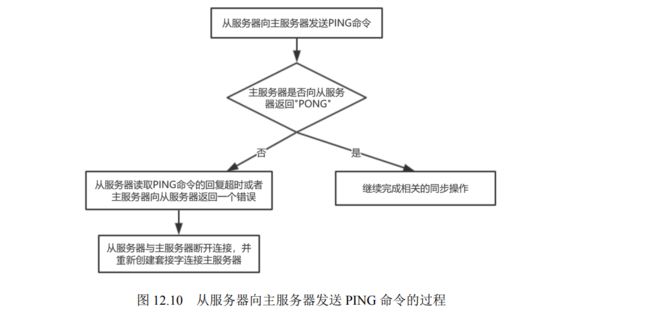
(5)从服务器向主服务器发送端口信息。从服务器通过执行命令 REPLCONF listening-port ,向主服务器发送从服务器的监听端口信息。比如,从服务器的监听端口为 6380,那么执行的命令就是 REPLCONF listening-port 6380。
在主服务器接收到从服务器发送过来的这条命令之后,会将这个端口号记录在从服务器所对应的客户端状态的 slave_listening_port 属性中。在主服务器中执行 INFO replication命令之后,就会打印出 slave_listening_port 属性所监听的端口号。命令操作如下:
127.0.0.1:6379> INFO replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=86688,lag=0
master_replid:3a761d54b8fb5dbdc1407658f57df3c03f7e7d85
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:86688
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:86688
(6)从服务器向主服务器发送 PSYNC 命令完成同步功能。从服务器向主服务器发送 PSYNC 命令,主服务器在接收到 PSYNC 命令之后,判断是执行全量同步还是执行部分同步,之后完成相关的同步功能,使得主从服务器的数据库状态保持一致。在完成同步功能之后,主从服务器互相成为对方的客户端,它们可以互相向对方发送命令请求,或者互相向对方返回命令回复。
(7)主从服务器之间进行命令传播,进而维持数据库状态的一致性。
在完成同步功能之后,主从服务器就会进入命令传播阶段,主服务器将自己执行的写命令及时发送给从服务器,而从服务器接收来自主服务器的写命令并执行,这样就能保证主从服务器的数据库状态一致了。
12.1.5 Redis 读写分离
Redis 读写分离用于实现将读流量分摊到每个从节点。
读写分离是一种很好的策略,它将 master 上的数据同步给 slave,让 slave 分摊去执行相关的业务,比如,一个业务只需要读数据,那么我们直接去读从节点就可以了。通常的做法是让 master 执行写操作,让 slave 执行读操作,这样一方面可以减轻 master 的压力,提高性能;另一方面扩展了 Redis 读的能力,适用于读多写少的业务场景。
读写分离也会有一定的问题,具体有如下几点。
● 复制数据延迟。在大多数情况下,我们在同步 master 上的数据时,会做一个异步执行的同步数据操作,将数据复制给 slave,这期间就会有一定的时间差。而且当 slave 发生阻塞的时候,它会延迟接收到主服务器发送过来的写命令,就有可能发生读写不一致的情况。如果担心发生读写不一致的情况,则可以对它的复制偏移量进行监控。
● 读到一些过期的数据。Redis 使用两种策略来判断某个 key 是否过期,进而删除这个 key。一种是使用懒惰性策略,只有当它去操作某个 key 时,它才会判断这个 key 是否已经过期,如果发现过期,就会将这个 key 删除,再返回给客户端空的操作。而另一种策略是它会有一个定时任务,每次去采样一些 key,来判断它们是否过期,这时就会造成一种情况:当过期的 key 非常多,而且采样速度慢于过期 key 的产生速度时,就会造成许多过期的 key 没有被及时删除。另外,在 Redis 中,master 和 slave 达成了一个约定,就是 salve 节点不能处理数据,也就是不能删除数据,这就会造成 slave 节点在读取 master 节点时可能读到脏数据。
● 在读写分离的过程中,发生从节点故障。在从节点发生故障的时候,就需要进行数据迁移,这时我们就需要考虑一些成本问题。Redis 读写分离示意图如图 12.11 所示。
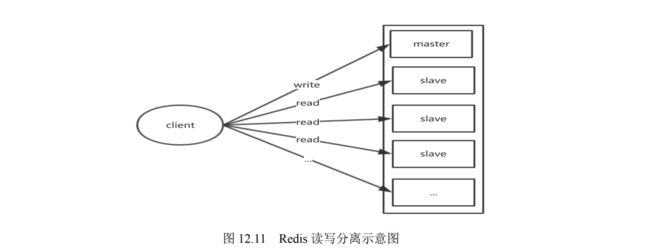
12.1.6 Redis 心跳机制
在主从服务器之间进行命令传播的时候,从服务器默认会以每秒一次的频率发送命令REPLCONF ACK
从服务器发送 REPLCONF ACK 命令主要有以下几个作用。
● 检测主从服务器之间的网络连接情况。从服务器通过向主服务器发送 REPLCONF ACK 命令来检测主从服务器之间的网络连接情况。如果主服务器超过 1 秒没有接收到从服务器发送过来的命令,就会认为网络连接出现了问题。主服务器执行 INFO replication 命令之后,返回的信息如下:
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=103611,lag=1 # 表示刚刚发送过
REPLCONF ACK 命令
master_replid:3a761d54b8fb5dbdc1407658f57df3c03f7efd85
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:103611
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:103611
在正常情况下,lag 的值应该在 0 秒和 1 秒之间跳动。如果 lag 的值大于 1 秒,则表示主从服务器之间的网络连接出现了问题。
● 设置 min-slaves 属性配置。为了防止主服务器在不安全的情况下执行写命令,可以通过配置 Redis 的 min-slaves属性来进行设置。具体属性是 min-slaves-to-write 和 min-slaves-max-log。
在 Redis 配置文件中,这两个属性默认是不打开的,如下:
# min-slaves-to-write 3
# min-slaves-max-lag 10
如果打开这两个属性(去掉前面的注释),则表示在从服务器的数量少于 3 台或者 3台从服务器的延迟(log)时间超过 10 秒时,主服务器会拒绝执行写命令。
● 检测在命令传播过程中是否有命令丢失。在主从服务器进行命令传播的过程中,可能会因为网络的故障而导致传输的写命令在途中丢失,这样就会导致主从服务器的复制偏移量不一致。当从服务器向主服务器发送REPLCONF ACK 命令时,如果主服务器发现从服务器的复制偏移量与自己的复制偏移量不一致,就会根据从服务器的复制偏移量,在复制缓冲区中找到发送过程中所丢失的写命令,然后补发给从服务器,实现同步功能。
在进行主从复制的过程中,会有以下几个问题。
(1)有一个一主二从的服务器集群,在某一时刻,3 个客户端同时执行一条写命令,
这 3 个客户端会产生什么效果?
在 3 个客户端同时执行一条写命令之后,只有主服务器可以执行成功,两台从服务器将会报错,并提示不能写,这也可以体现出主从复制的读写分离。
(2)有一个一主二从的服务器集群,当 master 宕机之后,另外两个 slave 会原地待命还是夺权篡位做 master?
事实证明,如果 master 宕机,另外两个 slave 会原地待命,它们并不会夺权篡位。它们与 master 的连接状态将会变为 master-link_status: down。
(3)如果 master 复活了,它还是 master 吗?还是会因为它宕机了一次,主从复制会被打乱?
如果 master 复活了,那么它依然是 master,不会因为它宕机了一次而打乱主从复制结构。
(4)如果某个 slave 宕机了,那么在它重启复活之后,身份还是 slave 吗?它能否恢复回来?
如果一个 slave 宕机了,那么在它重启复活之后,身份不再是 slave,而是一个新的master,它不能恢复回来。如果想要恢复回来,则需要 slave 继续执行 SLAVEOF 命令,完成连接,进而完成数据恢复功能。从机与主机断开连接之后,需要重新建立连接。为了避免重新连接,可以写入配置文件。
12.2 Redis 集群的高可用哨兵模式
在学习 Redis 高可用哨兵(Sentinel)模式之前,我们先来回顾一下主从复制高可用。主从复制主要有两个作用:一是可以为主服务器提供一个备份,当主服务器发生故障之后,在这个备份中会有一份完整的数据;二是可以对主服务器实现分流,比如,实现读写分离的功能,将大部分的写操作放到主节点上,将大部分的读操作放到从节点上,以此来减轻 主节点的压力。但是这种模式存在一个问题,如果主节点出现了问题,那么故障转移基本 上就是需要手工来完成的,即使不需要手工来完成,也需要单独写一些脚本或者一些功能 来实现这个过程。实际上,主从复制存在两个问题。一个问题就是主从复制写能力和存储 能力受限,不管是采用读写分离,还是采用其他方式,写操作主要在一个节点上进行,而 且存储也只能在一个节点上进行,因为其他节点都是它的副本。这个问题涉及相关的分布 式存储问题,在这里不进行介绍。而另一个问题就是手动故障转移,当 master 出现故障之 后,需要手动处理故障,比如,选出一个新的 slave 作为新的 master 节点。为了解决主从 复制故障转移的问题,引入了 Redis 集群的高可用哨兵模式。
12.2.1 什么是高可用哨兵模式
哨兵模式是由一个或多个哨兵组成的哨兵系统,主要用于监控任意多台主服务器是否 发生故障,以及监控这些主服务器的从服务器。当主服务器发生故障时,它会通过投票选 举的方式从主服务器下属的从服务器中选举出一台新的主服务器,让这台新的主服务器代 替之前的主服务器继续处理命令请求及完成相关工作,从而实现了故障的自动转移,而无 须手工操作,达到了高可用、热部署的目的。
典型的哨兵模式架构图如图 12.12 所示。
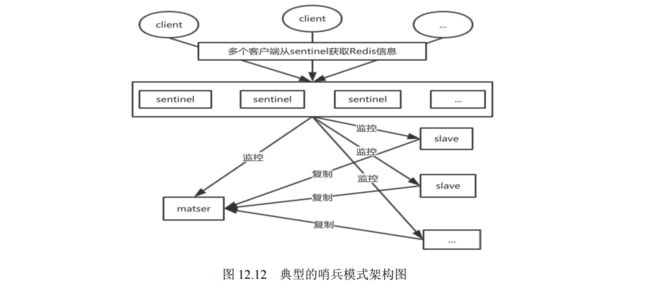
哨兵模式不会存储数据,它的作用是对 Redis 主从复制的节点进行监控,对其故障进行判断,进行故障转移的处理,以及通知相关的客户端。Redis Sentinel 可以同时监控多套主从复制模式,这样做的目的是节省资源。
哨兵模式监控多套主从复制架构图如图 12.13 所示。

在这里总结一下哨兵模式的具体作用。
● 监控:哨兵模式用于管理多台 Redis 服务器,哨兵会不断地检查它所监控的主从服务器,判断其是否发生故障。
● 通知:当被监控的某台 Redis 服务器出现故障时,哨兵会向管理员或者相关的应用程序发送通知。
● 自动故障转移:当一台主服务器出现故障,无法正常工作时,哨兵模式会开始一次自动故障转移操作。它会将出现故障的主服务器下属的某台从服务器升级为新的主服务器,并让出现故障的主服务器下属的其他从服务器改为复制新的主服务器;当客户端试图连接出现故障的主服务器时,哨兵会向客户端返回新的主服务器地址,使得集群可以使用新的主服务器代替出现故障的主服务器,这样就完成了故障转移操作
12.2.2 哨兵模式的配置
当前的 Redis 目录结构如图 12.14 所示。
1.配置开启主从节点 进入 Redis 的目录结构中,命令如下:
cd /home/redis/redis-4.0.9
(1)配置主节点。
执行命令 vim redis-6379.conf,进入编辑界面,编辑的内容如下:
port 6379 #master 的端口
daemonize yes #开启后台进程运行 Redis
pidfile /var/run/redis-6379.pid #指定 PID 进程文件
logfile "6379.log" #指定日志文件
dir "/home/redis/data" #指定工作空间
之后保存退出即可。
(2)配置从节点。
①slave1 配置如下。
执行命令 vim redis-6380.conf,进入编辑界面,编辑的内容如下:
port 6380
daemonize yes
pidfile /var/run/redis-6380.pid
logfile "6380.log"
dir "/home/redis/data"
slaveof 127.0.0.1 6379
之后保存退出即可。 ②salve2 配置如下。 执行命令 vim redis-6381.conf,进入编辑界面,编辑的内容如下:
port 6381
daemonize yes
pidfile /var/run/redis-6381.pid
logfile "6381.log"
dir "/home/redis/data"
slaveof 127.0.0.1 6379
之后保存退出即可。
使用命令编辑并查看主从服务器的配置信息,如下:
[root@localhost redis-4.0.9]# vim redis-6379.conf
[root@localhost redis-4.0.9]# cat redis-6379.conf
port 6379
daemonize yes
pidfile /var/run/redis-6379.pid
logfile "6379.log"
dir "/home/redis/data"
[root@localhost redis-4.0.9]# vim redis-6380.conf
[root@localhost redis-4.0.9]# cat redis-6380.conf
port 6380
daemonize yes
pidfile /var/run/redis-6380.pid
logfile "6380.log"
dir "/home/redis/data"
slaveof 127.0.0.1 6379
[root@localhost redis-4.0.9]# vim redis-6381.conf
[root@localhost redis-4.0.9]# cat redis-6381.conf
port 6381
daemonize yes
pidfile /var/run/redis-6381.pid
logfile "6381.log"
dir "/home/redis/data"
slaveof 127.0.0.1 6379
(3)开始启动主从服务器,命令如下。
①启动主节点。
redis-server /home/redis/redis-4.0.9/redis-6379.conf
②启动从节点。
redis-server /home/redis/redis-4.0.9/redis-6380.conf
redis-server /home/redis/redis-4.0.9/redis-6381.conf
③查看进程。
ps -ef | grep redis-server | grep 63
④查看主节点的主从复制信息。
redis-cli -p 6379 info replication
具体操作如下:
[root@localhost redis-4.0.9]# cd src/
[root@localhost src]# redis-server /home/redis/redis-4.0.9/redis-6379.conf
[root@localhost src]# redis-cli -p 6379 ping
PONG
[root@localhost src]# redis-server /home/redis/redis-4.0.9/redis-6380.conf
[root@localhost src]# redis-server /home/redis/redis-4.0.9/redis-6381.conf
[root@localhost src]# ps -ef | grep redis-server | grep 63
root 15561 1 0 12:43 ? 00:00:00 redis-server *:6379
root 15572 1 0 12:44 ? 00:00:00 redis-server *:6380
root 15576 1 0 12:44 ? 00:00:00 redis-server *:6381
[root@localhost src]# redis-cli -p 6379 info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=127,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=127,lag=0
master_repl_offset:127
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:126
- 配置开启 Sentinel 监控主节点
进入 Redis 的目录结构中,命令如下:
cd /home/redis/redis-4.0.9
复制一份 sentinel.conf 文件,命令如下:
cp sentinel.conf sentinel-26379.conf
去掉 sentinel-26379.conf 文件中的空格及注释,命令如下:
cat sentinel-26379.conf | grep -v "#" | grep -v "^$"
干净的配置如下所示:
[root@localhost redis-4.0.9]# cat sentinel-26379.conf | grep -v "#" | grep -v "^$"
port 26379
dir /tmp
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
编辑 sentinel-26379.conf 文件,命令如下:
vim sentinel-26379.conf
编辑的内容如下:
port 26379
daemonize yes
dir /home/redis/data
logfile "26379.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
之后保存退出即可。
到这里就已经完成相关的哨兵配置了,接下来启动哨兵模式开始监控主从服务器。
启动命令:
redis-sentinel /home/redis/redis-4.0.9/sentinel-26379.conf
查看进程命令:
ps -ef | grep redis-sentinel
连接命令:
redis-cli -p 26379
操作如下:
[root@localhost redis-4.0.9]# redis-sentinel /home/redis/redis-4.0.9/sentinel26379.conf
[root@localhost redis-4.0.9]# ps -ef | grep redis-sentinel
root 15737 1 0 13:13 ? 00:00:00 redis-sentinel *:26379 [sentinel]
root 15741 15537 0 13:14 pts/9 00:00:00 grep redis-sentinel
[root@localhost redis-4.0.9]# redis-cli -p 26379
127.0.0.1:26379> PING
PONG
使用命令 INFO sentinel 查看 Sentinel 信息,如下所示:
127.0.0.1:26379> INFO sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=1
启动 Sentinel 之后,它就会对主从复制中的节点进行监控。使用命令来查看一下 Sentinel
配置文件的变化,命令如下:
vim sentinel-26379.conf
配置文件的信息如下:
[root@localhost redis-4.0.9]# vim sentinel-26379.conf
port 26379
daemonize yes
dir "/home/redis/data"
logfile "26379.log"
sentinel myid f2672c2363f6384804e31fc6c26fb799f0e43d43
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
# Generated by CONFIG REWRITE
sentinel known-slave mymaster 127.0.0.1 6381
sentinel known-slave mymaster 127.0.0.1 6380
sentinel current-epoch 0
可以看到 sentinel-26379.conf 文件的内容发生了变化,除了之前配置的一些信息,额外多出了一些配置信息。
到这里我们才完成第一个 Sentinel 节点的配置,另外两个 Sentinel 节点的配置如下。
第二个 Sentinel 节点的配置(sentinel-26380.conf):
port 26380
daemonize yes
dir /home/redis/data
logfile "26380.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
第三个 Sentinel 节点的配置(sentinel-26381.conf):
port 26381
daemonize yes
dir /home/redis/data
logfile "26381.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
使用命令编辑并查看配置信息,如下所示:
[root@localhost redis-4.0.9]# vim sentinel-26380.conf
[root@localhost redis-4.0.9]# vim sentinel-26381.conf
[root@localhost redis-4.0.9]# cat sentinel-26380.conf
port 26380
daemonize yes
dir /home/redis/data
logfile "26380.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
[root@localhost redis-4.0.9]# cat sentinel-26381.conf
port 26381
daemonize yes
dir /home/redis/data
logfile "26381.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
分别启动这两个 Sentinel 节点,命令如下:
redis-sentinel /home/redis/redis-4.0.9/sentinel-26380.conf
redis-sentinel /home/redis/redis-4.0.9/sentinel-26381.conf
查看进程,如下所示:
[root@localhost redis-4.0.9]# redis-sentinel /home/redis/redis-4.0.9/sentinel26380.conf
[root@localhost redis-4.0.9]# redis-sentinel /home/redis/redis-4.0.9/sentinel26381.conf
[root@localhost redis-4.0.9]# ps -ef | grep redis-sentinel
root 15710 1 0 13:11 ? 00:00:00 redis-sentinel *:26380 [sentinel]
root 15714 1 0 13:11 ? 00:00:00 redis-sentinel *:26381 [sentinel]
root 15737 1 0 13:13 ? 00:00:00 redis-sentinel *:26379 [sentinel]
root 15741 15537 0 13:14 pts/9 00:00:00 grep redis-sentinel
至此,哨兵模式的配置就完成了。
12.2.3 Sentinel 的配置选项
1.Sentinel 相关配置选项说明
● sentinel monitor mymaster 127.0.0.1 6379 2:Sentinel 监控一台名为 mymaster 的主服务器,这台主服务器的 IP 地址为 127.0.0.1,端口号为 6379。当这台主服务器发生故障时,至少需要两个 Sentinel 同意,才能认定主服务器失效。如果主服务器失效,就需要进行故障转移。在只有少数 sentinel 进程正常运作的情况下,Sentinel 是不能执行自动故障转移的。
● sentinel down-after-milliseconds mymaster 30000:该选项指定了 Sentinel 认为服务器已经离线所需要的毫秒数,默认为 30s。服务器如果在指定的毫秒内没有返回 Sentinel发送的 PING 命令的回复,或者回复了一条错误信息,那么 Sentinel 会认为这台服务器已经离线,将其标记为主观下线(Subjectively Down)。一个 Sentinel 将服务器标记为主观下线,并不一定代表这台服务器已经离线,只有当多个 Sentinel 都将这台服务器标记为主观下线之后,这台服务器就会被标记为客观下线(Objectively Down)。如果服务器被标记为客观下线,就会触发自动故障转移机制。
● sentinel parallel-syncs mymaster 1:该选项指定了在执行故障转移时,最多可以有多少台从服务器同时对新的主服务器进行复制。默认为 1。这个值越小,在进行故障转移时所需要的时间就越长。将该选项的值设置为 1,可以保证每次只有一台从服务器处于不能处理命令请求的状态。
● sentinel failover-timeout mymaster 180000:该选项指定了在规定的时间(ms)内,如果没有完成 failover 操作,则认为该 failover 操作失败。默认为 180s。关于 Sentinel 的更多详细配置,在此不再一一介绍。
在启动 Sentinel 之后,执行命令 redis-cli -p 26379,进入之后,你会发现 Sentinel 并不会执行相关的写命令,原因是 Sentinel 并不使用数据库,它不能存储任何数据,它使用sentinel.c/sentinelcmds 作为服务器的命令表。sentinelcmds 函数的源码如下:
struct redisCommand sentinelcmds[] = {
{"ping",pingCommand,1,"",0,NULL,0,0,0,0,0},
{"sentinel",sentinelCommand,-2,"",0,NULL,0,0,0,0,0},
{"subscribe",subscribeCommand,-2,"",0,NULL,0,0,0,0,0},
{"unsubscribe",unsubscribeCommand,-1,"",0,NULL,0,0,0,0,0},
{"psubscribe",psubscribeCommand,-2,"",0,NULL,0,0,0,0,0},
{"punsubscribe",punsubscribeCommand,-1,"",0,NULL,0,0,0,0,0},
{"publish",sentinelPublishCommand,3,"",0,NULL,0,0,0,0,0},
{"info",sentinelInfoCommand,-1,"",0,NULL,0,0,0,0,0},
{"role",sentinelRoleCommand,1,"l",0,NULL,0,0,0,0,0},
{"client",clientCommand,-2,"rs",0,NULL,0,0,0,0,0},
{"shutdown",shutdownCommand,-1,"",0,NULL,0,0,0,0,0}
};
从 sentinelcmds 命令表中可以看出,在哨兵模式下,Redis 服务器不能执行像 SET、SADD、ZADD、DBSIZE 这样的写命令,因为服务器在命令表中没有载入这些写命令。
2.在哨兵模式下不能使用的命令
在 Redis 开启哨兵模式之后,会有部分命令无法使用,具体说明如下。
● 与操作数据库和键值对相关的命令不能使用,如 SET、SELECT、DEL、FLUSHDB 等。
● 与事务相关的命令不能使用,如 WATCH、MULTI、UNWATCH 等。
● 与操作脚本相关的命令不能使用,如 EVEL。
● 与持久化( RDB 和 AOF )相关的命令不能使用,如 BGSAVE 、 SAVE 、BGREWRITEAOF 等。
从 sentinelcmds 命令表中可以看出,PING、SENTINEL、SUBSCRIBE、UNSUBSCRIBE、PSUBSCRIBE、PUNSUBSCRIBE、PUBLISH、INFO、ROLE、CLIENT、SHUTDOWN 这11 个命令就是客户端可以对 Sentinel 执行的全部命令。
3.哨兵模式常用的命令
这里列举哨兵模式常用的几个命令。
● SENTINEL masters:该命令用于查看哨兵监控的主服务器的相关信息及状态。
● SENTINEL slaves :该命令用于列出指定主服务器的所有从服务器的信息及状态。
● SENTINEL get-master-addr-by-name :该命令用于返回指定名字的主服务器的 IP 地址和端口信息。如果这台主服务器正在执行故障转移操作,或者针对这台主服务器的故障转移操作已经完成,那么这个命令将会返回新的主服务器的 IP地址和端口信息。
● SENTINEL reset :该命令用于重置所有名字和给定模式(pattern)相匹配的主服务器。pattern 参数是一种 Glob 风格的模式。一旦执行此命令,它将会清除主服务器目前的所有状态,包括正在执行中的故障转移,以及删除目前已经发现和关联的、主服务器的所有从服务器和 Sentinel。请谨慎执行。
● SENTINEL failover :该命令用于当主服务器出现故障时,在不询问其他 Sentinel意见的情况下,强制开始一次自动故障转移操作。它会给另外的 Sentinel发送一个最新的配置,这些 Sentinel 在接收到最新的配置之后会自动更新。
● INFO:该命令用于查看 Redis 的相关配置信息。
● INFO sentinel:该命令用于查看 Sentinel 的基本状态信息。
12.2.4 哨兵模式的实现原理
在完成哨兵模式的相关配置后,需要启动 Sentinel 来监控相关的主从服务器,这个过 程如下。
1.启动 Sentinel 并初始化
启动命令:
redis-sentinel sentinel.conf 配置文件所在路径
或者:
redis-server sentinel.conf 配置文件所在路径 –sentinel
在这里为:
redis-sentinel /home/redis/redis-4.0.9/sentinel-26379.conf
前面说过,Sentinel 并不使用数据库,它不能存储数据,在启动的时候,它也不会加载RDB 文件或 AOF 文件。在启动之后,它会进行初始化,服务器会初始化一个sentinel.c/sentinelState 结构,在这个结构中保存了服务器中所有和 Sentinel 功能有关的状态。
sentinelState 结构的源码定义如下:
struct sentinelState {
char myid[CONFIG_RUN_ID_SIZE+1]; /*Sentinel 的 ID*/
uint64_t current_epoch; /*当前纪元,用于实现故障转移*/
dict *masters; /*字典,它保存了所有被 Sentinel 监控的主服务器,字典中的键是被监控的主
服务器的名字,字典中的值是一个指向 sentinelRedisInstance 结构的指针*/
int tilt; /*是否进入了 TILT 模式*/
int running_scripts; /*现在正在执行的脚本数量*/
mstime_t tilt_start_time; /*进入 TILT 模式的时间*/
mstime_t previous_time; /*最后一次执行时间处理器的时间*/
list *scripts_queue; /*有一个FIFO(先进先出)队列,包含了所有需要执行的用户脚本*/
char *announce_ip; /*记录 Sentinel 的 IP 地址*/
int announce_port; /*记录 Sentinel 的端口信息*/
unsigned long simfailure_flags; /*故障模拟标记*/
} sentinel;
Sentinel 状态中的 masters 字典记录了所有被 Sentinel 监控的主服务器信息,其中,字典中的键是被监控的主服务器的名字,字典中的值是一个指向 sentinel.c/sentinelRedisInstance 结构的指针。
每个 sentinelRedisInstance 结构(实例结构)表示一个被 Sentinel 监控的 Redis 服务器实例,这个实例可以是主从服务器,也可以是另一个 Sentinel。sentinelRedisInstance 结构的name 属性记录了实例的名字,其中主服务器的名字由用户在配置文件中设置,而从服务器及 Sentinel 的名字由 Sentinel 自动设置;另一个 addr 属性是一个指向 sentinel.c/sentinelAddr
结构的指针,这个结构用于保存实例的 IP 地址和端口信息,源码如下:
typedef struct sentinelAddr {
char *ip;
int port;
} sentinelAddr;
关于 sentinelRe对 Sentinel 状态的初始化也就是对 masters 字典的初始化,而被加载的 sentinel.conf 配
置文件就用于 masters 字典的初始化。
在初始化 Sentinel 之后,就会建立与被监控主服务器的网络连接,Sentinel 将成为主服务器的客户端,这个客户端可以向主服务器发送命令,并从中获取相关的服务器信息。Sentinel 在监控主服务器后,它们之间会建立两个异步网络连接。
一个是命令连接,这个连接专用于向主服务器发送命令,并获取返回的信息,以此来与主服务器一直保持通信状态。
另一个是消息订阅连接,这个连接专用于订阅主服务器的_sentinel_:hello 频道消息。在目前 Redis 的消息订阅发布功能中,被发送的消息并不会被保存到 Redis 服务器中。在发送消息的过程中,如果订阅消息的客户端离线或者因为其他原因而接收不到消息,那么这条信息将会丢失。为了保证订阅的_sentinel_:hello 频道的消息在传输过程中不丢失,Sentinel专门建立了一个订阅该频道消息的网络连接。
2.获取主从服务器的信息
在 Sentinel 启动并完成初始化后,就开始获取主从服务器的信息。在默认情况下,Sentinel 会以每 10s 一次的频率,通过命令连接向被监控的主服务器发送 INFO 命令,并通过分析 INFO 命令的回复信息来获取主服务器的当前信息
Sentinel 通过获取 INFO 命令返回的信息,可以知道被监控主服务器的信息,包括 run_id(它记录了服务器的运行 ID)和 role(它记录了服务器的角色信息)及其他信息。有了主服务器的 run_id 和 role 信息,Sentinel 就可以对主服务器的实例进行更新。还可以知道主服务器从属的从服务器的信息,每台从服务器都有一个以“slave”字符串开头的行记录。每行的 ip 选项记录了从服务器的 IP 地址,port 选项记录了从服务器的端口号。Sentinel 获取到这些 IP 地址和端口号之后,无须用户提供从服务器的地址信息,就可以发现从服务器。通过主服务器获取从服务器的信息,获取到的从服务器信息将会用于更新主服务器实例结构的 slaves 字典,这个字典用于记录从服务器的信息:字典中的键是从服务器的名字,它由 Sentinel 自动设置,格式为 ip:port,比如,127.0.0.1:6380;字典中的值是从服务器对应的实例结构。
Sentinel 在通过 INFO 命令获取从服务器信息的时候,会检查从服务器对应的实例结构中是否存在 slaves 字典。如果从服务器实例中存在 slaves 字典,Sentinel 就会更新从服务器的实例结构;如果从服务器实例中不存在 slaves 字典,就说明这台从服务器是新加入进来的,Sentinel 会在 slaves 字典中为这台新的从服务器创建一个实例结构,同时还会与这台新的从服务器创建命令连接和消息订阅连接。
主从服务器的实例结构如图 12.15 所示。isInstance 结构的参数众多,在这里就不展示源码了,感兴趣的读者请自行研究。
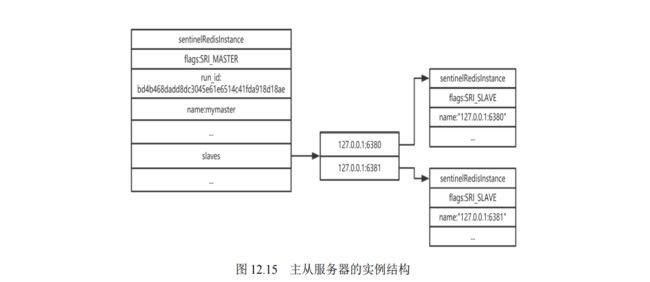
在主服务器的实例结构中,flags 属性值为 SRI_MASTER,name 属性值则是在配置文件 sentinel.conf 中设置的。
在从服务器的实例结构中,flags 属性值为 SRI_SLAVE,name 属性值则是由 Sentinel根据 ip 和 port 选项设置的。
在 Sentinel 与新加入的从服务器之间建立命令连接之后,它也会以每 10s 一次的频率向从服务器发送 INFO 命令,并从其返回的信息中获取从服务器的运行 ID(run_id)、角色(role)、优先级(slave_priority)、复制偏移量(slave_repl_offset),以及获取主服务器的 IP 地址(master_host)、端口号(master_port)、连接状态(master_link_status)等信息。根据获取到的这些信息,Sentinel 会对从服务器的实例结构进行更新。
3.向主从服务器发送信息
Sentinel 也会向主从服务器发送信息,它以每 2s 一次的频率,通过命令连接向所有被监控的主从服务器发送以下命令:
PUBLISH _sentinel_:hello ",,,,,,
,"
该命令向服务器的_sentinel_:hello 频道发送了一条消息,该条消息含有多个参数,内容如下。
● s_ip:Sentinel 的 IP 地址。
● s_port:Sentinel 的端口号。
● s_runid:Sentinel 的运行 ID。
● s_epoch:Sentinel 当前的配置纪元(一个配置纪元就是一台新主服务器配置的版本号)。
● m_name:主服务器的名字。
● m_ip:主服务器的 IP 地址。
● m_port:主服务器的端口号。
● m_epoch:主服务器当前的配置纪元。
其中,以 s_开头的是 Sentinel 本身的信息,以 m_开头的是 Sentinel 所监控的主服务器的信息。
一个 Sentinel 可以与其他 Sentinel 进行网络连接,各个 Sentinel 之间可以互相检查对方的可用性,并进行信息交换。同时,每个 Sentinel 都订阅了被它监控的所有主从服务器的_sentinel_:hello 频道,用于判断查找新的 Sentinel。当一个 Sentinel 发现一个新的 Sentinel时,它会将这个新的 Sentinel 添加到一个列表中,而这个列表中保存了 Sentinel 已知的监控同一台主服务器的所有其他 Sentinel 信息。Sentinel 所发送的信息中包含了主服务器的完整信息。如果一个 Sentinel 包含的主服务器的信息比另一个 Sentinel 发送的配置要旧,那么这个 Sentinel 会立即升级到新配置上。
如果要将一个新的 Sentinel 添加到监控主服务器的列表中,那么,在此之前,Sentinel会先检查这个列表中是否已经存在和将要添加进来的 Sentinel 相同的运行 ID、IP 地址、端口号等信息。如果列表中已经存在和将要添加进来的 Sentinel 相同的信息,那么 Sentinel会先移除列表中已有的那些拥有相同运行 ID 或 IP 地址、端口号的 Sentinel,再添加新的Sentinel。
4.接收来自主从服务器的频道消息
在 Sentinel 与主从服务器之间建立消息订阅连接后,Sentinel 就会通过消息订阅连接向服务器发送 SUBSCRIBE sentinel:hello 命令。Sentinel 会一直订阅服务器的_sentinel_:hello 消息频道,直到它与服务器断开连接为止。当 Sentinel 和服务器之间建立连接之后,它就会通过命令连接向服务器的_sentinel_:hello 频道发送消息,同时通过消息订阅连接来读取服务器的_sentinel_:hello 频道消息。
当一个 Sentinel 读取到_sentinel_:hello 频道中的信息时,就会从读取的信息中获取
Sentinel 的 IP 地址、端口号、运行 ID 等,用于做以下判断:
● 如果信息记录的 Sentinel 的运行 ID 和接收信息的 Sentinel 的运行 ID 相同,就说明这条信息是由它自己发送的,将移除这条信息,不做任何处理。
● 如果信息记录的 Sentinel 的运行 ID 和接收信息的 Sentinel 的运行 ID 不相同,就说明这条信息是由其他 Sentinel 发送的,接收信息的 Sentinel 将会根据信息中的各个参数,对相应的主服务器的实例结构进行更新,同时更新 sentinels 字典。
Sentinel 为主服务器创建的实例结构中的 sentinels 字典中保存了 Sentinel 本身的信息和它所监控的主服务器的其他 Sentinel 信息。sentinels 字典中的键是其中一个 Sentinel 的名字,这个名字由 ip:port 组成;而 sentinels 字典中的值则是键所对应 Sentinel 的实例结构。
当 Sentinel 通过消息频道发现一个新的 Sentinel 时,它不仅会为新的 Sentinel 在 sentinels字典中创建相应的实例结构,还会创建连向新的 Sentinel 的命令连接,最终多个 Sentinel互相连接,共同监控相应的主从服务器。
Sentinel 向服务器发送消息与接收服务器频道消息的过程如图 12.16 所示。

5.监控主从服务器下线状态
在默认情况下,Sentinel 会以每秒一次的频率向它所监控的主从服务器及其他 Sentinel发送一条 PING 命令,并通过接收返回的 PING 命令回复来判断主从服务器及其他 Sentinel是否已经下线。
Sentinel 向主从服务器及其他 Sentinel 发送 PING 命令的过程如图 12.17 所示。
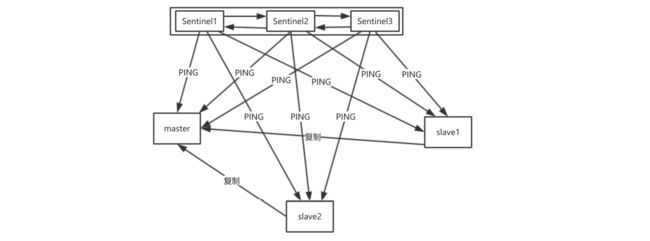
在图 12.17 中,多个 Sentinel 之间会互相发送 PING 命令,进行相互检测;同时,多个 Sentinel 会分别向其监控的主从服务器发送 PING 命令,在得到回复时,判断其是否已经下线。
PING 命令的有效回复有 3 种可能。
● 返回 PONG:表示网络连接正常。
● 返回 LOADING:发生错误。
● 返回 MASTERDOWN:发生错误。
除上述 3 种回复以外的回复,或者在规定的时间内没有任何回复,Sentinel 都会认为服务器返回的回复是无效回复。
6.完成故障转移
当一台主服务器被判断为客观下线时,监控这台下线主服务器的多个 Sentinel 会进行协商,采用一定的规则和方法选举出一个 Sentinel 领导,并由这个 Sentinel 领导对下线的主
服务器进行故障转移操作。
在讲解故障转移之前,先说一下 Sentinel 领导选举的规则和方法。
为什么要选举 Sentinel 领导呢?
因为只有一个 Sentinel 节点完成故障转移。当多个 Sentinel 同时监控一个或多个主从复制结构时,就需要选举出一个 Sentinel 领导来完成故障转移。
具体如下:
● 一个主从复制结构可以由多个 Sentinel 监控,而多个 Sentinel 都有被选举为 Sentinel领导的可能。在进行选举之后,无论选举成功与否,所有 Sentinel 的配置纪元的值都会自增一次。
● 在一个配置纪元里,所有 Sentinel 都有一次将某个 Sentinel 设置为局部领导的机会。当设置局部领导以后,就不能再更改它的配置纪元了。
● 每个 Sentinel 监控到主服务器客观下线后,都会要求其他 Sentinel 选举自己作为局部领导。
● 当一个 Sentinel(源 Sentinel)向另一个 Sentinel(目标 Sentinel)发送 SENTINELis-master-down-by-addr 命令,同时命令中的 runid 是源 Sentinel 的运行 ID 时,表示源 Sentinel 要求目标 Sentinel 将前者设置为后者的局部领导。
● 将 Sentinel 设置为局部领导的规则是:先到先得。谁先向目标 Sentinel 发送设置要求,谁就能成为目标 Sentinel 的局部领导,之后它将拒绝接受其他的所有设置要求。
● 目标 Sentinel 在接收到 SENTINEL is-master-down-by-addr 命令之后,将会向源Sentinel 返回一个命令回复,在回复的参数中,leader_runid 和 leader_epoch 参数分别记录了目标 Sentinel 的领导 Sentinel 的运行 ID 和配置纪元。
● 源 Sentinel 在接收到目标 Sentinel 返回的命令回复之后,会判断其中的 leader_runid和 leader_epoch 参数与自己的运行 ID 及配置纪元是否相同,如果相同,就表示目标Sentinel 将原 Sentinel 设置成了局部领导。
● 在多个 Sentinel 中,如果某个 Sentinel 被半数以上的 Sentinel 设置成了局部领导Sentinel,那么这个局部领导 Sentinel 将会成为多个 Sentinel 的领导。
● Sentinel 领导的选举需要半数以上的 Sentinel 的支持,并且每个 Sentinel 在配置纪元里只能设置一次局部领导,因此,在一个配置纪元里,只能出现一个 Sentinel 领导。
● 假如在指定的时间内,没有选举出一个 Sentinel 作为领导,那么各个 Sentinel 将会过一段时间再进行选举,直到选举出新的 Sentinel 领导为止。
Sentinel 领导选举成功之后,它将对已经下线的主服务器执行故障转移操作。具体步骤
如下:
(1)当 master 出现问题时,多个 Sentinel 发现并确认 master 有问题,多个 Sentinel 的确认保证了公平性。
(2)在 Sentinel 内部会选举出一个 Sentinel 作为领导,让它完成相关工作。
(3)作为领导的 Sentinel 会从这台已经下线的主服务器的所有从服务器中选出一个“合适”的 slave 节点作为新的 master。让这个 slave 节点执行 SLAVEOF no one 命令,让其成为 master 节点。
(4)此时 Sentinel 会通知其余的 slave 成为新的 master 的 slave,这些 slave 就会复制新的 master 数据,通过向其余的 slave 发送 SLAVEOF 命令来完成。
(5)之后 Sentinel 会通知相应的客户端新的 master 是谁,这样就能避免客户端再去连接旧的 master,从而导致读取数据失败的问题产生。
(6)在这个过程中,Sentinel 依然会监控旧的 master,对其进行“关注”。当旧的 master复活之后,就会让它成为新的 master 的 slave 节点,然后去复制新的 master 数据。
12.2.5 选择“合适”的 slave 节点作为 master 节点
1.选择 master 节点
那么,该如何选择一个“合适”的 slave 节点作为 master 节点呢?
要选择一个“合适”的 slave 节点,规则如下:
● 选择 slave-priority(slave 节点优先级)参数值最大的 slave 节点,如果存在则返回,不存在则继续选择。在默认情况下,在配置文件 redis.conf 中,slave-priority 参数的值为 100。我们可以根据实际情况来修改这个参数的值,以此来选定一个“合适”的 slave 节点作为新的 master。
● 如果 slave 节点的优先级不满足,就根据 slave 节点的复制偏移量来选定。一般选择复制偏移量最大的 slave 节点作为一个“合适”的 slave 节点,如果存在就返回,不存在则继续选择。如果 slave 节点的复制偏移量与 master 节点的复制偏移量比较接近,则说明它们之间的数据一致性更高。因此,选定复制偏移量最大的 slave 节点,这样 slave 与 master 之间的数据更接近,数据一致性也会很高。
● 如果 slave 节点和 master 节点的复制偏移量相同,就根据 slave 的 runid 来进行选定。一般选择 runid 最小的 slave 节点作为一个“合适”的 slave 节点,因为 runid 越小,说明它是最早的一个节点。
2.演示故障转移
假如有 3 个 Sentinel 同时监控一个 master 节点,而这个 master 节点有两个从节点 slave1(A)和 slave2(B)。在某一时刻,master 出现了故障,3 个 Sentinel 选举出了一个 Sentinel
领导来完成故障转移,经过一系列操作,选择了 slave1(A)作为新的 master 节点,之后完成了相关的故障转移工作,这个过程如图 12.18 所示。
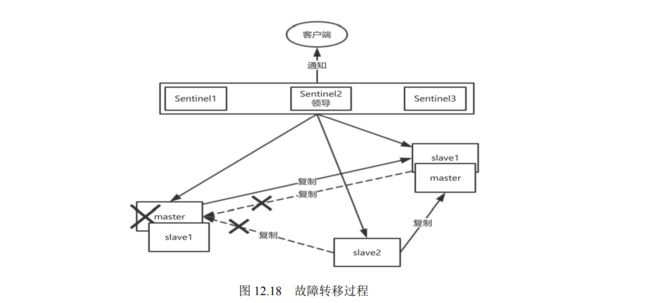
接下来,我们在 Linux 系统上演示 Sentinel 监控主从节点,当主节点出现故障之后进行故障转移的过程。
(1)进入 Redis 的目录结构,命令为 cd /home/redis/redis-4.0.9,执行以下命令启动主从节点服务(一主二从):
redis-server /home/redis/redis-4.0.9/redis-6379.conf
redis-server /home/redis/redis-4.0.9/redis-6380.conf
redis-server /home/redis/redis-4.0.9/redis-6381.conf
(2)启动 3 个 Sentinel 节点,来监控主从节点,命令如下:
redis-sentinel /home/redis/redis-4.0.9/sentinel-26379.conf
redis-sentinel /home/redis/redis-4.0.9/sentinel-26380.conf
redis-sentinel /home/redis/redis-4.0.9/sentinel-26381.conf
使用 ps -ef | grep redis 命令查看服务器启动的进程,操作如下:
[root@localhost ~]# cd /home/redis/redis-4.0.9
[root@localhost redis-4.0.9]# ps -ef|grep redis
root 28418 28350 0 01:01 pts/4 00:00:00 grep redis
[root@localhost src]# redis-server /home/redis/redis-4.0.9/redis-6379.conf
[root@localhost src]# redis-server /home/redis/redis-4.0.9/redis-6380.conf
[root@localhost src]# redis-server /home/redis/redis-4.0.9/redis-6381.conf
[root@localhost redis-4.0.9]# redis-sentinel /home/redis/redis-4.0.9/sentinel26379.conf
[root@localhost redis-4.0.9]# redis-sentinel /home/redis/redis-4.0.9/sentinel26380.conf
[root@localhost redis-4.0.9]# redis-sentinel /home/redis/redis-4.0.9/sentinel26381.conf
[root@localhost redis-4.0.9]# ps -ef|grep redis
root 28425 1 0 12:43 ? 00:00:27 redis-server *:6379
root 28429 1 0 12:44 ? 00:00:29 redis-server *:6380
root 28434 1 0 12:44 ? 00:00:31 redis-server *:6381
root 28438 1 0 13:11 ? 00:00:38 redis-sentinel *:26380 [sentinel]
root 28442 1 0 13:11 ? 00:00:38 redis-sentinel *:26381 [sentinel]
root 28447 1 0 13:13 ? 00:00:38 redis-sentinel *:26379 [sentinel]
root 28454 28350 0 17:00 pts/9 00:00:00 grep redis
(3)执行 redis-cli -p 26379 命令进入客户端,然后执行 INFO sentinel 命令,查看 Sentinel的信息。执行命令后,返回的信息如下所示:
127.0.0.1:26379> INFO sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3
可以看出,在当前 Sentinel 所监控的主从复制结构中,master 节点是 127.0.0.1:6379。
(4)现在我们模拟主节点宕机,来实现故障转移功能。执行 kill -9 28425 命令直接杀死 master 节点,过一段时间,再次执行 INFO sentinel 命令,然后查看 Sentinel 的信息。执行命令后,返回的信息如下所示:
127.0.0.1:26379> INFO sentinel # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 master0:name=mymaster,status=ok,address=127.0.0.1:6381,slaves=2,sentinels=3
从返回的信息中可以看出,新的 master 节点已经切换为 127.0.0.1:6381。 执行命令 cat /home/redis/data/26379.log 查看 Sentinel 的监控日志,日志信息如图 12.19 所示。
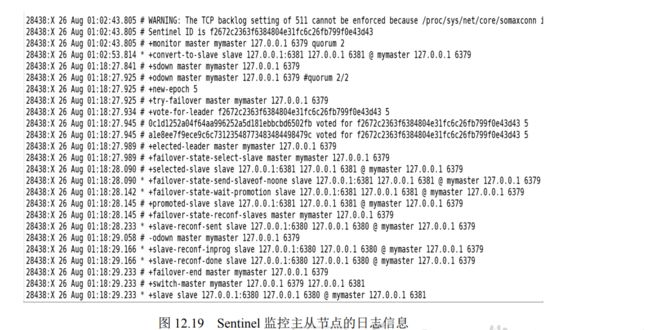
从日志信息中可以看出,master 节点由最初的 127.0.0.1:6379 转换为 127.0.0.1:6381, Sentinel 成功执行了故障转移操作。
12.2.6 Sentinel 的下线状态
在 Redis 的 Sentinel 中,有两种下线状态。
● 主观下线(SDOWN):指的是单个 Sentinel 对服务器的下线判断。在 sentinel.conf配置文件中,master-down-after-milliseconds 选项设置了服务器离线所需的毫秒数。如果一台服务器在该选项所指定的毫秒时间内,没有对发送 PING 命令的 Sentinel返回一个有效的回复(3 种有效回复中的一种),那么这个 Sentinel 就会认为这台服务器已经下线,就会将它标记为主观下线,同时将它的实例结构中的 flags 属性设置为 SRI_S_DOWN 标识。
master-down-after-milliseconds 选项的设置不仅会被 Sentinel 用来判断主服务器的主观下线状态,还会用于判断主服务器下属的从服务器,以及监控这台主服务器的其他 Sentinel的主观下线状态。
如果一个 master 被标记为主观下线,则正在监控这个 master 的所有 Sentinel 都会以每秒一次的频率来确认这个 master 是否真正进入主观下线状态。在这个过程中,master 又重新向 Sentinel 所发送的 PING 命令返回有效的回复,那么 master 的主观下线状态就会被及时删除。
总结为:主观下线就是每个 Sentinel 节点对 Redis 节点失败的“偏见”。
● 客观下线(ODOWN):指的是当一个 Sentinel 将一台服务器判断为主观下线之后,为了确认这台主服务器是否真的下线了,它会通过 SENTINELis-master-down-by-addr 命令与其他监控这台服务器的多个 Sentinel 进行交流,看它们是否也认为这台主服务器已经进入下线状态。当多个 Sentinel 同时认为这台主服务器已经下线时,Sentinel 就会将这台主服务器标记为客观下线,并对其执行故障转移操作。
判断主服务器为主观下线的过程如下。
● 一个 Sentinel(源 Sentinel)通过向监控这台主服务器的其他 Sentinel 发送 SENTINELis-master-down-by-addr 命令进行交流,询问是否同意主服务器已经下线。命令格式如下:
参数说明如下。
- :表示被 Sentinel 判断为主观下线的主服务器的 IP 地址与端口号。
:表示 Sentinel 当前的配置纪元,用于选举 Sentinel 领导。 - :runid 的值有可能是*,表示该命令仅仅用于检测主服务器的客观下线状也有可能是 Sentinel 的运行 ID,用于选举 Sentinel 领导。
● 当另一个 Sentinel(目标 Sentinel)接收到 SENTINEL is-master-down-by-addr 命令时,目标 Sentinel 会分析接收到的命令,并根据其中的 IP 地址和端口信息,去检查这台主服务器是否已经下线,然后返回一条包含 3 个参数的 Multi Bulk 回复给源
Sentinel。这 3 个参数具体如下。
- down_state:表示目标 Sentinel 对主服务器的检查结果。如果值为 1,则表示主服
务器已经下线;如果值为 0,则表示主服务器没有下线。 - leader_runid:其值可以是*,表示该命令仅仅用于判断主服务器是否为下线状态;其值也可以是目标 Sentinel 的局部领导 Sentinel 的运行 ID,用于进行 Sentinel 领导的选举。
- leader_epoch:表示目标 Sentinel 的局部领导 Sentinel 的配置纪元,用于选举Sentinel 领导。当 leader_runid 的值为时,leader_epoch 的值为 0,没有任何作用;只有当 leader_runid 的值不为时,这个参数才有用。
● 当目标 Sentinel 接收到其他 Sentinel 返回的 SENTINEL is-master-down-by-addr 命令回复时,它会统计其他 Sentinel 同意主服务器已经下线的数量。当这个数量达到配置文件所指定的客观下线所需的数量时,就会将这台主服务器标记为客观下线,同时修改主服务器的实例结构的 flags 属性为 SRI_O_DOWN,表示主服务器已经进入客观下线状态。
当主服务器被 Sentinel 标记为客观下线时,Sentinel 将会向下线的主服务器从属的 slave节点发送 INFO 命令,频率会从每 10s 一次改为每秒一次。
从主观下线状态转换为客观下线状态并没有使用严格的法定人数算法,而是使用了流言协议。如果在 Sentinel 所设定的时间范围内,从其他 Sentinel 那里接收到足够数量的主服务器下线回复,它就会将这台主服务器的主观下线状态转换为客观下线状态。而如果没有足够数量的 Sentinel 同意主服务器已经下线,那么主服务器的客观下线状态就会被删除。
客观下线条件只适用于主服务器。对于任何其他类型的 Redis 实例,Sentinel 在将它们判断为下线前不需要进行协商,所以从服务器或者其他 Sentinel 永远不会达到客观下线条件。
总结为:客观下线就是所有 Sentinel 节点对 Redis 节点失败“达成共识”。
12.2.7 Sentinel 内部的定时任务
在这里额外介绍一下 Sentinel 内部的定时任务。
Redis 的 Sentinel 可以对 Redis 的节点做失败判定及故障转移。在 Sentinel 内部,有 3个定时任务作为基础来实现这个失败判定及故障转移的过程。3 个定时任务具体如下:
● 每隔 10s,每个 Sentinel 节点会对 master 和 slave 执行 INFO 命令,用于发现 slave节点,以及当发生故障时确认 master 与 slave 的关系,如图 12.20 所示。
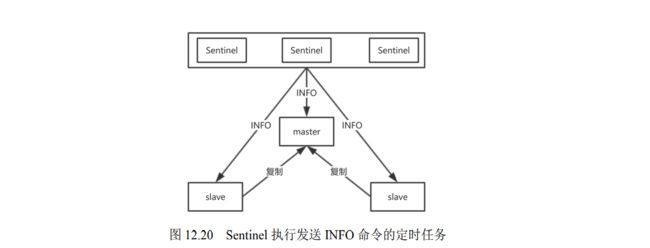
每隔 2s,每个 Sentinel 通过 master 节点的_sentinel_:hello 频道交换信息(pub/sub)。在 master 节点上有一个订阅发布频道,用于让 Sentinel 节点进行信息交换,原理就是每个 Sentinel 发布一条信息,其他 Sentinel 都可以接收到这样的信息,这条信息中包含了当前 Sentinel 节点的信息和它对 master 节点、slave 节点所做的一些判定信息等,如图 12.21 所示。

每隔 1s,每个 Sentinel 对其他 Sentinel 和 Redis 节点执行 PING 命令,用于确定节点的心跳监测,进而当作失败判定。前两个定时任务是该定时任务的基础。
12.3 Redis 集群搭建
12.3.1 什么是 Redis 集群
Redis 集群(Redis Cluster)是一个分布式、容错的 Redis 实现,它由多个 Redis 节点组成,在多个 Redis 节点之间进行数据共享。集群可以使用的功能是普通单机 Redis 所能使用的功能的一个子集,它提供了复制和故障转移功能。
Redis 集群中不存在中心节点或代理节点,而且不支持那些需要同时处理多个键的Redis 命令。因为要执行这些命令,需要在多个 Redis 节点之间移动数据,并且在高负载的情况下,执行这些命令会降低 Redis 集群的性能,并出现不可预料的问题。
Redis 集群的设计目标是达到线性可扩展性。
Redis 集群为了保证数据一致性,而牺牲了一部分容错性:Redis 系统会在保证对网络断线和节点失效具有有限抵抗力的前提下,尽可能地保证数据的一致性。Redis 集群的容错功能是通过主从复制实现的,当主节点宕机之后,从节点可以代替它完成相关工作。
Redis 集群通过分区来提供一定程度的可用性,当集群中有部分节点失效或者无法提供服务时,集群也可以继续完成相关的命令请求。
Redis 集群实现了单机 Redis 中所有处理单个数据库键的命令,它不支持多数据库功能。它默认使用 0 号数据库,并且不能使用 SELECT 命令。
使用集群的好处有:
(1)可以实现将数据自动切分到多个节点。
(2)当集群中有部分节点失效或者无法提供服务的时候,它仍然可以继续完成相关的命令请求。
(3)Redis 集群的使用可以解决高并发、大数据量的问题。
12.3.2 集群中的节点和槽
Redis 集群(Redis Cluster)是一个分布式、容错的 Redis 实现,它由多个 Redis 节点组成,在多个 Redis 节点之间进行数据共享。集群可以使用的功能是普通单机 Redis 所能使用的功能的一个子集,它提供了复制和故障转移功能。
Redis 集群中不存在中心节点或代理节点,而且不支持那些需要同时处理多个键的Redis 命令。因为要执行这些命令,需要在多个 Redis 节点之间移动数据,并且在高负载的情况下,执行这些命令会降低 Redis 集群的性能,并出现不可预料的问题。Redis 集群的设计目标是达到线性可扩展性。
Redis 集群为了保证数据一致性,而牺牲了一部分容错性:Redis 系统会在保证对网络断线和节点失效具有有限抵抗力的前提下,尽可能地保证数据的一致性。Redis 集群的容错功能是通过主从复制实现的,当主节点宕机之后,从节点可以代替它完成相关工作。Redis 集群通过分区来提供一定程度的可用性,当集群中有部分节点失效或者无法提供服务时,集群也可以继续完成相关的命令请求。
Redis 集群实现了单机 Redis 中所有处理单个数据库键的命令,它不支持多数据库功能。它默认使用 0 号数据库,并且不能使用 SELECT 命令。
使用集群的好处有:
(1)可以实现将数据自动切分到多个节点。
(2)当集群中有部分节点失效或者无法提供服务的时候,它仍然可以继续完成相关的命令请求。
(3)Redis 集群的使用可以解决高并发、大数据量的问题。
12.3.2 集群中的节点和槽
1.节点
一个 Redis 集群通常由多个节点(Node)组成。在没有搭建 Redis 集群之前,每个节点都是相互独立的,彼此之间没有任何联系,每个节点都只包含在自己的集群中,只有将多个独立的节点连接在一起,才能组建一个可以工作的集群。
通常使用 CLUSTER MEET 命令来连接各个独立的节点,命令格式如下:
CLUSTER MEET
将这条命令发送给某个节点,就可以让该节点与 ip 和 port 所指定的节点进行握手。当握手成功时,就表示该节点已经成功加入集群中。
在集群模式下,每个节点都是一台 Redis 服务器。在启动服务器的时候,会通过读取配置文件中 cluster-enabled 选项的值是否为 yes 来决定是否开启服务器的集群模式。当cluster-enabled 选项的值为 yes 时,表示开启服务器的集群模式成为集群中的一个节点;当 cluster-enabled 选项的值为 no 时,表示开启服务器的单机模式,也就是开启一台普通的 Redis 服务器。进入集群模式的节点会继续使用所有在单机模式中所使用的服务器组件,也就是说,每个节点所能使用的服务器组件不管是在集群模式还是在单机模式中都是一样的,不受影响。节点所能使用的服务器组件有文件事件处理器、时间事件处理器,
以及每个节点都可以使用数据库来保存键值对数据、使用复制功能完成数据复制、使用RDB 和 AOF 持久化来完成数据的恢复、使用订阅发布功能、使用 Lua 脚本环境执行 Lua脚本等。每个节点会继续使用 redisServer 和 redisClient 结构来分别保存服务器的状态和客户端的状态。
在开启集群模式的时候,服务器会创建一个 clusterState 类型的结构来保存当前节点视角下的集群状态。clusterState 结构的源码如下:
typedef struct clusterState {
//指向当前节点的指针
clusterNode *myself; /* This node */
//集群当前的配置纪元,用于实现故障转移
uint64_t currentEpoch;
//集群当前的状态,在线或下线
int state; /* CLUSTER_OK, CLUSTER_FAIL, ... */
//集群中至少负责一个槽的主节点个数
int size; /* Num of master nodes with at least one slot */
//保存集群节点的字典,字典中的键为节点的名字,字典中的值为节点对应的 clusterNode 结构
dict *nodes; /* Hash table of name -> clusterNode structures */
//防止重复添加节点的黑名单
dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */
//导入槽数据到目标节点,该数组记录这些节点
clusterNode *migrating_slots_to[CLUSTER_SLOTS];
//导出槽数据到目标节点,该数组记录这些节点
clusterNode *importing_slots_from[CLUSTER_SLOTS];
//槽和负责槽节点的映射
clusterNode *slots[CLUSTER_SLOTS];
//槽节点的数量
uint64_t slots_keys_count[CLUSTER_SLOTS];
//槽映射到键的指针
rax *slots_to_keys;
/* The following fields are used to take the slave state on elections. */
//之前或下一次选举的时间
mstime_t failover_auth_time; /* Time of previous or next election. */
//节点获得支持的票数
int failover_auth_count; /* Number of votes received so far. */
//如果为 true,则表示本节点已经向其他节点发送了投票请求
int failover_auth_sent; /* True if we already asked for votes. */
//该从节点在当前请求中的排名
int failover_auth_rank; /* This slave rank for current auth request. */
//当前选举的纪元
uint64_t failover_auth_epoch; /* Epoch of the current election. */
//从节点不能执行故障转移的原因
int cant_failover_reason; /* Why a slave is currently not able to
failover. See the CANT_FAILOVER_* macros. */
/* Manual failover state in common. */
//如果为 0,则表示没有进行手动故障转移;否则表示手动故障转移的时间限制
mstime_t mf_end; /* Manual failover time limit (ms unixtime).
It is zero if there is no MF in progress. */
/* Manual failover state of master. */
//执行手动故障转移的从节点
clusterNode *mf_slave; /* Slave performing the manual failover. */
/* Manual failover state of slave. */
//从节点记录了手动故障转移时的主节点偏移量
long long mf_master_offset; /* Master offset the slave needs to start MF
or zero if stil not received. */
//如果不为 0,则表示可以开始执行手动故障转移
int mf_can_start; /* If non-zero signal that the manual failover
can start requesting masters vote. */
/* The followign fields are used by masters to take state on elections. */
//集群最近一次投票的纪元
uint64_t lastVoteEpoch; /* Epoch of the last vote granted. */
//调用 clusterBeforeSleep()所做的一些事
int todo_before_sleep; /* Things to do in clusterBeforeSleep(). */
/* Messages received and sent by type. */
//发送的字节数
long long stats_bus_messages_sent[CLUSTERMSG_TYPE_COUNT];
//通过 cluster 接收到的消息数量
long long stats_bus_messages_received[CLUSTERMSG_TYPE_COUNT];
//发送失败的节点数,不包括没有地址的节点
long long stats_pfail_nodes; /* Number of nodes in PFAIL status,
excluding nodes without address. */
} clusterState;
在集群模式中,每个节点都会使用 cluster.h/clusterNode 结构来保存自己的当前状态, 如创建时间、名字、标识、配置纪元、IP 地址及端口等信息,同时也会为集群中的其他节 点创建一个 clusterNode 结构来保存其他节点的状态信息。clusterNode 结构的源码如下:
typedef struct clusterNode {
//节点的创建时间
mstime_t ctime; /* Node object creation time. */
//节点的名字,由 40 个十六进制的字符组成
char name[CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
//节点标识,用于记录节点的角色及当前状态
int flags; /* CLUSTER_NODE_... */
//节点的配置纪元,用于实现故障转移
uint64_t configEpoch; /* Last configEpoch observed for this node */
//节点的槽位图
unsigned char slots[CLUSTER_SLOTS/8]; /* slots handled by this node */
//当前节点复制槽的数量
int numslots; /* Number of slots handled by this node */
//从节点的数量
int numslaves; /* Number of slave nodes, if this is a master */
//从节点指针数组
struct clusterNode **slaves; /* pointers to slave nodes */
//指向主节点,即使是从节点,也可以为 NULL
struct clusterNode *slaveof; /* pointer to the master node. Note that it
may be NULL even if the node is a slave
if we don't have the master node in our
tables. */
//最近一次发送 PING 命令的时间
mstime_t ping_sent; /* Unix time we sent latest ping */
//接收到 PONG 的时间
mstime_t pong_received; /* Unix time we received the pong */
//被设置为 FAIL 的下线时间
mstime_t fail_time; /* Unix time when FAIL flag was set */
//最近一次为从节点投票的时间
mstime_t voted_time; /* Last time we voted for a slave of this master */
//更新复制偏移量的时间
mstime_t repl_offset_time; /* Unix time we received offset for this node */
//孤立的主节点迁移的时间
mstime_t orphaned_time; /* Starting time of orphaned master condition */
//该节点已知的复制偏移量
long long repl_offset; /* Last known repl offset for this node. */
//IP 地址
char ip[NET_IP_STR_LEN]; /* Latest known IP address of this node */
//节点端口号
int port; /* Latest known clients port of this node */
//集群端口号
int cport; /* Latest known cluster port of this node. */
//与该节点关联的连接对象
clusterLink *link; /* TCP/IP link with this node */
//保存下线报告的链表
list *fail_reports; /* List of nodes signaling this as failing */
} clusterNode;
clusterNode 结构中包含了一个具有 link 属性的结构 clusterLink,该结构中保存了其他 连接节点的相关信息,如节点的创建时间、缓冲区信息等。clusterLink 结构的源码如下:
typedef struct clusterLink {
//节点的创建时间
mstime_t ctime; /* Link creation time */
//TCP 套接字的文件描述符
int fd; /* TCP socket file descriptor */
//输出缓冲区,其中保存着将要发送给其他节点的信息
sds sndbuf; /* Packet send buffer */
//输入缓冲区,其中保存着从其他节点接收到的信息
sds rcvbuf; /* Packet reception buffer */
//与该节点关联的节点,没有就为 NULL
struct clusterNode *node; /* Node related to this link if any, or NULL */
} clusterLink;
关于集群节点的更多知识,在这里不再详述,感兴趣的读者可以参考其他资料学习。
2.槽
Redis 集群为了能够存储大量的数据信息,采用分片的方式将大量数据保存在数据库中,这个数据库被划分为 16 384 个槽(Slot)。这里所说的槽也称为虚拟槽,你可以把这个槽理解为一个数字,槽是有一定范围的,在 Redis 中的范围是 0~16 383。每个槽映射一个大数据子集,一般比节点数大。比如,有 10 万个数据,16 284 个槽,按照一定的哈希规则,对每个数字做一个哈希,然后对 16 363 进行取余,如果这个数字在某个槽的范围内,就证明这个数字就是这个槽要管理的数据。
在集群的数据库中,每个键都存储在 16 384 个槽的其中一个槽中,集群中的每个节点都可以处理 0 个或者最多 16 384 个槽。当数据库中的 16 384 个槽都有节点在处理时,集群处于上线状态;而如果数据库中有任何一个槽没有得到处理,集群就处于下线状态。
对于 16 384 个槽该如何来划分呢?
Redis 集群的服务器端负责管理节点、槽、数据,在划分槽时,它会根据哈希函数(如CRC16)来进行划分。采用哈希函数来划分所具有的优点是数据分散度高,键值分布与业务无关,同时支持批量操作;缺点是无法顺序访问数据。在划分槽时,需要根据节点的个数来进行划分。比如,对 5 个集群节点划分槽,如图 12.22 所示。
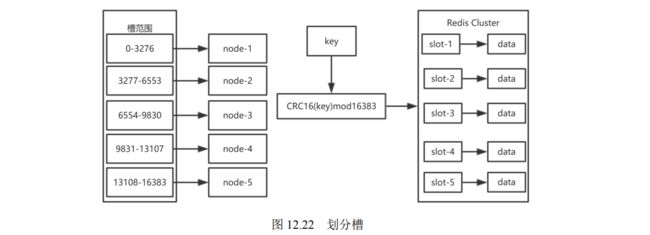
在 cluster.h/clusterNode 结构中有 slots 和 numslots 属性,它们记录了 Redis 节点负责处理哪些槽。其中,slots 属性是一个无符号二进制数组,其定义如下:
unsigned char slots[CLUSTER_SLOTS/8]
其中,CLUSTER_SLOTS 是一个常量,其值为 16 384,表示有 16 384 个二进制位。也就是说,这个 slots 数组的长度为 16 384/8=2048 字节。这个 slots 数组的下标从 0 开始,到16 383 结束。对 slots 数组中的 16 384 个二进制位进行编号,Redis 会根据这个 slots 数组的索引 i 来判断节点是否负责处理槽 i。
● 当 slots 数组在索引 i 上的二进制位的值为 1 时,表示节点负责处理槽 i。
● 当 slots 数组在索引 i 上的二进制位的值为 0 时,表示节点不负责处理槽 i。
slots 数组的原理图如图 12.23 所示。假设节点负责处理索引为 1、2、4、7、10、14、15的槽,就表示 slots 数组索引为 1、2、4、7、10、14、15 的槽所对应的二进制位的值为 1。
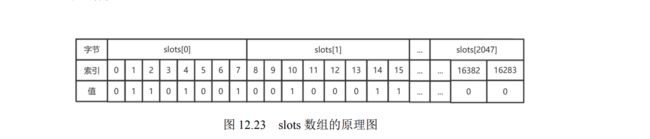
而 numslots 属性是 int 类型的,用于记录节点负责处理的槽的数量,也就是 slots 数组中值为 1 的二进制位的总数量。在图 12.23 中,numslots 属性的值为 7。
一个节点除将自己负责处理的槽记录在 clusterNode 结构中之外,还会将自己的 slots数组以消息的方式发送给集群中的其他节点,告诉其他节点自己目前负责处理哪些槽。
当为集群中的所有节点都指派了槽之后,集群中的所有槽的指派信息将会被记录到cluster.h/clusterState 结构中,该结构的 slots 数组属性记录了集群中所有 16 384 个槽的指派信息。
clusterState 结构的 slots 数组定义如下:
clusterNode *slots[CLUSTER_SLOTS];
其中,CLUSTER_SLOTS 常量的值为 16 384,也就是说,slots 数组的长度为 16 384,数组包含 16 384 个元素,而每个元素都是一个指向 clusterNode 结构的指针。
● 当 slots[i]指针指向 NULL 时,表示没有任何节点负责处理槽 i。
● 当 slots[i]指针指向一个 clusterNode 结构时,表示槽 i 已经被指派给了 clusterNode结构所代表的节点。
12.3.3 集群搭建
前面介绍了集群的节点和槽的相关知识点,接下来我们将会按照 Redis 集群的架构图 来搭建 Redis 集群。
1.集群架构说明
Redis Cluster 架构图如图 12.24 所示。

● 节点:Redis 集群中有一堆节点,节点之间是互相通信的,每个节点都负责读和写数据。
● meet:meet 操作就是完成节点相互通信的过程。
● 指派槽:只有给节点指派了对应的槽,节点才可以进行正常的读/写。当你启动了一个节点,并为它指定了 cluster 模式后,它不会进行正常的读/写,还需要为它指派槽。当有数据访问的时候,它会去查看自己的槽有没有对应的信息,也就是传递过来的key 计算出来的哈希值是否在槽的范围内。
● 复制:为了保证高可用,需要一个复制,就是每个主节点都有一个从节点。但是集
群有很多主节点,当主节点出现问题的时候,它通过某种形式也可以实现主备的一个高可用。当主节点宕机之后,从节点就会代替它,它内部的监控没有依赖于 Sentinel的,而是通过节点之间相互监控来完成的。
- 集群的搭建步骤
Redis 集群的搭建有两种方式:原生命令搭建和官方工具搭建。在这里只介绍采用原生
命令搭建的方式安装一个三主三从的集群(6 个节点)。至于官方工具的搭建,需要安装
Ruby 等相关环境,在这里就不介绍了。
三主三从集群的关系如下。
● 主节点:7000、7001、7002。
● 主从关系:7003 是 7000 的从节点,7004 是 7001 的从节点,7005 是 7002 的从节点。
具体搭建步骤如下。
(1)配置开启节点。
配置选项说明如下。
● port p o r t :指定端口。● d a e m o n i z e y e s :以守护进程的方式启动。● d i r " / h o m e / r e d i s / d a t a " :数据目录。● d b f i l e n a m e " d u m p − {port}:指定端口。 ● daemonize yes:以守护进程的方式启动。 ● dir "/home/redis/data":数据目录。 ● dbfilename "dump- port:指定端口。●daemonizeyes:以守护进程的方式启动。●dir"/home/redis/data":数据目录。●dbfilename"dump−{port}.rdb":指定 RDB 文件。
● logfile "redis-cluster- p o r t . l o g " :指定日志文件。● c l u s t e r − e n a b l e d y e s :开启集群模式,表示该节点是一个 c l u s t e r 节点。● c l u s t e r − c o n f i g − f i l e n o d e s − {port}.log":指定日志文件。 ● cluster-enabled yes:开启集群模式,表示该节点是一个 cluster 节点。 ● cluster-config-file nodes- port.log":指定日志文件。●cluster−enabledyes:开启集群模式,表示该节点是一个cluster节点。●cluster−config−filenodes−{port}.conf:为 cluster 节点指定配置文件。cluster 节点主要配置说明如下。
● cluster-enabled yes:开启集群模式,表示该节点是一个 cluster 节点。
● cluster-node-timeout 15000:表示故障转移的时间或节点超时的时间,15s。
● cluster-config-file “nides.conf”:集群节点的配置。
● cluster-require-full-coverage yes:是否需要集群的所有节点都提供服务,才会认为这个集群是正常运行的。假如集群中有一个节点宕机了,它就不对外提供服务了。这个配置默认是 yes。在实际生产过程中,这个配置是不合理的,因为集群的一个节 点宕机而停止所有的服务,这样做是不可取的,实际业务也是不允许的,所以建议 设置为 no。
准备 6 个配置文件(7000,7001,7002,7003,7004,7005),文件名为 redis-cluster-${port}.conf。redis-cluster-7000.conf 文件的内容如下:
port 7000
daemonize yes
dir "/home/redis/data"
logfile "cluster-7000.log"
dbfilename "dump-7000.rdb"
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-require-full-coverage no
编辑完之后,保存并查看,如下所示:
[root@localhost redis-4.0.9]# vim redis-cluster-7000.conf
[root@localhost redis-4.0.9]# cat redis-cluster-7000.conf
port 7000
daemonize yes
dir "/home/redis/data"
logfile "cluster-7000.log"
dbfilename "dump-7000.rdb"
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-require-full-coverage no
redis-cluster-7001.conf 文件的内容如下:
port 7001
daemonize yes
dir "/home/redis/data"
logfile "cluster-7001.log"
dbfilename "dump-7001.rdb"
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-require-full-coverage no
redis-cluster-7002.conf 文件的内容如下:
port 7002
daemonize yes
dir "/home/redis/data"
logfile "cluster-7002.log"
dbfilename "dump-7002.rdb"
cluster-enabled yes
cluster-config-file nodes-7002.conf
cluster-require-full-coverage no
redis-cluster-7003.conf 文件的内容如下:
port 7003
daemonize yes
dir "/home/redis/data"
logfile "cluster-7003.log"
dbfilename "dump-7003.rdb"
cluster-enabled yes
cluster-config-file nodes-7003.conf
cluster-require-full-coverage no
redis-cluster-7004.conf 文件的内容如下:
port 7004
daemonize yes
dir "/home/redis/data"
logfile "cluster-7004.log"
dbfilename "dump-7004.rdb"
cluster-enabled yes
cluster-config-file nodes-7004.conf
cluster-require-full-coverage no
redis-cluster-7005.conf 文件的内容如下:
port 7005
daemonize yes
dir "/home/redis/data"
logfile "cluster-7005.log"
dbfilename "dump-7005.rdb"
cluster-enabled yes
cluster-config-file nodes-7005.conf
cluster-require-full-coverage no
在编辑并保存完 redis-cluster-7000.conf 文件后,可以使用如下命令快速生成其他 5 个配置文件:
sed 's/7000/7001/g' redis-cluster-7000.conf >redis-cluster-7001.conf
sed 's/7000/7002/g' redis-cluster-7000.conf >redis-cluster-7002.conf
sed 's/7000/7003/g' redis-cluster-7000.conf >redis-cluster-7003.conf
sed 's/7000/7004/g' redis-cluster-7000.conf >redis-cluster-7004.conf
sed 's/7000/7005/g' redis-cluster-7000.conf >redis-cluster-7005.conf
配置完成之后,开始启动节点,命令如下:
redis-server redis-cluster-7000.conf
redis-server redis-cluster-7001.conf
redis-server redis-cluster-7002.conf
redis-server redis-cluster-7003.conf
redis-server redis-cluster-7004.conf
redis-server redis-cluster-7005.conf
然后使用命令 ps -ef | grep redis-server 查看进程,操作如下:
[root@localhost redis-4.0.9]# redis-server redis-cluster-7000.conf
[root@localhost redis-4.0.9]# redis-server redis-cluster-7001.conf
[root@localhost redis-4.0.9]# redis-server redis-cluster-7002.conf
[root@localhost redis-4.0.9]# redis-server redis-cluster-7003.conf
[root@localhost redis-4.0.9]# redis-server redis-cluster-7004.conf
[root@localhost redis-4.0.9]# redis-server redis-cluster-7005.conf
[root@localhost redis-4.0.9]# ps -ef | grep redis-server
root 16920 1 0 17:20 ? 00:00:00 redis-server *:7000 [cluster]
root 16924 1 0 17:20 ? 00:00:00 redis-server *:7001 [cluster]
root 16928 1 0 17:20 ? 00:00:00 redis-server *:7002 [cluster]
root 16932 1 0 17:20 ? 00:00:00 redis-server *:7003 [cluster]
root 16937 1 0 17:20 ? 00:00:00 redis-server *:7004 [cluster]
root 16945 1 0 17:20 ? 00:00:00 redis-server *:7005 [cluster]
root 16953 15537 0 17:21 pts/9 00:00:00 grep redis-server
下面执行命令 redis-cli -p 7000 连接 7000 节点,并执行命令 SET message hello,它会返 回错误提示信息,如下所示:
[root@localhost redis-4.0.9]# redis-cli -p 7000
127.0.0.1:7000> SET message hello
(error) CLUSTERDOWN Hash slot not served
错误提示信息 CLUSTERDOWN 说明集群处于下线状态,集群不可用。前面我们提到 过,在集群模式下,只有当为每个节点都指派了槽,而且对 16 384 个槽都进行了指派时, 这个集群节点才可用,才能对外提供服务。接下来的工作就是为集群节点执行 meet 操作及 指派槽。
我们使用命令查看一下 7000 节点的配置文件,操作如下:
[root@localhost redis-4.0.9]# cat /home/redis/data/nodes-7000.conf
08a9ea203c226231f52c17559b7ca146e668e :0 myself,master – 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
从中可以看出, 7000 节点是一个孤立的节点,它的 node-id 是08a9ea203c226231f52c17559b7cb7ca146e668e,myself 表示它自己,角色是 master,后面的相关信息是它的连接信息及配置纪元等。
使用命令 redis-cli -p 7000 cluster nodes 查看集群节点信息,使用命令 redis-cli -p 7000 cluster info 查看集群信息。命令操作如下:
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster nodes
08a9ea203c226231f52c17559b7ca146e668e :7000 myself,master – 0 0 0 connected
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:1
cluster_size:0
cluster_current_epoch:0
cluster_my_epoch:0
cluster_stats_messages_sent:0
cluster_stats_messages_received:0
Redis 集群中的节点负有以下责任:
● 保存客户端发送过来的键值对数据。
● 记录集群的状态,以及某个键到其所对应的节点映射。
● 自动发现其他节点,监控其他节点,当某个节点出现故障时,进行故障转移等。集群节点之间是互相连接的,组成一幅连通图,它们之间的网络连接是 TCP 连接,使用二进制协议(Gossip 协议)进行通信。集群节点之间使用 Gossip 协议来完成以下工作:
● 在节点之间互相传播集群信息,发现新节点。
● 时常监控其他节点,向其他节点发送 PING 数据包,监控其他节点是否正常运行。
● 在特定事件发生时,发送集群信息等。
(2)搭建集群——meet 操作。
执行命令 redis-cli -p 7000 cluster meet 127.0.0.1 7001,7000 与 7001 节点就完成了握手关系的建立。执行命令 redis-cli -p 7000 cluster nodes,查看节点关系。命令操作如下:
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster meet 127.0.0.1 7001
ok
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster nodes
267eb5710541fbd35974a17187c702934765f656 127.0.0.1:7001 master - 0 1535796528988 0
connected
08a9ea203c226231f52c17559b7cb7ca146e668e 127.0.0.1:7000 myself,master - 0 0 1
connected
分别建立 7000 与 7002、7003、7004、7005 节点的握手关系,命令操作如下:
redis-cli -p 7000 cluster meet 127.0.0.1 7002
redis-cli -p 7000 cluster meet 127.0.0.1 7003
redis-cli -p 7000 cluster meet 127.0.0.1 7004
redis-cli -p 7000 cluster meet 127.0.0.1 7005
集群节点之间建立了握手关系,如下所示:
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster meet 127.0.0.1 7002
ok
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster meet 127.0.0.1 7003
ok
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster meet 127.0.0.1 7004
ok
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster meet 127.0.0.1 7005
ok
之后集群的 6 个节点之间就会相互建立关系,最终形成一幅有 6 个节点的连通图。 执行命令 redis-cli -p 7005 cluster nodes 查看节点之间的关系,如下所示:
[root@localhost redis-4.0.9]# redis-cli -p 7005 cluster nodes
9e546e19ea5ce91f7e08299d105131a80920d4be 127.0.0.1:7005 myself,master – 0 0 4
connected
267eb5710541fbd35974a17187c702934765f656 127.0.0.1:7001 master – 0 1535796980239 2
connected
110e7059af3e2aa700e6f96f8a410e5a4164b4ac 127.0.0.1:7003 master – 0 1535796976227 3
connected
ef41fdf38fc2651dffb3cec51a3bdd5d4932144f 127.0.0.1:7004 master – 0 1535796979236 0
connected
5e7f8890fe75aefb1ea8f42c41e637cab746c8de 127.0.0.1:7002 master - 0 1535796974221 5
connected
08a9ea203c226231f52c17559b7cb7ca146e668e 127.0.0.1:7000 master - 0 1535796981241 1
connected
执行命令 redis-cli -p 7003 cluster info 查看集群信息,如下所示:
[root@localhost redis-4.0.9]# redis-cli -p 7003 cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:3
cluster_stats_messages_sent:564
cluster_stats_messages_received:564
其中,cluster_known_nodes:6 表示 6 个节点已经建立了连接。至此,节点之间的 meet操作就完成了。
cluster_state:fail 表示集群处于下线状态。这是因为还没有为节点指派槽,集群仍然不能对外提供服务,进入某个节点的客户端执行写命令,仍会返回错误。
(3)指派槽。
使用命令 redis-cli -p 7000 cluster addslots 0 为节点 7000 指派一个槽。我们知道共有 16 384 个槽,但我们不可能执行这个命令 16 384 次。下面编写一个脚本,来为集群节点指派槽。
创建脚本文件夹,文件夹名为 redis-cluster-slot-script 。执行命令 mkdir edis-cluster-slot-script 进入 redis-cluster-slot-script 目录,执行命令 vim addslots.sh 开始编辑脚本内容。操作如下:
[root@localhost redis-4.0.9]# mkdir redis-cluster-slot-script
[root@localhost redis-4.0.9]# cd redis-cluster-slot-script/
[root@localhost redis-cluster-slot-script]# vim addslots.sh
[root@localhost redis-cluster-slot-script]# cat addslots.sh
start=$1
end=$2
port=$3
for slot in `seq ${start} ${end}`
do
echo "slot:${slot}"
redis-cli -p ${port} cluster addslots ${slot}
done
start=$1
end=$2
port=$3
for slot in `seq ${start} ${end}`
do
echo "slot:${slot}"
redis-cli -p ${port} cluster addslots ${slot}
done
这个脚本接收 3 个参数:start 为起始参数;end 为终止参数;port 为端口。
例如,执行命令 sh addslots.sh 0 5461 7000,表示给 7000 端口指派 0~5461 范围内的槽。有 16 384 个槽,分别指派到 3 个主节点(7000、7001、7002)上,分配如下。
● 7000 节点:0~5461。
● 7001 节点:5462~10922。
● 7002 节点:10 923~16 383。
下面为 7000 节点指派 0~5461 范围内的槽,命令如下:
sh addslots.sh 0 5461 7000
在执行 sh addslots.sh 0 5461 7000 命令后,建立了与 7000 节点客户端的连接;再执行 cluster info 和 cluster nodes 命令,查看集群信息与节点信息。操作如下:
[root@localhost redis-4.0.9]# redis-cli -p 7000
127.0.0.1:7000> cluster info
cluster_state:ok
cluster_slots_assigned:5462
cluster_slots_ok:5462
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:1
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_sent:6626
cluster_stats_messages_received:6626
127.0.0.1:7000> cluster nodes
267eb5710541fbd35974a17187c702934765f656 127.0.0.1:7001 master - 0 1535799659054 2
connected
110e7059af3e2aa700e6f96f8a410e5a4164b4ac 127.0.0.1:7003 master - 0 1535799660056 3
connected
9e546e19ea5ce91f7e08299d105131a80920d4be 127.0.0.1:7005 master - 0 1535799661060 4
connected
5e7f8890fe75aefb1ea8f42c41e637cab746c8de 127.0.0.1:7002 master - 0 1535799662062 5
connected
08a9ea203c226231f52c17559b7cb7ca146e668e 127.0.0.1:7000 myself,master - 0 0 1
connected 0-5461
ef41fdf38fc2651dffb3cec51a3bdd5d4932144f 127.0.0.1:7004 master - 0 1535799663066 0
connected
从返回的信息中可以看出,已经成功为 7000 节点指派了 5462 个槽。 然后为 7001 节点指派 5462~10 922 范围内的槽,命令如下:
sh addslots.sh 5462 10922 7001
在执行 sh addslots.sh 5462 10922 7001 命令之后,建立了与 7001 节点客户端的连接。然后执行写操作 SET age 22,操作如下:
[root@localhost redis-4.0.9]# redis-cli -p 7000
127.0.0.1:7000> SET age 22
OK
127.0.0.1:7000> CONFIG GET cluster*
1) "cluster-node-timeout"
2) "15000"
3) "cluster-migration-barrier"
4) "1"
5) "cluster-slave-validity-factor"
6) "10"
7) "cluster-require-full-coverage"
8) "no"
可以看到执行成功了,即使还没有为 7002 节点指派槽,7000 节点也能对外提供服务 了。原因是我们设置 cluster-require-full-coverage 选项值为 no,就算集群中的某个节点宕机 了,其他节点也能对外提供服务。 最后为 7002 节点指派 10 923~16 383 范围内的槽,命令如下:
sh addslots.sh 10923 16383 7002
执行命令 redis-cli -p 7000 cluster info 查看集群信息。
执行命令 redis-cli -p 7000 cluster nodes 查看集群节点信息。
为主节点指派槽之后的集群信息如下所示:
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_sent:9779
cluster_stats_messages_received:9779
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster nodes
267eb5710541fbd35974a17187c702934765f656 127.0.0.1:7001 master - 0 15358001143315
2 connected 5462-10922
110e7059af3e2aa700e6f96f8a410e5a4164b4ac 127.0.0.1:7003 master - 0 15358001142312
3 connected
9e546e19ea5ce91f7e08299d105131a80920d4be 127.0.0.1:7005 master - 0 15358001143817
4 connected
5e7f8890fe75aefb1ea8f42c41e637cab746c8de 127.0.0.1:7002 master - 0 15358001144318
5 connected 10923-16383
08a9ea203c226231f52c17559b7cb7ca146e668e 127.0.0.1:7000 myself,master - 0 0 1
connected 0-5461
ef41fdf38fc2651dffb3cec51a3bdd5d4932144f 127.0.0.1:7004 master - 0 15358001141309
0 connected
其中,cluster_state:ok 表示集群处于上线状态;cluster_slots_assigned:16384 表示槽的总个数;cluster_slots_ok:16384 表示槽的状态是 OK 的数目;cluster_size:3 表示指派槽的节点个数。到这里,主节点的槽就已经指派完成了。
(4)主从分配。
主从关系分配:7003 是 7000 的从节点,7004 是 7001 的从节点,7005 是 7002 的从节点。
主从分配命令格式如下:
redis-cli -p <从节点端口> cluster replicate <主节点 node-id>
要分配主从关系,先要获得主节点的 node-id。执行如下命令查看节点 node-id:
redis-cli -p 7000 cluster nodes
节点 node-id 信息如下所示:
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster nodes
267eb5710541fbd35974a17187c702934765f656 127.0.0.1:7001 master - 0 1535801770125 2
connected 5462-10922
110e7059af3e2aa700e6f96f8a410e5a4164b4ac 127.0.0.1:7003 master - 0 1535801774138 3
connected
9e546e19ea5ce91f7e08299d105131a80920d4be 127.0.0.1:7005 master - 0 1535801775141 4
connected
5e7f8890fe75aefb1ea8f42c41e637cab746c8de 127.0.0.1:7002 master - 0 1535801773134 5
connected 10923-16383
08a9ea203c226231f52c17559b7cb7ca146e668e 127.0.0.1:7000 myself,master - 0 0 1
connected 0-5461
ef41fdf38fc2651dffb3cec51a3bdd5d4932144f 127.0.0.1:7004 master - 0 1535801771129 0
connected
分别执行如下命令分配主从关系:
redis-cli -p 7003 cluster replicate 08a9ea203c226231f52c17559b7cb7ca146e668e
redis-cli -p 7004 cluster replicate 267eb5710541fbd35974a17187c702934765f656
redis-cli -p 7005 cluster replicate 5e7f8890fe75aefb1ea8f42c41e637cab746c8de
再次执行 redis-cli -p 7000 cluster nodes 命令,就能看到三主三从的主从关系了。操 作如下:
[root@localhost redis-4.0.9]# redis-cli -p 7003 replicate
08a9ea203c226231f52c17559b7cb7ca146e668e
ok
[root@localhost redis-4.0.9]# redis-cli -p 7004 cluster replicate 267eb5710541fbd
35974a17187c702934765f656
ok
[root@localhost redis-4.0.9]# redis-cli -p 7005 cluster replicate 5e7f8890fe75aefb
1ea8f42c41e637cab746c8de
ok
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster nodes
267eb5710541fbd35974a17187c702934765f656 127.0.0.1:7001 master - 0 1535802107076 2
connected 5462-10922
110e7059af3e2aa700e6f96f8a410e5a4164b4ac 127.0.0.1:7003 slave 08a9ea203c226231f52c
17559b7cb7ca146e668e 0 1535802105070 3 connected
9e546e19ea5ce91f7e08299d105131a80920d4be 127.0.0.1:7005 slave 5e7f8890fe75aefb1ea8
f42c41e637cab746c8de 0 1535802106074 5 connected
5e7f8890fe75aefb1ea8f42c41e637cab746c8de 127.0.0.1:7002 master - 0 1535802101057 5
connected 10923-16383
08a9ea203c226231f52c17559b7cb7ca146e668e 127.0.0.1:7000 myself,master - 0 0 1
connected 0-5461
ef41fdf38fc2651dffb3cec51a3bdd5d4932144f 127.0.0.1:7004 slave 267eb5710541fbd3597
4a17187c702934765f656 0 1535802108080 2 connected
执行命令 redis-cli -p 7000 cluster slots 查看集群槽的指派信息,同时也能看到主从关系。操作如下:
[root@localhost redis-4.0.9]# redis-cli -p 7000 cluster slots
1) 1) (integer) 5462
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 7001
3) "267eb5710541fbd35974a17187c702934765f656"
4) 1) "127.0.0.1"
2) (integer) 7004
3) "ef41fdf38fc2651dffb3cec51a3bdd5d4932144f"
2) 1) (integer) 0
2) (integer) 5461
3) 1) "127.0.0.1"
2) (integer) 7000
3) "08a9ea203c226231f52c17559b7cb7ca146e668e"
4) 1) "127.0.0.1"
2) (integer) 7003
3) "110e7059af3e2aa700e6f96f8a410e5a4164b4ac"
3) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 7002
3) "5e7f8890fe75aefb1ea8f42c41e637cab746c8de"
4) 1) "127.0.0.1"
2) (integer) 7005
3) "9e546e19ea5ce91f7e08299d105131a80920d4be"
接着执行集群模式下的数据操作:执行命令 redis-cli -c -p 7000,建立与 7000 节点
客户端的连接;执行写操作命令 SET color red,将会返回 OK。
至此,Redis 的集群搭建就已经完成了,整个过程是在同一台机器上完成的。在实际应用中,需要配置 6 台或 3 台 Redis 服务器,才能实现真正的高可用集群模式。如果是 3 台机器,两台之间可互为主从,则也可以搭建一个集群模式。
3 台机器搭建集群模式的参考设置如下:
192.168.0.1:7000 192.168.0.2:7003
192.168.0.2:7001 192.168.0.3:7004
192.168.0.3:7002 192.168.0.1:7005
请读者根据实际情况,具体搭建集群模式,这里只是提供一个参考。这里额外说一下集群中的主从复制与故障转移。
Redis 集群中的主从复制,其中主节点主要用于处理槽,而从节点则用于复制其对应的主节点。当被复制的主节点发生故障时,从节点就会代替这个下线的主节点,完成故障转移操作。
执行命令 CLUSTER REPLICATE
12.3.4 使用 Redis 集群
在对集群节点指派槽之后,集群就处于上线状态,就可以对外提供服务了,也就是客户端可以向集群节点发送命令请求了。当客户端向集群中的某个节点发送与数据库键有关的命令时,节点在接收到命令后,会根据这条命令计算出要处理的数据库键属于哪个槽,并判断这个槽是否在自己槽的范围内,换句话说,就是判断这个槽是否由当前节点复制处理。
● 如果这条命令的键所在的槽正好在当前节点槽的范围内,也就是键所在的槽指派给了当前节点,那么这个节点就会成功执行这条命令。
● 如果这条命令的键所在的槽不在当前节点槽的范围内,那么在执行这条命令后,节点将会向客户端返回一个 MOVED 错误信息,并给出这条命令的键所在的槽及节点的 IP 地址和端口信息提示。命令操作返回的信息如下所示:
[root@localhost redis-4.0.9]# redis-cli -p 7000
127.0.0.1:7000> SET message hello
(error) MOVED 11537 127.0.0.1:7002
从返回的信息中可以看出,键 message 所在的槽是 11 537,这条命令应该在 127.0.0.1:7002节点中执行。以上判断过程的流程图如图 12.25 所示。
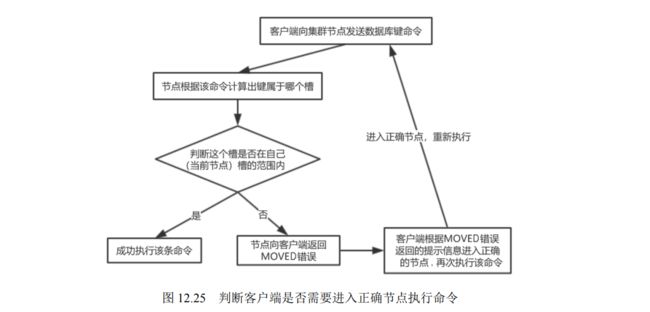
如何计算一个给定的键属于哪个槽呢?
Redis 集群节点采用 CRC16 算法来计算给定的键属于哪个槽。
HASH_SLOT = CRC16(key) mod 16383
其中,CRC16(key)语句用于计算给定键的 CRC16 校验和;mod 是取余操作,用于计算出 0~16 383 之间的整数作为给定键所在的槽号。
使用命令 CLUSTER KEYSLOT 来获取指定键属于哪个槽,也就是获取键所在的槽号。命令操作如下:
127.0.0.1:7000> CLUSTER KEYSLOT message
(integer) 11537
127.0.0.1:7000> CLUSTER KEYSLOT name
(integer) 5798
127.0.0.1:7000> CLUSTER KEYSLOT age
(integer) 741
在执行 CLUSTER KEYSLOT 命令之后,底层会调用 CRC16(key)算法来计算出给定键所在的槽号,并返回给客户端。
根据 CRC16(key)算法计算出槽号后,如何判断这个槽号是否在自己(当前节点)槽的范围内呢?
根据 CRC16(key)算法计算出给定键所在的槽号 i 后,节点就会根据 clusterState.slots[i] (其中 i 是 slots 数组的下标)是否等于 clusterState.myself 来判断键所在的槽是否由自己负责。
● 当 clusterState.slots[i]等于 clusterState.myself 时,表示槽 i 在当前节点槽的范围内,槽 i 由当前节点负责,这条命令可以在该节点上成功执行。
● 当 clusterState.slots[i]不等于 clusterState.myself 时,表示槽 i 不在当前节点槽的范围内,当前节点不负责处理槽 i。在执行这条命令后,节点会根据 clusterState.slots[i]指向的 clusterNode 结构所记录的节点 IP 地址和端口信息,向客户端返回 MOVED错误,并返回该条命令的键所在的槽号,以及所在节点的 IP 地址和端口信息。
12.3.5 集群中的错误
- MOVED 错误
集群搭建完成后,当客户端向其中一个节点发送数据库键命令时,如果这条命令的键所对应的槽号不在该节点指派槽的范围内,就会返回一个 MOVED 错误信息。
MOVED 错误的格式如下:
MOVED :
这个错误信息包含键所属的槽号,以及负责处理这个槽的节点的 IP 地址和端口信息。当客户端接收到节点返回的 MOVED 错误时,会根据错误信息中的 IP 地址和端口信息,转向负责处理指定键的槽所属的节点,并向该节点重新发送这条命令请求。
返回 MOVED 错误信息,命令操作如下:
127.0.0.1:7000> SET username "liuhefei"
(error) MOVED 14315 127.0.0.1:7002
一个集群客户端通常会与集群中的其他节点创建套接字连接,而前面所说的节点转向实际上就是换一个套接字来发送命令。假如这个客户端还没有与想要转向的节点创建套接字连接,就会先根据 MOVED 错误提供的 IP 地址和端口信息来进行连接,再进行节点转向操作。
- ASK 错误
在讲解 ASK 错误之前,先介绍一下 Redis 集群的重新分片操作。
Redis 集群的重新分片操作可以将任意数量已经指派给某个节点(源节点)的槽重新指派给新节点(目标节点),重新分片之后,相关槽所属的键值对也会从源节点转移到目标节点。集群重新分片的过程可以在线进行,集群不需要下线处理,此时源节点和目标节点都能继续处理其他命令请求。
下面为之前搭建的集群再添加一个节点 127.0.0.1:7006,来进行重新分片操作。这个过程与前面讲解的搭建集群的操作步骤相同,在这里不再详细讲解。我们先新建并编辑新节点的配置文件 redis-cluster-7006.conf,然后启动新节点。查看添加新节点后的集群节点信息,
命令操作如下:
[root@localhost redis-4.0.9]# redis-cli -p 7000
127.0.0.1:7000> cluster nodes
267eb5710541fbd35974a17187c702934765f656 127.0.0.1:7001 master - 0 1535880299036 2
connected 5462-10922
110e7059af3e2aa700e6f96f8a410e5a4164b4ac 127.0.0.1:7003 slave 08a9ea203c226231f52
c17559b7cb7ca146e668e 0 1535880302045 3 connected
288∣从零开始学 Redis
9e546e19ea5ce91f7e08299d105131a80920d4be 127.0.0.1:7005 slave 5e7f8890fe75aefb1ea8
f42c41e637cab746c8de 0 1535880298033 5 connected
5e7f8890fe75aefb1ea8f42c41e637cab746c8de 127.0.0.1:7002 master - 0 1535880303049 5
connected 10923-16383
266502a1ff1924c7d6f7f1739fc631e1fe514c44 127.0.0.1:7006 master - 0 1535880301043 0
connected
08a9ea203c226231f52c17559b7cb7ca146e668e 127.0.0.1:7000 myself,master - 0 0 1 con
nected 0-5461
ef41fdf38fc2651dffb3cec51a3bdd5d4932144f 127.0.0.1:7004 slave 267eb5710541fbd3597
4a17187c702934765f656 0 1535880300039 2 connected
之后利用集群管理软件 redis-trib 完成重新分片操作,具体过程如下。
(1)redis-trib 对目标节点发送 CLUSTER SETSLOT IMPOREING
(2)同时,redis-trib 会发送命令 CLUSTER SETSLOT MIGRATING
(3)redis-trib 向源节点发送命令 CLUSTER GETKEYSINSLOT ,来从源节点中获取 count 个属于槽的键值对的键名。
(4)redis-trib 向源节点发送 MIGRATE
(5)转移完之后,redis-trib 会向集群中的任意一个节点发送 CLUSTER SETSLOT NODE
以上这个过程就是重新分片的过程。至于提到的 redis-trib 工具,本章没有讲解如何安装,请读者自行学习相关资料。
在进行重新分片的时候,在源节点向目标节点转移一个槽的过程中,可能会产生这样的情况:被转移的槽的数据有可能部分存在于源节点中,另一部分随转移而进入目标节点中。
此时,当客户端向源节点发送与数据库键有关的命令请求,而恰好要处理的键就在被重新指派到目标节点的槽中时,源节点在接收到这条命令请求时,会到自己的数据库中查找这个需要处理的键,如果顺利找到这个键,就成功执行这条命令请求;如果没有找到这个需要处理的键,就说明这个键所对应的槽已经被重指派到新节点中,此时源节点会向客户端返回一个 ASK 错误,提示客户端转向目标节点,然后重新执行这条命令请求。
以上判断是否发生 ASK 错误的过程如图 12.26 所示。
图 12.26 判断是否发生 ASK 错误的过程
ASK 错误格式如下:
ASK :
ASK 错误格式与 MOVED 错误格式相似。
比如,返回的 ASK 错误信息为 ASK 14531 127.0.0.1:7002,则说明这个键所对应的槽号是 14 531,并提示到 127.0.0.1:7002 节点执行该条命令。
接收到 ASK 错误信息的客户端会根据其中的 IP 地址和端口信息转向正在指派槽的目标节点,然后向目标节点重新发送这条命令请求,在这之前,它还会向目标节点发送一条ASKING 命令。向目标节点发送 ASKING 命令的目的在于打开发送该命令的客户端的REDIS_ASKING 标识,用于判断是否要执行这条命令请求。在遇到 ASK 错误时,就会发送 ASK 转向操作。在这个过程中,如果不发送 ASKING 命令来打开 REDIS_ASKING 标识,目标节点就会拒绝执行这条命令请求。
如果客户端向某个集群节点发送一条关于槽 i 的命令,却没有为这个槽 i 指派节点,那么,在执行这条命令后,将会返回一个 MOVED 错误;而如果节点的 clusterState.importing_ slots_from[i]显示节点正在指派槽 i,并且发送命令的客户端具有 REDIS_ASKING 标识,那么这个节点将会执行这条关于槽 i 的命令。
REDIS_ASKING 标识是一个一次性标识。当节点执行了一条带有 REDIS_ASKING 标识的命令之后,就会立即删除这个标识。
12.3.6 集群的消息
Redis 集群的多个节点之间互相连通,构成一幅连通图,它们之间通过发送消息、接收消息来进行通信,实现集群之间的数据共享,以达到分布式、高可用的目的。其中,发送消息的节点被称为发送者,而接收消息的节点被称为接收者。消息由消息头和消息正文组成。
节点发送的消息类型有以下几类。
● PING 消息:集群节点之间通过发送 PING 消息,来检测某个节点是否在线。在默认情况下,集群中的每个节点每隔 1s 就会从已知节点列表中随机选出 5 个节点,然后对这 5 个节点中最长时间没有发送 PING 消息的节点发送 PING 消息,来判断这个节点是否在线。
● PONG 消息:当消息接收者接收到其他节点发送过来的 PING 消息或者 MEET 消息时,为了表示已经成功接收到 PING 消息或 MEET 消息,会向消息发送者返回 PONG消息,以确认成功接收到消息发送者发送过来的消息。另外,一个节点也可以向其他节点广播发送自己的 PONG 消息,来提示其他节点立即刷新关于这个节点的认识,进而确认自己的在线状态。
● MEET 消息:当消息发送者接收到客户端发送过来的 CLUSTER MEET 命令时,会向消息接收者发送 MEET 消息,请求消息接收者加入消息发送者的集群中,成为集群中的新节点。
● FALL 消息:当一个主节点(master1)判断另一个主节点(master2)已经进入 FALL状态时,主节点(master1)会向集群中的其他节点发送一条关于主节点(master2)的 FALL 消息,来表示主节点(master2)已经下线。当其他节点收到主节点(master1)发送过来的 FALL 消息时,就会立即将主节点(master2)标记为下线状态,然后主节点(master1)从属的从节点就会进行 master 选举,从节点代替这个主节点,完成故障转移等相关操作。
● PUBLISH 消息:当集群中的某个节点接收到一条 PUBLISH 命令时,该节点就会执行这条命令,同时向集群中的其他节点广播这条 PUBLISH 消息,让所有接收到这条 PUBLISH 消息的节点都执行这条 PUBLISH 命令。
13.redis实战
13.1 java连接redis
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.2.0version>
dependency>
常用api和方法:
public class TestApi {
//Redis中对键通用的操作
@Test
void universal(){
Jedis redisConnection = RedisUtil.getRedisConnection();
redisConnection.flushAll();
// 清空所有数据库中的内容
redisConnection.flushDB();
//清空当前数据库中的数据
redisConnection.select(1);
//选择指的的数据库
redisConnection.exists("k1");
//判断某个key是否存在
redisConnection.set("k2","v2");
//新增键值对
Set<String> stringSet = redisConnection.keys("*");
//获取所有的key
redisConnection.del("k2");
// 删除键为key的数据项
redisConnection.expire("k2",10);
//设置键为key的过期时间为i秒
redisConnection.persist("k2");
//移除键为key属性项的生存时间限制
redisConnection.type("k2");
//查看键为key所对应value的数据类型
Long ttl = redisConnection.ttl("k2");
//获取键为key数据项的剩余时间(秒)
}
// Redis中,字符串的操作
/**
* 字符串类型是Redis中最为基础的数据存储类型,它在Redis中是二进制安全的,这 便意味着该类型可以接受任何格式的数据,
* 如JPEG图像数据或Json对象描述信息等。 在Redis中字符串类型的Value最多可以容纳的数据长度是512M。
*/
@Test
void operationString(){
Jedis redisConnection = RedisUtil.getRedisConnection();
redisConnection.set("k3","v3");
//增加(或覆盖)数据项
redisConnection.setnx("k4","v4");
//不覆盖增加数据项(重复的不插入)
redisConnection.setex("k5",10,"v5");
//增加数据项并设置有效时间
redisConnection.del("k5");